
融合多尺度特征与多分支预测的多操作检测网络
2023-08-19 02:39朱新山卢俊彦甘永东任洪昊王洪泉薛俊韬陈颖
湖南大学学报(自然科学版) 2023年8期
朱新山 ,卢俊彦 ,甘永东 ,任洪昊 ,王洪泉 ,薛俊韬 †,陈颖
(1.天津大学 电气自动化与信息工程学院,天津 300072;2.北京国网信通埃森哲信息技术有限公司,北京 100052)
随着图像采集设备的普及和图像编辑软件的快速发展,近年来数字图像的伪造现象也越来越多.数字图像取证技术的基本思想是从图像中提取篡改痕迹的统计特征,建立分类器对篡改进行识别和判断,以获取操作的历史信息.目前,已经研究的取证技术包括图像来源取证、篡改操作取证、复制粘贴取证、图像修复取证等,这些取证技术都可以反映图像的完整性和真实性[1].
本文主要研究了对图像操作篡改的检测方法,图像操作篡改取证是当前在取证领域活跃的研究方向.可用于图像篡改的操作主要包括滤波操作、图像压缩操作、图像重采样操作等[2].图像篡改操作检测不需要过多关注图像的语义信息,主要研究各种操作对图像信号统计规律的影响.并且,操作检测可以挖掘篡改区域与无篡改区域之间的操作历史不一致性,间接实现图像复制粘贴、合成等篡改检测.
目前已有的图像篡改检测方法主要可以分为两类,一类是基于传统方法的篡改检测,另一类是基于深度学习的篡改检测.传统方法主要利用手工设计的特征来描述篡改检测模型.Chen 等人[3]通过分析中值滤波图像像素与邻域像素的差值的关系,将全局概率特征与局部相关特征进行融合,得到全局-局部特征集(Global and Local Feature Set,GLF),并基于GLF 特征设计检测器进行中值滤波检测.Vazquez-Padin 等人[4]通过奇异值分解(Singular Value Decomposition,SVD)提取图像的渐进特征值,发现真实图像与经过上采样的图像存在差异,由此设计了一种能够发现重采样痕迹的图像取证检测器.李晟等人[5]利用JPEG 合成图像中往往存在质量因子不一致性或分块位置不一致性的特点,判断图像是不是JPEG 压缩合成图像.Yang 等人[6]提出了一种基于误差的统计特征提取方案来解决双重JPEG压缩取证问题.首先,通过解压缩JPEG 图片生成重建图像,进而可以计算压缩图像与重建图像之间的量化误差和截断误差.然后,根据误差构造统计特征.最后,采用支持向量机来识别图像是不是经过双重压缩的.Wang 等人[7]对篡改图像使用似然对数滤波器提取关键点,并用鲁棒的特征来描述,以检测图像是否存在拷贝-粘贴操作.De Rosa等人[8]提出了一种基于二阶共生矩阵的对比度增强取证方案,通过计算共生矩阵每一列的标准差进行特征检测.Fan等人[9]采用高斯混合模型(Gaussian Mixture Model,GMM)对不同类型的操作图像进行统计分析建模,提取通用特征以检测不同类型的图像操作.该方法需要构建多个二分类器进行分类检测,操作复杂,而且鲁棒性不强.谢伟等人[10]提出了一种基于局部色彩不变量的图像篡改检测方法,具有较快的检测速度且鲁棒性较好.张旭等人[11]根据篡改区域与真实区域之间的光照不一致性,提出了一种透视投影下空间光照估计方法,可以检测图像是否经过拼接篡改操作.孙鹏等人[12]利用自动白平衡方法对图像块的色温进行估计,实现了图像篡改的检测与定位.传统方法通常需要手动设计特征,但手动设计特征非常困难.而且,特征提取和分类器分开设计,无法实现二者的同时优化.
近些年,深度学习已经在许多领域取得了巨大成功[13-16],学术界已经开始研究基于深度学习的图像取证技术.Zhang 等人[17]使用离散傅里叶变换将空间域图像转化到频域中,然后输入到卷积神经网络(Convolutional Neural Network,CNN).其通过训练两个卷积的偏置项,舍弃部分与中值滤波无关的频率信息.Barni等人[18]针对两次JPEG压缩提出了改进的基于CNN的取证方案.该网络具有相对复杂的结构,可以自动学习操作特征,而且能够检测有序的和无序的二次JPEG 压缩.Zhang 等人[19]将VGG(Visual Geometry Group)网络提取的特征分成两个路径输出给两个网络,分别用于提取Gamma 校正的操作痕迹和直方图均衡的操作痕迹.该方案可实现对全局对比度的检测,并对中高质量的JPEG 压缩具有很强的鲁棒性.Kumawat 等人[20]利用非JPEG 压缩图像和无损JPEG 压缩图像之间DCT系数分布的差异性,构建检测模型,以检测无损JPEG 压缩,拓展了研究方向.为确定图像拼接的位置,Pomari 等人[21]把图像变换到亮度空间,再将亮度空间特征输入ResNet[22],分类器采用了SVM.该方案可获得96%的区域定位精度.Zhu 等人[23]提出一种基于自注意力机制和残差结构的篡改检测网络.首先,结合空间和通道注意力自适应的捕捉上下文特征.然后,使用深度匹配方法计算特征图之间的相关性并生成粗糙掩码.最后,用能够保留目标边界结构的残差细化模块对掩码进行优化,实现像素级的篡改检测定位.Zhang 等人[24]提出了一种基于扩散的图像修复的取证分析方法,该方法采用改进的编码解码网络来组成特征金字塔(Feature Pyramid Network,FPN),以提取多尺度篡改特征,完成图像修复取证.Kim 等人[25]提出建立一个双流神经网络,一个是受限的CNN,一个是马尔可夫网络,前者接收原图,后者接收图像的DCT 系数,然后,将两个CNN的输出组合在一起进行操作检测.该方案具有一定程度的通用图像篡改检测功能,且提升了对JPEG 压缩的鲁棒性.田秀霞等人[26]提出了一个双通道的全卷积网络结构,深度挖掘彩色图像和隐写分析通道的篡改痕迹,可以实现图像篡改检测任务.钟辉等人[27]提出并行空洞卷积层和通道注意力模块,能够获取更全面的上下文信息.朱叶等人[28]设计了一个端到端的高分辨率扩张卷积注意力网络,具有较优的检测性能和泛化性.陆璐等人[29]使用最新的Transformer 结构与卷积神经网络融合,使模型能够检测不同大小、形状的篡改区域.
最近,也有少量研究采用目标检测框架构建篡改检测网络.Zhou 等[30]提出了基于Faster R-CNN 的双流网络实现篡改区域定位的方法.其中,以空域图像作为输入的RGB 流负责提取边界信息.再使用空域富隐写模型[31](Spatial Rich Model,SRM)滤波器将空间域图像转换成噪声图像,使用噪声流捕捉噪声图像的篡改痕迹.最后,通过双线性池化操作融合双流信息用于分类和边框回归.在此基础上,Chen[32]摒弃了SRM 滤波,改为通过CNN 来提取噪声图像特征,并引入残差网络提取特征,从而提高了检测效果.然而,这两种方法只适用于单种操作的检测及定位.
通过总结图像篡改检测的研究现状,我们发现已有的图像取证技术存在以下问题:
1)不能同时对多种操作类型进行取证.现有图像篡改检测方法大多是针对某种特定的篡改操作设计对应的检测模型,一旦有多种操作需要检测,则需要使用多个不同的检测器,效率较低,普适性不强.
2)不能对出现在同一幅图像的多种操作类型进行取证.图像伪造者往往使用多种篡改操作对图像进行处理,多种操作同时出现在图像中可能会使单一类型的操作检测失效,增大取证的难度.针对单幅图像的多操作检测具有更高的普适性,但这方面的研究目前非常少.
3)现有图像篡改检测大多是针对操作的特定参数设计.比如针对特定滤波核参数设计得到的高斯滤波篡改检测器,一旦伪造者更改滤波核尺寸和方差等参数,则检测效果下降甚至检测失效.
4)现有的方法大多对图像进行全局的判断,检测篡改操作是否发生.然而,伪造者一般只对图像进行局部篡改,如何定位局部篡改操作是个值得研究的问题.
针对当前图像篡改检测技术中存在的不足之处,本文将目标检测技术应用于图像篡改检测,设计了一种多操作图像篡改检测网络.网络结构主要分为残差主干网络、多尺度特征融合模块和多分支预测模块.该方法实现了单幅图像的多操作篡改检测,且具有较好的鲁棒性.
1 多操作图像篡改检测问题
本文需要设计基于深度学习的目标检测方案来对图像中的多种篡改操作目标进行检测和定位.更具体来说,先指定多种篡改操作类型,针对图像中存在的所有篡改操作目标,本文的方法可以检测出图像中所有篡改操作目标的最小包围矩形框以及对应的操作类型.
1.1 多操作图像篡改模型
为了更直观了解图像中的局部篡改操作,本文用图1展示篡改操作过程.图中ImgA表示原图,在图中随机选择操作区域得到ImgB.为了提高检测器的实用性,本文设计的检测方法需要对不规则区域进行检测,所以选择的操作区域也是不规则的,更加符合一般情况.接下来再对每个区域随机选择一种操作进行篡改,得到篡改后的ImgC.值得一提的是,篡改前后的图像ImgA 和ImgC 从视觉上难以区分,计算机图像取证技术从统计特征方面来分析图像是否经过篡改将是更加准确和高效的.
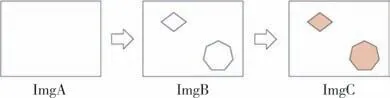
图1 多操作篡改示意图Fig.1 The process of image multi-operation tampering
当前图像取证领域对图像的多操作局部篡改缺少明确的数学模型描述.为了更清晰地理解这个问题,本文构建了图像的多操作局部篡改的数学模型.输入图像用I(u,v)表示,从原图像素到操作后像素的映射关系用F表示,不同的篡改操作对应不同的F,则对于输入图像I(u,v),经过多操作局部篡改操作后的图像I'(u,v)可以表示如下:
式中:(u,v)表示像素坐标,S表示所有操作目标的像素点坐标集合.
1.2 篡改操作与视觉语义目标的差异
本文虽然将篡改检测定位问题视为目标检测问题进行解决,但是通用的目标检测方法所提取的特征偏重内容特征,而篡改操作遗留的痕迹称为操作特征,二者存在很大的差异.研究者通过设计实验[33-34],证实了中值滤波操作遗留的痕迹特征其实是一种“弱特征”,该特征不容易被CNN 提取.同理,其他大多数篡改操作特征都存在该特性,所以需要对篡改检测网络进行针对性设计和改进.
2 多操作篡改检测网络架构
本文设计了以残差块卷积流作为提取篡改操作特征的主干网络,并联合多尺度特征融合与多分支预测模块,构建一种多操作检测深度卷积神经网络.如图2 所示,网络结构由三部分组成:主干网络、多尺度特征融合和多分支预测.输入图像为RGB 三通道图像,尺寸为300×300×3,经过主干网络提取特征,使用特征金字塔网络结构融合不同尺度的特征,得到一组多尺度特征图,然后在具有不同感受野的多尺度特征图上进行类别预测和边框位置回归,得到预测结果.测试模式的推理阶段,会将所有预测结果进行非极大值抑制,去除冗余的预测目标,得到最终的输出结果.
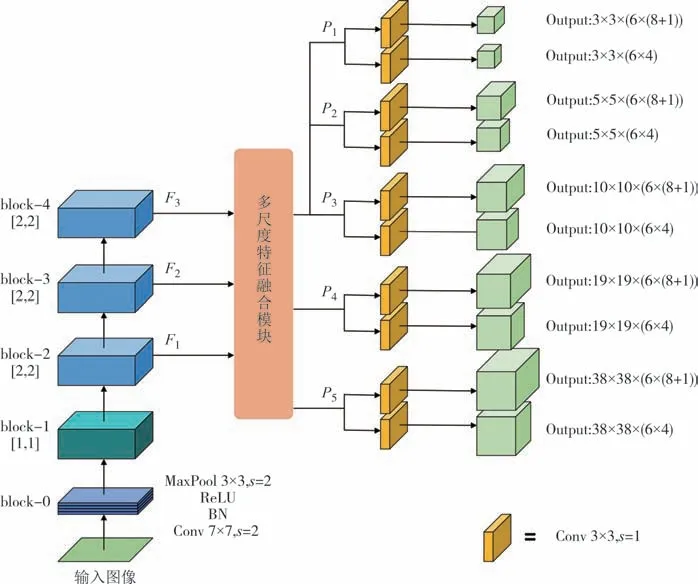
图2 多操作图像篡改检测网络结构Fig.2 The architecture of multi-operation image tampering detection network
2.1 主干网络结构设计
主干网络的主要作用是从输入数据中提取特征,能够提取到有效的特征是提高目标检测精度的关键.基于CNN的主干网络从数据中学习特征,比传统手工设计的特征具有更好的泛化能力,使模型具有更好的性能.但是,随着CNN 卷积层数的增加,会产生梯度消失和梯度爆炸问题.残差网络中的跳跃连接结构很好地解决了这个问题,让网络能够更深,模型拟合能力更强.研究者提出基于残差的局部描述子,可以看作是一个简单的约束CNN 用于实现篡改检测,能区分篡改区域和非篡改区域.本网络结构的主干就是卷积层堆叠的同时,添加跳跃残差连接,形成卷积块残差流.
如图2 所示,主干网络首先将输入图像送入block-0,经过步长为2 的跨步卷积、批归一化(Batch Normalize,BN)、ReLU 非线性激活函数和步长为2的最大池化,对输入图像降低分辨率的同时增加通道个数,减少计算量和显存占用.
接下来是四个结构相似的特征提取块,单个模块结构如图3 所示.每个特征提取块由两个残差单元组成,每个残差单元由3×3卷积、ReLU、BN 组成.使用S1和S2表示特征提取块中卷积的步长,用于进行下采样操作,可以减小特征图尺寸,降低模型的计算量.完整的主干网络参数表如表1所示.
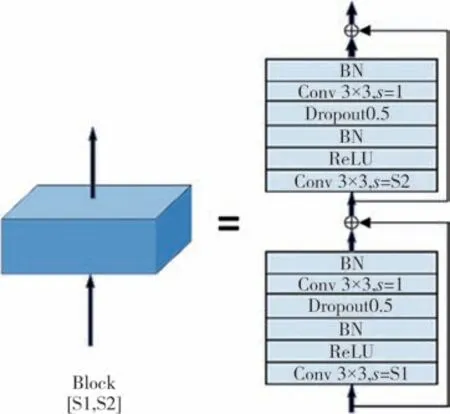
图3 特征提取块网络结构图Fig.3 The structure of feature extraction block
另外,本文设计的主干网络残差单元,添加了Dropout 层进行随机失活处理.随机失活处理的关键思想是在训练期间从神经网络中随机让神经元的输出为0,即让其丧失活性,以防止训练的模型过度依赖局部区域内神经元之间的联系,提高了模型的泛化能力.主干网络中的4 个特征提取块,共包含8 个残差单元,本文在每个残差单元的第二个卷积层之前添加Dropout层,所以共添加8个Dropout层.其中,Dropout 层的失活概率p作为超参数直接影响调节效果,本文中p取0.5.
主干网络的block-2、block-3 和block-4 特征提取块分别输出三种分辨率的特征图(F1、F2和F3),包含了篡改操作痕迹的有效统计特征.F1、F2和F3作为主干网络的输出,提供给多尺度特征处理模块.
2.2 多尺度特征融合
图像中的篡改区域面积是不固定的,为了适应不同尺寸的目标,本文基于特征金字塔结构设计了多尺度特征融合模块.具体结构如图4所示.
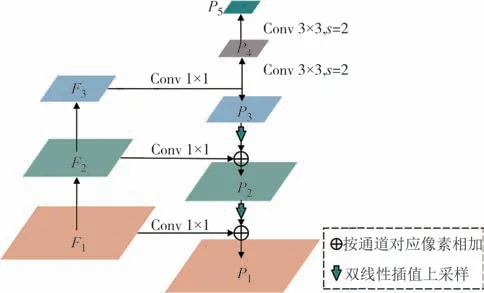
图4 多尺度特征融合模块结构图Fig.4 The structure of multi-scale feature fusion module
首先,主干网络输出的特征图F1、F2、F3,经过1×1 的卷积处理,将通道数统一为64,输入到多尺度特征融合模块中.然后,P3经过上采样和特征融合操作,得到特征图P2,P2经过同样的操作得到P1.上采样使用的是双线性插值,采样倍数为2,融合操作使用的是特征图相加操作,保持了特征图尺寸不变.接下来,对P3使用步长为2 的卷积进行下采样,得到特征图P4,进一步可以得到P5.这五个具有不同分辨率的融合特征图P1、P2、P3、P4、P5即多尺度特征融合模块的输出.
本文设计的特征融合模块划分了精细的五层多尺度,这样可以让不同尺度的目标更容易被其中一个尺度匹配,有利于提高检测精度.
2.3 多分支预测模块
多分支预测模块进行操作类型预测和边框位置回归,得到最终的多操作篡改检测结果.
多尺度特征融合模块输出的5 个特征图分别送入5 组预测头.每一组预测头包含两个并行的分类分支和边框位置回归分支,两个分支都是由连续4个卷积核大小为3×3 的卷积层组成.5 组预测头结构相同,但是权重参数不共享,每组预测头可以适应不同大小的目标区域.
为了减少计算量,同时提高预测的准确性,本文在输出预测特征图的每个像素位置放置B个锚框,本文中B取4.锚框放置方式如图5 所示.令hl表示输入特征图Pl的高度,l∈{1,2,3,4,5},则特征图中每个锚框的高度和宽度ah、aw的计算公式如下:

图5 锚框设置示意图Fig.5 The setting of anchor boxes
式中:t表示锚框的纵横比,本文选择1∶1和2∶3两种纵横比.αsf表示锚框的缩放系数,该参数决定了特征图相对于所有锚框的整体大小比例,本文αsf取值为16.αsf的取值需要适应数据集的大部分目标的尺寸分布,如果整体尺寸较大,αsf应当设置更大的值,反之亦然.
假设总共要预测K类目标,那么一个分类分支输出的通道总数=B·K,一个边框位置回归分支输出的通道总数为=4K.分类分支预测的是每个锚框分别属于K个类别的概率,边框位置回归分支预测的是每个锚框相对于真实边框位置的中心坐标的偏移量(Δx,Δy)、宽度偏移量Δw和高度偏移量Δh.边框位置回归分支预测的都是相对于锚框的偏移量,而不直接预测边框相对图像的绝对位置,这是因为锚框是人为预设的已知信息,在这个基础上预测边框位置的偏移量,可以更好地接近真实物体.反之,如果直接预测边框绝对位置,那么可能由于边框坐标变化幅度大而导致网络难以收敛.
在测试模式下,为了得到最终有效的输出,需要将预测得到的结果进行转换和筛选,保留有效预测结果.本文网络结构将预测结果经过边框绝对位置转换和非极大值抑制两个过程,得到最终输出结果.为了得到边框的绝对位置,先要利用锚框的参考位置,将预测结果转换成绝对位置.接下来剔除冗余的预测结果,因为锚框是在特征图上密集放置的,一张300×300×3 的输入图像,生成的融合特征图尺度集合为{3,5,10,19,38},放置的锚框个数为(32+52+102+192+382)×4=7 756,这些锚框区域存在大量重叠.所以对任意一个图像中的真实目标,可能存在多个锚框覆盖,导致预测结果中可能有多个预测目标对应一个真实目标的情况.为了抑制这些冗余的预测,本文采用Soft-NMS 算法[35],相比NMS更加灵活,而且提高了检测器的召回率.
2.4 损失函数
为了更好地引导神经网络完成取证任务,正确优化网络权重参数,损失函数的设置至关重要.
本文总损失Ltotal由分类损失Lcls和边框位置回归损失Lloc组成.计算公式如下:
式中:np为所有正样本数量,nn为用于计算损失的所有负样本数量.
Lcls使用交叉熵损失,同时统计了所有正样本和负样本损失,其数学表达为:
式中:K表示目标种类数,log(·)表示对数函数,表示将第i个样本划分为第k类目标的概率,表示将第j个负样本划分为背景类别的概率.
Lloc使用Smooth L1 损失[36],只统计了所有正样本损失,计算公式为:
式中:表示第i个正样本的边界框的m属性的网络输出值,表示图像中与第i个正样本对应的真实目标的边框与锚框在边界框属性m上的偏移量.这里两个边框的位置偏移量 Δ 具体由(Δcx,Δcy,Δw,Δh)四个属性表示,Δcx、Δcy表示两个边框中心点的偏移量,Δw/Δh分别表示两个边框的宽度和高度的偏移量,LL1(·)表示Smooth L1损失.
模型的复杂度与权重参数w的个数呈线性关系,即参数量越多,模型越复杂.在训练数据量有限的情况下,过高的模型复杂度容易引起过拟合,所以考虑用更宽松的正则化来限制权重参数.正则化是通过在预测值和真实值的损失Ltotal之外,引入一个正则项Ω(w)来约束权重参数.加入正则项后,公式如下:
式中,λ是调节正则项权重因子,本文取0.003.
常用的正则化函数有L1范数和L2范数,本文使用L2 范数,对应的正则化叫L2 正则化,L2 正则项表示如下:
从公式(7)和(8)可以看出,L2 正则化将权重参数w的平方和引入损失函数的计算中,权重参数平方和越大,损失越大,所以优化目标变成了最小化数据损失的同时,让所有权重参数w的平方和尽量小.这样所得的网络优化权重参数较为均衡且较小,确保网络提取的所有特征都能对最终决策起作用,因此可以获得更好的泛化性.
3 实验结果与分析
为了测试提出的多操作图像篡改检测方案的性能,本文构建了多操作篡改图像数据集,并用该数据集对模型进行了训练和测试.然后,将该数据集应用到主流目标检测网络进行训练和测试,使用平均精度(Average Precision,AP)和平均精度均值(mean Average Precision,mAP)来评估检测器的检测性能,比较本文方案的优缺点.此外,在数据集中添加了JPEG 压缩、模糊、加噪、重采样等后处理操作,并测试检测模型性能,验证检测方法的鲁棒性.
3.1 数据集构建
本文基于公开数据集获取的源图像,制作了一个多操作图像篡改数据集.选择了八种图像操作对源图像进行篡改,分别为中值滤波(Median Filtering,MF)、高斯滤波(Gaussian Filtering,GF)、高斯白噪声(Gaussia White Noise,WG)、重采样(Resampling,RS)、同态滤波(Homogeneous Filter,HF)、直方图均衡 化(Histogram Equalization,HE)、Prewitt 锐 化(Prewitt Sharpening,PS)和Gamma 变 换(Gamma Transformation,GT).这八种操作包括了图像篡改领域常用的增强操作,能进行图像增强,修改图像的对比度、色调等视觉效果,还可以掩盖合成篡改操作遗留的痕迹.部分数据集图像如图6 所示,其中第一行是原始图像,第二行是生成的篡改区域及操作类型伪彩图,第三行是篡改后的图像,第四行是带真实标签的图像.

图6 部分数据集图像Fig.6 Some typical examples from the datasets
篡改操作的参数设置如下.同态滤波计算如公式(9)所示:
式中:D(u,v)为输入图像信号,H(u,v)为输出同态滤波结果,D0表示截止频率,c控制从低频到高频过渡段的速度,γH和γL控制滤波器的幅值上限和下限.在本文中,γH=2.2,γL=0.25,c=2,D0=0.008.
Gamma变换结果G(u,v)的计算见公式(10):
式中:α0是变换的线性系数,γ为变换的指数.在本文中,α0=1.02,γ=1.2.
对于中值滤波和高斯滤波,本文选择了3×3、5×5、7×7 三种尺寸的滤波核.高斯滤波和高斯白噪声的标准差σ=1.2.最后,局部重采样的缩放因子设置为α=0.5.
数据集的制作流程见表2.其中,不规则篡改区域的像素面积占全图像素面积的比例介于3%~7%.由图6 可以看出,局部区域篡改操作后的图像,从人眼视觉上并无明显差异.数据集共有17 125张图像,并把篡改数据集按照约9∶1 的比例划分为训练集和测试集.值得注意的是,为了避免类别不平衡导致训练的模型偏重类别数量多的一方,本文在制作数据集过程中,保持了不同类型的目标数量的相对平衡,各类别数量和占比如表3所示.

表2 本文数据集制作流程Tab.2 The procedure for the construction of our forensics dataset
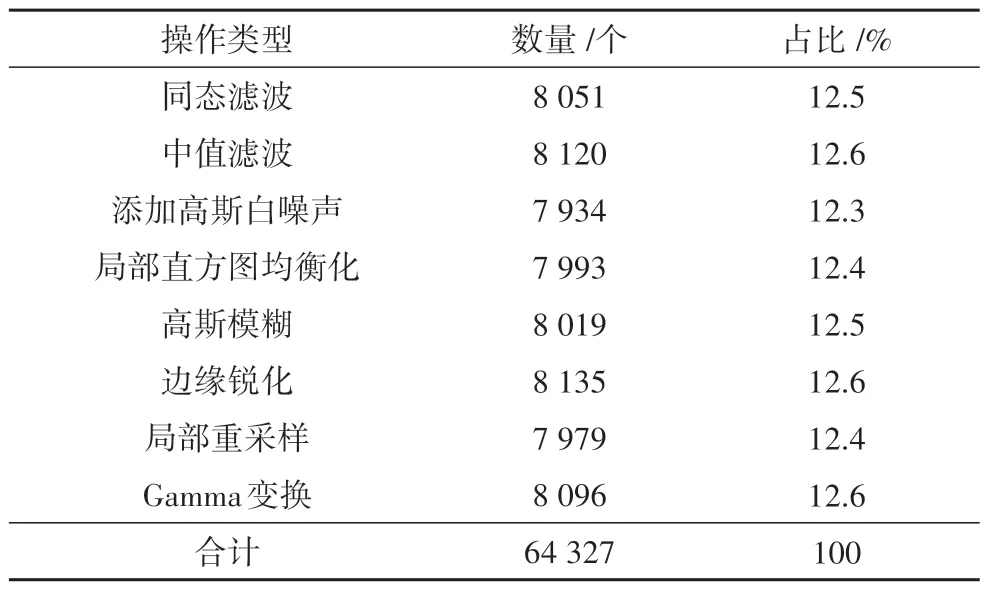
表3 本文数据集各操作类型对象的数量和占比Tab.3 The number and proportion of objects of each operation type in this dataset
3.2 训练细节
本文模型的训练与测试使用NVIDIA GeForce RTX 3090 GPU,Intel Xeon(R)W-3223 CPU 和64GB RAM.所提出的网络模型使用PyTorch 深度学习框架实现,输入图像尺寸为300×300×3.网络训练采用随机梯度下降优化器(Stochastic Gradient Descent,SGD),训练参数设置如下:动量为0.9,衰减系数为0.000 5,初始学习率为9×10-4.学习率和梯度决定了每次迭代更新参数的幅度,所以学习率的设置非常重要,随着模型收敛,学习率应该逐渐下降.否则在最优解附近,过大的学习率会导致损失严重振荡甚至发散.所以本文设置逐渐衰减的学习率,当迭代次数为{7×104,9×104,11×104,13×104} 时,学习率在上一次的基础上衰减40%.另外,训练时每次送入神经网络的批尺寸(Batch size)大小设置为128.
深度学习方法通常依赖大量的数据集,当数据量不足的时候,可以使用数据增强技术,在不实质性增加数据的情况下,对现有数据执行变换操作,变换后的数据具有同等的训练价值.常用数据增强方法中的变形、缩放、模糊等操作很容易破坏篡改操作痕迹,所以本文尽量避开这些数据增强方法,而采用对操作特征影响不明显的数据增强方法,比如图像翻转和镜像方法进行数据增强,提高模型的泛化能力.同时,本文所有的训练数据都经过了JPEG 压缩,压缩因子为75.
3.3 评价指标
为了能够客观地对本文提出的方法进行评价,本章选取了平均精度(Average Precision,AP)和总平均精度(mean Average Precision,mAP)两个常用的评价标准.
平均精度可以综合不同情况下的召回率和准确率信息,以衡量模型对于某一类别目标的检测效果.最准确的方法是将准确率-召回率曲线与坐标轴所围成的面积作为平均精度值.但实际计算AP 时,为了减小计算量,会在召回率上均匀取11 个点作为11个召回率阈值,统计召回率大于每一个阈值时对应的最大精确率,求取该11 个精确率的平均值得到AP,这种方法也叫11点法,可以表示如下:
式中:r表示召回率,pre(r)表示召回率为r时,对应的精确率最大值.
对于需要检测多种目标的检测器,则取每类的AP的均值作为总平均精度mAP.假如有K类目标,第j类目标的AP 值表示为APj,则该检测器mAP 计算公式如下所示:
3.4 无后处理的性能测试
为了说明本文方法的有效性,选择两种当前主流的单阶段Anchor-based 目标检测方法:SSD[37]和YOLOv3[38]作为对比方法.我们使用相同的训练参数,对这两种检测方法进行了训练和测试.
本文使用三种检测方法分别对测试图像进行检测,检测结果如图7 所示.其中,第一行为篡改后的图像,第二行为篡改真实标签图,第三到五行分别为SSD[37]、YOLOv3[38]和本文模型的测试结果.我们提出的模型展示出了优秀的性能,比如:第一列的图中,SSD 和YOLOv3 都漏检了一个同态滤波,而本文方法成功检测到同态滤波篡改对象;在第三列的图中,YOLOv3 误检了一个锐化篡改操作,SSD 和本文提出的方法都成功检测.但是,本文提出的方法检测的置信度得分相较于SSD 要高很多,本文方法检测三个操作目标的置信度分别是0.71、1.00、0.95,而SSD 对应的置信度是0.43、0.98、0.47,证明本文的检测方法更加稳定可靠;第五列的图SSD和YOLOv3都误检了一个高斯白噪声篡改对象,只有本文提出的方法正确检测出全部的操作类型和准确的定位.

图7 可视化取证结果Fig.7 Visualization of forensic results
然后,本文用测试集对训练得到的模型进行客观性能评估,当真实标注区域与预测篡改区域重合区域的交并比(Intersection over Union,IoU)大于50%时,认为该区域识别准确,测试结果如表4所示.观察实验结果可以发现,本文提出方法的mAP 指标为69.69%,比SSD 高5 个百分点,比YOLOv3 高4 个百分点,说明在8 种目标的平均精度上,本文提出的方法具有很大的优势.另一方面,比较单个类别的AP指标,SSD对局部直方图均衡化的检测精度最高,为79.60%;YOLOv3 对同态滤波和Gamma 变换的检测精度最高,分别为92.26%和40.74%.对于其他五个类别,本文提出的方法都具有最高的单类检测平均精度.此外,三种检测方法普遍存在对中值滤波和Gamma 变换的检测困难,AP 指标都低于45%.综上所述,本文提出的方法在较好定位出篡改区域的前提下,还能够准确地区分篡改操作的类型.
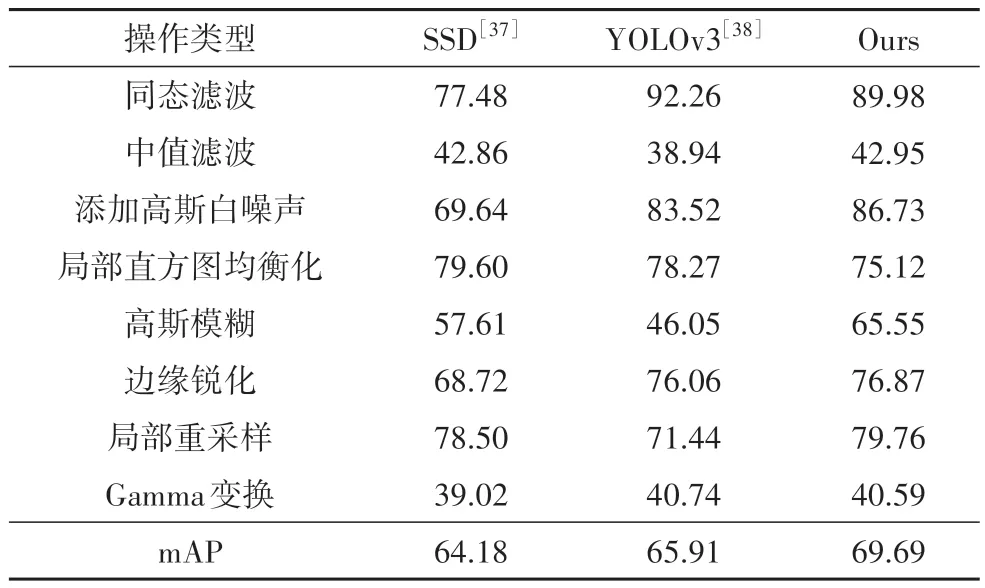
表4 不同取证方案取得的AP结果Tab.4 Experimental results of different forensics methods%
3.5 鲁棒性分析和比较
为了测试本方法在篡改图像经过各种后处理情况下的检测效果,本文对测试集图像进行5 种后处理,得到5 个鲁棒性测试数据集.5 种后处理方式分别是JPEG 压缩、二次JPEG 压缩、缩放操作、添加椒盐噪声和双边滤波,具体参数如表5所示.

表5 后处理参数Tab.5 Parameters of the post-processing
用得到的5 个鲁棒性测试数据集,分别对原始数据集训练得到的检测模型进行测试,三种方案的平均检测结果记录在表6 中.括号内的数据表示当前测试与无后处理情况下的测试结果的差值,可以反映模型在不同后处理情况下检测性能变化情况.
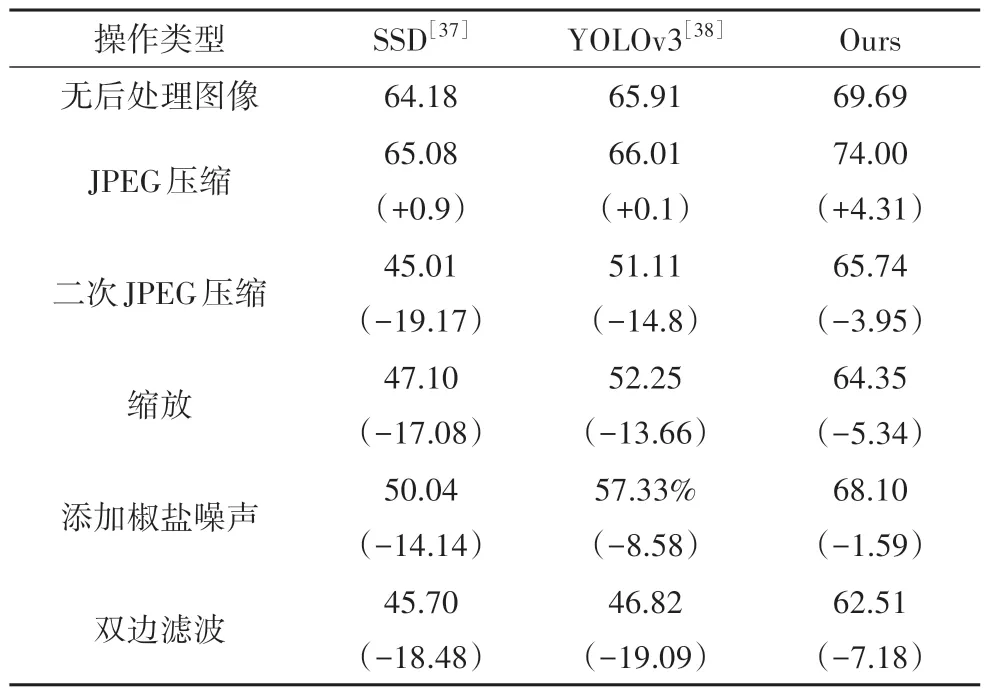
表6 不同取证方案对经过后处理图像取得的mAP结果Tab.6 Experimental results of different forensics methods on post-processing images %
观察表6,经过JPEG 压缩(QF=95%)处理后,三种检测方法的mAP 指标都有所上升,这是因为本文训练使用的是经过JPEG 压缩的图像,所以模型能学习到压缩后篡改痕迹特征.其中,本文提出的方法上升幅度最大,达到了4.31%,其他两种方法只上升了0.1%和0.9%.对于二次JPEG 压缩(QF1=75%,QF2=95%)后处理,SSD 和YOLOv3 都下降了超过10 个百分点,本文的方法只下降了3.95%.其他后处理操作都可以观察到类似的现象,本文方法下降幅度都远小于SSD 和YOLOv3.以上结果表明本文提出的方法能更好地应对JPEG 压缩、二次JPEG 压缩、缩放、加噪和双边滤波后处理,具有更强的鲁棒性,优于经典的SSD和YOLOv3检测器.
3.6 模型复杂度
本文使用参数量和模型计算量(Floating Point Operations,FLOPs)两种指标,对SSD、YOLOv3 以及本文模型进行了复杂度评估,其中输入图像的尺寸为300×300×3.结果如表7 所示,可以看出本文提出的方法在各项指标上都好于SSD.而YOLOv3 的FLOPs 指标略低于本文模型,但是模型参数量远高于本文提出的模型,说明其模型更为复杂.综上,本文提出的方法使用更少的参数,实现了更强的性能,但是在计算效率方面还可以优化.

表7 模型的复杂度对比Tab.7 Comparison of model complexity
4 结论
本文提出了一种基于深度学习的多操作图像篡改检测深度神经网络.与其他篡改检测网络只能检测单一类型的操作目标不同,本文提出的检测网络能同时检测图像中存在的多种篡改操作目标,且对每个操作目标使用最小包围的矩形边框确定位置.通过构建的数据集对网络进行训练和测试,结果表明:本文提出的方法能有效进行多操作篡改检测和定位,且能应对JPEG 压缩、缩放、加噪和双边滤波等图像后处理.
猜你喜欢
黄河之声(2022年10期)2022-09-27
智能制造(2022年4期)2022-08-18
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
