
气象数据分区处理算法与策略研究
2023-08-15 02:02文立恒朱宏武
计算机技术与发展 2023年8期
冯 冼,方 昆,文立恒,朱宏武
(1.湖南省气象信息中心,湖南 长沙 410118;2.气象防灾减灾湖南省重点实验室,湖南 长沙 410118)
0 引 言
气象现代化和信息化不断推进,业务服务不断拓展,各类气象数据海量增长[1]。以湖南为例,目前各类观测系统、CMACast和行业汇集的数据达400 GB/日。尤其是建设湖南省高分卫星气象应用中心后,增加了高分遥感卫星资料,日处理数据量达TB级。如何进行海量气象数据高速处理,为气象预报预警、防灾减灾提供更及时、更高效的数据服务,其作用至关重要[2]。
近年来信息技术不断发展,出现了Hadoop、HDFS、MapReduce等技术支撑海量数据处理,在气象和其他行业普遍应用[3-5],但由于Hadoop基于文件批处理设计、MapReduce基于批处理模型编程,普遍存在响应不及时、处理延迟大等情况。为解决上述问题,信息行业提出了Storm分布式架构[6]以及Spring Cloud云架构[7]增强实时数据处理能力,采用Apache Kafka[8]作为流式数据处理消息中间件,剥离数据流程中的发送、处理、输出环节,因具备扩展能力强的特性在气象和各行业广泛应用[9-10]。
但随着数据挖掘与分析应用的不断深入,Kafka消息并发能力和数据吞吐性能有待进一步优化的问题也逐渐表露出来,众多学者也开展了改进Kafka性能的相关研究。Bunrong Leang等提出在大数据环境下基于分区和多线程的流媒体改进方法以提升Kafka性能[11],颜晓莲等提出一种改进型Kafka Partition过载优化算法缓解Partition过载问题[12],为解决气象数据在Kafka中高效处理提供了借鉴。
为解决在有限基础资源支撑下提升气象数据并发处理性能的技术难点,该文提出了一种气象数据在流转和处理时所需耗费的基础资源综合权重计算方法,以及基于气象数据综合权重在Kafka中分区处理的最优策略,极大提升了气象数据并发处理效率。
1 算法设计
1.1 气象数据综合权重计算思路
权重计算法是一种常见的评价分析方法,在数据处理中得到广泛应用[13-14]。在数据权重评价体系中,某一个权重的大小不仅取决于单位数值(或变量)大小,也取决于单位数值在一定时间的出现次数(即为频率),因此也统称为权数[15]。
常用的权重计算法包括主观赋权法、客观赋权法等类型。主观赋权法主要通过专家和决策者意愿或经验确定指标权值,其不足在于过分依赖专家意见。而客观赋权法则通过数据相互之间的关联性计算分类权重,其数学理论依据较强,应用也较为广泛。
该文采用客观赋权法中的熵权法[16](Entropy Weight Method,EWM)对气象数据集中各类数据特征指标进行综合计算,依据计算得出的信息熵确定其综合权重,即为气象信息系统处理某类气象数据所需占用系统资源的相对比例。某类气象数据权重值越高,处理时需占用的系统资源越多,则越容易对处理系统的性能造成较大的影响。
1.2 优化Kafka并发处理性能的思路
近年来随着大数据挖掘分析的广泛应用,基于MQ的传统消息模式难以满足海量数据实时传输处理需求,而流式消息处理中间件Kafka较好地适应了这种需求[17],气象大数据云平台[18]、气象综合业务监控系统[19]以及湖南高分卫星多源数据获取管理平台均采用Kafka作为消息中间件。
Kafka处理集群中包含Producer(消息生产者)、Broker(处理节点)、Consumer(消息消费者)等核心组件。其数据处理流程如图1所示。
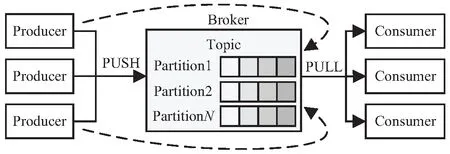
图1 Kafka数据处理流程
一个Kafka集群可以设计多个Broker服务,每一个Producer以Thread(线程)方式通过PUSH方法将消息发送至相应的Broker。每一个Broker中又可分为多个Topic(消息主题),分组对消息进行管理。而Partition(消息分区)则是Topic的物理组成,各类消息顺序写入一个或多个Partition中,通过一个或多个Consumer组成ConsumerGroup(消费者群组)以PULL方式顺序读取消息,从而达到读写速度O(1)的高性能。
从Kafka数据处理流程分析,可以通过以下方法提升气象数据并发处理性能:一是将气象数据按科学方法进行分区,利用Kafka多Partition的方式提升并发处理性能;二是设计气象数据在Kafka生产端的Producer实例池,通过多Thread并发的方式提升消息写入性能;三是按业务需求将气象数据服务端多个Consumer组合成Group,通过多Thread并发方式提升消息读取性能。
1.3 气象数据分区处理算法设计
依据上述气象数据综合权重计算和优化Kafka并发处理性能的思路,设计气象数据权重算法和分区策略,流程如图2所示。
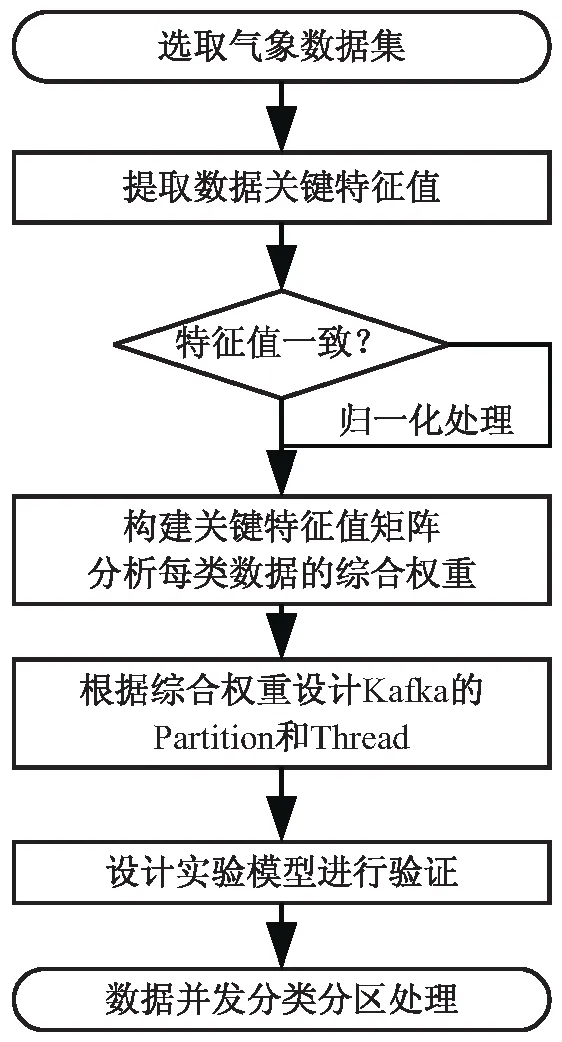
图2 并发处理算法流程
首先选取具有代表性的气象数据集,提取对气象数据处理所耗费基础资源相关性较大的关键特征,采用熵权法进行综合权重计算。再以气象数据关键特征综合权重为分区处理依据,分别在Kafka中设计相应的Topic、Partition进行分区处理,并采用多Thread方式并行处理,提升气象数据处理效率。
2 气象数据综合权重计算
2.1 选取数据集
从湖南气候特征分析,每年5月下旬至7月上旬为汛期关键时期[20],因此选取湖南省内2020年6月1日至6月30日的气象数据作为实验数据集,涵盖天气晴朗、阴雨、暴雨等复杂天气过程。在数据服务需求方面考虑,选取气象数据处理系统中最具代表性,在气象预报预警和防灾减灾中应用广泛、时效性要求高的数据,包括:国家站观测数据、区域站观测数据、雷达基数据、雷达PUP产品、卫星云图数据等,详情如表1所示。
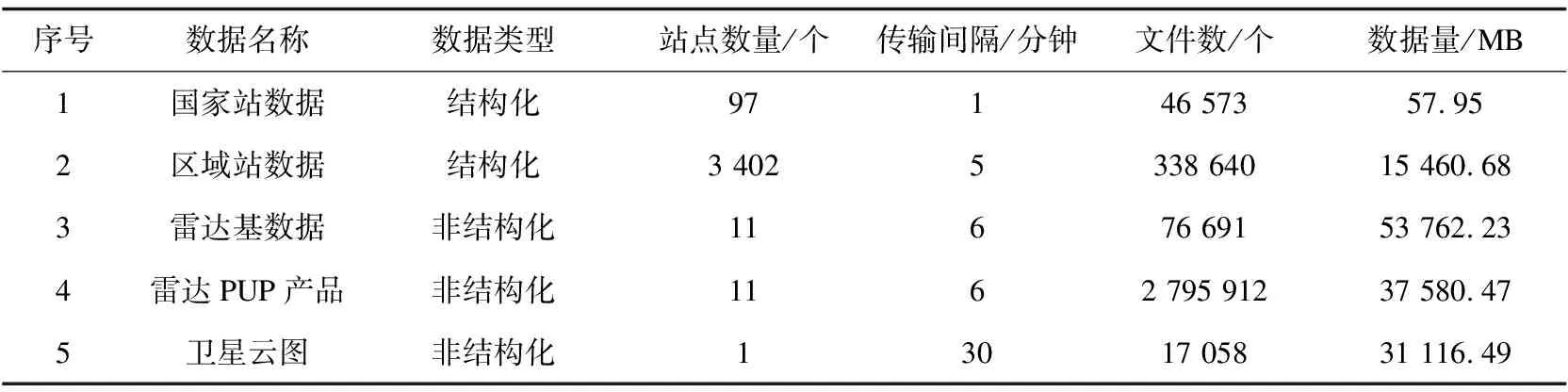
表1 气象数据集详情
气象数据集中,国家站数据为BUFR格式传输落地所生成的二进制文件(BIN),包括气温、风向、风速、降水等观测要素,传输间隔1分钟;区域站数据为中心站生成的文本数据(TXT),包括二要素、四要素、六要素等不同类型站点,传输间隔5分钟;雷达基数据为湖南省内11部多普勒天气雷达标准格式数据(BZ2),传输间隔6分钟;雷达PUP产品包括基本反射率、组合反射率、回波顶高等不同类型产品文件(BIN),传输间隔与雷达基数据一致;卫星云图数据选择常用的FY-2G卫星AWX文件,包含红外、水汽、可见光等要素,传输间隔30分钟。
从表1可以看出:气象数据集包含数据名称、数据类型、站点数量、传输间隔、文件数、数据量等多种特征指标,不同特征指标的量度差异大,同一特征指标的离散度较高,在数据处理层面,难以从单一特征指标得出科学处理方法。因此,该文采用熵权法计算所有气象数据关键特征指标的综合权重,再根据综合权重进行分区,结合Kafka特性提升气象数据并发处理性能。
2.2 关键特征量权重计算
从计算机系统原理以及气象数据处理流程分析,上述气象数据集中,影响处理性能的关键特征指标为站点数、传输间隔、文件数、数据量,而数据名称、数据类型等描述性信息对计算机系统运行性能不会产生影响。因此,在气象数据权重算法中,提取站点数量、传输间隔、平均数据量(即数据量除以文件数)三个指标参与计算。为同化数据,将传输间隔(分钟)转化为传输频率(次/小时),形成气象数据关键特征量,如表2所示。
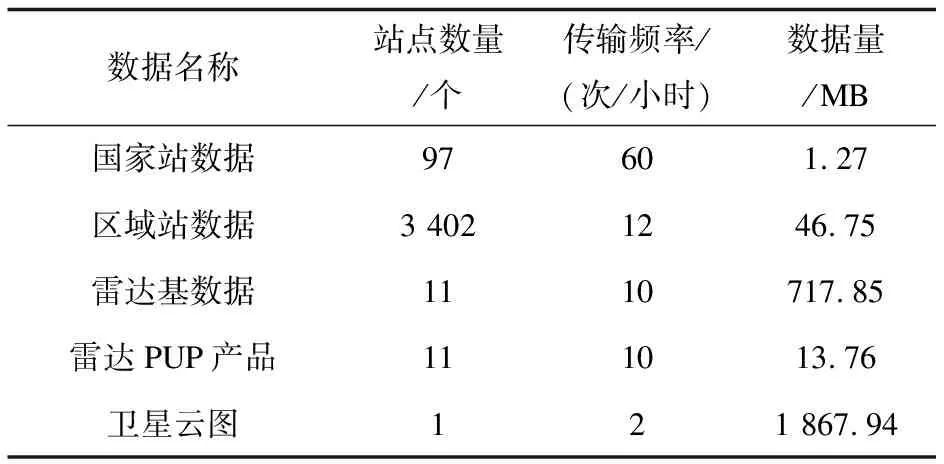
表2 气象数据关键特征量详情
进行权重计算前,首先要将表2中的气象数据关键特征量进行Normalization(归一化)处理[21],剔除不同种类气象数据关键特征量的单位度量,将气象数据关键特征量转化为不包含量纲的纯数值,便于进行不同类型或量级的特征量基于客观权重的综合评价综合分析数据处理中常用的各类归一化方法,Linear Normalization(线性归一化)[22]在分析各数据变量权重时过分依赖两个极端值;ZScore Normalization(零均值归一化)[23]常用于信号处理,需要数据基于正态分布;Mean Normalization(均值归一化)[24]采用平均值对数据特征进行缩放,减少数据之间的波动。
该文的目的是计算各类气象数据关键特征量的综合权重,从而分析其在数据流转和处理等环节所消耗的基础资源,因此采用Sum Normalization(总和归一化)[25]方法,得出每一类气象数据在整个数据处理系统流转所需耗费系统资源的比例,其过程如下:
(1)通过公式(1)计算气象数据关键特征量的Pij矩阵,用于后续权重分析。
(1)
式中,i代表气象数据特征量序号,j代表气象数据种类序号,n为气象数据种类总量。经计算,得出上述气象数据关键特征量Pij矩阵为:
(2)通过公式(2)计算每类气象数据每个关键特征量的PijLn(Pij)矩阵Lij。
Lij=PijLn(Pij)
(2)
得出气象数据关键特征量Lij矩阵如下:
(3)基于Lij矩阵,通过公式(3)逐个计算每类气象数据每个关键特征量的信息熵Ej。
(3)
式中,n为气象数据种类数量,K为常数,根据公式(4)进行计算。
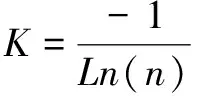
(4)
本例中n=5,得出K值为0.621 334 935。经计算,得出气象数据关键特征量的信息熵Ej,以及信息熵的冗余度(1-Ej)矩阵如下:
(4)通过公式(5)计算每一类气象数据关键特征量在总量中所占的权重Wj。
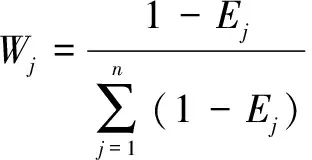
(5)
计算得出气象数据Wj矩阵如下:
(5)按公式(6),通过各特征量的权重系数Wj与每类数据对应的特征量相乘,最后按气象数据类别分别进行求和,得出每类气象数据的综合权重值。
(6)
最终得出气象数据集中各类数据关键特征量的综合权重Sij,如表3所示。
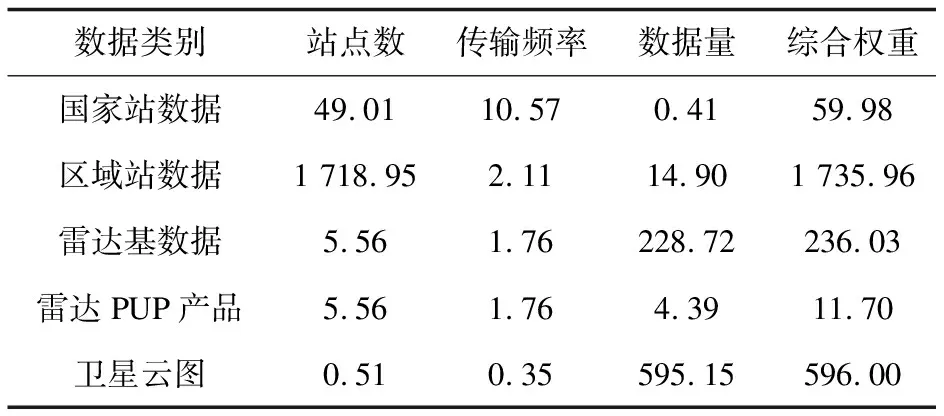
表3 综合权重
2.3 气象数据分区思路
对表3进行分析,五类气象数据综合权重分布在三个区间:最高的区域站数据权重为1 735.96,最低的雷达PUP产品权重为11.70,五类数据权重均值为527.94。因此需要根据综合权重合理分区,通过多分区并行处理的方式减轻单类数据、单一流程占用系统资源过多导致数据堵塞的情况,提升整体数据处理性能,步骤如下:
(1)在Kafka中,为五类气象数据分别设计一个Topic,便于应用端分类开展数据服务。
(2)依据Kafka数据处理原理,在每类气象数据所分配的Topic中,最少应分配一个Partition。因此对于综合权重较低的国家站数据、雷达PUP产品两个Topic,直接采用单Partition进行分区。
(3)对于综合权重最高区域站数据,其权重达到五类数据权重均值的3.29倍,是最低权重的148.37倍。合理配置其Partition,并优化Thread数量,对Kafka集群整体性能至关重要。该文将设计实验平台对其不同Partition、Thread数量进行实验,得出最佳策略。
(4)对权重处于中间区间的卫星云图、雷达基数据的分区策略,对比最高和最低分区数量分别设计。
3 分区策略实验
3.1 模型设计
为找出气象数据分区最优策略,参考气象大数据云平台架构,设计以Kafka为消息中间件的气象数据处理实验模型,分别从Producer消息写入、Consumer消息读取两端,通过不同数量的Partition和Thread进行对比实验,得出最优解。
此模型在Kafka Cluster中设计了4个Broker进行分布式处理,模拟气象大数据云平台中数据流转的实际状况。在Producer端采用并发写入设计,针对不同气象数据输入场景,分别模拟多个写入Thread,测试不同Producer Thread数量对Kafka消息写入性能的影响。在Consumer端则构建了多个Group,模拟多个气象预报预警服务应用端并发提取消息的状况,测试不同的Consumer Thread数量对Kafka消息读取性能的影响。
支撑模型运行的基础资源为4台部署在湖南气象虚拟化资源池中的虚拟服务器(CPU 8*2.2 GHz,RAM 32 GB),操作系统采用CentOS,部署Kafka作为消息中间件,采用Ngnix实现负载均衡,服务器之间依托1 000 Mbps内网互联。
按照综合权重计算结果,选取测试数据集中综合权重最大的区域站数据作测试,包含AWS_FTM_PQC格式的文件总数338 640个,数据总量15 460.68 MB。直接采用Kafka本身提供的Producer-Perf-Test和Consumer-Perf-Test工具,分别进行消息写入和消息读取的并发性能测试,从而验证气象数据在不同Partition和Thread数量下的并发处理性能,包括MsgRate(消息并发量)和DataRate(数据吞吐量)。
3.2 实验结果
3.2.1 Producer端多Partition并发实验
首先测试区域站数据在不同Partition数量下的并发处理性能。测试方式为:在Producer端通过单Thread写入测试数据,测试Kafka处理性能变化情况,实验得出的Kafka消息并发量和数据吞吐量的性能变化曲线如图3所示。
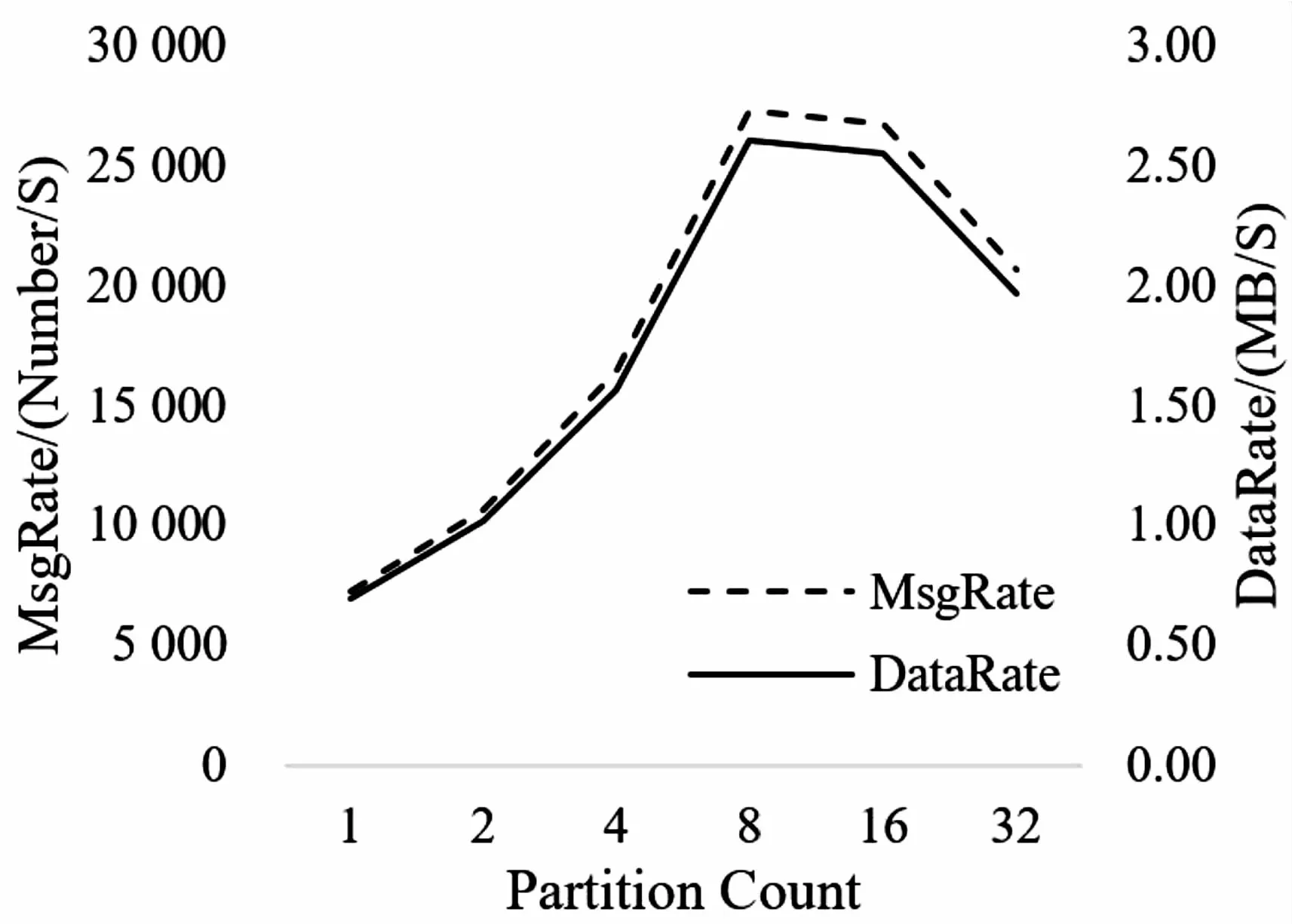
图3 Producer端多Partition并发性能曲线
从图3可知:在Producer端写入消息过程中,随着Kafka中Partition数量增长,其消息并发性能和数据吞吐量均随之增长,在Partition数量为8时达到峰值,随后其并发性能随着Partition数量增长而下降。
实验得出最优Partition数值为8,为实验平台的Broker总数量的2倍,此时Kafka并发处理性能相比单Partition可提升至377.06%。
3.2.2 Producer端多Thread并发实验
在实验得出Producer端最优Partition的情况下,进一步测试不同Thread数量对Kafka并发处理性能的影响,实验得出的Kafka消息并发量和数据吞吐量的性能变化曲线如图4所示。
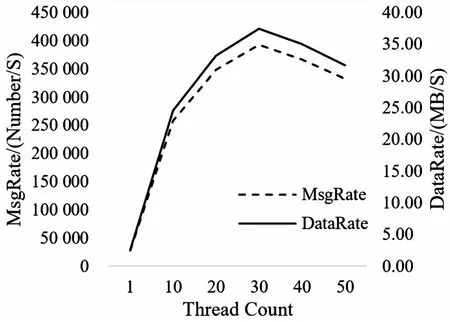
图4 Producer端多Thread并发性能曲线
对图4进行分析:在Partition为8的情况下,随着Kafka中Thread数量增长,其并发处理性能也随之增长,在Thread数量为30的时候达到最优,随后其并发性能随着Thread数量增长而下降。
实验得出最优Thread数值为30,排除实验误差影响,与实验平台中单个Broker的CPU核心数32个一致,此时Kafka并发处理性能相比单Thread可提升至1 439.69%。
3.2.3 Consumer端多Partition并发实验
参照前述Producer端测试过程,继续测试Kafka在Consumer端的并发处理性能。测试方式为:模拟Consumer端从Kafka中读取已存储的区域观测站测试数据,验证不同Partition数量下的并发处理性能,实验得出的Kafka消息并发量和数据吞吐量的性能变化曲线如图5所示。
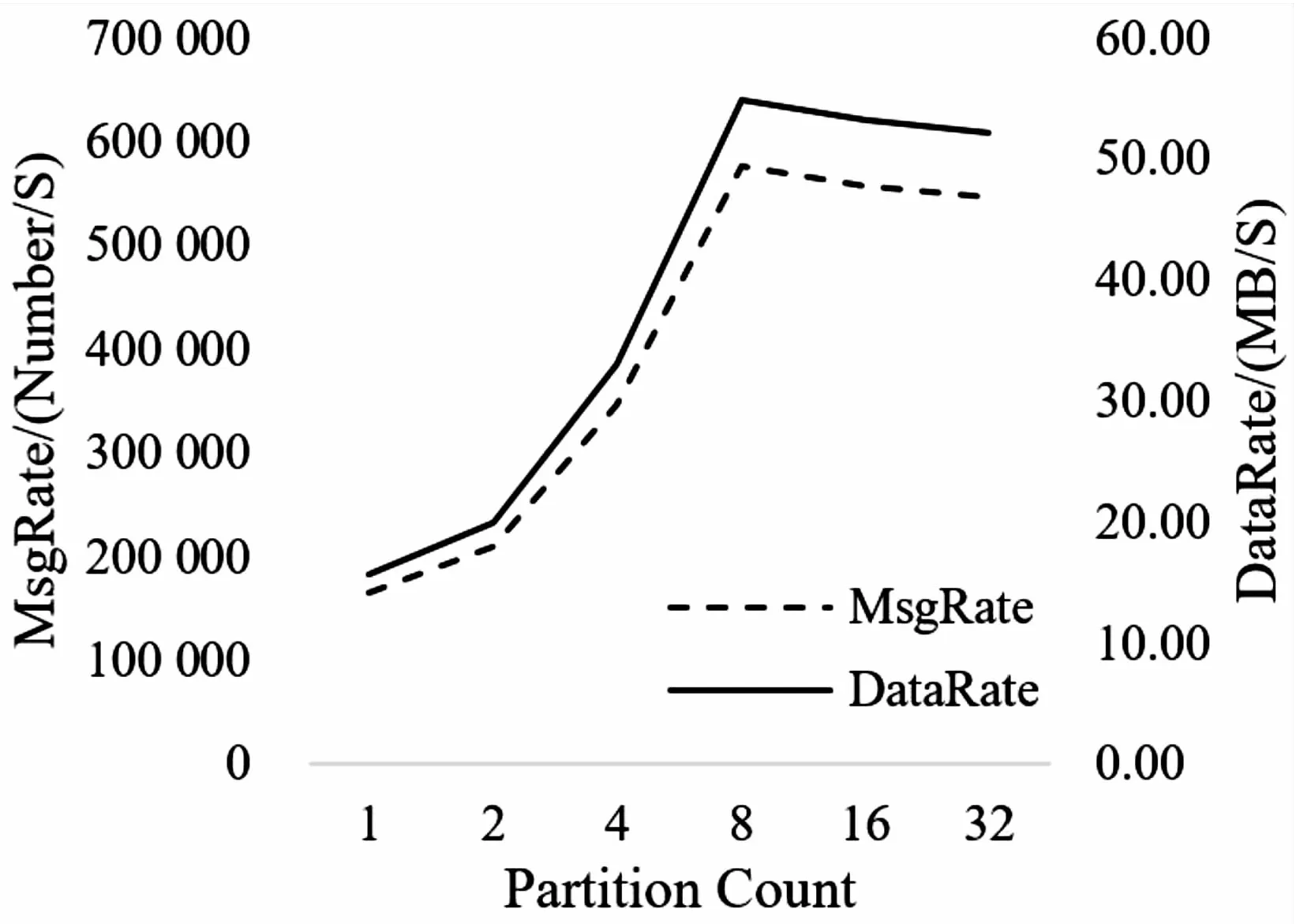
图5 Consumer端多Partition并发性能曲线
通过图5分析可知:在Consumer端单Thread情况下,Kafka并发处理性能随着Partition数量的增长而提升,最优Partition数量为8个,与Producer端实验结论一致。此时Kafka并发处理性能相比单Partition可提升至350.73%。
3.2.4 Consumer端多Thread并发实验
继续测试Consumer端不同Thread数量对Kafka并发处理性能的影响,实验得出的Kafka消息并发量和数据吞吐量的性能变化曲线如图6所示。
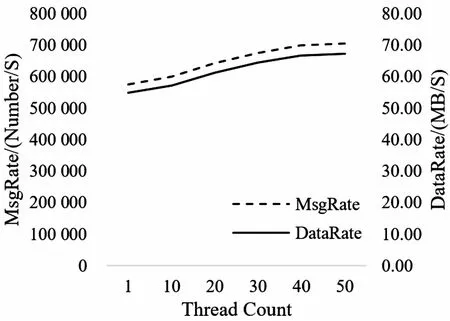
图6 Consumer端多Thread并发性能曲线
对图6进行分析:在Consumer端Thread数量增长的情况下,Kafka并发处理性能有增长,但趋势不明显。Thread数量为10、30和50性能提升分别为104.26%、117.48%和122.68%,出现一定边际效应。
3.3 气象数据集分区策略
根据实验结果得出的Kafka最优Partition和Thread数量,参照前述气象数据分区思路,在所构建的实验平台基础资源支撑条件下,设计五类气象数据进行分区处理最优策略,如图7所示。
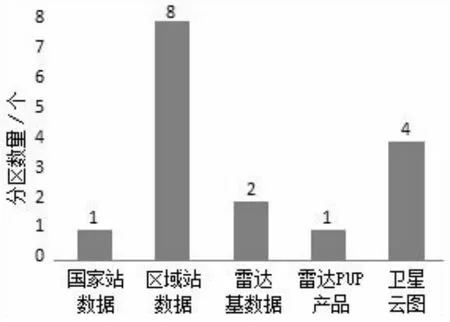
图7 气象数据分区策略
(1)为综合权重最高区域站数据设置8个Partition,采用32个Thread并发处理,可达到最高处理性能。
(2)参照综合权重对比,为卫星云图数据设置4个Partition,雷达基数据设置2个Partition,分别设置Thread数量为16和8。
(3)国家站数据和雷达PUP产品流转处理时,对基础资源的需求相对较小,分别设置为单Partition和单Thread。
4 应用成效
该文的研究成果已应用于湖南高分卫星多源数据获取管理平台。该平台基于Spark分布式处理架构,以Kafka为数据处理核心,采用HAProxy以及Nginx实现负载均衡和反向代理,支撑海量气象数据高负载处理。应用研究成果前,由于气象观测及高分遥感数据量大、传输频次高,数据传输处理过程出现消息阻塞现象,严重影响实时气象业务的连续性和可靠性。经数据分区和策略优化后,平台并发连接数峰值达到3 000次/分钟,数据吞吐量峰值达到550 MB/分钟,有效解决了消息堵塞现象。平台运行状况如图8所示。
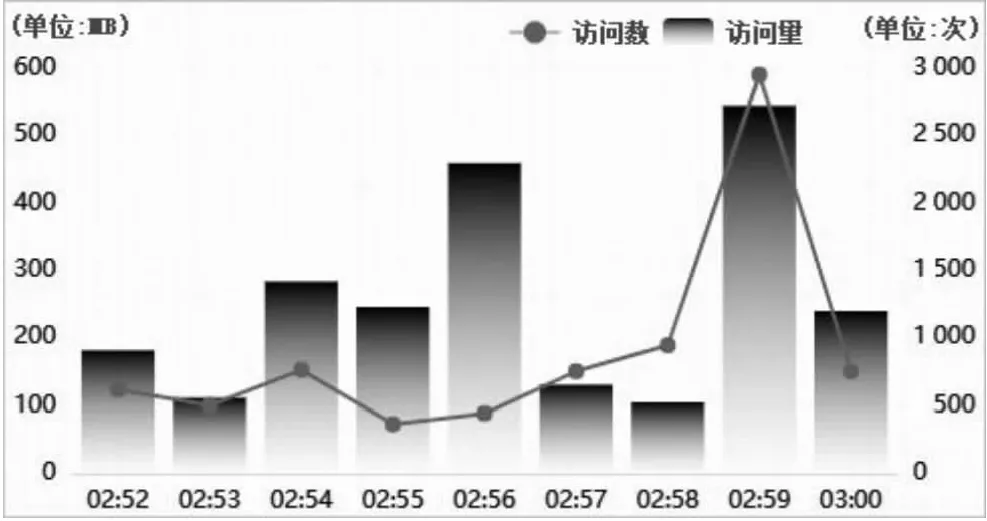
图8 平台并发性能
5 结束语
提出了采用熵权法综合计算气象数据多个关键特征量综合权重的算法及流程,得出的综合权重即为此类数据在气象数据处理系统中流转和处理时消耗系统资源所占的相对比重,并将综合权重作为气象数据分区处理的客观依据,避免主观因素造成分区不合理的情况在以Kafka为消息中间件的数据处理平台中,根据基础支撑资源状况,合理设计Partition和Thread数量可以显著提升并发处理性能。最优Partition数量为数据处理平台Broker总数量的2倍,最优Thread数量与单个Broker的CPU核心数一致。以所构建的包含4个Broker实验模型为例,在Kafka中Partition和Thread均最优的情况下,消息写入性能从一个Partition和一个Thread的0.69 MB/s提升至37.44 MB/s,提升至5 426.09%,消息读取性能则从15.65 MB/s提升至67.34 MB/s,提升至430.29%。
基于权重的气象数据分区算法和Kafka最优处理策略在各类数据处理系统中具有较强的应用价值,但该文的思路及方法基于数据处理系统在设计时所采取的最优策略,尚无法根据不同时间、不同季节对气象数据需求的重点不同而动态调整资源配置。后续将结合人工智能技术,通过机器自动学习历史数据处理状况的周期性变化,在一定范围内动态调整数据分区算法和Kafka配置策略,实现更高效的数据处理。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
心理学报(2022年4期)2022-04-12
环球时报(2022-03-29)2022-03-29
水泵技术(2021年3期)2021-08-14
内蒙古气象(2021年2期)2021-07-01
知识经济·中国直销(2018年7期)2018-07-27
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
中国惯性技术学报(2015年1期)2015-12-19
电测与仪表(2015年8期)2015-04-09
