
家庭服务机器人领域知识图谱构建与应用
2023-08-15 02:02吴培良王天成金鑫龙闫鹏宇张云川陈雯柏毛秉毅高国伟
计算机技术与发展 2023年8期
吴培良,王天成,金鑫龙,闫鹏宇,张云川,陈雯柏,毛秉毅,高国伟
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.河北省计算机虚拟技术与系统集成重点实验室,河北 秦皇岛 066004;3.上海工业自动化仪表研究院有限公司,上海 200233;4.北京信息科技大学 自动化学院,北京 100192)
0 引 言
随着人口老龄化的加剧和用工成本的上涨,家庭服务机器人的市场需求在不断扩大。在2021年的德国国际机器人联合会(International Federation of Robotics)发表的世界机器人-服务类机器人的报告中指出:全球市场在专业型服务机器人领域的营业额已经达到67亿美元,同比过去的2020年增长率可达到12%;专业性服务机器人中细分的家居服务机器人的营业额同比增长可达到16%,累计44亿美元[1]。由此可见,家庭服务机器人拥有迅猛的发展势头和巨大的市场前景。
然而,当前服务机器人的智能化程度还不能够满足室内场景下人机交互的需求,主要原因为当前的环境信息表示方法无法使机器人产生对家庭环境的深入认知。目前,常用的环境信息表示方法有谓词逻辑表示法[2]、产生式规则表示法[3]和语义网本体表示法[4]。这些环境信息表示方法努力增强了对环境信息的表达,但是对信息记录的同时,忽略了各信息之间的关系,使得机器人在使用已获取的信息时存在一定的困难,导致其无法智能化地执行服务任务。例如,机器人要执行“倒垃圾”任务,那么它不仅需要知道垃圾与垃圾桶的位置信息,还需要根据它们的功能来判断它们与任务之间的关联。
近年来,知识图谱的研究受到越来越多的关注。知识图谱的研究价值集中地体现在它是实现认知智能的基础。“理解”和“解释”是机器认知智能的两个核心能力,二者均与知识图谱有着密切关系[5]。“理解”视作建立从数据(包括文本、图片、语音、视频等数据)到知识图谱中的实体、概念、属性之间映射的过程。这一过程的本质就是将知识图谱中的知识与问题或者数据相关联。有了知识图谱,机器有望可以重现人类的这种理解与解释的过程。
当前,研究人员已经针对国防、能源、金融等领域展开知识图谱研究,但针对家庭服务机器人的领域知识图谱构建方面的研究十分稀少。为此,该文提出了一种家庭服务领域知识图谱的自动化构建方法。基于深度学习的神经网络框架实现场景分割,获取家庭场景中实体的语义信息;基于知识图谱的共享性与拓展性构建知识图谱,实现机器人的推理功能。通过知识图谱领域知识与家庭服务场景机器人的场景分割识别逻辑相结合,完成交叉学科跨领域知识运用,进一步提高家庭服务机器人在感知与认知部分的可靠性与适应性。
1 相关研究
1.1 知识图谱与环境信息表达
2012年,知识图谱(Knowledge Graph)的概念由Google公司正式提出,旨在实现更智能的搜索,并且于2013年后开始在学术和业界普及,在智能问答[6]、智能推荐[7]、反欺诈[8]等领域中发挥重要作用。由于其出色的环境信息表达能力,在其它领域知识图谱也得到了广泛应用。在自动驾驶领域,自动驾驶场景的实体及其关系表示通过知识图谱构建,生成的场景语义网络可用于实体预测的任务,从而提高驾驶过程中对于周边场景的理解[9];在图像遥感领域,利用遥感知识图谱推理与深度数据学习的融合,来提升遥感影像的解译性能[10];在社会交通领域,基于开源数据构建交通知识图谱和事理图谱,利用自然语言处理技术对网络文本进行分析,从而实现知识图谱对于网络交通事件说明的识别[11]。
由此可知,知识图谱拥有良好的环境信息表达能力,能够帮助智能体理解环境中实体之间的关系。对于家庭服务领域,知识图谱可以帮助机器人更好地理解用户、实体、服务任务之间的关系,使得其可以更加准确地完成有关服务任务的逻辑推理。
1.2 室内场景识别
一般地,家庭服务机器人通过摄像设备进行信息采集,通过对于场景图片的处理来获取场景的物品参数。如何对场景图片进行快速有效的信息抽取,是亟需解决的重要环节。目前常用的方法主要有基于物品识别实现场景信息汇总以及基于场景分割实现场景物品分模块识别。其中,基于物品识别实现场景信息汇总可用的方法常为级联分类器框架[12]、卷积神经网络[13]以及基于回归的YOLO(You Only Look Once)算法[14]。基于场景分割实现场景物品分模块识别则是采用神经网络模型进行深度学习。
在家庭场景中,实体的形态特征在画面中因摆设位置不同将会发生形体抽象变形,并因为物品间覆盖和放置大小差异,从而使得物品无法被有效地进行多角度特征抽取。通过YOLO物品检测算法进行物品识别的准确率最高只能达到42.5%。因此,对于家庭场景,信息理解的重心将放在基于场景分割实现场景物品的分模块识别。Zhou Liguang[15]和Miao Bo[16]等皆采用场景分割的思路来进行场景中实体的识别。
2 家庭服务场景知识图谱构建
由于各个家庭的环境具有较大差异,所以家庭服务机器人应该现场采集数据,构建家庭服务领域知识图谱,基于此,设计了如下自动构建流程:
(1)获取服务策略的文本信息,通过词频-逆向文件频率算法(Term Frequency-Inverse Document Frequency,TF-IDF)提取服务策略关键字,构成服务策略图谱。
(2)家庭服务机器人现场采集家庭场景图片,将其输入到训练好的场景分割模型(Scene Segmentation Model,SSM)中,得到场景中的实体信息。
(3)将实体信息输入到场景分类模型(Scene Classification Model,SCM)中,预测当前场景类别,如厨房、卧室、餐厅等。
(4)将SSM模型得到的物品信息和SCM模型得到的场景类别进行信息汇总,得到对应的文本文件。得到家庭实体知识图谱。
(5)将服务策略图谱与家庭实体图谱进行拼接,得到家庭服务知识图谱。
家庭服务场景系统框架如图1所示。
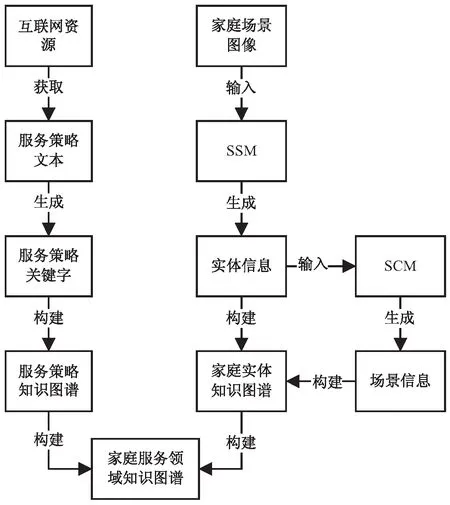
图1 系统框架
2.1 服务策略知识图谱构建
服务策略文本主要来源于WikiHow[17]网站,它是一个开放的互联网网站,包括多个与家庭服务任务相关的知识模块,例如兴趣与手艺、家居与园艺、饮食与休闲等,具体服务知识包括如何洗碗、如何做饭等。该网站的信息利用半结构化文本表示,易于提取,故采用该网站的文本数据作为服务策略文本。
之后,利用TF-IDF算法[18]对策略文本进行处理,生成服务策略关键字。首先,根据公式(1)计算词频(Term Frequency,TF)。
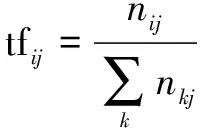
(1)
其中,nij表示该词出现的次数,分母部分表示文本dj中所有词汇的数量,tfij表示文本dj中第i个关键词出现的频率,这个值越大,代表这个词出现的频率越高。
之后,根据公式(2)计算逆向文件词频(Inverse Document Frequency,IDF)。
(2)
其中,|D|是文件总数,|{j:ti∈dj}|表示包含该词语的文件总数,包含该词语的文档越少,idfi值越大,表示该词语具有良好的类别区分能力。
最后,如公式(3)所示,将tfij与idfi相乘,即可得到该词条的权值Wij,数值越大,代表该词汇越关键。
Wij=tfij×idfi
(3)
得到服务步骤的关键字后,利用自言语言处理工具包[19](Natural Language Toolkit,NLTK)对原文本进行处理,根据词性标注判断该关键字是动作还是物品词条,将其输入到知识图谱中,构成服务策略知识图谱。
2.2 场景分割模型(SSM)
在构建家庭服务场景知识图谱时,首先需要利用SSM模型对场景内的实体进行分割,并将其识别出来。
2.2.1 ADE20K数据集
SSM模型采用ADE20K进行训练,ADE20K是一个密集注释的数据集,总共有25K张复杂的日常场景的图像,其中包含日常生活中常见的150种物体类别,平均每个图像有19.5个实例和10.5个对象类。数据集根据训练集和检验集分成两大部分,每部分中根据a-z的相同首字母进行场景分类。
2.2.2 场景编码器(Encoder):ResNet50
ResNet50为残差神经网络,50代表该残差神经网络层数。为了解决梯度消失与梯度爆炸问题,ResNet提出了两种映射:一种是恒等映射,另一种残差映射[20],将两种映射组合,最后的输出是y=F(x)+x。其中,恒等映射是指本身,也就是公式中的x,而残差映射指的是y-x,所以残差指的就是F(x)部分。残差网络的组合单元如图2所示。
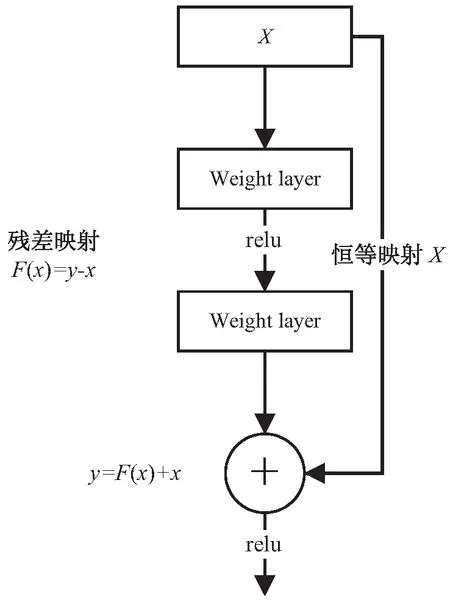
图2 残差网络组合单元(示例)
将输入数据记为x,则中间网络层对于数据的操作可以记为F(x),通过残差网络的构件输出结果为F(x)+x,即将残留下来的数据与原数据合并,再进行运算输出,故该模型称为残差神经网络。这时需要考虑对F(x)和x的数据格式进行分类讨论,如果F(x)的数据通道数与x相同则输出结果见式(4)。
y=F(x,{Wi})+x
(4)
其中,F(x,{Wi})指的是中间网络层对于数据使用权值ωi进行计算,x为原输入数据。y为最终的输出结果。另一种情况为F(x)的数据通道数与x不同,则需要将x原数据转换成相同的数据格式,结果见式(5)。
y=F(x,{Wi})+Wsx
(5)
其中,Ws为通过权值的计算将x为原输入数据转化为相同的数据通道数量。y为最终的输出结果。
在家庭场景分割的过程中,通过ResNet50将ADE20K数据集的图片转化成物品的区域预测概率序列,将图像编码成高维特征区块的物品种类分布,以此来实现家庭服务场景的编码过程。
2.2.3 场景解码器(Decoder):PPM
高维特征区块物品种类预测序列并不是最终的数据结果,需要对该序列进行反向编码,即解码的过程。将高维特征还原成对应的原图片区域,并根据该种类查询对应色卡进行上色,完成对于识别的物品种类在图中进行标记。为了实现这一解码过程,使用场景解码器:金字塔池化模型(Pyramid Pooling Module,PPM)。
采用1×1、2×2、3×3和6×6四种不同尺寸的卷积核,对ResNet50获取到的特征图进行卷积。得到多个尺寸的特征图,并对这些不同尺寸的特征图再次进行1×1的卷积操作来减少通道数。然后采用双线性插值进行上采样,以此获得金字塔模块前相同尺寸的特征图,并在通道上进行拼接,将不同层级的特征图拼接为最终的金字塔池化全局特征。从直觉上来看,这种多尺度的池化确实可以在不同的尺度下保留全局信息,比起普通的单一池化更能保留全局上下文信息。
2.3 场景分类模型(SCM)
家庭场景中实体分布具有一定的规律,如床大概率出现在卧室、沙发大概率出现在客厅、厨房中很可能存在厨具等。故而可以根据SSM模型识别出的实体来对当前所处的场景进行预测分类。
2.3.1 PLACE365数据集
PLACE365数据集有365个场景类别,用于各类场景识别的比赛和训练。该家庭服务场景系统所作用的场景为家庭常见环境,因此选取PLACE365-standard数据集中的浴室(bathroom)、卧室(bedroom)、衣帽间(closet)、餐厅(dining room)、书房(home office)、厨房(kitchen)和客厅(living room)共7个数据集进行分类测试。
通过训练好的SSM模型生成家庭功能区的标签和功能区中的前10种像素占比大于0.1%的物品(不足10种补空物品样本)样本数据集,用于后续SCM模型进行场景分类的训练。
2.3.2 场景数据预处理与标签加载
由SSM模型生成的数据格式可得,每个检测出来的物品都是通过字典的形式进行存储,字典中包含对应物品的中文名、英文名和功能关键词,该文只需要选取物品的英文名作为每条数据样本的属性即可。
模型的数据属性一般要求是数字格式,所以需要对物品列表文件进行反向字典生成,即通过物品的英文名将物品的标签还原,让每一条场景数据都是10个标签数字组成的数字序列(如果检测物品不足10个,则对应的物品标签用-1代替)。
在完成对7个场景类别图片的识别后,将文本文件用于基于梯度提升决策树(Gradient Boosted Decision Tree,GBDT)算法的SCM。其中,GBDT算法是通过梯度提升的方式不断地优化参数,直到达到局部最优解。梯度提升算法每一步优化的对象是不同的。第一步是以label值为目标来优化参数,第二步优化的目标就是第一步的残差,第三步优化的目标是第二步的残差。以此类推,不断地对权重进行调整,是一种带权的决策树形式。
2.4 模型测试
2.4.1 评价指标
SSM与SCM的性能通过响应速度、准确率(Accuracy)、F1-score和Cohen's Kappa等参数来进行判定。
其中,F1-score是基于准确率、精确率(Precision)、召回率(Recall)加权调和后得到的。以二分类问题为例,最终结果应当被分为正类或者负类。如果原标签标记为正类,并且分类结果为正类,则记为TP(True Positive)。同理,负类标签与分类结果一致就可以得到FN(False Negative)。TP和FN都是分类正确的结果。反之,正类被预测为负类、负类被预测为正类,分别记为TN(True Negative)和FP(False Positive),TN和FP是分类错误的结果。根据上述得到的四种分类情况,可以得出精确率、准确率、召回率、F1-score的计算方式,具体见式(6)~式(9)。
(6)
(7)
(8)
(9)
除了上述的性能参数外,再引入 Cohen's Kappa 进一步检验模型的分类精度与性能。当标签数据存在样本失衡的情况时,准确率就无法反映出模型的分类效果。因而需要引入一个基础准确率(Pe)来均衡这种样本数据失衡的情况。基础准确率计算公式见式(10)。
(10)
其中,k表示第k个类别,nk1和nk2的乘积表示为真实占比与预测占比的乘积。在得出基础准确率后,就可以得出 Cohen's Kappa的数值,数值越大代表分类效果越好,具体如式(11)所示。
(11)
2.4.2 SSM模型测试
通过场景编码器ResNet50进行场景解析物品的分类,然后场景解码器PPM充分利用好场景的上下文信息,将场景中的物品解析得更加准确与全面。到此为止,通过场景编码器和场景解码器完成场景分割识别物品的功能。训练模型最终像素准确率为80.13%,总分为61.14,响应速度为2.6 s。与其他训练模型的结果对比如表1所示[21]。
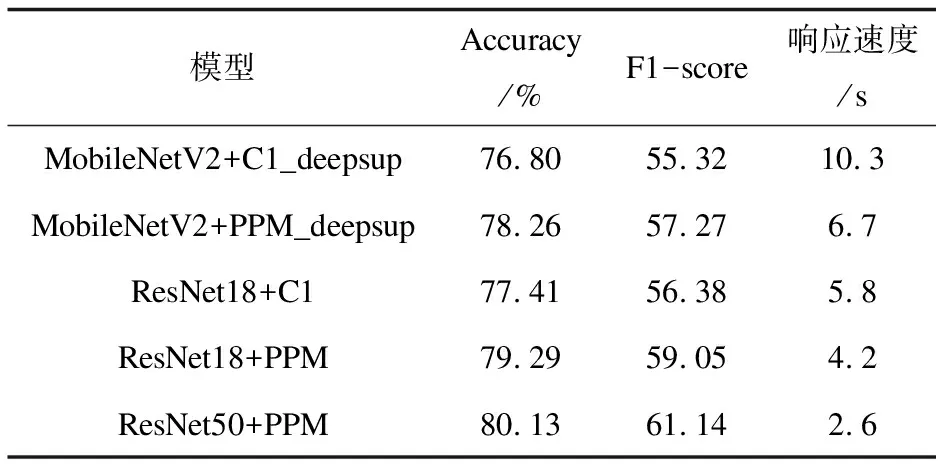
表1 SSM模型训练结果统计
通过测试结果可知,SSM模型性能良好,与其它场景分割模型相比,能够较为准确地获取场景中的信息,且图像处理速度快,能够满足家庭服务机器人连续采集并处理场景图像信息的需求。
2.4.3 SCM模型测试
选取PLACE365数据集中7种场景的部分数据集作为测试集,通过sklearn的机器学习库选取多种机器学习算法与GBDT算法进行数据的训练与预测比较,使用Accuracy和Cohen's Kappa系数来进行各模型的评估。从模型对比可得,GBDT算法能够在使用10个物品特征的情况下,取得较好的场景分类效果。在SSM的像素识别准确率为80.13%的情况下,将场景分类的准确率维持在79%。因此选择该模型作为分类模型使用。各模型训练后,对测试集进行测试的结果如表2所示[22]。
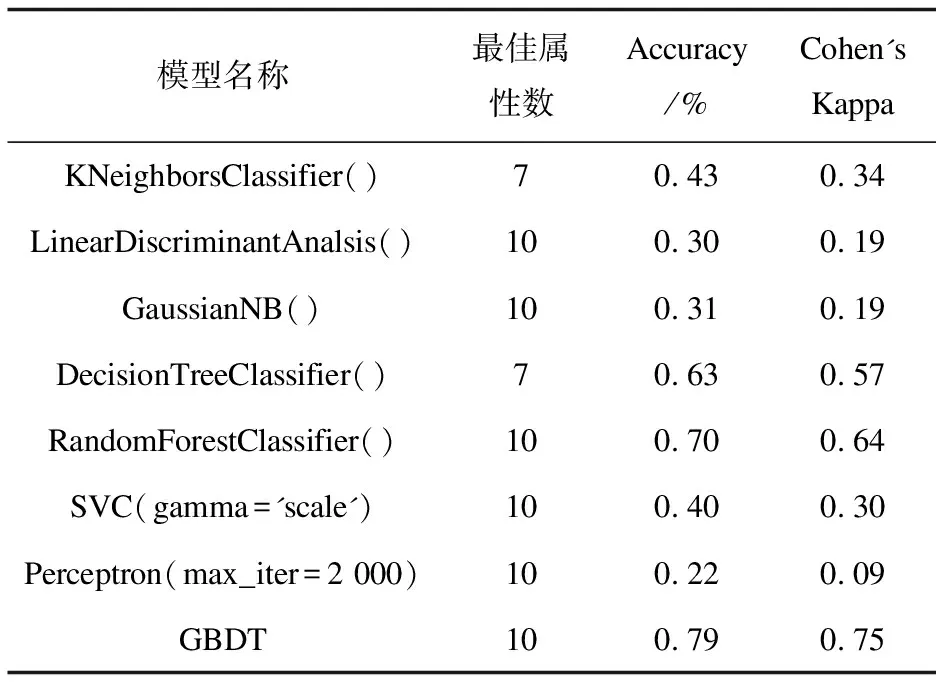
表2 SCM模型训练结果统计表
2.5 家庭服务领域知识图谱结构设计
通过对家庭服务的场景分析,家庭环境可以划分成若干个房间,每个房间中拥有若干个物品,每个物品拥有若干关联词,关联词可以为功能词汇,也可以是人的需求词汇。基于此,家庭服务机器人便可以通过查询知识图谱来找到服务所需的实体信息。
之后,将构建好的策略图谱与实体图谱合并,生成家庭服务知识图谱,结合三元组的知识,创建家庭服务场景的本体结构。功能区(Room)和家庭(Home)拥有位于(Located in)的关系;工具物品(Object)和功能区(Room)拥有从属(Belong to)的关系;服务任务(Service)和任务步骤(Service Step)拥有方法(Method)的关系;任务步骤(Service Step)和工具物品(Object)拥有动作(Affordance)的关系;功能需求关联词(Function)和工具物品(Object)拥有属于(Owned to)的关系。所构建的知识图谱结构的三元组表示形式如式(12)至式(16)所示。
(12)
(13)
(14)
(15)
(16)
除了本体结构外,仍需要考虑构建成实体后,每个节点需要的属性值。一个知识图谱数据库中,可能存在多个家庭环境信息,所以Home节点需要拥有名称(name)和该家庭的唯一信息标识符(id)。Room与object同理也需要拥有name和id两个属性。一种服务任务可能有多种策略方法,所以任务与服务步骤之间用methodi(i=1,2…)来区别不用策略方法。
以wash clothes服务任务为例,家庭服务知识图谱片段如图3所示(工具物品的功能节点已隐去)。
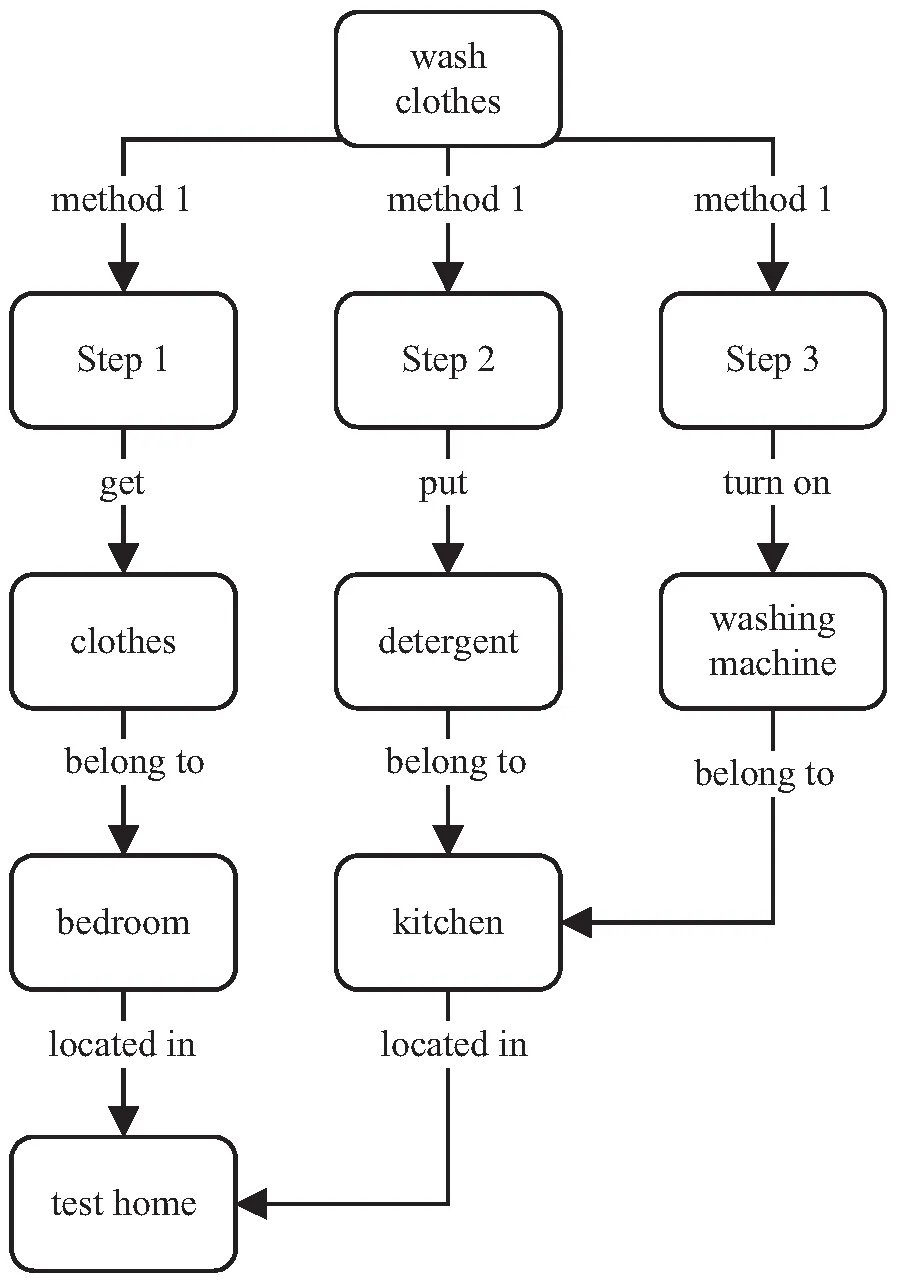
图3 家庭服务知识图谱片段
3 家庭服务领域知识图谱应用
3.1 实验与应用
为了模拟验证所提方法的有效性,从PLACES365数据集中选取7张场景图片当作机器人在家庭中采集的图像信息,以此来模拟家庭场景,包含的7个常见家庭场景有餐厅、厨房、客厅、书房、卧室、衣帽间和浴室。
通过训练好的SSM模型与SCM模型,获取实验场景图中的实体、场景与功能的语义信息,构建家庭服务领域知识图谱,所构建的知识图谱共包含337个实体,783条关系。机器人通过搜索知识图谱,可以获取家庭环境中的实体与场景信息,与图谱的交互结果如图4所示。通过结果可知,所构建的知识图谱能够帮助机器人对家庭环境产生深入认知。

图4 图谱搜索结果
3.2 反馈与更新
由于家庭环境中的实体是复杂多变的,且构建图谱时可能会匹配错误,所以需要对家庭服务领域知识图谱进行实时更新。为了达成这个目的,加入了反馈响应实体关系更新功能,该功能主要通过与用户间的交互完成家庭知识图谱数据的更新。即在进行查询后,用户可以对上一步交互结果进行反馈,当接收到用户关于“错”之类的关键词后,通过用户的选择与上一步查询结果中反馈的领域词信息对图谱进行修改,例如增加或删除实体的功能信息,以及修改实体的位置信息等,以此来达到更新知识图谱的效果。反馈更新效果图如图5所示。

图5 反馈更新效果
3.3 服务策略生成
当用户对机器人发出任务指令时,机器人可以通过匹配功能需求节点以及任务节点,遍历家庭服务领域知识图谱,选择适合当前环境的服务策略,根据服务任务的步骤、动作、实体以及实体的位置信息来制定相应的策略。生成的服务策略示例如表3所示。
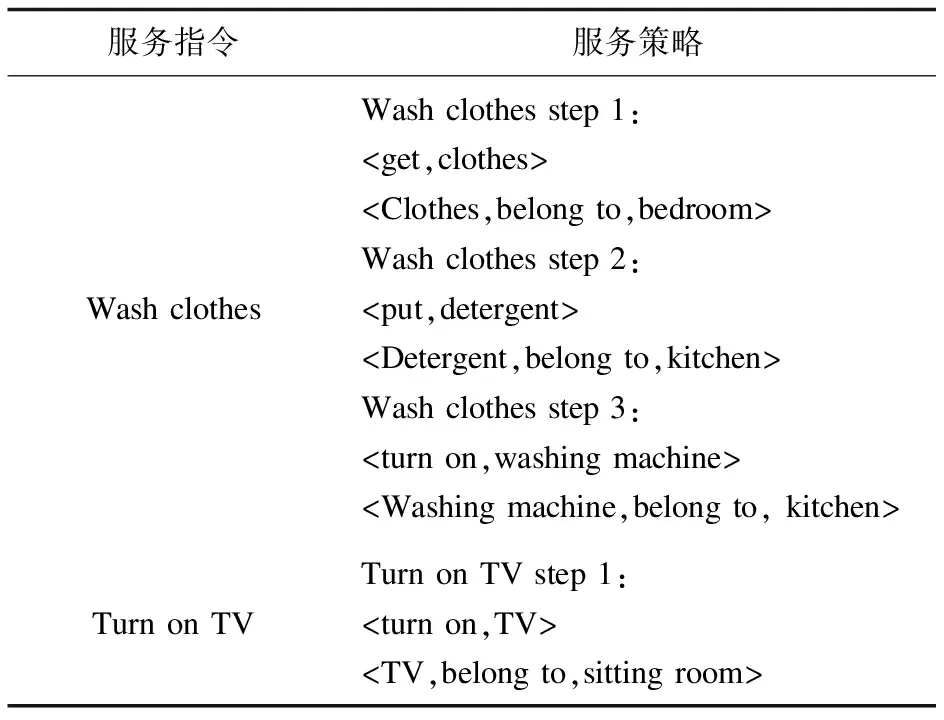
表3 服务策略示例
现有的家庭服务机器人策略生成方法主要有两种:一种为基于语义解析器的方法,从用户指令中获取动作序列,这种方法不适合多物品操作的复杂任务;另一种为基于强化学习的方法,设置基于先验知识的奖励,让机器人探索生成策略,这种方法没有考虑到当前的环境信息,所给出的服务策略可能包含环境中不存在的物品,导致任务失败。由于所构建的知识图谱能够反映出服务任务与实体之间的关系,所以用户只需下达任务指令,机器人便可以根据家庭环境生成服务策略。与现有的几种策略生成方法对比如表4所示。
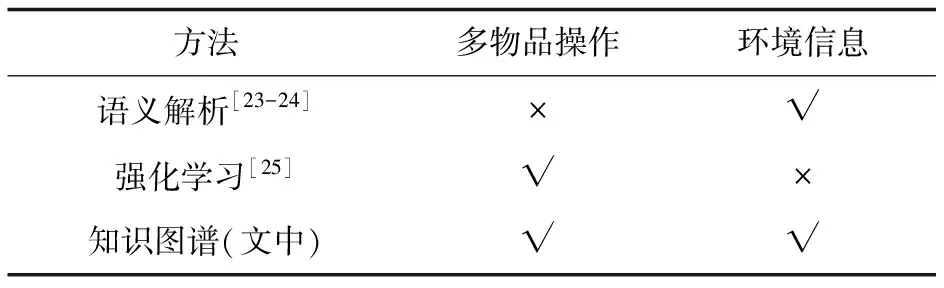
表4 服务策略生成方法对比
4 结束语
为了增强家庭服务机器人的信息获取能力与知识推理能力,设计了一种自动构建家庭服务领域知识图谱的方法流程。所构建的SSM模型及SCM模型能够快速准确地识别出家庭环境中的场景及实体,生成相应的文本文档,将其存储neo4j图数据库中,完成家庭服务领域知识图谱的构建。通过对知识图谱进行查询,可以得到服务所需的语义信息,进而生成服务策略。除此之外,还可以通过与用户的问答反馈来实现知识图谱的自更新。
所提出的方法的创新点如下:
(1)将知识图谱应用到家庭服务领域,使得家庭服务机器人拥有了一定的推理能力,可以更加准确地获取服务所需的语义信息。
(2)所提出的家庭服务领域知识图谱为完全自动化构建,只需要机器人在工作区内采集图像便可以自动生成知识图谱,不需要人工参与构建。
除此之外,在家庭服务领域知识图谱研究的过程中,仍存在一些不足之处。未来将通过以下几个方面进行改进:
(1)数据集扩充与模型优化。当前的ADE20K数据集中标注的物品为150种,且对于家庭环境而言,诸多细小物品并不存在相应的数据。因此,使用该数据训练出的模型识别物品类别数量与此相同,对部分家庭物品无法实现分割与分类。在未来的工作中,可以通过使用场景分割的标注工具,采用相同的数据格式对于ADE20K数据集的训练与检验样本进行扩充,以便完成SSM与SCM的优化。
(2)改进策略生成算法。目前服务策略是基于模板匹配算法生成,模板较为单一,无法处理多元化的服务指令。下一步可以利用所构建的知识图谱辅助强化学习来生成服务策略,使机器人能够更好地利用图谱中的信息,为用户提供更加宜人化的服务。
(3)改用更加真实的实验场景,当前采用场景图像来模拟真实场景,与真实家庭环境相差甚远。未来可以采用AI2-THOR等虚拟环境来模拟机器人的工作环境,使其具有更强的实用性。
综上所述,通过系统的研究实现,完成家庭服务领域知识图谱的构建、应用与创新。通过当前系统存在的不足提出未来的发展规划,力求在原基础上不断地更新与完善,来推进家庭服务机器人对于场景信息的感知与处理,从而推动服务型机器人智能化的发展。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
疯狂英语·初中天地(2021年11期)2021-02-16
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
少年漫画(艺术创想)(2019年2期)2019-06-06
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
