
基于领域知识内嵌的深度学习网络流量预测研究
2023-08-11 14:54:30张必浪张倩杨予光耿书鹏北京航空航天大学北京006中讯邮电咨询设计院有限公司北京00048
邮电设计技术 2023年7期
张必浪,张倩,杨予光,耿书鹏(.北京航空航天大学,北京 006;.中讯邮电咨询设计院有限公司,北京 00048)
0 前言
流量预测是计算机网络管理和优化中的重要任务,其目标是分析和预测网络中的数据流量,为网络资源的规划、调度和管理提供依据。近年来,随着互联网的快速发展和智能化应用的不断增加,快速增长的用户需求和网络规模对当前的网络基础架构带来了许多挑战。流量预测是指根据过去的流量观测数据,对未来一段时间内的网络流量进行估计和预测。传统的流量预测方法通常依赖于统计模型[1]和时间序列分析算法[2−3]。随着以深度学习为代表的人工智能技术逐渐成熟,基于深度学习的流量预测算法逐渐成为研究的热点[4−5]。然而,当前数据驱动的深度学习范式在复杂动态的网络流量环境中存在模型功耗大、存储成本高、算法难优化等问题。考虑到人的快速学习能力是建立在对任务完备的背景知识之上,且有科学的公理系统支撑。因此,本文基于深度学习方法提出了一种基于领域知识内嵌的全流程框架,以实现快速精准的流量预测,从而实现更符合现实场景的网络资源分配,为智能化网络提供决策能力。
1 流量预测研究背景
随着互联网技术的普及,网络流量快速增长。根据中国互联网信息中心发布的第47次《中国互联网络发展状况统计报告》,我国网络用户数不断增加,使用移动设备的网民比例高达99.7%,移动互联网接入的流量也呈现快速增长趋势[6]。然而网络运营商如果长时间、大规模地维持如网络基站与服务器等流量承载设施,将产生高昂的运营支出。考虑到大部分网络在小时或日尺度上存在的繁忙间歇性与规律性,可以对周级的短期流量进行预测,帮助移动网络运营商及时调整射频资源的分配。因此,流量预测已成为移动网络运营商降低运营成本,提升用户体验的重要任务。
2 基于领域知识内嵌的流量预测框架
2.1 总体研究方案
图1所示为本文所提出的基于领域知识内嵌的流量预测总体框架。考虑到流量数据存在的偶发性强、时域分布不确定性高的问题,本研究提出了基于JS 散度的数据分布检测算法对原始数据中的时域和频域异常数据进行清洗,以避免异常数据干扰模型学习。在模型设计的过程中,考虑到流量数据本身存在的自相似性、长时相关性、周期性等特点,本文设计了动态时域生成流量预测模型(GDTN)。GDTN 能够在使用卷积生成网络对流量数据进行去噪−复原的同时,自动分配同期多时域流量特征的重要性,以捕捉输入流量数据中存在的规律变化的模式,提升模型的学习效率与预测性能。整体而言,本文提出的基于领域知识内嵌的流量预测框架通过综合应用数据清洗、数据驱动的特征提取和领域个性化的模型设计等技术,能够实现准确预测流量数据的目标。
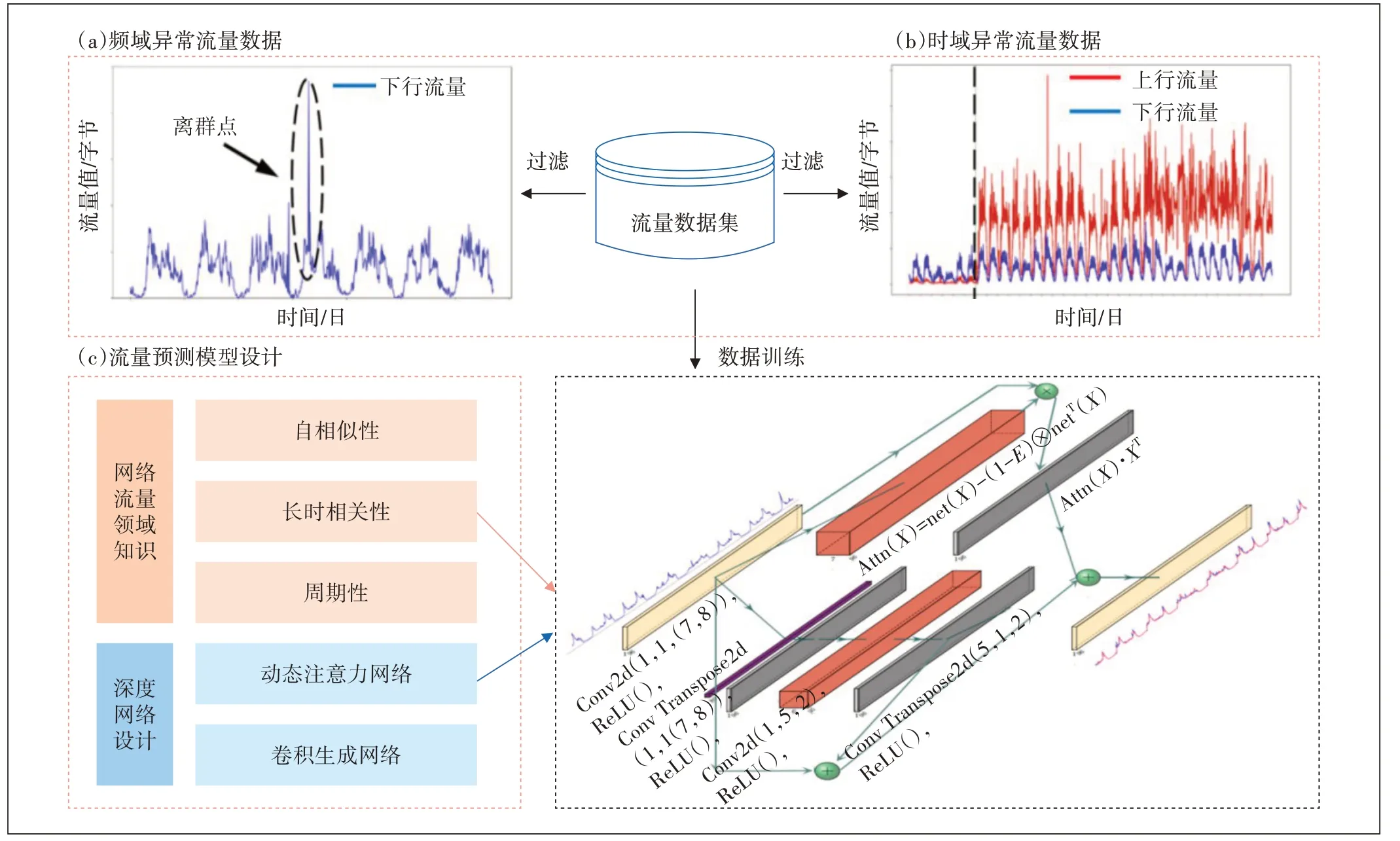
图1 基于领域知识内嵌的流量预测总体框架
2.2 基于JS散度数据分布异常检测算法
JS 散度数据分布异常检测算法的核心思想是以JS 散度衡量序列数据之间的距离,衡量2 个同宽度的相邻或相隔一定天数的滑动窗口内的序列数据之间的距离,并应用孤立森林异常点检测算法检测数据分布发生明显改变的间断点。图2所示为本文所提出的分布异常检测算法,主要包括序列相似性度量、孤立森林异常检测2 个部分,当孤立森林检测算法判定异常且时域分布差异大于设定阈值2 个条件同时满足时,判定为该数据存在异常。接下来,本文对该算法进行详细介绍。
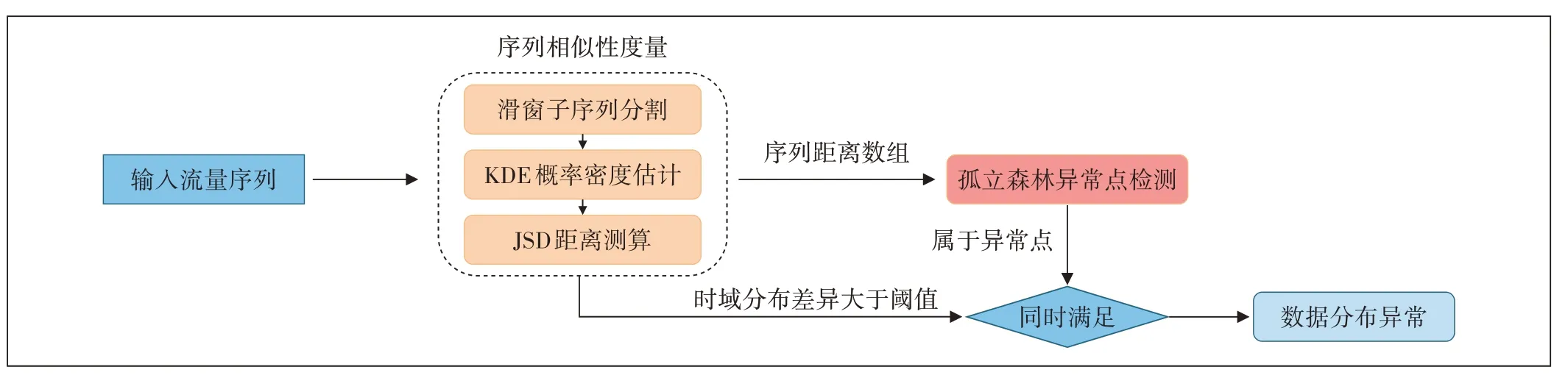
图2 基于JS散度的数据分布异常检测算法
2.2.1 基于JS散度度量序列相似性度量
一般的序列相似性度量方法往往基于欧式距离、形状距离[7]或模式距离[8]将时间序列视为高维向量进行处理;然而,由于大量的偶发流量事件,使得流量数据异常频发且异常流量往往高出正常流量几个数量级,因此基于距离的相似度衡量算法并不适用于流量数据。为解决这一问题,本文提出基于JS 散度的序列相似性度量算法,将变动的时间序列视为某个模式在数据分布上的改变,将时间序列处理为高维概率密度函数,以对流量数据的整体概率密度分布进行度量,排除异常流量数据的干扰。下面对具体的运算过程与理论进行介绍。
为了方便描述,定义散度为:
在应用散度度量序列相似性时,需要应用KDE 核密度估计方法对序列的概率密度进行估计,以得到序列的概率密度函数,以度量时间序列之间的相似性。
2.2.2 孤立森林异常检测算法
孤立森林是一种适用于连续数据的无监督异常检测方法,并且能够根据给定数据的不同动态地确定异常分数,是一种全自动的异常检测算法[10]。孤立森林的核心思想是通过递归地随机分割数据集来查找哪些点容易被孤立;异常点则被定义为容易被孤立的离群点,也即分布稀疏且离密度高的群体较远的点。在这种随机分割的策略下,异常点通常具有较短的路径。
为便于描述,定义异常分数为:
给定一个包含n个样本的数据集,树的平均路径长度为:
其中H(i)为调和数,该值可以被估计为ln(i)+0.577 215 664 9。则样本x的异常得分定义为:
其中,h(x)为样本x的标准化路径长度,E[h(x)]为样本x在一批孤立树中的路径长度的期望。
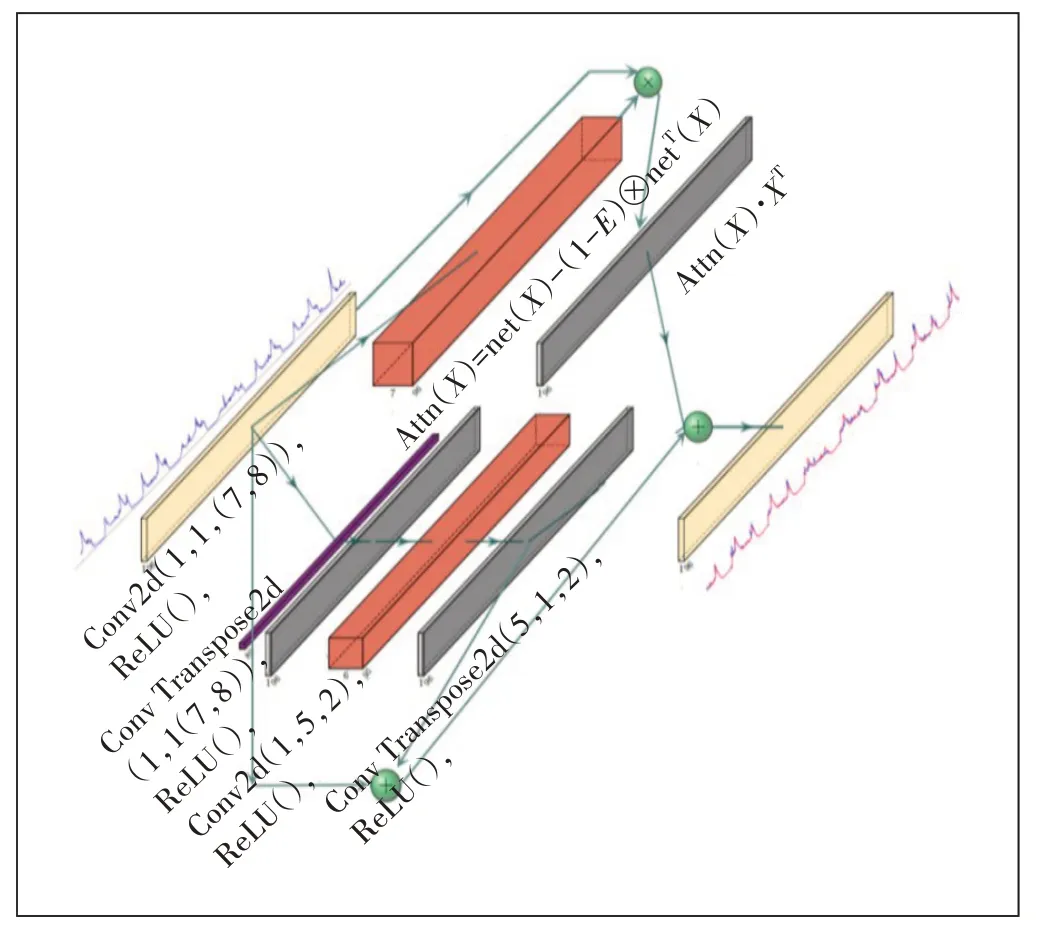
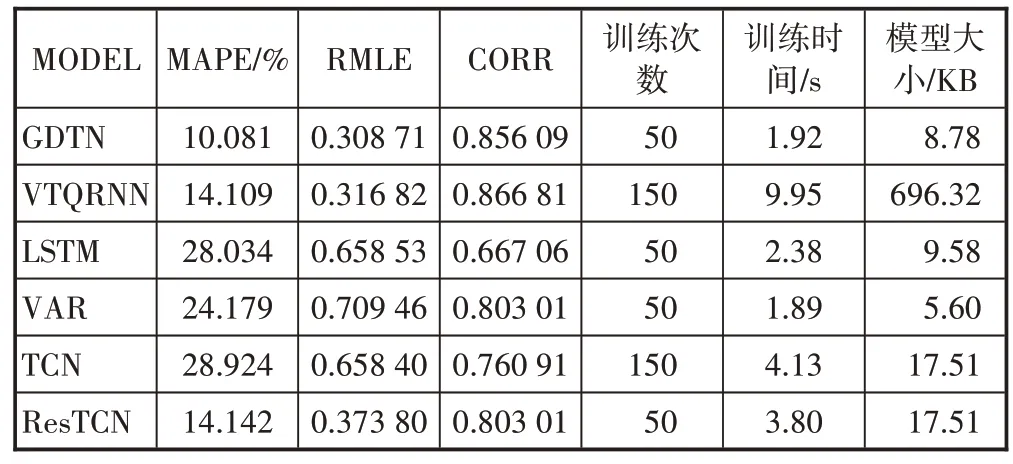
孤立森林异常检测算法的运算过程为:给定n个样本数据X={x1,…,xn},特征的维度为d。为了构建一棵孤立树,对于给定节点T,随机选择一个特征q及其分割值p对样本进行分割,将q a)树达到了限制的高度。 b)节点上只有1个样本。 c)节点上的样本所有特征都相同。 在得到孤立树后,可以计算不同样本的异常分数,当c(x) →0时,样本点x的异常分数s(x) →1。一般将异常分数大于0.9的样本点视为异常点。 2.2.3 基于JS散度的数据异常分布检测方案 检测方案的核心思想是通过比较滑动窗口内数据的概率密度函数来计算距离,并利用JS 散度来度量数据分布的差异性。接着通过孤立森林异常点检测算法,可以识别出距离数组中的异常点,从而进行数据异常分布的检测。设定的阈值可以根据具体需求进行调整,用于筛选出具有较大差异性的异常点。 具体流程如下。 a)读取一段时间序列的数据。 b)设置2 个相邻的滑动窗口window1、window2 大小为s。若序列呈现明显的周期性,设其周期为T个时间点,设置第3 个滑动窗口window3,大小为s,与win⁃dow2相隔T−1个时间点。 c)沿着时间序列以s为步长不断地滑动window1、window2 和window3,并保持它们之间的时间间隔不变。 d)将window1、window2 和window3 内的序列数据分别进行统计分析,并利用KDE 核密度估计方法生成window1、window2 和window3 内序列数据的概率密度函数。 e)以JS散度方式定义序列数据之间的距离。 f)不断重复步骤c)~e),直至序列数据末端,得到序列数据的距离数组。 g)利用孤立森林异常点检测算法检测距离数组中存在的异常点,得到预备异常点集合。 h)设置阈值,以距离数组中大于阈值的点构成异常点集合。 图3所示为本文所设计的动态时域生成流量预测模型(GDTN),该模型由并行的自适应注意力元网络与卷积生成网络2个部分构成。下面对该模型的设计动机与重要技术点进行介绍。 图3 GDTN网络模型示意 2.3.1 自适应注意力元网络 自适应注意力元网络通过深度网络学习不同天之间的重要分数,并根据重要分数构造注意力矩阵,使注意力机制在网络流量任务上具备良好的可解释性。自适应注意力元网络主要由重要分数学习网络与注意力矩阵推理网络构成。其中,重要分数学习网络net(X)可以由任意网络替代。 a)重要分数学习元网络。 (a)定义任意函数net(·) 满足条件:net:Rn,m→{x|0 ≤x≤1,x∈Rn,m}。 (b)计算重要程度IS(X)=net(X)。 (c)对重要分数score进行有界压缩: 其中,σ 为任意在实数域上具有上下界的函数,此处取常见的S型激活函数Sigmoid(x)= b)注意力矩阵推理元网络。注意力矩阵推理元网络能够根据重要分数学习元网络得到的一个周期内每天的重要性,推理计算得到注意力矩阵。其计算流程如下: (a)对net(X)得到的重要性分数IS′(X)广播到指定维数: (b)根据net(X)′求解注意力矩阵Attn(X): (c)根据Attn(X)对不同天之间的流量数据进行加权求和,得到预测结果: 其中X′=unsqueeze(X,dim=3)。 2.3.2 卷积时域生成网络具体设计方案 卷积生成网络能够将在图像生成方面的优秀表现迁移到流量预测任务之中,使得流量数据沿着编码器网络向生成器网络流动的过程中,流量数据噪点被逐渐删去,并引入符合数据输入输出分布的流量特征。卷积时域生成网络由2次压缩−生成过程组成,其中压缩过程使用卷积神经网络,生成过程使用反卷积神经网络。具体来说,给定输入流量序列X与第k次压缩−生成过程的输出Xk,卷积时域生成网络模块的计算过程如下: 2.3.3 模型集成 GDTN 流量预测方法由并行的卷积生成网络与自适应注意力元网络2个阶段组成。通过将两者进行加权求和实现网络集成。 其中,w1、w2分别表示不同组块的融合权值。 为验证所提出算法的可行性,本研究收集了来自智能城域网接入路由器(MAR)上联到汇聚路由器(MER)的1 000 个网络端口的流量数据。本研究将该数据集中时间长度大于90 天的端口沿着时间维度进行训练、验证、测试集划分,其中将倒数第1 个月的数据用作验证集,倒数第2个月的数据用作测试集,剩余的数据用于训练。不足90 天的数据仅用于测试和验证,不参与训练。为了综合评估GDTN 流量预测模型的性能表现,本研究选取了多种同类型时间需要预测模型在智能城域网数据集上进行对比实验。这些对比模型分别是VTQRNN、LSTM、VAR、TCN和ResTCN。 如表1 所示,与传统模型和近期的同类时序预测模型相比,GDTN 模型实现了10.081%的相对误差控制,优于目前模型的14.109%,同时GDTN 作为一种轻量模型设计,仅占用8.78 KB 的硬盘资源,有效减少了存储成本,而且,GDTN 平均在1.92 s 内完成了单端口模型训练,减少约2 s 的单端口训练成本。总的来说,GDTN 模型具有精准的相对误差与绝对误差控制、经济的存储资源占用以及高回报时间效用等特点。 表1 智能城域网数据集对比实验 流量预测模型对未来移动通信网络的扩容建设与资源优化分配具有重要意义。本文通过重采样与基于滑窗的JS 散度数据分布改变检测算法对原始数据进行清洗,有效促进模型对正常数据分布的学习,并基于多时域流量数据进行方法上的创新,引入时间卷积的模式设计GDTN 流量预测模型,在长端口数据集上进行了预测并取得较好的性能,可以对未来的网络规划设计、基站建设、容量优化等工作提供参考。2.3 动态生成时域网络
3 实验
3.1 实验设置
3.2 智能城域网端口实验
4 结束语
猜你喜欢
数学年刊A辑(中文版)(2022年1期)2022-08-20 08:50:04
玩具世界(2022年2期)2022-06-15 07:35:36
房地产导刊(2021年8期)2021-10-13 07:35:16
出版人(2020年4期)2020-11-14 08:34:26
数学物理学报(2019年6期)2020-01-13 06:08:08
测控技术(2018年11期)2018-12-07 05:49:02
数学物理学报(2018年3期)2018-07-17 06:15:30
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:12
系统工程与电子技术(2016年7期)2016-08-21 13:59:14
西北工业大学学报(2015年4期)2016-01-19 03:31:55
