
ChatGPT背后的人工智能大模型的技术影响及应用展望
2023-08-10 00:44李振华倪丹成徐润编辑韩英彤
中国外汇 2023年6期
文/李振华 倪丹成 徐润 编辑/韩英彤
从2022年下半年人工智能绘画热潮,到人工智能对话机器人程序ChatGPT在全球走红,ChatGPT上线仅2个月全球活跃用户数量达1亿,超越TikTok成为史上用户增长最快的消费者应用,再到3月14日OpenAI发布下一代里程碑大模型GPT-4,生成式人工智能领域持续爆出令人惊喜的技术突破和产品体验,并催生多家独角兽公司。生成式人工智能领域的爆发主要归功于人工智能大模型技术的巨大突破,标志着人工智能技术从专用人工智能转向通用人工智能的拐点,有望大幅提升人工智能的适用场景和研发效率,并打开大规模商业化的想象空间。目前以微软、谷歌、Meta、百度、腾讯、阿里巴巴、字节跳动等为代表的头部科技企业纷纷摩拳擦掌,积极投身于人工智能大模型研发热潮之中。
人工智能大模型技术演进趋势
人工智能大模型的定义和优势
人工智能大模型即基础模型(Foundation Model)(《On the Opportunities and Risk of Foundation Models》,2021.08,李飞飞等100位学者联合发表),国际上称为预训练模型,指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。
相较于小模型(针对特定场景需求、使用人工标注数据训练出来的模型),大模型主要有以下三点优势:
涌现能力。通过简单的规则和相互作用,大模型能够有效集成自然语言处理等多项人工智能核心技术,并涌现出强大的智能表现,将人工智能的能力从感知提升至理解、推理,甚至近似人类“无中生有”的原创能力。
适用场景广泛。人工智能大模型通过在海量、多类型的场景数据中学习,能够总结不同场景、不同业务下的通用能力,摆脱了小模型场景碎片化、难以复用的局限性,为大规模落地人工智能应用提供可能。
研发效率提高。传统小模型研发普遍为手工作坊式,高度依赖人工标注数据和人工调优调参,研发成本高、周期长、效率低。大模型则将研发模式升级为大规模工厂式,采用自监督学习方法,减少对人工标注数据的依赖,显著降低人力成本、提升研发效率。
人工智能大模型的技术演进趋势
阶段一,训练数据演进:从追求规模到重视质量
追求规模。2018年以来,以BERT、GPT-3等为代表的人工智能大模型的成功使人们认识到通过提升参数规模、训练数据量有助于显著提升人工智能的智能水平,引发了大模型研发的军备竞赛,大模型参数呈现数量级增长,充分享受算法进步下的数据规模红利。
人工智能大模型的发展也经历预训练模型、大规模预训练模型、超大规模预训练模型三个阶段,参数量实现从亿级到百万亿级突破(见图1)。

图1 人工智能大模型参数量从亿级到百万亿级
重视质量。伴随大模型参数的持续扩大,训练数据的质量对模型表现的重要性愈发凸显。OpenAI对其研发的InstructGPT模型进行实验发现:随着参数量增加,模型性能均得到不同程度的提高;利用人工标注数据进行有监督的微调训练后的小参数模型,比100倍参数规模无监督的GPT模型效果更好。未来,提升大模型的训练数据质量或许比提升数据规模更为重要,人工标注数据仍有其存在的价值和意义,相关产业链的发展也值得重视(见图2)。

图2 InstructGPT采用不同训练方法的效果对比图
阶段二,模态支持演进:从单一模态到多模态
从支持的模态来看,人工智能大模型先后经历了单语言预训练模型、多语言预训练模型、多模态预训练模型三个阶段,模型能力持续升级(见图3)。

图3 从支持模态来看人工智能大模型的发展历程
多模态预训练模型代表有2022年大火的开源模型Stable Diffusion,掀起一波人工智能绘画热潮,已有大量产品级应用;以及谷歌、Meta推出的文字生成视频、文字生成音乐等预训练模型,但仍在早期研发阶段,技术尚未成熟。
ChatGPT所基于的InstructGPT模型仍属于自然语言处理(NLP)领域的单模态模型,擅长理解和生成文本,但不支持从文本生成图片、音频、视频等功能。OpenAI最新发布的大模型里程碑之作GPT-4并没有一味追求更大规模参数,而是转向多模态,支持输入图像或文本后生成文本。
阶段三,架构设计演进:从稠密结构到稀疏结构
人工智能大模型架构设计指模型的计算架构,分为稠密结构和稀疏结构,二者区别为:在训练中,稠密结构需激活全部神经元参与运算,而稀疏结构仅需部分神经元参与运算。
稠密结构导致高昂的大模型训练成本。以GPT-3为代表的早期的人工智能大模型均为稠密结构,在计算时需激活整个神经网络,带来极大的算力开销和内存开销。根据国盛证券的测算,GPT-3一次训练成本高达140万美元。
稀疏结构能够显著降低大模型训练成本。稀疏结构是一种更像人脑的神经网络结构,在执行具体任务的过程中只有部分特定的神经元会被激活,显著降低模型算力消耗。目前稀疏结构已经应用至人工智能前沿研究。2022年6月,谷歌发布了第一个基于稀疏结构的多模态模型LIMoE,证明了稀疏结构在降低模型算力消耗的同时,还能在多项任务中取得不亚于稠密结构的效果。
中美人工智能大模型技术现状对比及原因探析
国内在人工智能大模型研究上具备良好的基础
从2018年至今推出大模型数量来看,美国头部科技企业如谷歌、Meta、OpenAI、微软等在人工智能大模型领域积累深厚,但我国研究机构在全球前十大排名中也占据四个席位,包括智源人工智能研究院、清华大学、百度、阿里巴巴(见图4)。

图4 中美人工智能大模型十大机构(2018至2023年总模型数)
我国与国外最领先的技术相比仍有2—3年差距
从大模型的参数量来看,美国人工智能研究机构总是率先取得突破,比如谷歌201 7年提出Transformer模型奠定了大模型的底层模型基础,OpenAI的GPT系列持续引领潮流;中国人工智能大模型虽然具备追赶的能力,但追赶的过程需要花费1—2年时间,此后在模型技能上仍需时间打磨,完全拉齐效果大概需要2—3年时间(见图5)。例如,OpenAI于2019年1月推出拥有15亿参数量的GPT-2大模型,而国内直至2021年1月由智源人工智能研究院研发出26亿参数量的大模型——悟道文源1.0。
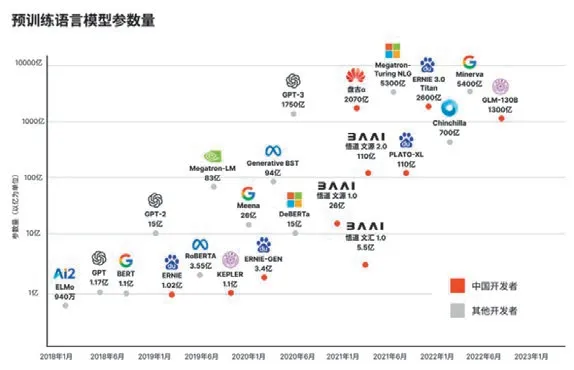
图5 中美代表性大模型推出时间及参数量对比
中美大模型技术差距的原因探析
人工智能大模型研发已成为全球新一轮技术竞争的核心领域之一,但以下多种因素制约了我国大模型技术的进一步发展,导致与美国大模型技术存在较大差距。
过度依赖开源模型进行复制和模仿。人工智能大模型研发的关键因素之一是算法,而算法的进步又依赖于持之以恒的前沿研究投入。在当下国内企业快节奏的竞争和盈利压力下,企业难以做到不计短期回报的投入。因而,在这些高风险的创新技术领域,国内企业更倾向于采取复制和追随策略,国内大模型大多基于国外公开论文和开源模型的基础上进行模仿和复制,故而总是“慢人一步”。
产业链仍有短板,人工智能芯片自研能力不足制约算力发展。伴随大模型参数量的指数级扩张,对于算力的要求也呈爆炸式增长,而算力增长主要依靠高端人工智能芯片的储备和芯片技术的持续进步。但在芯片方面,美国占据绝对领先地位,我国起步晚,对美国进口依赖程度高,存在“卡脖子”风险。近年来,国内大厂如阿里巴巴、华为、百度、腾讯等也正加快投入积极研发本土人工智能芯片。
制度保障尚不完善,数据流通和管理机制仍有不足。在大模型训练所需要的数据方面,中文数据虽然在规模上有优势,但质量普遍不高,一方面是国内数据积累问题,国内的数据存在严重的“信息孤岛”问题,高质量的数据信息割裂并沉淀在各个机构和企业内部;另一方面是由于数据管理机制不够成熟,也影响了国内数据价值的释放。
人工智能大模型应用场景和商业化前景展望
人工智能大模型有望赋能乃至颠覆各行各业
赋能制造业。首先,人工智能大模型能够大幅提高制造业的从研发、销售到售后各个环节的工作效率。比如研发环节可利用人工智能生成图像或生成3D模型技术赋能产品设计、工艺设计、工厂设计等流程。在销售和售后环节,可利用生成式人工智能技术打造更懂用户需求、更个性化的智能客服及数字人带货主播,大幅提高销售和售后服务能力及效率。其次,人工智能大模型结合机器人流程自动化(RPA)有望解决人工智能无法直接指挥工厂机器设备的痛点。RPA作为“四肢”连接作为“大脑”的人工智能大模型和作为“工具”的机器设备,降低流程衔接难度,实现工厂生产全流程自动化。最后,人工智能大模型合成数据能够解决制造业缺乏人工智能模型训练数据的痛点。以搬运机器人(AMR)为例,核心痛点是它对工厂本身的地图识别、干扰情景训练数据积累有限,自动驾驶的算法精度较差,显著影响产品性能。但人工智能大模型合成的数据可作为真实场景数据的廉价替代品,大幅缩短训练模型的周期,提高生产效率。
赋能医疗行业。首先,人工智能大模型能够帮助提升医疗通用需求的处理效率,比如呼叫中心自动分诊、常见病的问诊辅助、医疗影像解读辅助等。其次,人工智能大模型通过合成数据支持医学研究。医药研发所需数据存在法律限制和病人授权等约束,难以规模化;通过合成数据,能够精确复制原始数据集的统计特征,但又与原始数据不存在关联性,赋能医学研究进步。此外,人工智能大模型通过生成3D虚拟人像和合成人声,解决部分辅助医疗设备匮乏的痛点,帮助丧失表情、声音等表达能力的病人更好地求医问诊。
赋能金融行业。对于银行业,可以在智慧网点、智能服务、智能风控、智能运营、智能营销等场景开展人工智能大模型技术应用;对于保险业,人工智能大模型应用包括智能保险销售助手、智能培训助手等,但在精算、理赔、资管等核心价值链环节赋能仍需根据专业知识做模型训练和微调;对于证券期货业,人工智能大模型可以运用在智能投研、智能营销、降低自动化交易门槛等领域。
赋能乃至颠覆传媒与互联网行业。首先,人工智能大模型将显著提升文娱内容生产效率、降低成本。此前人工智能只能辅助生产初级重复性或结构化内容,如人工智能自动写新闻稿、人工智能播报天气等。在大模型赋能下,已经可以实现人工智能营销文案撰写(如美国独角兽公司Jasper.ai)、人工智能生成游戏原画(目前国内游戏厂商积极应用人工智能绘画技术)、人工智能撰写剧本(仅凭一段大纲可以自动生成完整剧本的产品Dramatron)等,后续伴随音乐生成、动画视频生成等AIGC技术的持续突破,人工智能大模型将显著缩短内容生产周期、降低制作成本。其次,人工智能大模型将颠覆互联网已有业态及场景入口。短期来看,传统搜索引擎最容易被类似ChatGPT的对话式信息生成服务所取代,因为后者具备更高的信息获取效率和更好的交互体验;同时传统搜索引擎商业模式搜索竞价广告也将迎来严峻的挑战,未来可能会衍生出付费会员模式或新一代营销科技。中长期看,其他互联网业态,如内容聚合分发平台、生活服务平台、电商购物平台、社交社区等流量入口都将有被人工智能大模型重塑或颠覆的可能性。
人工智能大模型的商业模式及前景分析
短期内,人工智能大模型的变现方式仍然以开放付费应用程序编程接口(API)调用为主。由于人工智能大模型投入成本高昂,大模型厂商前期投入巨大,通过开放API模式向各行业开放模型并收取调用费,能够规避集中押注单一行业的风险,构建相对稳定且轻量的收入模型。而行业应用开发者通过较低的价格便可调用最领先的大模型技术,应用于自身产品中提升服务质量。以OpenAI为例,2023年3月1日宣布正式允许第三方开发者通过API将ChatGPT集成到其应用程序(APP)和服务中,同时采取低价抢占市场策略,将优化后API定价降至此前的十分之一,对后发大模型公司带来巨大追赶压力。这一举措大幅降低使用门槛,商业用户数量将迎来快速增长。
在人工智能大模型及相关应用产业发展的早期,监管层应以更为包容的态度展开相关工作,鼓励探索创新。
长期来看,人工智能大模型厂商仍会深度介入某些具备重要价值的垂类应用场景,比如信息咨询、金融服务、医疗服务等,通过战略投资生态合作伙伴或自研应用级产品的方式,并通过付费订阅或新一代广告模式来进行变现。
相关建议
现阶段,人工智能大模型发展存在着一定挑战。首先,人工智能大模型本身仍有一定技术风险:鲁棒性(即系统的健壮性)不足,系统在面对黑天鹅事件和对抗性威胁时可能会表现出能力缺失;可解释性较低,缺乏理论支撑,本质基于条件概率,只能接近但无法重现人类思维逻辑,存在部分事实性错误;算法偏见,训练语料库若缺乏代表性或包含人类偏见,模型会存在算法偏见问题。其次,人工智能大模型发展也会带来一定的社会风险:数字鸿沟,可能会加剧技术拥有者和缺乏者在信息获取层面的不公平现象;垄断风险,领先的大模型技术若被海外巨头垄断,将对国内的技术进步和经济发展造成不利影响;内容风险,人工智能生成内容爆发后可能会产生大量错误信息污染互联网环境。
为此,人工智能大模型作为中美新一轮技术竞争的核心领域之一,国家层面应积极鼓励国内基础模型研究的发展、配套硬件基础设施建设及应用落地,配套管理措施也需及时跟进。
基础研究方面,人工智能大模型是高资金投入、高人才壁垒的研究领域,头部效应明显,应构建以领军企业为主体、产学研合作的创新体系,对于重点人才需加大力度引进,强化科学家之家的国际交流合作,加速追赶国际前沿水平。
产业配套方面,大力支持国产人工智能芯片和超算平台的发展,构建国家数据资源平台、发展数据标注产业及合成数据产业等,为国产人工智能大模型研发提供算力和数据保障。
应用落地方面,应积极推动大模型在制造业、医疗、金融、传媒、互联网领域的行业示范应用和规模化价值落地,打造一批可复制、可推广的标杆型示范案例。
行业监管方面,在人工智能大模型及相关应用产业发展的早期,监管层应以更为包容的态度展开相关工作,鼓励探索创新,大模型带来的风险主要是技术层面的问题,通过行业共同探索技术解决方案能够有效把控相关风险。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
西安航空学院学报(2022年2期)2022-07-04
成都医学院学报(2021年2期)2021-07-19
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
光学精密工程(2016年6期)2016-11-07
南风窗(2016年19期)2016-09-21
