
问题解决任务中行动序列的二分类建模:单/两参数行动序列模型*
2023-08-04 06:36:58付颜斌陈琦鹏詹沛达
心理学报 2023年8期
付颜斌 陈琦鹏 詹沛达
问题解决任务中行动序列的二分类建模:单/两参数行动序列模型*
付颜斌 陈琦鹏 詹沛达
(浙江师范大学心理学院; 浙江省儿童青少年心理健康与心理危机干预智能实验室; 浙江省智能教育技术与应用重点实验室, 金华 321004)
行动序列作为一种典型的过程数据, 可反映被试解决问题的详细步骤。鉴于行动或状态转移可区分正误, 本文基于二分类Logistic建模提出两个复杂度相对较低的行动序列模型——单/两参数行动序列模型(1P-/2P-ASM); 两者差异在于是否允许自由估计问题状态的区分度。通过实证研究和模拟研究对比探究两个新模型与基于多分类Logistic建模的序列作答模型(SRM)的表现。研究结果主要发现:(1)两个ASM能够获得与SRM几乎一致的问题解决能力估计值; (2)两个ASM的计算耗时明显低于SRM的; (3) 2P-ASM比1P-ASM的综合表现更优。总之, 两个模型复杂度相对低的ASM均能够实现对行动序列的有效分析, 有益于行动序列数据分析的落地。
过程数据, 行动序列, 问题状态转换, 行动序列模型, 项目反应理论
1 引言
问题解决是指在没有清晰解决方案的任务情境中, 个体通过一系列认知加工过程, 应用认知技能和认知活动, 在问题空间中进行探索, 将问题从初始状态转变为问题解决目标状态的过程(Newell & Simon, 1972)。问题解决过程中, 被试需要根据问题解决的目标构建计划, 选择策略并预估该计划的执行能否达到期望的状态; 同时, 被试还需要根据问题目标对行动结果进行检查, 发现问题并采取补救措施, 及时调整先前的行动策略。因此, 对问题解决能力的测量, 不仅要关注问题解决的最终结果, 还需要关注问题解决过程中系列行为(刘耀辉等, 2022)。比如, 国际学生测评项目(PISA) (OECD, 2013)推出了模拟生活情境的问题解决测验, 通过真实且具有互动性的任务, 记录学生在整个问题解决过程中行为的动态变化过程, 这为问题解决能力的测量提供了一种全新的方式。这些测验不仅记录了学生问题解决的结果, 还可以将学生在问题解决过程中的操作步骤实时记录在日志文件中, 即过程数据(process data)。相较于传统的结果数据, 基于过程数据的挖掘分析, 可以为推断学生的潜在问题解决能力提供更为丰富的信息。
目前, 针对计算机化问题解决任务所产生的过程数据的分析方法研究, 根据研究目的主要可分为特征提取与能力评估建模两类(Han et al., 2022; Xiao & Liu, 2023; 韩雨婷等, 2022)。其中, 特征提取可分为理论驱动和数据驱动两类, 理论驱动的特征提取方法一般采用专家定义的行为指标来对学生的问题解决过程进行评分(Harding et al., 2017; Rosen, 2017; Yuan et al., 2019), 这种方法依赖于专家的知识经验, 属于自上而下的特征提取方法。理论驱动方法标定的行为指标不仅能够用作对学生的评分依据, 还可以基于一定的测量模型进一步建模分析(Liu et al., 2018; Zhan & Qiao, 2022; Zhang et al., 2022), 但该方法往往要针对不同的任务情境设定不同的特征提取规则, 使得应用成本较高。数据驱动的方法指的是应用数据挖掘、机器学习等算法从过程数据中提取关键信息, 常使用的方法包括自然语言处理(Hao et al., 2015; He & von Davier, 2016; He et al., 2021; Zhan et al., 2015)、降维算法(Tang et al., 2020, Tang et al., 2021)和网络分析方法(Vista et al., 2017; Zhu et al., 2016)等。
另外, 根据模型对行动序列顺序关系的利用与否以及能否获得连续稳定的能力估计值, 能力评估建模可进一步分为传统心理计量模型的迁移应用、随机过程建模以及这两类的结合(韩雨婷等, 2022)。传统心理计量模型的迁移应用主要是先利用特征提取方法提取完成任务的关键指标, 然后参照这些关键指标对被试呈现的具体操作或行动序列(action sequence)1文中, “行动序列”是指被试为完成任务而呈现出的一系列行动或状态转换(state transition), 其中“状态转换”在本文中与“行动”交替使用, 均指的是两个相邻问题状态之间的转换。例如, A→B或AB表示从当前阶段的问题状态A到下一阶段的问题状态B的状态转换, 进而“A→B→C"表示一个包括两个行动或状态转换的行动序列(AB和BC)。同时, 本文中我们根据语言场景需求交替使用“行动序列”和“状态转移序列”两个含义相同的名词。进行编码(如, 若具体操作中包含关键指标则被编码为1, 否则为0), 最后基于题目作答理论(item response theory, IRT)模型或认知诊断模型对编码数据进行分析, 并估计被试的问题解决能力(Han & Wilson, 2022; Liu et al., 2018; Wilson et al., 2017; Yuan et al., 2019; Zhan & Qiao, 2022; Zhang et al., 2022; 李美娟等, 2020)。然而, 这种方法会部分或完全忽视具体操作中的顺序信息。与之相对, 已有研究直接对行动序列进行随机过程建模, 如动态贝叶斯网络(Levy, 2019)和隐马尔可夫模型(Arieli-Attali et al., 2019; Bergner et al., 2017; Xiao et al., 2021)。这种方法虽然考虑到了行动序列中的顺序信息, 但估计得到的潜变量通常是是离散的属性或知识掌握状态, 无法了解被试稳定且连续的问题解决能力(韩雨婷等, 2022)。另外, 还有研究提出了结合随机过程思想的心理计量建模方法(Chen, 2020; Han et al., 2022; Lamar, 2018; Shu et al., 2017; Xiao & Liu, 2023)。通常, 这类方法假设在给定潜在问题解决能力的前提下, 被试的不同状态转换或操作转移之间满足条件独立性假设; 比如, 将问题状态转换序列看作具有一阶马尔可夫特性的离散随机过程(Han et al., 2022; Xiao & Liu, 2023), 从而在保留序列本身顺序信息的同时推断出连续的潜在能力估计值。
针对已有方法的局限性, Han等人(2022)将动态贝叶斯网络与称名作答模型(nominal response model, NRM) (Bock, 1972)相结合, 提出了序列作答模型(sequential response model, SRM)。SRM假设被试的问题解决能力和某状态转移的特征共同决定了被试呈现该状态转移的概率。相比于已有方法, SRM不仅考虑了行动序列的顺序信息, 考虑了任务中不同状态转移的独特性, 还可以提供问题解决能力的连续估计值, 可用于精细化了解不同被试问题解决能力之间的个体差异。与NRM类似, SRM假设被试在每个问题状态下的所有转移可选项(即行动可选项)都会提供测量信息, 进而为任务中每一个可能存在的状态转移都赋予不同的参数(如, 转移倾向性参数和转移区分度参数)。本质上讲, SRM是对状态转移的多分类(或多元无序)建模, 即假设下一个阶段中的所有转移可选项之间没有数量顺序。然而, 在实际问题解决任务中, 行动或状态转移是有正误之分的:可将有助于成功解决任务的状态转移界定为正确状态转移, 而将最终可能会导致任务失败的状态转移界定为错误状态转移。因此, 被试在每个问题状态下的所有转移可选项是有正误之分的, 并非完全是没有数量顺序的等价关系。
理论上, 对于有正误之分的数据, 二分类建模更为适宜。与二分类建模相比, 多分类建模(Han et al., 2022; Xiao & Liu, 2023)的相对优势是可以将更丰富的测量信息纳入到数据分析中, 但这势必导致模型的复杂性相对更高; 更高的模型复杂性通常意味着更多的待估计参数种类和数量, 更高的参数估计计算负担, 更低的参数估计结果可解释性(Ma et al., 2016)。基于模型比较与选择的简约原则(Beck, 1943), 本研究拟对包含正误信息的行动序列进行二分类建模, 提出单参数和两参数行动序列模型(one- and two-parameter action sequence model, 1P- / 2P-ASM), 以期降低行动序列分析模型的复杂性并增加计算效率; 同时, 相对简约的模型也有助于增加模型参数估计结果的可解释性, 进而增加行动序列模型的实践易用性。
首先, 阐述行动序列建模基础; 其次, 介绍本文两个新模型:1P-ASM和2P-ASM; 然后, 基于一则实证研究数据对比两个新模型和SRM的参数估计结果, 以展现新模型的实践可应用性及其与SRM的参数估计结果一致性程度; 再然后, 通过模拟研究探究两个新模型在不同模拟测验条件的心理计量学性能; 最后, 对研究结果进行总结并探讨研究局限及未来研究方向。
2 背景知识
2.1 行动序列建模基础
本研究聚焦于任务目标明确且已知信息完备的结构良好(well-defined)任务; 这类任务常以有限状态自动机(finite state automata)为原型构建。这类任务通常拥有有限的问题状态, 有限的用户输入信号(即行动或操作), 并且通过用户的操作可以产生对应的输出信号, 即拥有明确的状态转移规则(Buchner & Funke, 1993)。图1(a)呈现了一个FSA问题解决任务的例子, 该问题解决过程包含了S、A、B、C、D和E共六种问题状态。其中S为问题解决初始状态, E为问题解决的目标状态, 其余均为问题解决的中间状态。由于该题目允许被试在任意中间状态反悔回到初始状态, 所以理论上会出现多种行动序列, 比如, S→A→C→E、S→B→S→ A→C→E、S→B→D→E等。在众多行动序列中, 把达到任务目标的最短行动序列界定为最优状态转移序列或最优行动序列; 如最优状态转移序列S→A→C→E包含S→A、A→C和C→E三个状态转移。图中, 红色实线箭头表示正确状态转移, 即有助于正确解决问题的状态转移; 而黑色虚线箭头为错误状态转移, 即最终可能导致远离任务目标的状态转移。
实际上, 我们可以将被试在每个问题状态下的行动转移视为被试在作答一道“选择题”。图1(b)是与图1(a)相对应的问题解决流程图。当被试处于阶段1中问题状态S时, 他/她需要在阶段2中的两个问题状态A和B之间做出选择; 同理, 当被试处于阶段2中问题状态A时, 他/她需要在阶段3中三个问题状态C、D和S之间做出选择(S表示返回到初始状态)。此时, 我们就可将适用于题目层面作答精度数据分析的传统IRT模型迁移应用于此。比如, Han等人(2022)就将NRM迁移应用于此, 进而基于多分类建模提出了SRM。
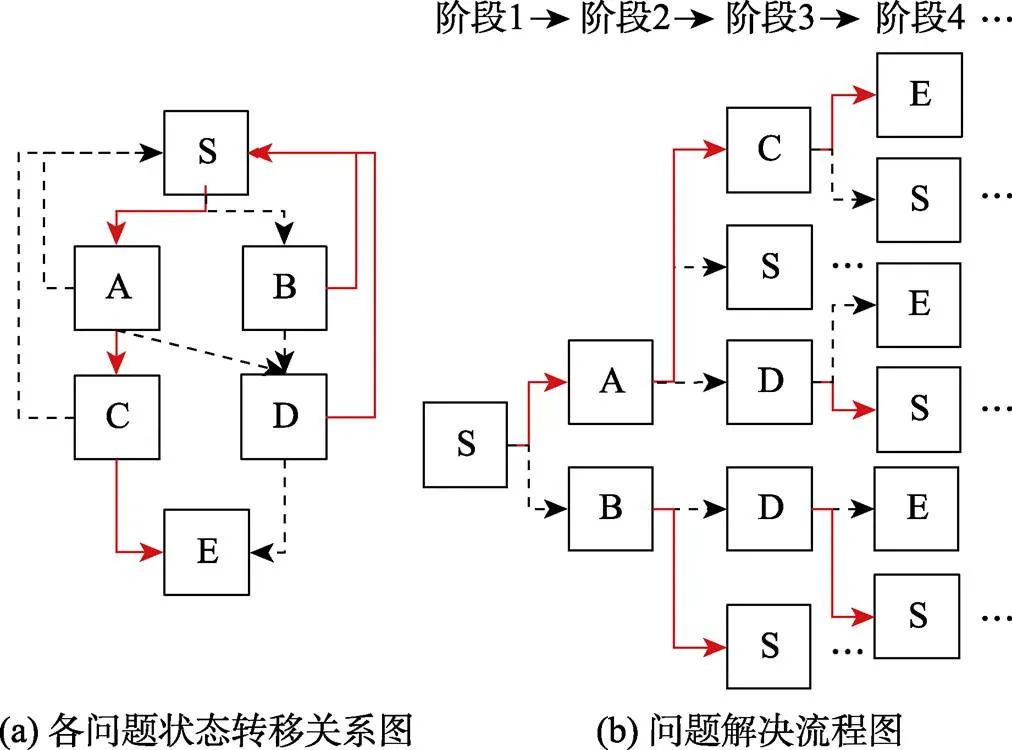
图1 问题解决任务示意图
注:红色实线箭头表示正确状态转移, 黑色虚线箭头表示错误状态转移; S→A→C→E为最优行动序列, 其中包含S→A、A→C和C→E三个状态转移。省略号表示问题解决流程的重复出现。
2.2 SRM简介
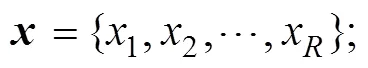


图2 序列作答模型示意图
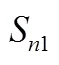
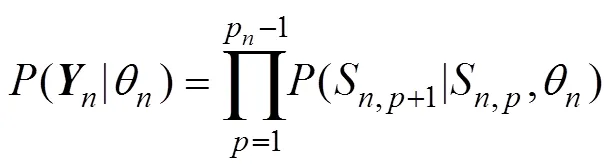

3 行动序列的二分类建模:1P-ASM和2P-ASM
3.1 模型构建
尽管SRM采用多分类建模将所有行动序列所提供的测量信息均纳入到模型之中, 但它仍然通过一个预先设定的状态转移区分度参数区别对待了行动序列中状态转移的正确与否。针对具有正误之分的状态转移, 本研究采用二分类建模思路, 使用针对二级评分数据的IRT模型对行动序列进行建模, 如单参数IRT模型/罗氏模型(Rasch, 1960)和两参数IRT模型(Birnbaum, 1968)。对此, 图3呈现了与图1对应的问题解决任务的二分编码示意图, 该图中我们将正确状态转移编码为1, 错误状态转移编码为0。图3(b)中, 我们可以将每一阶段中的“选择题”视为“具有正确答案的多项选择题”; 此时, 就可以借鉴传统二级评分IRT模型来构建行动序列模型。
图4呈现了两个ASM的建模示意图。首先, 将任务中所有的状态转移进行二分编码:将正确状态转移编码为1, 将错误状态转移编码为0。此时, 被试解决问题所呈现的状态转移向量就被编码为仅包含0或1元素的二元向量; 比如图1中最优行动序列S→A→C→E所对应的状态转移向量(SA, AC, CE)’可被转换为(1,1,1)′。然后, 基于二级评分IRT模型, 假设被试的问题解决能力影响被试呈现正确状态转移的概率。
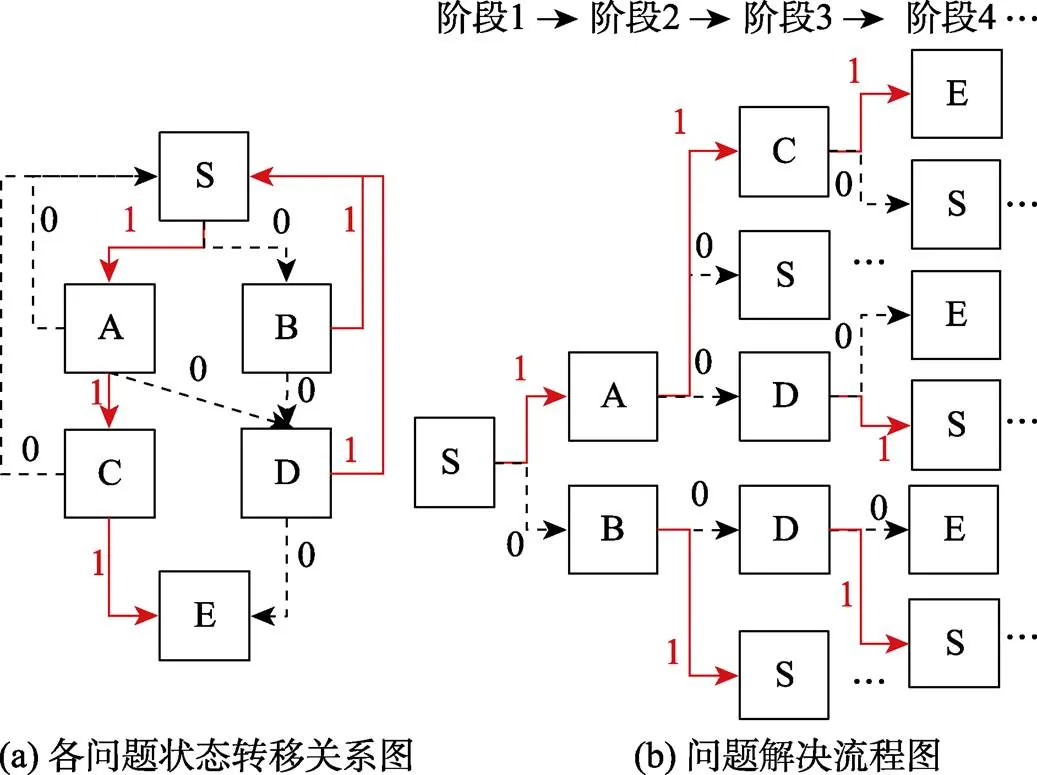
图3 问题解决任务二分编码示意图
注:红色实线箭头表示正确状态转移, 编码为1; 黑色虚线箭头表示错误状态转移, 编码为0; 省略号表示问题解决流程的重复出现。
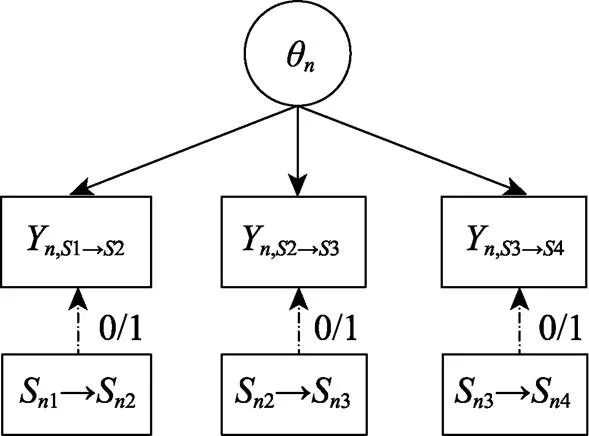
图4 二分类行动序列模型建模示意图
借鉴单参数IRT模型, 1P-ASM可被表示为:
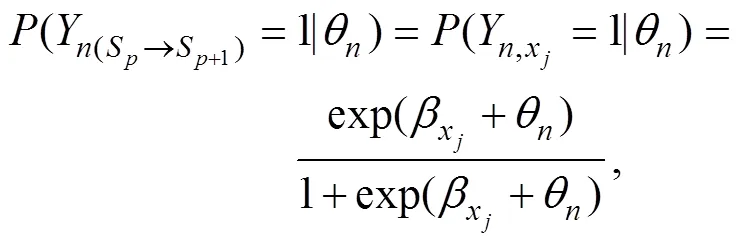
借鉴两参数IRT模型, 2P-ASM可被表示为:
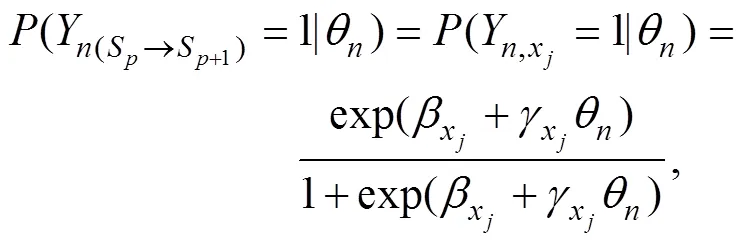

3.2 与相关模型的对比
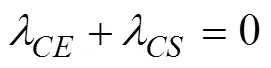
3.3 贝叶斯参数估计
与SRM一样, 两个ASM也可使用全贝叶斯马尔可夫链蒙特卡洛(MCMC)算法进行参数估计。详见网络版附录7。
4 实证数据分析
4.1 任务描述
与Han等人(2022)研究保持一致, 本研究也选用PISA 2012计算机化问题解决“Tickets”任务(CP038Q02)的行动序列数据进行分析。该任务要求被试操作一台虚拟售票机, 购买一张可以乘坐2次的全价郊区火车票。图5呈现了该任务的初始界面, 问题解决过程中各阶段的截图见网络版附录2。为解决问题, 被试首先需要在交通方式上选择“城市地铁”或“郊区火车”。其次, 根据所选的交通方式, 被试需要在“全价票”和“打折票”之间做选择。然后, 根据所选票价类型, 再选择购买“包日票”或“次票”; 如果选择“次票”则还要选择购买的乘车次数(“1次”~“5次”)。最后做出“购买”决定即可完成该任务。被试可以在任意操作界面通过点击“取消”来返回到任务的初始界面重新进行选择。为了解决该任务, 不同被试最终呈现的行动序列的长度不尽相同。

图5 PISA 2012购票任务初始界面
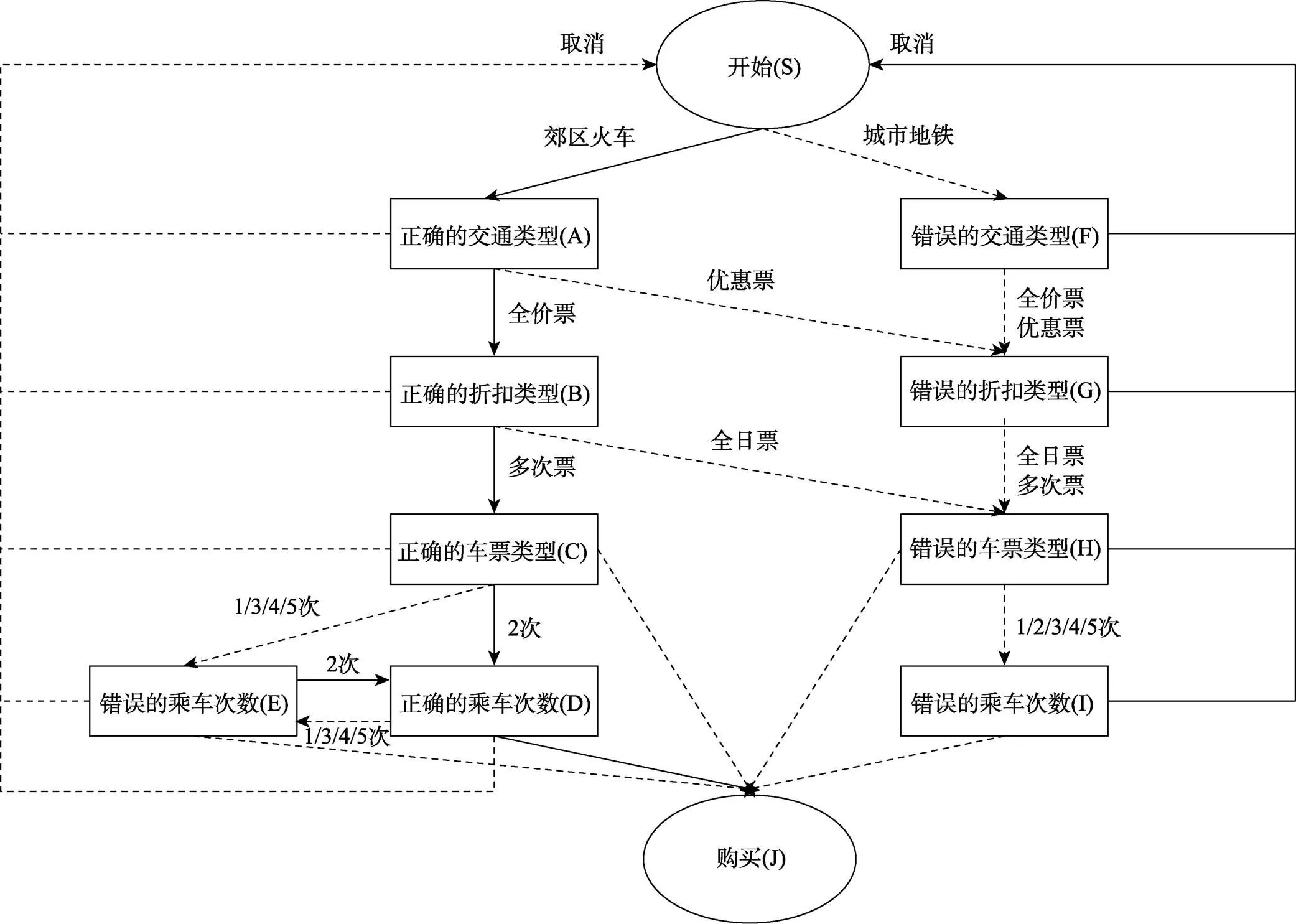
图6 PISA 2012购票任务结构图
表1从“选择题”视角进一步整理了图6中的操作过程。可将当前阶段所处的问题状态视为一道被试需要作答的“选择题”, 将下一阶段的可选问题状态视为“选项”。比如, 在初始阶段被试需要在“选择题”S的两个“选项”A和F之间进行选择; 其中A为正确“选项”, F为错误“选项”。针对这些“选择题”, SRM将它们视为称名作答题, ASM将它们视为二级评分选择题。比如, 某学生的行动序列为SABCDEDJ, 则SRM分析的状态转移向量为(SA, AB, BC, CD, DE, ED, DJ)′, 而ASM分析的状态转移二分向量为(1, 1, 1, 1, 0, 1, 1)′。
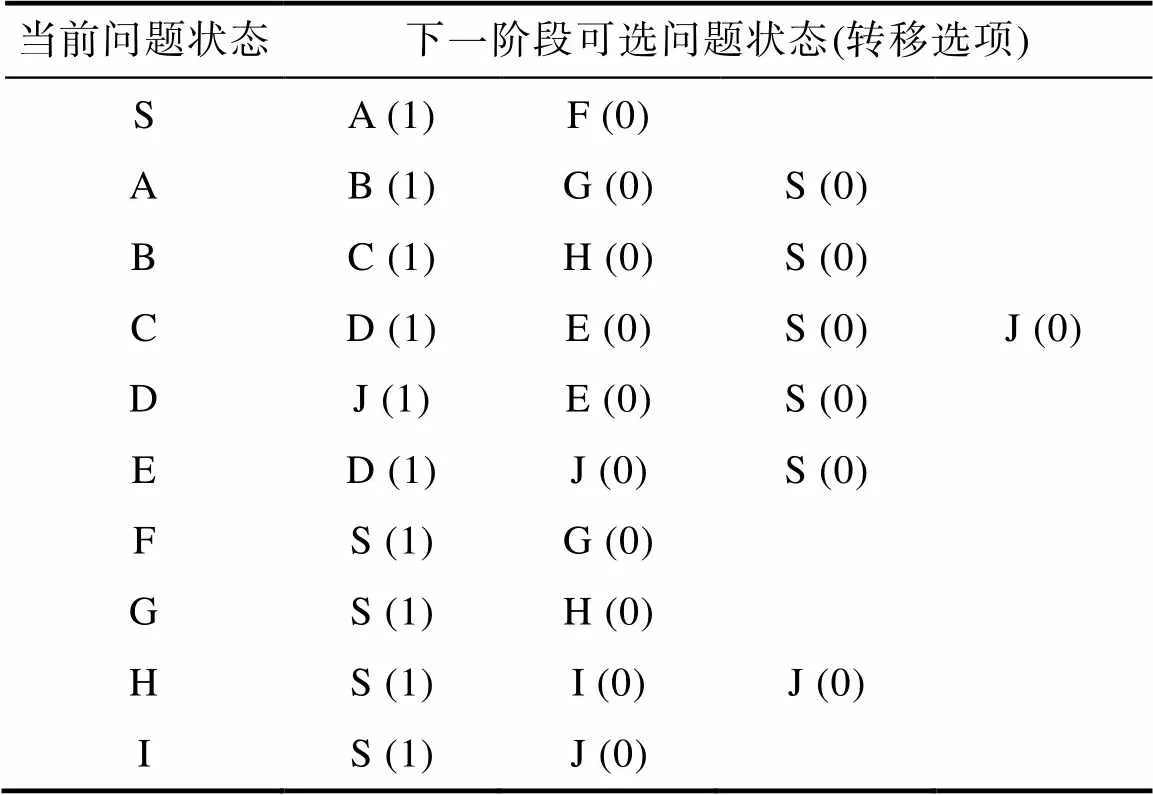
表1 PISA 2012购票任务所类比的“选择题”
注:括号中的1代表正确“选项”(即正确状态转移), 0代表错误“选项”(即错误状态转移)。
4.2 数据整理与分析
原始数据来源于PISA官网下载2https://www.oecd.org/pisa/pisaproducts/database-cbapisa2012.htm。在进行具体的数据分析之前, 先根据图6中定义的任务结构对原始数据进行重新编码, 并对数据进行清理:(1) 删去提前终止作答的行动序列, 即没有点击“购买”的行动序列; (2) 删除包含了不可能的状态转移的行动序列(如网络版附录3表A2)。最终, 从记录行动的日志文件中提取了28,851名被试的行动序列, 其中行动序列的最短长度为5, 最长长度为110, 平均长度为6.992。原始数据当中包含了1,395种行动序列, 其中有569种行动序列完成了任务目标(涉及15,408名被试:有10,610名被试按照最优行动序列完成了任务目标, 另外4,798名学生在正确解决问题过程中有错误修正过程)。最后, 限于算力且为增加研究效率, 我们采用简单随机抽样, 从28,851名被试中随机选取了2,000名学生的行动序列用于本研究的实证分析(行动序列的最短长度为5, 最长长度为46, 平均长度为7.03; 包含了1395种行动序列, 其中有569种行动序列完成任务目标(涉及1068名学生, 有737人按照最优行动序列完成了任务目标)。
分别使用1P-ASM、2P-ASM和SRM分析数据。参数估计时, 选用2条马尔可夫链, 每条链长5,000次, 预热(burn-in)3,000次。使用PSRF值(PSRF; Gelman & Rubin, 1992)来确定MCMC算法得到的参数估计值是否达到收敛; 当PSRF < 1.1时, 表明参数估计收敛。此外, 采用Watanabe-Akaike信息准则 (WAIC; Watanabe, 2010)和留一法交叉验证(LOO, Vehtari et al., 2017)两个完全贝叶斯的相对拟合指标来衡量模型对数据的拟合情况, 为模型选择提供证据; 两个指标值越小, 表明模型对数据的拟合越好。值得注意的是, 由于SRM和ASM分析的数据并不相同(前者分析的是每位学生的状态转移向量, 后者分析的是每位学生的状态转移向量的二分化向量), 所以两者的相对拟合值无法比较。因此, 我们仅能通过相对拟合指标判断两个ASM之间的相对拟合优劣, 无法用于判断ASM和SRM的相对拟合优劣。对此, 本研究将通过计算ASM和SRM参数估计结果的一致性来体现二分类建模具有与多分类建模相接近的表现。另外, 使用后验预测检验(PPC; Gelman et al., 1996)评估模型对数据的绝对拟合; 如果模型拟合数据, 则其后验预测概率()接近0.5, 反之, 如果模型不拟合数据, 则其值 < 0.025或 > 0.975。本文中PPC所使用的统计量见网络版附录4表A3。
4.3 结果
所有模型中所有参数的PSRF值均小于1.05, 表明在我们的设定下所有参数估计达到收敛标准。此外, 网络版附录5中提供了模型参数的抽样轨迹图。表2呈现了三个模型对数据的拟合情况和计算耗时。首先, 三个模型的值均接近0.5, 表明三个模型均拟合该数据。其次, 两个相对拟合指标表明2P-ASM对数据的拟合优于1P-ASM, 意味着考虑状态转移的区分度能更好地反映该数据的特征, 即不同状态转移对问题解决能力的区分能力是不同的。如上文所述, ASM和SRM的相对拟合结果不具有可比性。最后, 参数估计耗时可以综合反映模型的复杂性程度, 结果发现SRM的耗时最长, 2P-ASM次之, 1P-ASM的耗时最短; 这表明二分类模型的确比多分类模型简约。下文主要研究结果围绕两个ASM阐述, 并呈现ASM和SRM对被试问题解决能力估计的一致性。
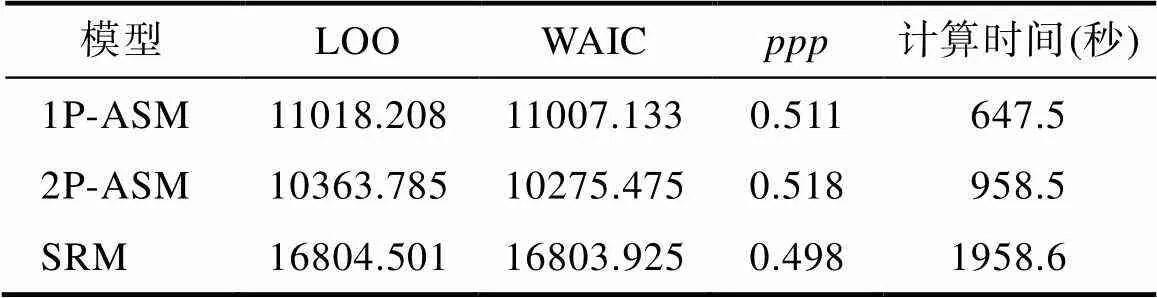
表2 实证研究中三个模型对数据的拟合情况和计算耗时
注: 1P-ASM = 单参数行动序列模型; 2P-ASM = 两参数行动序列模型; SRM = 序列作答模型; LOO = 留一法交叉验证; WAIC = Watanabe-Akaike信息准则;= 后验预测概率。
表3中呈现了两个ASM的题目参数估计结果3SRM的题目参数估计结果见于网络版附录8。(后验均值、后验标准差和95%最高概率密度[贝叶斯可信区间])。首先, 对于行动容易度参数而言, 正确问题解决路径(即最优行动序列)上的问题状态(S、A、B、C和D)的容易度参数的后验均值均大于0 (2P-ASM中问题状态D的后验均值与零无显著差异), 表明当被试处于正确路径上的问题状态时, 其更容易继续呈现正确状态转移; 与之相对, 错误问题解决路径(即非最优行动序列)上的问题状态(F、G、H和I)的容易度参数的后验均值均小于0 (1P-ASM中问题状态I的后验均值与零无显著差异; 2P-ASM中问题状态H和I的后验均值与零无显著差异), 表明当被试已经处于错误路径上的问题状态时, 其更难以纠正错误转向正确的问题状态(即更易于继续维持在错误路径上)。值得注意的是, 问题状态E和I是错误路径上的问题状态, 其含义均为“选择错误的乘车次数”; 相较于其他错误路径上的问题状态, E和I的容易度估计值更高, 表明当被试处于这两个错误状态时, 更有可能在下一步选择时纠正自己的错误(即选择S返回初始状态重新作答)。其次, 对于行动区分度参数而言, 不同问题状态的行动区分度有一定差异性。其中, 问题状态C和I的行动区分度后验均值相对较高, 表明不同问题解决能力的学生在这两个问题状态下呈现正确状态转移的概率差异相对较大。也就是说, 已处于正确问题解决路径上的学生是否能够选择正确的乘车次数, 以及已经处于错误问题解决路径上的学生是否能够通过“取消”来纠正自己的错误, 这两个操作对于学生的能力的区分力是相对最强的。总之, 根据行动参数估计值可发现, 当被试已经处于正确问题解决路径, 则其更易于保持在正确问题解决路径上; 而当被试已经处于错误问题解决路径, 则其更易于继续错下去, 直到末尾选择乘车次数界面时才有一个纠正错误的关键期。
图7呈现了三个模型的问题解决能力估计值(后验均值)的对比散点图及概率密度图。首先, 散点图结果呈现出三个模型的问题解决能力估计值具有较高的一致性(三者之间的相关系数均在0.99以上), 表明它们测量的是同一潜在特质且二分类建模与多分类建模一样能够通过分析行动序列数据测量被试的问题解决能力并反映个体之间的差异性。其次, 对比三模型的概率密度图, 可发现三个模型在高能力区间和低能力区间的概率密度分布基本一致, 仅在中能力区间的分布略有差异(主要是SRM)。一个可能的原因是SRM更充分地利用了不同状态转移所提供的测量信息:它不仅利用了正确状态转移所包含的测量信息, 也利用了不同错误状态转移中的测量信息。比如, 当多名被试同时处于问题状态A时, 相比于选择错误“选项”G的被试而言, 选择错误“选项”S的被试的问题解决能力似乎要更高一些; 此时, SRM是可以区分呈现AG的被试和呈现AS的被试之间的区别的, 而ASM则将他们均视为同一类做出错误选择的人。
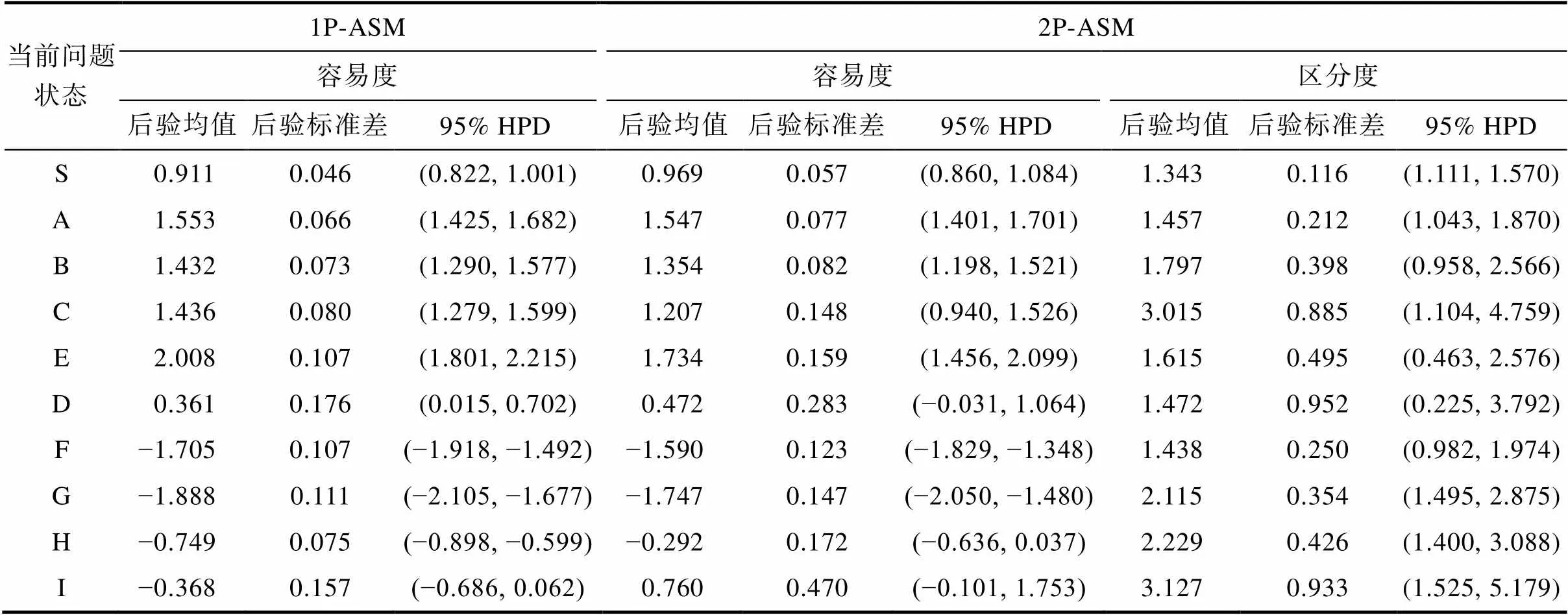
表3 实证研究中行动序列模型参数估计结果
注: 1P-ASM = 单参数行动序列模型; 2P-ASM = 两参数行动序列模型; SRM = 序列作答模型; 95% HPD = 95%最高概率密度(贝叶斯可信区间)。

图7 实证数据中三个模型的问题解决能力参数后验均值对比散点图及概率密度图
注: 1P-ASM = 单参数行动序列模型; 2P-ASM = 两参数行动序列模型; SRM = 序列作答模型; r = 皮尔逊积差相关。
从分析数据中挑选取出现频率大于20次的行动序列作为典型行动序列(涵盖了80.1%的被试)。表4呈现了典型行动序列在三个模型中的问题解决能力估计值的描述统计(按SRM的能力估计均值从高到低排序)。首先, 三个模型对呈现各典型行动序列的被试的能力估计的描述性统计具有一定的一致性。比如, 呈现最优行动序列SABCDJ的被试的能力估计均值相对最高, 而呈现最差行动序列SFGHIJ的被试的能力估计均值相对最低。其次, 整体而言, 各典型行动序列中, 出现正确问题状态的数量越多且出现错误问题状态的数量越少则被试的能力估计值的均值就越高, 反之, 被试的能力估计值的均值就越低。然后, 对比ASM和SRM的结果, 发现ASM中有两个序列下的被试的能力估计值的均值排序与SRM中的不同:SABCEDJ对应的能力估计值的均值略低于SFGHSABCDJ对应的。呈现SABCEDJ的被试尽管在状态C上的选择出现了错误转移(CE)且马上进行了纠正(ED), 而呈现SFGHSABCDJ的被试在初始状态就出现了错误转移, 直到选择购买乘车次数时才返回初始页面纠正自己的错误。ASM和SRM在这两个序列上的排序差异可以从不同的视角解释。首先, 从出现错误状态的次数或问题解决效率(序列长度)看, 似乎呈现SABCEDJ的被试的能力估计值均值应该高于呈现SFGHSABCDJ的被试的; SRM的排序结果支持该视角解释。其次, 结合表3中的行动容易度参数可发现, 问题状态C的容易度较高(难度较低), 而问题状态F、G和H的容易度较低(难度较高); 因此, 从错误选择对能力估计带来的负面影响或惩罚看, 在状态C的错误选择所带来的惩罚高于在状态F、G和H的错误选择所带来的, 进而导致SABCEDJ的被试的能力估计值均值低于呈现SFGHSABCDJ的被试的; ASM的排序结果支持该视角解释。
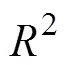
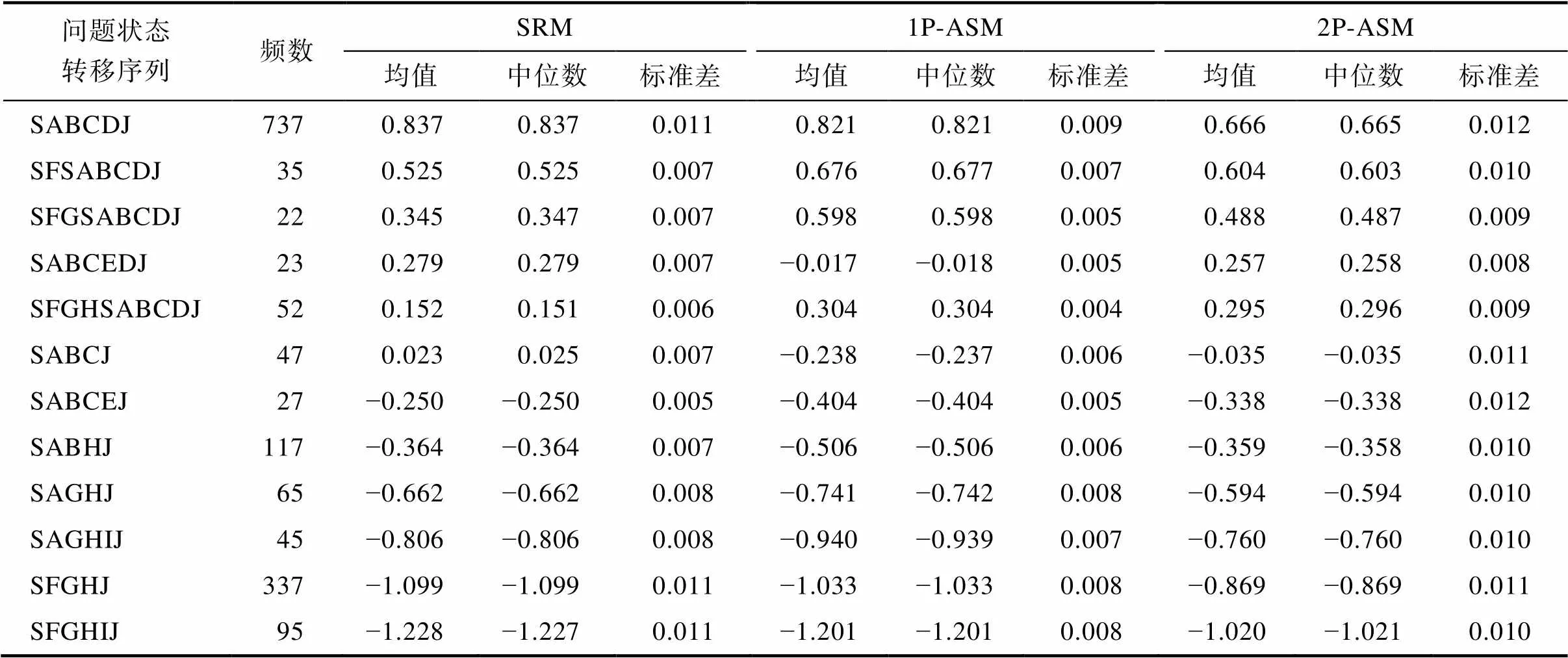
表4 典型行动序列对应的问题解决能力估计值的描述统计
注:1P-ASM = 单参数行动序列模型; 2P-ASM = 两参数行动序列模型; SRM = 序列作答模型。
5 模拟研究
5.1 研究设计、数据生成与分析
通过一则模拟研究进一步探究两个ASM在理想测验情境下的心理计量学表现。需要强调的是ASM本身并无法生成被试解决任务所呈现的行动序列(只能生成0-1向量); 因此, 模拟研究中使用SRM作为行动序列数据的生成模型。采用实证研究中的问题解决任务结构(图6)来生成行动序列数据。模拟研究包含两个操纵变量:样本量(含100、200和500人三个水平)和行动序列长度(含短和长两个水平); 参照Han等人(2022)和Fu等人(2022)的做法, 在SRM中通过调整“取消”操作(如, A→S)的转移倾向参数来操纵行动序列的长度:该参数取值越大行动序列长度越长。行动序列生成步骤详见网络版附录6。最终, 本研究中生成的短行动序列和长行动序列的平均长度分别约为10.5和20.2。此外, 为减少随机误差影响, 六种模拟条件下均按照上述数据生成步骤重复生成50组数据。
5.2 结果
首先, 在所有条件下, 三模型中所有参数的PSRF均小于1.1, 表示所有模型参数估计均收敛。表5呈现了不同模拟条件下三个模型的问题解决能力参数估计的返真性和计算耗时。首先, 被试样本量对能力参数估计的返真性的影响较小; 序列平均长度越长, 能力参数估计的返真性越高。从另外的角度来看, 序列的平均长度反映了题目样本量的大小, 序列平均长度越长, 即题目的样本量越大, 对于被试能力值的推断则越准确。其次, SRM作为数据生成模型, 其返真性理应最好, 2P-ASM次之, 1P-ASM最差, 但三者间整体差异不大(绝大多数条件下1P-ASM的RMSE比SRM的高不到0.05, Cor低不到0.02)。最后, 在所有条件下1P-ASM的计算耗时最短, 2P-ASM次之, SRM最长; 该结果与实证研究结果吻合, 表明相比于多分类模型, 二分类建模在保证其能力参数估计精度仅有微弱下降的同时, 可大幅减少参数估计耗时。
表6呈现了不同模拟条件下两个ASM与SRM的问题解决能力参数估计的一致性。整体看, 两个ASM与SRM的一致性均较高, 且2P-ASM与SRM的一致性高于1P-ASM与SRM的一致性。另外, 值得注意的是, 当序列长度增加后, 1P-ASM与SRM的一致性略有下降, 而2P-ASM与SRM的一致性略有提升。可能的原因是, 1P-ASM相对简单, 其约束所有问题状态具有相同的区分度, 而序列较短(“题目”数量较少)时这种约束带来的负面影响比序列较长时低(序列越长, 各问题状态之间的区分度差异越大); 而2P-ASM相对复杂, 需自由估计所有问题状态的区分度, 此时, 随着序列长度的增加, 各问题状态的区分度差异随之增加, 更符合2P-ASM的假设。
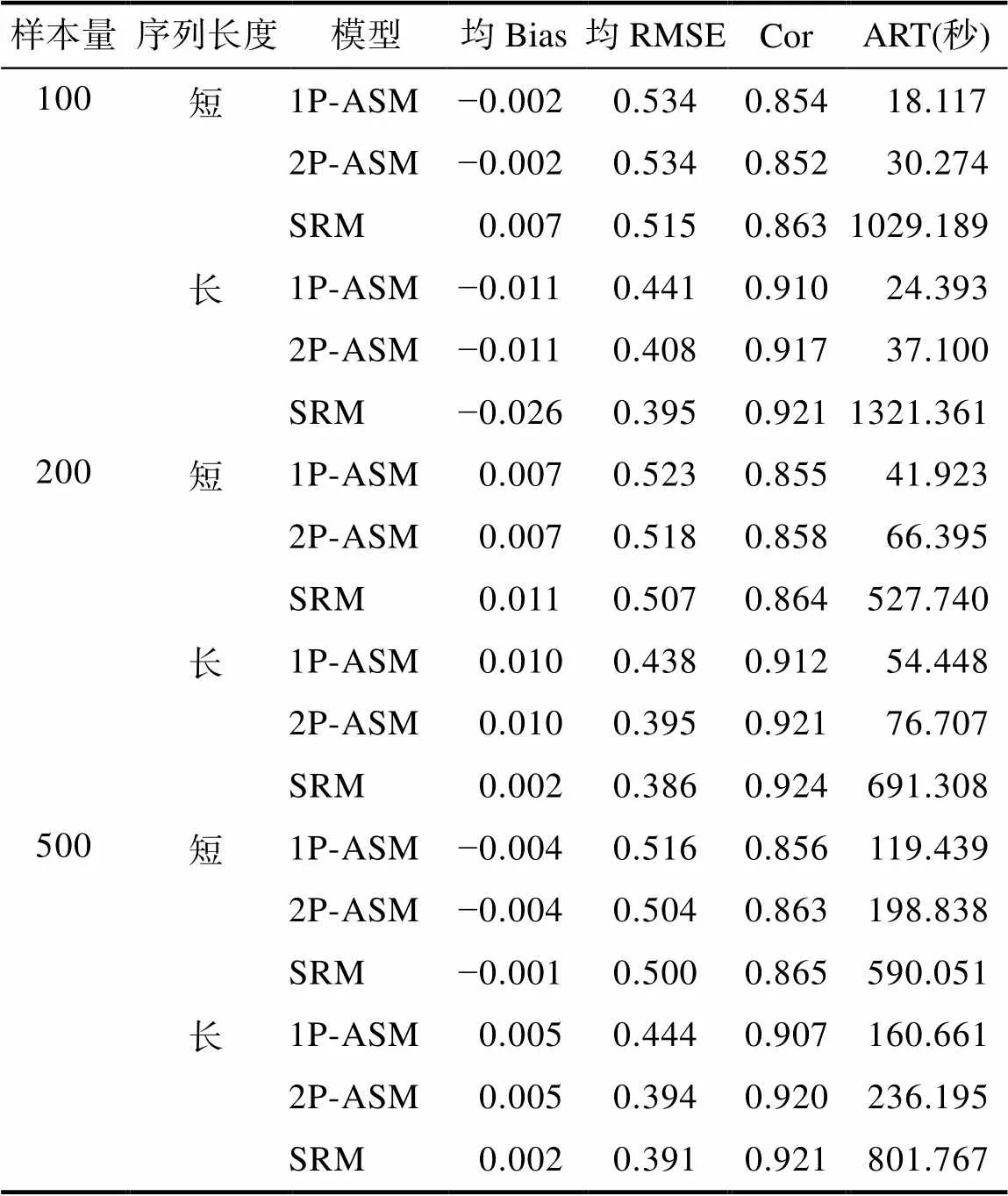
表5 模拟研究中三个模型的问题解决能力参数的估计返真性和计算耗时
注: 1P-ASM = 单参数行动序列模型; 2P-ASM = 两参数行动序列模型; SRM = 序列作答模型; 均Bias = 所有被试的估计偏差的均值; 均RMSE = 所有被试的均方根误差的均值; Cor = 真值与估计值之间的相关系数; ART = 平均计算时间。当样本量为100时, SRM模型的计算耗时明显多于其他较高样本量条件下的计算耗时; 可能是因为样本量较少的情况下, 数据提供的测量信息有限, 使复杂程度较高的SRM的MCMC抽样更为困难。
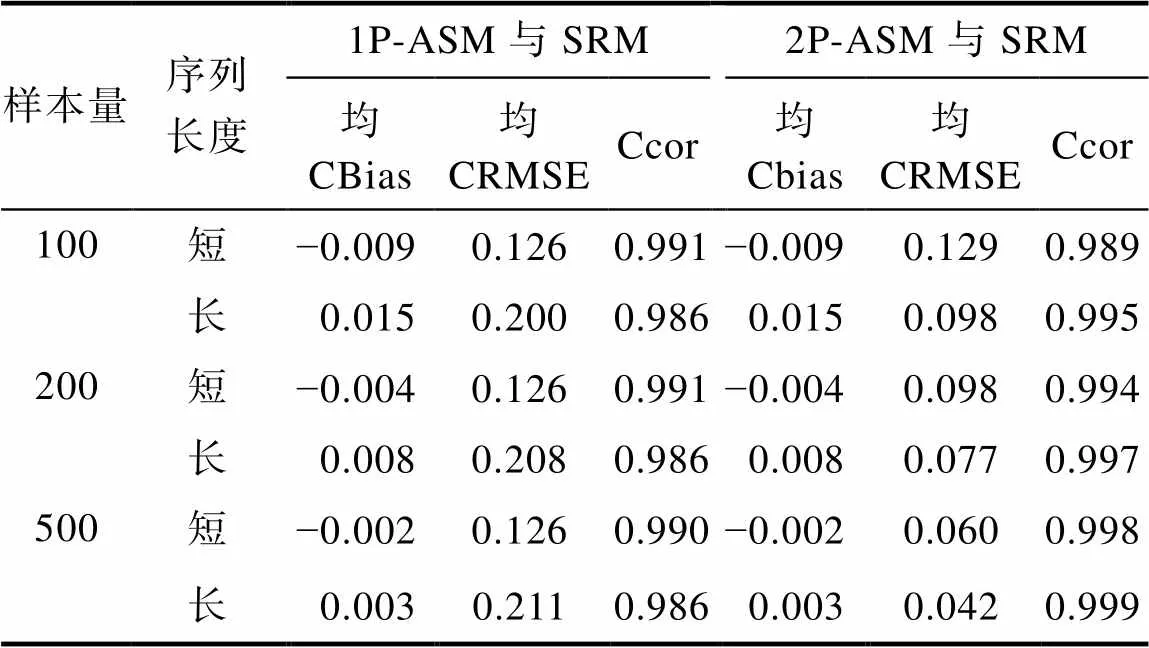
表6 模拟研究中两个ASM和SRM的问题解决能力参数估计的一致性
注: 1P-ASM = 单参数行动序列模型; 2P-ASM = 两参数行动序列模型; SRM = 序列作答模型; 均Cbias = 所有被试的一致性偏差的均值; 均CRMSE = 所有被试的一致性误差的均值; Ccor = SRM估计值与ASM估计值之间的相关系数。
6 总结与讨论
与传统作答精度数据相比, 诸如行动序列等过程数据能提供有关被试如何解决问题的更丰富信息。同时, 行动序列数据的非标准化格式(即不同被试的数据长度不同)也给传统心理计量学模型的直接应用带来了困难。针对已有方法的局限, Han等人(2022)将动态贝叶斯网络与NRM相结合, 提出了SRM。与NRM类似, SRM采用多分类logistic建模, 进而为任务中每一个可能存在的状态转移都赋予不同的参数, 导致模型复杂性较高。鉴于问题解决任务中状态转移有正误之分, 而非是没有数量顺序的等价关系, 本文基于二分类建模提出了两个模型复杂性相对较低的行动序列模型——1P-ASM和2P-ASM。不同于SRM将NRM迁移应用至行动序列数据分析, 1P-ASM和2P-ASM分别将更为简单的单参数IRT模型和两参数IRT模型迁移应用至行动序列数据分析。实证研究结果发现(1)两个ASM和SRM的问题解决能力估计值具有接近于1的相关系数, 表明它们测量的是同一潜在特质; (2)两个ASM的计算耗时明显低于SRM的, 一定程度上表明ASM的模型复杂性低于SRM的; (3)参数估计结果揭示了本研究中任务的特征:当被试已经处于正确问题解决路径, 则其更易于保持在正确问题解决路径上; 反之, 当被试已经处于错误问题解决路径, 则其更易于继续错下去; (4)与1P-ASM和SRM将区分度参数进行固定不同, 2P-ASM可以提供在当前所处问题状态下呈现正确状态转移的区分度参数, 有助于确定相对比较重要的问题状态(比如实证研究中的问题状态C和I), 以便数据分析者更好地了解任务本身。模拟研究结果发现(1)即便不是数据生成模型, 两个ASM也能提供较高的参数估计返真性; (2)两个ASM的计算耗时低于SRM, 尤其是在小样本量条件下的相对优势更为明显; (3)两个ASM的问题解决能力估计值与SRM的均具有很高的一致性, 且2P-ASM与SRM的一致性相对更高; (4)被试解决问题时最终呈现的行动序列的长短是影响两个ASM以及SRM参数估计返真性的主要原因之一:序列越长, 数据所含信息越多, 对问题解决能力的估计精度更高。综上所述, 本文基于二分类建模提出的两个ASM能够实现对行动序列数据的有效分析, 在减少模型复杂性的同时, 还能够提供与SRM几乎一致的被试问题解决能力估计值。同时, 综合模拟研究与实证研究的结果, 我们认为2P-ASM比1P-ASM的综合表现更优; 但当样本量较小(如100人)或任务简单(解决问题所需的操作较少)时, 则推荐使用更简约的1P-ASM。
当然, 作为二分类模型, ASM与SRM相比仍有一定的理论局限。比如, 使用ASM分析行动序列数据前需要将行动序列进行二分编码, 将所有错误状态转移视为“等价”, 进而不可避免地损失了不同错误状态转移所提供的差异化信息。另外, 由于ASM是对二分编码后的行动序列数据进行建模的, 导致我们无法通过给定模型参数使其生成行动序列数据。
尽管本文提出两个可有效分析行动序列数据的模型, 但仍有一些不足值得在今后的研究中做进一步尝试。比如, 首先, 与SRM一样, ASM也假设被试的问题解决能力是单维的; 然而, 在一些问题解决任务中, 有可能需要被试使用多个不同维度的问题解决能力。后续研究也可尝试进一步提出多维行动序列模型(Shu et al., 2017)。其次, 在过程数据中, 不仅记录了被试在问题解决各阶段所处的问题状态, 还记录了被试在问题解决各阶段上的时间戳信息; 利用时间戳信息可以计算出被试呈现各状态转移所花费的时间, 即行动时间(action times) (Fu et al., 2022)。目前, 在题目层面数据分析中, 已有大量关于题目作答时间(item response times)数据分析的以及将其与题目作答精度数据进行联合分析的研究(e.g., van der Linden, 2006; 2007; Man et al., 2022; Peng et al., 2022; Zhan et al., 2018, Zhan et al., 2022)。后续研究也可尝试将行动时间数据与行动序列数据相结合, 进一步挖掘过程数据中所包含的丰富信息(Fu et al., 2022)。再有, 被试在解决问题过程中必须从下一个阶段的转移可选项中选择一个才能将任务继续下去; 当被试不知如何选择时, 是有可能通过猜测来进行选择的。后续研究也可以尝试迁移应用包含猜测参数的三参数IRT模型来处理行动序列数据中可能存在的猜测问题。最后, 由于篇幅、时间和精力所限, 模拟研究中所操纵的变量数量或水平数量有限, 未能充分挖掘ASM在不同理想测验条件下的表现。后续研究也可尝试通过操纵其他变量(如, 任务的复杂性[包含更多数量问题状态])来进一步探究ASM的心理计量学性能。
Arieli-Attali, M., Ou, L., & Simmering, V. R. (2019). Understanding test takers' choices in a self-adapted test: A hidden Markov modeling of process data.,, 83.
Beck, L. W. (1943). The principle of parsimony in empirical science.,(23), 617−633. https://doi.org/10.2307/2019692
Bergner, Y., Walker, E., & Ogan, A. (2017). Dynamic Bayesian network models for peer tutoring interactions. In A. A. von Davier, M.Zhu, & P. C. Kyllonen (Eds),(pp. 249−268). Cham: Springer.
Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee's ability. In F. M. Lord & M. R. Novick (Eds.),(pp.397−124). Reading, MA: Addison-Wesley.
Bock, R. D. (1972). Estimating item parameters and latent ability when responses are scored in two or more nominal categories.(1), 29−51. https://doi.org/10. 1007/BF02291411
Buchner, A., & Funke, J. (1993). Finite-state automata: Dynamic task environments in problem-solving research.(1), 83−118.
Chen, Y. (2020). A continuous-time dynamic choice measurement model for problem-solving process data.(4), 1052−1075.
Fu, Y., Zhan, P., Chen, Q., & Jiao, H. (2022). Joint modeling of action sequences and action times in problem-solving tasks.. Retrieved from psyarxiv.com/e3nbc
Vehtari, A., Gelman, A., & Gabry, J. (2017). Practical Bayesian model evaluation using leave-one-out cross- validation and WAIC., 1413− 1432.
Gelman, A., Meng, X.-L., & Stern, H. (1996). Posterior predictive assessment of model fitness via realized discrepancies.,, 733−760.
Gelman, A., & Rubin, D. B. (1992). Inference from iterative simulation using multiple sequences.,, 457−511.
Han, Y., Liu, H., & Ji, F. (2022). A sequential response model for analyzing process data on technology-based problem- solving tasks.(6), 960-977.
Han, Y., & Wilson, M. (2022). Analyzing student response processes to evaluate success on a technology-based problem-solving task.(1), 33−45.
Han, Y., Xiao, Y., &Liu, H. (2022). Feature extraction and ability estimation of process data in the problem-solving test.,(6), 1393−1409.
[韩雨婷, 肖悦, 刘红云. (2022). 问题解决测验中过程数据的特征抽取与能力评估.(6), 1393− 1409.]
Hao, J., Shu, Z., & von Davier, A. (2015). Analyzing process data from game/scenario-based tasks: An edit distance approach.(1), 33− 50.
Harding, S. M. E., Griffin, P. E., Awwal, N., Alom, B. M., & Scoular, C. (2017). Measuring collaborative problem solving using mathematics-based tasks.(3), 1-19.
He, Q., Borgonovi, F., & Paccagnella, M. (2021). Leveraging process data to assess adults’ problem-solving skills: Using sequence mining to identify behavioral patterns across digital tasks., 104170.
He, Q., & von Davier, M. (2016). Analyzing process data from problem-solving items with N-grams: Insights from a computer-based large-scale assessment. In R. Yigal, F. Steve, & M. Maryam (Eds.),(pp. 749−776). Hershey, PA: Information Science Reference.
Hoffman, M. D., & Gelman, A. (2014). The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo.(1), 1593−1623.
LaMar, M. M. (2018). Markov decision process measurement model.(1), 67−88.
Levy, R. (2019). Dynamic Bayesian network modeling of game-based diagnostic assessments.(6), 771−794.
Li, M., Liu, Y., Liu, H. (2020). Analysis of the Problem- solving strategies in computer-based dynamic assessment: The extension and application of multilevel mixture IRT model.(4), 528−540.
[李美娟, 刘玥, 刘红云. (2020). 计算机动态测验中问题解决过程策略的分析: 多水平混合IRT模型的拓展与应用.(4), 528−540.]
Liu, H., Liu, Y., & Li, M. (2018). Analysis of process data of PISA 2012 computer-based problem solving: Application of the modified multilevel mixture IRT model.1372.
Liu, Y., Xu, H., Chen, Q., & Zhan, P. (2022). The measurement of problem-solving competence using process data.,(3), 522−535.
[刘耀辉, 徐慧颖, 陈琦鹏, 詹沛达. (2022). 基于过程数据的问题解决能力测量及数据分析方法.(3), 522−535.]
Ma, W., Iaconangelo, C., & de la Torre, J. (2016). Model similarity, model selection, and attribute classification.(3), 200−217.
Man, K., Harring, J. R., & Zhan, P. (2022). Bridging models of biometric and psychometric assessment: A three-way joint modeling approach of item responses, response times and gaze fixation counts(5), 361−381.
Newell, A., & Simon, H. A. (1972).(Vol. 104, No. 9). Englewood Cliffs, NJ: Prentice-hall.
OECD. (2013).. OECD Publishing. http://dx.doi.org/10. 1787/9789264190511-en
Peng, S., Cai, Y., Wang, D., Luo, F., & Tu, D. (2022). A generalized diagnostic classification modeling framework integrating differential speediness: Advantages and illustrations in psychological and educational testing.(6), 940−959.
Rasch, G. (1960).. InProceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability: Held at the Statistical Laboratory, University of California, June 20-July 30, 1960 (Vol. 4, p. 321). University of California Press.
Rosen, Y. (2017). Assessing students in human-to-agent settings to inform collaborative problem-solving learning.(1), 36−53.
Shu, Z., Bergner, Y., Zhu, M., Hao, J., & von Davier, A. A. (2017). An item response theory analysis of problem- solving processes in scenario-based tasks.(1), 109−131.
Tang, X., Wang, Z., He, Q., Liu, J., & Ying, Z. (2020). Latent feature extraction for process data via multidimensional scaling.(2), 378−397.
Tang, X., Wang, Z., Liu, J., & Ying, Z. (2021). An exploratory analysis of the latent structure of process data via action sequence autoencoders.(1), 1−33.
van der Linden, W. J. (2006). A lognormal model for response times on test items.(2), 181−204.
van der Linden, W. J. (2007). A hierarchical framework for modeling speed and accuracy on test items.(3), 287−308.
Vista, A., Care, E., & Awwal, N. (2017). Visualising and examining sequential actions as behavioural paths that can be interpreted as markers of complex behaviours., 656−671.
Watanabe, S. (2010). Asymptotic equivalence of Bayes cross validation and widely applicable information criterion in singular learning theory.(12), 3571−3594..
Wilson, M., Gochyyev, P., & Scalise, K. (2017). Modeling data from collaborative assessments: learning in digital interactive social networks.(1), 85−102.
Xiao, Y., He, Q., Veldkamp, B., & Liu, H. (2021). Exploring latent states of problem-solving competence using hidden Markov model on process data.(5), 1232−1247.
Xiao, Y., & Liu, H. (2023). A state response measurement model for problem-solving process data., Online First.
Yuan, J., Xiao, Y., & Liu, H. (2019). Assessment of collaborative problem solving based on process stream data: A new paradigm for extracting indicators and modeling dyad data., 369.
Zhan, P., Jiao, H., & Liao, D. (2018). Cognitive diagnosis modelling incorporating item response times.(2), 262−286.
Zhan, P., Man, K., Wind, S. A., & Malone, J. (2022). Cognitive diagnosis modeling incorporating response times and fixation counts: Providing comprehensive feedback and accurate diagnosis.(6), 736−776.
Zhan, P., & Qiao, X. (2022). Diagnostic classification analysis of problem-solving competence using process data: An item expansion method.,(4), 1529−1547.
Zhan, S., Hao, J., & Davier, A. V. (2015). Analyzing process data from game/scenariobased tasks: An edit distance approach.,(1), 33−50.
Zhang, S., Wang, Z., Qi, J., Liu, J., & Ying, Z. (2022). Accurate assessment via process data.,(1), 76−97.
Zhu, M., Shu, Z., & von Davier, A. A. (2016). Using networks to visualize and analyze process data for educational assessment.(2), 190−211.
Binary modeling of action sequences in problem-solving tasks: One- and two-parameter action sequence model
FU Yanbin, CHEN Qipeng, ZHAN Peida
(School of Psychology, Zhejiang Normal University; Intelligent Laboratory of Child and Adolescent Mental Health and Crisis Intervention of Zhejiang Province; Key Laboratory of Intelligent Education Technology and Application of Zhejiang Province, Jinhua 321004, China)
Process data refers to the human-computer or human-human interaction data recorded in computerized learning and assessment systems that reflect respondents’ problem-solving processes. Among the process data, action sequences are the most typical data because they reflect how respondents solve the problem step by step. However, the non-standardized format of action sequences (i.e., different data lengths for different participants) also poses difficulties for the direct application of traditional psychometric models. Han et al. (2021) proposed the SRM by combining dynamic Bayesian networks with the nominal response model (NRM) to address the shortcomings of existing methods. Similar to the NRM, the SRM uses multinomial logistic modeling, which in turn assigns different parameters to each possible action or state transition in the task, leading to high model complexity. Given that actions or state transitions in problem-solving tasks have correct and incorrect outcomes rather than equivalence relations without quantitative order, this paper proposes two action sequence models based on binary logistic modeling with relatively low model complexity: the one- and two-parameter action sequence models (1P and 2P-ASM). Unlike the SRM, which applies the NRM migration to action sequence analysis, the 1P-ASM and 2P-ASM migrate the simpler one- and two-parameter IRT models to action sequence analysis, respectively.
An illustrated example was provided to compare the performance of SRM and two ASMs with a real-world interactive assessment item, “Tickets,” in the PISA 2012. The results mainly showed that: (1) the latent ability estimates of two ASMs and the SRM had high correlation; (2) ASMs took less computing time than that of SRM; (3) participants who are solving the problem correctly tend to continue to present the correct actions, and vice versa; and (4) compared with the fixed discrimination parameter of the SRM, the free estimated discrimination parameter of the 2P-ASM helped us to better understand the task.
A simulation study was further designed to explore the psychometric performance of the proposed model in different test scenarios. Two factors were manipulated: sample size (including 100, 200, and 500) and average problem state transition sequence length (including short and long). The SRM was used to generate the state transition sequences in the simulation study. The problem-solving task structure from the empirical study was used. The results showed that: (1) two ASMs could provide accurate parameter estimates even if they were not the data-generation model; (2) the computation time of both ASMs was lower than that of SRM, especially under the condition of a small sample size; (3) the problem-solving ability estimates of both ASMs were in high agreement with the problem-solving ability estimate of the SRM, and the agreement between 2P-ASM and SRM is relatively higher; and (4) the longer the problem state transition sequence, the better the recovery of problem-solving ability parameter for both ASMs and SRM.
Overall, the two ASMs proposed in this paper based on binary logistic modeling can achieve effective analysis of action sequences and provide almost identical estimates of participants' problem-solving ability to SRM while significantly reducing the computational time. Meanwhile, combining the results of simulation and empirical studies, we believe that the 2P-ASM has better overall performance than the 1P-ASM; however, the more parsimonious 1P-ASM is recommended when the sample size is small (e.g., 100 participants) or the task is simple (fewer operations are required to solve the problem).
process data, action sequence, problem state transition, action sequence model, item response theory
B841
2023-01-04
* 国家自然科学基金青年基金项目(31900795)资助。
詹沛达, E-mail: pdzhan@gmail.com
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:28
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
电子制作(2018年17期)2018-09-28 01:56:44
通信电源技术(2018年5期)2018-08-23 01:15:36
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
统计与决策(2017年2期)2017-03-20 15:25:22
数学物理学报(2016年5期)2016-08-24 07:38:48
系统工程与电子技术(2016年2期)2016-04-16 05:17:08
家庭百事通(2016年3期)2016-03-14 08:07:17
