
增强局部上下文监督信息的麦苗计数方法
2023-07-31 08:06申华磊麻巧迎郑国清臧贺藏
农业机械学报 2023年7期
申华磊 张 洁 刘 栋,2 麻巧迎,2 郑国清 臧贺藏
(1.河南师范大学计算机与信息工程学院, 新乡 453007; 2.河南省教育人工智能与个性化学习重点实验室, 新乡 453007;3.河南省农业科学院农业经济与信息研究所, 郑州 450002; 4.农业农村部黄淮海智慧农业技术重点实验室, 郑州 450002)
0 引言
小麦是我国重要的粮食作物,保持小麦的持续高产对维护我国粮食安全具有重要意义[1]。在小麦生长过程中,麦苗株数是制约产量的关键因素,麦苗过于稀疏或稠密极大地影响小麦产量。因此,及时准确地统计麦苗株数将为后续的出苗率估算、产量预测和籽粒品质评估等生产环节提供重要科学依据[2]。
传统的麦苗计数工作主要依赖于人工在田间进行数苗,存在经济成本高、劳动力消耗大和计数效率低等问题,并且计数结果易受主观因素影响。随着深度学习的发展,使用深度神经网络进行目标对象自动计数正成为新的研究热点。与人工数苗方法相比,使用深度神经网络对采集到的麦苗图像进行分析,进而自动检测麦苗株数,可打破时空限制和对农业专家的依赖,提高劳动效率。
已有学者使用深度学习技术对细胞[3]、人群[4-6]、猪只[7-9]和麦穗[10-12]等目标对象进行计数。这些方法可被分为两类:基于目标检测的方法和基于密度图回归的方法。基于目标检测的方法主要使用YOLO、SSD和Faster R-CNN等检测器对图像中的目标对象进行检测[13-15],之后得到目标对象的数目。这类方法不仅可以提供目标对象的计数结果,还可以通过边框提供目标对象的位置信息。然而,这类方法在训练阶段需要标注大量的目标对象边框作为标签[16];麦苗细小且相互之间存在遮挡、重叠和扭曲等现象,使得麦苗边框标注费时费力。同时,根据麦苗点标注结果自动生成伪框图的方法容易出错,并需要手动进行后处理。基于密度图回归的方法[17-21]对目标对象使用点标注生成密度图,以作为模型的学习目标,之后对模型预测出的密度图求积分得到目标对象的计数值。目前,具有代表性的方法有CSRNet[22]、CANet[23]、SCAR[24]、BL[25]和DM-Count[26]等。CSRNet使用空洞卷积以提高拥挤场景下的计数精度。CANet组合多个不同大小感受野获得的特征以自适应地对不同尺度的上下文信息进行编码。SCAR引入注意力机制以获取像素和人群上下文之间的关联信息。BL使用贝叶斯损失函数,从点标注构建密度贡献概率模型以弥补密度图的不足。DM-Count将分布匹配用于计数任务,并设计了新的优化策略以度量真实值与预测值之间的相似性。总体而言,这类方法的麦苗标注成本不高,但不能标识出麦苗的准确位置。这不利于种植规划和良田培育等下游任务;且易受透视图失真的影响,导致模型的鲁棒性不强。
SONG等[27]提出的P2PNet为目标对象计数提供了新的解决方案。P2PNet直接将点标注结果作为学习目标,之后预测出所有目标对象的点坐标,从而得到计数结果。与上述两类计数方法相比,P2PNet不需要对训练样本中的目标对象进行框标注,也不需要通过点标注生成伪密度图或伪框图间接得到学习目标。这不仅显著降低了训练样本的标注成本,还减少了间接生成学习目标导致的模型计数性能下降的风险。并且,P2PNet可明确标识出目标对象的位置,更能满足下游任务的应用需求。由以上分析可知,P2PNet更适于复杂场景下的麦苗计数。
但是,P2PNet直接用于麦苗计数的性能较差。一方面,麦田中的枯叶、不同光照角度导致麦苗图像出现不同方向和尺寸的阴影,为计数模型带来干扰噪声,严重影响P2PNet的性能。另一方面,麦田中土块对麦苗的遮挡以及麦苗生长稠密时叶片间的重叠,导致P2PNet的误判。
农业专家对麦苗人工计数时,对于不易判别的困难样本,通常根据麦苗的局部根茎信息、叶片发育的全局信息判断麦苗为一株还是多株。受此启发,本文对P2PNet进行改进,提出增强局部上下文监督信息的麦苗计数模型P2P_Seg。首先,引入局部分割分支改进网络结构,以增强麦苗的局部上下文监督信息,引导网络的注意力到麦苗根茎部区域,并减弱上述杂物、光照和土块等带来的噪声。之后,设计逐元素点乘机制融合分割分支提取到的麦苗局部根茎信息与基础网络提取到的叶片发育全局信息,以模仿农业专家结合麦苗的根茎信息和叶片发育的全局信息应对遮挡和重叠造成的计数困难。最后,将融合后的特征信息通过点回归分支和分类分支以预测麦苗的位置与株数。
1 研究区概况与数据
1.1 研究区概况
实验地位于河南省现代农业研究开发基地的小麦实验区,地处北纬35°00′28″,东经113°41′48″,海拔为97 m。实验采用完全随机区组设计,播种日期为2021年10月15日,共有400个小区,每个小区面积为36 m2。
1.2 研究数据
研究数据主要通过数据采集、预处理、图像标注和数据集划分4个步骤获取。研究数据的主要制作流程如图1所示。
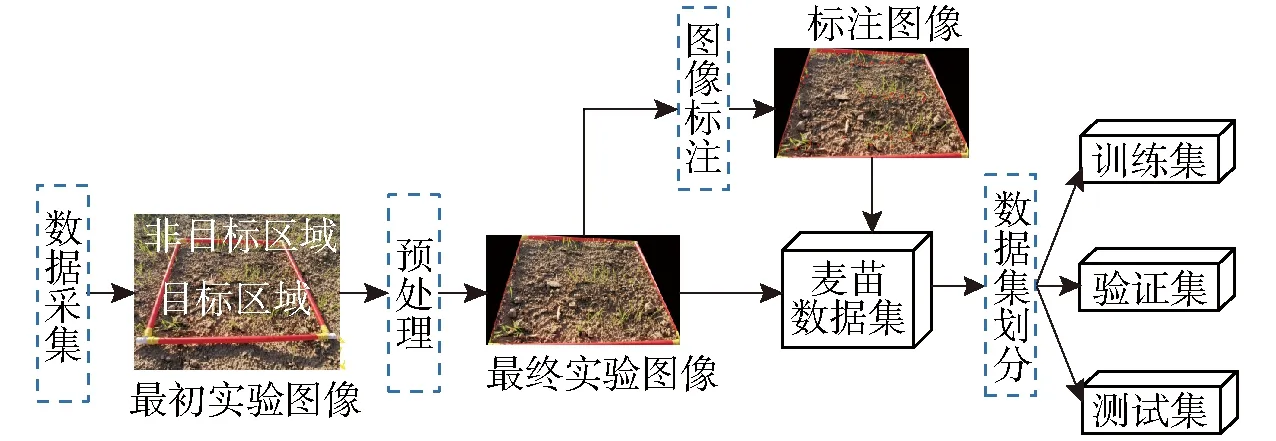
图1 研究数据制作流程图
1.2.1数据采集
使用型号为HONOR 20 PRO的智能手机采集数据,相机分辨率为4 800万像素,传感器类型为BSI CMOS,光圈f/2.2。拍摄时间为2021年11月,小麦正处于苗期。主要对使用1 m×1 m红色矩形框标出的目标计数区域进行采样,共采集到317幅麦苗图像,分辨率为4 000像素×3 000像素。剔除画质模糊或存在严重遮挡的图像,共筛选出295幅图像作为最初实验图像。
1.2.2数据预处理
数据预处理的目的是对红色矩形框外的非目标计数区域进行黑色填充和冗余剔除,其流程如图2所示。为避免非目标区域麦苗对计数结果的影响,使用预处理工具对非目标区域进行黑色填充。为避免后续用于数据增强的随机裁剪操作可能得到大面积的非目标计数区域,从而干扰目标区域的计数结果,对非目标区域进行最大程度的冗余剔除。经过以上两个步骤,得到本文的最终实验图像。

图2 麦苗图像预处理步骤
1.2.3图像标注
麦苗形态细小且易出现遮挡、重叠等现象,这使得基于框标注的方法非常困难,因此采用成本较低、方便快捷的点标注方法。一个点标注表示对应麦苗在图像中的点坐标。采用WANG等[28]开发的标注工具进行数据集标注。该标注工具不仅能够对图像进行分块标记,而且可对分块区域进行随机缩放。对于麦苗图像中较为稠密、遮挡和重叠较为严重的区域,使用该工具对其放大再进行标注,有效地提高了标注速度与质量。标注区域为特征相对明显的麦苗根茎部,便于后续网络的训练。
使用上述方法对295幅图像进行点标注,共标注32 237株麦苗。其中,单幅图像总标记点的最大值为321,最小值为18;平均每幅麦苗图像约标记109株麦苗。不同密度等级的麦苗标注图像如图3所示。

图3 不同密度等级的麦苗标注图像
1.2.4数据集划分
经过标注可得到295幅最终实验图像及对应的标注点,它们共同构成麦苗数据集。接着,按照比例6∶1∶3将麦苗数据集随机划分为训练集、验证集和测试集。其中训练集、验证集和测试集分别含有177、29、89幅麦苗图像。麦苗数据集划分结果如表1所示。

表1 麦苗数据集划分结果
2 研究方法
2.1 P2PNet
P2PNet为目标计数提供了新的解决方案,是一个基于点标注的计数模型,以点的形式标注出目标对象的位置坐标,然后直接把标注结果作为模型的学习目标。P2PNet以VGG16_bn[29]为骨干网络,提取目标对象的全局特征;之后将全局特征同时送入点回归分支和分类分支以分别生成目标对象的候选点和每个候选点对应的置信度分数;最后根据分类结果从候选点中筛选出目标对象的位置坐标。位置坐标的总数即为目标对象的计数结果。
2.2 P2P_Seg整体框架
为减少光照、遮挡和重叠等因素对麦苗计数的影响,本文对P2PNet进行改进,引入麦苗局部分割分支以增强麦苗局部上下文监督信息,提出增强局部上下文监督信息的麦苗计数模型P2P_Seg。其网络架构如图4所示。首先,基础网络提取麦苗图像的全局特征,得到全局特征图F0。其次,麦苗局部分割分支生成局部特征图F1,以提取麦苗局部上下文监督信息。然后,特征融合模块的逐元素点乘机制融合麦苗的全局信息与局部上下文信息,生成融合后的特征图F2。最后,通过点回归分支与分类分支分别预测出麦苗的候选点位置坐标及其对应的置信度分数。
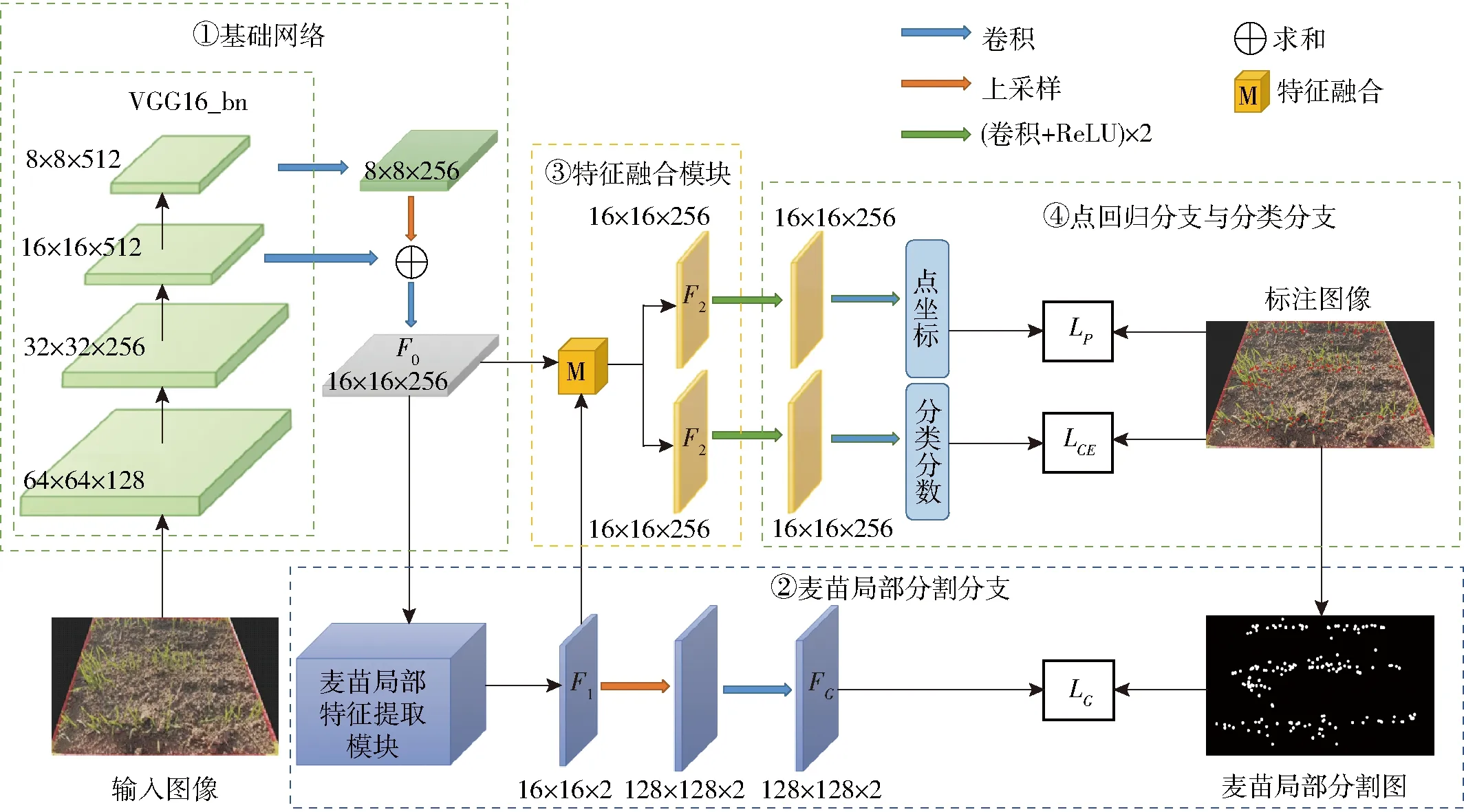
图4 P2P_Seg模型整体框架
上述基础网络、点回归分支与分类分支继承自P2PNet。与P2PNet不同,为融合麦苗的局部根茎信息和全局叶片发育信息,以对抗光照、遮挡和重叠等因素的干扰,P2P_Seg从基础网络得到全局特征图F0后,并未将其直接送入点回归分支和分类分支,而是引入麦苗局部分割分支以提取麦苗局部特征图F1。将F0与F1融合后得到的特征图F2作为点回归分支与分类分支的输入,预测候选点位置坐标及其对应的置信度分数。
2.3 麦苗局部分割分支
麦苗局部分割分支旨在提取麦苗根茎部的局部上下文监督信息,具有2个用途:①集中模型的注意力到点标注的麦苗根茎部目标区域,忽略光照导致的阴影和田间枯叶等噪声的干扰。②当麦苗标注点位置被土块等杂物遮挡时,可以提供更多的上下文参考信息,提高模型的计数精度。麦苗局部分割分支包含的关键技术有麦苗局部分割图生成和麦苗局部特征提取模块设计。
2.3.1麦苗局部分割图
麦苗局部分割图是由点标注结果生成的体现麦苗局部上下文监督信息的图像。该分割图是麦苗局部分割分支的学习目标。麦苗局部分割分支使得计数网络在将点标注作为学习对象的基础上,又同时利用麦苗局部分割图提取出麦苗局部上下文信息。这对计数网络起到更强的监督作用。
麦苗局部分割图是二值图像,图像上每个像素的值为0或1。值为0的区域为非麦苗根茎部目标区域;值为1的区域为本文所关注的麦苗根茎部目标区域,即局部上下文监督信息区域。给定一幅带有N个点标注的麦苗图像,点标注的位置在麦苗的根茎处,用P={pi|i∈{1,2,…,N}}表示该图像内所有麦苗的点标注坐标,其中pi=(xi,yi)表示第i株麦苗的坐标。分别生成N个以pi为圆心、σ为半径的圆域;圆域内的像素值为1、圆域外的像素值为0,从而得到麦苗局部分割图G。圆域半径σ决定了每株麦苗的根茎部目标区域的大小。SHI等[30]通过将图像分割成局部区域块,提出了核估计器σpi,以估计目标对象的尺寸。原始的核估计器σpi未考虑麦苗在整体图像上的分布,可能会得到过大或过小的麦苗根茎部目标区域,如图5a所示。过大的麦苗根茎部目标区域会引入额外的噪声,过小的麦苗根茎部目标区域不能充分表示上下文信息。因此,本文在原始核估计器σpi的基础上,考虑麦苗的整体分布,对所有点标注对应的核估计器σpi求平均,得到了更适合估计麦苗根茎部目标区域大小的圆域半径σ,从而得到如图5b所示的麦苗分割图。上述麦苗局部分割图G和圆域半径σ的生成过程为
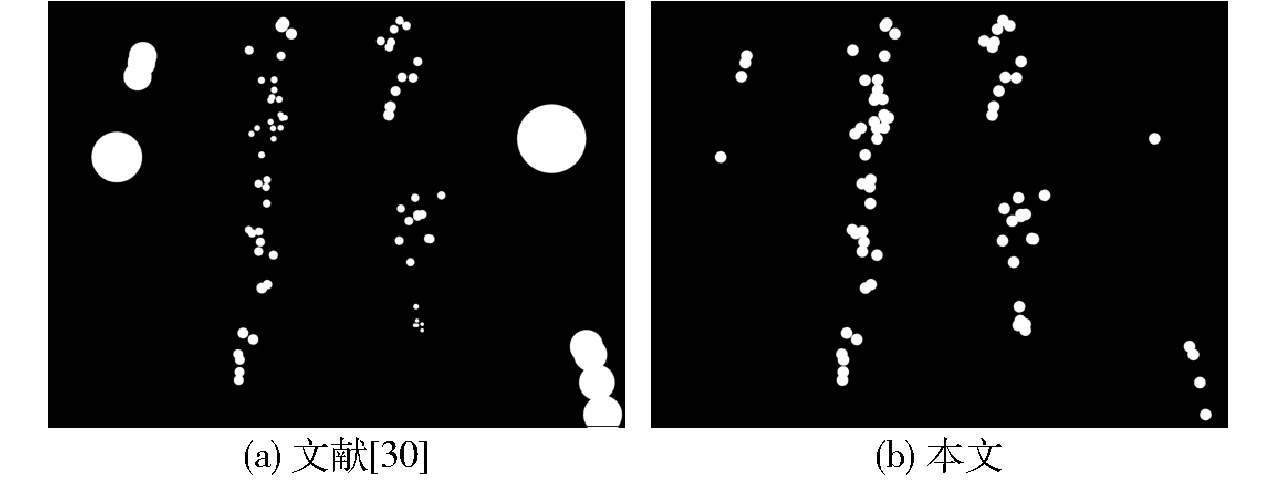
图5 不同方法生成麦苗的局部分割图
(1)
(2)
式中p——麦苗局部分割图中的像素位置
pi——第i株麦苗的坐标
‖p-pi‖——p与pi间的欧氏距离
2.3.2麦苗局部特征提取模块
麦苗局部特征提取模块是麦苗局部分割分支的重要组成部分,旨在生成局部特征图F1。本文设计的麦苗局部特征提取模块如图6所示,主要由降维卷积单元和卷积层组成。

图6 局部特征提取模块
降维卷积单元的作用是在不改变输入特征图尺寸的前提下将其通道数减半,由连续2个3×3卷积层与ReLU激活函数交替组成。其中,第1个3×3卷积层将输入特征图的通道数减半;第2个3×3卷积层继续提取深层特征,不改变特征图的尺寸。为了提高网络模型的非线性表达能力,每层卷积之后采用ReLU函数进行非线性激活。同时,在两个卷积层之间使用残差连接以对抗梯度消失。
麦苗局部特征提取模块的输入为16×16×256的全局特征图F0。首先,F0经过连续3次的降维卷积单元,其尺寸依次变为16×16×128、16×16×64、16×16×32。接着,保持F0的尺寸不变,使用3×3卷积层将其通道数变为2,分别对应麦苗根茎部和非麦苗根茎部的特征图。这两个特征图拼接在一起,得到尺寸为16×16×2的局部特征图F1。F1表征麦苗根茎部的高层语义信息,也是本文强调的麦苗局部上下文监督信息。
局部特征图F1的生成过程为
F1=f1(f(F0))
(3)
式中f(·)——连续3次的降维卷积单元操作
f1(·)——卷积函数
预测分割图FG的生成过程为
FG=f1(f2(F1))
(4)
式中f2(·)——上采样函数
如图4所示,局部特征图F1的作用有两个:F1用来与全局特征图F0进行融合,进而实现麦苗局部上下文监督信息与全局信息的融合;F1依次经过8倍最近邻插值法上采样、3×3卷积层生成预测分割图FG,从而在网络训练阶段实现对麦苗局部分割分支的优化。上采样使得预测分割图FG的尺寸与麦苗局部分割图的尺寸保持一致;3×3卷积层平滑上采样产生的噪声,以得到数学性质更稳定的特征表达。
2.4 特征融合模块
本文设计的特征融合模块如图7所示。首先,将尺寸为16×16×2的局部特征图F1送入一个softmax层,得到两个尺寸为16×16的张量。每个张量的元素值被归一化到[0,1],表示对应每个像素被网络判定为麦苗根茎部和非根茎部两个类别的概率。其次,对表征局部上下文监督信息的麦苗根茎部特征张量执行repeat操作、复制256次,得到尺寸为16×16×256的新特征图。最后,将新特征图与全局特征图F0逐元素点乘,得到融合后的特征图F2。F2融合了麦苗的局部根茎信息与全局特征信息,进一步增强网络对麦苗的识别能力,从而有效提高麦苗计数的准确率。
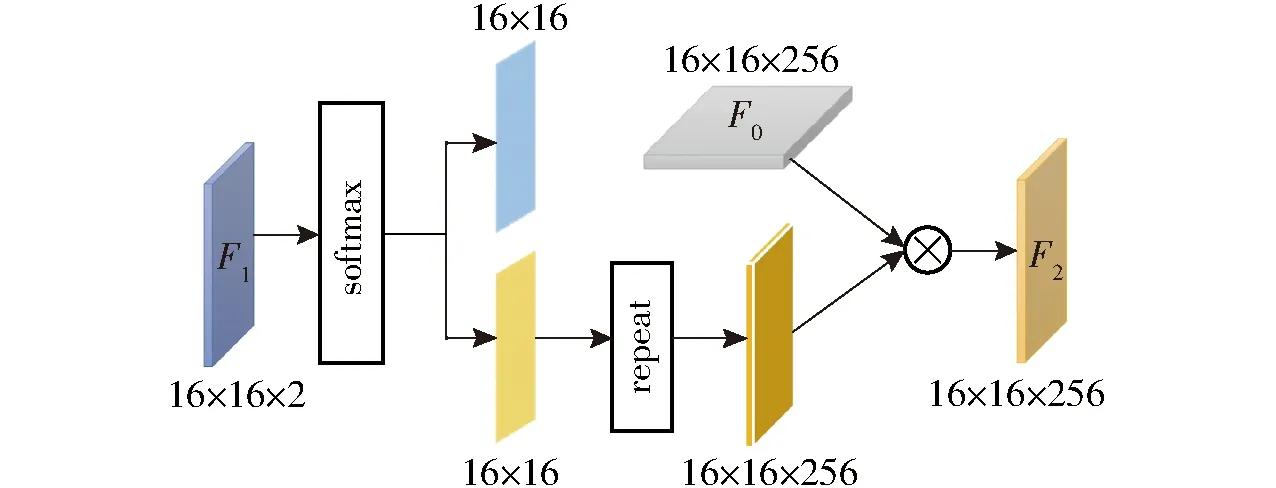
图7 特征融合模块
2.5 损失函数
如图4所示,为了更充分地训练P2P_Seg,分别对点回归分支、分类分支和麦苗局部分割分支设计了LP、LCE、LG损失函数。
点回归分支预测出M个候选点坐标,分类分支生成M个对应的置信度分数。在训练阶段,首先使用SONG等[27]提出的一对一匹配策略对网络生成的候选点坐标与标注点坐标进行一对一匹配。与标注点坐标匹配成功的N个候选点坐标即为预测的麦苗位置坐标。它们对应的置信度分数标签为1;剩余候选点坐标被分类为背景点,这些背景点对应的置信度分数标签为0。这N个麦苗预测坐标与真实标注点坐标之间的距离越小越好,因此使用欧氏距离优化点回归分支。分类分支则使用交叉熵损失函数(Cross entropy loss function,CE)进行优化。点回归分支的损失函数LP和分类分支的损失函数LCE分别表示为
(5)
(6)
y——类别标签,取0或1
分割分支生成的预测分割图FG是像素级二分类结果。为缓解前景类与背景类之间存在的样本不平衡问题,减少对计数精度的影响,本文引入SHI等[30]提出的逐像素加权焦点损失LG,即
(7)

(8)
式中w——权重
l——通道对应的索引值,取0或1
G(l)——标签分割图中上标为l的通道形成的张量

f3(·)——对张量的所有元素值求算术平均函数
γ——超参数,根据焦点损失(focal loss)[31]的推荐设置为2
f4(·)——对张量的所有元素值求和函数
组合上述点回归分支、分类分支和麦苗局部分割分支的损失函数,得到总损失函数L为
L=LCE+λ1LP+λ2LG
(9)
式中λ1——超参数,取0.002
λ2——超参数,取0.005
3 实验与结果分析
3.1 实验设置
实验使用的计算机配置为Intel(R)Core(TM)i7-10600 CPU@2.90 GHz;GPU为NVIDIA GeForce RTX3090,显存容量为24 GB。实验使用PyTorch作为深度学习框架,设置训练批次为8、训练轮数为1 000、学习率为0.000 1,采用Adam算法进行优化。基础网络在ImageNet上进行了预训练,其训练学习率设置为0.000 01。采用随机裁剪和随机旋转对训练样本进行数据增强,每幅图像被随机裁剪为4份,每份尺寸为128像素×128像素。随后,对裁剪后的图像进行概率为0.5的随机旋转。
3.2 评价指标
使用平均绝对误差(Mean absolute error, MAE)和均方根误差(Root mean square error, RMSE)评价模型的性能。MAE用来衡量网络的计数准确率;其值越小,表明麦苗株数的预测值越接近真实值。RMSE用来衡量网络的稳定性;其值越小,表示网络的稳定性越强、鲁棒性越好。
3.3 麦苗根茎部区域的影响
为评估不同麦苗根茎部区域对麦苗计数结果的影响,对比本文提出的圆域半径σ生成方法和SHI等[30]提出的核估计器σpi生成方法所得到的不同麦苗局部分割图对P2P_Seg计数性能的影响。实验结果如表2所示。

表2 不同麦苗局部分割图对P2P_Seg的影响
由表2可知,使用本文的麦苗局部分割图作为麦苗局部分割分支的学习目标时,可得到更准确的计数效果。这说明本文提出的圆域半径σ生成方法能得到尺寸更为合理的麦苗根茎部目标区域,从而使得P2P_Seg的计数性能更好。
3.4 与其他方法对比
为进一步验证P2P_Seg的性能,在自建麦苗数据集上与CSRNet、CANet、SCAR、BL、DM-Count和P2PNet进行对比实验。其中,前5种方法为基于密度图的计数方法,P2PNet为基于点标注的计数方法。如表3所示,P2P_Seg的MAE为5.86,RMSE为7.68,与P2PNet相比分别降低0.74、1.78。同时,与其他计数方法相比,P2P_Seg的两种计数误差亦最小。这说明增强局部上下文监督信息可以提高P2P_Seg对麦苗的识别能力,从而显著提高计数精度。

表3 在麦苗数据集上不同方法实验结果对比
图8展示了上述网络在部分测试样例上的可视化结果。图8a为点标注的结果,直接作为P2PNet与P2P_Seg的真实值。图8b为由点标注生成的密度图像,作为基于密度图计数方法的真实值。图8c~8i分别为CSRNet、CANet、SCAR、BL、DM-Count、P2PNet、P2P_Seg的计数结果,通过密度图进行可视化展示;密度图的颜色越深,说明麦苗密度越大。这些基于密度图方法的计数准确率不高,生成的密度图不能直接标识出麦苗的位置,无法为下游任务提供更多的支撑信息。最后两列分别为P2PNet和P2P_Seg的预测结果,这些结果均为更加直观的麦苗坐标。由于P2P_Seg引入了局部分割分支以增强局部上下文监督信息,在对受遮挡、重叠和光照等因素影响的麦苗图像计数时,其预测值更接近真实值,计数误差更小。从顶部第1行到底部第6行,图像中麦苗逐渐由稀疏变得稠密,并且图像中存在枯叶、光照导致的阴影等噪声,给现有的计数网络识别带来了不小的挑战。但是,本文提出的P2P_Seg通过增强局部上下文监督信息,将注意力集中在麦苗根茎部,使其尽可能忽略其他噪声,从而显著提高了麦苗计数的准确率。同时,在处理不同稠密程度的麦苗图像时,P2P_Seg皆取得最好的计数结果,表现出更好的泛化性能。
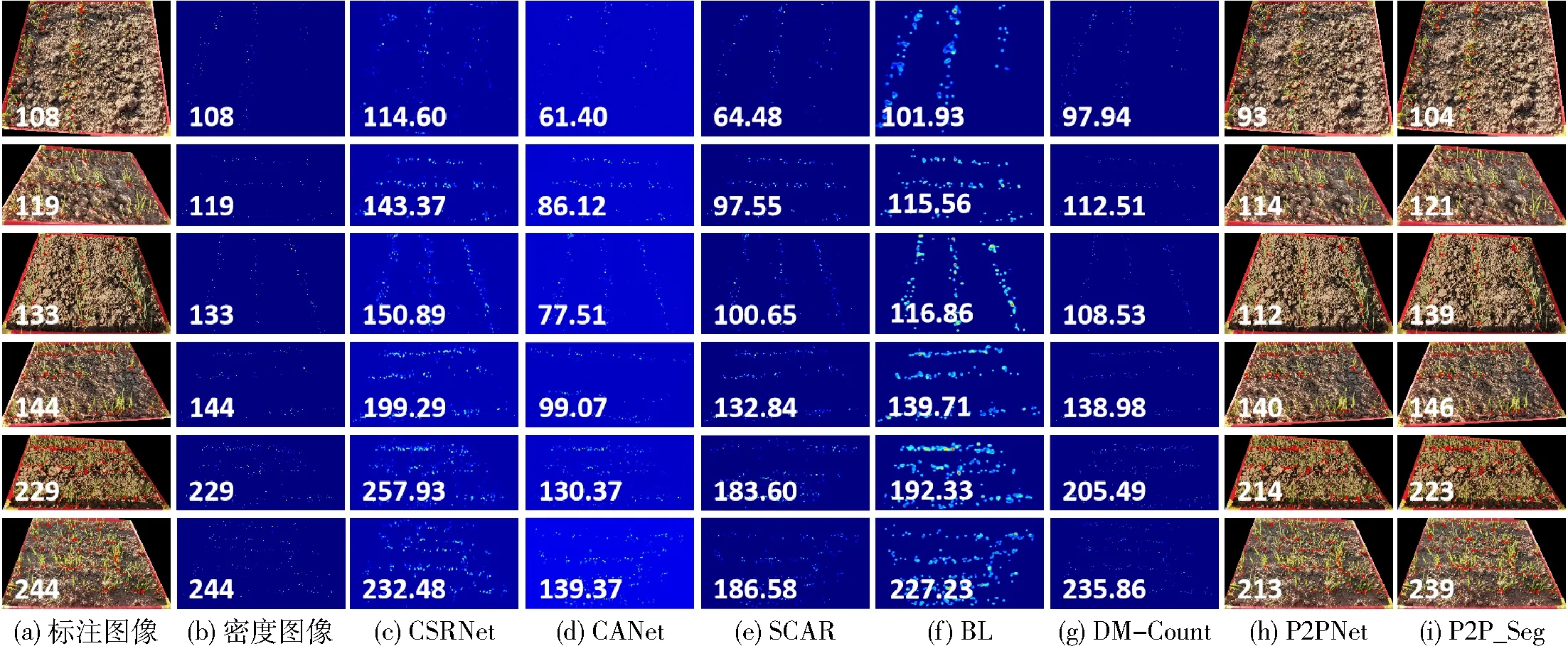
图8 不同方法计数结果可视化图
3.5 应用测试分析
为测试本文提出的P2P_Seg在实际大田环境下开展麦苗自动计数的性能,将训练好的模型在实际获取的89幅大田图像上进行麦苗计数。表 4列出了部分大田图像上的计数结果。这些图像按照麦苗密度等级分为3类:密度偏小、密度中等和密度偏大。其中,图像1~5为密度偏小麦苗图像,图像6~10为密度中等麦苗图像,图像11~15为密度偏大麦苗图像。从表4中可以看出,P2P_Seg在所有密度等级大田麦苗图像上都取得了最好的计数结果。
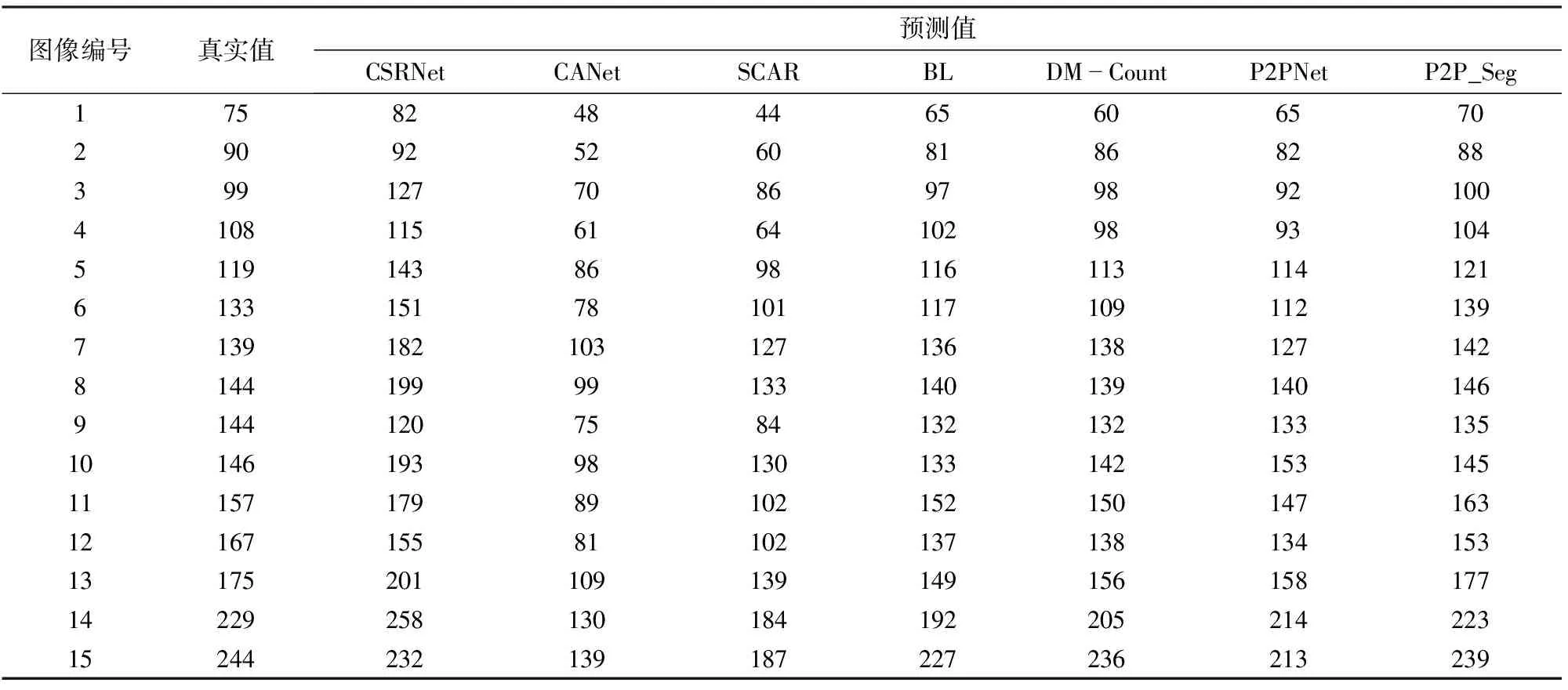
表4 部分大田图像上不同方法麦苗计数结果对比
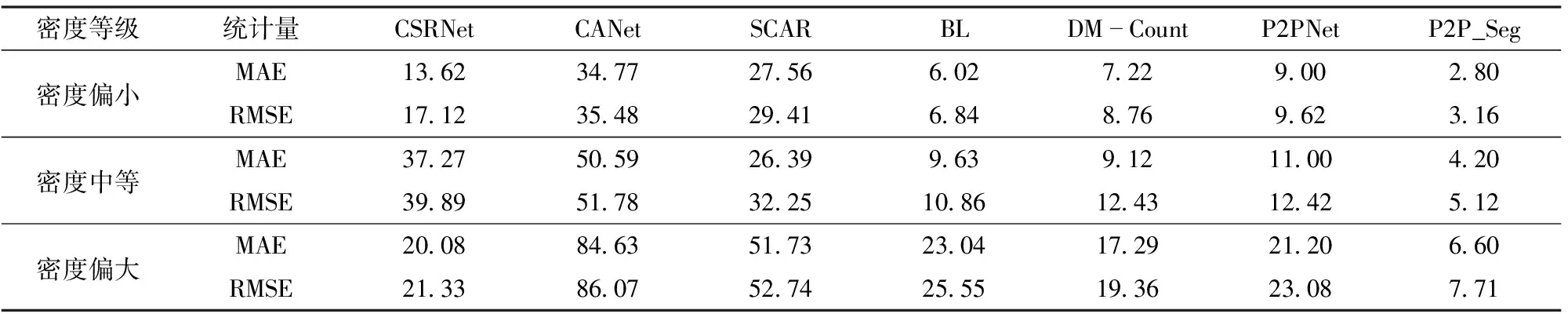
表5 不同密度等级麦苗图像计数结果对比
表 5使用MAE和RMSE对这些计数结果进行统计对比。在密度偏小大田麦苗图像上,P2P_Seg的MAE和RMSE分别为2.80和3.16,在所有方法中最好。在密度中等大田麦苗图像上,P2P_Seg的MAE和RMSE分别为4.20和5.12,在所有方法中最好。在密度偏大大田麦苗图像上,P2P_Seg的MAE和RMSE分别为6.60和7.71,在所有方法中最好。
3.6 误计数和漏计数情况分析
受成像角度、麦苗密度和杂物遮挡等因素的影响,P2P_Seg的计数结果存在误计数和漏计数的情况。图9展示了这些情况,其中误计数区域用矩形标识、漏计数区域用椭圆标识。
误计数的主要原因包括成像角度不佳、麦苗相互遮挡和杂物遮挡等。如图9a所示,因为成像方向与麦苗所在行平行,出现较严重的麦苗相互遮挡,从而出现误计数(图9a的区域①、②),尽管该区域的麦苗密度偏小。随着麦苗稠密程度增加,麦苗相互遮挡变得严重,这会导致误计数,如图9b的区域⑤和图9c的区域⑤所示。此外,杂物遮挡致使麦苗根茎部未完全展露也会出现误计数(图9d的区域④)。
漏计数的主要原因包括麦苗相互遮挡、杂物遮挡和苗株细弱等。麦苗相互遮挡导致的漏计数现象较为普遍,如图9b的区域①、②、⑥、⑦、⑧和图9c的区域①、②、③、④、⑥所示。同时,杂物遮挡导致的麦苗根茎部未完全展现(图9d的区域①)或发育迟缓导致的苗株细弱(图9d的区域③)也会引起漏计数。
4 结论
(1)针对光照、遮挡和重叠等因素导致的现有计数模型性能受限问题,提出增强局部上下文监督信息的麦苗计数模型P2P_Seg。该模型在P2PNet的基础上引入麦苗局部分割分支以获取更多的麦苗局部上下文监督信息,并使用逐元素点乘机制融合局部上下文监督信息与基础网络提取的全局信息。对网络结构的改进和专门设计的特征融合策略提高了模型的特征提取能力,增强了模型对光照、遮挡和重叠等因素的对抗能力,提高了模型的鲁棒性,显著减少了模型对麦苗的误计和漏计。
(2)在自建麦苗数据集上,与其他主流计数方法进行了对比实验。结果表明,P2P_Seg的MAE为5.86,RMSE为7.68;与P2PNet相比,分别降低0.74和1.78。同时,与其他计数方法相比,P2P_Seg的两种计数误差亦最小,计数性能最好。
(3)在实际大田环境下进行的麦苗自动计数测试表明,P2P_Seg在密度偏小、密度中等和密度偏大3种等级的大田麦苗图像上都取得了最好的计数结果。P2P_Seg能够更准确地预测出麦苗的株数,可有效缓解传统人工数苗费时费力的问题。同时,P2P_Seg还能预测出麦苗的位置,为种植规划和良田培育等下游任务提供有效支撑信息,更有助于实际农业生产。
猜你喜欢
中成药(2021年5期)2021-07-21
今日农业(2020年13期)2020-08-24
学生天地(2019年28期)2019-08-25
幼儿100(2019年34期)2019-02-11
数学物理学报(2018年1期)2018-03-26
青年歌声(2018年11期)2018-01-23
中成药(2017年3期)2017-05-17
戏剧之家(2017年1期)2017-02-05
天然产物研究与开发(2014年3期)2014-04-27
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
