
基于融合预处理的掺假咖啡太赫兹光谱识别
2023-07-27 02:31:30张傲林李绅邹颖芳王继芬张震孙一健
食品与发酵工业 2023年14期
张傲林,李绅,邹颖芳,王继芬*,张震,孙一健
1(中国人民公安大学 侦查学院,北京,100038)2(武汉体育学院 运动训练学院,湖北 武汉,430079)
咖啡作为一种常见的饮品,在国内外具有广阔的消费市场。近年来掺假咖啡在市面上流行,以星空咖啡为例,掺假咖啡的成分除咖啡因、蛋白质、矿物质等主要成分还包含西布曲明、苯二氮卓等非法药物。由于其组合药理学机制为食欲抑制、饱腹感以及可能诱导产热[1-3],广泛流售于减肥人群中。微商、电商、物流寄递等是其常见的销售流通渠道,为使服用者减肥效果明显,不法分子通常在咖啡中大量掺入此类食欲抑制类精神药物,长期食用此类咖啡严重危害消费者的身体健康。由于售卖数量庞大,包装形式多样,检测手法繁冗,针对国内消费市场形式,有必要建立一种快速无损检验方法来开展寄递渠道大量咖啡中掺假非法添加成分的工作。
对于涉及咖啡及其添加成分的检测,现有研究中的检验方法主要是分子光谱技术和液相色谱等方法,邵金良等[4]选择高效液相色谱-紫外双波长方法(high performance liquid chromatography-double UV wavelengths,HPLC-DUVW)同时测定咖啡制品中的生物碱成分以及多酚类化合物。陈华舟等[5]分别采用紫外(ultraviolet,UV)和傅里叶红外(Fourier-transform infrared spectroscopy,FTIR)光谱法测定咖啡因和有机物的含量,在FTIR的指纹区域的特征吸收峰反映出咖啡中的无机物和多糖物质。陈秀明等[6]使用近红外光谱并建立Adulterant Screen算法对咖啡中掺假物大麦等进行了识别。近年来,模式识别方法在食品的检测中逐渐成熟,王艳艳等[7]建立了一种基于小波变换的反向传播神经网络,对不同品牌咖啡的红外光谱数据实现了100%分类。色谱检验方法预处理工序复杂,检测效率低,对样本具有破坏性;传统分子光谱的穿透性较差,对样本的检测受环境噪声干扰较大,上述方法不适用于大批量样本的快速、无损检测,无法满足打击食品犯罪的实际需求。
太赫兹时域光谱(THz time-domain spectroscopy,THz-TDS)是一种新型光谱技术,由于0.1~10 THz电磁频域区间具有量子能量低、穿透性能优异且许多生物大分子的振动和旋转频率都处于THz波段,所以利用THz-TDS可以获得丰富的生物及其材料信息,且不会使检材由于量子作用产生爆炸[8-10]。此外,THz辐射能以很小的衰减穿透如碳板、布料、塑料等常见物质,因此THz-TDS非常适合用于存在外包装的检材无损检测。杨少壮等[11]选择不同肉类在0.6~1.4 THz波段的太赫兹光谱进行主成分分析-支持向量机(principal component analysis-support vector machine,PCA-SVM)建模。结果表明,吸收系数等光谱参数的建模分类准确率均能达100%,可以实现对不同肉类的无损检测。王倩等[12]为实现不同品种的大米鉴别,利用标准差和区间偏最小二乘方法提取0.53~1.21 THz波段的太赫兹吸收光谱信息进行建模,对比多种模型发现决策树模型分类准确率为95%,能够为食品无损检测提供一种新思路。目前在国内在使用THz-TDS检测咖啡方面的研究报道较少[13-14],基于维护涉及咖啡类食品安全的需要,本实验收集7种不同品牌的70份掺假有西布曲明成分的咖啡样本,通过THz-TDS获取光谱数据,比较导数(derivative)、巴特沃斯滤波器(Butterworth filter)、特征融合(fusion feature)3种不同类型预处理的建模效果,建模方法选择随机森林(random forest,RF)、支持向量机(support vector machine,SVM)、贝叶斯判别分析(bayes discriminant analysis,BDA),以确定最优的检测模型,并进一步对产地进行识别。
1 实验方法
1.1 实验样本
实验中70份减肥咖啡样本来自于海关实际案件中缴获,根据品牌可以划分为星空咖啡、真业主代、微韵咖啡、我叫小几、赵氏思思小乐。其中星空咖啡按来源地划分可以分为星空联创、星空专柜、星空总店,为便于实验将7类样本按C1、C2、C3、C4、C5、C6、C7依次编号,具体见表1。

表1 实验样本及信息Table 1 Experimental samples and information
1.2 实验仪器
THz-TDS系统的原理是基于相干探测技术的太赫兹产生与探测系统,可以同时提取太赫兹脉冲的振幅信息、相位信息,通过对时间波形傅立叶变换的处理,能直接得到样品的吸收系数。本实验选用QT-TS2000型号太赫兹时域光谱系统(青岛青源峰达太赫兹科技有限公司)对样本进行快速分析,具体仪器参数见表2。

表2 仪器参数Table 2 Instrument parameter
1.3 建模原理
1.3.1 随机森林
RF是基于Bagging框架和决策树参数的集成学习算法,其最大特点可以处理高维特征的输入样本,并且能够评估重要特征[15-16]。集成的树集合是通过替换训练样本的子集进行创建的,通过选择合适样本特征进行选择划分,可以进行交叉验证。其主要参数如下:决策树最大深度(max depth),内部节点再划分所需最小样本数(min samples split),叶子节点最少样本数(min samples leaf),最大特征数(max features),袋外(out-of-bag, OOB)误差。其中OOB被主要用于模型整体误差评估。
在统计学上其参数优化组合取决于决策树最大深度(max depth) , 内部节点再划分所需最小样本数(min samples split), 叶子节点最少样本数(min samples leaf), 最大特征数(max features)。由于RF模型可以对数据进行自动降维,故当数据维度消减到一定时通过对参数的调整不再能够影响模型变化。
1.3.2 支持向量机
SVM算法是传统监督学习中性能较为优异的分类算法[17-18],主要用于解决线性不可分的数据集的分类问题,被定义为特征空间上间隔最大的线性分类器模型。主要通过RBF核函数、Sigmoid核函数、线性核函数、Polynomial核函数等对向量进行投影划分最优超平面。本实验选用多分类问题效果优异的RBF核函数,其表达式和超平面表达式如公式(1)、公式(2)所示:
(1)
ωx+b=0
(2)
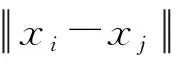
1.3.3 贝叶斯判别分析
BDA在统计学上可以根据全集样本的先验概率得到概率密度函数[19],然后利用贝叶斯判别公式[公式(3)]计算不同样本判定为不同子域的概率即后验概率P(Ci|x),最后根据后验概率的大小进行判别,得到整体分类准确率。
(3)
式中:P(x)为x样本发生的概率。
2 结果与分析
2.1 原始数据建模
在实验中,首先对未经预处理的原始数据进行建模研究,选择RF和SVM模型对70份咖啡样本的光谱数据进行分类研究,由图1-a和图1-b中结果可知,RF模型最优参数分类准确率为79.8%,SVM模型最优参数分类准确率为90.8%。
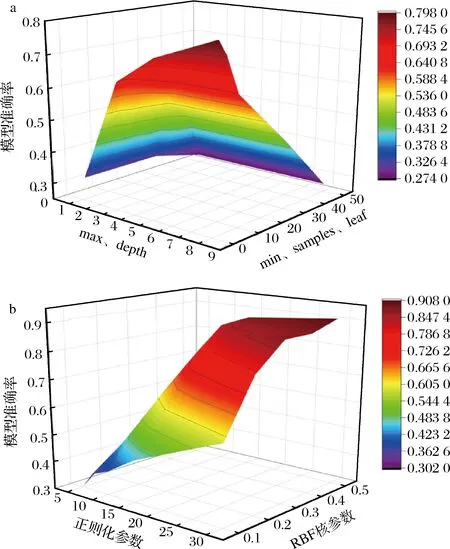
a-RF;b-SVM图1 RF、SVM参数影响分类准确率Fig.1 RF and SVM parameters affect classification accuracy
RF模型作为集成学习算法,在模型中可以通过树子集进行交叉验证提高。通过输入70组样本光谱特征数据进行建模,结合交叉验证能够得出RF模型对此类咖啡的分类结果。如图1-a所示,实验中在max depth≤8,min samples leaf≤20的范围内,通过调节参数可以发现减肥咖啡的分类准确率在27.5%~79.7%呈离散型变化。当控制最大节点数=10 000,max depth=8时,随min samples leaf不断减小,模型分类准确率逐渐上升,当min samples leaf=2时准确率不再变化达最高79.7%。
在监督学习算法中SVM模型的“鲁棒性”较为优异,可以根据核函数的调整适应不同的分类问题。进而在不同的分类中,通过相应核函数构建最优超平面可以达到最佳训练效果。本实验选择适合用于多分类问题的RBF核SVM,回归精度设置为0.1,通过调整规则化参数R和RBFγ对模型进行优化,当R在5~30区间变化且RBFγ在0.1~0.5区间变化时准确率明显提升,当R=30,RBFγ=0.5时达到最高分类准确率90.8%。
BDA模型建模首先计算函数的最大后验概率,建立6组BDA判别函数对样本进行逐一分类。通过选择Sig值最明显的3个函数BDA1、BDA2、BDA3建立三维方向上的特征,取BDA模型计算判别得分作为方向上的变量,建立样本三维空间分布图。图2中各类品牌咖啡样本在空间中的聚敛程度不一,部分品牌的样本聚敛较为分散,容易与其他样本混淆,总体分类效果较差。

图2 BDA模型样本空间分布图Fig.2 Spatial distribution of BDA model samples
2.2 预处理方法比较
在上述3类模型建模效果不理想的基础上,进一步选择预处理方法进行比较,对3种模型进行优化,并确定最优预处理建模模型。
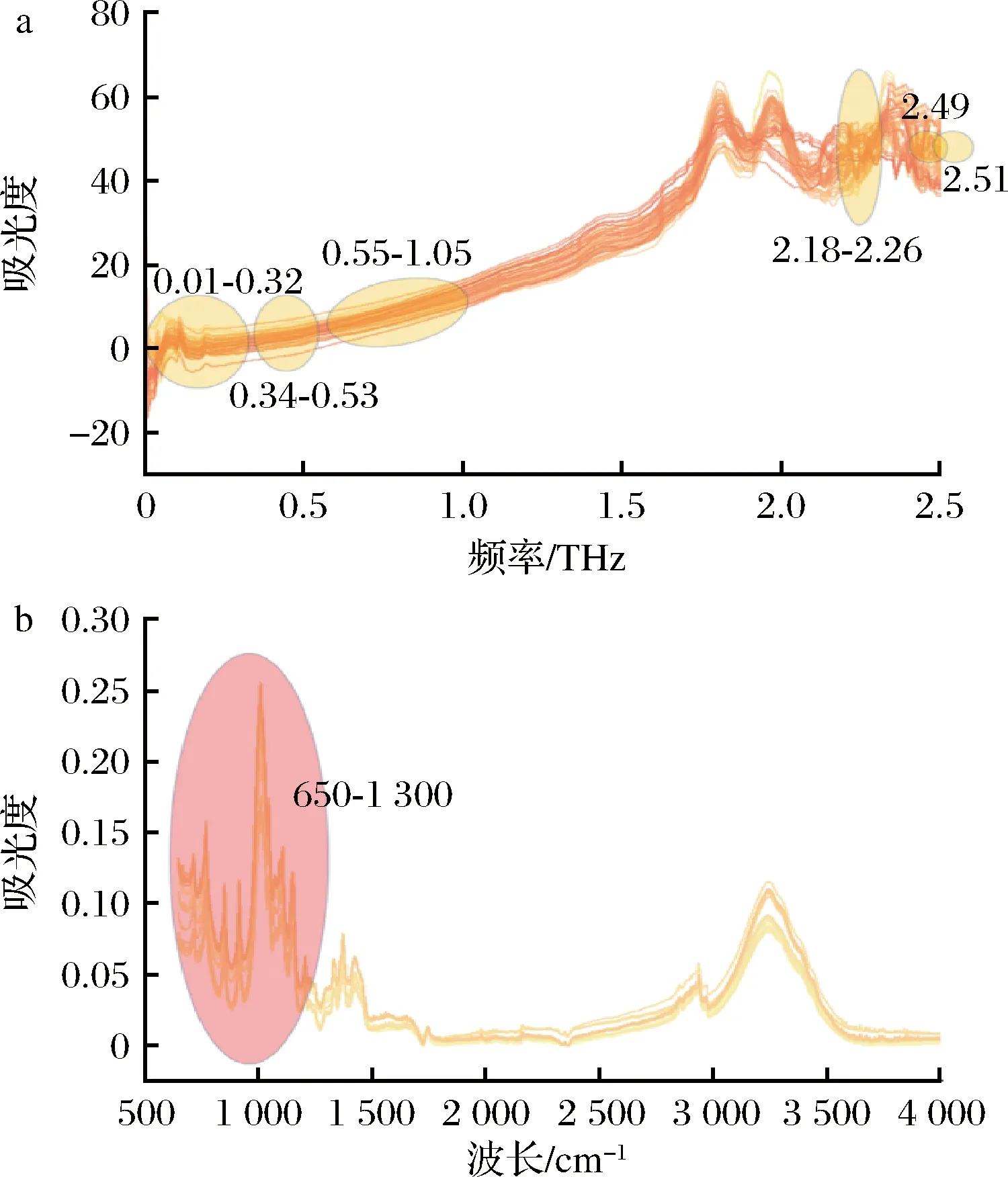
如图3-a所示,70组样本在0~2.5 THz波段的太赫兹时域光谱中的吸收曲线形,吸收曲线走向以及特征峰位置基本一致,在0~0.15 THz及1.8~2.5 THz波段内具有8处明显特征峰,分别在0.11、0.08、1.8、1.98、1.96、2.22、2.33、2.37 THz八个位置。

a-原图;b-一阶导数;c-二阶导数;d-低通巴特沃斯;e-高通巴特沃斯;f-带通巴特沃斯图3 光谱预处理效果图Fig.3 Spectral pretreatment rendering
通过进一步观察样本在0~2.5 THz内的谱图,发现较大区间范围内的光谱信号存在严重的噪声和冗余信息,在特征峰频率区间内,不同样本的特征峰会有较多的重合现象。同时,实验环境不能完全将湿度、光线等干扰噪声消除,需要进一步通过光谱预处理和特征提取的方法消除冗余成分,筛选出主要信息,以提高建模的准确率,达到对不同品牌中咖啡掺假的识别分类。图3-b和图3-c是分别通过一阶导数(first derivative,FD)、二阶导数(second derivative,SD)处理后的咖啡太赫兹光谱图。通过导数对光谱进行预处理可以有效的消除实验环境导致的常数基线漂移,且能够将不完全重合的谱峰进行分离。对比图3-b和图3-c,随导数阶的增加,咖啡的太赫兹光谱特征峰分离效果趋于明显,并能够有效提高光谱的分辨率、信噪比以及模型的检测效果。但增加导数的阶,会放大光谱的高频信号,图3中二阶导数的高频信号明显强于一阶导数,因此本研究只选择一阶导数和二阶导数的方法,避免高阶导数的处理造成信噪比降低。
在信号处理领域,巴特沃斯滤波器因通频带内的频率响应曲线最大限度平坦,没有频率上的起伏,而在阻频带则逐渐趋近于0。根据常见的频率可以分为低通、高通、带通、带阻四种滤波器。观察图3-d、图3-e、图3-f中通过低通、高通、带通3种10阶巴特沃斯滤波器对太赫兹光谱图进行校正的结果,可以有效地筛选光谱的主要特征信息,并且分离重合的特征峰,是一种良好的光谱信号处理方法。
通过振幅和频率之间的关系函数表示巴特沃斯滤波器如公式(4)所示:
(4)
式中:n为滤波器的阶数;ωp为截止频率;ωc为通频带边缘频率。
2.2.1 导数预处理方法
由图3可知,选择常用的一阶导数、二阶导数对咖啡样本的太赫兹光谱进行预处理,能够有效的区分开在0~0.3 THz区间和2.2~2.5 THz区间的特征峰,且对于无特征意义的频率范围可以进行平滑处理,防止模型计算冗余。何欣龙等[20]在进行车祸现场中保险杠的识别研究中发现,一阶导数和二阶导数处理的BDA模型优于原始数据和三阶导数,这是由于三阶导数会大幅降低光谱的信噪比和识别灵敏度。基于上述研究,本实验选择FD-BDA、FD-SVM、FD-RF、SD-BDA、SD-SVM、SD-RF六种导数融合识别模型与原始数据建模进行对比,如图4所示,未经导数预处理的BDA模型准确率仅为88.6%,经一阶导数处理后,BDA模型分类准确率均明显提高,其中FD-BDA模型分类准确率最高为98.6%。FD-RF模型分类准确率仅为63.8%,与原始数据建模结果相同,这可能是因为在导数计算的过程中,一阶导数只能消除常数项的噪声,RF模型本身存在特征筛选的作用,所以一阶导数的处理效果对于RF模型训练影响不大,但经二阶导数处理后可以进一步对光谱信息进行降噪,并且对较高频率的光谱基线进行校正,因此RF模型的分类准确率明显提高。SVM模型的变化幅度较小,且SD-SVM 图4 导数预处理模型分类结果Fig.4 Classification results of derivative preprocessing model a-太赫兹时域光谱;b-红外光谱图5 太赫兹时域光谱和中红外光谱的特征选择图Fig.5 Feature selection of THZ time-domain spectra and mid-infrared spectra 2.2.2 光谱信号校正方法 Butterworth滤波器是一种全极点滤波器,函数零点均在无穷远点,其主要特点是最大平坦性和幅频单调下降,可以有效降低频率以外的干扰噪声,优化特征变量的建模效果。蒋强[21]通过Butterworth滤波器对太赫兹时域光谱信息进行处理,能够有效降低管道厚度测量模型的误差效果。基于此,本实验选择采样频率/FS为48 000,滤波器阶为10的低通、高通、带通3种Butterworth滤波器进行预处理建模比较。其中带通的带通频率和带阻频率于低通和高通不同。具体参数及建模结果见表3。 表3 巴特沃斯滤波器预处理的分类结果Table 3 Classification results of Butterworth filter preprocessing 由表3可知,RF模型和SVM模型在3种不同的Butterworth滤波器下分类准确率提升至94.2%。在两类模型中,高通滤波器的分类准确率优于低通和带通。高通滤波器能够抑制低频分量并选择高通分量通过,从而降低噪声,筛选出合适的光谱信号。相较于直接对模型的参数进行优化,通过High-Pass Butterworth滤波器的方法进行预处理,能够有效提高模型准确率。进一步选择Band-Pass Butterworth-BDA模型,对每一类样本的分类准确率进行预测,结果表明70组样本的总体识别准确率达98.6%,可以有效地对掺假有西布曲明的咖啡进行识别,但尚未达到100%准确分类。 2.2.3 特征选择融合方法 Pearson相关系数是选择重要特征变量的常用方法[22],可以用来检测两个连续型变量之间线性相关的程度,取值范围为正负1的区间,在区间内大于0表示正相关,小于0表示负相关,绝对值越大表示线性相关程度越高。本实验中通过Pearson方法对咖啡样本的太赫兹光谱图进行特征选择,并选择对应咖啡样本中红外光谱图的指纹区域(650~1 300 cm-1)进行特征融合建模。邱薇纶等[23]通过对180份植物油的拉曼光谱和中红外光谱进行融合建模研究,结果表明特征层光谱融合效果优于数据层光谱融合,通过BDA和MLP模型实现分类准确率100%和97%。特征层的光谱融合主要是通过相关性计算的筛选主要特征变量。本实验通过Pearson方法筛选出太赫兹时域光谱的主要特征频率范围,并且通过筛选发现咖啡的中红外光谱数据在指纹区域内的特征变量均具有较强的关联性。表4中给出了实验样本的太赫兹光谱在0~2.5 THz区间内的主要变量和中红外光谱选择的指纹区域。 表4 咖啡样本的光谱特征频率选择Table 4 Selection of spectral characteristic frequencies of coffee samples 通过太赫兹时域光谱的特征频率和中红外光谱的指纹区域进行融合建模,模型准确率有效提高,SVM>BDA>RF其中SVM模型在特征融合下的准确率提高至100%,分类效果最好。能够满足快速、无损对咖啡中掺假非法药物成分的准确鉴别。在确立最优预处理方法建模的基础上,选择星空咖啡的三类不同产地的样本进行识别研究,如图6所示,能够准确地对品牌-产地实现二维特征识别,为进一步确定掺假咖啡的来源提供侦查线索。 图6 星空品牌样本产地分类Fig.6 Classification of Starry Star brand samples 通过太赫兹时域光谱结合机器学习对70组含西布曲明的减肥咖啡的样本建立一种“品牌分类-产地识别”的快速分析方法。通过一/二阶导数、巴特沃斯滤波器、融合特征提取3种方法对250维THz-TDS光谱数据进行预处理,预处理方法能够有效提取特征信息,消除部分实验噪声。结果表明,Band-Pass Butterworth-BDA模型、FD-BDA模型分类准确率均达98.6%,这表明BDA模型的分类效果较好,且2种预处理方法都能够有效提升模型精度,但均未达100%。High-Pass-RF模型准确率为94.2%,较FD-RF、SD-RF的准确率高,这表明通过高频分量的滤波器筛选光谱信息相较单一的特征峰校正和导数降噪可以有效地提升RF模型的准确率。最终,确立基于THz-TDs-FTIR两种光谱特征变量融合的SVM模型对不同咖啡样本的分类准确率最高100%,并进一步选择此方法开展对产地的识别,结果表明能够准确区分来自3个产地的同一品牌掺假咖啡。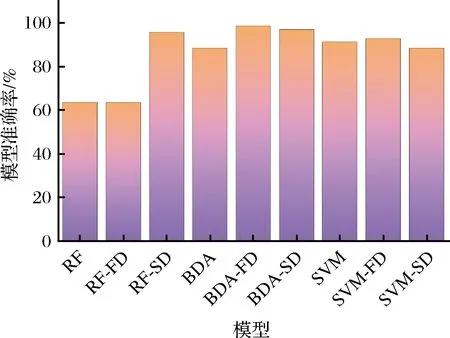



3 结论
猜你喜欢
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:48
雷达学报(2018年1期)2018-04-04 01:56:56
雷达学报(2018年1期)2018-04-04 01:56:48
雷达学报(2018年1期)2018-04-04 01:56:44
制导与引信(2017年3期)2017-11-02 05:16:56
数学大世界·中旬刊(2017年3期)2017-05-14 17:41:25
高中生学习·高三版(2016年9期)2016-05-14 14:05:08
工业设计(2016年11期)2016-04-16 02:50:19
环境科技(2015年6期)2015-11-08 11:14:26
电网与清洁能源(2015年2期)2015-02-28 16:03:07
