
大数据技术下煤矿设备状态Hadoop 平台设计
2023-07-26 06:38:48胡伟英
山东煤炭科技 2023年6期
胡伟英
(山西焦煤集团霍州煤电集团店坪煤矿,山西 方山 041600)
在店坪煤矿井下设备较多且分布杂乱,收集数据的种类较多且较为离散,将数据集中记录以及集中处理的难度较大,同时对于数据中心的维护比较困难,容易出现信息孤岛问题。为了方便煤矿的数据管理,本文依托大数据技术进行数据管理平台的设计[1-4],旨在顺利完成数据的存储与管理,同时实现企业化的分布式数据管理。
1 Hadoop 设备运行状态管理平台需求分析
1.1 Hadoop 平台数据源分析
在大数据技术上设备运行状态管理数据平台中,数据主要来源如下所示:
1)机电设备的基础信息。主要是围绕井下各大系统包括供电、通风、压风、排水等系统中各个关键设备,通过其基础信息包括型号、额定参数等录入,管理员可以通过系统对所有设备的基础信息进行查阅,确保工作的高效进行。
2)设备的运维以及检修信息。由于井下环境的特殊性,井下很多设备需要进行定期维护与检修,通过供应商提供的寿命标准,要按期进行零部件的更换,严控设备的检修,保证井下生产的安全。
1.2 Hadoop 平台需求功能分析
井下设备运行状态管理平台是一个集成化的系统,由很多设备管理小部门组合而成。为保证管理平台的正常运转,其下的小部门需要在同一个平台上进行工作的协调,在相同的服务器下进行记录以及查询工作,确保值班人员在进行交班前,下一个值班人员能通过平台数据记录了解设备的运行状态与记录的相符性。为了实现上述功能,数据平台的功能需求如下:
1)数据在线录入。首先在进行设备的检查以及日常维护时,工作人员能够通过平台的在线功能,进行在线录入,主要包括排班信息、设备运行状态信息、故障信息以及故障排查信息等。
2)数据在线检索。在平台中存储有海量的信息,需要定位查找,难度较大,需要有在线检索功能,通过查询,可以直接找到想要的信息。
3)数据导出功能。在线录入的信息,可以按照时间的排序,实时存储在Excel 中,通过平台的导出功能实现数据的下载导出打印,方便查询等。
除了上述的平台功能要求,还有一定的非功能性的需求。其中就有数据一致性的要求,确保平台中数据的准确性以及实时性;海量的存储空间要求,设备信息以及人员信息较多,对于存储空间的要求较大,要保证空间足够;读写延迟小,平台信息更新频次多、频率快,对读写功能有一定的要求。
2 大数据技术下Hadoop 平台设计
矿井机电信息由三部分组成,包括运行数据、监控数据以及信息文档。为了将信息简化,需要对信息进行转换,将数据统一为XML 文本格式。为确保平台数据精确集成,平台需要读取各个站点的运行信息以及图纸信息,保证数据管理的有序开展。这样一来,数据平台就有实时监控、数据管理以及运行监控等功能。为确保数据平台快速存储以及快速处理等功能,需要将站内的各个网络接口进行连接。目前由于数据平台越来越完整,搭建的标准也越来越高。数据管理平台的设计是以Hadoop 平台为基础,在最大程度保留原有平台的基础上,配备集群部署计算机,同时在目标计算机上搭建虚拟机。通过结合大数据技术,Hadoop 平台拥有强大的计算能力,同时拥有高容量的存储能力。图1 为Hadoop平台设备运行状态数据管理平台总体设计结构图。

图1 总体设计结构图
从图1 可以看出,Hadoop 数据管理平台可以分为四大部分,包括数据采集、数据转换、数据存储、数据分析。数据采集主要是通过井下各个设备上的传感器完成信息的采集,包括温度、湿度、转速等,再通过PLC 以及以太网组合完成采集数据的上传工作,将数据传输到地面管理中心。数据转换是将数据通过XML文本格式的媒介进行数据的规范化处理,避免了数据各自孤立的问题存在。数据存储是将转换完成的数据进行指定位置的存储,存储过程分为两部分,一部分是通过Redis 将实时数据进行传输同时将其暂时储存在内存中便于上层实时显示数据;另一部分是将以往数据通过文件系统保存在HBase各节点容器中,方便数据的读取。在远程服务器中需要实时显示各煤矿的信息,也是从Redis 直接调取。平台的最后工作是数据的分析,同时根据分析结果作出判断与决策。通过数据分析掌控井下的运转情况,还可以实现异常数据的排除,同时在大数据技术的基础上进行数据对比分析、故障诊断等。
3 Hadoop 平台子系统的设计
3.1 OPC UA 协议基础数据采集系统设计
为了实现井下的机电设备数据采集驱动标准一致,能够通过传感器将反馈的数据进行统一的处理,因此基于OPC UA 协议搭建了每组数据的存储地址,按照一致的采集协议实现各个设备之间信息的交互,同时也能够解决现在由于远程集成系统导致的数据不通的问题。
数据采集系统的结构组成如图2。

图2 采集系统结构组成图
采集系统中本地服务器通过以太网与工业网络相连接,同时以网络为路径,将本地服务器PC 作为客户端,形成C/S 形式的本地数据采集系统。在对各个设备进行数据采集时,通过多线程的模式,实现同时采集。采集结束后将数据进行解析封装之后传递到相应的地址空间,再上传到云服务器中,完成数据的存储,为后续的分析处理做准备。
3.2 MapReduce 特征的数据提取
在Hadoop 平台中,集群批处理框架被称为MapReduce,依靠框架本身的分布式计算环境来提供相应的计算模式。其计算模式主要来源于框架的两大功能,即Map 和Reduce。其代表的是两种函数,分别是映射函数Mapper 和归约函数Reducer。在数据处理过程中首先在Map 中进行筛选以及转换,之后数据会进行Reduce 归约,完成数据规模收缩,再通过Reducer 聚合功能来获得最终的结果。图3为MapReduce 结构图。
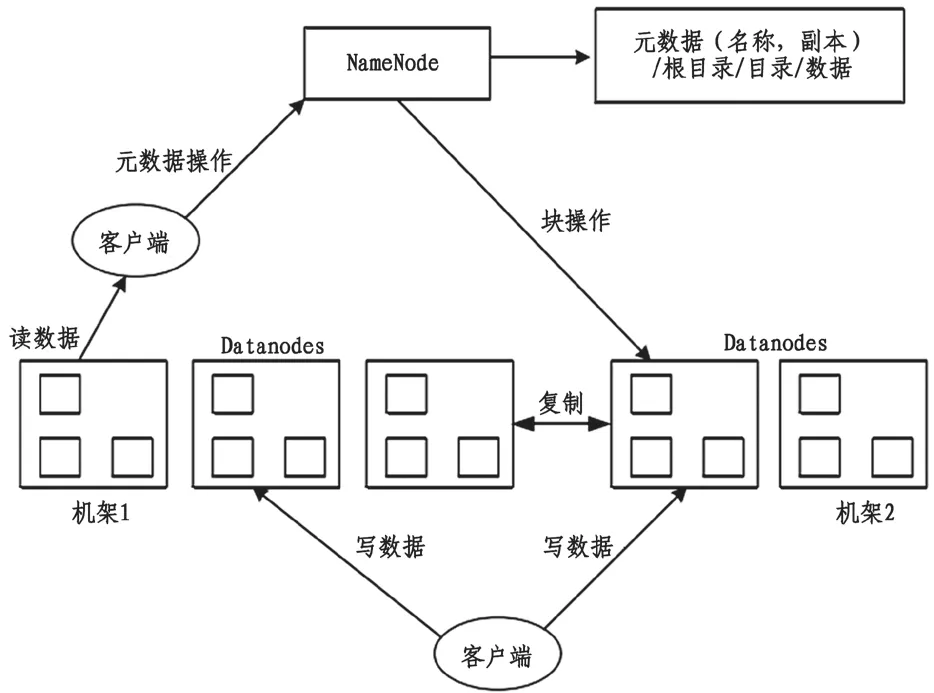
图3 MapReduce 结构图
在完成数据采集存储之后,需要对特征数据完成提取,方便后续的分析。数据提取流程如图4。

图4 特征数据提取过程
3.3 Redis 技术下的数据传输架构
Redis 技术下的数据传输层作为连接采集层与上机监管端之间的桥梁,在Hadoop 平台下,起着关键的作用。Redis 技术具有数据读写快、数据缓存持久、交互模式多等特点,可以通过发布以及订阅两种模式将数据进行传输,实现了数据从客户端到服务端的传输,极大地缩短了数据的传输时间。由于其内部的分布式缓存功能,可以将解析的数据暂存在Redis 数据库中,减小了数据丢失的问题。图5 为Redis 的两种模式。

图5 Redis 发布/订阅模式
3.4 HBase 技术下的数据存储
图6 为HBase 技术下数据存储流程图。在整个过程中,首先通过OPC 服务器来获取设备的实时状态数据,将数据进行XML 文档格式的转换,后到达用户界面终端对设备数据进行操作。一旦数据中心收到终端查询指令后,平台内Yarn 实物调动引擎将会对指派的任务进行分解。对于实时类数据存储,会根据业务规则完成数据的计算,将计算结果归纳到存储区内,再按照多个数据完成节点来进行数据存储;对于文档类文件,将会根据属性自动识别为标准格式进行存储。根据数据节点完成的缓存,将会按照Yam 指令程序分解任务进行逐一完成:首先实时数据到达缓存区,按照时间的先后顺序对数据进行接收排序;随后数据到达计算区,Yarn 实物引擎会通过发出的调度指令接收下发的历史数据集,将数据存储在实时数据缓存区内;紧接着对HBase 数据库进行容量检测,若发现资源充足,将会被立即送到数据库中,若空间不足,会将其暂存在Redis 中,待资源充足后再进行传输。
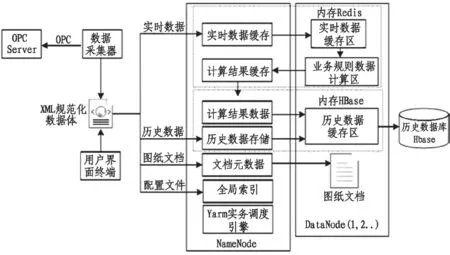
图6 HBase 技术下数据存储流程图
4 结论
本文以数据监测平台为研究对象,为了解决目前出现的数据杂乱难集中、难处理、难维护、难流通等的问题,以大数据技术为依托,对设备状态Hadoop 平台进行设计,再分别对Hadoop 平台4 大组成系统进行设计,分别是数据采集、数据提取、数据传输以及数据存储,成功将难集中、难处理、信息孤岛等问题解决,实现海量数据的有序化存储,为数字化矿山注入自己的一份力量。
猜你喜欢
中华诗词(2022年6期)2022-12-31 06:41:24
中国特种设备安全(2022年6期)2022-09-20 02:52:28
汽车实用技术(2022年10期)2022-06-09 11:33:52
汽车实用技术(2022年5期)2022-04-02 09:36:52
海洋信息技术与应用(2021年2期)2021-11-02 06:59:10
铁道通信信号(2020年4期)2020-09-21 09:15:24
电子制作(2018年11期)2018-08-04 03:26:08
中国科技论坛(2017年7期)2017-07-25 08:49:53
工业设计(2016年12期)2016-04-16 02:52:00
消费者报道(2014年7期)2014-07-31 11:23:57
