
一种基于YOLOX 的映射式无载体信息隐藏方法
2023-07-13 10:33苟沛东张春玉刘海伦石倚菲
电子制作 2023年11期
苟沛东,张春玉,2,刘海伦,石倚菲
(1.西藏民族大学 信息工程学院,陕西咸阳,712082;2.西藏自治区光信息处理与可视化技术重点实验室,陕西咸阳,712082)
0 引言
信息隐藏[1]作为一种有效的隐蔽通信方法,旨在利用载体的某些特征将秘密信息隐藏在载体中,例如文本、数字图像和音视频文件等,以进行隐蔽通信。由于图像是信息传输中最重要的媒介之一,因此图像信息隐藏受到了广泛的关注。传统的信息隐藏主要侧重于在数字图像中嵌入消息,主要在空域[2~3]、频域[4~5]和自适应域[6~8]进行嵌入,同时对该图像保持最少的嵌入修改[9]。然而,隐写分析技术[10~11]的主要目的就是通过修改痕迹检测秘密信息的存在。所以,传统的图像隐写术无法完全抵抗隐写分析,因为秘密信息的嵌入破坏了载体图像的统计特性,这也使得隐写分析具有可乘之机。
为了避免在载体上留下痕迹,而导致秘密信息被隐写分析发现,故无载体信息隐藏的技术应运而生[12~13]。与传统的信息隐藏方法相比,无载体信息隐藏方法不改变载体,故而可以抵抗现有的所有隐写分析工具,从而比传统的信息隐藏方法具有更高的安全性。目前已有许多学者对无载体信息隐藏方法进行了研究,当前主要为映射/编码式无载体信息隐藏和生成/构造式无载体信息隐藏这两类方法。其中映射式无载体方法也被称为基于载体选择的无载体信息隐藏,其通过建立秘密信息与载体间的映射关系来实现隐蔽通信。该类方法一般需要建设大型数据库,存在映射方案覆盖率低、易被隐写分析获取秘密信息等普遍问题。
近年来,随着更加强大的算力的出现,以及更加庞大的数据集的支持,人工智能的浪潮席卷了全世界,而深度学习正是引发这一浪潮因素之一。深度学习是机器学习的一种技术,相对于较为传统的机器学习方法,深度学习十分擅长发现高维数据之中的复杂结构,如今它已经拥有了许多高效的模型,如卷积神经网络、生成对抗神经网络等。深度学习中优秀的模型被研究者们广泛地应用在信息隐藏之中。传统的信息隐藏算法一般都是算法设计者通过自身的领域知识来确定在载体图像哪些具体位置嵌入秘密信息,需要较高的专业知识,并且需要手工设计高斯滤波器等。由于深度学习的强大的特征学习能力,可以通过大量样本的训练拟合一些优秀的特征提取器,并通过神经网络来辨别出载体图像之中哪里适合嵌入秘密信息,摆脱了对算法实现者专业知识的需求。我们也可以将深度学习中训练生成的思想带入到信息隐藏模型的训练中去,基于深度学习执行秘密信息隐藏算法,来使信息隐藏具有更高的安全性。目前基于深度学习的信息隐藏算法已经全面超过了传统的基于领域知识的设计的算法,所以将深度学习应用在信息隐藏算法之中是一个非常优秀的方向,能够很好地加速信息隐藏算法的发展。
映射式无载体方法的经典算法是2013 年M.Bilal 等提出的零隐藏的概念[14]。该框架嵌入秘密信息时并不依赖于修改载体数据,而是建立秘密信息与载体之间的映射关系生成秘钥,把秘钥单独传送给接收方。ZHOU[15]等人提出了一种新的基于定位梯度直方图哈希算法的无载体信息隐藏方法。ZHENG[16]等人提出一种基于鲁棒图像哈希的无载体隐写方法。
随着深度学习[17]的快速发展,基于深度学习的映射式无载体信息隐藏方法应运而生。王亚宁等[18]针对大多数无载体隐写算法先定义映射规则,再在图库中匹配图像的思路,反其道而行之,提出先给定图库,根据已有图库自动搜索无载体映射关系的思路,隐藏量、抗检测能力、鲁棒性方面性能都有所提高。Zhou 等人[19]在2019 年将FasterRCNN 与秘密信息相结合,通过检测目标类别构建映射关系,建立对应多级索引图像库以支持秘密信息传输,在传输准确度、信息隐藏容量等方面具有较好效果。Zhou 等人[20]利用K-means 算法建立一个图像数据库,通过比较库中图像的HSV 特征来选择部分重复图像,而后利用图像不同位置的复制部分来进行信息隐藏。
2017 年,Girshick 关于提出了准确度和运行耗时表现均表现良好的FasterRCNN 算法。2019 年Zhou 提出基于FasterRCNN 的映射式无载体信息隐藏方案,算法基于FasterRCNN 来检测和定位图像中的目标,并利用目标标签来表达秘密信息,与传统的信息隐藏方法相比,在容量方面具有更高的性能,但研究的FasterRCNN 算法对目标识别准确率的具有局限性,需构建大量图像库,算法应用难度较高,且受攻击后鲁棒性具有一定限制。
基于上述方案,本文提出了基于YOLOX 算法的映射式无载体信息隐藏方法根据秘密信息的二进制序列与检测目标间构建映射关系库;根据映射关系多级索引图像库,查找对应图像信息,若图像库中不包含所需信息,则可临时构建含密图像以支持信息传输。与之前的工作相比,本文研究的算法的主要贡献如下:
(1)本研究的映射式秘密信息传输具有较高的提取准确率,与传统的信息隐藏方法相比在受到攻击时也能保证图像的鲁棒性。
(2)本文算法对比传统算法提高了隐藏容量,且本文实现的方法为可扩展隐藏方法,从而支持隐藏容量持续提升。
(3)本文的含密载体质量高、更逼真,在进行秘密信息隐藏时可保证第三方无法发现,从而具有更高的安全性。
1 相关工作
YOLOX 目标检测算法由ZhangGe 等人[21]于2021 提出的目标检测网络模型,是目前YOLO 网络系列速度最快,精度最高的检测模型。YOLOX 目标检测网络分为四部分组成,其分别为模型的输入端,主干网络Darket53,特征增强网络以及模型预测端。
YOLOX 数据输入部分采用强大的数据增强策略,将Mosica 以及Mixup 两种数据增强策略相结合,能对数据进行有效扩充,防止模型的过拟合。Mosaic 数据增强策略已应用在其他YOLO 系列模型当中,是一种非常有效地提高样本质量的技巧。首先,从数据集中随机抽取四张图片,并对每张图片进行随机翻转,裁剪,颜色扰动以及添加噪声等操作,然后再对其进行裁剪拼接,极大扩充了目标的背景,Mixup 数据增强方法则是首先从训练集中随机选取两张图像,并采用线性插值的方法对像素值进行叠加,扩充了目标的背景,将两种数据增强方法结合,更加有利于小目标的检测。
模型的主干网络则采取传统YOLO 系列模型的Darknet53 作为特征提取网络。在增强模块中,采用空间金字塔结构的FPN 网络将高语义信息特征与低级特征相结合进行多尺度训练,提高模型对小目标的检测能力。预测输出网络采用解耦头对检测目标类别以及坐标框的预测。传统的网络输出阶段,直接将目标分类与回归任务在同一特征图上进行,由于分类任务考虑样本之间的特征差异,而回归任务更加注重目标的外形轮廓特征,因此会导致任务产生冲突。YOLOX 的解耦头采用1×1 卷积将特征图的通道数进行调整,调整后特征图连接两个并行的分支,每个分支采用两次3×3 的卷积用以分类和回归任务。
YOLOX 采用Anchor-free 的检测器对坐标信息进行预测。在回归网络中,每个预测点需要预测边框的左上角坐标(x,y)以及矩形框的宽度、高度;分类网络需要对目标的类别进行预测;预测网络需要对框选的目标区域判断是目标区域还是背景区域,并采用目标的中心点作为训练的正样本。每个输出特征图上的点只预测一个预选框,将预测结果与原始的样本进行匹配来判断是否为正样本,需要采用合适的标签分配策略,YOLOX 采用simOTA 方法作为标签的匹配方式。首先,获取预选框和目标框的坐标信息以及类别信息,通过计算IOU 值得到与每个目标框对应10 个候选框,IOU是一种测量在特定数据集中检测相应物体准确度的一个标准,是算法检测中最常用的指标,它不仅可以确定正样本和负样本,还可以用来获得预测检测框与真实检测框之间的距离。其在数学上的表示为如下公式所示:一般约定IOU>0.5 时,认为正确检测。然后利用回归损失以及分类损失计算代价函数,利用代价值给每个目标挑选候选框,最后再采用非最大抑制筛除重复的检测框。
2 信息隐藏方法
本研究实现了基于YOLOX 算法的映射式无载体信息隐藏方法,扩展了无载体信息隐藏的多样性,针对了传统安全性差的问题进行优化提升,并在此基础上进一步提升了信息隐藏容量。本研究提出框架如图1 所示,隐写方式为无载体信息隐藏,不会在图像中留下修改痕迹,利用YOLOX 算法检测来自图像库的图像的目标标签。算法根据秘密信息的二进制序列与检测目标之间构建映射关系库;根据映射关系多级索引图像库,查找对应图像信息,若图像库中不包含所需信息,则可自行构建含密图像以支持信息传输。发送端确认发送秘密信息,将秘密信息对应二进制序列,然后根据映射关系索引图像库或构建含密图像进行信息传输。接收方根据YOLOX 算法从隐写图像中检测目标区域并获取其锚框中心点信息,然后根据映射关系库将识别目标信息转换为二进制序列,进而转化为秘密信息。
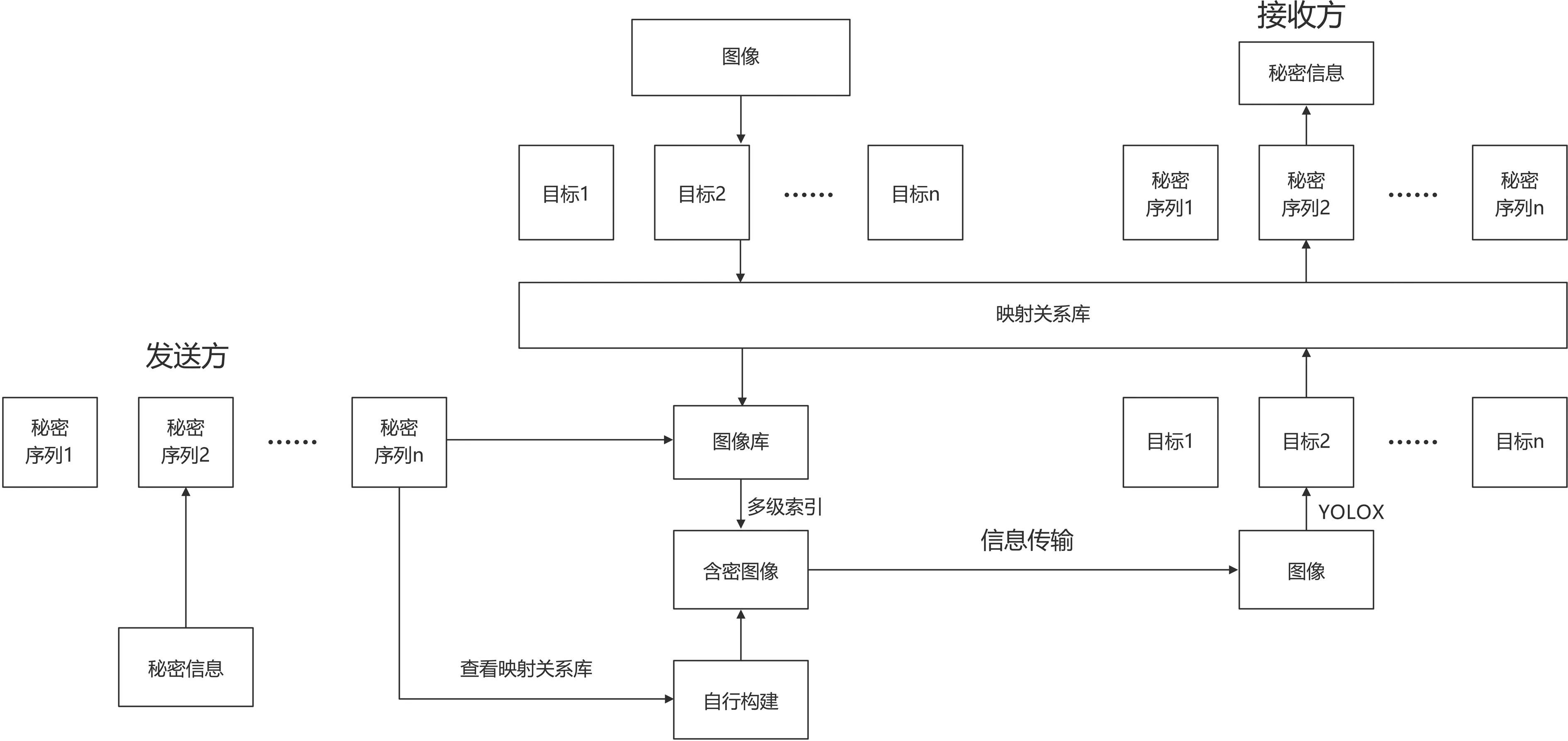
图1 基于YOLOX 算法的映射式无载体信息隐藏方法
■2.1 映射关系库建立
为了实现无载体信息隐藏,需要在秘密二进制序列和原始图像的特征之间建立映射关系库。在本研究中,使用目标标签来表示秘密消息,从而将秘密消息转换为二进制序列,并使用YOLOX 算法检测目标标签及锚框中心以建立映射关系库。YOLOX 算法检测到一组目标标签。如果将目标标签分为2n个类别,每个目标可以表示n 位消息。构建映射关系库,表示为M。在此映射关系库中,目标标签分为25个类别。由于使用目标标签来表示秘密消息,因此需要确定用于表示秘密信息的目标标签的顺序。本研究使用YOLOX 算法从图像中检测目标及其标签。每个目标锚框中心点表示为(x,y),其中x 和y 表示目标锚框区域中心点的横、纵坐标。然后,根据目标锚框区域中心点横坐标x 值对目标从左至右进行排序,若检测横坐标相同,则根据纵坐标y 值从上至下进行排序,本研究图像主动生成过程应尽可能避免目标锚框横坐标值相同,即应尽量避免生成图像时目标物体出现锚点覆盖。
构建映射关系库时应考虑后续秘密信息传输的图像载体的合理性进行充分考虑,本研究采用了COCO2017 数据集的目标标签,针对COCO2017 数据集包含81 种分类,本研究每个目标物体映射为5bit 信息,为了降低含密图像载体的不合理构图可能性,本研究映射遵循常见目标单独映射,不常见目标合并映射的思路构建映射关系库,例如:person(人)单一属性为一个分类,表示二进制密码段为00000;stop sign(停车标志)、parking meter(停车计费器)、fire hydrant(消防栓)三属性为一个分类,表示二进制密码段为00111,表1 给出了对应映射关系信息。

表1 映射关系库
根据表1,每个目标表示5 位消息。在秘密通信之前,将秘密消息转换为N位二进制字符串。如果N不能被5整除,在二进制字符串的末尾添加几个零,以确保位数可以被5 整除。同时,在二进制序列最后添加一组5bit 用来表示补0的个数,且为了更好的指示信息,构建如下映射:00000 到00110 表示没补0;00111到01100 表 示 补1 个0;01101 到10010 表 示 补2个0;10011 到11000 表示补3 个0;11001 到11111表示补4 个0。例如,实际有效消息为[11111 00000 00011 11],图像表示的二进制序列为[10111 00110 10111 11000 xxxxx],其中xxxxx 可 以 是10011 到11000 任意一个。
■2.2 选择/构建含密图像
2.2.1 图像库多级索引
发送方需要的含密信息图像载体可以通过在图像库中查找符合要求的已有图像作为含密图像,然后进行秘密信息传输,但是,在大规模图像数据库中直接查找可以表示给定秘密信息的图像是非常耗时的。因此,为了实现高效的无载体信息隐藏,本研究设计了一种多级索引结构如图2 所示。具体索引过程如下,采用YOLOX 算法对图像数据库的每个图像中的目标及标签进行识别,并按目标锚框区域中心点的横坐标升序进行排序,然后根据映射关系库将这些标签转换为二进制序列。之后,根据二进制序列分级将图像列表的ID 存储在索引文件中。
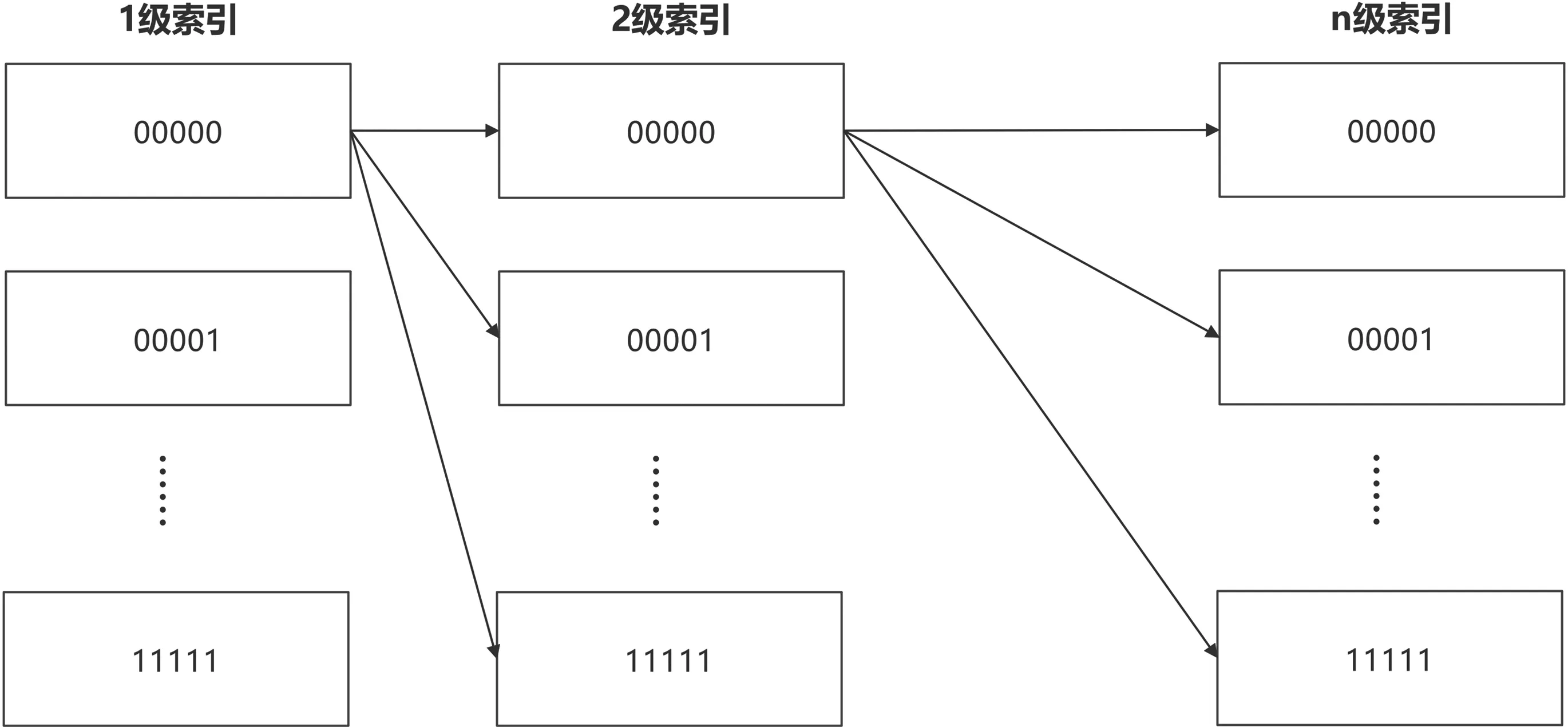
图2 多级索引结构
2.2.2 构建含密图像
在进行秘密信息传输时,若在图像库中搜索载体图像作为含密图像的方法不能满足用户需求,用户可在紧急需求时,通过部分可获取的真实场景目标物自行构建含密图像以支持使用。此时选取映射关系库中定义的日常常见目标为含密映射目标,这样可以简单进行含密图像构建。根据可获取的映射库中构建的目标,结合秘密信息将目标按对应序列进行排序映射,并利用拍照等方式完成构建,然后通过YOLOX 模型进行检测。临时构建含密图像的方式也可以降低图像库构建复杂度,支持高效完成图像构建及传输。表2 中给出了拍照生成图像中目标对应的秘密信息示意。

表2 拍照生成图像中目标对应秘密信息示意图
■2.3 信息隐藏过程
本研究方法利用图像的目标标签来表示和传输二进制序列。如图3 所示,信息隐藏过程旨在找到可以表示秘密消息的原始图像。

图3 信息隐藏过程
隐藏步骤如下:
(1)本研究在所提出的方法中,为了提高安全性,不同的用户会采用不同的映射关系库,同一个用户在不同的时间也会采用不同的映射关系以支持秘密信息传输。在信息隐藏之前,我们需要确定当前秘密通信的映射关系库M,M定义如下:
其中M 是初始映射关系库,R(ID)及R(T)是随机函数,ID是用户身份,T是时间间隔。
(2)将秘密消息转换为二进制字符串。假设机密信息的总长度为n 位,每个目标表示N 位二进制。如果N 不能被n 整除,我们在二进制串后面补零,直到秘密信息的长度可以被n 整除。同时,在二进制串最后增加N 位二进制数表示补零的个数,在本研究中N 表示为5。秘密信息被划分为m 个二进制信息段,其中段的数量m 由下述公式确定。因此,秘密消息可以表示为B={B1,B2,B3,...,Bm}。
(3)根据映射M 得到对应目标O ={O1,O2,O3,...,Om}的目标集。
(4)通过索引图像库或含密图像构建,根据不同用户在不同时间拍摄出的图像不同,实现不同的隐写图像来隐藏和传输相同的秘密消息。
最后获取隐写图像,用于隐藏传输秘密图像。
■2.4 信息提取过程
在本研究方法中,与发送方的信息隐藏过程相比,接收方的信息提取过程相对简单。如图4 所示,信息提取过程的步骤如下:

图4 信息提取过程
(1)接收方从传输信道接收隐写图像。
(2)接收方使用YOLOX 算法检测隐写图像中的对象O ={O1,O2,O3,...,Om}及其标签,然后根据这些对象区域中心点横坐标值按升序对它们进行排序。
(3)接受方根据上文建设的映射关系库M 获取相应的二进制序列B={B1,B2,B3,...,Bm}。
(4)将所有段连接起来形成秘密二进制序列,并删除二进制序列前面的前n 位和二进制序列末尾的数字0。然后,将二进制机密序列转换为秘密信息。
3 实验分析
■3.1 隐写实验结果
本研究基于python3.8、pytorch1.2.0 以及torchvis ion0.4.0 的软件平台进行实验。首先对YOLOX 检测图像载体的识别准确率进行实验分析。模型对图像中目标检测的结果通常有4 种情况:TP(True Positive),表示目标正确检测出的目标数量;FP(False Positive),表示把错误目标当成正确目标检测出的数量;FN(False Negative),表示目标存在,但系统未将其检测出的目标数量;TN(True Negative),表示目标缺失,但系统将其检测为目标的数量。
针对这四种情况,目标检测算法模型通常用以下几个评价指标来评价模型优劣:
精确率P(Precision):指分类正确的组件正常状态个数占模型判定为正常状态的样本个数的比例,公式如下:
(2)召回率R(Recall):指分类正确的组件正常状态个数占所有样本中正常状态个数的比例,公式如下:
(3)平均精准度AP(Average Precision):以精确率P为纵轴,召回率R 为横轴构建PR 曲线并做平滑处理,对不同召回率对应的精确率求平均,即PR 曲线下的面积,公式如下:
对比YOLOv3 以及Faster RCNN 算法的实验结果如下表3。实验证明本研究算法具有较高的识别准确度,可以保证在图像构建过程中,更容易建立图像以支持图像库建立,方便用于后续传输。
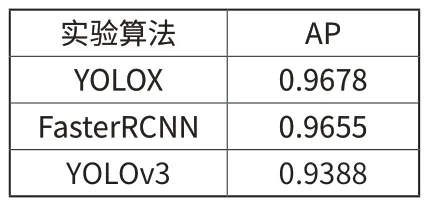
表3 检测准确率
■3.2 提取准确率分析
本研究实验在接收端利用YOLOX 进行图片的秘密信息检测提取,不同图像的提取结果如表4 所示,根据下表可以看出本研究算法可以准确进行目标分类检测以及锚框中心点识别,根据对应检测识别信息,可将目标信息准确转换成二进制序列段,并根据信息构建方案准确执行对应信息转换,输出为准确的有效秘密信息字段。
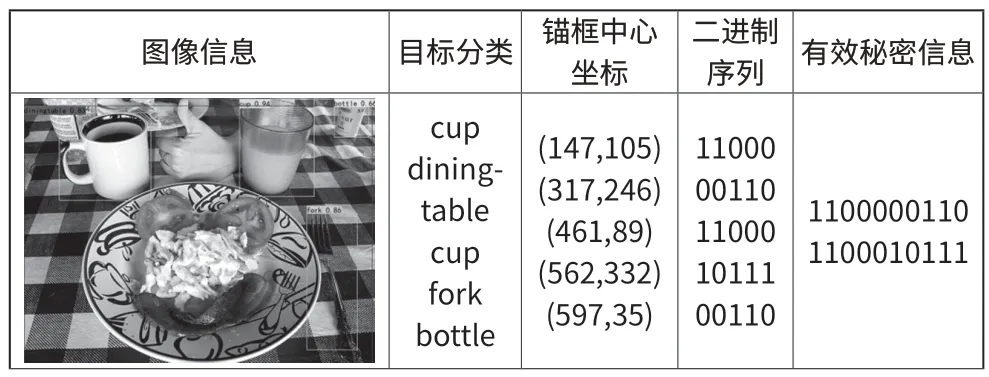
表4 秘密信息检测提取结果

images/BZ_117_320_384_676_622.pngchair chair bed laptop(131,250)(281,246)(319,304)(368,303)00101 00101 00110 01010 00101001 010011images/BZ_117_350_634_646_1019.pngbanana apple chair book bottle(282,1001)(338,1094)(547,1621)(658,1068)(877,861)11001 01100 00101 11101 00110 1100101100 0010111101
秘密信息提取准确率由字符级别解码的正确率CA(Character-level decoding Accuracy)表示,计算公式如下:
其中,公式中n 表示所有参与解码图片的数目,SN 为图片的序号,M 表示发送方嵌入的消息,M′表示接收方解码出的消息。如果M 与M′相等,则f(M, M′)返回1,否则返回 0。
本研究对比了文献[22] 及文献[23]的传统秘密信息传输算法,准确率CA 如表5 所示,从表格中可以看出本研究算法具有较高提取准确率。
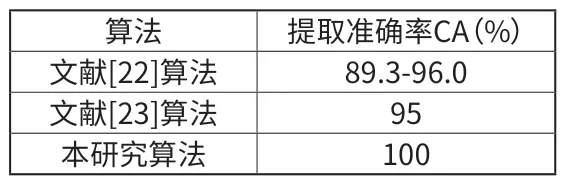
表5 秘密信息提取准确率对比
■3.3 安全性分析
本研究利用了高斯噪声、椒盐噪声以及斑点噪声的不同攻击强度参数值对含密图像进行攻击,在不同参数时,攻击结果示意表6 所示,可以看出,本研究算法具有较好的鲁棒性及安全性。

表6 秘密信息攻击结果示意
本研究选取了100 张样本数据进行攻击实验,其秘密物体数目为500,秘密信息提取准确率如表7 所示。其中高斯噪声选取参数为σ(0.005)、椒盐噪声选取参数为σ(0.005)、斑点噪声选取参数为σ(0.01)。与FasterRCNN 文献对比,可以看出本研究算法具有更好的鲁棒性。此外,本研究方法选择目标分类执行映射。攻击者若仅得到了含密图像,由于其无法判断图像目标分类与秘密信息间的映射关系,故而无法确定秘密信息。若某次传输过程中,攻击方得知了部分特征与秘密消息的对应关系,那么下次传输时也仅需适当的修改对应映射关系便可保证安全。因此,本研究方法在无法得知含密图像与秘密消息之间的映射关系时,可以很好的抵抗唯密文攻击以及已知明文攻击,具有较高的安全性。

表7 秘密信息提取准确率对比

表8 隐藏容量分析
■3.4 隐藏容量分析
本研究算法隐写容量由图像中目标数量决定,所提出的信息隐藏系统使用图像的对象标签来传输二进制比特序列。在实验中,每个目标代表5 位信息。因此,每个隐写图像的隐藏容量取决于它包含的对象的数量。假设隐写图像中包含的目标的数量为O。本方法的隐藏容量随着O 的增加而增加。然而,随着O 的增加,能够表示秘密信息的图像将更加难以识别。表格8 体现了随着O 增加,YOLOX 检测准确率对比分析如下,随着隐写图像中使用的目标数目增加,表示秘密信息数量也随之增加,但由于YOLOX 算法性能限,获取对应图像复杂度升高,其中O 数量在5 左右较容易获取对应图像,对应秘密信息隐写容量为25bit,故为建议选取数目,算法通过分析可知,秘密信息传输数量随图像中目数目增加,因此与之前的方法相比,所提出的方法的隐藏容量更高。
4 总结
本文研究实现了基于YOLOX 的映射式无载体信息隐藏方法,通过实验对比传统算法的信息提取准确率、噪声攻击结果分析以及隐写容量对比,表明本文的基于YOLOX 的映射式无载体信息隐藏方法性能良好。本研究算法由于图像库中目标均经过YOLOX 识别,临时构建图片也经过检测后进行传输,所以接收方对秘密信息的提取具有较高的准确率。本研究算法抵抗高斯噪声、椒盐噪声以及斑点噪声的攻击时均具有较好的鲁棒性,通过分析也可知本研究算法安全性更高。此外,算法在25bit 秘密信息的隐藏容量时具有较好效果,且容量随着目标数量增长仍可有进一步的提升,故基于YOLOX 的映射式无载体信息隐藏方法具有良好性能。
猜你喜欢
中等数学(2021年8期)2021-11-22
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
小溪流(画刊)(2016年11期)2017-01-05
公民与法治(2016年10期)2016-05-17
作文与考试·小学低年级版(2015年22期)2015-12-07
小学科学(2015年11期)2015-12-01
计算机工程(2015年8期)2015-07-03
