
从隐空间理解编码器(Encoder)
2023-07-10 05:47:35高焕堂
电子产品世界 2023年6期
高焕堂

1前言
当我们在阅读关于AIGC的文章时,常常会看到Encoder和Decoder名词。它们是AI(即ML)的核心模型,如果能深入理解它们的涵意和功能,就能更流畅地理解相关文章的内容,以及图示。例如,关于Diffusion(扩张模型)的文章里常看到如图1。
图1说明诸如Stable Diffusion里,就含有文本编码器(text encoder)、图像编码器(img decoder)、以及解码器(decoder)。这些都是AI里的基本名词,处处可见。再如,关于DeepFake(换脸)的文章里,也常看到这两个名词(图2)。
这图里就说明了,一般的DeepFake模型里常含有一个图像编码器(Eecoder)、以及两个图像解码器(即Decoder_A和Decoder_B)。
诸如上述图片,其中的”Encoder”、”Decoder名词是处处常见的。所以把它弄清楚是有必要的。于是,本文就先来解说第1个名词:编码器(Encoder)。当您深入理解编码器了,就能轻易继续理解第2个名词:解码器(Decoder)。
2从欧式空间出发
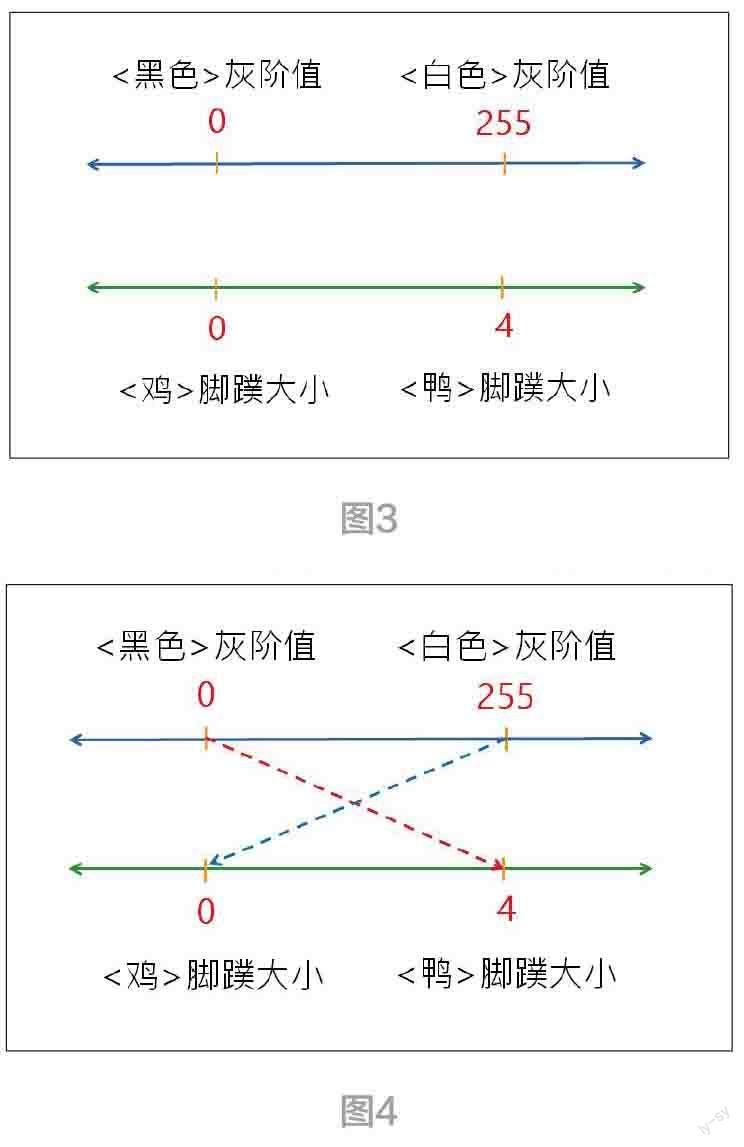
为了充分掌握它,就必需从欧式(Euclidean)空间来入手。所谓空间就是大家熟悉的坐标空间(Coordinate space)。例如,一维空间就是数线(图3)。
这图里有两个一维空间。人们随着阅历增多,逐渐学习,就会连连看,把两个空间对映起来(图4)。
人们把它记忆于脑海里。看到池塘里有黑色家禽,就会联想的< 鸭>。看到池塘里有白色家禽,可能就会联想的< 鹅> 或< 鸡>。接下来,请您先思考:AI 如何学会上述的连连看呢? 也就是,人们如何当老师,把上述的连连看智能,传授( 教导) 给AI 模型,让它也能记忆上述的连连看关系。
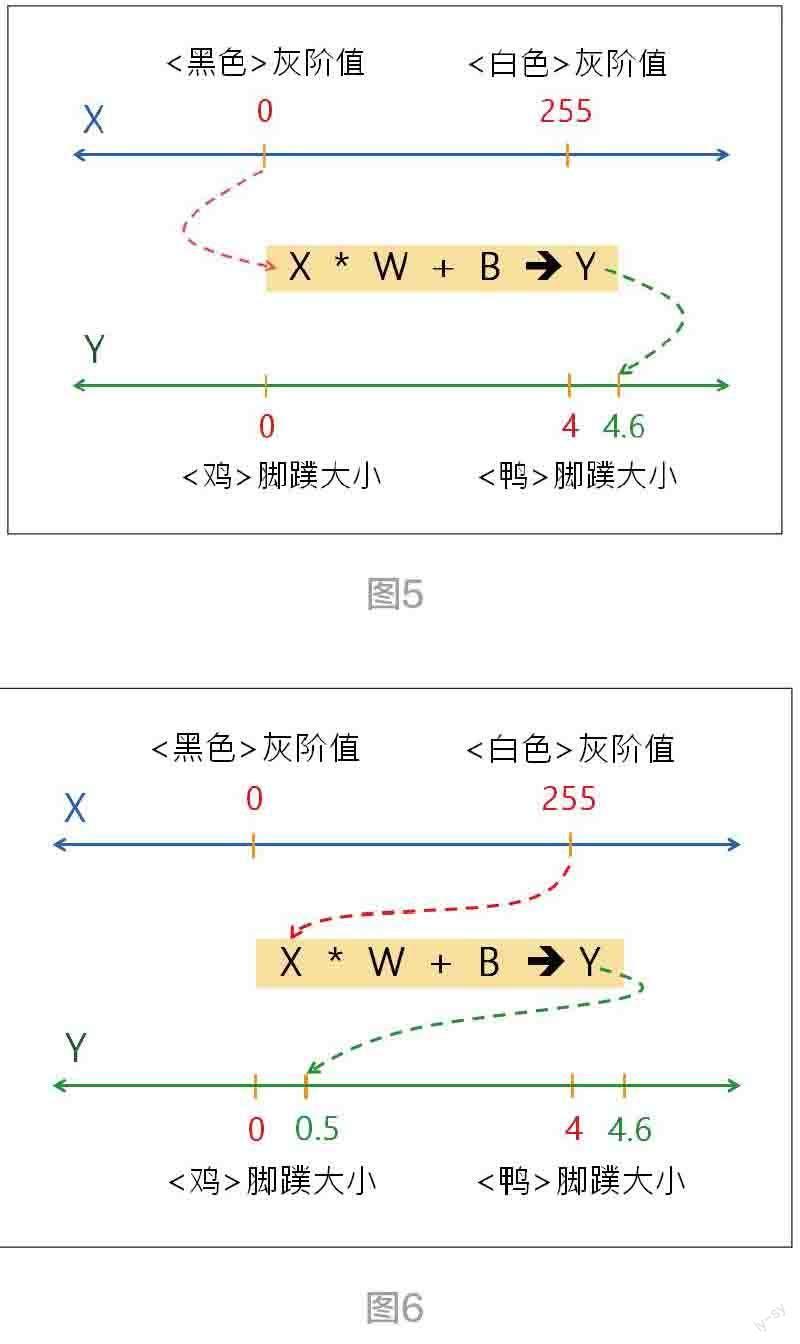
其实,它是依赖一个简单的数学公式:Y = X * W +B。有时候会再添加激活函数,如:Z = Sigmoid(Y)。于是,拿来X = 0,放入公式计算出Y = 4.6 的值( 图5)。
AI 就依赖这些参数( 即W 和B 值) 来记忆这项连连看的智慧。于是,再拿来X = 255,放入公式计算出Y = 0.5 的值( 图6)。
当AI 计算出Y=4.6,很接近于4,就连结到< 鸭> 了,也就凭过去的学习经验和智慧,拿起画笔画出一只黑色鸭了。同样地,AI 计算出Y = 0.5,很接近于0,就连结到< 鸡> 了,也就凭过去的学习经验和智慧,拿起画笔画出一只白色鸡了。这就是AI 绘图创作的源点。
在上述的例子里,白色灰阶值为0,只有1 个特征值(Feature),可以是使用1 维空间表示。同理,当x = [255,100] 时,它即是2 维欧式空间里的一个点。
依此类推,当x = [255, 255, 255] 时,它即是3 维欧式空间里的一个点。在AI 里,就拿欧式空间来表达宇宙中的一切事物或现象。例如,拿欧式空间来表达RGB 色彩,就成为大家熟知的RGB 色彩空间( 图7)。
3 范例演练
此范例里,包含4 张图像,各章都由4个像素(Pixel)所组成( 图8)。
请您练习想想看,在AI 里如何使用欧式空间来表达这4 件事物( 即4 张图) 呢? 答案是:每一张图像有4*3 = 12 个值( 即12 个特征),每一个特征值各在一维度轴上。于是,上述每一张图在12 维欧式空间里,就是一个点。以此类推,这是1 张512 x512 的JPG 图像( 图9)。
请您练习想想看,在AI 里如何使用欧式空间来表达这张图像呢? 答案是: 每一张图像有512*512*3 个值( 即特征),每一个特征值各在一维度轴上。于是,上述这张图在512*512*3维欧式空间里,就是1 个点。
基于上述的基础,接下来,就可来理解一个常见的名词:Embedded 及Embedding 。刚才提到,在这12 维空间里,存放( 記载) 这4张图( 只含4 个点)。似乎有些浪费空间,计算也常比较费时。那么,我们能否把它降维呢?例如,利用5 维空间的4 个点来代表这4 张图,会更省空间。
答案是:可以的。但是,请想一想:5 维空间的每一个点只能含有5 个值( 特征),而上述每一张图有12 个值,该怎么办呢?这个降维过程,就称为:嵌入(Embedding )。即是:高维空间里的点,对应到低维空间里的点。于是,可将两个不同的高维空间里的点,嵌入到同一个低维( 如3 维) 空间里( 图10)。
这表达了,仙剑奇侠传里的“赵灵儿”喜欢“图像-B”,而“李逍遥”喜欢“图像-A”。负责嵌入的模型叫:编码器(Encoder)。
人们想象可观察空间里事物,然后由Encoder 来进行编码,即嵌入到隐空间里,而AI 则对隐空间里的嵌入数据( 通称为:Embedding code) 进行操作,来组合、生成创新的东西( 仍在隐空间里),然后交给Decoder来还原出可观察空间的事物( 如新图像、或新文句等)。例如,更多创新组合( 图11)。
上图里的灰色部分就是隐空间,而Diffusion 就是在这隐空间里,进行图像的组合创新。
4 结束语
深刻领会Encoder 和Decoder 的功能,非常有助于理解AIGC 的涵意。例如,理解Encoder 在进行嵌入到低维空间时,会过滤掉一些讯息。然后Decoder 必需( 依据其所学习的智慧) 把被过滤掉的细节部分弭补起来。
此时,像Diffusion 在隐空间里的创新组合,以及其Decoder 所添加弭补的部分,就是Diffusion 生成的内容。
猜你喜欢
小天使·聪聪画刊(2021年5期)2021-09-10 09:52:16
小天使·聪聪画刊(2021年4期)2021-09-10 07:22:44
小天使·聪聪画刊(2021年3期)2021-09-10 04:12:13
小天使·聪聪画刊(2020年12期)2020-09-10 07:22:44
空间科学学报(2020年5期)2020-04-16 13:55:46
石材(2020年2期)2020-03-16 13:12:56
数学物理学报(2019年6期)2020-01-13 06:08:20
少年漫画(艺术创想)(2019年6期)2019-10-12 07:35:42
中华建设(2019年8期)2019-09-25 08:26:32
大众科学(2016年11期)2016-11-30 15:28:35
