
基于运行工况和多分类支持向量机的柴油机共轨系统诊断方法
2023-07-06 09:51:10黄英王拓裴海俊王健王绪
北京理工大学学报 2023年7期
黄英,王拓,裴海俊,王健,王绪
(北京理工大学 机械与车辆学院,北京 100081)
柴油机作为商用车的主要动力机械设备,因其结构复杂,工作环境恶劣,所以故障率极高.在柴油机产生故障的各个部件中,燃油系统故障所占的比例最高,高达27%[1].因此对燃油系统进行故障诊断是发动机整体健康状态监测的核心内容.高压共轨系统由于其精准的喷油时序控制和超高的喷油压力而被广泛应用,能够对柴油机性能进行全面优化[2].柴油机共轨系统的主要部件有:燃油泵、共轨管、燃油计量阀、喷油器等[3].高压共轨系统常见的故障有燃油泵柱塞卡滞、喷油器堵塞、喷油器电磁阀卡滞、燃油计量阀弹簧预紧力变化等[4].
对于燃油系统的故障诊断国内外已经有了许多研究,主要包括基于振动信号和基于燃油压力信号进行故障诊断.采用振动信号进行故障诊断在内燃机故障诊断领域是一种常见的做法,可以诊断发动机失火、气门故障以及燃油系统故障[5−7].在燃油系统故障诊断方面,张斌等人针对某型柴油机燃油喷射系统故障,提出了一种基于振动信号分析的方法.首先,在时域和频域进行信号特征提取,然后,训练反向传播神经网络对燃油系统6 种不同类型的故障进行分类,文章显示了该方法具有较高的故障诊断精度[8].
另一种方法是采用燃油压力信号对燃油系统进行故障诊断,相较于振动信号,燃油压力信号能够更加直接的反映出燃油系统的健康状态,因此也在燃油系统故障诊断领域得到广泛应用.柯赟等[9]针对喷油器电磁阀失效和喷油器喷嘴堵塞两类故障,采集燃油系统各状态下的轨压数据,并进行层次离散熵处理,运用PWFP 算法对所得层次离散熵进行降维处理,最后建立二叉树支持向量机故障诊断模型,结果显示该方法能够很好的诊断两类故障
如果故障诊断数据来源为台架实验或者仿真实验,其工况设定为稳态工况,传感器采样频率较高,使原始数据的时域和频域特性相对较好,易于进行故障诊断.但在车辆真实运行过程中,工况变动剧烈,同时实车传感器采样频率相对较低,很难将从台架或仿真数据得到的故障诊断模型应用到实际车辆中.针对燃油系统基于实际跑车数据的故障诊断在国内外研究中相对较少,王英敏等[10]采用 Elman 神经网络建立发动机进气压力预测模型,为了体现柴油机的不同工况,选择涵盖不同转速、不同负荷(由油量表征)、不同的发动机工况变化率(由油门表征)下的样本数据,通过统计学残差分析方法,制定故障诊断策略,对传感器偏差故障、彻底失效故障、精度下降故障和漂移故障进行诊断.然而这种通过残差分析来判断对象健康状态的方法对数据采样频率的要求也相对较高,并且一般只能针对一种部件的健康状态进行识别,不能解决涉及多个部件、或多类别的故障诊断问题.
文中针对柴油机共轨系统计量阀复位弹簧松弛和喷油器针阀偶件磨损这一典型的多部件多故障诊断问题,基于低采样频率的实车数据,提出了基于运行工况和多分类支持向量机的故障诊断方法.首先根据车速将实车数据划分为3 类子工况集,并采用层次定比采样方法来构建训练集;其次,运用卡方分析和主成分分析方法(PCA)提取特征参数,并用轮廓系数筛选出敏感子工况集;然后,建立SVM 诊断模型,并运用PSO 算法优化模型参数.最后,通过实车测试数据集对诊断模型精度进行了验证.
1 支持向量机原理
在健康状态识别领域,支持向量机(SVM)能够有效解决非线性、小样本等方面的实际问题,因其良好的分类能力,已经成为健康状态识别领域的常用算法[11].支持向量机(SVM)分类算法的原理就是找到一个分类超平面,要求这个分类超平面不仅能准确地分开样本,而且能使分开样本之间的间隔最大.对于给定的训练数据集:
式中:ui∈Rn为输入数据;vi∈{−1, +1}为输出类别.延伸到多维空间时,求解最优分类超平面的问题转换成求解以下的对偶二次优化问题:
式中:C为惩罚系数;β为拉格朗日乘子;K(ui,uj)为核函数,当样本线性不可分时,SVM 则主要通过核函数将数据样本转化到高维特征空间的线性可分的情况,然后在高维特征空间中求解最优超平面.
2 共轨系统故障诊断流程
文中提出的共轨系统故障诊断流程如图1 所示 ,主要分为数据预处理、故障特征提取、故障诊断模型训练和故障诊断模型验证4 部分.

图1 基于PCA_SVM 故障诊断流程图Fig.1 PCA_SVM based fault diagnosis flow chart
数据预处理:首先对实车采集得到的数据进行数据清洗,考虑到运行工况在不同工况下对故障敏感程度不同,将数据划分为3 个子空间集.故障特征提取:根据卡方检验和机理分析筛选出与故障相关的状态参数,然后通过PCA 融合状态特征和工况参数得到故障特征,最后计算3 个子工况集特征的轮廓系数,并筛选出对故障最敏感的工况作为诊断工况集.故障诊断模型训练:在敏感子工况集建立一对一SVM 故障诊断模型,运用PSO 优化SVM 模型参数.故障诊断模型诊断:通过实车测试数据集对故障诊断模型性能进行验证.
3 实车数据预处理
文中所得数据为同一型号的3 个玉柴某型号商用车实车传感器数据,分别为燃油系统正常、燃油泵计量阀复位弹簧松弛、喷油器针阀偶件磨损3 类健康状态.去除含缺失值和停机时的数据,各健康状态的数据样本量为:正常8 405,计量阀故障5 548,喷油器故障8 644,采样频率为1 s,部分数据样本如表1 所示.

表1 实车采集数据样本(部分)Tab.1 Real vehicle data sample (part)
由表1 可知实车运行工况参数(车速、发动机转速、油门开度等)随时间变动剧烈,难以保证采集得到的数据都在敏感工况内,因此有必要在建立故障诊断模型前对实车数据进行工况划分,以提高诊断精度.
在进行工况划分时,当划分越细致则最终筛选的敏感工况诊断精度越高,但此时敏感工况在车辆循环中占比较低,实车运行时难以达到该工况范围,从而导致实车诊断时测试集数据收集困难的问题.
文中以车速为基础,根据所获取实车数据工况覆盖范围和各工况样本数量,在工况划分时需要涵盖实车数据所有工况,且保证各子工况集样本数量充足,综合考虑所划分子工况的数量与容量,将数据样本划分为低、中、高车速(L,M,H)三个子工况集,具体工况划分情况如表2 所示,并对这三类子工况集分别建立故障诊断模型.在构建训练集时,文中采用层次定比采样方法来构建训练数据集,使用该方法需要先对数据进行分层,按发动机转速和油门开度将3 个子工况集分别划分为9(3×3)层,由三段发动机转速和三段油门开度组合而成,然后根据各层数据在子工况集中的占比进行抽样.与传统的完全随机采样方法相比,使用该方法能够避免训练集过于集中于某个小的工况范围,从而由于实车数据的随机性难以采集到有效数据,并且构建的训练集可以反映真实的数据分布情况,有利于提高故障诊断模型的泛化能力.

表2 实车数据运行工况划分依据Tab.2 Real vehicle data operating condition division basis
4 数据特征提取
4.1 故障相关状态参数筛选
为了减少模型构建中的模型复杂性和训练时间,需要进行特征选择.通常来说,特征选择主要考虑特征与目标的相关性,卡方检验作为一种常用的相关性检验方法,可以检验两个变量之间有无关联,其基本公式为
式中:A为实际频数;T为理论频数;χ为卡方值.
卡方检验一般选择置信度p来作为判断变量是否独立的依据,选择置信度0.05 作为阈值,当p<0.05 时则认为该参数与故障之间相关,将p<0.05 参数作为原始数据中初步筛选特征.表3 为样本集各参数计算的置信度p值.

表3 样本集各置信度p 值Tab.3 Each confidence p-value of the sample set
由卡方检验计算结果,选择计量阀流量、轨压和喷油量作为故障诊断的初步特征.
4.2 PCA 数据特征融合
为了减少各故障特征的冗余信号,同时避免故障诊断过程出现过拟合问题,减少模型训练与诊断时间,运用PCA 方法对状态参数和运行工况参数进行特征融合,将得到的特征值按照贡献率由大到小排列,结果如图2 所示.

图2 主成分分析处理后各特征贡献率Fig.2 Contribution of each feature after processing by PCA
从图中可以得到前三特征值其累计贡献率已经达到97.6%,已经超过了95%,因此选择前三特征值所对应特征向量构建新的特征参数.
4.3 故障敏感子工况集筛选
为了进一步筛选出故障敏感子工况集,对于各子工况集提取的特征进行评价,文中采用轮廓系数来对特征的簇内紧密性和簇间可分性进行评价,其计算式为
式中:s(i)为第i类特征的轮廓系数;a(i)为类别i中同类样本的平均距离,该值反映了样本所属类的特征紧密性,该值越大,则表示同类样本特征越紧凑;b(i)为样本到其他各类样本的平均距离的最小值,该值反映了样本所属类与其他类样本的可区分性.
表4 为低速(L),中速(M),高速(H)3 类子工况集的轮廓系数值,可以看到高速的轮廓系数远大于低速和中速,因此选择高速类子工况集的数据进行故障诊断.

表4 各子工况集轮廓系数Tab.4 Silhouette Coefficient for each subset of working conditions
5 模型训练与验证
5.1 诊断模型框架
文中采用SVM 诊断柴油机共轨系统计量阀复位弹簧松弛和喷油器针阀偶件磨损两类典型故障.由于传统SVM 主要解决二分类问题,为了解决多分类问题采用的方法主要是通过某种方式构造一系列的两类分类器井将它们组合,例如一对多,二叉树,一对一等.
其中一对一方法由于每个分类器只有2 个样本,在训练单个模型时,速度相对较快,适合多分类类别相对较少的情况[12].因此文中选择1 对1 多分类支持向量机作为诊断模型框架.
一对一支持向量机原理如图3 所示,假设有A、B、C3 类数据集,在训练的时候分别建立AB、AC和BC 3 个SVM 模型.在测试的时候,将测试数据分别用每个SVM 进行测试,选取出现次数最多得结果作为最终分类结果.

图3 1 对1 多分类支持向量机框架Fig.3 1 vs 1 multiclassification SVM framework
5.2 故障诊断模型训练
在进行训练数据集划分时,采用层次定比采样方法从L类子工况集中抽取数据,以避免训练数据分布过于集中,同时为了避免不平衡训练样本对训练结果的影响,各类别抽取的训练样本量都为100.
由于 SVM 性能取决于惩罚参数c和径向基函数(RBF)参数g的选择,因此,选择合适的优化算法对两者进行优化是十分必要的.粒子群算法(particle swarm optimization,PSO)有收敛速度快、可调参数少易于实现、适应于动态环境等突出优点[13].因此文中在进行模型训练时,运用PSO 优化 SVM 诊断模型参数.
粒子群优化算法(PSO)的主要思想是首先初始化一组随机粒子,设置适应度函数,然后通过迭代找到最优解,诊断模型训练流程如图4 所示.
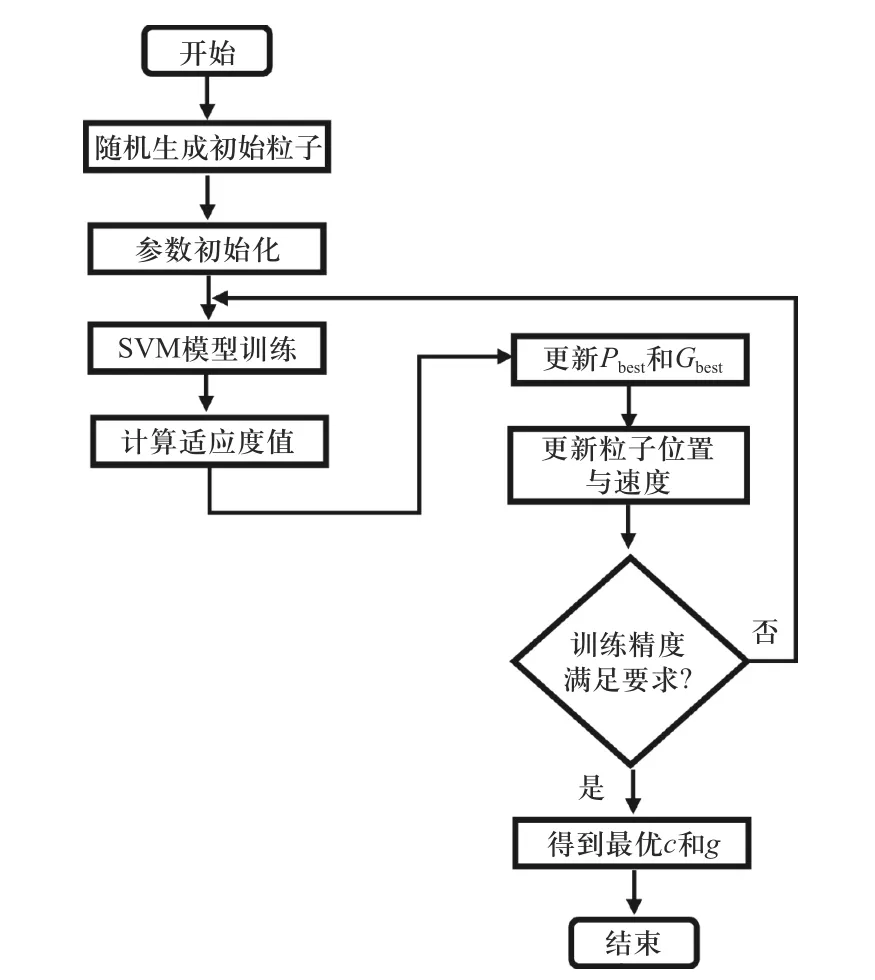
图4 PSO_SVM 流程图Fig.4 PSO_SVM flowchart
文中选择将SVM 的k折交叉验证正确率作为适应度函数[14]选择为5, 并记忆个体与群体所对应的最佳适应值位置为个体极值Pbest和全局极值Gbest,通过追踪Pbest和Gbest,来更新粒子速度和位置.
在运用PSO 对SVM 进行参数优化时,其种群个数为20,终止进化代数为200,惩罚参数c与RBF 参数g的范围均设置在0.01~100 之间,图5(a)为PSO_SVM 训练结果,其中实线为每一代最优正确率,代表每一代粒子个体中最佳适应值,点线为每代的平均最正确率,代表群体的平均适应值,主要用来更新每一代的粒子种群.在75 代时达到最优结果,图5(b)为SVM 的参数优化结果,最终优化结果为惩罚参数c为18.84,RBF 参数g为4.26.
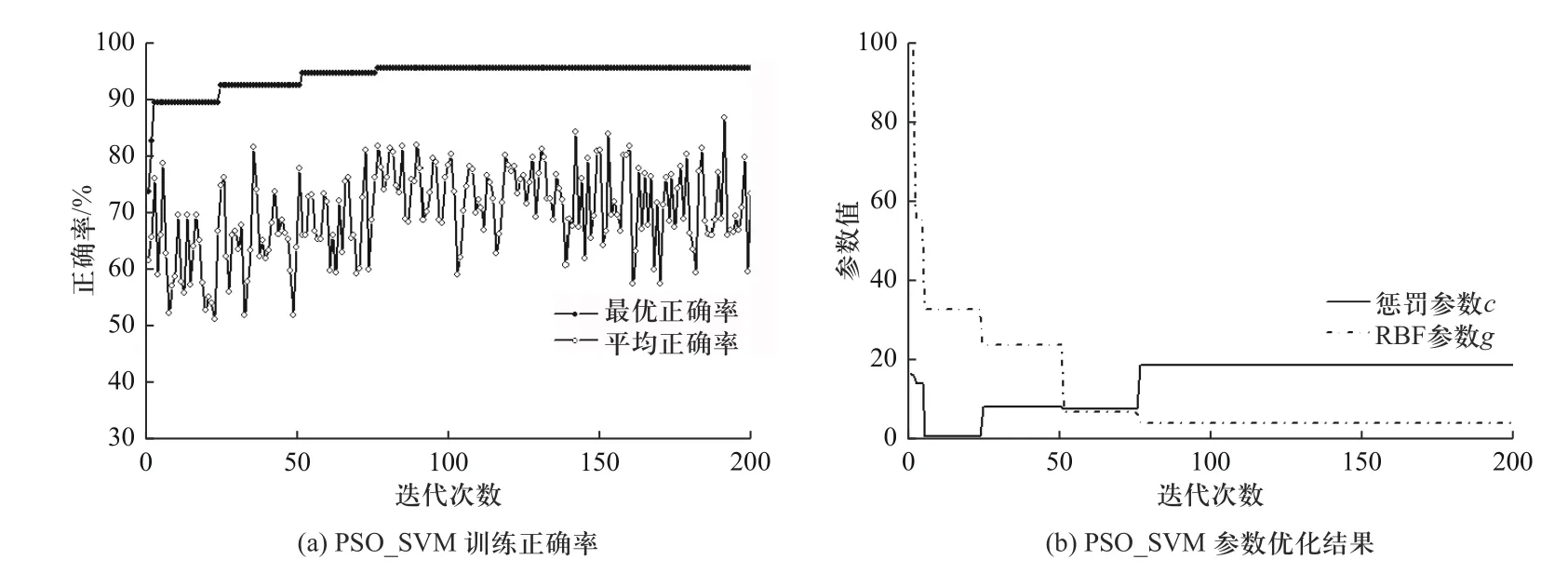
图5 PSO_SVM 训练结果Fig.5 PSO_SVM training results
5.3 故障诊断模型验证
通过训练样本得到模型后,需要通过训练集来验证模型的精度.在H类子工况集中,从三类健康状态数据样本中各选择1 000 个数据(不包含训练数据)作为测试样本,为了不失一般性,从中随机选择50个数据作为单个测试集,共60 个测试集(每类样本20个测试集)对训练得到的SVM 模型精度进行检验.图6 为不同健康状态测试集诊断结果.
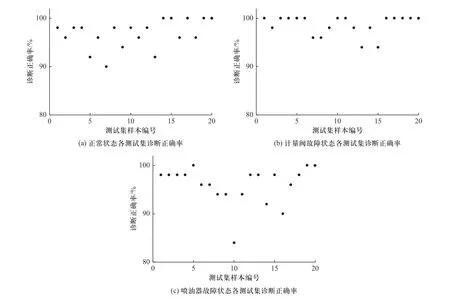
图6 各测试集诊断正确率Fig.6 Correct diagnosis rate of each test set
由图可以看出对于不同健康状态测试样本诊断结果,只有喷油器故障有单个测试集诊断正确率为84%,这是由于测试数据集为随机选取,且数据集样本量为50,该测试集中包含较多油门开度为0 的点,此时油门这个维度的特征被淡化,导致部分样本点分类错误,造成诊断正确率低于90%,其余各测试集诊断正确率基本在90%以上,可以表明该诊断模型满足诊断精度要求,可以完成高压共轨系统故障诊断.
6 结 论
文中采用一对一SVM 对共轨系统计量阀复位弹簧松弛和喷油器针阀偶件磨损这两类故障进行诊断.
首先根据车速将实车数据划分为3 个子工况集,便于筛选出对故障敏感的子工况集.采用卡方检验和机理分析获取与故障最为相关的特征参数,并通过PCA 得到融合特征,并计算各子工况集轮廓系数筛选出敏感工况,确定高速工况为故障敏感工况.通过分层定比采样方法构建训练集,提高SVM 模型泛化能力.对于低采样频率的实车数据,除了燃油系统故障,对于其他系统故障,该方法也能够很好地进行故障特征提取,筛选敏感工况以及训练集构建.
在模型训练时,用PS0 算法来优化SVM 的惩罚参数c和径向基参数g,能够快速获得最优参数.最后用测试数据集对SVM 故障诊断模型进行验证,结果表明SVM 故障诊断模型在突出工况的诊断正确率基本达到90%以上,文中提出的方法能够有效地实现高压共轨系统故障诊断.
猜你喜欢
车主之友(2023年2期)2023-05-22 02:50:34
汽车实用技术(2022年19期)2022-10-19 07:46:24
内燃机与配件(2021年11期)2021-09-10 07:22:44
小哥白尼(野生动物)(2021年3期)2021-07-21 02:28:38
内燃机与配件(2020年20期)2020-09-10 07:53:49
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
汽车维护与修理(2015年6期)2015-02-28 12:17:16
汽车维护与修理(2015年2期)2015-02-28 12:15:44
汽车维护与修理(2015年2期)2015-02-28 12:15:42
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
