
基于Ansible的数据仓库自动化部署研究与实现
2023-06-26 13:11熊超李满刘晓莉秦黄刘晓娟
无线互联科技 2023年8期
关键词:数据仓库
熊超 李满 刘晓莉 秦黄 刘晓娟

摘要:随着大数据时代到来,企业对数据仓库的需求日益增加,一个企业通常需要部署和管理上千台服务器,而数据仓库涉及的配置非常复杂。随着集群的组件逐渐增多,规模逐渐增大,传统的运维方式将不再适用,不仅运维难度大,而且效率较低。因此,为了降低运维的难度,提高效率,文章提出一種通过Ansible来运维管理服务器的方式,利用Ansible的批量系统配置、批量程序部署、批量运行命令等功能,编写Playbook并且集成到roles中,实现数据仓库系统的快速部署,提高企业的工作效率。
关键词:Ansible;数据仓库;自动部署;Hadoop
中图分类号:TP311 文献标志码:A
0 引言
数据仓库是大数据背景下的存储和分析系统,能够支持海量数据的存储和分析,是各大IT企业的重要组件。中国互联网络信息中心(CNNIC)发布的第49次《中国互联网络发展状况统计报告》显示,截至2021年12月,中国网民规模达10.32亿人,较2020年12月增长4 296万人,互联网普及率达73.0%。在如此庞大的网民数量下,每一天都会产生海量的数据,而双十一、618这种购物高峰期的前后一周内,各大互联网企业的用户产生的数据量和订单都会激增,所以各大企业都会在这段时间内临时增加大量服务器。由于在数据仓库集群中,每增删一个服务器都需要对集群中所有节点进行修改,这就导致运维人员在高峰期将面临大量的重复任务。传统的shell脚本运维方式不仅效率低下,而且需要频繁地修改和维护服务器,而Ansible自动化运维,不仅效率高,而且其中的template模块能够对配置文件进行动态修改,完美地解决了高峰期所带来的大量重复任务,减少了运维人员的工作量,提升了运维的效率[1-2]。
1 Ansible的工作原理
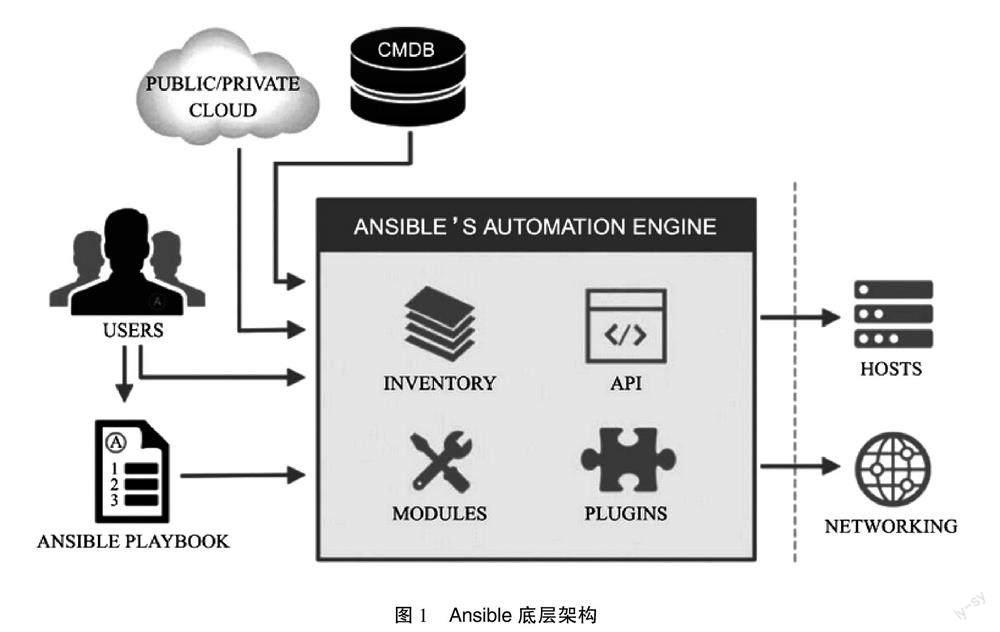
Ansible是基于Python的paramiko模块开发的一款轻量级自动化运维工具(见图1),不遵循Client/agents架构,基于模块化工作,一共有3 387种模块,其中包括Command和shell模块,能够代替shell脚本完成大部分的工作内容。Ansible安装完成之后会生成/etc/ansible/hosts主机清单文件,在执行Ansible命令时,Ansible会访问这个文件拿到相应的所有主机地址,通过SSH来批量执行模块,并且Ansible对shell模块还做了一些优化。通过shell模块远程执行本地脚本的时候,Ansible会自动将脚本拷贝到目标主机执行,完成后还会自动删除脚本文件,即使在执行异常退出时,Ansible也会将远程脚本删除,避免了脚本文件堆积[3-4]。
Ansible有Playbook的定义,Playbook是由一个或多个Play组成的列表。Play的主要功能是将预定义的一组主机,装扮成事先通过Ansible中task定义好的角色。task实际是调用Ansible中的一个模块,将多个Play组织在一个Playbook中,就可以按照一定的顺序执行预定义的动作。
在整个数据仓库集群中,如果需要增加或者减少服务器,就必须修改所有服务器的配置文件,大部分自动化运维工具对此没有很好的解决方案,但是Ansible中的template就完美地解决了这个问题。通过Jinja2语言为每一个配置文件编写一个模板,所有的服务器都根据这个模板进行配置。对于需要变动的部分,Jinja2也提供了循环和分支遍历提前设置好的变量文件进行灵活改变,这样工作人员只需要修改一个文件就可以对所有服务器的配置文件进行更改。
但是在实际生产环境中,用一个Playbook来管理整个数据仓库集群显然是不合理的,如果仅仅需要更新某一个组件,就需要把整个集群都检测一遍。因此,Ansible提出了role的定义,工作人员可以将某一个组件的安装、配置、启动设置成一个role,在批量部署和修改的时候通过调用这个role就能完成这一组件的部署。在需要部署、修改某一组件的时候,工作人员仅需要调用这一组件对应的role,而不是重新部署和配置整个集群。
在文件结构上,每一个role都对应一个文件夹,每一个文件夹都有tasks,files,templates,handlers,vars子文件夹等。其中最主要的就是tasks文件,里面放了很多yml文件,每一个文件都对应一个操作,比如安装、配置和启动等。此外,文件夹中还有一个main.yml文件,main.yml文件决定了操作的执行顺序,将需要执行的yml文件按照执行顺序从上到下依次声明,在role执行的时候就会按照顺序调用对应的yml文件,从而完成整个组件的部署和修改。
2 数据仓库集群部署规划
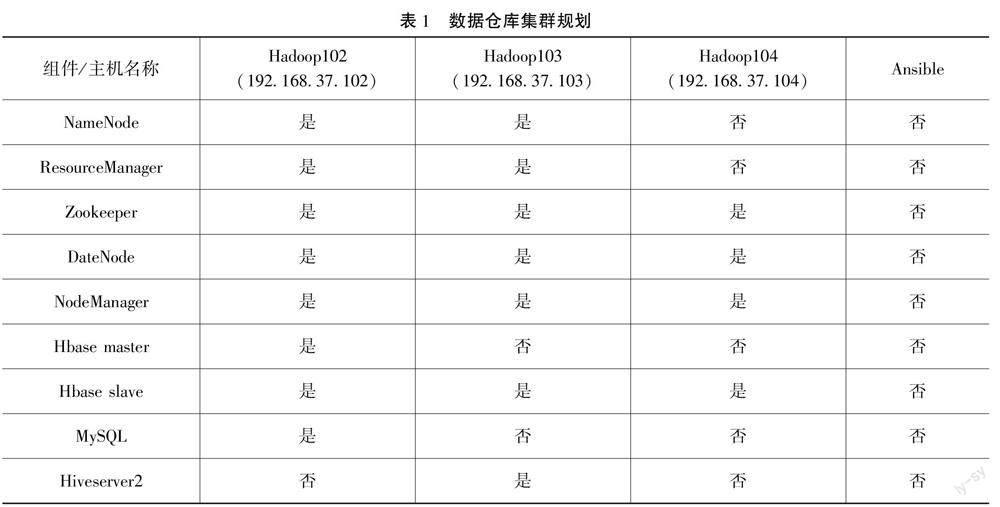
Ansible部署数据仓库集群的过程非常灵活,只需要根据集群规划(见表1),为每一个组件编写role,再依次执行就能完成整个集群的部署。
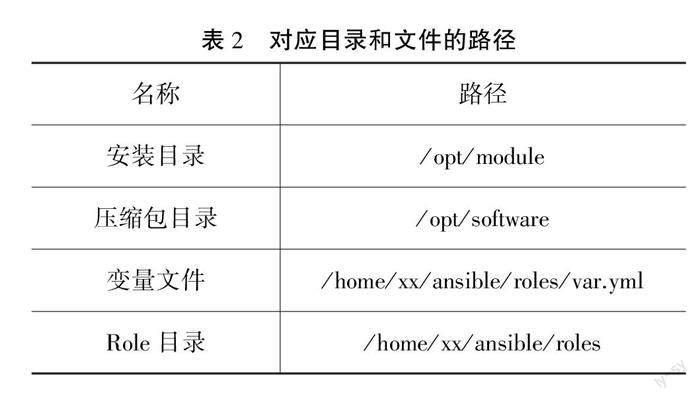
为了方便统一管理,提前确定好组件压缩包目录、安装目录、变量文件以及对应组件的压缩包名称和安装名称,如表2—3所示。
3 Ansible自动化部署过程
3.1 基础环境配置
关键配置主要包括:(1)配置SSH免密连接,需要Ansible节点对集群所有节点免密登录。(2)Ansible节点安装Ansible。(3)准备集群需要的所有组件的压缩包。此外还需要完成系统的一些基础配置,这些基础配置也都可以通过Ansible来批量完成,例如:执行ansible all -m shell -a “sed -i’s/SELINUX=.*/SELINUX=disabled’ /etc/selinux/config”,设置selinux永久关闭、执行ansible all -m shell-a “systemctl stop firewalld”、ansible all -m shell-a “systemctl disable firewalld”关闭防火墙并关闭开机自动开启,执行ansible all -m copy -a “src=path to hosts dest=/etc/hosts”为所有主机添加主机映射等。
3.2 编写role并测试
工作人员创建一个roles目录,在该目录中创建需要部署的组件的子目录:Hadoop,zookeeper,Kafka,Flume,Hive,Sqoop,Spark,Hbase,并在每个子目录中创建files,handlers,tasks,templates目录。在编写role之前创建一个全局的变量文件vars.yml,设置一个包括集群所有节点IP的数组和每个组件所在节点的IP,并且设置一些常用的变量,方便在需要的时候进行修改。组件的部署流程大致分为3个步骤——解压、修改配置文件、启动,分别对应tasks目录中的3个yml文件:install.yml,config.yml,start.yml。除此之外,还有配置文件的模板文件,Ansible通过模板文件来动态修改配置文件。
4 Ansible部署和测试
编写好的role不能直接执行,在Ansible架构中只提供了单个模块的执行命令(ansible)和Playbook的执行命令(ansible-playbook)。想要执行role必须通过Playbook来调用role,示例如下:
---
- hosts: all
remote_user: xx
vars_files:
- /home/xx/ansible/roles/vars.yml
- ...
roles:
- { role: hadoop ,tags: ['hadoop'] }
- { role: spark-standalone ,tags: ['spark-standalone'] }
- { role: zookeeper ,tags: ['zookeeper']}
- { role: kafka ,tags: ['kafka'] }
Playbook的核心元素包括Hosts(主机清单)、tasks(任务集)、Variables(内置变量或者自定义变量)、roles(角色集)、tags(标签)等。调用role的时候必须声明hosts,roles,如果设置了外部变量文件则必须添加vars_files,引入变量文件,如果需要用到其他用户执行role,可以添加“remote_user: xx”指定连接的用户,前提是当前用户对目标主机能够通过SSH免密登录。
在执行Playbook之前,通常会在ansible-playbook命令后面加上“--syntax-check”或者“-C”对Playbook进行语法检测和测试运行,当确认无误后再真正执行部署命令。在Playbook执行过程中,蓝色的部分表示该步骤跳过执行,绿色的部分表示执行成功并且不需要做改变的操作,黄色的部分表示执行成功并且对目标主机做变更,红色的部分表示执行失败。
5 结语
市面上有很多专门做数据仓库运维和自动部署的集成工具,比如Ambari和CDH,虽然很方便,功能也比较多,但是不够灵活。对于Ambari和CDH这种平台级工具而言,想要進行组件更新非常复杂,必须重新编译Ambari的源码才能完成对单个组件的更新。就这一点而言,Ansible很好地解决了这个问题,不仅自身部署灵活,而且各个组件之间的角色互相独立。不仅如此,Ansible是一个开源的工具,对于大数据的初学者而言这是一个不错的选择,而且Ansible的部署流程比较偏向底层,在部署过程中能够让初学者很清晰地了解到整个数仓的架构。
参考文献
[1]李沁蔓.基于Ansible的服务器自动化运维技术研究与实现[J].电子设计工程,2020(13):23-26,31.
[2]范永合,杨澎涛,朱应科,等.基于Ansible实现Zabbix自动部署[J].电脑知识与技术,2019(35):260-261.
[3]李湘林,向全,韦美雁,等.基于Ansible自动化运维系统批量部署LAMP架构的设计与实现[J].大众科技,2021(3):1-4.
[4]赵创业,唐亮亮,郭威,等.基于Ansible和Flume的海量数据自动化采集系统[J].电子设计工程,2020(3):47-51.
(编辑 王雪芬)
Research and implementation of data warehouse automation deployment based on Ansible
Xiong Chao, Li Man*, Liu Xiaoli, Qin Huang, Liu Xiaojuan
(Guangzhou College of Technology and Business, Guangzhou 510000, China)
Abstract: As the big data era, the enterprise growing demand for data warehouse, an enterprise usually need to deploy and manage thousands of servers, which involves the configuration of the data warehouse is very complex, as the big data era, enterprise growing demand for data warehouse, an enterprise usually need to deploy and manage thousands of servers, which involves the configuration of the data warehouse is very complicated, As the components of the cluster gradually increase and the scale gradually increases, the traditional operation and maintenance methods will no longer be applicable, which is not only difficult to operate and maintain, but also inefficient. Therefore, in order to reduce the difficulty of operation and maintenance and increase the efficiency, this paper proposes a way to operate and maintain the server through Ansible. Using the functions of batch system configuration, batch program deployment and batch command running of Ansible, the Playbook is written and integrated into roles to realize the rapid deployment of the data warehouse system, increase the work efficiency of the enterprise.
Key words: Ansible; the data warehouse; automatic deployment; Hadoop
猜你喜欢
电子乐园·下旬刊(2021年3期)2021-02-08
自然资源信息化(2019年4期)2019-03-29
录井工程(2017年3期)2018-01-22
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
