
基于LDA主题模型的某品牌手机评论数据分析
2023-06-22 05:52:32吴楠楠石家程刘胜强
现代信息科技 2023年2期
关键词:品牌手机
吴楠楠 石家程 刘胜强


摘 要:在互联网高度发展和智能技术普及的大环境下,电商平台出现了大量的评论数据,它们对挖掘用户需求和建立商品口碑具有重要价值。文章爬取了京东电商平台上某品牌手机的评论数据,并基于预处理之后的数据进行了倾向性分析和LDA主题模型分析。研究结果表明,该品牌手机具有外观好看、充电快、性价比高和拍照功能强大等优势,但也有新品定价偏贵、保值率低、售后服务差、部分包装零件不全等不足之处。所得结论为该品牌手机升级提供一定的参考依据。
关键词:倾向性分析;LDA主题模型;品牌手机
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2023)02-0012-03
Analysis of Comment Data of a Brand Mobile Phone Based on LDA Theme Model
WU Nannan, SHI Jiacheng, LIU Shengqiang
(School of Mathematical & Computing Science, Guilin University of Electronic Technology, Guilin 541004, China)
Abstract: In the context of the high development of the Internet and the popularization of intelligent technology, a large number of review data have emerged on E-commerce platforms, which are of great value in mining user needs and establishing product reputation. It crawls the review data of a brand's mobile phone on JD E-commerce platform, and conducts a tendentiousness analysis and LDA theme model analysis based on the pre processed data. The research results show that the mobile phone of this brand has the advantages of good-looking appearance, fast charging, high cost performance and strong photographing function, but it also has the disadvantages of expensive new product pricing, low value preservation rate, poor after-sales service, and incomplete parts of some packaging. The conclusion provides a reference for the upgrading of the mobile phone of this brand.
Keywords: tendentiousness analysis; LDA theme model; brand mobile phone
0 引 言
隨着互联网的高度发展以及智能技术的普及,网络购物已成为一种热潮,也成为人们购物的一种主要方式。电商评论数据是指用户在电商平台完成购物后,对已购买的商品进行评论所产生的文本数据,这些数据里蕴涵了顾客购买后的主观感受,反映了购买者对商品及服务的态度、立场和意见,因此这些评论数据也是潜在客户在购物之前的决策参考,从而越来越多的商家和顾客关注电商评论数据[1]。倾向性分析是指通过分析和归纳用户对事件或商品的评论文本,进而发现或找到用户所持有的观点[2]。因此,倾向性分析能从用户的评论数据中挖掘出顾客的主观感受,这些感受或信息可以帮助商家改善自身缺点,提高其服务质量,从而吸引更多顾客购买。
某品牌手机作为中国乃至全世界的知名品牌手机,它的发展属于中高端市场,虽然在国外的发展中具有一定的优势,但在国内的市场中所占份额不大,这说明中国手机行业的竞争非常激烈,同时该品牌手机在国内市场中也存在某些竞争劣势。为能挖掘出该品牌手机在国内市场上的优势和不足之处,本文对该品牌手机电商进行了倾向性分析以及LDA主题模型分析。
1 LDA主题模型的简介
LDA主题模型,即潜在狄利克雷分配,由Blei等人在2003年提出[3],该模型对词汇、主题和文档的三层结构进行贝叶斯概率分布,认为每个文档由多个主题构成,每个主题由多个特征词汇构成,文档中的每个词汇都是按照“以一定的概率选择了某个主题,并从该主题中以一定的概率选择了某个词汇”的方式来获得,将上述步骤重复即可获得整个文档[4]。
LDA模型一种采用词袋的模型,它将每个文档视为词频向量,并将文本信息转换为易于建模的数字信息。LDA主题模型基于三个假设[5]:
(1)假设某一商品的评论集D由M篇评论(文档)构成,记为D=d1, d2,…, dM;每篇评论(文档)中存在K个互相独立的主题Zm,i(i=1, 2,…, K),并由K个主题随机混合组成;每个主题下由N个词wm,n(n=1, 2,…, N)构成评论,每个词是一个L维向量(1, 0, 0, …, 0, 0)。
(2)每篇评论(文档)在主题上服从多项式分布,每个主题在单个词上服从多项式分布。
(3)每一篇文档在主题上的多项式分布的先验分布是参数为α的Dirichlet分布,每一个主题在词汇上的多项式分布的先验分布是参数为β的Dirichlet分布。在以上假设下,对于评论(文档)集D中的评论(文档)dm,LDA模型生成文本的方式如下[3,5,6]:
1)从参数为α的Dirichlet分布中进行采样,生成第m个评论(文档)的主题多项式分布θm。
2)从主题多项式分布θm中进行采样,生成第m个评论(文档)第n个词汇的主题Zm,n。
3)从参数为β的Dirichlet分布中进行采样,生成主题Zm,n所对应的词汇多项式分布φk。
4)从φk中进行采样,最终生成汇wm,n,其中,m∈[1, M ],n∈[1, Nm],k∈[1, K ],M为待处理评论(文档)数,Nm为第m个文本的总词汇数,K为待分类主题数。
LDA主题模型可采用变分最大期望法或Gibbs抽样方法进行参数估计,训练出图1中文本的主题分布概率θm以及主题对应的词汇分布概率φk[6]。
2 实证分析
2.1 数据的获取与预处理
本文通过Python软件对“京东商城”中“某品牌手机销售”商品的评论数据的爬取,主要爬取评论数据中的好评与差评数据,约800条。在京东商城平台上,若电商产品在用户确认收货的一段时间后未给出评价,则系统会默认好评,这种文本数据对本文的分析无实质作用,故需删除。同时,论中夹杂着许多数字与字母,以及较高频率出现“京东”“京东商城”等词,但它们对本次分析也无实质作用,因此在分词之前也将这些数据清洗掉。
2.2 倾向性分析
2.2.1 匹配倾向性词
在商品评论中,可以理解为用户对该商品表达自身观点所持的态度是支持、反对还是中立。本文采用2007年10月知网分布的“倾向性分析用词(beta版)”词典匹配的方法,主要使用“中文正面评价”“中文负面评价”词表。将每个“中文正面评价”词语赋予初始权重1,作为本文的正面评价表;将每个“中文负面评价”赋予每个词语初始权值-1,作为本文的负面评价表。
在匹配评价词的时候,较多词语在网络购物评论上出现,但不在本次匹配表的词库中,因此要进行词语的优化。例如“满意”“好评”“很快”“还好”“还行”等根据词语倾向添加至对应的中文正面词表内;同样的,将“差评”“贵”“问题”等词语添加到中文负面词表内。
2.2.2 修正倾向性词语
词语的倾向性修正是指通过查看倾向性词的前两个位置的词中是否具有否定词来判断倾向性词的正确性,如果存在否定詞,则当否定词出现奇数次时,表示否定意义,将该词调整为相反的倾向性词性;而当否定词出现偶数次时,表示的是肯定词性,此时不需要调整词性。如果倾向性词的前两个位置的词中没有否定词,则也不需要调整词性。本次分析所使用的否定词主要有19个,分别是:不、没有、无、非、莫等。
2.2.3 检验倾向性词分析结果
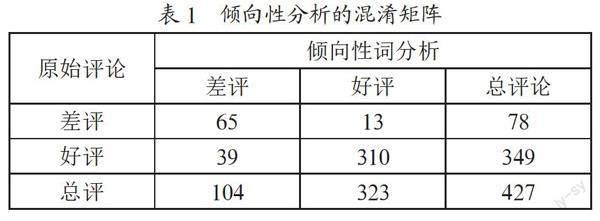
将原始评论的评论类型与基于词表的倾向性词分析进行比较,得到评论类型的混淆矩阵,如表1所示。在不存在选好评的标签而写了差评内容的情况下,基于词表的倾向性词分析的准确率为87.82%,这表明通过词表的倾向性词分析去判断某文档的倾向程度是有效的。
2.3 基于LDA模型的主题分析
运用LDA主题模型,可以求得词汇在主题中的概率分布,并获得属于该主题的概率及同一主题下的其他特征词,从而解决多个指代的问题。
计算主题间的平均余弦距离,该值最小,则相对应的主题数最优。正面评论和负面评论主题间平均余弦距离图分别如图2和图3所示。图2中横轴代表主题数,纵轴代表平均余弦,该图表示当主题数为3时主题间的平均余弦相似度。因此,对于正面评论数据做LDA模型分析时,主题数为3。同理,由图3可得,负面评论数,当主题数为4时,主题间的平均余弦相似度最低。
使用Python语言gensim库和LdaModel库下的LDA l函数,对正面评论数据和负面评论数据分别构建LDA主题模型。经过LDA主题分析后,在每个主题下生成10个最有可能出现的词语,随后对主题分析的结果进行评价,潜在的正负面主题分别如表2和表3所示。
由表2可知,主题1中的高频特征词主要是:不错、屏幕、清晰、效果、很快、充电等,主要反映了该品牌手机屏幕显示效果清晰,充电速度很快;主题2中的高频特征词主要是:拍照、好看、流畅、价格、性价比等,主要反映了该品牌手机拍照功能强大,深受用户喜爱,且性价比高;主题3中的高频特征词主要是:外观、运行、快、物流、满意等、主要反映了该品牌手机外观好看,运行速度快、物流快。
由表3可知,主题1中的高频特征词主要是:卡、降价、使用、价格等,主要反映了该品牌手机有卡顿现象,降价快,保值率低;主题2中的高频特征词主要是:慢、反应、时间、发现、无充等,主要反映了该品牌手机反应慢,存在有些包装没有配套充电器的问题;主题3中的高频特征词主要是:不好、贵、客服、差评等,主要反映了该品牌手机贵,客服态度不好的问题;主题4中的高频特征词主要是:感觉、网络、差评等,主要反映了该品牌手机存在用户购买体验较差的问题。
综合以上对主题及其中对高频特征词的分析得出,该品牌手机的优势主要有以下几个方面:外观好看、充电快、性价比高、拍照功能强大等。相对而言,用户对该品牌手机的抱怨点主要在新品定价偏贵、保值率低、售后服务差、部分包装零件不全等。
3 结 论
本文采用LDA模型对京东网站的某品牌手机的评论数据进行了文本分析。由正面倾向性词分析得出用户对该手机品牌的评论主要是外观好看、充电快、性价比高、拍照功能强大等。可以看出,用户对该电商产品的品质还是认可的,这些被用户认可的地方,应继续加强管理,让产品在众多商品中脱颖而出。由负面倾向性词的研究分析得出该品牌手机的新品定价偏贵、保值率低、售后服务差、部分包装零件不全等。
本文的研究结论为该品牌手机升级提供了一定的参考依据。
参考文献:
[1] 刘玉林,菅利荣.基于文本情感分析的电商在线评论数据挖掘 [J].统计与信息论坛,2018,33(12):119-124.
[2] 李天辰,殷建平.基于主题聚类的情感极性判别方法 [J].计算机科学与探索,2016,10(7):989-994.
[3] BLEI D M,NG A Y,JORDAN M I. Latent Dirichlet Allocation [J].Journal of Machine Learning Research,2003(3):993-1022.
[4] 王鹏飞,张斌.基于文献计量的国内LDA主题模型研究进展分析 [J].图文情报研究,2020,13(2):85-91+111.
[5] 王丽君.词向量和文本隐含主题的联合学习研究 [D].武汉:华中师范大学,2018.
[6] 袁扬,李晓,杨雅婷.基于LDA主题模型的维吾尔语无监督词义消岐 [J].厦门大学学报:自然科学报,2020,59(2),198-205.
作者简介:吴楠楠(2002.05—),男,汉族,湖北武穴人,本科在读,研究方向:数据分析;石家程(2001.11—),男,汉族,海南乐东人,本科在读,研究方向:数据分析;刘胜强(1998.01—),男,汉族,广西桂林人,JAVA技术顾问,本科,研究方向:软件开发。
收稿日期:2022-09-06
基金项目:广西大学生创新创业项目(201910595202)
猜你喜欢
设计(2023年16期)2023-09-01 16:25:20
检察风云(2023年11期)2023-06-21 11:39:30
电脑爱好者(2020年13期)2020-08-17 16:09:29
中国防伪报道(2020年10期)2020-01-08 02:17:30
中国计算机报(2018年49期)2018-02-24 02:44:06
初中生(2016年16期)2016-07-14 02:50:58
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:33
通信世界(2014年17期)2014-09-04 01:31:50
通信世界(2013年19期)2013-02-14 19:40:23
通信世界(2012年47期)2012-07-10 10:19:56
