
双路径多尺度混合感知语音分离模型
2023-06-21 17:44:23刘雄涛周书民方江雄
现代信息科技 2023年1期
刘雄涛 周书民 方江雄


摘 要:单通道语音分离主要采用循环神经网络或卷积神经网络对语音序列建模,但这些方法都存在对较长停顿的语音序列建模困难的问题。提出一种双路径多尺度多层感知混合分离网络(DPMNet)去解决这个问题。提出多尺度上下文感知建模方法,将三个不同时间尺度的输入通道特征融合。与传统的方法相比,加入全连接层以弱化噪音的干扰,卷积和全连接的交叉融合增加了模型的感受野,强化了长序列建模能力。实验表明,这种双路径多尺度混合感知的方案拥有更少的参数,在Libri2mix及其实验嘈杂的版本WHAM!,以及课堂真实数据的ICSSD都表明DPMNet始终优于其他先进的模型。
关键词:多尺度上下文建模;混合感知;全连接层;双路径网络;语音分离
中图分类号:TP18 文献标识码:A 文章编号:2096-4706(2023)01-0008-06
Dual-Path Multi-Scale Hybrid Perceptual Speech Separation Model
LIU Xiongtao1, ZHOU Shumin1, FANG Jiangxiong2
(1.Jiangxi Engineering Research Center of Process and Equipment for New Energy, East China University of Technology, Nanchang 330013, China; 2.School of Electronics and Information Engineering, Taizhou University, Taizhou 318000, China)
Abstract: Single-channel speech separation mainly uses recurrent neural networks or convolutional neural networks to model speech sequences, but these methods all have the problem of difficulty in modeling speech sequences with longer pauses. A dual-path multi-scale multi-layer perceptual hybrid separation network (DPMNet) is proposed to solve this problem. A multi-scale context-aware modeling method is proposed to fuse the input channel features of three different time scales. Compared with the traditional method, adding the fully connected layer could weaken the interference of noise. And the cross-fusion of convolution and fully connected increases the receptive field of the model and strengthens the modeling ability of long sequences. Experiments show that this dual-path multi-scale hybrid perceptual scheme has a fewer parameters. In Libri2mix and its experimental noisy version WHAM!, as well as ICSSD on real classroom data show that DPMNet consistently outperforms other advanced models.
Keywords: multi-scale context modeling; hybrid perception; fully connected layer; dual-path network; speech separation
0 引 言
語音分离技术常被称为鸡尾酒会问题[1],旨在从多个混合语音中提取单个说话人语音,噪声条件下的语音分离是其重要组成部分。近年来,基于深度学习的时域语音分离方法得到了研究人员的关注,传统的语音分离是在时频中完成的(T-F)域[2-4]。为解决相位重构以及STFT延迟的问题,基于时域的卷积音频分离网络被提出。
一方面,Tasnet采用“编码器-解码器”框架,这种方法省去了时域转频域步骤,并将分离问题转换成掩码问题[5]。但是,LSTM存在长序列梯度消失和无法并行计算的问题。使用TCN[6]代替LSTM的Conv-Tasnet在解决这些问题的同时拥有更灵活的感受野[7]。深度可分离卷积将原先的一种卷积操作,变为两个卷积操作,可以大大地减小参数量。使用最大化最佳尺度不变信噪比(OSI-SNR)[8]通过在训练时学习潜在目标分离模块,更好的解释了时域损失函数[9]。为了解决混乱场景分离效果不好的问题,Stacked-LSTM网络[10]将长序列输入划分为更小的块并堆叠在一起,相比于TCN收敛更快,模型更小,但是分离速度较慢。为了提高卷积网络中语音特征提取的准确率,减少卷积和池化运算导致有效信息丢失,使用胶囊网络在Conformer模型中引入了动态进程机制[11]。另外,在FurcaNeXt[12]、SuDoRM-RF[13]、SpEx[14]和SpEx+[15]模型中融合了在不同时间尺度上进行语音编码的方法,称为多尺度融合(MSF),相比单个分辨率能够更好地还原原始特征[15,16],能够更好地提高语音分离效果。
另一方面,由于Conv-TasNet使用固定的时间上下文长度[7],因此对单个说话者的长期跟踪可能会失败,尤其是当句子中存在较长停顿时。当输入长序列数据集,由于一维卷积的感受野较小导致无法对话语间的关系进行建模,双路径递归神经网络(DPRNN)通过将长序列拆分成小块进行块内和块间操作[17]。使用多尺度Loss函数以及把单个双向LSTM换成了平行的两个LSTM实现了对多个说话人的语音分离[18]。目前主要的语音分离模型通常基于循环神经网络(RNN)或卷积神经网络(CNN)不能直接根据上下文对语音序列进行建模[19],从而导致次优的分离性能。例如,基于RNN的模型需要通过许多中间状态传递信息。基于CNN的模型存在感受野有限的问题。幸运的是,基于自注意力机制的Transformer可以有效地解决这个问题[20],其中输入的元素可以直接交互。但Transformer通常的数据长度与端到端时域语音分离系统相比较短,双路径网络是解决极长输入序列建模的有效方法[17]。
值得注意的是,基于自注意力的架构,尤其是Transformer被证实能够很好地实现语音分离任务[20-23]。随着ViT[24]结构的在CV领域的爆火,基于mlp的改进将CNN和Transformers有效结合起来[25,26]的方法,在保证较小模型尺寸的情况下提高分离效果。MLP-Mixer,一个完全基于MLPs的结构,其MLPs有两种类型,分别是channel-mixing MLPs和token-mixing MLPs,前者独立作用于image patches融合通道信息,后者跨image patches融合空间信息。
在本研究中,为了解决上述问题,提出双路径多尺度多层感知混合分离网络DPMNet,包含语音编码器,分离网络,语音解码器。具体来说,语音编码器包含短、中、长三个不同尺度的采集窗口,将这些包含更多的长时间信息的不同尺度语音特征转换成中间特征。分离网络主要分析编码器的输出数据,得到各个源的掩码。其中分别包含块内和块间的卷积和全连接层,用于融合不同空间的语音特征,同时为了提高了模型的映射能力,降低训练难度,使用残差网络连接。最后中间特征与每个源的掩码进行元素级相乘,解码器将重构每个源的波形。
本文的其余部分安排如下。第一节提出了使用多尺度卷积编码器实现的不同时间域内的特征融合,介绍分离网络混合感知的方法。实验的具体设置在第二节中说明。第三节显示实验结果。第四节得出结论。
1 模型
1.1 整体结构
DPMNet模型如图1所示,由语音编码器,分离网络和解码器组成。该模型结构与Conv-Tasnet[7]类似,在此基础上,为了更好地表现长语音结构特征,语音编码器由L1、L2、L3三个不同大小的一维卷积组成,得到的多分辨率特征数据送到分离网络中,通过分析得到不同说话人的掩码。解码器窗口与编码器的参数相同,但是由三个转置一维卷积构成。分离器中包含一个块内和块间感知层,分别由一维卷积和线性层组成,并通过残差连接串联在一起。其他部分还包含Dropout层Groupnorm层等。最后语音解码器通过解码还原各个说话人的语音波形。接下来将展开介绍编码器,双路径混合感知分离网络和解码器。
1.2 语音编码器
由于单个卷积层的窗口相对固定,且当语音长度较长且句子中存在较长停顿时,单个的卷积无法准确地表现这些信息,所以本文中采用三个不同的窗口大小的卷积分别采集不同时间跨度的信息[15],最后对信息进行融合,这在保证信息不变的情况下能够更好地反应句子中的细节问题。
语音编码器由几个并行的1-D具有不同滤波器长度的CNN会产生不同的时间分辨率。虽然多个尺度的数量可以因人而异,本文只研究三种不同的尺度。如果用X来表示输入的混合语音,L来表示三个卷积的窗口的话,则编码器中的声音信号WK将用如下公式表示:
WK=ReLU(X*LK,K∈(1,2,3) (1)
通过设置三个不同的时间窗口大小L1(short),L2(middle),L3(long),来实现句子中不同长度的特征关联,步长分别是其窗口的一般。为了避免大小不同的数据直接相加造成的信息错乱,在较短的数据后面补充对分离效果不产生影响的数据,最后通过如下公式将数据整合得到编码器的输出Xe。
Xe=cat(W1,W2,W3) (2)
1.3 分离网络
分离网络结构如图2所示,由块内mlp和块间mlp组成,之间通过残差连接,网络中由K个模块串联在一起。mlp block包含线性层、Layernorm层、Dropout层以及两个mlp层,其中可以为一维卷积或者全连接层。采用残差连接將线性层的输出与第二个dropout层的输出叠加。
首先,通过分块(Segmentation)将二维的语音数据变换成三维数据。若原始音频长度为L,宽度为C=1,则经过分块之后形成的长宽高分别为2P,S,C。其中P为分块的长度,为了之后的切片(patch)的方便,这里设置2P和S是patch_size的整数倍,且他们相等。关系如下,其中Xe表示编码器输出,XS表示经过分块的模型输出。
XS=Segmention(Xe,Patch_size,S,C) (3)
分离网络由块内的mlp和块与块之间的mlp,通过与ViT[24]相似的拆分思想,将按照默认patch_size=16,长与宽为16×16的大小将数据进行切分,将其展开成一条直线。通过块内的mlp计算每个patch内语音的相关性,利用卷积操作在数据之间计算相关性。采用mlp的方式在较长的数据长度内计算句子相关性,方便网络对较长句子停顿的情况进行建模。为了更好地保留原始特征的比重,使用大量使用残差连接弥补模型计算过程中的数据丢失。分离网络中,块内mlp可以用Wr表示,Xseperate表示经过分离网络之后的模型输出。
分离网络的关系如下:
Wr=XS+row_mlp(XS) (4)
Wseperate=Xr+col_mlp(Xr) (5)
XO=Xseperate*Xe (6)
最后,使用二维卷积层为每个源计算一个掩码。分离网络的输出Xseperate与原始混合音频的特征数据Xe之间计算元素乘法得到每个源的波形。
1.4 语音解码器
一维卷积形式的解码器只需要通过转置计算即可得到分离完成的语音波形,但是在这篇文章中,首先需要通过逆向的切片运算把三维数据转换为二维音频数据。之后将每条通道中的数据与编码器中的三个不同时间窗口的一维卷积进行逆向运算,LT为卷积模型的转置参数,计算方式如下:
Xoutput_K=ReLU(X*LTK, K∈(1,2,3) (7)
最后将三个通道内的数据叠加在一起得到不同说话人的语音波形。
2 实验
2.1 数据集
Libri2Mix-K:Libri2Mix[27]由两个或三个扬声器的混合以及来自WHAM![28]的环境噪声样本组成。该数据集是使用train-100、train-360、dev和测试集构建的LibriSpeech数据集[29]。使用train-100作为训练集,生成两个说话人的音频数据,大约41个小时,包含13 900条语音数据。测试集大约6个小时,包含3 000条语音数据,来自Librispeech的del数据。采样率为16 kHz。为了保证对比的可行性,使用相同的数据对不同的模型进行测试。
Libri2Mix-N:这个数据集同样由LibriSpeech[29]与WHAM![28]生成。通过将咖啡馆、餐厅和酒吧等环境噪声与Libri2Mix混合在一起,SNR在-6 dB和3 dB,数据规模上与Libri2Mix数据集相同。该数据集是为了与Libri2Mix数据集形成对比,证明模型在噪音条件下的泛用性。
ICSSD:此数据集是本文提出的基于课堂的语音数据集,通过采集课堂中的声音信息生成包含mix、noise、student和teacher四个部分数据,采样率为16 kHz。训练集大约7小时,包含6 000条语音数据。测试集大约1小时,包含1 000条语音数据。与前两个数据集不同的是本数据集中的语音为中文,而前两个为英文。其次本数据集中的噪音包含教室铃声和与语音无关的学生窃窃私语声等,更符合模型的实际使用情况。
2.2 实施细节
编码器和解码器分别采用三个一维卷积和三个转置一维卷积,在默认情况下,卷机核大小(kernel_size)分别为L1=10,L2=50,L3=100,步长分别是其窗口大小的一半,卷积产生的通道数为256,这与后面的块大小(patch_size)有关。
每个模型都在Libri2Mix-K、Libri2Mix-N和ICSSD三个数据集上训练20个epoch,采样率为16 kHz,批量处理大小为4,学习率为1×10-3。所有的实验都是在Intel(R) Xeon(R) Silver 4210 CPU @ 2.20 GHz和GeForce RTX 3080 10G上进行的。
2.3 模型训练
使用了尺度不变的信噪比改进SI-SNRi[30]和信号失真比率改进SDRi[31]作为衡量语音分离精度的评估指标的模型。SDR其计算公式为:
(8)
其中 表示估计的信号,E表示语音中的噪音信号。
SISDR的计算公式为:
(9)
(10)
(11)
其中 表示干凈的源信号,xE表示与估计信号相垂直的语音声音信息无关的噪音信号。
3 结 果
3.1 三种mlp_block结构的比较
在对比卷积和mlp在含有噪音的语音进行特征采集时,如图3所示,可以说明的是卷积会降低分贝值,卷积操作加重了无用数据的比重,不能更好地区别停顿的位置,且受噪音的影响较大。
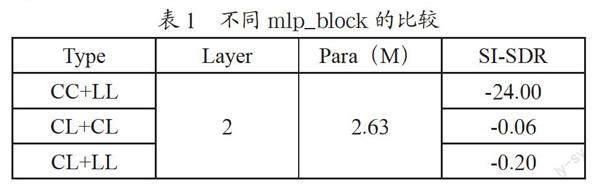
为了证明不同卷积和线性连接在DP分离网络中的作用,设计了如表1所示的三种方案,层数都为2,分别在Libri2mix-k上进行试验。
其中L1=2,L2=12,L3=72,patch_size=16。由上面的結论结合表中的实验结果得知,CC+LL的效果最好。通过利用卷积可以更好地挖掘块内的信息,而利用线性层则可以更好地获取在较长时间内的特征关系,便于对长数据的建模,减少较长句子停顿的影响,同时也可以减少噪音在数据中的比重。
3.2 模型比较
设计了DPMNet网络,其中包含CC+LL,为了证明不同patch_size和MS对系统的影响,在三个数据集上设计了表2所示的实验列表。
由表2中数据可知,当编码器解码器的窗口大小逐渐增大时,模型的参数在不断增大,但是模型的分离能力却在下降,设计差别过大的时间窗口卷积不利于模型的建立,但是过小差别的编码器也不利于模型对较长数据的建模。表3中patch_size表示将三维数据分块的大小,layer表示mlp_block在网络中的层数,他们之间是通过串联连接的,L1,L2,L3表示编码器解码器窗口大小,表中包含了不同参数下Epoch=20的SI-SDR结果。Patch_size为分块操作中的关键参数,从数据可知,在其他条件不变的情况下,越大的数值分离的效果越好,但是受限于设备原因,只测试了20轮训练的结果。
为了表现模型与其他模型的不同,分别在Libri2Mix-k、Libri2Mix-n和ICSSD数据集上进行测试,如表4所示,其中包含基于波形的语音分离模型DPCL++[32]和UPIT-BLSTM-ST[33],基于时域语音分离的模型有BLSTM-TasNet[5]、Conv-TasNet[7]和DPRNN-TasNet[34]。DPMNet的模型尺寸只有2.7 M,且在ICASSD数据集上相比其他模型拥有更好的分离准确率。
3.3 多尺度特征融合
多尺度特征输入相比于单个的一维卷积能够更好地提取语音特征,设计了如表5所示的实验,最小的时间窗口为10,MS分别为10,50,100,分离网络的结构为CC+LL。由SISDR的结果可知,多尺度相比于单尺度拥有更好的分离效果。如图4所示,多尺度编码器相比单尺度拥有更好的特征表现能力。
4 结 论
ViT和mlp-mixer算法在图像以及NLP领域得到广泛应用,通过对比基于卷积的模型发现其能够更好地提取长序列的语音特征,同时提高模型速度。本文提出可否利用mlp-mixer的结构将卷积的思想融合进来,一方面可以减少模型的参数量,另一方面对于语音的特征可以更好地提取。发现在不同的组合情况下,模型的表现不同,当两个卷积与两个全连接层相连接时,更能够提取混合信号中的说话人特征。另外也发现结合多尺度的特征融合在长序列的语音分离任务中得到了更好的效果。
通过本次实验证明卷积网络主要存在三个问题:
(1)卷积算法会加重噪音在特征向量中的比重,其中,空洞卷积会丢失信息的连续性,使分离语音失真;
(2)卷积的长时间依赖性依然存在,数据中的有效信息占比越小,对分离的效果影响越大;
(3)卷积会降低句子的分贝,对于句子停顿的敏感性与全连接相比较差。为解决较长停顿的语音分离,提出了双路径多尺度多层感知混合分离网络(DPMNet)。使用多尺度特征融合操作避免了单个卷积的视野固定,特征容易丢失的问题。使用双路径的混合感知结构,结合卷积和多层感知机的优点,在全局和局部之间读取句子内部,句子与句子之间的特征关系。该设计为单通道语音分离提供了新的思路。
尽管这些结果较为满意,但是依然存在许多挑战。在本文中没有对三个说话人及以上的情况进行试验,希望在之后进行位置数量源的语音分离。同时由于设备影响导致实验数据较少,无法进行参数量更大的实验也是本文的遗憾。
参考文献:
[1] HAYKIN S,CHEN Z.The Cocktail Party Problem [J].Neural Comput,2005,17(9):1875-902.
[2] HERSHEY J R,CHEN Z,ROUX J L,et al.Deep Clustering:Discriminative Embeddings for Segmentation and Separation [C]//2016 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Shanghai:IEEE,2016:31-35.
[3] CHEN Z,LUO Y,MESGARANI N.Deep Attractor Network for Single-Microphone Speaker Separation [C]//2017 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).New Orleans:IEEE,2016:246-250.
[4] KOLBAEK M,YU D,TAN Z H,et al.Multitalker Speech Separation With Utterance-Level Permutation Invariant Training of Deep Recurrent Neural Networks [J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2017,25(10):1901-1913.
[5] LUO Y,MESGARANI N.TasNet:Time-Domain Audio Separation Network for Real-Time,Single-Channel Speech Separation [C]//2018 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Calgary:IEEE,2018:696-700.
[6] BAI S J,KOLTER J Z,KOLTUN V.An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling [J/OL].arXiv:1803.01271 [cs.LG].[2022-08-09].https://arxiv.org/abs/1803.01271.
[7] LUO Y,MESGARANI N.Conv-TasNet:Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation [J/OL].arXiv:1809.07454 [cs.SD].[2022-08-06].https://arxiv.org/abs/1809.07454.
[8] MA C,LI D M,JIA X P.Two-Stage Model and Optimal SI-SNR for Monaural Multi-Speaker Speech Separation in Noisy Environment [J/OL].arXiv:2004.06332 [eess.AS].[2022-08-07].https://arxiv.org/abs/2004.06332.
[9] WU X C,LI D M,MA C,et al.Time-Domain Mapping with Convolution Networks for End-to-End Monaural Speech Separation [C]//2020 IEEE 5th International Conference on Signal and Image Processing (ICSIP).Nanjing:IEEE,2020:757-761.
[10] ZHAO M C,YAO X J,WANG J,et al.Single-Channel Blind Source Separation of Spatial Aliasing Signal Based on Stacked-LSTM [J].Sensors,2021,21(14):4844.
[11] LIU Y K,LI T,ZHANG P Y,et al.Improved Conformer-based End-to-End Speech Recognition Using Neural Architecture Search [J/OL].arXiv:2104.05390 [eess.AS].[2022-08-07].https://arxiv.org/abs/2104.05390v1.
[12] ZHANG L W,SHI Z Q,HAN J Q,et al.FurcaNeXt:End-to-End Monaural Speech Separation with Dynamic Gated Dilated Temporal Convolutional Networks [C]//26th International Conference on Multimedia Modeling.Daejeon:MMM,2020:653–665.
[13] TZINIS E,WANG Z P,SMARAGDIS P.Sudo RM-RF:Efficient Networks for Universal Audio Source Separation [C]//2020 IEEE 30th International Workshop on Machine Learning for Signal Processing(MLSP).Espoo:IEEE,2020:1-6
[14] XU C L,RAO W,CHNG E S,et al.Time-Domain Speaker Extraction Network [C]//2019 IEEE Automatic Speech Recognition and Under-standing Workshop (ASRU).Singapore:IEEE,2019:327-334.
[15] GE M,XU C L,WANG L B,et al.L-SpEx:Localized Target Speaker Extraction [C]//ICASSP 2022-2022 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).Singapore:IEEE,2022:7287-7291
[16] TOLEDANO D T,MP FERN?NDEZ-GALLEGO,LOZANO-DIEZ A,et al.Multi-Resolution Speech Analysis for Automatic Speech Recognition Using Deep Neural Networks:Experiments on TIMIT [J/OL].PLoS ONE,2018,13(10)[2022-8-26]. https://ideas.repec.org/a/plo/pone00/0205355.html.
[17] LUO Y,CHEN Z,YOSHIOKA T.Dual-Path RNN:Efficient Long Sequence Modeling for Time-Domain Single-Channel Speech Separation [C]//ICASSP 2020-2020 IEEE International Confer-ence on Acoustics,Speech and Signal Processing (ICASSP).Barcelona:IEEE,2020:46-50.
[18] ZHAO Y,WANG D L,XU B Y,et al.Monaural Speech Dereverberation Using Temporal Convolutional Networks with Self Attention [J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2020,28:1598-1607.
[19] NACHMANI E,WOLF L,ADI Y M.Voice Separation with an Unknown Number of Multiple Speakers:US16853320 [P].[2020-04-20].
[20] SPERBER M,NIEHUES J,NEUBIG G,et al.Self-Attentional Acoustic Models [J/OL].arXiv:1803.09519 [cs.CL].[2022-08-19].https://arxiv.org/abs/1803.09519v1.
[21] KAISER L,GOMEZ A N,SHAZEER N,et al.One Model To Learn Them All[J/OL].arXiv:1706.05137 [cs.LG].[2022-08-11].https://arxiv.org/abs/1706.05137.
[22] SUBAKAN C,RAVANELLI M,CORNELL S,et al.Attention is All You Need in Speech Separation [J/OL].arXiv:2010.13154 [eess.AS].[2022-08-13].https://arxiv.org/abs/2010.13154.
[23] SUN C,ZHANG M,WU R J,et al.A Convolutional Recurrent Neural Network with Attention Frame-Work for Speech Separation in Monaural Recordings [J].Scientific Reports,2021,11:1-14.
[24] DOSOVITSKIY A,BEYER L,KOLESNIKOV A,et al.An Image is Worth 16×16 Words:Transformers for Image Recognition at Scale [J/OL].arXiv:2010.11929 [cs.CV].[2022-08-14].https://arxiv.org/abs/2010.11929.
[25] TOLSTIKHIN I,HOULSBY N,KOLESNIKOV A,et al.MLP-Mixer:An all-MLP Architecture for Vision [J/OL].arXiv:2105.01601 [cs.CV].[2022-08-17].https://arxiv.org/abs/2105.01601.
[26] LIU H X,DAI Z H,SO D R,et al.Pay Attention to MLPs [J/OL].arXiv:2105.08050 [cs.LG].[2022-08-15].https://arxiv.org/abs/2105.08050.
[27] COSENTINO J,PARIENTE M,CORNELL S,et al.LibriMix:An Open-Source Dataset for Generalizable Speech Separation [J/OL].arXiv:2005.11262 [eess.AS].[2022-08-16].https://arxiv.org/abs/2005.11262.
[28] WICHERN G,ANTOGNINI J,FLYNN M,et al.WHAM!:Extending Speech Separation to Noisy En-vironments [J/OL].arXiv:1907.01160 [cs.SD].[2022-08-16].https://arxiv.org/abs/1907.01160.
[29] PANAYOTOV V,CHEN G G,POVEY D,et al.Librispeech:An ASR Corpus Based on Public Domain Audio Books [C]//2015 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP).South Brisbane:IEEE,2015:5206-5210.
[30] ROUX J L,WISDOM S,ERDOGAN H,et al.SDR–Half-baked or Well Done? [J/OL].arXiv:1811.02508 [cs.SD].[2022-08-17].https://arxiv.org/abs/1811.02508.
[31] VINCENT E,GRIBONVAL R,F?VOTTE C.Performance Measurement in Blind Audio Source Separation [J].IEEE Transactions on Audio,Speech,and Language Processing,2006,14(4):1462-1469.
[32] HERSHEY J R,ZHUO C,ROUX J L,et al.Deep Clustering:Discriminative Embeddings for Segmentation and Separation [C]//2016 International Conference on Acoustics,Speech and Signal Processing(ICASSP).Shanghai:IEEE,2016:31-35.
[33] HUANG L,CHENG G F,ZHANG P Y,et al.Utterance-level Permutation Invariant Training with Latency-controlled BLSTM for Single-channel Multi-talker Speech Separation [J/OL].arXiv:1912.11613 [cs.SD].[2022-08-17].https://arxiv.org/abs/1912.11613v1.
[34] ZHU J Z,YEH R,HASEGAWA-JOHNSON M.Multi-Decoder DPRNN:High Accuracy Source Counting and Separation [J/OL].arXiv:2011.12022 [cs.SD].[2022-08-18].https://arxiv.org/abs/2011.12022v1.
作者簡介:刘雄涛(1999—),男,汉族,河北沙河人,研究生在读,研究方向:控制工程。
收稿日期:2022-09-09
基金项目:国家自然科学基金项目(61966001,61866001,62163004,61866016,62206195)
