
基于自监督对比学习的寒旱区遥感图像河流识别方法
2023-06-20 04:40王海龙牛东兴李阳阳
农业机械学报 2023年6期
沈 瑜 王海龙 梁 栋 牛东兴 严 源 李阳阳
(1.兰州交通大学电子与信息工程学院, 兰州 730070; 2.中国中铁科学研究院有限公司, 成都 610032)
0 引言
河流作为生态系统的重要组成部分,对自然环境以及人们的生产生活有着至关重要的作用,尤其对我国寒旱区的河流进行识别,在农业灌溉、水利水电调控、生态监测和环境改善等方面有着重大意义[1-3]。
近年来,使用深度学习方法从高分辨率遥感图像中对河流进行识别成为主要方法之一[4-5]。文献[6]构建并训练了卷积神经网络和DeepLabv3两种水体识别模型,其识别精度分别达到95.09%和92.14%,均高于支持向量机、面向对象以及水体指数等方法。文献[7]通过在DenseNet网络中增加上采样和全卷积网络内的跳层连接,缓解梯度消失和网络退化问题,其识别精度优于其他深度神经网络,精度高达96%以上。文献[8]通过改进U-Net网络,并引入条件随机场进行后处理,精细化了分割结果,实验结果表明,该网络对小目标水体能够准确识别。文献[9]用自适应简单线性聚类算法(ASLIC)将遥感图像分割成高质量的超像素,再利用新的池化卷积神经网络提取水体高级特征并进行二分类标记,该方法实验平均总准确率为99.14%,高于传统方法。文献[10]采用集成预测,同时优化有标签样本上的标准监督分类损失及无标签数据上的非监督一致性损失,来训练端到端的语义分割网络。文献[11]利用半监督学习中的生成对抗性网络,用softmax替代最后的输出层,结合自动化分类诊断进行实验。
以上研究均依靠大量标签数据,由于有标签数据的制作难度和成本较高,利用无标签数据进行网络训练的自监督学习(Self-supervised learning, SSL)方法逐渐引起重视[12-13]。自监督学习属于无监督学习,无需大量标签数据,只需通过构建前置任务(Pretext task)从无标签数据中学习自身的监督信息,然后将训练好的模型迁移到下游任务中,使用少许标签数据微调后训练,最后进行目标任务预测[14-16]。自监督学习的主流方法包括生成式、对比式、生成式对比自监督学习(对抗学习)方法,其中对比式自监督学习方法应用最广泛[17]。文献[18]提出了一个全局风格和局部匹配的对比学习网络,在Postdam数据集上Kappa系数提高6%。文献[19]设计了3个不同的前置任务和3个一组的孪生网络进行训练,实验结果表明,只需10%~50%的标记数据即可达到有监督网络相同的性能。文献[20]提出一种自监督学习算法(Inpainting based self-supervised learning,IBS)解决了电力线分割任务缺乏大规模数据的问题,实验表明其精度和速度都超越了已有的方法。文献[21]提出一种视觉表示的自监督对比学习框架(Simple framework for contrastive learning of visual representations,SimCLR),该结构不需要专门的架构,也不需要特殊的存储库,因此具有通用性且网络性能更优。自监督学习方法训练的网络模型可以学习遥感图像潜在的特征,获得更好的拟合起点,并取得优秀的分割结果,将自监督学习获得的学习参数用作预训练模型,利用迁移学习对后续遥感图像任务进行微调,可证明网络的泛化能力[22-23]。以上基于自监督学习范式的研究虽然已经取得大量成果,但其大多数针对分类问题进行研究,并且网络收敛速度较慢,编码器常采用ResNet50网络,识别精度有限,在具有较多干扰的寒旱区遥感图像河流提取方面鲜有报道。
本文针对大量有标签的寒旱区遥感图像河流数据很难获得,以及河流边缘细节难以识别的问题,采用自监督对比学习方式并对其进行改进,充分利用无标签数据对遥感图像河流提取网络进行预训练,同时在下游任务训练好的编解码网络中使用一种新的非均匀采样方式,提取河流边缘细节,通过实验证明其有效性和泛化性能。
1 网络框架
网络总体框架如图1所示,分为基于自监督对比学习的预训练阶段和下游目标任务提取阶段两部分,以AFR-LinkNet[5]网络为基础网络构建模型。首先将大量无标签遥感图像河流数据进行数据增强,获得大量正负样本对,然后输入基于改进的SimCLR框架的自监督网络模型进行训练,其编码器使用下游目标任务中AFR-LinkNet网络的编码器进行替换,并在映射头的Dense层和ReLU激活函数之间添加BN(Batch normalization)层。编码器与映射头结合的两次非线性映射能够大幅度提升对比学习性能,编码器后的图像特征会有更多包含图像增强信息在内的细节特征,即编码更多与任务无关的通用细节信息,在高层网络映射头中编码更多与对比学习任务相关的信息。网络将正样本对拉近,将负样本对拉远,不断进行对比,直到正样本对比损失最小,否则不断梯度回传更新编码器参数。最后将训练好的编码器模型参数作为预训练的编码器,利用迁移学习方式迁移到下游目标任务的语义分割网络的编码器中。其次,将少量带有标签的遥感图像河流数据输入AFR-LinkNet语义分割网络,微调后进行训练。将编码器输出的粗粒度语义图和解码器输出的细粒度语义图,通过对高频区域多采样、低频区域少采样的非均匀采样策略后进行特征融合,最后将融合后输出的高精度河流分割语义图与语义标签图进行损失函数校验,如果损失最小,则输出分割结果,否则进行模型参数更新。
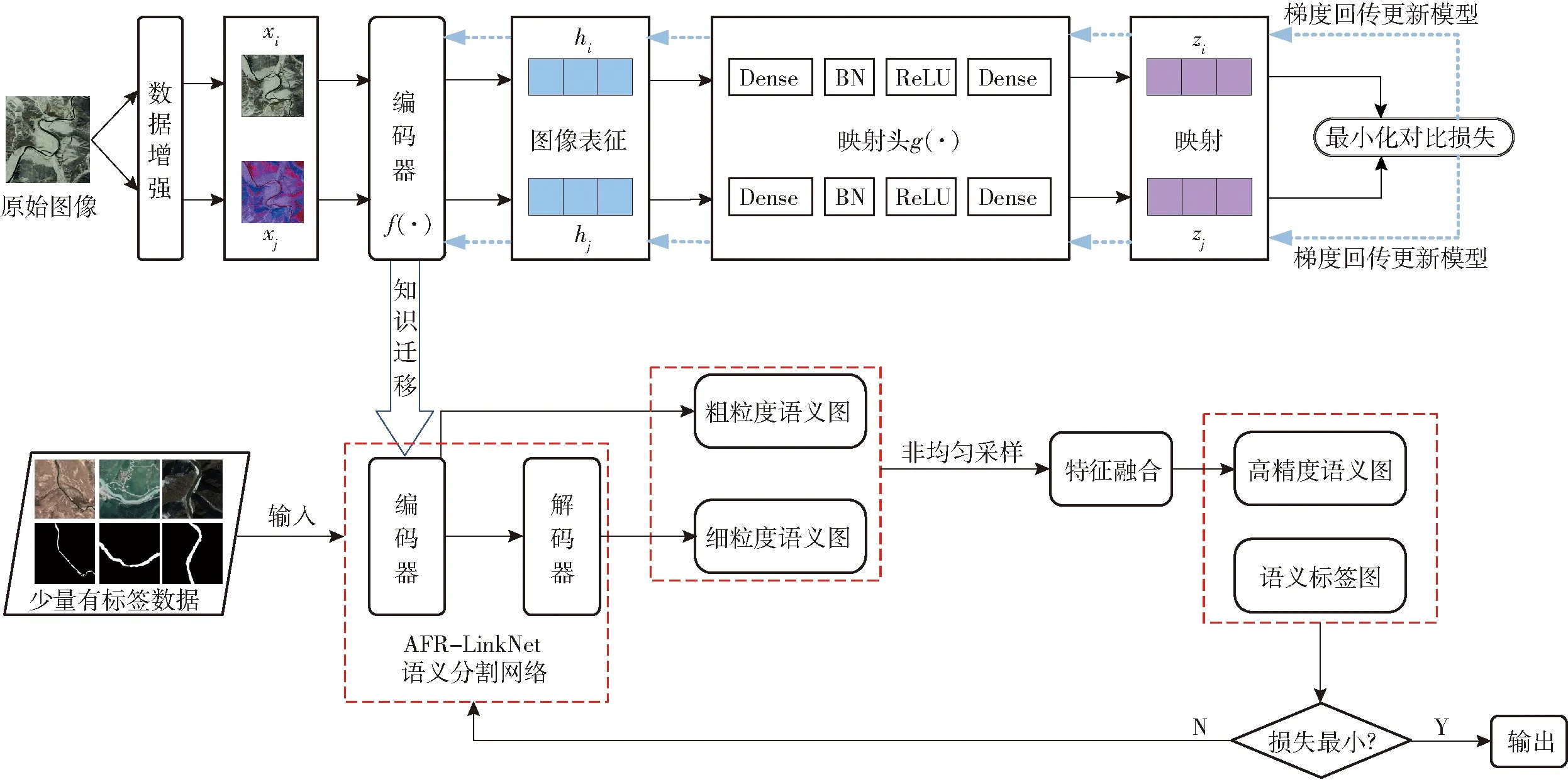
图1 网络框架Fig.1 Network framework
2 相关原理
2.1 自监督学习
机器学习一般分为有监督学习、半监督学习、无监督学习和强化学习,而自监督学习是一种新的无监督机器学习方法,能够挖掘出数据自身的监督信息关系作为标注样本进行训练,通过这种方式可以获得更多的语义特征,解决了有监督学习中需要大量标注数据的问题,其核心是在无标签的预训练数据上进行自监督任务的训练,通过最小化损失函数更新模型参数,得到一个可以对数据产生良好特征表征的编码器模型[24]。
自监督学习原理如图2所示,为了更好地迁移模型参数,自监督代理任务和下游目标任务使用相同的编码器模型。在自监督代理任务阶段,首先将大量无标签数据输入编码器,得到含有自身监督信息的图像特征,再通过自监督训练任务模型(如生成型、对比型等)得到预测图像,然后进行损失对比,直到损失最小时停止梯度回传,将预训练好的编码器模型参数迁移到下游目标任务。在下游目标任务阶段,将少量有标签数据输入到经过预训练的编码器模型中,然后微调参数后开始训练,将提取到的图像特征通过下游目标任务模型(如图像分类、语义分割等)获得预测图像,最后进行损失函数校验,符合损失函数最小条件后输出最终的预测图像。
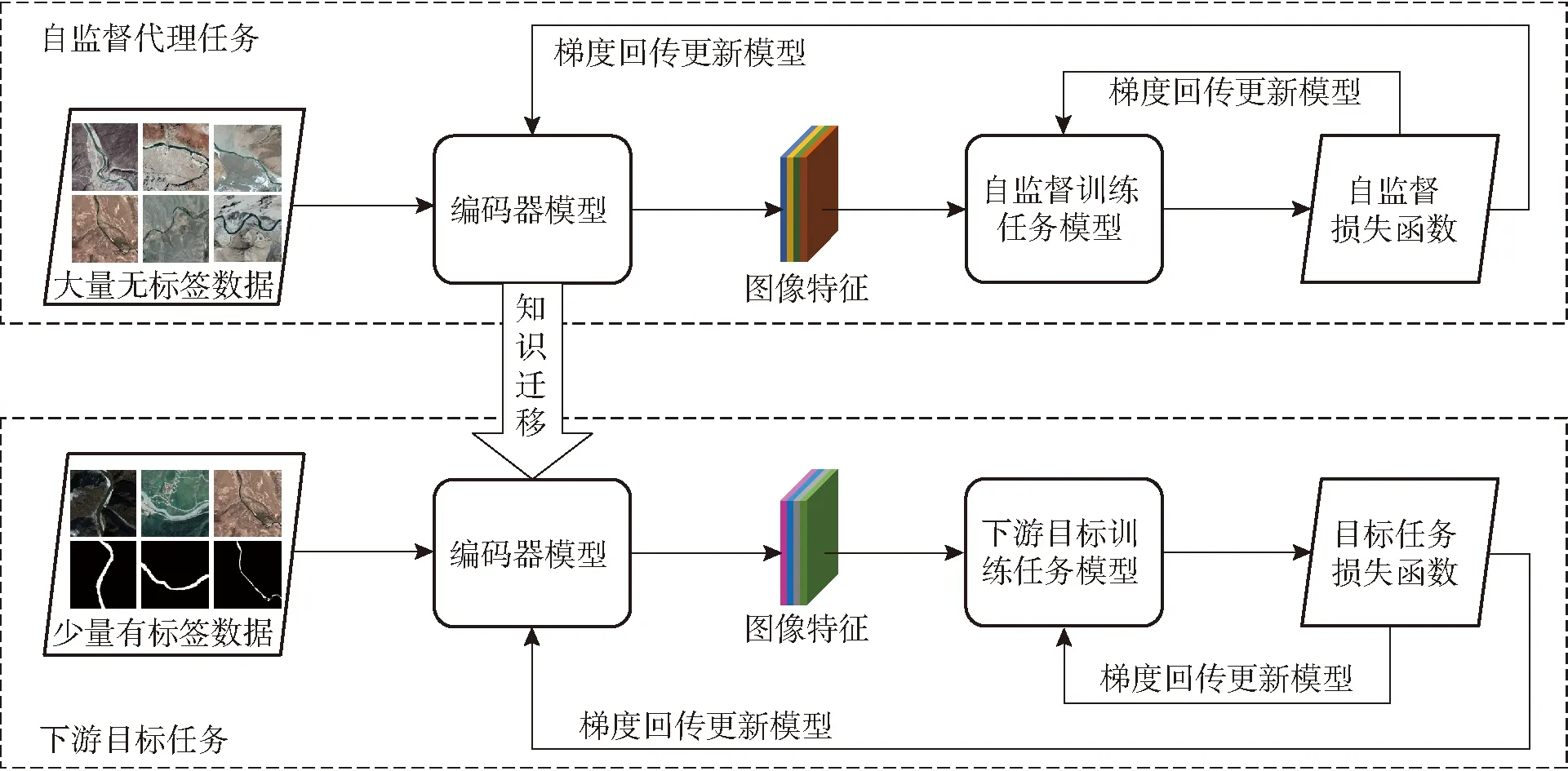
图2 自监督学习原理图Fig.2 Schematic of self-supervised learning
自监督对比学习是目前主流研究方法之一,并且取得了较好的效果,其核心思想是通过一个辅助任务,构建正负样本对,使网络通过比较正负样本的距离差学习到将相似样本(正样本对)拉近,不相似样本(负样本对)拉远的能力,从而可以获得特征可区分性表达的目标,即
score(f(x),f(x+))≫score(f(x),f(x-))
(1)
式中 score(·)——样本相似度比较函数
f(x)——原始图像预测图
f(x+)——正样本预测图
f(x-)——负样本预测图
其实现步骤如图3所示。
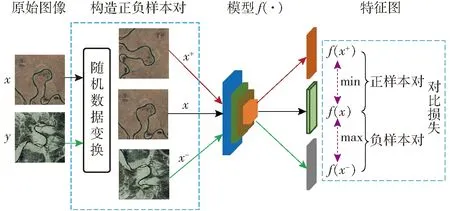
图3 自监督对比学习原理图Fig.3 Schematic of self-supervised comparative learning
其中,合理构建正样本对,并包含足够多且足够难的负样本对能够有效提升对比自监督学习的学习性能。文献[25]提出使用动量对比学习的方法对负样本编码器进行更新,并且保持该负样本队列足够大,巧妙地解耦模型批次大小和一个学习批次可容纳的负样本数量。
目前,常见的主流自监督对比学习框架包括MoCo、SimCLR、SwAV、SimSiam等。其中,SimCLR模型兼具框架简单与网络性能高的特点,但其收敛速度较慢、预训练编码器提取精度有限。因此,本文将对SimCLR框架进行改进,并作为自监督预训练阶段的网络模型。
SimCLR模型主要包含3部分:数据随机增强、深度神经网络和损失对比函数,如图4所示,其核心原理是利用同一样本数据增强后具有相似特征、不同样本之间数据增强后具有差异特征构造损失函数进行特征学习。
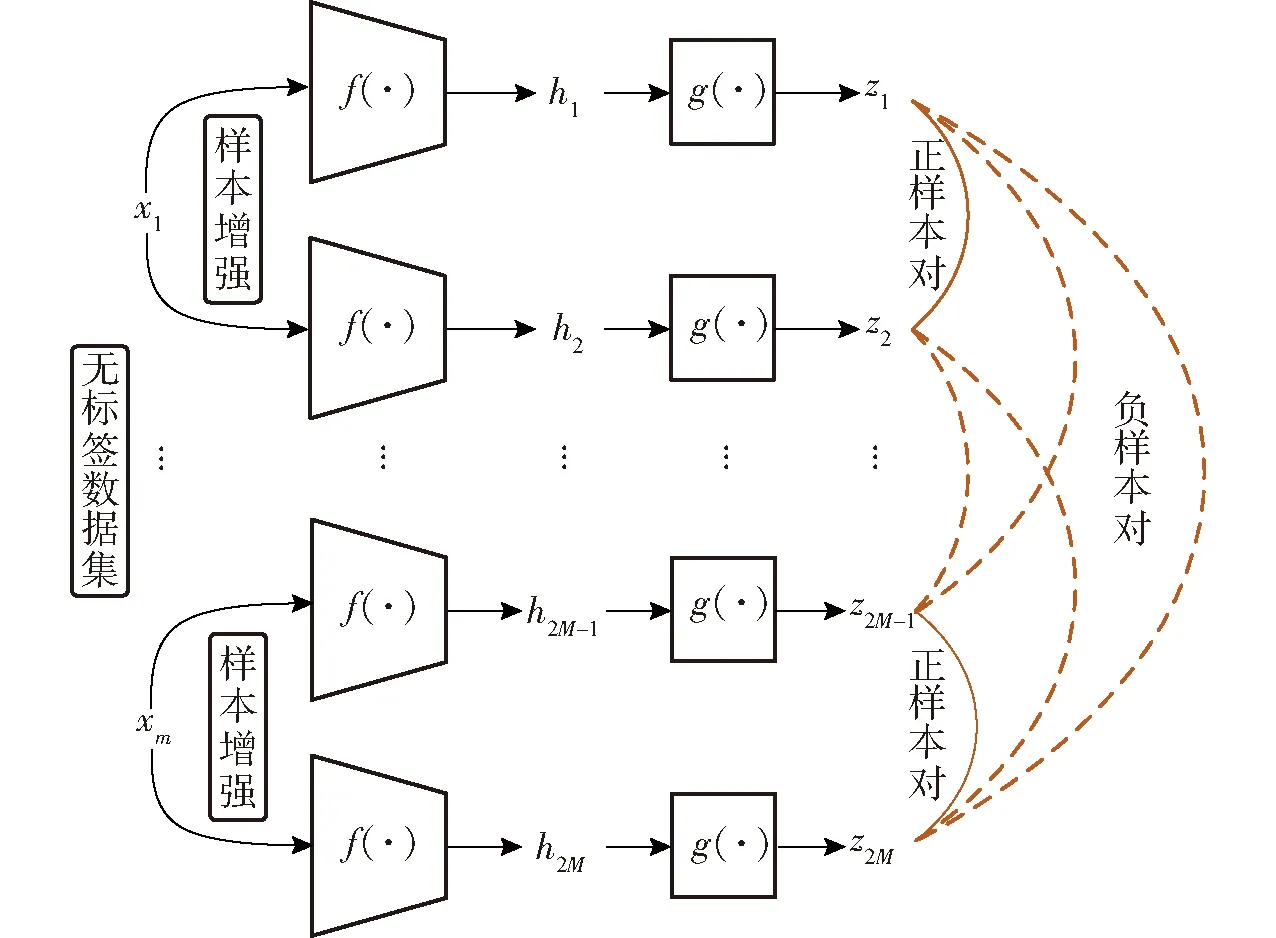
图4 SimCLR原理图Fig.4 SimCLR principle framework
(1)数据随机增强
自监督学习利用样本自身的信息进行学习,不需要样本标签。自监督对比学习只需通过原始数据构造出正负样本对即可进行学习。如图4所示,从训练集中随机选取M幅河流图像为一个批次进行样本增强,将每幅河流图像经过两次随机裁剪获得两个增强数据,使得其中任意一幅图像保持不变,另一幅图像进行随机色度变换、旋转、高斯模糊、随机颜色失真等。同一图像经数据增强后的两个样本为一个正样本对,剩余的2(M-1)个增强的样本数据全部为该图像的负样本。因为正样本来源于同一图像,具有内在信息联系,负样本来源于不同图像,具有内在信息差异,因此可以进行图像信息学习。
(2)深度神经网络
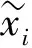
(3)损失对比函数
数据增强后的样本通过特征提取和特征映射模块,最后需要使用归一化加权交叉熵损失函数(Normalized temperature-scaled cross entropy loss,NT-Xent)将正样本对之间的相似度最大化,负样本对之间的相似度最小化,最终达到能够学习遥感河流图像中的通用特征表示。NT-Xent损失函数定义为
(2)
式中M——批次大小
其中l(j,k)为正样本对的损失对比函数,定义为
(3)
其中
(4)
(5)
式中z——特征映射网络输出
τ——权重,取0.1
m——数据增强后正样本
j——用于数据增强样本
f(m,j)——指示函数
sim(·)——数据相似度函数
2.2 非均匀采样
图像采样可分为均匀采样和非均匀采样,河流与非河流边界处具有不规则性,且阴影等干扰因素较多,均匀采样针对河流不规则边界处区分度低、识别精度较差。因此,要对河流边缘高精细度提取,只能通过对高频区域密集采样、对低频区域稀疏采样的非均匀采样方式获得图像中不同类别之间清晰的边界信息和同类别区域中的细节信息,同时减少模型的冗余度。
目前多数研究都是针对输入图像的非均匀采样,本文针对编解码器输出的粗粒度图像和细粒度图像分别进行非均匀采样,粗粒度图像中包含不同类别之间详细的类别信息,能够明确局部边界特征,细粒度图像中蕴含同类别的细节信息,具有更多的语义信息和上下文信息,能够提供全局特征信息,其原理如图5所示。首先,原始遥感河流图像经过编解码网络分别输出粗粒度图像和细粒度图像,再使用轻量级分割头对检测到的河流对象进行粗滤预测(红色框内),利用点选择策略选择一组点(红点),使用小的多层感知器(Multilayer perceptron, MLP)对每个点独立预测,进行细化。使用双线性插值作用于粗粒度图像上的这些点,获得图像低级信息,同时使用2倍双线性插值作用于细粒度图像上的这些点,获得图像高级信息,将高级信息和低级信息特征融合后得到最终的特征向量。最后MLP使用在这些点上计算的插值特征(蓝色虚线)对特征向量进行掩膜预测,获得每个点的预测结果。不断使用该过程迭代地细化预测掩膜的不确定区域,实现非均匀采样,直到获得预期分辨率的河流语义图。
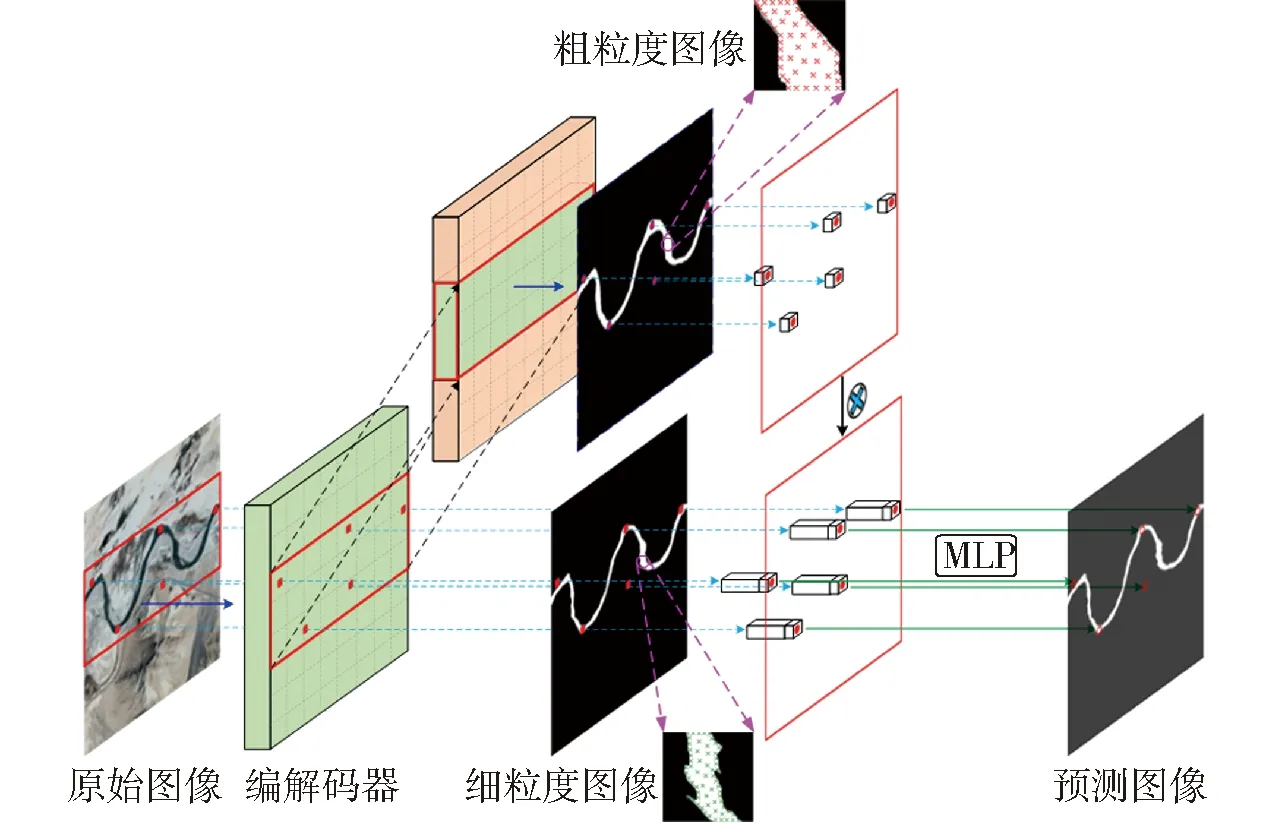
图5 非均匀采样原理图Fig.5 Non-uniform sampling
2.2.1双线性插值
原始遥感河流图像经过特征提取器后,其图像尺寸和图像中特定点的像素与原始图像相比较已经发生较大变化,为将其恢复到原始图像尺寸,可通过双线性插值对其进行上采样操作。双线性插值是在两个方向分别进行一次线性插值操作,原理是待插点像素取原图像中与其相邻的4个点像素的水平、垂直两个方向上的线性内插,即根据待采样点与周围4个邻点的距离确定相应的权重,从而计算出待采样点的像素。其原理和步骤如图6、7所示,图中灰色板表示像素点的坐标,蓝色、红色和绿色点分别表示初始像素点、中间像素点和输出像素点。
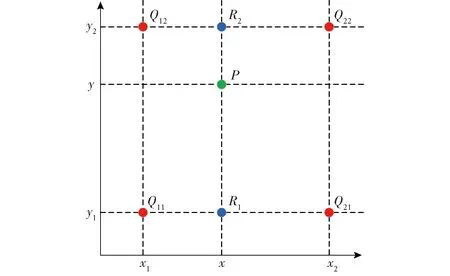
图6 双线性插值Fig.6 Bilinear interpolation

图7 基于插值的上采样方法Fig.7 Interpolation based upsampling methods
为得到未知函数f在点P=(x,y)的值,假设已知函数f在Q11=(x1,y1) 、Q12=(x1,y2),Q21=(x2,y1)以及Q22=(x2,y2)4个点的值。f就是一个像素点的像素值,首先在x方向进行线性插值,得到
(6)
(7)
然后在y方向进行线性插值,得到
(8)
综合得到双线性插值结果为
(9)
2.2.2点选择策略
针对遥感图像中不规则的河流边界,如果对全局点采样将增大计算量,非均匀采样方式基于点选择策略,只对预测困难点进行采样,可以大幅度降低计算量,增加采样灵活性,有效恢复图像中河流的边缘细节。
点选择策略核心思想是能够在河流图像平面上的高频区域附近(如河流边界等)灵活、自适应、密集地选择用于预测分割标签的点。选择过程中只计算值与邻近值显著不同的可能性较大的位置,实现高分辨率图像的有效分割,对于所有其他位置的预测值是通过插值已经计算的输出值(粗预测图)来获得。针对各个区域,均使用由粗到细的方式不断地迭代输出预测图,对规则网格上的点只需要进行最粗级别预测即可。在每次迭代预测中,利用双线性插值对其之前预测的河流语义分割图实行上采样,然后在较为密集的网格上选取概率为0.5的N个点,最后计算这N个点的特征表征,同时预测出它们的标签,并不断重复该步骤,直到获得期望的分辨率。如图8所示,使用双线性插值将分辨率4×4上的预测进行2倍上采样,获得分辨率8×8,然后对这N个点(蓝色点)进行预测,以便于在更高分辨率的图像上恢复河流边缘的细节信息。
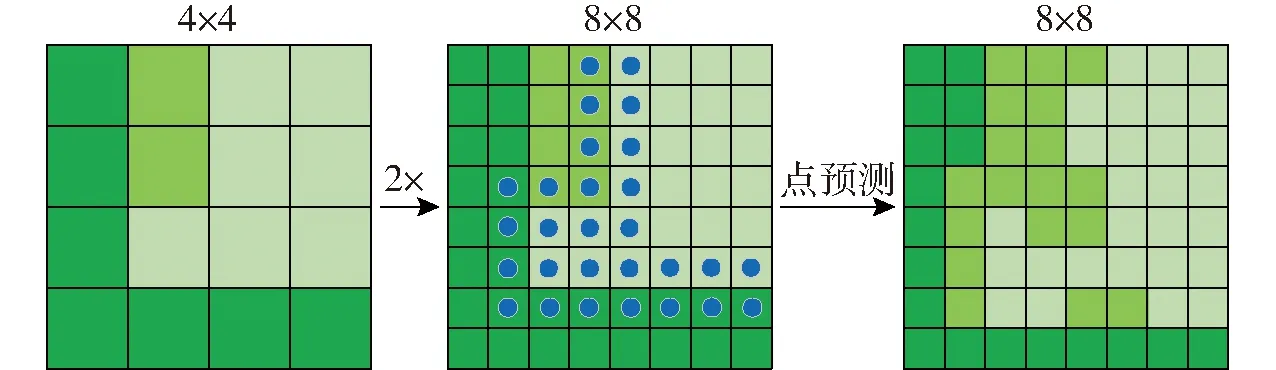
图8 分辨率4×4细化到分辨率8×8示意图Fig.8 Resolution 4×4 refined to resolution 8×8 schematic
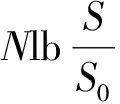
为了平衡网络数据计算量和均匀覆盖问题,本文k取4,α取0.75(适度偏置能够使得训练更有效),在进行训练时,只计算N个采样点上的预测值和损失函数值,使计算效率更高。
3 数据集与预处理
实验数据集从高分二号卫星图像中截取600幅尺寸为1 024像素×1 024像素的寒旱区遥感河流图像,将其中300幅图像进行二值化人工标注,河流标注为1,其他的均标注为0。通过数据扩增将这300幅原始图像和对应的语义图像按照相同的数据扩增方式均拓展为1 500幅,最后将剩余未标注的300幅图像通过数据扩增拓展为1 500幅无标签数据,并单独截取100幅相同规格的河流图像进行语义标注,作为网络的测试集。
因此,遥感图像河流数据集共3 100幅河流图像,其中训练集、验证集、测试集比例为24∶6∶1。训练集中1 200幅无标签数据用于训练自监督对比学习网络,1 200幅有标签数据用于训练有监督网络和对自监督对比学习网络进行微调,图9为数据扩增示意图。

图9 数据扩增示意图Fig.9 Schematic of data amplification
使用最大最小标准化对原始图像进行归一化预处理,可以将所有数据映射到[0,1]区间内,减少模型计算量以及加快模型的收敛速度。
4 实验结果与分析
4.1 实验设置
实验平台为Windows 10操作系统、CPU i9-11980HK、GPU RTX3080 (16 GB显存)、内存 32 GB,使用PyTorch框架搭建网络模型,编程语言为Python。自监督学习时的批次大小M设置为10,同批次生成增强样本时按概率0.25进行随机裁剪、旋转、翻转和颜色失真,由此构成正负样本对。自监督学习的初始学习率设置为2.5×10-4,迭代轮次为400,优化器均选择Adam优化器,在少量带标签数据上微调模型时使用相同的学习率和优化器,迭代训练至网络收敛,网络全部使用文献[26]的初始化权重。
4.2 评价指标
采用像素准确率(Accuracy, ACC)、召回率(Recall)和交并比(Intersection over union, IoU)作为评价指标。
4.3 实验结果
通过对比和消融实验,证明本文提出的基于自监督对比学习的遥感图像河流识别网络在只有少量标签数据情况下,只需对用无标签数据训练好的自监督网络进行微调,各项评价指标便超过了使用大量标签数据训练的有监督网络模型。实验结果表明,网络模型的像素准确率、交并比和召回率分别达到93.7%、73.2%和88.5%,超过有监督网络AFR-LinkNet、DeepLabv3+、LinkNet、ResNet50和UNet,河流图像提取结果在边缘细节上有了较高提升,优于其他有监督网络;使用360幅有标签数据微调网络时,其像素准确率达到90.4%,与有监督AFR-LinkNet网络提取精度相当。
4.3.1对比实验
将使用1 200幅有标签数据进行微调的SimCLR+AFR-LinkNet+非均匀采样网络(自监督对比学习网络)与使用相同数量有标签数据进行有监督训练的网络AFR-LinkNet、DeepLabv3+、LinkNet、ResNet50和UNet进行对比,图10为验证集上各网络的像素准确率变化曲线,图11为网络在训练集和验证集上的损失值变化曲线,表1为各网络在测试集上的评价指标结果。
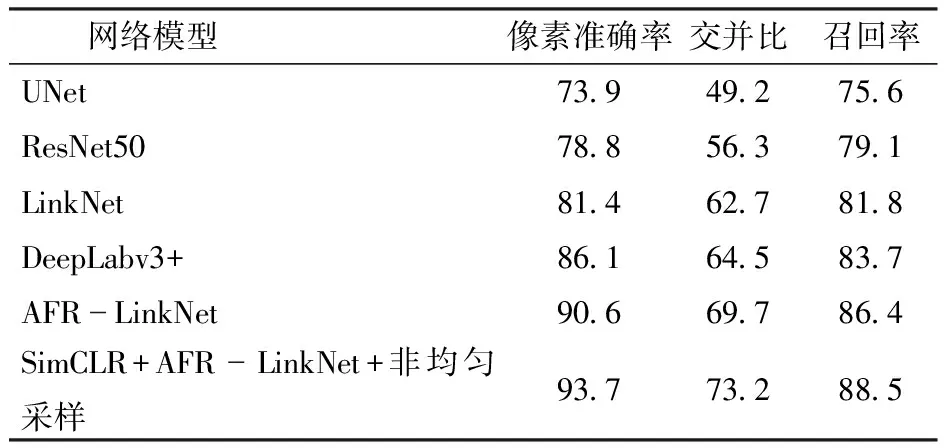
表1 各网络评价指标Tab.1 Evaluation indicators of each network %
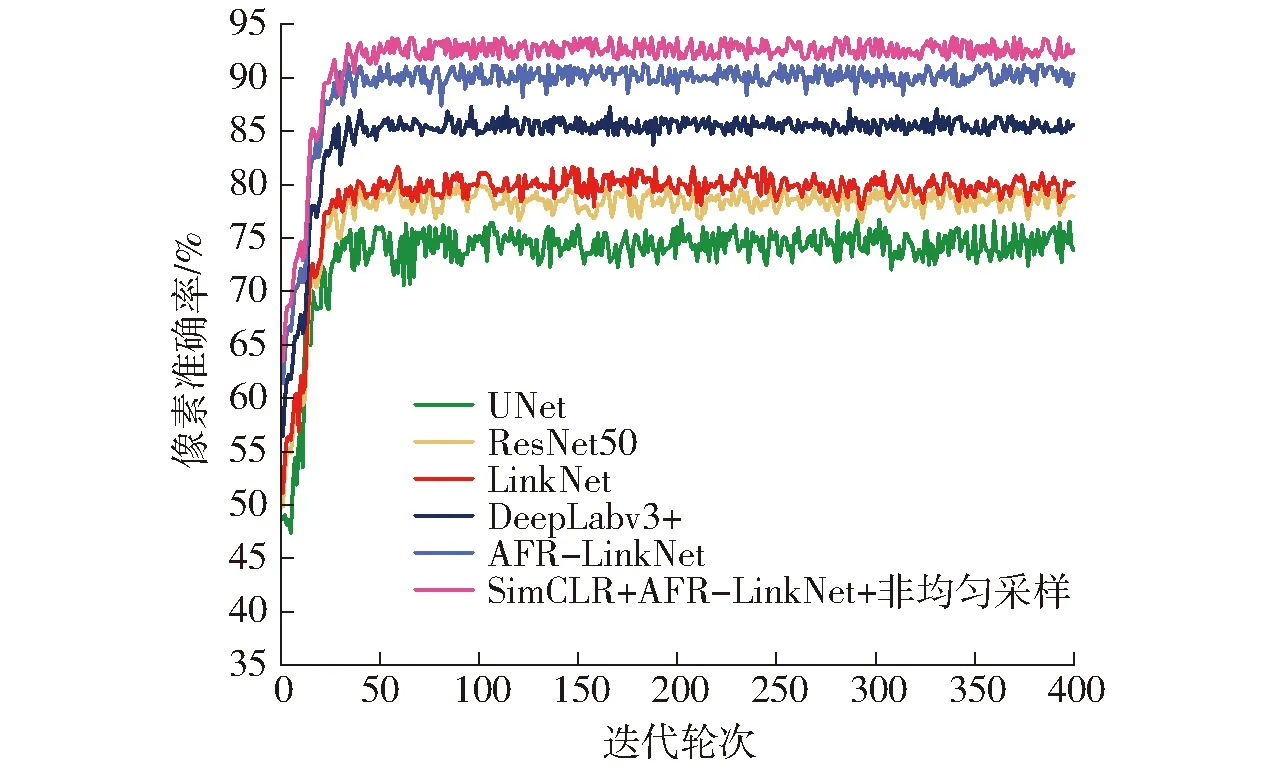
图10 各网络像素准确率变化曲线Fig.10 Change curves of pixel accuracy of each network
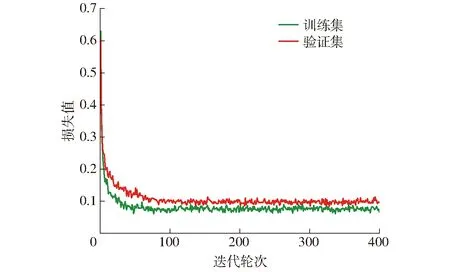
图11 训练集与验证集上网络损失值变化曲线Fig.11 Change curves of network loss function on training set and test set
由图10、11可以看出,自监督网络在50个迭代轮次时已经趋于稳定,像素准确率高于其他有监督网络,收敛速度较快,训练集和验证集上的损失都较小,在验证集上的损失稍大于训练集上的损失,在前50个迭代轮次时损失下降较快,验证了自监督网络的各种超参数设置较为合理且网络对河流提取准确率较高、收敛性较好。
由表1可知,自监督网络像素准确率、交并比和召回率分别达到93.7%、73.2%和88.5%,各项评价指标均高于有监督网络AFR-LinkNet、DeepLabv3+、LinkNet、ResNet50和UNet,像素准确率分别提高3.1、7.6、12.3、14.9、19.8个百分点,交并比分别提高3.5、8.7、10.5、16.9、24.0个百分点,召回率分别提高2.1、4.8、6.7、9.4、12.9个百分点。
图12为3幅不同网络的遥感河流图像的语义分割效果图,图中红色标记为不同网络提取效果的主要区别点。从图12可以看出,UNet网络的识别效果最差,ResNet50、LinkNet和DeepLabv3+网络错误地将道路、冰雪以及山体阴影识别为河流,在细小河流处出现较多断续,AFR-LinkNet网络与SimCLR+AFR-LinkNet+非均匀采样网络在细节提取上更精细、更准确,但是因为自监督对比学习模型以AFR-LinkNet网络的编码器为基础进行无标签数据训练,具有较强的抗干扰性,并且学习到了有监督模型无法学习到的图像内在蕴含的一些细节信息,因此在河流的边缘细节提取效果上表现更好,在特别细小的河流处基本没有出现断流和误识别的情况,河流识别结果更加完整,但是在特别复杂的干扰因素以及更少的标签数据情况下的提取精度还有一定提升空间。
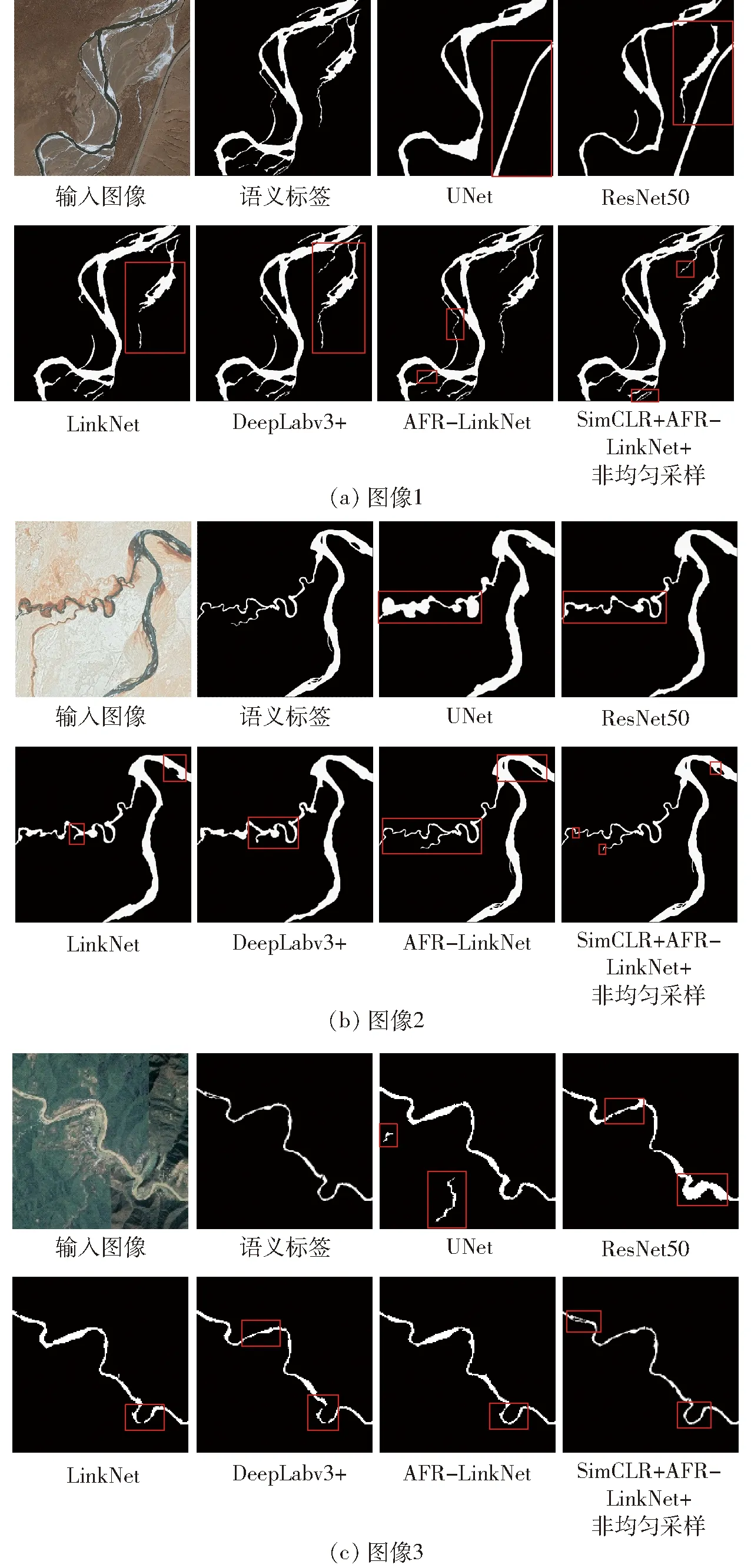
图12 3幅图像不同网络识别结果对比Fig.12 Comparisons of recognition results of three images with different networks
4.3.2消融实验
为验证各个模块的有效性,从改变用于微调的标签数量、样本数据增强以及自监督对比学习与非均匀采样3方面进行消融实验,验证其对网络性能的影响。
(1)微调标签数量对网络性能的影响
为了验证用于微调下游任务模型的标签数量对网络性能的影响,将标签数据按1/10、3/10、5/10、7/10、1的比例对下游任务模型进行微调训练,图13为测试集上像素准确率和交并比随着标签数量比例的不同而变化的曲线,表2为微调标签数量对网络模型性能影响的各项评价指标。
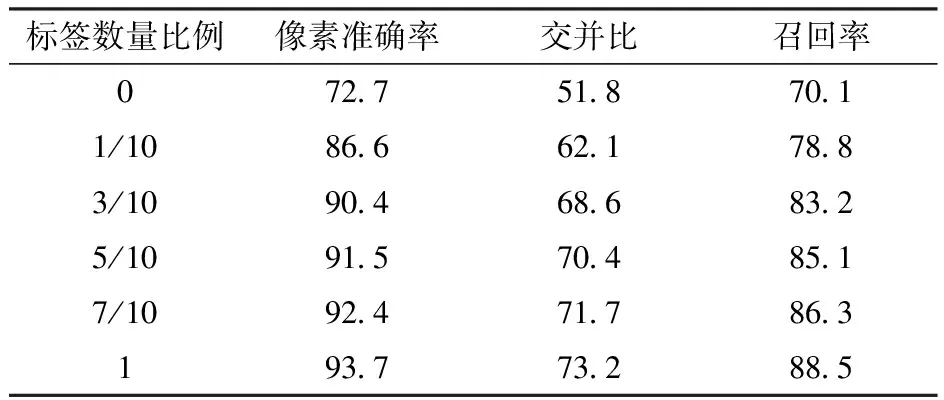
表2 不同标签数量比例下网络各项评价指标Tab.2 Network evaluation index under different label quantity ratios %
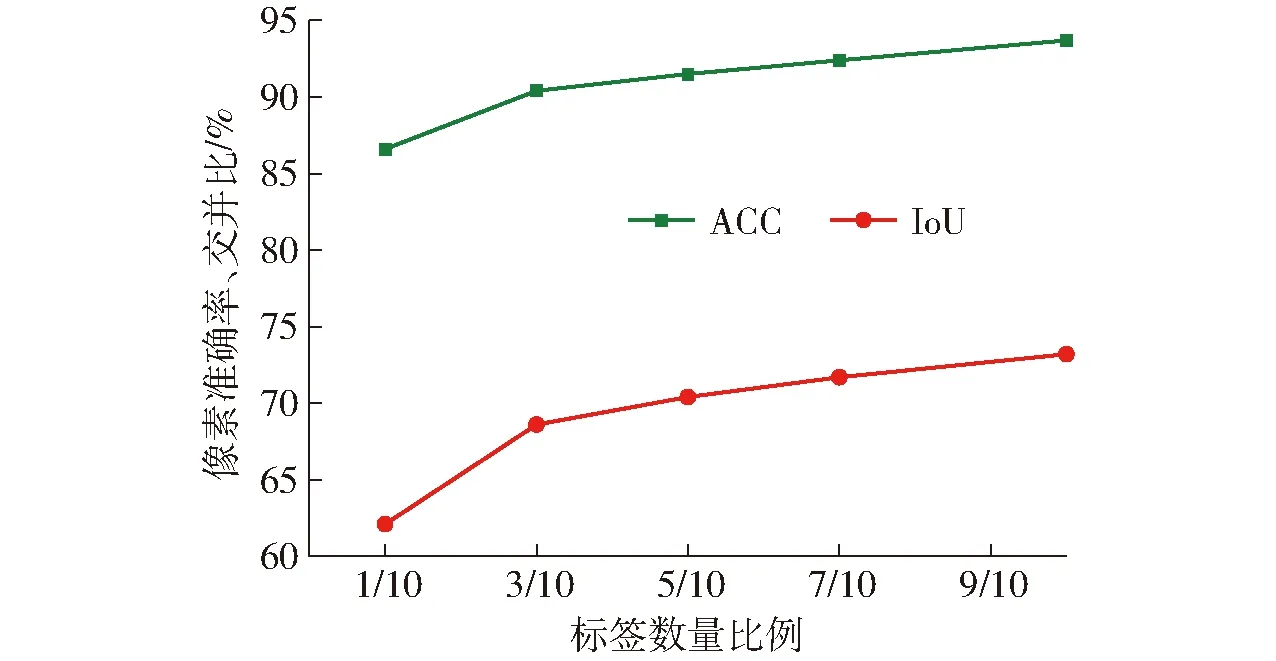
图13 网络像素准确率与交并比变化曲线Fig.13 Change curves of network pixel accuracy and intersection over union
由图13可知,随着微调标签数量的不断增加,网络的像素准确率和交并比均呈不断提高趋势,当标签比例由1/10增加为3/10时,提升速度最快,后面随着标签比例的增加,提升速度较慢,当所有标签数据全部用于微调模型时,像素准确率和交并比都达到最大值,此时像素准确率为93.7%,交并比为73.2%(表2);当微调标签比例为3/10时(即使用360幅标签数据对模型进行微调训练),网络像素准确率、交并比和召回率分别达到90.4%、68.6%和83.2%,已经和使用1 200幅标签数据进行有监督训练的AFR-LinkNet网络各项评价指标(像素准确率90.6%、交并比69.7%、召回率86.4%)相当;当使用1 200幅全部标签数据进行微调时,其网络性能的各项评价指标相比有监督训练有了较大的提高。这验证了本文提出的自监督对比学习方式进行网络预训练,并结合非均匀采样,可以在少量有标签数据情况下使网络达到较高的河流提取效果,解决了遥感图像河流标签数据难以大量获取的问题。
(2)样本数据增强对网络性能的影响
通过数据增强可以增加训练样本的多样性,提高模型鲁棒性,有效避免网络过拟合。图14为经过数据增强和没有进行数据增强的网络各项评价指标的对比,从图14可以看出,经过数据增强后,网络的像素准确率、召回率和交并比相较于没有经过数据增强的网络,分别提高5.3、4.4、4.8个百分点,这表明将样本进行数据增强能更好地提升网络性能。
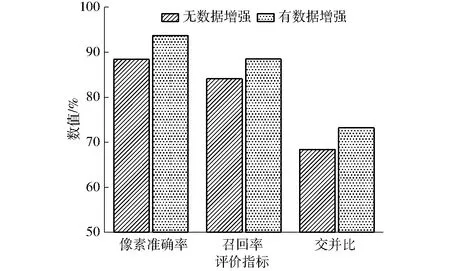
图14 数据增强对网络评价指标的影响Fig.14 Influence of data enhancement on network evaluation index
(3)自监督对比学习与非均匀采样对网络性能的影响
选用AFR-LinkNet网络为基准网络,使用1 200幅有标签数据训练有监督网络AFR-LinkNet,同时对通过自监督对比学习方式训练的网络进行微调,并将非均匀采样与两种网络分别结合,验证其对网络性能的影响。图15为验证集上各网络像素准确率变化曲线,表3为测试集上网络对应的各项评价指标。
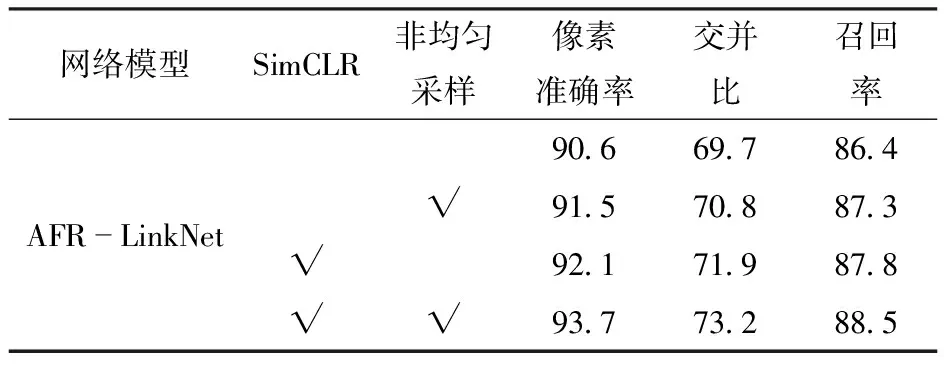
表3 网络各项评价指标Tab.3 Network evaluation indicators %
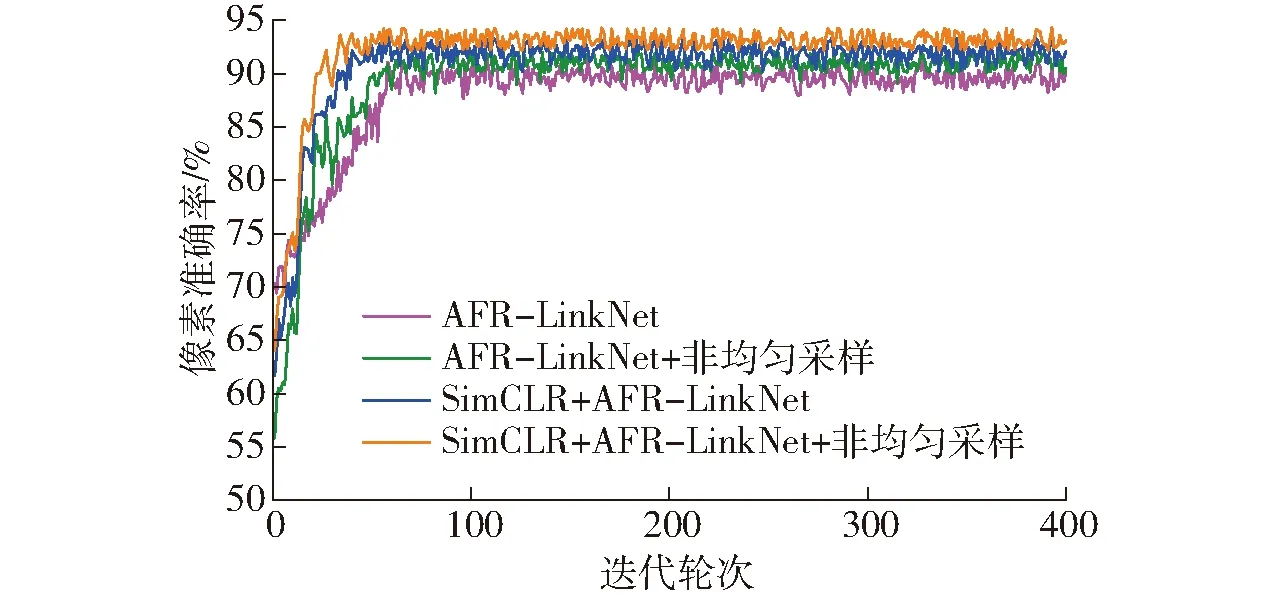
图15 像素准确率变化曲线Fig.15 Change curves of pixel accuracy of each network
由图15和表3可知,没有引入非均匀采样时,仅通过自监督对比学习方式预训练编码器,使得网络学习到有监督网络无法学习到的图像内在信息,网络收敛速度快于有监督的AFR-LinkNet网络,像素准确率达到92.1%,提高1.5个百分点,交并比、召回率分别提高2.2、1.4个百分点;当引入非均匀采样后,有监督和自监督网络像素准确率都进一步提升,自监督网络的像素准确率达到93.7%,相比有监督网络AFR-LinkNet提高2.2个百分点,交并比和召回率分别提高2.4、1.2个百分点,验证了非均匀采样的有效性和较强的泛化性能。图16为3幅相应网络的遥感图像河流分割效果,通过自监督对比方式训练并引入非均匀采样的网络,其河流提取的连续性得到提升,细小河流更加连贯,边缘细节提取也更加准确,能够有效优化河流边缘细节,在边缘容易误判处提取效果也更加平滑,降低了对道路、冰雪、高山阴影的错误识别。

图16 3幅图像不同网络提取结果对比Fig.16 Comparisons of extraction results of three images with different networks
5 结束语
针对有监督网络训练需要大量遥感图像河流标签数据以及河流提取边缘细节分割效果不佳问题,提出一种通过自监督对比学习方式利用大量无标签数据预训练编码器,并将训练好的编码器利用迁移学习方式迁移到下游河流提取任务中,并使用少量标签数据进行微调编码器,然后结合一种新的非均匀采样方式对寒旱区遥感河流图像进行提取的网络。实验结果表明,仅用360幅有标签数据就达到与使用1 200幅有标签数据训练的有监督网络相当的提取效果,当全部标签用于微调网络编码器时,其像素准确率、交并比和召回率分别达到93.7%、73.2%和88.5%,均高于有监督网络,解决了大量标签数据难以获取的问题,并提高了河流提取精细度,证明了其有效性和泛化性。
猜你喜欢
小太阳画报(2019年4期)2019-06-11
车迷(2018年11期)2018-08-30
成都信息工程大学学报(2018年3期)2018-08-29
海峡姐妹(2018年3期)2018-05-09
散文诗(2018年20期)2018-05-06
电子设计工程(2017年20期)2017-02-10
公民与法治(2016年10期)2016-05-17
电子器件(2015年5期)2015-12-29
少儿科学周刊·少年版(2015年11期)2015-12-17
计算机工程(2015年8期)2015-07-03
