
基于计算机视觉的仰卧起坐计数算法
2023-06-09 08:57陶青川
现代计算机 2023年7期
敬 倩,陶青川
(四川大学电子信息学院,成都 610065)
0 引言
人工智能、深度学习和计算机视觉等技术在体育行业的应用日趋成熟和广泛,极大地促进了学生体测测评系统的研究[1]。深度学习在运动分析领域中已经取得了长足的进步,它在预测能力和应用效果方面都表现出色[2]。Jian等[3]通过使用卷积神经网络来逐帧分析运动员的训练过程,并从中提取出关键帧来估算姿态,最终建立起一种能够根据感知变化来调整姿态的算法。Grunz 等[4]对足球比赛使用人工神经网络的分层结构进行了深入的分析,并且在较短时间完成了较多数据的处理,还发现该方法可以对比赛策略进行更有效的优化,针对当前情况给出有效战术。
仰卧起坐是体测项目中的通用考核项目,有一定难度。在完成仰卧起坐动作时,动作标准与否以及改进之处基本上依靠人脑的主观经验性的评价,存在效率低下和打分误差大的问题[5],无法在不同环境、不同时刻、不同测试人员之间保证考核和指导相一致,也比较难具体、细致、专业地指导学生。
综上,本文设计了一种基于计算机视觉的仰卧起坐计数算法,在解决传统问题的基础上,减轻了监考人员和成绩录入的压力,具有较高的理论研究价值和实用性。首先通过摄像头采集动作信息,将其输入到改进后的YOLOv7‑Pose[6]网络中检测出人体的关键点坐标,根据关键点坐标计算当前动作和标准动作之间的相似度,并对符合要求的动作进行计数。
1 关键点检测算法
1.1 关键点检测算法介绍
随着深度学习技术的发展,基于二维人体关键点预测的方法在各个领域风靡,通过该技术,我们可以更好地提取图像和视频的特征,并且比传统方法更准确地估算人体姿态[7]。从RGB 图像中确定所含的人体,并定位人体的各个关键点坐标是二维姿态估计的基本任务。基于二维人体姿态研究目标数量的差异,可分为单人以及多人方法。单人姿态估计是多人姿态估计的基础[8]。单人姿态估计分为基于直接预测人体坐标点的坐标回归方法,以及基于预测人体坐标点的高斯分布的热图检测方法。基于方法论的不同,多人姿态估计的主要研究方法可以分为基于关键点的方法和基于实例的方法这两种[9]。基于实例的方法先从图像中检测出所有人体目标,接着单独对每个目标进行姿态估计。而基于关键点的方法首先检测当前场景内人体的全部坐标点,然后再将对应的关键点连接成图,最后通过图优化的方法剔除错误的连接,构成人体的姿态骨架。
与传统姿态估计算法不同,YOLOv7‑Pose是一个单级多人关键点检测器。它具有自顶向下和自底向上两种方法的优点,是基于YOLO目标检测框架提出的新颖的、无热力图的方法,类似于谷歌使用回归计算关键点的思想,YOLOv7‑Pose既不使用检测器进行二阶处理,也不使用热力图拼接,是一种暴力回归关键点的检测算法,且在处理速度上具有一定优势。
1.2 算法模型
YOLOv7‑Pose 由两个组件组成:Backbone和Head。Backbone 是一种用于提取图像特征的卷积神经网络。Backbone 主要包含了CBS、ELAN 等模块,CBS 操作其实是由三个操作组合而成:Conv、BN 和Silu 激活函数;ELAN 模块是一个高效的网络结构,也是YOLOv7的主要贡献之一,由多个CBS 构成,它通过控制最短和最长的梯度路径,使网络能够学习到更多的特征,并且具有更强的鲁棒性。
YOLOv7‑Pose的Head相当于融合了YOLOv5的Neck 和Head 的功能,主要包含SPPCSPC、ELAN−W 等模块,作用是对图像进行预测。SPPCSPC 用SPP 空间金字塔池化操作代替了卷积层后的常规池化层,可以增加感受野,使得算法适应不同的分辨率图像;CSP 模块首先将特征分为两部分,其中的一个部分进行常规的处理,另外一个部分进行SPP 结构的处理,最后把这两部分合并在一起,从而减少一半的计算量,速度得到有效提升。ELAN−W 跟ELAN模块非常相似,略有不同的就是它在第二条分支的时候选取5个输出进行相加。
YOLOv7‑Pose 首先将输入的图片转换为640 × 640 大小,输入到Backbone 网络中,然后经Head 层输出四个特征图,再分别经过Rep 和Conv 输出20 × 20,40 × 40,80 × 80 和160 ×160这四种不同尺度的未经处理的预测结果。
YOLOv7‑Pose 在公开数据集上有着一流的表现,模型的特征提取和预测能力都得到了认可,但是其模型YOLOv7‑w6 的参数量过大导致无法在边缘设备上运行,因此,本文对其进行了轻量化改进,以适用于本文的体能计数场景。
1.3 改进的算法模型
本文提出的算法应用在单人体能训练场景,摄像头采集的人体目标较大,因此针对YOLOv7‑Pose进行了一系列改进,改进策略如下:
(1)YOLOv7‑Pose 采用4 层特征融合的方式主要是为了解决小尺寸目标难以检测的问题,但是这对算法的检测速度也会有影响。特征图像的尺寸越小,它们就越能够检测到大体积的物体,反之亦然[10]。考虑到实际场景下的人体目标较大,因此删除YOLOv7‑Pose 针对小目标检测的两个分支80 × 80 和160 × 160,只保留20 × 20 以及40 × 40 这两个针对较大尺寸的目标的独立预测分支。
(2)由于仰卧起坐计数只需要检测较为简单的人体目标,只有这一个类别且场景简单,最重要的是对实时性的要求较高,因此本文对原网络的ELAN和ELAN‑W 模块的特征提取层进行删减,从而大幅度降低了网络参数,提高了姿态估计的实时性。改进后的网络结构如图1所示。
(3)由于仰卧起坐的计数不需要关注头部的信息,比如眼睛和耳朵,因此将YOLOv7‑Pose原本的17 个关键点缩减至13 个,主要关注四肢及躯干等重点部分的关键点,从而加快推理速度,进一步提高了姿态估计的实时性。
使用改进后的网络对自制仰卧起坐数据集进行训练,在几乎不降低精度的前提下,模型的计算量从153.7 M 下降到30.7 M,即降低到原来的1/5,证明了本文轻量化方法的有效性。
2 实验与分析
2.1 动作计数算法
人体骨骼是人类运动的基础,所以,我们能够通过观察人体骨骼来更好地理解身体行为和活动方式。本文提出的动作计数方法首先通过YOLOv7‑Pose 检测出人体关键点坐标,再用坐标信息表征人体运动姿态,改进后的模型可以对视频进行实时检测,满足算法实时性需求。由于仰卧起坐动作的特殊性,每个动作都会带来上下半身的折叠角度的变化,因此本文根据仰卧起坐不同关节角度变化自定义了检测方式,只需要判断人体肩关节、髋关节和踝关节三个部位的角度变化来区分动作是否标准[11]。对姿态估计获得的人体关键点坐标进行处理,得到上述角度值,当角度大于160°时认为躺下,角度小于100°时认为坐起,当两个条件同时满足时,方可认为是一个合格的仰卧起坐,从而计数一分钟内学生所做的仰卧起坐个数,停止计数,期间若有动作不满足以上条件,则视为不规范且不计数。
计算公式如下:设肩膀,髋及脚踝的点位分别为A(x1,y1),B(x2,y2)和C(x3,y3),可得到待测角度为
2.2 性能评价指标
(1)平均准确度(average precision, AP)。单人姿态估计AP 的计算公式基于OKS,OKS 表示了真实关键点和预测关键点之间的相似性[12],AP的计算公式为
式(2)中,T为给定的阈值。
(2)平均准确度均值(mean average preci‑sion, mAP)。平均精度均值是常用的指标之一,其计算方式为先求出所有关节点的AP,再对其求均值[12],计算公式如下:
(3)计数准确率(count accuracy, CA)。CA是本文提出的评价指标,记实际仰卧起坐数量TrueNum,测得仰卧起坐数量为TestNum,则计数准确率公式为
基于以上评价指标,表1给出了改进前后的两个网络相关参数的对比。
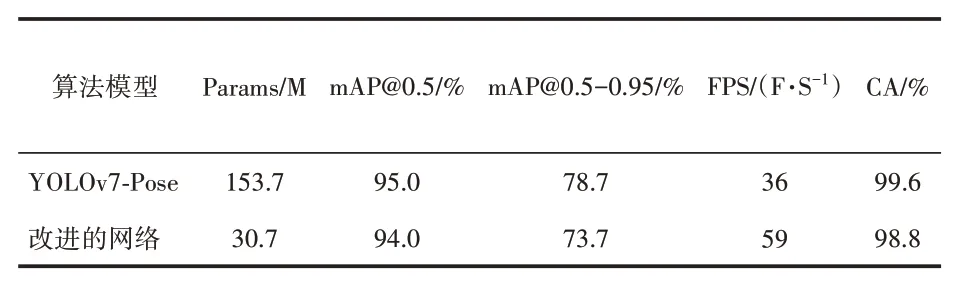
表1 改进前后网络各参数对比
2.3 结果与分析
本文的实验环境为Ubuntu16.04LTS,处理器为Intel(R)Xeon(R)Platinum 8255C,主频2.50 GHz,基于64 位操作系统,使用的GPU 型号为GeForce RTX 2080 Ti,单卡,显存为11 GB,模型的训练和测试基于PyTorch 1.8.2框架。
现有的二维数据集,如MS COCO、MPⅡ等,图像中大部分是站立的正面的人体,但是本文关注的场景基于侧面的横向的人体,因此公开数据集并不能完全适配当前动作场景。因此本文是基于自制的数据集。首先是在不同光照、拍摄距离和背景下拍摄了80 个仰卧起坐动作的视频,然后进行人工打标,再通过镜像、旋转和裁剪等数据增强方式扩充数据集,最终达到10000个样本。
本文以仰卧起坐计数的准确率为评价指标,选取50 个时长1 分钟的视频进行测试,使用本文的方法最终的计数准确率CA(count accuracy)达到98.8%,可以部署在边缘设备。相比于传统的计数方法,本文方法计数的精度更高,且更便捷。基于本文方法的计数效果图如图2所示。

图2 计数效果图
3 结语
本文针对仰卧起坐计数任务,对YOLOv7‑Pose网络进行轻量化改进,对ELAN模块删减部分特征提取层,减少关键点预测量,并删减针对小目标的检测分支。在自制数据集上的实验结果证明,以上改进在少量精度损失下,大大减少了模型大小,提高了关键点提取速度,有利于后续基于关键点坐标进行体能计数。但是本文的算法是采用人工设计的轻量化网络,更注重降低网络的参数量和检测的实时性,缺乏了一定的人体结构约束带来的先验知识,后续将进一步完善。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
数学小灵通(1-2年级)(2021年11期)2021-12-02
今日农业(2021年8期)2021-11-28
中等数学(2020年8期)2020-11-26
学生天地(2020年3期)2020-08-25
小学生学习指导(低年级)(2020年4期)2020-06-02
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
数学小灵通·3-4年级(2017年11期)2017-11-29
中国卫生(2014年2期)2014-11-12
