
基于改进YOLOv5算法和边缘设备的电动车违规载人检测
2023-06-08 08:10孙福临李振轩粱允泉董苗苗葛广英
现代计算机 2023年8期
孙福临,李振轩,粱允泉,董苗苗,葛广英
(1. 山东省光通信科学与技术重点实验室,聊城 252059;2. 聊城大学物理科学与信息工程学院,聊城 252059;3. 聊城大学计算机学院,聊城 252059)
0 引言
这些年来,随着社会经济的不断发展,汽车的保有量不断攀升,燃油价格走高,机动车出行越发不便,越来越多的人选择了电动车这一出行方式。正是因为许多人在驾驶电动车出行时缺乏安全意识,有关部门于2022 年出台了新的交通法规,对电动车驾驶人员的行为做出了严格限制,其中明确规定电动车严禁违规载人。目前来说,仅仅依靠交警很难完成对于电动车违规载人行为的查处,并且缺乏相关的能辅助交警检测的电子系统或设备。因此,结合计算机视觉以及深度学习技术来构建一套可以判别电动车违规载人的系统很有必要。
21 世纪,伴随着深度学习技术突飞猛进的发展,立足于深度学习的目标检测算法也迎来了长足发展,主要包含了以YOLO、SSD[1]、Efficientnet[2]系列算法为代表的单阶段检测方法和以R‑CNN[3]、Faster R‑CNN[4]、Mask R‑CNN[5]等算法为代表的两阶段检测方法这两大类目标检测算法。其中两阶段检测的网络依赖于算法提前产生的目标候选框,而单阶段检测方法则不需预先生成目标候选框。
自2015 年YOLOv1[6]被提出以来,YOLO 系列算法得到了广泛发展,YOLOv1算法利用回归的思想,使用一阶网络直接完成了分类与位置定位两个任务。YOLOv2[7]在此基础上加入了Batch Normalization,High Resolution Classifier,Anchor Boxes 等方法,成功地提升了网络收敛速度和网络定位的精准度。2018 年YOLOv1 的作者提出了YOLOv3[8],它是前作的改进,最大的改进特点包括使用了残差模型Darknet‑53来提升主干网络的深度,以及为了实现多尺度检测采用了FPN 架构。YOLOv4[9]在原来的YOLO 目标检测架构的基础上,采用了很多优化策略,在数据处理、主干网络、网络训练、激活函数、损失函数等方面都有不同程度的优化,有效增强了网络的学习能力,降低了成本。YOLOv5则是于2020年通过Ultralytics 提出,该网络一经问世便广受好评。与YOLOv4 相比,YOLOv5 不仅目标检测的准确率不相上下,而且其强大的推理能力、快速的训练过程,以及轻量级的模型大小使其非常适合于前端部署和快速目标检测,这项优点使得YOLOv5广受青睐。
综上所述,正是由于YOLOv5 在推理速度和准确率方面都十分优秀,而针对于电动车违规载人检测的轻量级算法部署在模型推理速度和准确率方面均有较高的需求,因此本文在YOLOv5的基础上,进一步针对其网络结构进行不断优化,通过更换轻量级主干网络Mobile‑netv3、增加高效的注意力机制ECA‑Net、更换轻量级的颈部网络Slim‑Neck、空间金字塔池化结构SPPFCSPC 等方法以达到尽可能减少参数量和计算成本的目的,进而实现提高FPS 和检测精度的目标,最终通过筛选模型的准确率和推理速度等指标来确定和验证所提出模型的优越性,并将其部署在前端嵌入式设备Jetson nano上进行实时检测。
1 YOLOv5网络模型概述
自从2020 年Ultralytics 发布YOLOv5 以来,该算法经过了多次更迭和改进,目前最新的YOLOv5‑6.2 共有五种不同参数量的版本(N,S,M,L,X),他们的不同之处在于控制其网络的宽度和深度的参数不同,如果想要完成边缘计算的模型部署,首选模型最小且参数量最少的YOLOv5n部署实验,其结构如图1所示。
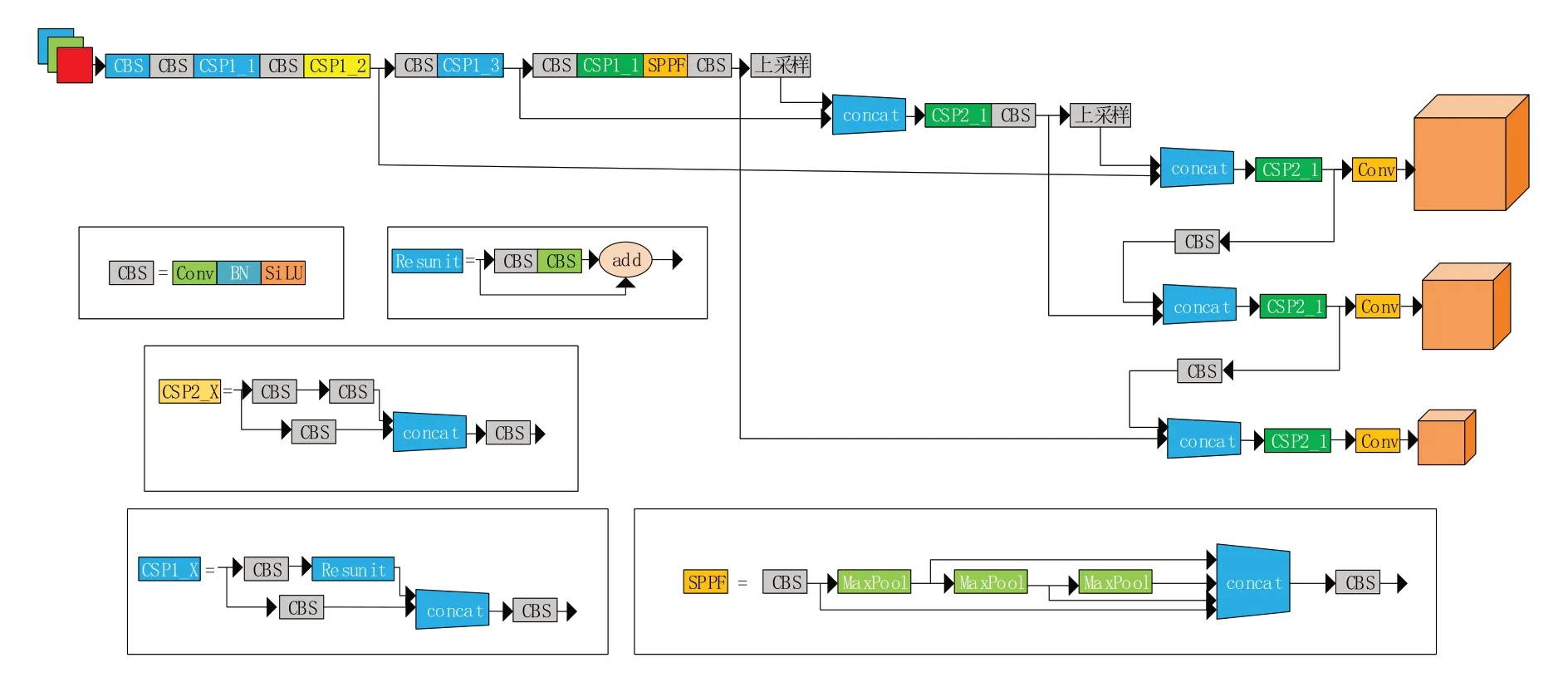
图1 YOLOv5结构
YOLOv5n 的整个结构由四部分组成:①由各种卷积网络组成的主干网络Backnbone;②用于预测目标框和目标类别的检测头Head;③介于Backbone 和Head 之间的Neck 结构;④用于输出检测结果的预测层。
YOLOv5n算法的工作原理:
(1)输入端采用了自适应图片缩放、自适应锚框计算、Mosaic 数据增强对数据集进行操作以提高目标检测的精确度。
(2)主干网络删除了Focus 结构来压缩网络提高速度,使用CSP1_X 残差结构对图像特征进行提取,使用相较于SPP[10]结构而言速度更快的SPPF结构进行特征提取,提高感受野。
(3)Neck 网络使用了FPN[11]+PAN[12]结构并结合CSP2_X 结构来融合图像特征,得到预测的特征图。
(4)输出端使用了DIOU_Loss 损失函数,在IOU_Loss 和GIOU_Loss 的基础上,改进了边界框中心点距离的信息。
2 电动车违规载人模型改进
2.1 YOLOv5n主干网络改进
随着深度学习的不断发展,深度学习模型的网络深度持续增加,虽然很大程度上提升了精度,却也使得模型对计算资源的要求越来越高,运行速度变慢[13]。因此本文想要寻求一种以YOLOv5为基础的轻量化网络模型,作为适用于边缘设备的解决方案。
在YOLOv5n 的主干网络中,主要由Conv 模块和使用了CSP 架构(cross stage partial network)的C3 模块组成,它们的主要工作就是提取输入图片的有效特征信息。在实验中发现,YOLOv5的作者设计的通过调节网络宽度系数和深度系数的方式来减少网络参数实现模型轻量化的方法,会导致训练出的模型的目标检测准确度降低,同时误检率和漏检率升高。因此,本文寻求一种可以在减少网络参数量的同时提高特征提取能力的方法来实现轻量化,故此引入Mo‑bilenetv3 网络结构对YOLOv5n 的主干网络所使用的Conv模块和C3模块进行替换,达到同时缩减模型参数量和提升检测准确率的目的。
2.1.1 Mobilenetv3工作原理
Mobilenetv1[14]是由Google 团队于2017 年提出的专注于移动端或者嵌入式设备的轻量级CNN 网络。使用深度卷积(depthwise convolu‑tion,DW)在准确率小幅降低的前提下大大减少模型参数与运算量。紧接着,2018 年Google 团队又提出了Mobilenetv2[15],基于前作增加了两个新的改进点,使用倒残差结构(inverted residu‑als)来增加网络深度,减少DW 卷积所造成的特征信息损失;在结构的最后一层采用线性层(linear bottlenecks)取代了ReLU 激活函数,降低对低维特征的信息损失。
2019 年提出的Mobilenetv3[16]网络在结合前作的基础上重新设计了耗时层,加快了推理速度,引入了轻量级注意力机制SE‑Net(squeeze‑and‑excitation networks)并且重新设计了激活函数(hard‑sigmoid)。
深度可分离卷积(depthwise separable convo‑lution,DSC)包含了深度卷积(depthwise convolu‑tion,DW)以及逐点卷积(pointwise convolution,PW)两个部分,图2展示了其卷积过程。相较于传统卷积而言,DSC 卷积的参数量和计算量都大幅减少,对比如下:
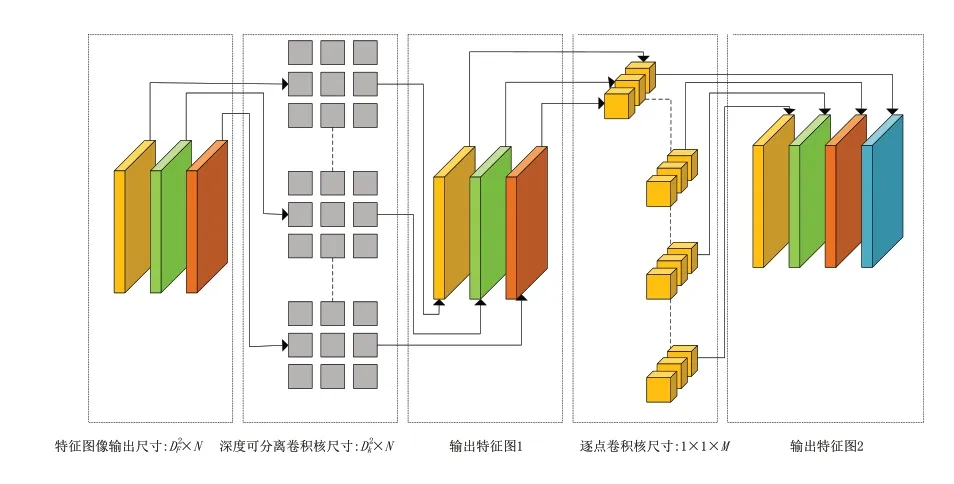
图2 深度卷积示意图
其中:W1代表了DSC 卷积的计算量;W2代表了传统卷积的计算量。Mobilenetv3 网络中卷积核尺寸多数为5*5。所以DSC卷积的计算成本仅为传统卷积的1/25。
如图3 所示,在Mobilenetv3 的倒残差结构中先使用1*1卷积扩张通道数,在高维度中使用DW 卷积,最后使用1*1 卷积缩减通道数。这样做的目的在于通过第一次的升维操作将Tensor维度拉高,低纬度Tensor 计算速度快,但是无法提取足够多的特征信息,因此将通道数目扩张,而针对高维Tensor 使用传统卷积计算量太大,因此使用DW 卷积既可以有效完成特征提取又可以减少运算量,随后再使用1*1卷积来压缩数据重新让网络变小,实现轻量化计算。正因如此,Mobilenetv3 可以用于构建轻量化网络[17],从而适配于边缘计算。
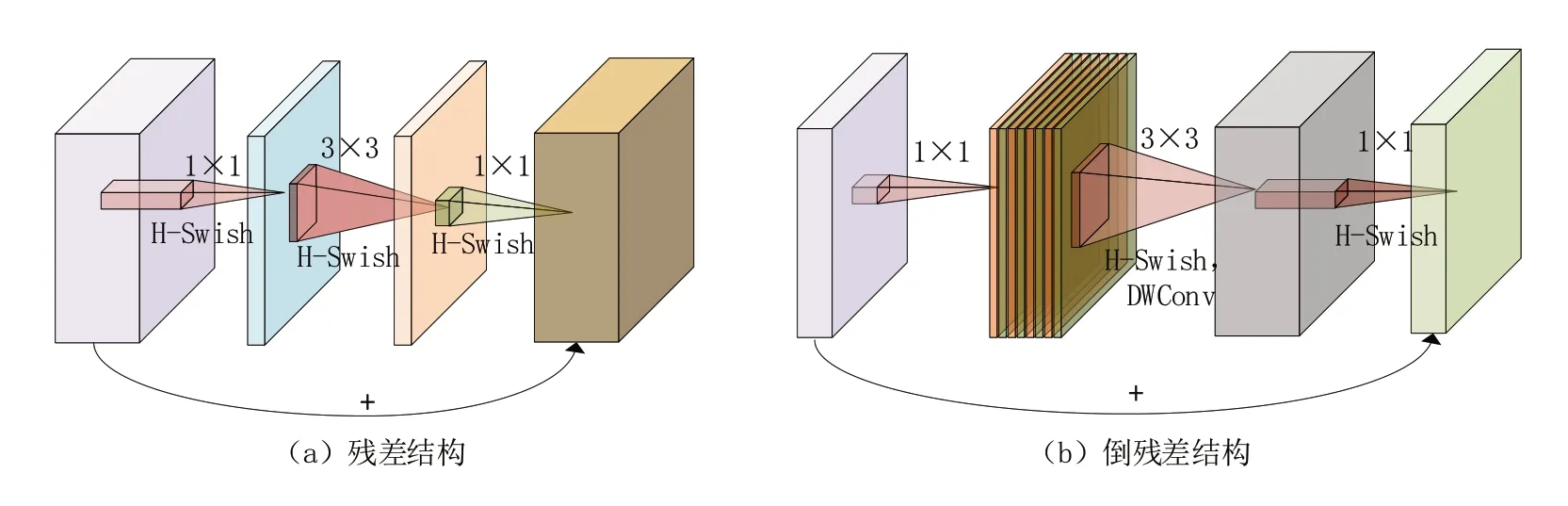
图3 残差结构与倒残差结构示意图
2.1.2 Mobilenetv3激活函数改进
之前在Mobilenetv2 都是使用ReLU6 激活函数。现在比较常用的是swish 激活函数,即swish=x×σ(x)。使用swish 激活函数确实能提高网络的准确率,但是它存在一些问题。首先就是其计算和求导时间复杂,仅仅是进行σ(x)计算和求导就比较困难了。其次就是对量化过程非常不友好,特别是对于移动端的设备,为了加速一般都会进行量化操作。为此,作者提出了一个叫做h‑swish的激活函数。
h‑swish激活函数与h‑sigmoid有些相似之处:
从图4 可以看到swish 激活函数的曲线和h‑swish 激活函数的曲线非常相似。Mobilenetv3 的作者在原论文中提到,经过将swish激活函数替换为h‑swish,sigmoid 激活函数替换为h‑sigmoid 激活函数,对网络的推理速度是有帮助的,并且对量化过程也很友好。

图4 激活函数对比
2.2 针对于Mobilenetv3注意力机制的改进
常用的注意力机制一般分为通道注意力机制和空间注意力机制两种,在Mobilenetv3中添加了轻量级注意力机制SE‑Net(squeeze‑and‑excitation networks)[18],属 于 通道注意 力 机制。如 图5 所示,在输入SE 注意力机制之前,特征图的每个通道的重要程度都是一样的,通过SE‑Net之后,不同颜色代表不同的权重,使每个特征通道的重要性变得不一样,使神经网络重点关注某些权重值大的通道。
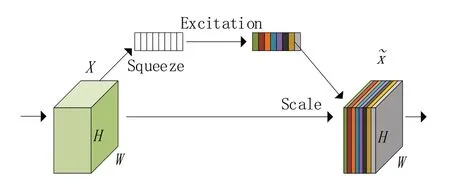
图5 SE注意力机制
SE注意力机制的实现步骤如下:
(1)Squeeze:通过全局平均池化,将每个通道的二维特征(H*W)压缩为1个实数,将特征图从[h,w,c]转变为[1,1,c]。
(2)excitation:给每个特征通道生成一个权重值,论文中通过两个全连接层构建通道间的相关性,输出的权重值数目和输入特征图的通道数相同。特征图张量保持不变。
(3)Scale:将前面得到的归一化权重加权到每个通道的特征上。Mobilenetv3 论文中使用的是乘法,每个通道分别乘以权重系数。
SE‑Net 的核心思想是通过全连接网络根据loss损失来自动学习特征权重,而不是直接根据特征通道的数值分配来判断,使有效的特征通道的权重增大。然而SE‑Net注意力机制不可避免地增加了一些参数和计算量,SE‑Net中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依存关系效率不高,而且是不必要的。因此,本文使用SE‑Net的改进版ECA‑Net[19]注意力机制对其进行替换。
ECA 注意力机制模块直接在全局平均池化层之后使用1*1卷积层,去除了全连接层。该模块避免了维度缩减,并有效捕获了跨通道交互。并且ECA‑Net 只涉及少数参数就能达到很好的效果[20]。
ECA‑Net 通过一维卷积layers.Conv1D 来完成跨通道间的信息交互,卷积核的大小通过一个函数来自适应变化,使得通道数较大的层可以更多地进行跨通道交互。
自适应函数为
其中:γ= 2,b= 1。
ECA‑Net注意力机制如图6所示。
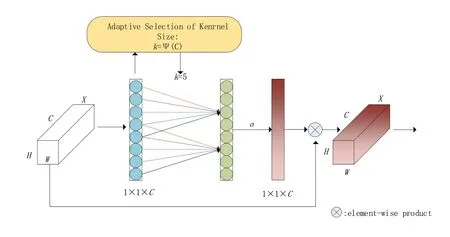
图6 ECA注意力机制
ECA注意力机制的实现过程如下:
(1)将输入特征图经过全局平均池化,特征图从[h,w,c]的矩阵变成[1,1,c]的向量。
(2)根据特征图的通道数计算得到自适应的一维卷积核大小kernel_size。
(3)将kernel_size 用于一维卷积中,得到对于特征图的每个通道的权重。
(4)将归一化权重和原输入特征图逐通道相乘,生成加权后的特征图。
2.3 兼顾精准度与高效的GSConv和颈部网络改进
2022 年6 月,重庆交通大学和不列颠哥伦比亚大学共同提出了新的卷积模块GSConv[21],阐述了目前的卷积机制的优劣,PW 卷积的精度高但是计算成本高,DSC 卷积可以有效缓解高计算成本[22],但是其缺点也十分明显,其输入图像的通道信息在计算过程中是分离的,这会导致精度出现下降。在此基础上提出了GSConv结构,通过GSConv 引入了Slim‑Neck 方法,在减少计算成本的同时维持精度,更好地维护了模型准确性与速度的平衡。其结构如图7 所示。首先使用卷积核尺寸为1*1 的PW 卷积运算压缩通道数,得到特征图f1,再经过DW 卷积得到特征图f2,将二者拼接得到f3,而后通过shuffle 操作将PW 卷积生成的信息渗透到DW 卷积生成的信息当中,得到最终的特征图f4,这样做既能减少计算成本又可以最大限度降低DW 卷积对模型精度造成的影响,使最终的卷积结果接近于PW卷积。
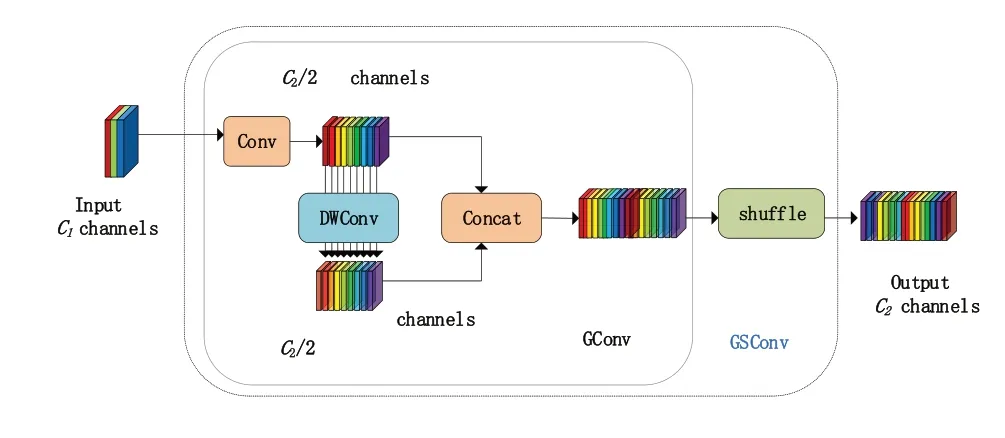
图7 GSConv结构
为了加快模型的运算速度,特征图会在Backbone 中经历如下的过程:空间信息会逐步向通道传输,特征图的宽度和高度被不断压缩而通道数逐渐增多,这会导致语义信息的丢失。PW 卷积最大程度地留存了通道之间的隐藏链接,而DSC 卷积则完全切断了这些隐形链接,由于GSConv结合了PW 卷积和DSC卷积的特点,所以尽可能多地保留了这种隐形链接,但是如果在Backbone 和Neck 中都是用该结构的话,会使网络模型层不断加深,这会大大增加推理计算所耗费的时间,而特征图在传输到Neck 时,已经变得较为细长,不再需要进行变换,冗余信息少且不需要压缩,因此在Neck 部分使用GSConv 效果最好。值得一提的是,原论文中认为在使用Slim‑Neck 的基础上使用注意力机制和空间金字塔池化结构的效果会更好,因此本文也针对这两处做了改进[23]。
使用轻量级卷积网络GSConv 代替PW 卷积构建GSbottleneck,其结构如图8(a)所示。相较于原先的bottleneckCSP,其运算量只有60%~70%,两者的学习能力旗鼓相当。在此基础上,我们使用一次性聚合方法来构建跨级部分网络(GSCSP)模 块VoV‑GSCSP,结 构 见 图8(b)。VoV‑GSCSP 在保持了精准度的基础上,降低了网络结构的复杂性和计算成本。与YOLOv5原先的C3模块相比,其FLOPS降低了大约15.7%。
本文在此基础上使用GSConv替换原Conv结构,使用VoV‑GSCSP 结构替换C3 结构,构建Slim‑Neck结构,如图9所示。
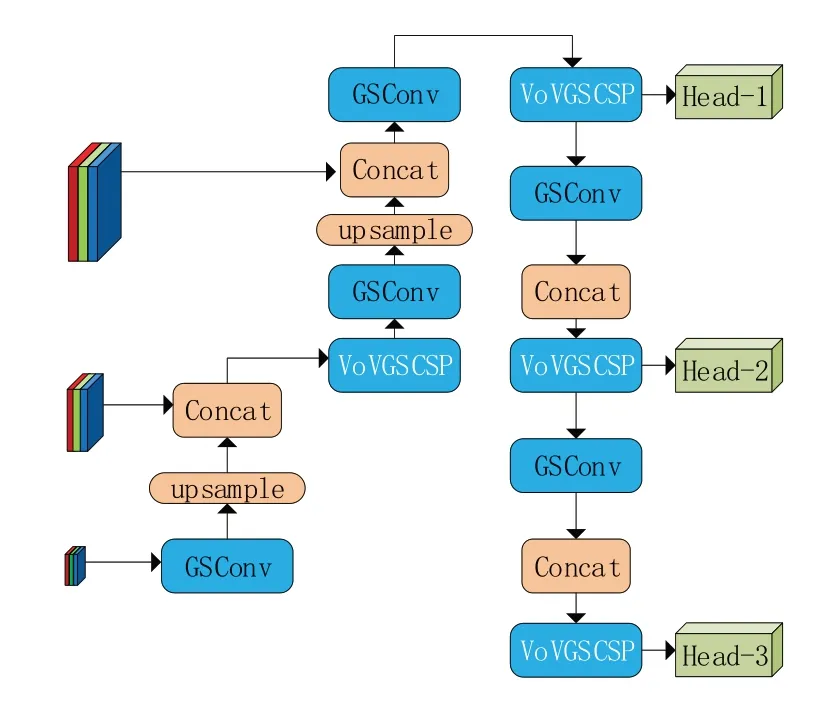
图9 Slim⁃Neck结构
2.4 空间金字塔池化结构(SPPFCSPC)
空间金字塔结构(SPP)最早由何凯明提出,旨在解决输入图像的尺寸问题,该结构包含三个显著优点,一是可以忽略输入尺寸并产生固定长度的输出;二是使用多尺度空间容器进行Maxpool;三是可以在不同尺度上提取特征图的特征信息,有效提高了识别准确率。在YO‑LOv5‑6.0 中其作者提出了SPPF 结构,相较于SPP 模块而言,SPPF 模块使用了多个小尺寸的池化核,通过级联的方式来替代大尺寸的池化核,经过实验证明,该方法可以在保留原有的融合不同尺寸的特征图的功能下,加快推理速度,可以节省大约51.6%的推理时间。
YOLOv7 在SPP 的基础上提出了一种名为SPPCSPC 的金字塔池化结构,其结构如图10(a)所示。该结构与原SPP 结构相比,输入端要先通过一个卷积核尺寸为1*1的卷积压缩通道数得到特征图f1,然后再通过两个卷积核尺寸为3*3和1*1 的卷积得到特征图f2,然后通过SPP 结构,得到特征图f3,再将f3通过两个卷积核尺寸为3*3 和1*1 的卷积得到f4,与输入端经过一个1*1 卷积后得到的f5进行Concat 操作,得到的结构再通过一个1*1卷积得出最终结果。
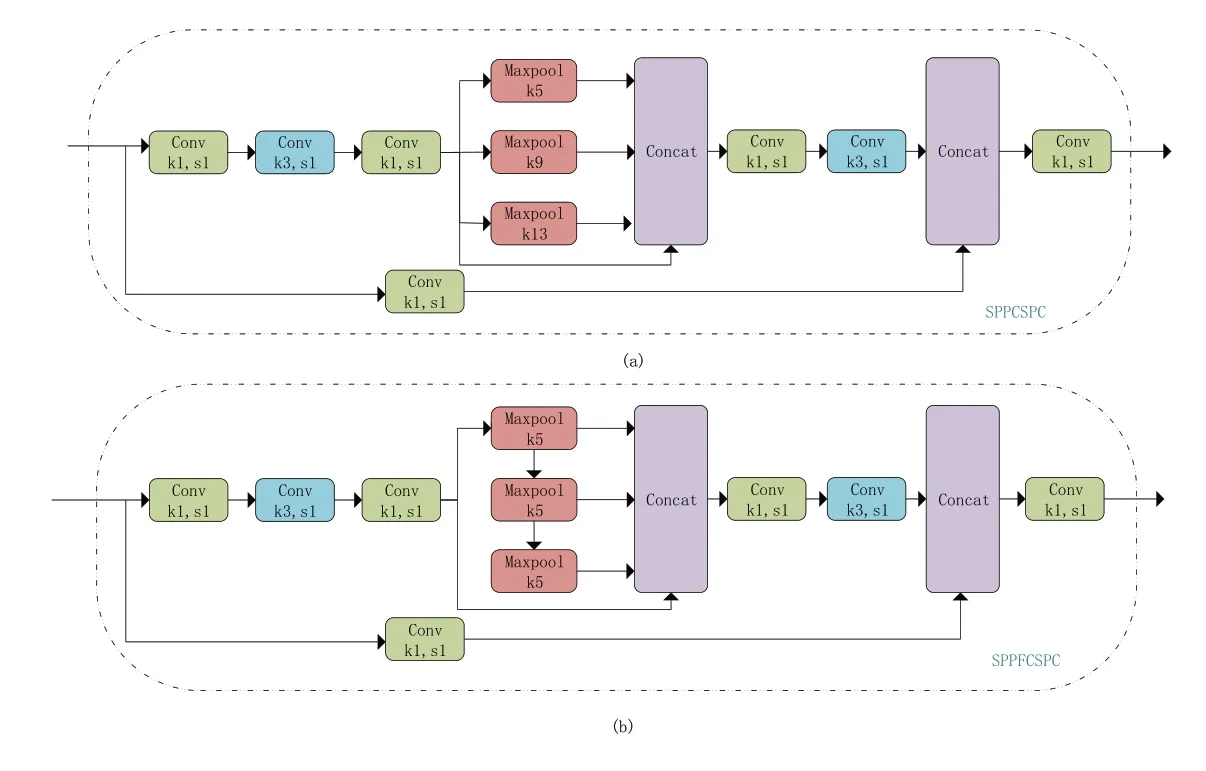
图10 SPPCSPC和SPPFCSPC结构
本文所使用的SPPFCSPC[24]结构由博主迪菲赫尔曼于他自己的博客提出,其结构如图10(b)所示。该结构立足于SPPF 对SPP 结构的改进方法,将YOLOv7 所提出之SPPCSPC 结构中最大值池化的部分修改为类似于SPPF 的多个小尺寸卷积核级联的方式,本文经过实验可以证实,在参数量没有改变的情况下推理时间缩减为SPPCSPC的72.7%。
2.5 改进的YOLOv5目标检测算法
综上所述,根据以上的改进策略完成网络模型的搭建。如图11 所示,输入的电动车违规载人检测图像首先经过Backbone 的Mobile‑netv3‑ECA 模块,通过其中的DWconv 卷积完成特征提取,然后经过ECA‑Net 注意力机制完成通道维度的信息融合,特征信息被送入空间金字塔池化结构SPPFCSPC,在不同尺度进行特征提取,而后送入颈部网络,通过轻量化的Slim-Neck 结构,不同大小的特征层之间会再进行特征的进一步处理,最终将特征信息送入头部网络进行目标的检测。
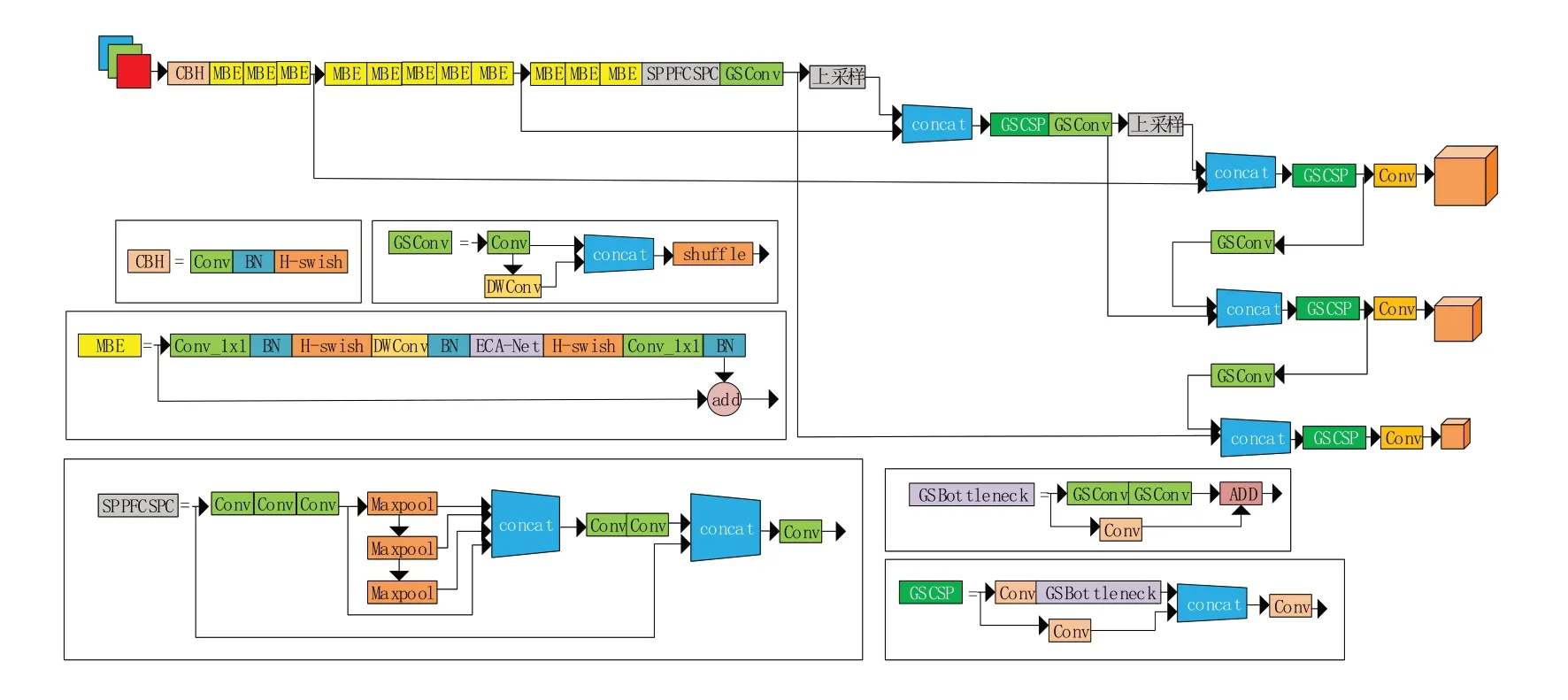
图11 YOLOv5⁃Mobilenetv3⁃ECA结构
3 实验方案
3.1 实验数据来源
因为目前尚未出现统一且公开的电动车违规载人的数据集,因此本文所使用的实验数据均通过网络爬虫和使用摄像头在不同道路对行驶的电动车进行拍摄获取,所获取的数据包括了不同的角度、不同的明暗色调、不同的道路场景和车辆稠密程度。总共有图片12951张,其中涵盖了电动车驾驶的各种尺寸的目标,使用LabelImg软件,将检测对象分成两类:overload、safe。根据分类对待检测对象进行标注。对于模糊的物体和远离摄像头的物体则不进行标注。
将数据集打乱后随机进行挑选和分类,最终选取了11291张图片作为训练集,验证集和测试集各830张图片,将数据集送入网络进行训练。
3.2 实验环境
本次实验的实验平台基于Windows10 操作系统搭建,Intel(R)Xeon(R)Silver 4210R CPU@2.40GHz型号的CPU 共有两个。GPU 显存为8GB的Quadro RTX 4000 系列,使用PyTorch 深度学习框架,编程语言为Python3.8,网络模型使用YOLOv5n,将改进之后训练完成的网络模型结合摄像头和边缘设备组成电动车违规载人检测系统,系统界面如图12所示。

图12 系统展示界面
3.3 实验结果及分析
本文选用精确率(precision,P)、召回率(re‑call,R)、平均精确度(mean average precision,mAP)、参数(parameters,Par)、浮点运算数(giga floating‑point operations per second,GFLOPs)、帧速(frames per second,FPS)这六个指标作为改进后网络模型的评价标准,其中帧速指标使用CPU 对图片进行推理而测定,目的是检验在低算力的边缘设备上改进模型的推理速度和计算能力。
本文将YOLOv5n 作为电动车违规载人检测的baseline,以此为基础增加各类改进策略进行消融实验,来验证不同改进策略在使用本文的数据集进行训练所生成的模型的检测性能的优化效果。为了验证本文针对YOLOv5n 所使用的两种优化策略,在保持相同的硬件配置、数据集和超参数的情况下,加入Mobilenetv3 模块、ECA 注意力机制、Slim‑Neck 结构和SPPFCSPC模块,通过实验来验证改进策略的有效性,其结果见表1和表3。
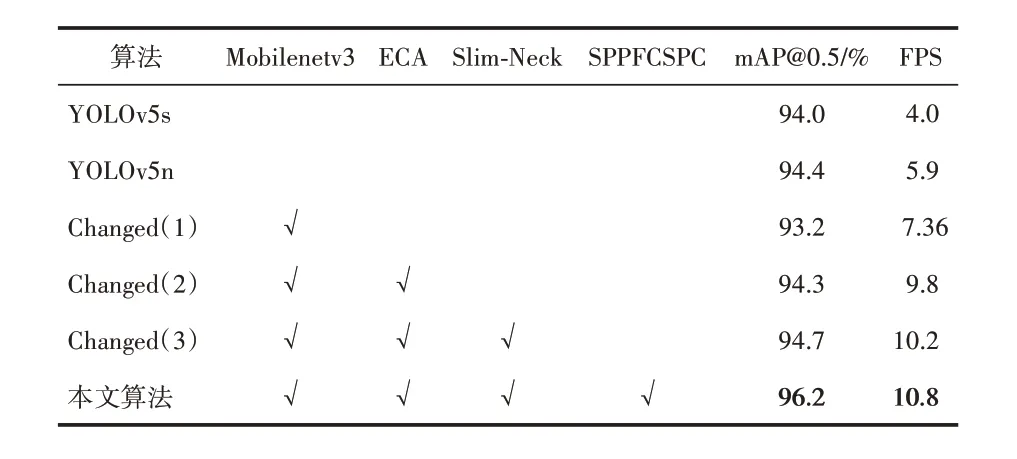
表1 YOLOv5n消融实验

表3 实验结果
通过结果分析可知,与YOLOv5n 相比,引入Mobilenetv3 后,参数量减少为原先的42%,FPS 提升了24%。继续引入ECA‑Net 注意力机制后,其参数量下降为原始YOLOv5n 的18%,检测速度相较于YOLOv5n也提升至原先的1.66倍,在mAP@0.5 这个指标上与YOLOv5n 基本持平。而通过对比Changed(1)和Changed(2)算法可以看出,Mobilenetv3‑ECA 结构的算法在mAP@0.5上提升了1.1%,在参数量上缩减了57%,并且FPS 提升了0.33%。由此可以证明在低算力平台下,Mobilenetv3 结构可以有效降低参数量,节约推理时间,而引入ECA‑Net 注意力机制来替换Mobilenetv3 中原有的SE‑Net 注意力机制可以进一步降低网络参数量,并且提高了网络的特征提取能力,提升了网络中不同尺度之间特征融合的能力,弥补了单纯使用轻量化网络降低网络参数而导致的网络损失部分特征提取能力不足,以及检测精度下降的缺点。通过比较Changed(2)算法和Changed(3)算法可以看出,mAP@0.5 和FPS 均有所上升,这是由于引入了轻量化的颈部结构Slim‑Neck,减少了颈部网络的参数量从而加快了推理速度。通过比对本文算法和Changed(3)算法可知,在mAP@0.5 指标上提升了1.5%,这是因为在Slim‑Neck 结构前加入了空间金字塔池化结构SPPFCSPC,通过SPPFCSPC 结构在不同尺度上完成特征提取的特征图在送入Slim‑Neck 后由于其冗余信息少的特点可以取得更好的结果。
图13 展示了两车重合场景、树木遮挡场景、人物重合场景下,消融实验的检测结果对比,可以看出消融实验组检测结果的准确率要低于本文算法,并且会出现错检和漏检的现象,而本文所提出的算法在以下场景均有较好的检测效果。

图13 消融实验对比示例
3.4 边缘设备部署实验与结果分析
为了验证本文所提到的改进模型在边缘设备上的推理能力,我们将模型部署在边缘设备上进行实验。
3.4.1 边缘设备简介
本文的边缘设备使用NVIDIA 公司于2019年发布的Jetson Nano 开发套件,Jetson Nano 使用 了ARM 系 列 的4 核64 位CPU 和NVIDIA 公 司的128 核集成GPU,最高可提供472 GFLOPS 的计算性能,拥有4 GB 容量的LPDDR4 存储器,具有高功效、低功耗的特点。
该产品使用了基于Ubuntu18.04 的Jet‑Pack4.4.1 镜像系统,拥有流畅的图形操作界面,支持NVIDIA CUDA Toolkit 10.0,以及cuDNN 7.3 和TensorRT 等库,也支持主流的深度学习框架如TensorFlow,PyTorch 等,同时还安装了计算机视觉的框架,如OpenCV 和ROS。完全兼容这些框架的Jetson Nano(见图14),非常适合作为承载AI 推理测试和实时目标检测的轻量化边缘计算设备,设备的具体配置如表2所示。

图14 NVIDIA Jetson Nano
3.4.2 部署实验
表3展示了在Jetson Nano设备上部署模型进行推理得到的性能指标对比结果。
通过表3 的实验结果可以发现,YOLOv5s在YOLO Parsing time、Inference time、FPS 这些指标上都要远低于YOLOv5n,其中YOLOv5n 的FPS 提升了72.6%。这是因为不管是参数量还是网络深度,YOLOv5n 都要远小于YOLOv5s,因此推理速度较快;通过对比YOLOv5n 和Changed(1)可以看出,在YOLOv5n 的基础上使用Mobilenetv3 结构替换backbone 中原有的卷积模块后可以发现,新的网络模型参数量大幅度减少伴随着mAP@0.5 也有降低,这是由网络参数量下降使得网络的特征提取和融合能力下降导致的。在Changed(2)算法中,其FPS 相较于YOLOv5n提升了72.9%,然而YOLO Parsing time却并未有明显提升,这是因为虽然使用了轻量化网络Mobilenetv3 降低了网络参数量,却导致了网络层数大幅增加,使得推理过程中对于YOLO 层的解析速度提升并不明显。针对Changed(1)的两个缺陷,在Changed(2)算法中使用ECA‑Net 注意力机制替换SE-Net 注意力机制,一方面增强网络的特征提取能力;另一方面减小网络深度,减少YOLO 层的解析时间。Changed(2)相较于YOLOv5n 而言,其mAP@0.5基本持平且FPS 也提升了72.9%,并且得益于网络深度的减少,YOLO Parsing time 也降低了8.3%,取得了良好的推理速度。通过对比Changed(2)算法和Changed(3)算法的结果可以看出,增加了Slim‑Neck 结构后其参数量降低了30%,FPS 增长了5.8%,Inference time 下降了13.9%,进一步加快了推理速度,验证了轻量化颈部网络Slim‑Neck 的有效性。通过观察本文算法的数据可以看出,在Changed(3)算法的基础上引入SPPFCSPC 模块后,mAP@0.5 增长了1.5%,验证了SPPFCSPC 结构可以有效增强网络的特征提取能力,提高检测的精度。可以看出在Slim‑Neck 的基础上引入SPPFCSPC 结构后,本文算法与Changed(2)算法相比,在参数量(Parameters)超过Changed(2)算法的情况下,GFLOPs 却小于Changed(2)算法,在map@0.5 取得1.9%的增长后FPS基本持平,可以验证Slim-Neck 与SPPFCSPC 结合后在网络推理速度和检测精度二者之间取得了良好的平衡性。本文算法在取得较高的检测精度的同时维持了较高的检测速度,其检测速度可以满足实时目标检测和前端部署的需求。
本文选取了100组数据进行推理实验,将每组数据的推理时间做比对,其结果如图15所示。相较于其他消融实验的算法,本文算法的推理速度较快且推理过程最为稳定,其推理时间浮动集中在59 ms 到64 ms 之间,通过对比可以验证本文所提出的算法具有良好的推理速度和不错的稳定性。
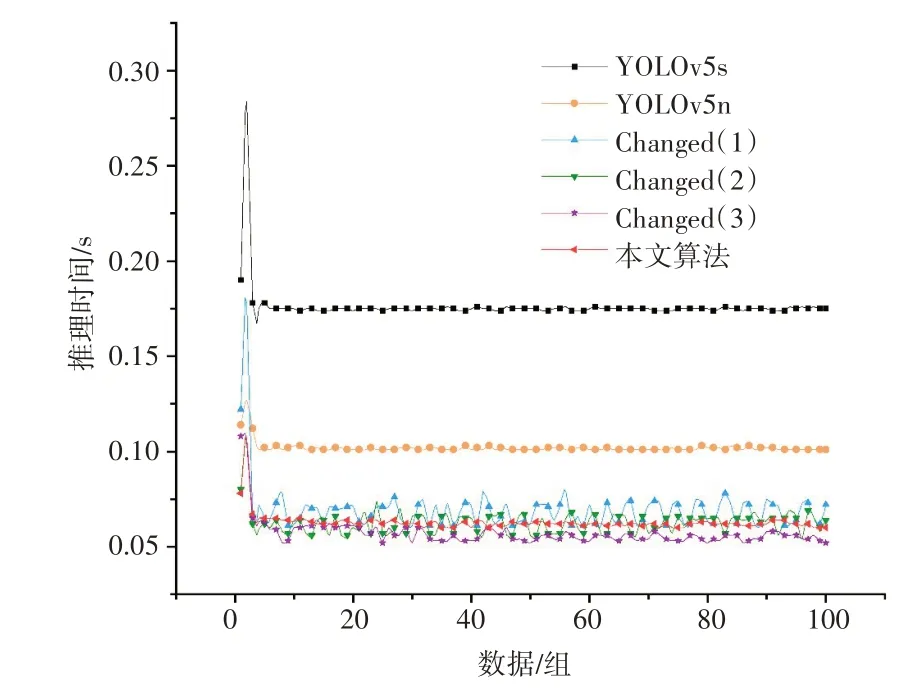
图15 100组数据推理时间折线图
4 结语
综上,本文基于YOLOv5目标检测算法,通过加入Moblienetv3 轻量化网络、ECA-Net 注意力机制、Slim‑Neck 结构和SPPFCSPC 空间金字塔池化结构的方式对YOLOv5进行改进,来实现电动车违规载人的检测效果,将改进后的算法和NVIDIA 的边缘设备Jetson Nano 相结合,通过边缘计算的方式测试了改进算法的检测效果,并且比较了不同的网络模型在Jetson Nano 上的推理速度和检测精度。根据实验结果分析,可以在边缘设备Jetson Nano上运行YOLOv5目标检测算法,且本文所提出的算法比YOLOv5n 的检测速度更快,模型参数量较少。为交警提供了一种在复杂交通环境下查处电动车违规载人的解决方案,为了更好地帮助解决复杂交通环境下的各类实时检测问题,后续工作也将基于边缘设备Jetson Nano展开。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
文苑(2018年21期)2018-11-09
北京航空航天大学学报(2018年1期)2018-04-20
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
中国卫生(2015年9期)2015-11-10
中国卫生(2014年3期)2014-11-12
中国火炬(2014年4期)2014-07-24
