
基于YOLOv4 改进算法的零件表面缺陷检测*
2023-06-04 06:24王宪伦孙宇轩
计算机与数字工程 2023年2期
王宪伦 孙宇轩 王 栋
(青岛科技大学机电工程学院 青岛 266100)
1 引言
在经济高速发展的今天,我国的机械行业市场空前扩大。但是由于技术水平和加工设备的限制,零件表面加工质量仍难以出现质的飞跃[1]。传统的检测方式是由人眼进行检测,检测效率低,长时间的工作也会导致检测结果出现纰漏。
近年来,深度学习凭借特征提取与模式识别方面的独特方式和优势在众多领域发挥了独到的作用。在目标检测方面,随着图像采集设备的不断发展,图像采集的质量不断提高,基于计算机视觉的目标检测逐渐流行起来[2]。早期的目标检测是基于图像的颜色、纹理等特征进行特征提取,进而实现目标检测[3~4]。随着卷积神经网络[5](CNN)的提出,以及硬件性能的提升,基于深度学习的目标检测算法成为主流,并且取得优秀的成果。目前。基于深度学习的目标检测算法主要分两种。一种是基于区域建议的目标检测算法,代表算法是RCNN、Fast-RCNN、Faster-RCNN 等[6~8],其原理是利用启发式方法或者CNN 网络提取区域块,再对区域中的对象进行识别。另外一种是基于回归方法的检测算法,代表算法为YOLO、SSD 等[9~10]。其原理是仅使用CNN 网络来预测目标的种类和位置。
深度学习在应对复杂工业环境下的缺陷检测有着独到的优势[11]。基于深度学习的缺陷检测已经应用各种工业环境下。文生平等采用变形卷积技术和密集连接技术改进YOLOv3 框架,将其应用到铝型材的表面缺陷检测,取得了良好的成果[12]。刘亚男利用机器视觉的相关方法对钢材表面进行缺陷检测,通过灰度化、图像增强、边缘提取的方法提取出缺陷区域,再进行缺陷识别,达到了较好的效果[13]。张秦玮等建立了利用粒子群算法进行参数寻优的PSO-SVM 分类识别模型来检测焊盘表面缺陷。首先采用OTSU 算法将焊盘从背景中提取出来,再利用PSO-SVM 分类识别模型进行缺陷识别分类。将该模型和传统的B-P神经网络对比,体现了该算法的优越性[14]。
目前,对于零件表面缺陷的检测仍存在一定的问题。复杂的表面缺陷种类,表面缺陷的隐蔽性,加工环境复杂性等等,这都是影响检测结果的因素。某些方法虽然检测结果准确,但是实时性较差,无法实现实时检测的功能。为了解决上述问题,本文提出了基于YOLOv4 改进算法的零件表面缺陷检测算法,利用稠密网络结构代替部分残差网络结构,使网络参数更少,从而提升算法的运算速度,并且保证了检测结果的准确性。
本文中采用的训练集为德国DAGM2007 数据集,以其中8 种缺陷图像为检测目标。由于该数据集包括的缺陷图片较少,因此采用图片增强的方式进行扩充,使训练集的数量达到6800张。
通过实验对比了原算法和改进算法的检测精度和每张图片的检测时间,证明了改进的检测算法在保证检测精度的同时,可以明显减少图片检测时间,提高了检测效率。
2 YOLOv4目标检测改进算法
2.1 YOLO算法介绍
2.1.1 YOLOv1
与RCNN 算法有所不同,YOLOv1 采用了端到端的检测框架,将目标检测作为回归问题来处理。其核心思想是将整张图片作为输入,直接在输出层回归预测框和预测类别。实现方法为将一张图片分成s×s的网格,如果某个物体落在某个网格中,则由这个网格预测这个物体。每个网格要预测B个预测框,每个预测框要负责预测物体中心的位置和置信度一共5 个变量。置信度包括了预测框中是否存在物体和物体检测准确度两种信息,其计算公式如式(1)所示。
其中,如果物体中心在网格内,则Pr(Object)取1,否则取0。IOU代表了预测框和实际框的重合度。
在检测时,通过式(2)来计算每个框预测目标的得分。
其中Pr(Classi|Object)是每个网格的预测信息。通过设定阈值,过滤掉低分的预测框,在通过非极大值抑制算法进行处理,便可以得到需要的预测结果。
2.1.2 YOLOv2
为了实现更快的检测速度和更高的准确率,在YOLOv1 的基础上,Redmon J 等提出了YOLOv2[15]。YOLOv2 采用了多种方法来提升准确率和检测速度。首先,YOLOv2 提出了基于CNN 网络的Darknet-19,并使用416×416的输入格式,这样的图片在经过5 次下采样后生成13×13 的特征图,奇数的特征图会使获得的中心点特征更加准确。YOLOv2还采用了大量的小技巧来提升准确率,包括批量正则化,基于K-means算法生成锚点,迁移学习等。
2.1.3 YOLOv3
YOLOv3[16]是在YOLO 之前的基础上,借鉴了一些优秀的方案,从而实现更高的准确率。主要的改进方案为:网络结构调整;多尺度预测;logistic代替Softmax进行分类。
在网络结构上,YOLOv3 提出了Darknet-53 网络结构,该结构借鉴了残差网络结构,在一些层之间设置了快捷链路,从而加深网络结构,可以获得更好的结果。与YOLOv2 不同,YOLOv3 提出了多尺度预测的方案。该方案有利于产生不同尺寸的特征图,从而获得不同大小的感受野,这有利于检测不同尺寸的对象。logistic 代替Softmax 进行分类,这能够支持多标签对象。
2.2 YOLOv4改进算法
YOLOv4 目标检测算法是以YOLOv3 算法为基础,在数据处理、特征提取框架、激活函数,损失函数等方面进行优化,从而获得速度和准确度上最优匹配[17]。YOLOv4 算法主体框架包括以下几个方面:CSPDarknet53 特征提取网络,空间池化网络SPP[18],特征金字塔PAnet[19],YOLO Head 预测模型。在CSPDarknet53特征提取网络上进行修改,将部分残差网络模型替换为稠密网络模型,从而减少网络参数量,在保证检测精度的情况下,提高运算速度,进而提高识别效率。改进后的网络模型如图1所示。
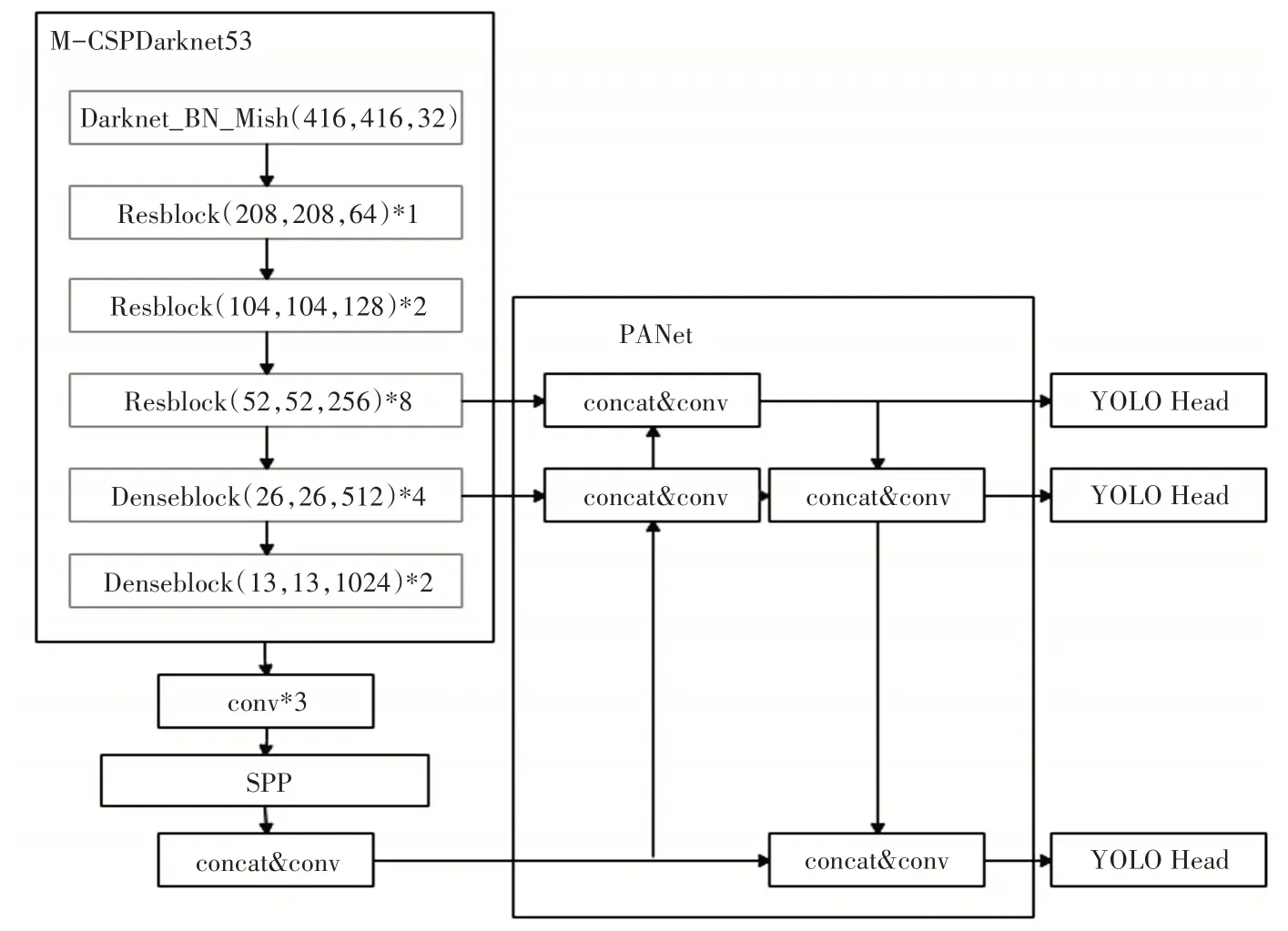
图1 YoLov4改进算法框架
2.2.1 稠密网络模型
为了加快运算速度,减少模型参数是重要的一步。同时,为了保证检测结果的准确性,需要加强模型对于小特征的特征提取能力,充分利用每个卷积层的输出信息,采用稠密网络模型对部分残差网络模型进行代替。
稠密网络模型的基本思想和残差网络模型基本一致,都是建立前层和后层的短路连接。由于稠密网络充分利用了每个卷积层的特征信息从而可以充分利用前层的特征信息,防止出现梯度消失,可以训练出更深的网络模型[20]。稠密网络模型如图2所示。
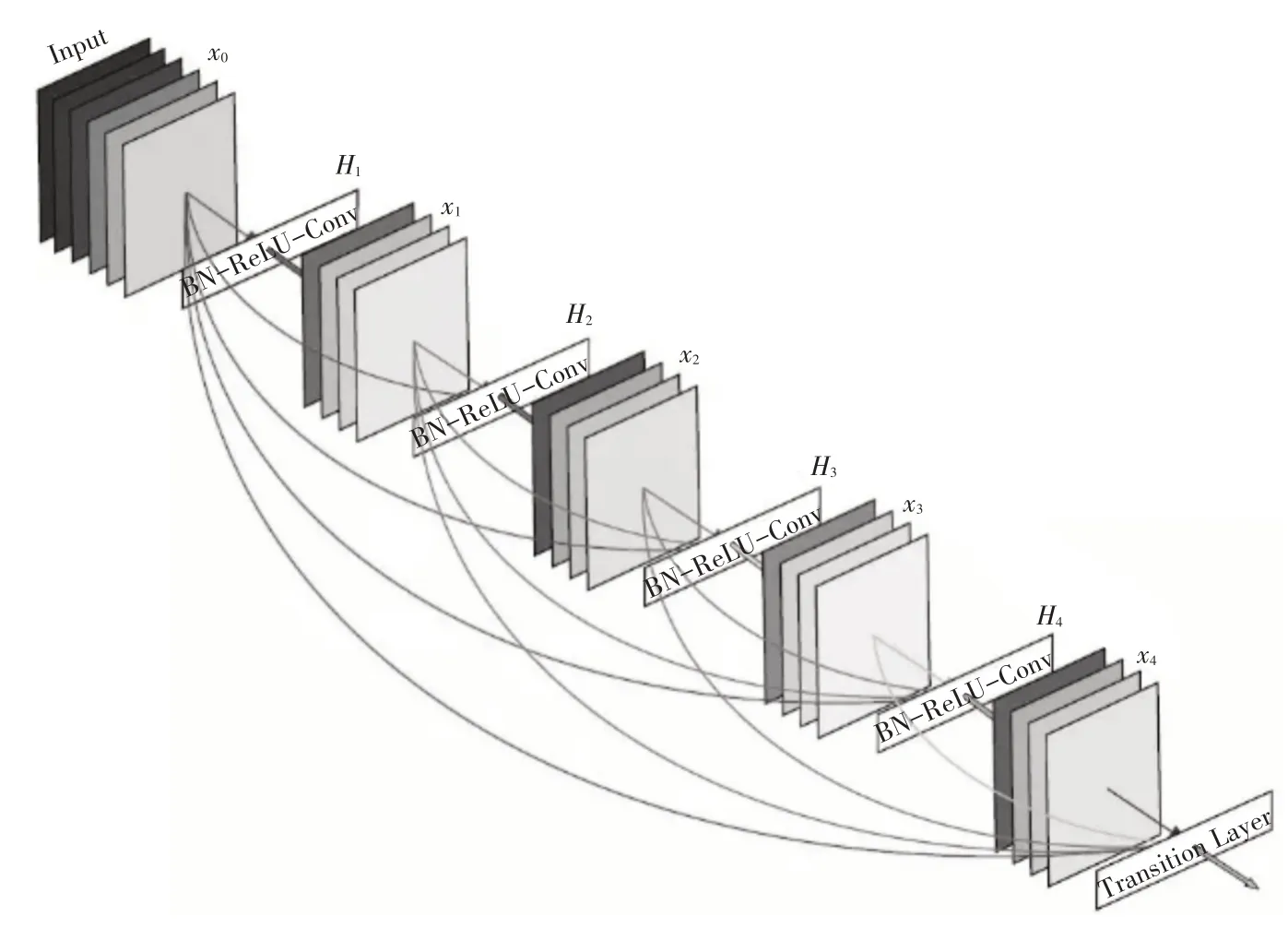
图2 稠密网络
与残差网络模型有所不同,稠密网络模型建立了与前面所有层与后面层的密集连接,从而实现了特征重用,在使用更少参数和计算成本的情况下获得更优异的性能。在稠密网络模型中,会连接前面所有的层作为输入,其表达式如式(3)所示:
式(3)中,[]代表了拼接操作,指在将x0层至xi-1层按维度方向进行拼接,并将其作为输入。Hi(·)代表了一些非线性转化函数,目的是将输入进行非线性操作。
2.2.2 YOLOv4目标检测改进算法流程
如图1 所示,改进后的YOLOv4 算法主要由以下几部分组成:M-CSPDarknet53 模型,PAnet 特征金字塔,SPP空间池化结构,YOLO Head预测模型。
训练图片首先经过M-CSPDarknet53 模型进行特征提取,原特征提取结构是由残差网络结构进行特征提取和加深网络,在M-CSPDarknet53 模型中,将最后两层的残差网络层替换为稠密网络层,从而减少训练参数,提高训练和预测速度,并且可以保证预测结果的准确性。
在M-CSPDarknet53 最后一个特征层之后,增加了一个空间池化金字塔(SPP)结构。由于在实际操作时,不可能一直输入固定尺寸的图片,通常情况下,为了满足神经网络的输入尺寸要求,需要对输入图片进行处理。大部分的处理方式是裁剪或者拉伸,这样会导致图像的横纵比发生改变,甚至丢失部分特征。使用SPP 结构可以处理不同尺寸的图像,一定程度上保证了尺寸不变性。由于训练图像尺寸的多样性高,有利于网络收敛,在一定程度上降低过过拟合。
图像经过M-CSPDarknet53 结构和SPP 结构后,会生成尺寸分别为(76,76,256)、(38,38,512)、(19,19,1024)的特征层,特征层会经过PANet特征金字塔结构,最后通过YoLo Head 进行预测。特征金字塔采用上采样的方式利用了底层特征的高分辨信息和高层的语义特征信息,从而保证了图像信息的完整性,有利于图像的识别定位。
经过特征金字塔处理后的特征层输入到YOLO Head,YOLO Head 对输入的3 个不同尺寸的特征层进行预测,从而得出预测结果。
3 数据增强
一般来说,比较成功的神经网络需要大量的参数,而使这些参数能够正常工作则需要大量的数据,但是在实际情况中,数据的数量并没有想象的那么多。因此,需要采用数据增强的方法来对原数据进行扩充,从而获得更多的样本。本文中采用的数据增强的方法为通用数据增强方法和Mosaic 增强方法。
3.1 通用数据增强
通用的数据增强方法包括对图片进行平移、随机剪裁、加噪声、镜像等。增强效果如图3所示。
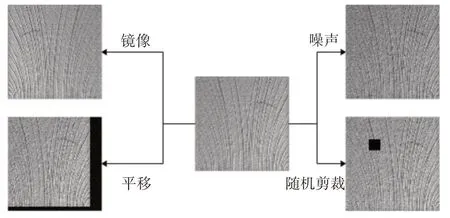
图3 数据增强
3.2 Mosaic数据增强方法
Mosaic 数据增强方法是在YOLOv4 算法提出的图像增强方法,借鉴于CutMix[21]数据增强方法。不同于CutMix,Mosaic 增强方法一次性读取4 张图片进行拼接,该方法首先读取四张图片,然后分别对四张图片进行翻转、缩放、色域变化等,并且安四个方向位置摆好,最后对图片进行拼接。示意图如图4所示。

图4 Mosaic数据增强
4 实验过程与结果
4.1 数据处理
论文中采用的数据集为德国DAGM2007 数据集,选用了其中8 种类型的缺陷作为检测样本。由于数据集中缺陷样本较少,因此采用数据增强的方式增加缺陷样本数量。采用的数据增强方法为旋转,加噪声以及Mosaic 数据增强方法,共计生成6800张缺陷图片。
4.2 实验评判标准
在本论文实验中,将处理每张图片的时间作为效率指标,采用mAP和AP来衡量改进算法的检测性能。计算mAP和AP首先要计算准确率和召回率,准确率和召回率的计算公式如下:
其中,pr代表准确率,re代表召回率。TP是检测缺陷种类正确的数量,FP是检测错误的数量,FN是没有检测出缺陷的数量。针对每个种类的缺陷,计算出pr和re,画出PR曲线。计算PR的面积即为AP,所有缺陷的平均精度为mAP。公式如下。
5 实验过程和结果
数据增强后的缺陷样本总共6800 张,选取其中80%作为训练集,用于训练神经网络,10%作为验证集,10%作为测试集。
实验所用GPU 为Gtx1070Ti,显存8G。软件部分采用Ubuntu18.04 系统。使用Python3.0 作为编程语言,采用Keras 作为深度学习框架。对于数据集的标注则采用Labelimg。
训练结果如图5所示。
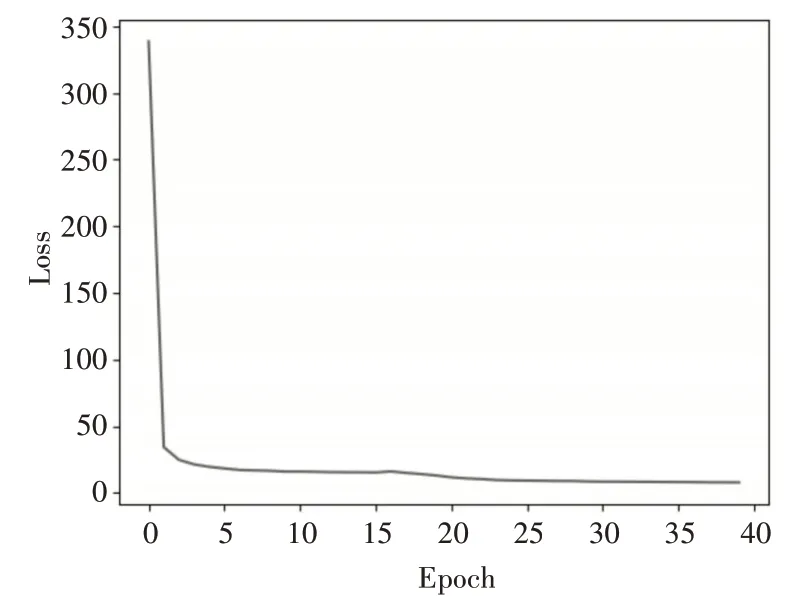
图5 改进算法Loss值
将改进后的YOLOv4 算法和原算法进行对比,对比结果如图6 所示。同时对比了两者的检测时间和mAP,结果如表1所示。
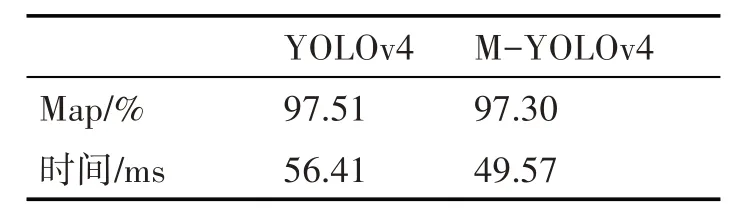
表1 改进前后算法对比

图6 各个缺陷检测AP 值
6 结语
本研究提出了基于改进的YOLOv4 的目标检测算法,以德国DAGM2007 缺陷数据集为检测样本,通过数据增强的方式对缺陷样本的数量进行扩充。通过实验,对比了改进算法和原算法的检测精度和速度,改进算法可以达到97%,每张图片的检测时间为49.57ms。改进之后的算法在保证检测精度的同时,可以明显提升检测速度,从而提升检测效率。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
电子制作(2018年19期)2018-11-14
数学小灵通·3-4年级(2017年9期)2017-10-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
