
MP-CMLMs 模型的藏汉机器翻译研究*
2023-06-04 06:24严松思
计算机与数字工程 2023年2期
严松思 珠 杰 汪 超
(1.西藏大学信息科学技术学院 拉萨 850000)(2.省部共建西藏信息化协同创新中心 拉萨 850000)
1 引言
一方面,深入研究藏汉机器翻译有助于非藏文母语的其他学者了解和掌握藏族的历史和文化;另一方面,深入研究藏汉机器翻译能够促进民族之间的交往交流交融,有助于民族团结。因此藏汉机器翻译研究有非常重要的意义。
藏汉机器翻译近年来的研究进展如下。2017年李亚超等[1]研究了藏汉神经网络机器翻译;赵阳等[2]在CCMT2019评测中针对民汉机器翻译采用知识蒸馏、反向翻译+联合训练和多策略模型等方法,实验结果表明,这些方法能够有效提高翻译的质量;2020年沙九等[3]探究了不同切分粒度的藏汉双向神经机器翻译,该文章提出了藏汉双向机器翻译的具有音节、词语以及音词融合的多粒度训练方法;2020 年慈祯嘉措[4]通过单语语言模型的融合,迭代式回译策略的应用提高了藏汉(汉藏)机器的效果;2021年沙九等[5]构建了面向司法领域的高质量开源藏汉平行语料库;2021年头旦才让等[6]研究了基于改进字节对编码的汉藏机器翻译,该研究改进了字节对编码算法,提出了带字数阈值的藏文字节对编码算法。2021 年刘赛虎[7]进行了基于注意力机制的藏汉双语机器翻译技术研究,该研究在不同切分粒度的实验中,探讨了以藏字汉字、藏词汉词、藏词汉词+BPE 三种切分粒度形态下的两种模型的藏汉机器翻译效果。2022 年孙义栋等[8]通过改进生成藏汉词表来提升下游藏汉双向翻译性能。
虽然一直有学者从事藏汉机器翻译的研究,但目前使用非自回归模型针对藏汉机器翻译的研究较少。藏汉机器翻译仍面临如下问题。1)藏汉平行语料资源稀缺;2)在特定领域的翻译中,性能也受到显著影响。本文针对上述问题,本文研究了基于Mask-Predict 的CMLMs 模型在藏汉机器翻译上的应用,以下简称MP-CMLMs模型。
2 MP-CMLMs模型概述
MP-CMLMs 模型,该模型可以学习并行预测目标翻译中屏蔽词的任意子集。与此同时,这个模型中的解码器的自注意力机制[9]可以关注整个序列(左上下文和右上下文)来预测每个被屏蔽的单词。不同于文献[13]提出的插入模型将每一个token 都视为一个单独的训练实例,本文中的CMLMs可以从整个序列并行训练,从而使训练速度大大加快。而mask predict,这种解码算法,它使用CMLMs的顺序不可知特性来支持高度并行的解码。这种方法仅需几个周期就能产生高质量的翻译。这种整体策略允许模型在丰富的双向上下文中反复重新考虑单词选择。
2.1 CMLMs
CMLMs 模型[14],即条件掩蔽语言模型。该模型采用标准的编码器-解码器转换器进行机器翻译[9]。参数与标准结构保持一致。不同之处在于decode 端的self-attention 不再使用attention mask,防止看到预测单词之后的词。
特别地,在给定一个源文本X 和部分目标文本Yobj后,条件掩蔽语言模型(CMLMs)预测一组目标标记Ymask。本模型假设记号Ymask有条件地相互独立(在给定X 和Yobj的情况下),并预测了每个y∈Ymask的个体概率P=(y|X,Yobj)。
由于Ymask中标记的数量是预先给出的,因此该模型也隐式地调节了目标序列N=|Ymask|+|Yobj|的长度。
CMLMs的总体结构如图1所示。

图1 CMLMs总体结构
在训练期间,模型在目标token 中随机选择Ymask。首先从(1,n)之间的均匀分布中抽取屏蔽记号的数目,n 代表序列长度,其次随机选择该数目的记号。然后用一个特殊的掩码标记替换Ymask的输入。同时针对Ymask中每个token 的交叉熵损失优化CMLMs。上述操作可以并行完成,因为该模型假设Ymask中的token 有条件地相互独立。虽然该架构在技术上可以对所有目标语言标记(包括Yobj)进行预测,但只计算Ymask中标记的损失。
由于CMLMs 是并行预测,所以必须事先就知道序列的长度。因此,受文献[11]的启发,模型在编码器加一个特殊的长度token,这个token 类似于BERT 中的CLS token。该模型可以用来预测目标序列N的长度作为长度标记的输出。
2.2 Mask-Predict
Mask-Predict,即掩码预测算法,该算法在一个恒定的周期数量内并行解码整个序列。在每次迭代中,该算法都会选择要屏蔽的标记子集,然后使用一个底层的CMLMs并行地预测它们。当以先前的高置信度预测为条件时,屏蔽模型有疑虑的标记,让模型重新预测具有更多信息的更具挑战性的情况。
给定目标序列的长度N,定义了两个变量:目标序列(y1,…,yn)和每个标记的概率(P1,…,Pn)。该算法运行一个预先确定数量的迭代次数T,它是一个常数或N的简单函数。在每次迭代中,都会执行一个掩码操作,然后进行预测。图2 说明了算法的掩码预测过程。

图2 来自语料验证集的示例
2.2.1 Mask
在第一次迭代中(t=0),模型屏蔽了所有的token。对于以后的迭代,如下公式,用最低的概率分数掩码n个token。目标:
掩码标记的数量n 是迭代t的函数;具体地说,使用线性衰减,其中T 是总迭代次数。
例如,如果t=10,将在t=1 时掩盖90%的token,在t=2时掩盖80%,以此类推。
2.2.2 Predict
在被掩蔽后,CMLMs 以源文本X 和未被屏蔽的目标标记为条件,预测被掩蔽的token。对每个掩码tokenyi∈掩码选择概率最高的预测,并相应地更新其概率分数:
未掩蔽token的值和概率保持不变:
3 实验
3.1 数据集及预处理
本文将采集到的语料分为口语语料、新闻语料和法律语料。称其为数据集一,语料规模如表1 所示。
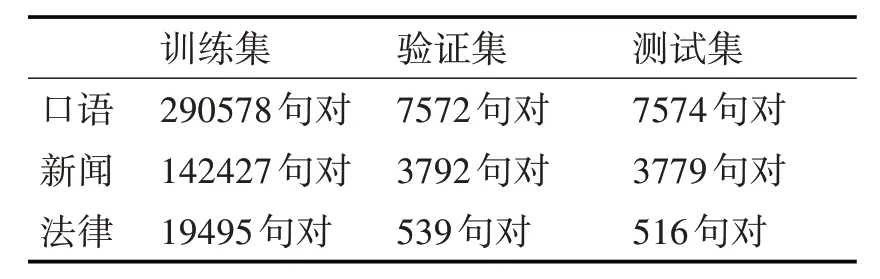
表1 数据集一语料规模
本文按照训练集、验证集和测试集为95∶2.5∶2.5的比例进行划分。
口语领域语料来自人们的日常对话以及部分读物,相对来说较为口语化;新闻领域语料来自《西藏日报》《每日邮报》以及政府公文;法律领域语料由党章、教育法及献血法构成,专业名词多,且用词较为严格。
根据上述比例将训练集验证集和测试集分开后,在测试集中未登录词在这些领域语料中的比重如表2所示。
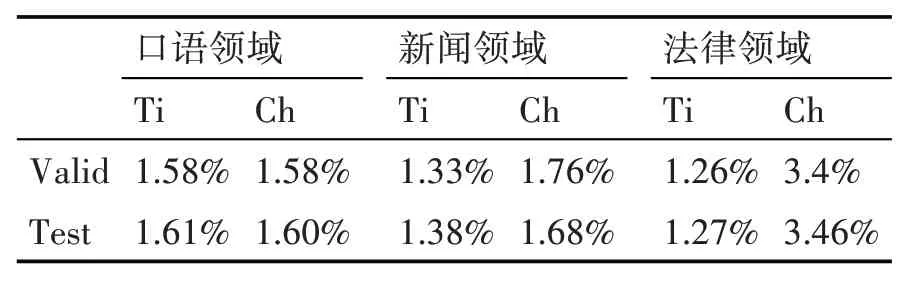
表2 数据集未登录词占比
对这些平行语料我们采取了相同的预处理和参数设置。
预处理步骤包括:1)将平行语料的数据文件切分成标准格式,即源语言(raw.ch)、目标语言(raw.ti)文件各一个;2)使用jieba 分词工具对汉语进行分词,并且使用中科院提供的藏语Dolma 分词软件对藏语进行分词;3)对上述处理后的双语文件进行bpe子词处理并且生成词表及二进制文件。
3.2 实验设置
本文实验设置如下,基准实验及CMLMs 模型均采用pytorch 框架。其中所有实验采用的优化器都是adam,设置为--adam-betas'(0.9,0.98)',初始学习率都是0.005,label-smoothing 0.1 以及dropout 0.3、weight-decay 0.01。
本文中的实验不同设置如表4。

表4 实验设置不同点
所有上述模型,本文在预处理阶段采用--joined-dictionary,在训练阶段采用share-allembeddings,即联合训练,共享词表,这样可以加快训练速度。
3.3 实验结果
本文的MP-CMLMs 模型,模型Ⅲ与NAT[10],模型Ⅰ和标准的Transformer 模型[9],模型Ⅱ做了对比,同时使用不同领域的藏汉数据集进行实验,以此观测模型在藏汉机器翻译上的可行性,评价指标为BLEU4。实验结果如表5所示。
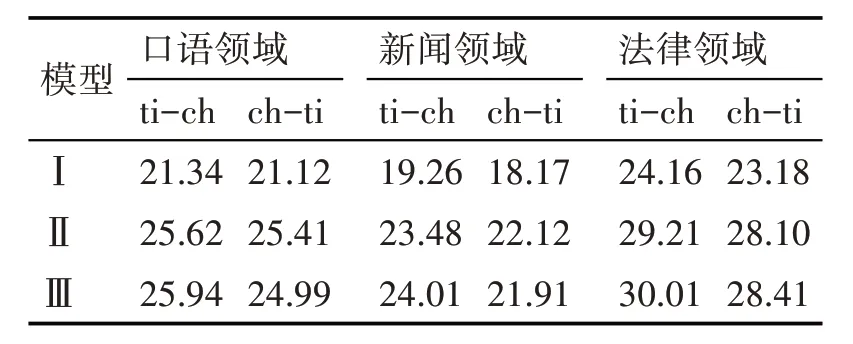
表5 实验结果

表6 解码所需时间对比
解码所需时间(s)对比,下表只统计了模型在藏文-汉文方向的解码时间。
3.4 实验分析
本文的实验证明了MP-CMLMs 在藏汉机器翻译领域有着不错的表现。
口语领域的语料相对较多,且句子长度较短,并且较为简单,因此口语领域的翻译效果较好。而新闻领域的语料长度比其他两个领域的数据长,句式结构较为复杂,因此新闻领域的翻译效果较差。而由于法律领域的语言简洁精炼,概括性好,因此本模型在法律领域的表现较好。
并且从解码时间的表中可以看出,本模型的解码时间与NAT模型解码时间相当,都比Transformer模型快很多。
图3是翻译效果展示。

图3 翻译效果展示
4 结语
本研究在藏汉机器翻译研究中引入了MP-CMLMs 模型,该算法利用它们的并行性在恒定次数的解码迭代中生成文本。实验证明,在藏汉机器翻译领域,本模型提升了非自回归藏汉机器翻译的效果,并且该方法实质上优于以前的并行解码方法,改进的该模型可以达到自回归模型的性能,甚至在法律领域优于Transformer模型的性能,同时解码速度比自回归模型快得多。
将在藏文分词阶段对模型进行改进,主要针对藏文中的紧缩词。并打算采用多任务学习,通过编码器共享将AT 知识转移到NAT 模型中。通俗地讲,打算将AT 模型作为增强NAT 模型性能的辅助任务继续引入藏汉机器翻译。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
客联(2022年4期)2022-07-06
黄河之声(2022年4期)2022-06-21
中国外汇(2019年19期)2019-11-26
通信学报(2019年5期)2019-06-11
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
通信技术(2018年3期)2018-03-21
西藏科技(2015年12期)2015-09-26
西藏科技(2015年10期)2015-09-26
