
基于非自回归模型中文语音合成系统研究与实现*
2023-06-04 06:24王志超刘益岑
计算机与数字工程 2023年2期
王志超 吴 浩,2 李 栋 刘益岑
(1.四川轻化工大学自动化与信息工程学院 自贡 643000)(2.人工智能四川省重点实验室 自贡 643000)(3.国网四川省电力公司电力科学研究院 成都 610000)
1 引言
语音合成(Speech Synthesis)是通过机械、电子方法产生和人类说话声音相似的语音技术。又名文本转换语音技术TTS(Text to Speech)[1]。它可以应用于各种生活场景之中,例如汽车导航、音乐合成以及为视力受损人士提供更便利的服务[2]。
在语音合成技术的发展历史中,语音合成技术随着时代与科技发展逐渐变得更加智能与可靠。传统语音合成方法步骤繁琐,要求专业知识背景强,对于没有声学和统计学基础的从业者具有很高的准入门槛。在传统语音合成系统中,主要分为前端和后端两大部分[3~4]。
前端针对输入的文本进行预处理,例如文本正则化(text normallization):将输入的文本中包含的数字、英文字母转化为中文文字等;文本转音素(text to phoneme):在语音合成系统中,我们输入的是中文文字,但是计算机并不会直接识别文字,所以需要提前将文字转换为音素的形式。
后端合成语音传统方法为参数合成或拼接式合成。参数合成方法指通过数学方法对语料库录音进行建模,提取已有录音频谱、时长信息等特征,构建文本序列映射到语音特征的映射关系[5]。在合成阶段通过时长(duration)模型和声学模型预测声学特征参数,最后利用声码器(vocoder)合成波形[6]。这类方法所需录音数据量小,合成语音平滑,但缺点是太过机械不够自然[7]。拼接式合成方法是通过在录音室或其他专业器械帮助下预先录制大量音频,针对对应的音节音素,从语料库中挑选出适当语音单元进行参数合成。拼接法需要大量录音来构建语料库才能合成效果较好的音频,拼接法的优点是音质较好并且拥有一定情感,但缺点是字与字之间缺乏平滑过渡,不自然。
随着近几年机器学习技术的进步,语音合成技术也从传统合成方法转变,出现了一大批基于深度学习的合成方法。深度学习因为它独有的可学习的特性,使合成出来的语音更加自然、平顺,更加符合人类的听觉习惯。文献[8]是由谷歌公司提出的Tacotron 端到端语音合成系统,其基于seq-to-seq自回归模型[9],采用Griffin-lim 作为声码器进行音频合成[10],这是第一个真正意义上的输入文本直接输出语音的端到端语音合成系统[11],简化了传统语音合成步骤,但其训练速度较慢,且因声码器在合成音频中会丢失大量相位信息,所以音频质量得不到较好保证。文献[12]是谷歌公司提出的第二代Tacotron,它的模型架构中舍去了CBHG(Convolution Bank Highway Network Bidirectional Gated Recurrent Unit)模块,使用了位置敏感注意力机制[13],并将声码器更改为WaveNet[14]。得益于WaveNet声码器,音频合成质量明显提升。但受制于自回归模型架构,训练速度依然缓慢。文献[15]将自然语言处理领域大放异彩的Transformer 结构运用在语音合成领域,使用多头注意力机制来代替速度较慢的RNN(Recurrent Neural Network)[16]网络和原始的注意力机制。编码器和解码器在隐藏层是平行结构,这样可以有效提升训练效率。但模型在获取音频特征时存在损失,合成音频效果较差。其他语音合成模型还包括Deep Voice1[17]、Deep voice2[18]等。
针对以上语音合成方法训练速度慢、音频质量不高等问题,本文提出了一种基于非自回归模型的中文语音合成方法。模型采用多头注意力机制和并行化编解码器提高合成效率,利用可变信息适配器添加音频特征使梅尔频谱拥有更丰富特征信息,提升了所合成语音质量。并将生成对抗网络应用在声码器中,成功合成了高质量音频。
2 模型架构
本文所提出的基于非自回归模型的语音合成系统,由三大部分:前端处理、声学模型和声码器组成。模型结构如图1所示。
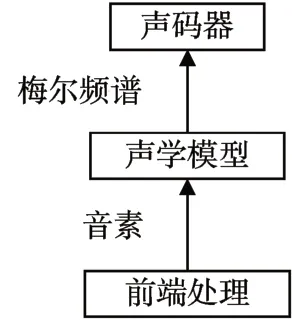
图1 模型结构图
前端处理负责将输入的中文汉字转换为最小声音单元:音素。再将音素输入到声学模型中,经过编解码器转换,音素序列由解码器输出为梅尔频谱。声码器由生成器和判别器组成,利用生成器生成音频波形,判别器将真实音频与合成音频进行判断,得以输出高质量的合成音频。
2.1 前端处理
在神经网络中,机器并不能直接识别输入的中文汉字,要利用模型合成中文音频,第一步是将汉字转换为音素。前端处理主要包括文本规范化、汉字转拼音、拼音转音素。在进行文本规范化时,主要针对多音字、符号、日期、时间等进行规范化处理。例如句号标记为长时间停顿,逗号标记为短时间停顿;2020 年10 月1 日转换为二零二零年十月一日;16:34 转换为十六点三十四分等。汉字转拼音则使用内嵌《汉语拼音方案》工具pypinyin 进行转换,同时可在转换时提供该汉字声调。音素采用国际音标(IPA)标记,将拼音转为音素更有利于合成语音质量的提升。由于汉语具有多音字的特殊性,多音字在转换时不容易得到正确读音,需构建多音字词库,在文字转拼音时与多音字词库进行匹配,输出正确读音。
2.2 声学模型
声学模型部分由编码器、可变信息适配器、梅尔频谱解码器组成用以生成梅尔频谱。结构如图2 所示。
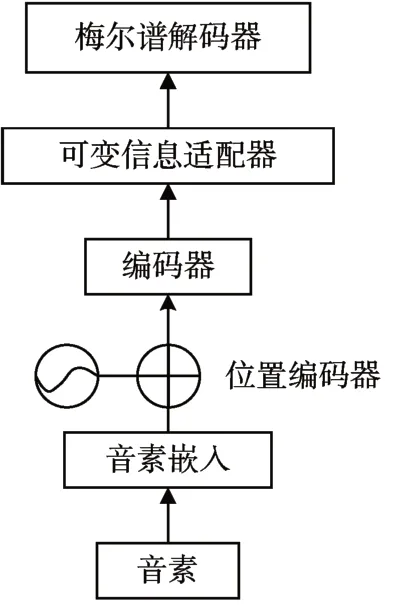
图2 声学模型结构图
将前端处理后的音素作为输入,通过独热编码(one-hot encoding)将音素符号编码为向量转换到音素嵌入层。独热编码器将总的音素个数表示为N,单个音素使用N-1 个0 和单个1 的向量来表示。本文中的非自回归模型的注意力机制并没有位置信息,为了注意词与词之间的位置关系,针对位置不敏感的模型需采用相对位置编码,使用正余弦函数表示绝对位置,相乘得到相对位置。
这里PE表示二维矩阵,pos为词语在句子中的位置,2i和2i+1 表示词向量位置,dmodel是每个一帧的词向量维数。
编码器与解码器均由包含自注意力机制和一维卷积网络4 个前馈网络组成,前馈网络中分别在多头注意力机制和一维卷积网络后添加了残差网络和层归一化。通过前馈网络将音素序列转换为隐藏序列,音素序列作为前馈网络的输入,利用自注意力机制中的多头注意力可以注意整个序列的上下文信息。多头注意力机制是注意力模型中的一种,注意力模型由Q(query) 、K(key) 、V(value)组成,本质上是对V进行加权求和,而Q和K是对V进行权重的计算。多头注意力中创建query、key、value三个向量,各自进行相应的线性变换输入到放缩点积注意力中,如下所示:
其中W为待训练的权值参数矩阵,有h个头即有h个维度,每个维度都为一个向量,即每次Q、K、V进行线性变换时参数矩阵W均随之变换,最后做h次放缩点积参数后进行线性变换作为多头注意力的结果。
可变信息适配器[19]由时长预测器、长度规范器、音高预测器和能量预测器组成,它从真实录音中提取音频的时长、音高和能量信息添加到由编码器输出的隐藏序列中用以预测目标语音。一个音素序列往往要短于梅尔频谱序列长度,为解决音素序列长度和梅尔频谱序列长度不匹配的关系,假设音素时长为d,长度规范器会扩大音素序列的隐藏层d倍,总的隐藏层长度将会与梅尔频谱长度相等,长度规范器可表示为
Hpho表示音素隐藏层序列,D表示音素时长序列,α是确定Hmel梅尔频谱序列拓展长度的超参数。隐藏序列经过时长预测器将会输出对数域中音素的长度,经过音高预测器输出帧级的基频序列,而能量预测期则会输出梅尔频谱帧的能量序列。
最后解码器将添加了可变信息适配器语音信息的隐藏序列作为输入,经过与编码器相同的前馈网络,通过输出线性层将256维隐藏序列转换为80维梅尔频谱序列。
2.3 声码器
将梅尔频谱转换为音频形式所需声码器主要类型为纯信号处理、自回归神经网络模型和非自回归神经网络模型。纯信号处理的声码器代表有Griffin-lim、world 等,在梅尔频谱到音频的映射时会引入明显的伪像,造成音频听感含有金属感。自回归神经网络模型的声码器代表有WaveNet、WaveRNN[20]等,合成音频效果较好,但由于自回归下一步的输入必须依赖上一步的输出,所以合成音频效率较低。非自回归网络模型声码器代表为WaveGlow[21]和Parallel WaveNet[22],这一类型声码器训练过程太过复杂,训练速度虽快于自回归模型但效果略差。
本文采用基于生成对抗网络(GAN)[23~25]的非自回归模型声码器,由生成器和判别器两大部分组成。声码器结构如图3所示。

图3 声码器结构图
生成器是非自回归前馈卷积网络,将解码器输出的梅尔频谱序列作为输入,通过反卷积网络对频谱序列进行上采样,卷积核的大小是步长的两倍。在每个上采样层后连接残差模块和空洞卷积以扩大感受域。为了能更好还原音频特征,通过分析滤波器得到子频带的目标波形,采用多分辨率的短时傅里叶对子频段进行计算:
对于单个短时傅里叶变换目标函数,本文将最频谱收敛Lsc最小化:
这里‖ ·‖F属于F-范数,x表示原始音频,为生成器生成的预测音频波形。
所有子频带信号相加合成为全频带信号作为判别器输入,全频带信号经过平均池化为三个不同尺度的音频信号,分别经过三个不同尺度的判别器:D1、D2 、D3。D1 以原始尺度音频波形执行,D2 和D3 分别以2、4 倍数的下采样执行。判别模块结构如图4所示。
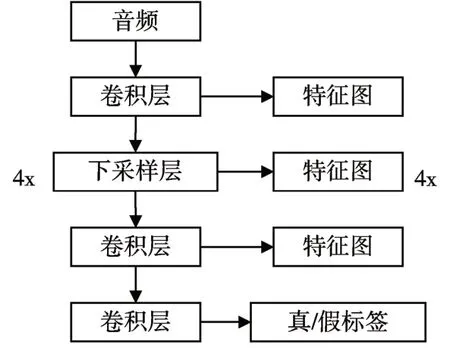
图4 判别模块结构图
判别模块通过计算不同尺度上生成音频和真实音频之间的特征图损失与均方损失函数,通过对抗学习使判别器无法判断生成器生成音频的真假。
另外,政府及行业协会还应该积极举办低碳环保宣传活动,增强国民低碳意识,使企业、游客、社区居民能够在旅游的各个环节自觉践行节能减排的行动,真正实现旅游的绿色低碳可持续发展目标。
3 实验分析
3.1 实验配置
本文采用由年龄20 岁~30 岁专业播音女性在专业录音棚环境录制(录制环境及设备保持不变,录音环境信噪比不低于35dB),音频容量为10000句,每句长度约为16 个字的WAV 格式语音合成数据集,总时长约为12h,采样率为48kHz,16bit。其中数据标注已完成韵律标注、音字校对以及中文声韵母边界切分。其中8000 句作为训练集,1000 句作为验证集,1000句作为测试集。
实验基于Linux 16.04 操作系统,GPU 采用NVIDIA GeForce GTX 1070Ti,CPU Intel i7-7700,训练框架为TensorFlow 2.0。
声学模型由4 个前馈模块组成编码器和解码器,解码器和编码器中隐藏层数和大小分别为4 和384。多头注意力机制中,头数设置为2,卷积核大小为3。可变信息适配器两层卷积核大小分别为9和3,丢弃率为0.5。批大小设置为16,Adam优化器β1=0.9 ,β2=0.98 ,ξ=1e-6 ,初始学习率为0.001。训练迭代次数在160K时模型收敛。
声码器中生成器模型初始卷积层和结束卷积层卷积核大小为7,残差层中的空洞卷积核大小为3,残差层数设置为4,输出通道为4 个子频段音频。判别器在3 种尺度来判断真实音频与生成音频特征,池化层大小为4,非线性激活函数使用Leaky ReLU,α=0.2。批大小大64,Adam优化器[26]学习率使用分段恒定衰减。训练迭代次数在1740K时模型收敛。
3.2 实验结果
本文通过TensorFlow 可视化工具,将训练后的训练集和验证集loss 进行可视化分析。通过训练集和验证集收敛情况,可以判断模型训练效果是否良好。结果如图5所示。
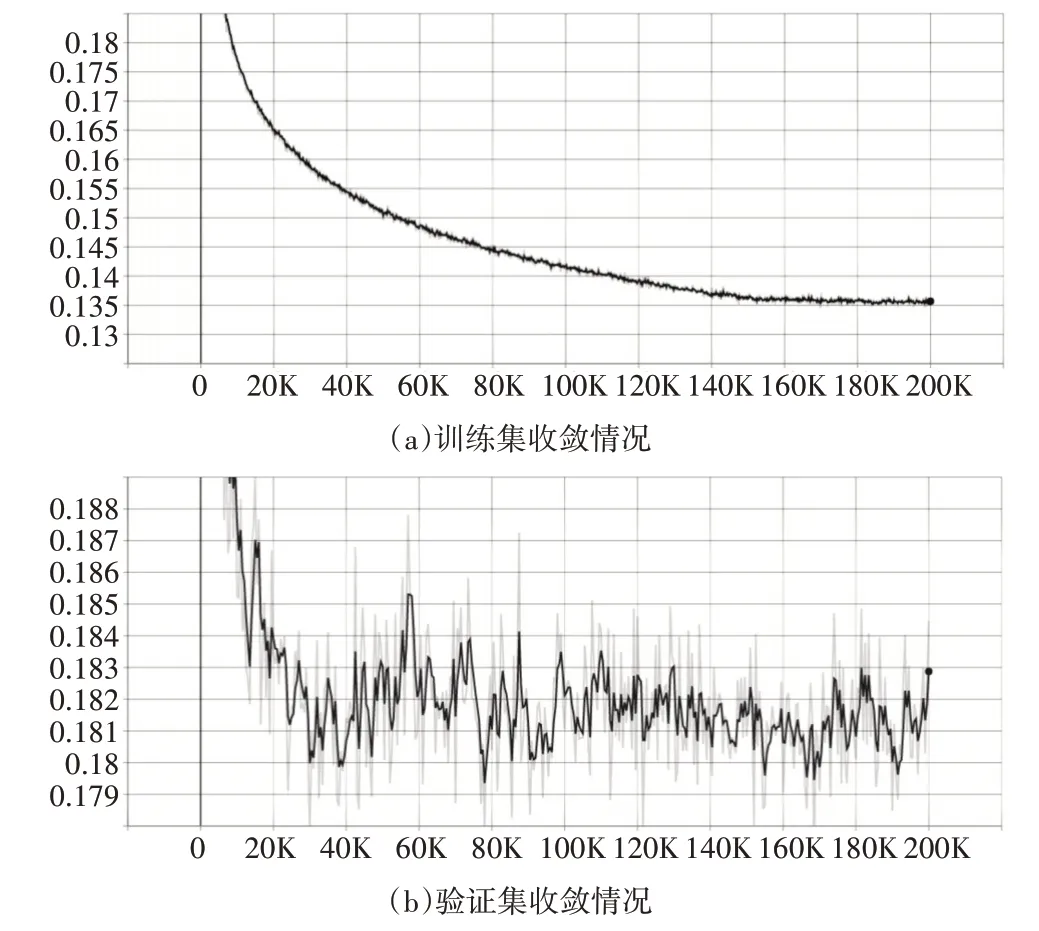
图5 可视化loss曲线
其中图5(a)为训练集收敛情况,图5(b)为验证集收敛情况。由图5 可知,训练集loss 迭代次数在160K时基本收敛,loss系数为0.135。验证集loss迭代次数在80K 时收敛,loss系数为0.182。训练集与验证集均能收敛,说明模型训练效果良好。
本文利用原始录制语音文本,分别合成20 段音频,并随机选取其中三段与原始音频进行对比。利用Sonic Visualiser 音频分析软件生成各段语音频谱图进行对比。对比结果如图6所示。

图6 频谱对比分析图
图6 (a)、(b)、(c)为三段频谱对比图,左方为合成语音,右方为原始音频。每段语音文字分别为“宝马配挂跛骡鞍,貂蝉怨枕董翁榻”、“老虎幼崽与宠物犬玩耍”、“南越昆仑山与西藏接壤”。由图6可知,合成语音较原始音频字与字发音更为清晰,各音素间间隔较为分明。但是在字与字间过渡较为生硬,连续性较差。分析共振峰可知,合成语音频率较高,相较于原始音频拥有更高的音高。
3.3 实验评估
MOS 评分邀请30 名无明显听力缺陷大学生对合成语音进行打分:5分优秀;4分良好;3分中等;2分较差;1分差,最小分值间隔为0.5,最后综合所有得分选取平均分作为最终得分。
本文将真实音频、Tacatron2和传统参数式模型与本模型所合成语音进行对比,由表1 可知,得分最高为真实音频,说明评分符合实际情况真实有效。Tacotron2 声码器选用WaveNet。本文所提出的基于非自回归模型所合成语音得分明显高于传统参数式模型,略低于Tacotron2 模型和真实语音,说明合成质量较为优异。
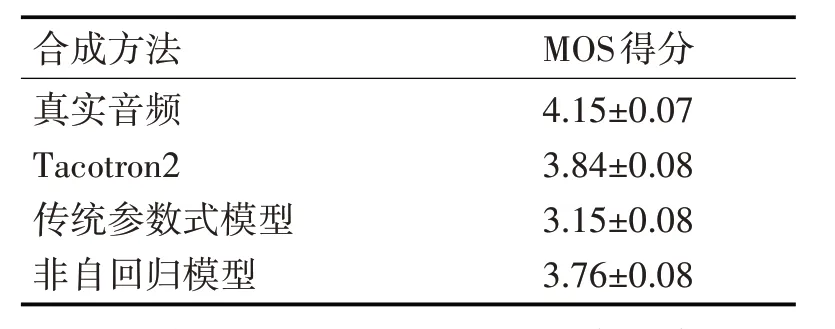
表1 平均主观意见得分
客观评价法是将合成音频的梅尔频率倒谱系数(MFCC)与原始音频梅尔频率倒谱系数差距进行计算,原始音频MFCC 特征设为x,合成音频特征为,计算公式为
由表2可知,基于非自回归模型的MCD值在三种方法中MCD值最低,表明合成音频MFCC特征与原始音频MFCC特征差距最小,语音合成质量最高。

表2 客观评价法MCD值
语音合成中模型训练速度同样是一项重要指标,本文分别统计了自回归模型Tacotron2 与非自回归训练所需时长。
由表3 可知,Tacotron2 是基于自回归模型,需要编码器和解码器序列对齐,解码器依赖于上一步的输出,所以训练速度较慢,本文所提出的非自回归模型编解码器是并行化结构,解码器不依赖上一步输出,训练速度较快。
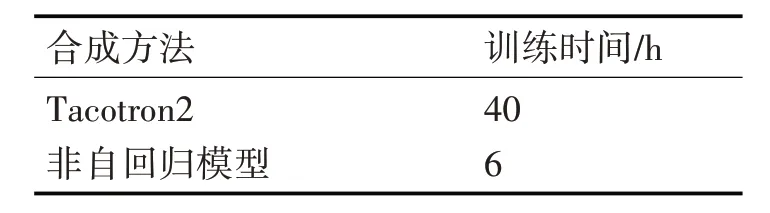
表3 神经网络模型训练时间
4 结语
本文提出一种基于非自回归模型的语音合成方法,输入音素序列经过编码器和多头注意力机制转换为隐藏序列,再加上可变信息适配器预测的相关音频特征,解码器接受到添加音频特征的隐藏序列后将其转换为梅尔频谱。梅尔频谱作为声码器的输入,经过生成器和判别器语音波形合成生成相应原始音频。经过研究得到以下结论:
1)本文基于非自回归模型的语音合成方法,训练速度快于基于自回归模型语音合成方法。
2)使用基于非自回归网络的声学模型,合成语音质量与自回归模型相近,显著高于传统参数式方法。
3)采用基于生成对抗网络的声码器用于音频波形生成,证明GAN 网络也能在语音合成中得到良好效果。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
电子测试(2021年22期)2021-12-17
北京教育·普教版(2020年9期)2020-10-09
校园英语·中旬(2019年11期)2019-11-26
传感器世界(2019年5期)2019-08-07
广西教育·D版(2019年6期)2019-07-11
红领巾·探索(2019年2期)2019-04-19
语言与文化论坛(2019年3期)2019-04-13
畅谈(2018年17期)2018-10-28
疯狂英语·新策略(2018年7期)2018-08-29
