
基于点积自注意力机制和残差网络的DAGAN图像补全算法
2023-05-30 15:24宁浩宇张逸彬张莉娜李申章耿贞伟
计算机应用文摘 2023年5期
宁浩宇 张逸彬 张莉娜 李申章 耿贞伟
关键词:DAGAN;自注意力机制;残差网络
1引言
最初的图像补全主要是基于数学和物理学的一种传统图像学技术。然而,近来年,在深度学习(DeepLearning,简称DL)逐渐占领视觉领域研究前沿的趋势下,以深度学习为代表的机器学习正带领研究者突破传统模型发展的瓶颈。利用DL处理图像补全的典型算法,按照网络结构类型可以分为2类,即基于CNN(Convolutional Neural Networks,卷积神经网络)的语境自编码算法和基于GAN(Generative AdversarialNetwork,生成对抗网络)的图像补全算法。因此,本文在这两种图像补全的典型算法基础上,结合其目前衍生的产物,设计了基于自注意力机制和残差网络的DAGAN(self-attention and residual GenerativeAdversarial Network)图像补全算法,旨在对已有的部分算法进行整合并适当创新。
2相关工作
随着人工智能时代的来临,图像补全技术算法不断地更新换代,其在各大研究领域都起到了较大的辅助性作用。
在医学影像领域,由于磁共振图像的特殊成像方式,致使成像过程中产生伪影和噪声,进而影响对病情的判断。刘哲等[1]为了消除这些伪影和噪声,使修复后的磁共振图像细节更加丰富,提高其医学应用价值,提出了一种基于深度残差网络编码一反卷积网络解码框架的算法。针对手指静脉由于位置特性导致成像中存在局部血管残缺的问题,贾桂敏等[2]首次提出一种指静脉红外图像血管网络修复方法,实验结果表明,该方法可以实现手指静脉图像局部血管网络残缺修复,得到更加完整、稳定的血管网络结构,利用修复后的图像可以进一步提高手指静脉识别精度。
3图像补全算法模型
近年来,随着人工智能时代的到来,各大领域都在使用深度学习技术解决实际问题,如图像分割[3]、分类[4]、对象识别[5]等.而本文着重介绍基于深度学习的图像补全技术。
针对文本上的应用,林阳等融合自注意力机制的跨模态食谱检索方法,这是一种利用食物图片对食谱进行在线检索的技术,在食谱文字编码模块中利用attention算法识别文本语义向量间的空间维度距离,解决了在食谱中同一原材料文本处理步骤相隔较远的问题。王佛林等提出了基于自注意力机制的语义加强模型,由于每一个方面词都有固定的情感修饰词,因此该模型用自注意力机制获取情感词语义、句子分割点语义等多个维度的语义向量,提高了分类准确率。
3.1自注意力机制算法
3.1.1缩放点积注意力机制算法
缩放点积自注意力算法其实就是使用点积函数进行特征向量相似度的计算,其中缩放就是在进行相似度计算的基础上缩小了为向量的维度),通过调节样本维度使相似值不会太大,从而解决梯度消失的问题。缩放点积注意力机制的计算式为:
3.1.2多头注意力机制
多头注意力机制其实就是在缩放点积自注意力机制的基础上加入了特征映射。算法思想为Query,Key,Value三个输入维度的向量矩阵经过线性变换,然后对矩阵进行点积函数的计算,重复以上操作,并对计算矩阵进行特征拼接。在进行矩阵计算时,Query,Key,Value三个向量矩阵线性变换的权重是不同的。
3.1.3缩放点积多头注意力机制
通过缩放点积注意力机制得到的结果将作为本文self-attention的值。具体实现过程为,将通过SEnet得到的卷积层作为self-attention的原始输入。定义Q的特征通道,其中参数并不相同,将Q的输出矩阵进行转置,并和K的输出矩阵进行计算,经过softmax得到attention权重矩阵,将这一矩阵和V(x)相乘得到基于自注意力机制的特征图。这样就可以很好地解决DCGAN本身处理图像产生的边缘模糊的问题。本文自注意力机制形式化计算式为:
3.2GAN图像补全模型
GAN(Generative
Adversarial
Network)有2个网络,即生成器(generator)和判别器(discriminator),在图像补全中就是通过这两个网络来互相对抗以达到最好的生成效果。本文通过以下操作来扩展查询图。本文所提出的基于自注意力机制和残差网络的DAGAN图像补全算法,对经过SEResNet和self-attention处理的模型作为GAN生成器,而没有经过SEResNet处理的模型作为GAN判别器,使用交替训练的方式来最小化损失函数。
在以往传统的GANs中,它们擅长合成那些纹理特征区别明显却几乎没有结构约束的图像类,如海洋、天空和景观类,但对于那些受结构约束较强的图像,就会无法捕捉某些类别中一贯出现的几何或结构模式,如有四肢躯干的哺乳动物通常生成的图像是具有现实的皮毛纹理,但没有明确的独立的脚。因此,在本文的GAN中self-attention模塊通过帮助生成器和判别器建模跨图像区域的长期、多层次的依赖关系,而更好地体现整个图像的结构约束特征。
4实验
4.1实验结果及分析
本文使用MNIST手写体识别数据集和celebs数据集作为实验数据,并用两个数据集进行对比实验。
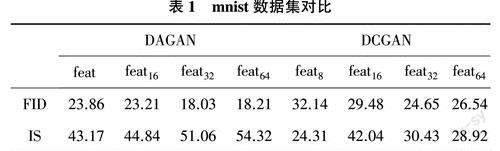
为了探讨所提出的DAGAN算法在MNIST数据集的训练效果,本文将从生成器和判别器的不同阶段利用FID和IS两种评估指标,对DAGAN算法和DCGAN算法进行对比分析。具体对比情况如表1所列。
如表1所列,在中到高级特征图(如feat32和feat64)中DAGAN算法具有更好的性能。在DAGAN中feat8~feat32,FID指标从23.86改进到18.21,其原因是在生成器中通过self-attention获得了更多、更具代表性的缺失图像块特征,并享有更多的自由来选择更大feature map的条件,即对于大的feature map,它是卷积的补充,但是对于小的feature map,如8*8,它在建模依赖关系时,起到了与局部卷积类似的作用。
图1为DAGAN与DCGAN准确率对比图,在训练了35个Epoches后,尽管DAGAN的准确率在75%左右,但在此之前DCGAN的准确率依然低于DAGAN。图2为DAGAN与DCGAN修复视觉效果对比。
5结束语
实验结果表明,在DCGAN基础上增加了自注意机制和SEResNet模块,为生成器和判别器提供了更强大的能力,可以对特征图中的长期依赖关系进行建模,并更好地采集到图像缺失边缘的样本,以此生成内容语义合理、图像纹理足够清晰真实的修复图像。
