
基于多模块深度神经网络的陶瓷图像视觉问答方法
2023-05-24 08:15张岱松盛文婷
南京理工大学学报 2023年2期
张岱松,盛文婷,谷 峥,刘 静
(1.唐山学院 文法系 河北 唐山 063000;2.新疆农业大学 网络技术与信息中心,新疆 乌鲁木齐 830091;3.新疆工程学院 控制工程学院 新疆 乌鲁木齐 310001;4.喀什大学 计算机科学与技术学院 新疆 喀什 844000)
视觉问答[1](Visual question &answer,VQA)是关于图像问题的回答,也可称为视觉图灵测试[2],即给出一幅图像或一个组合问题,需要模型同时根据问题的语义和图像的内容作推理并给出正确答案[3]。这类问题要求对视觉场景和自然语言这两方面的较深刻理解,在新兴的人工智能领域尤为重要,是值得关注和研究的领域。VQA可结合图像捕捉、视觉问题生成和视觉对话技术,创建能够在现实中执行各种任务并通过语言与人类沟通的智能体,并应用到图像智能分析[4]、视力残障人士辅助、无标签图像检索[5]等各种领域。
目前,已有一些研究成果,如文献[6]在多模态视觉问答数据集上分析了多个VQA模型的性能,这些模型都通过基于注意力机制的神经网络,学习到接近于人类认知的神经注意力策略。比较结果表明,VQA模型性能不但与图像模态相关,且会受到文本注意力的显著影响。VQA问题中的一个重要组成部分在于从图像中寻找问题的根据,文献[7]已经就这类问题进行了论证,并通过评估视觉问题与图像证据之间的关系,提出不但要学习数据中的巧合关系,还需要捕捉图像内容与文本概念之间的深度关联。文献[8]提出了结合自下而上的注意力机制的VQA模型,首先利用预训练目标检测网络提取图像目标和显著区域,其后将其与相关问题表征输入到一个记忆网络以生成最终信息表征,最后融合信息表征和问题表征,推导出正确答案。文献[9]提出了结合卷积神经网络(Convolutional neural network,CNN)和长短期记忆单元(Long short-term memory,LSTM)的VQA模型,利用张量分解和回归策略显著加快了VQA任务的处理速度,但会造成准确度的下降。为充分利用深度模型的视觉内容表征能力与自然语言处理的语义分析能力,文献[10]提出基于图像捕捉的VQA模型,将图像捕捉模型提取的特征与注意力视觉特征相融合,由此图像捕捉任务中学习知识并迁移到VQA任务中,改善生成答案的准确度。
VQA问题的重点是探索传统语义分析中集合论方法[11]与计算机视图属性之间的天然相似性。为此,本文提出了一种基于多模块结构的神经网络进行VQA视觉问答,这个方法能够使用联合训练回答出陶瓷相关图像的自然语言问题。本文方法的主要创新之处是将不同种类的、联合训练的神经模块组成深度神经网络,不同种类的信息能够从某一模块传递到下一个模块,并对陶瓷产品的视觉回答问题进行了试验。试验结果表明所提方法可以较好地处理视觉问答问题。
1 VQA属性-成分模块空间
为了与可组合的视觉元素最小集保持一致,本文组合成了任务所需的所有配置。这些配置模块在三种基本数据类型中进行操作:图像、非规范性属性及标签。模块的名字是固定宽度字体的类型集,是TYPE格式的[INSTANCE](ARG1,…),TYPE是一种高级模块类型(属性,分类等)。INSTANCE为模型中的特殊案例。
(1)寻找模块。find[c]用权值矢量卷积[12](每个c都对应于不同的权重),输入图像中的所有位置,来生成热图或非标准化的属性。find[red]会定位红色的物体,如图1(a)所示。模块find[red]的输出为一个数字矩阵。

图1 模块示意图
(2)转化模块。transform[c]是一种有着修正线性单元[13](ReLU)的多层感知器,能够完全连接属性之间的映射,如图1(b)所示。同样,每个矢量c的影射权值均不同。因此,transform[about]表示属性转换向上的最大激活区域,而transform[no]则是将属性从活跃区域移走。在本文的试验中,第一个全连接层(Fully connected layer,FC layer)会生成大小为32的矢量,第二个全连接层与输入的大小一致。
(3)联合模块。combine[c]将两种属性融合成一个属性。例如,combine[and]表示只在两种输入都活跃的区域,而combine[or]表示在第一个输入活跃第二个输入不活跃的区域,如图1(c)所示。一般,联合模块可以将其看作是非线性后的卷积。
(4)描述模块。describe[c]取属性和输入图像共同作为输入,并将两者映射为标签空间上的分布。具体而言,首先计算由属性值权重得到的图像特征均值,然后将图像特征矢量传递到全连接层(FC)中。如图1(d)所示,describe[color]会返回该区域指向的颜色。
(5)测量模块。measure[c]能够独立获得属性值,并将其映射到标签分布中。由于模块之间的属性是非规范化的,所有测量可用于评估待检测物体是否存在,或用于计算物体集的数量,如图1(e)所示。
2 VQA模型
本文VQA的基本流程图如图2所示,图的流向分为两条,一条为自然语言,一条是图像,以上述模块化属性-成分网络为基础,使用自然语言分析器,来动态地表示由可重复使用的模块组成的深度网络。并添加了用户响应机制。为了简化,本文将数据看作是一个三元组(w,x,y)。其中,w是自然语言问题;x是图像;y是回答。模型由一组模块{m}完全指定,每一个模块都有关联参数θm,以及从线映射到网络的网络布局预测P。给定如上所示的(w,x),模型基于P(w)实例化网络,将x(或w)作为输入值,就能获得标记的分布(为完成VQA任务,本文需要输出模块来生成答案表示)。这样,模型就将预测分布编码为p(y|w,x;θ)。而用户响应机制进一步优化了VQA,使得问题回答更加准确鲁棒。
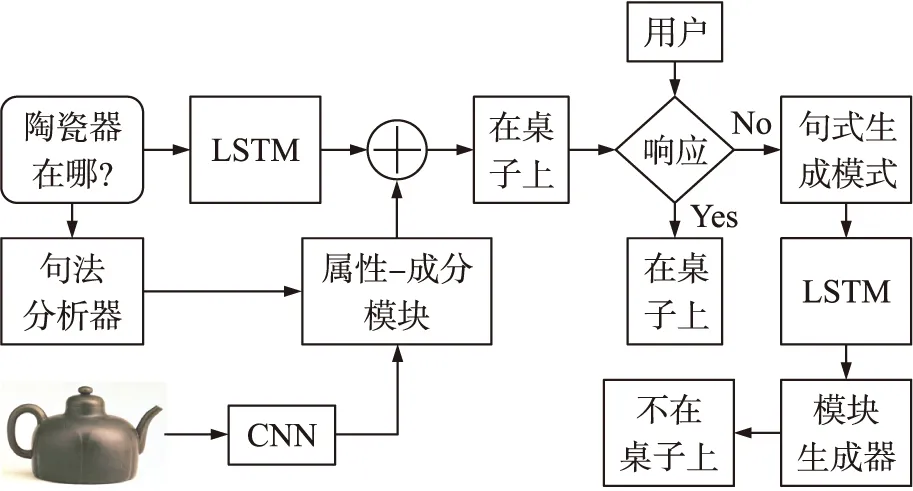
图2 本文VQA的基本流程图
2.1 从字符串到网络
本文首先使用斯坦福句法分析器[14]分析每个问题,以获得通用的句法表。句法分析能够表示出句子各部分之间的语法关系(如物体和属性之间的关系,事件与参与者之间的关系),并可提供与句子表面结构不同的抽象概念。句法分析器还进行了基本的词干提取,这可以减少模块的分析。然后,将句法集过滤到连接问题的连接函数(具体取决于任务,以及特殊案例的数量)。从而得到一个能够表达句子基本意思的符号形式。在这个过程中,还要将一些功能词,如限定词和情态动词抛开。这些表示与组合逻辑有些相似,其中,每个叶子节点都是输入函数,根节点表示计算的最终值。为了对语句歧义进行消除,本文提出一种利用不同含义问题语句的方法,生成的语句根据图像内容和用户反馈机制进行评价。通过置信度给出最终输出。本文对问题创建的句子模式有5个,其模式判定如下
B1={Qi|are∈Qi∧Qi⊆Q}
(1)
B2={Qi|or∈Qi∧Qi⊆Q}
(2)
B3={Qi|and∈Qi∧Qi⊆Q}
(3)
B4={Qi|as∈Qi∧Qi⊆Q}
(4)
B5={Qi|have∈Qi∧Qi⊆Q}
(5)
式中:Q表示总问题模式,第i个模式用Bi表示。上述模式的语句分支判断规则为
f(B1,B2,B3,B4,B5,Q)=
(6)
式中:整数r、m、n满足至少两个数不为0。这些整数的组合使得f(B1,B2,B3,B4,B5,Q)大于0。引起语句分支歧义的组合如下
分支1:{B5∪B4},…have…as…形式;
分支2:,…are…or…形式;
分支3:{B1∪B2∪B1},…are…or…are…形式;
分支4:{B1∪B3},…are…and…形式;
分支5:{B1∪B1∪B2},…are…are…or…形式;
分支6:{B1∪B4},…are…as…形式。
上述有代表性的句法表示确定了预测网络的结构,但是没有确认组成的模块。模块的最终任务完全由结构确定,所有叶子节点变成寻找模块,所有的内部节点都根据其数量变成转换模块或联合模块,根节点根据其领域变成描述模块或测量模块。大多数情况下,这些网络结构是不同的,但是参数都相互关联,网络结构数据如表1所示,其中“#案例”表示特定模块案例数量,“#分布”为不同组合结构数量,“#最大深度”为所有分布的最大深度,“最大尺寸”为网络模块最大数量。
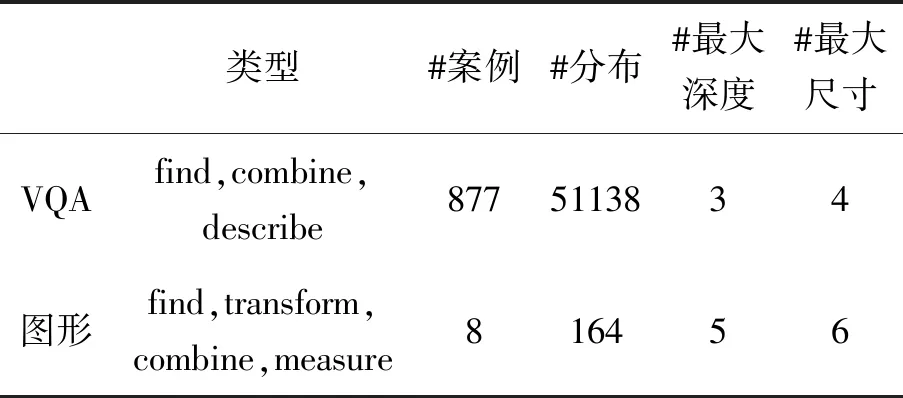
表1 本文神经模块网络的结构数据
2.2 自然语言的回答问题
本文将神经模块网络的输出和LSTM编码器结合起来,这样做源于以下两个原因。
(1)由于分析器中发生的问题都进行了相对激进的简化,所有语法提示(即:不会对问题的语义产生太大的影响但是可能会影响答案)都被省去。
(2)因为这样可以得出语义规律,这问题编码器也使得本文能够对这类问题的影响进行建模。因此,所有试验都使用了标准单层LSTM[15],其包含了1 000个隐藏单元。为了计算答案,通过完全连接层去掉了LSTM的最后隐藏部分,将其加入神经网络模块根节点生成的表示中。应用ReLU非线性,另一个全连接层和softmax层来获取答案的分布。与神经网络方法类似,本文将答案预测看作是一个纯粹的分类问题[16],即:模型选出训练过程观测到的答案集,并将每个答案看作是不同的类。这样,在最终预测层中就不会有相同的参数了,如“左边”和“左”。
2.3 损失函数
为了度量分布的差异,本文使用相对熵函数(又称KL散度,Kullback-Leibler divergence)作为损失函数,训练过程中的分类器逐步拟合真实答案,损失函数的定义如下
(7)
式中:xi为模型输出第i个类别的预测概率,yi第i个类别的真实概率。S为训练集中的问题-答案对的数量。
3 试验与分析
本文的训练目的就是找到能够最大化数据可能性的find模块。本文将每个网络的最后一个模块设计成标签分布的输出,这样,每个组合好的网络也能表示可能性分布。由于动态网络结构用于回答问题,一些权值可能比其他权值更新快。因此,有着自适应权值学习率的学习算法远远优于简单的梯度下降。为此,本文在所有试验中使用了Adafactor算法[17],并沿用了标准参数设置。
3.1 陶瓷制品的组合性VQA
由于本文的目标是研究深度语义组合性的模型,因此创建了一个陶瓷图像的合成数据集。这数据集在制备中考虑了很多语义组合方式,还包含了与色彩和形状的排列相关的复杂问题(如图3)。本文方法在VQA任务中的案例输出如图3所示。问题包含了2~4种属性,目标类型和关系。本文合成数据集包含244个问题,每个问题有64张不同的图像,一共有15 616张图像。其中14 562张在训练集中,1 024张在测试集中。为了减少猜测,所有问题都包含“是或不是”的答案,但为进一步提高性能,问答系统需要学习对形状、颜色、目标类型的识别,并理解目标之间的空间和逻辑关系。
笔者聆听了加拿大西蒙菲莎大学(Simon Fraser University)环境学院副院长、考古学系教授、古代DNA实验室主任杨东亚教授作的题为“古基因组学和考古学的整合”的学术讲座。杨东亚教授说:

图3 本文方法在VQA任务中的案例输出
为了生成图像特征的初始集合,本文使用LeNet[18]的卷积部分作为输入图像,LeNet与视觉问答部分共同训练,得出了嵌入LeNet中的预训练图像。并将本文方法与LSTM方法[9]作比较。
陶瓷图像的合成数据集中得出的结果如表2所示。由表2可知,本文方法表现最佳,优于LSTM方法和猜测方法。这表明本文的联合训练过程能够正确地分配不同模块的任务,进一步说明了本文的方法能够对复杂组合性现象进行建模。表2中最后一行数据是本文在修改过的训练集中进行了附加试验,该训练集不包含大小为6的问题(即与问题相对应的神经网络有6个模块)。这种情况下的性能与全部训练集的性能基本相同。这表明,本文的模型能够泛化到比训练所碰到的更加复杂的问题。有了语言信息,模型就能依据简单视觉模式,推算到更深的结构中。
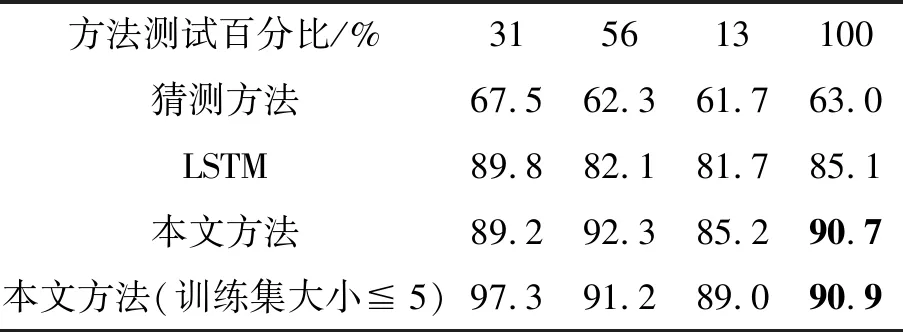
表2 从合成数据集中得出的预测精度
3.2 其他自然图像的VQA
本节在VQA数据集[6]中评估所提方法处理自然图像认知问题的能力。VQA数据集包含来源于MSCOCO的200 000多幅图像,每幅图像有3个问题,每个问题有10个答案,这些答案是由人工注释器生成。本文使用标准训练/测试分割来训练模型(只训练置信度高的答案)。本文深度神经网络的视觉输入是conv5层,在进行最大池化后是一个16层的VGGNet[19],其特征被规范化为0,标准误差为1。比较的方法有:1)LSTM方法:能够直接从图像和问题的编码中预测答案;2)添加了添加了属性的LSTM方法(属性+LSTM);以及常用的猜测方法。
第一组试验是基本计算结构与本文模型不同,从VQA数据集测试得出的结果如表3所示,在测试-验证中,回答“是/否”问题和回答数量问题时,本文方法占有较明显的优势。对于其他问题和所有问题组合在一起的情况下,所有方法都表现比较差,这是因为目前VQA问题解决的难点。

表3 第1组:VQA数据集测试得出的预测精度
第二组试验是基本计算结构与本文方法相同,但是其没有句法组合,即,每个问题使用的网络布局都是相同的(先用describe模块,再用find模块),所有问题中的参数都是相关的,如表1所示,且模块类型和案例的数量都很大。其测试结果如表4所示,其基本情况与表3的结果类似,这说明句法组合似乎对本文方法没有太大影响。
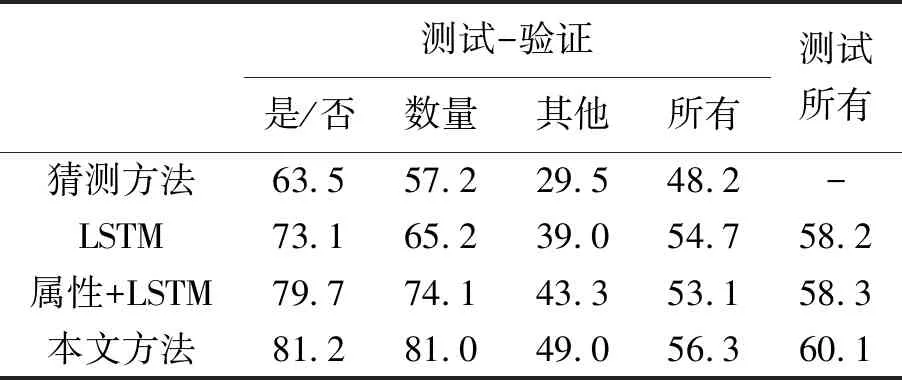
表4 第2组:VQA数据集测试得出的预测精度
由表3可知,本文方法优于其他方法,结果表明,本文方法在回答物体属性或数量上表现最佳。另外,采用人工方式对训练集中的前50个分析进行检查表明:大多数(80%~90%)询问物体的简单属性的问题都能得到正确的分析和回答,但是更复杂的问题有时候选出不相关的谓语,从而导致一些问题回答失败。举例来说,“人们在哪里踢球”,理想的问题解析应该是(人,哪里),但句法分析器会将问题解析为(人,踢球)。未来,可通过联合学习来解决此类解析器错误。
4 结束语
本文提出了一种多模块的神经网络,以解决陶瓷制品相关的VQA问题。其中,神经模块能够动态地组合成深度神经网络,并用这些模块结构动态地将模块网络实例化。同时引入的用户反馈机制,使得模型准确性更高。另外,还构建了一个组合问题的陶瓷图像合成数据集,这些组合问题与简单的形状排列相关。试验结果表明所提方法在视觉问答中的性能优于当前一些方法,尤其是在回答物体属性或数量的问题中。
本文的多模块神经网络可以通过训练来生成可预测的输出(包括自由组合的输出),即:从神经网络中生成更加通用的范例程序。因此,未来本文会扩展到与文件或结构性知识库有关的查询研究中。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
作文小学中年级(2020年6期)2020-07-24
电子制作(2019年19期)2019-11-23
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
自然资源遥感(2014年3期)2014-02-27
汽车与新动力(2012年1期)2012-03-25
