
YOLOv4算法在安全帽目标检测技术中的应用
2023-05-24 20:53:03程潇刘雪梅郭幸语韩昌
无线互联科技 2023年5期
程潇 刘雪梅 郭幸语 韩昌

摘要:目标检测技术广泛应用于各个领域,其目的是通过对输入图像中的物体和场景进行信息的特征提取,从而识别图中感兴趣的目标。为了减少作业人员在建筑工地作业时因未佩戴安全帽造成的人员伤亡事故,文章提出了一种基于深度学习的建筑工地安全帽目标智能检测方法,检测建筑工地人员安全帽佩戴情况,提高行业安全生产效率。本研究通过安全帽数据集进行先验框设计,采用k-means算法获得本数据集的先验框维度;将用于训练的图片进行拼接实现了数据集的增强;用CIOU代替回归损失增加预测精度,基于YOLOv4的基础网络进行特征提取,获得不同尺度的特征层,将获得的特征层经过深层次特征金字塔进行特征融合,再输入分类回归层进行回归预测。
关键词:安全帽检测;数据增强;特征金字塔
中图分类号:TP399文献标志码:A
1 研究背景及意义
在建筑生产环境中,由于工作人员在进行生产操作过程中没有按照安全规定佩戴安全帽或者没有正确佩戴安全帽而造成的安全事故越发多见,为了响应国家对施工安全规范的提倡,越来越多的企业注重员工的安全行为规范,因此,需要一种技术来监测作业工人在建筑生产环境中安全帽的佩戴情况,从而督促工人们佩戴好安全帽,减少安全事故的发生。
随着卷积神经网络的提出和发展,可以用一些数学函数来描述计算机难以理解的问题,使得目标检测有了新的研究方向。通过设计神经网络模型进行训练后,自动提出特征的方法使目标检测的研究方向转到了深度学习。基于深度学习的目标检测算法发展得很迅速,从Faster RCNN[1]锚框的提出到SDD、YOLOv系列的提出,在不断地提高目标检测的精度和计算速度。
关于如何保障作业人员在建筑生产环境中的安全问题,目前已经有一些有关安全帽佩戴检测的相关研究。在计算机视觉研究方面,冯国臣等[2]提出了应用机器视觉的相关方法来实现安全帽的自动识别任务,通过在图像预处理的基础上利用混合高斯模型来做前景检测,然后运用连通域的判断来进行人体头部区域的定位[2]。杨莉琼等[3]在机器学习的基础上对安全帽佩戴检测做了相关研究,利用深度学习算法检测出现场视频中的施工人员脸部位置,根据安全帽与人脸的关系估算出安全帽潜在区域再对区域图像进行增强处理,使用 H方向梯度直方图提取样本的特征向量,用支持向量机分类器对脸部上方是否有安全帽进行判断,实现对施工人员安全帽佩戴行为的实时检测与预警。在建筑施工场地方面,刘云波等[4]提出一种基于计算机视觉的施工现场的安全帽监控技术,通过利用背景差法从图像中提取出前景,运用二值化的方法分割出检测目标进行尺度滤波提高检测的准确性。
在YOLOv系列算法的改进方面,王兵等[5]在YOLOv3的基础上使用GIoU代替交并比IOU,在包含IOU对目标物体的尺度不敏感的特点下,GIoU可优化预测框与真实框的重叠区域,从而改进了回归的损失函数,提高了判断是否佩戴安全帽的检测效果。林俊等[6]利用YOLO v3提出了安全帽检测的方法,通过修改分类器使输出的张量为18维度,再对基于YOLOv3的预训练模型进行训练,根据损失函数和交并比的曲线对模型的参数进行优化得到最适合的安全帽检测模型。施辉等[7]提出了基于改进YOLO v3算法的安全帽佩戴检测方法,通过采用图像金字塔结构获取不同尺度的特征图用于多尺度的位置和类别预测,使用施工场地的监控视频作为数据集进行目标框维度聚类,在训练迭代过程中改变输入图像的尺寸从而增加模型对尺度的适应性。
王明芬等[8]基于视频图像做了安全帽检测、识别和跟踪的相关研究,通过提取视频里的帧序列进行前景处理,然后在处理后的结果中检测目标、预测和跟踪轨迹的新位置,再匹配检测目标并显示目标的跟踪结果。邓开发等[9]提出一种基于深度学习的安全帽佩戴检测方法,使用Keras深度学习框架搭建Faster RCNN模型,通过卷积层和池化层提取图像的信息形成特征图,提高了检测速度。刘晓慧等[10-12]对安全帽的识别算法进行了研究,在定位识别人脸时创新性地引入了检测肤色的方法来获得脸部以上的区域图像,将不变矩作为图像的特征向量,再通过支持向量机(SVM)分类模型[13]判断是否佩戴安全帽。
2 安全帽检测算法
以提高建筑行业安全生产效率为目的,本文提出了一种基于机器人视觉的建筑工地安全帽目标检测算法用于检测建筑工地人员安全帽佩戴情况,算法的设计思路如图1所示。本文的目标检测算法采用k-means算法通过自制的安全帽数据集进行先验框设计获得新的先验框维度,将用于训练的图片进行拼接实现了数据集的增强,使用CIOU量化真实框与预测框的重合度优化回归损失,从而增加预测精度,基于YOLOv4的基础网络进行特征提取,获得不同尺度的特征层,将获得的特征层经过深层次特征金字塔进行特征融合,再输入分类回归层进行回归预测。
2.1 特征提取网络
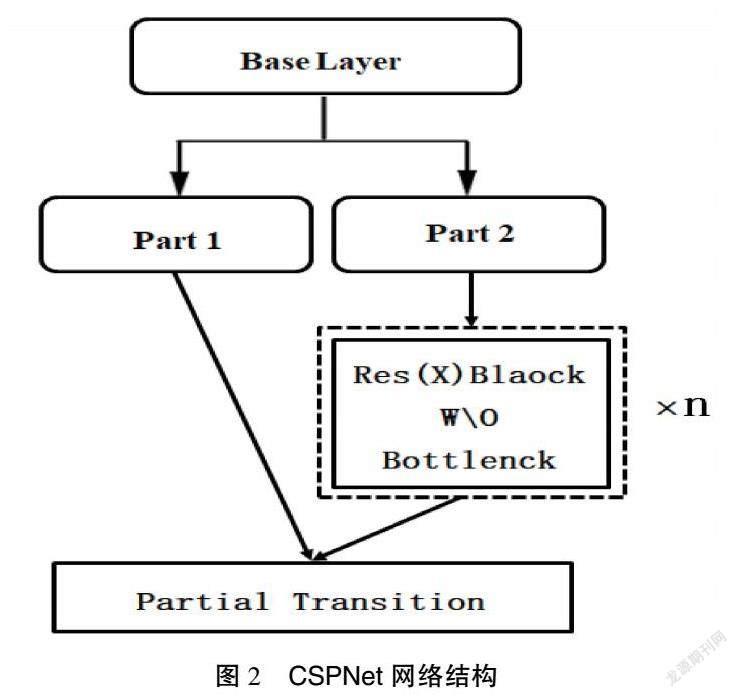
CSPDarkNet53作为YOLOv4的主干特征提取网络,是在DarkNet53的基础上结合了CSPNet。CSPNet网络主要用来增强卷积神经网络的学习能力,其结构如图2所示。CSPNet将原来由残差单元叠加的卷积网络进行了左右的拆分,第一部分会有一个大的残差边不经过堆叠的残差結构直接连接到后面的输出层,第二部分作为主干部分继续进行原来残差块的堆叠。
从图2 CSPDarkNet53特征提取网络结构中可以看到,YOLOv4的输入是一个416×416×3的图片,当然也可以对输入图片的大小进行改变,例如改为608×608×3的图片,但考虑到常用电脑显存的问题,本论文选择了输入大小为416×416×3的图片。
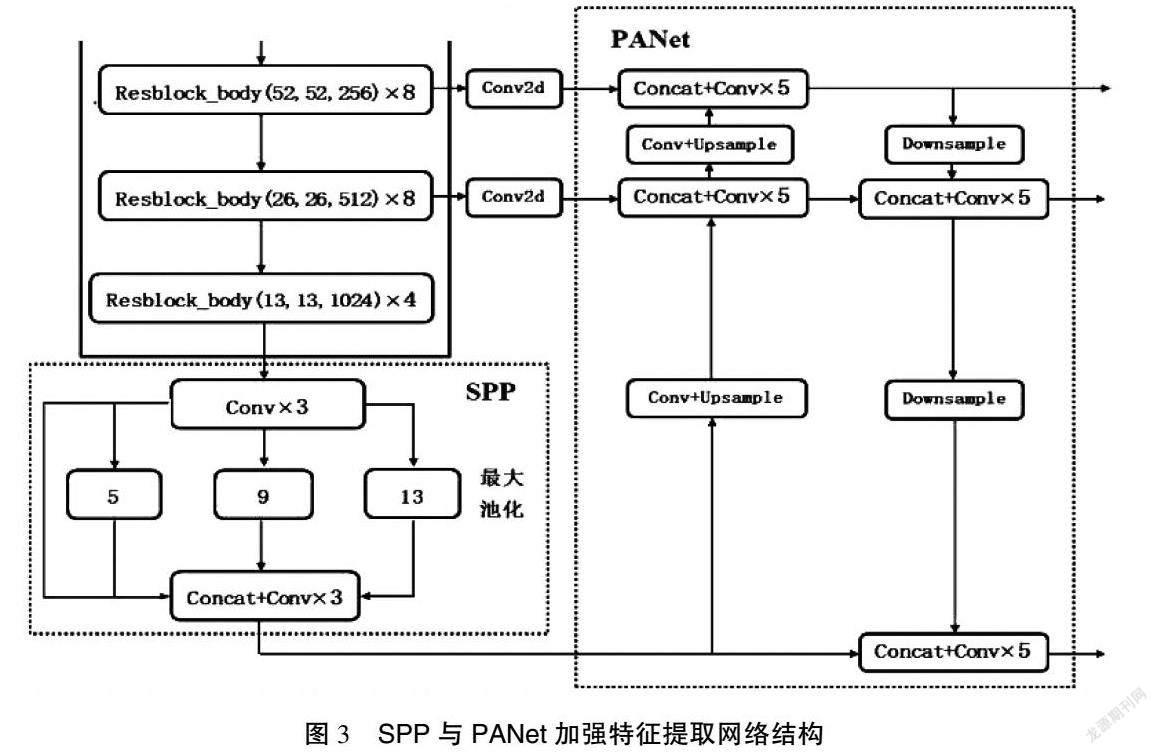
在主干特征提取网络中,只使用了最后面3个的特征层进行下一步的操作,因为这3个特征层的语义信息更为丰富一些。在获得了最后3个特征层后,本研究将第五层的特征层,即13×13×1 024的有效特征层进行3次卷积操作,再将卷积后的结果输入SPP网络结构中。
SPP网络结构具有4个分支,事实上就是运用不同池化核大小的最大池化对输入进来的特征层进行池化处理从而增加网络的感受野,然后将池化后的结果经过堆叠和3次卷积操作输入下一个环节即PANet网络中。SPP与PANet加强特征提取网络结构如图3所示。通过堆叠和3次卷积后的特征层在PANet网络中通过上采样,将输入的特征层的高和宽变为原来的2倍,当输入的特征层尺寸为13×13,则经过上采样处理后的特征层尺寸为26×26,这样就可以把上采样得到的特征层与在主干特征提取网络中获取到的shape同样为26×26×512的特征层进行堆叠从而实现特征融合,完成堆叠后再进行5次卷积,5次卷积的操作为1×1的卷积和3×3的卷积交替进行来完成,这样的结构有助于提取图片的特征并减少了参数量。同理再一次上采样、堆叠、卷积,这样就完成了一个特征金字塔的结构并将主干特征提取网络中的3个有效特征层都进行了特征融合。
PANet网络结构进一步加深了特征提取,将特征融合后的结果进行下采样,使特征层的高和宽再一次被压缩,从而与第一次上采样得到的特征层进行堆叠,堆叠后进行5次卷积,卷积后的输出一方面用于YOLO Head进行结果预测,另一方面继续进行下采样再与池化后的特征层进行特征融合。在PANet结构中,进行多次的特征融合得到了更加有效的特征。
2.2 YOLO Head网络结构
YOLO Head将提取到的特征进行结果预测,YOLO Head的结构与YOLOv3的分类回归层是一致的,在YOLOv4网络结构中一共存在3个YOLO Head,可以分为上层、中层和下层。每个YOLO Head的内部是1个3×3的卷积和1个1×1的卷积,3×3的卷积是对前一层输出结果的特征整合,1×1的卷积是利用3×3卷积后的特征获得最终的输出结果。YOLO head的网络结构如图4所示。
本文使用的数据集是基于VOC数据集的格式。因此,YOLO Head的预测结果为(52×52×75)(26×26×75)(13×13×75),分别对应着上层、中层和下层。以下层为例,下层的预测结果(13×13×75)基于下采样与池化后的特征层进行特征融合获得特征图预测。75可以分解成3×25,其中3表示网格点上的3个先验框,下层利用的特征层shape为13×13,即将输入的图片划分为169个网格,每个网格会负责该区域物体的检测。当某个物体的中心落到该区域时就需要利用网格对物体进行检测。因此,YOLO Head输出的预测结果是将先验框进行调整后的最终预测框结果。因为使用的是VOC数据集的格式,所以分为20个种类。25则包含着VOC数据集分的20个种类;4个用于调整先验框的参数,通过4个调整参数对已经设定好的先验框的中心和宽高进行调整,调整后的结果即为预测框;最后剩下的1个1,用来判断先验框内部是否包含需要检测的物体。当数值越趋近于1,则表示先验框内包含检测物体;同理,当数值越趋近于0,则表示先验框内不包含检测物体。
3 实验过程及即结果分析
3.1 实验数据集制作
实验数据集是目标检测任务的关键性部分,数据集的好坏直接影响着训练模型的预测效果,本文使用的数据集是基于VOC格式的自制数据集,利用企业提供的安全帽数据进行数据集的制作,通过对图片数据的筛选滤除了重复的或不符合检测任务的图片,用于本文的安全帽数据集总共包含8 270张,其中,用于模型训练的图片为7 581张、用于模型测试的图片为689张。用于模型训练的图片需要对图片进行数据标注,本文使用了专门的图像标记工具labellmg对安全帽数据集中的训练图片进行标记,制作用于模型训练的训练数据集。
3.2 实验平台
本实验所使用的软硬件工具包括Python,CUDA,OpenCV,Keras,numpy以及服务器等工具,基于YOLOv4的安全帽检测算法采用Pytorch框架。为了方便环境的搭建和管理,本文还使用了anaconda软件工具包。本文实验环境的配置如表1所示。
3.3 实验方案
本文的实验把安全帽数据集分为两类:一类是用于对改进后的新网络进行训练的训练集。在训练的时候,网络算法会在训练集的图片中随机选取图片进行训练,直至遍历完所有的图片;另一类是用于已经训练成功的网络模型进行测试的测试集。
本实验的网络训练初始参数参考了YOLOv4官网上提供的部分参数,然后在预训练权重的基础上进行训练。将首次训练得到的权重参数作为下一次训练的权重,根据训练效果对网络参数进行调节再多次进行训练,从而得到最优网络效果的权重参数。本文的特征提取网络会有3种不同尺度的特征层。因此,本实验在安全帽图片尺寸的选择上并没有采取相同尺寸的训练图片,而是在网络训练时随机输入不同尺寸的图片。
3.4 实验结果分析
本实验通过使用最佳的权重参数进行图片预测,从而检测模型的训练效果。实验模型算法的检测效果如图5所示。
从该图片的检测结果中可以看出,本研究把图片中佩戴安全帽的作业人员的安全帽用描框框选出来并标记为hat;同时,把未佩戴安全帽的作业人员也框选出来并用红色标记为person。模型检测精度的計算采用的是mAP,mAP常用于衡量目标检测的精确度。
在使用mAP计算精度前,需要了解TP,TN,FP和FN的概念。mAP的计算过程会涉及检测样本是否有被正确地分类以及被分成了正样本还是负样本,因此采用TP,TN,FP和FN来代替4种分类,即正确的被分为了正样本;正确的被分为了负样本;错误的被分为了正样本,实际上为负样本;错误的被分为了负样本,实际上为正样本。
在计算mAP中,需要使用精确度和召回率这两个指标,精确度的概念表示的是分类器正确分类正样本的部分占所有被分类器认为是正样本的比例(包含被错误分为了正样本的部分),用来衡量分类器预测结果的准确度,其表达见公式(1):
召回率的概念表示的是分类器正确分类正样本的部分占所有实际上是正样本的比例(包含被错误分为了负样本的部分),用来衡量分类器是否把比较多的正样本检测了出来,其表达见公式(2):
在计算mAP中,要使用两个指标,是因为在目标检测算法中,会人为地对置信度的值进行设定。只有当预测结果的置信度大于所设定的值时,检测网络才会认为图片中包含检测的目标。如果置信度的值设置得比较合适,分类器预测的结果就会越符合实际情况,即更多的正样本被正确地检测了出来。如果设置得太高就会使一部分实际的正样本被分为负样本,此时在计算精确度时其值为等于1,召回率的值就会很低。因此,如果只用精确度来衡量预测效果的话,虽然精确度很高,但是仍有明显的目标没有被检测出来;同理,如果只用召回率来衡量预测效果的话,当置信度设置得越低,计算召回率的值就会越高而精确度却较低,那么就会存在较多的误检测,即被错误地分类为正样本的数量会增多,检测效果不好。不同置信度的值会影响精确度和召回率的大小,最终在计算mAP时要同时考虑精确度和召回率,只有将两者进行结合才能正确评价目标检测算法的优劣。在取不同的置信度时会得到不同的精确度和召回率值,利用不同的精确度[0,1]与召回率[0,1]的点的组合所得到的曲线围成面积的值为这一类的AP值,而mAP就是这一类AP值的平均值。
在运行mAP的计算程序前需要准备两个文件夹,分别为detection_result,ground_truth。detection_result用于存放检测结果的txt文件,文件里包含物体的种类、物体的置信度以及物体位置的预测结果;ground_truth用于存放真实框的内容。文件里包含物体的种类以及检测物体真实存在的位置。运行相应的程序即可得到对应文件夹中的内容。部分操作及运算结果如图6、图7所示。
当生成计算mAP所需要的文件后,便可以运行程序得到mAP的计算结果,mAP计算的值如图8所示。从mAP的计算结果图中可以得到,检测安全帽的召回率为93%,检测精度为95.61%;检测未佩戴安全帽的作业人员的召回率为81.57%,检测精度为84.63%,整体上mAP的计算结果为89.08%。以mAP作为本文算法检测效果的评价指标,满足了本设计的检测要求。
4 结语
本文基于YOLOv4的深度学习算法,首次在建筑工地领域实现了安全帽的智能检测。实验采用k-means算法通过安全帽数据集进行先验框设计获得新的先验框维度,将用于训练的图片进行拼接实现了数据集的增强,使用CIOU量化真实框与预测框的重合度优化回归损失从而增加预测精度,基于YOLOv4的基础网络进行特征提取,获得不同尺度的特征层,将获得的特征层经过深层次特征金字塔进行特征融合,再输入分类回归层进行回归预测。本文的安全帽算法在检测精度和速度上都满足设计的要求。
参考文献
[1]GIRSHICK R.Fast R-CNN:Proceedings of the IEEE international conference on computer vision[C].Santiago:2015 IEEE International Conference on Computer Vision (ICCV),2015.
[2]馮国臣,陈艳艳,陈宁,等.基于机器视觉的安全帽自动识别技术研究[J].机械设计与制造工程,2015(10):39-42.
[3]杨莉琼,蔡利强,古松.基于机器学习方法的安全帽佩戴行为检测[J].中国安全生产科学技术,2019(10):152-157.
[4]刘云波,黄华.施工现场安全帽佩戴情况监控技术研究[J].电子科技,2015(4):69-72.
[5]王兵,李文璟,唐欢.改进YOLOv3算法及其在安全帽检测中的应用[J].计算机工程与应用,2020(9):33-40.
[6]林俊,党伟超,潘理虎,等.基于YOLO的安全帽检测方法[J].计算机系统应用,2019(9):174-179.
[7]施辉,陈先桥,杨英.改进YOLOv3的安全帽佩戴检测方法[J].计算机工程与应用,2019(11):213-220.
[8]王明芬.基于视频的安全帽检测和跟踪算法研究[J].信息通信,2020(1):40-42.
[9]邓开发,邹振宇.基于深度学习的安全帽佩戴检测实现与分析[J].计算机时代,2020(7):12-15.
[10]刘晓慧,叶西宁.肤色检测和Hu矩在安全帽识别中的应用[J].华东理工大学学报(自然科学版),2014(3):365-370.
[11]姬壮伟.基于pytorch的神经网络优化算法研究[J].山西大同大学学报(自然科学版),2020(6):51-53,58.
[12]BOCHKOVSKIY A,WANG C Y,LIAO H Y M. YOLOv4:Optimal Speed and Accuracy of Object Detection[EB/OL].(2020-04-23)[2023-03-06].https://doi.org/10.48550/arXiv.2004.10934.
[13]WANG C Y,MARK LIAO H Y,WU Y H,et al.CSPNet:A new backbone that can enhance learning capability of cnn[C].Seattle:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops,2020.
(编辑 王永超)
