
基于车辆的关系型数据库性能提升
2023-05-22 03:56:50孙代青王光福张文成
汽车实用技术 2023年9期
刘 路,孙代青,王 瑞,王光福,张文成
(陕西汽车集团股份有限公司技术中心,陕西 西安 710200)
现在主流的数据库包括 MySQL、Oracle、 PostgreSQL等,对于这些数据库各有利弊。MySql有很灵活的口令系统,但是在数据库压力达到极限临界点的时候,服务器会出现丢失数据的情况。Oracle和PostgreSQL在很多方面存在相似之处,Oracle能在所有主流平台上运行,但是安装环境及安装包都占用很大的空间,且操作比较复杂。PostgreSQL运行采用的是抢占资源方式,可能会堵塞其他进程,但是可以进行优先级设置,可规避某些阻塞进程的发生。PostgreSQL是一种关系型数据库,客户和服务器软件既可以运行在同一台机器也可运行在不同的机器上[1],其性能稳定,即使数据库压力达到极限值临界点,它也可以保持稳定的状态,并且在内存很小的机器上依旧能够运行。PostgreSQL支持更多的互联网特征的功能,比如拥有更多的数据类型,支持更多的正则表达式[2]。本文描述了运用PostgreSQL对某车的行车数据进行表的结构设计和数据库的优化方法,极大程度地提升数据库的响应效率,提升了用户的体验度。
1 数据库设计
某车数据上报采用状态量及模拟量的方式。比如四状态量:当某一秒内有四状态数据上报时,无论是一条数据还是多条数据,都可以用一个四状态枚举量数据包进行传输,由于它们都是在同一秒内上传的,因此,采样时间的天、时、分、秒都是一样的,把不同信号以value_id或者status_id(数据类型编号)进行区别。gps(车辆定位信号)和 diagnosis(诊断信号)数据上报方式与状态量及模拟量数据的上报方式不同,所以单独设计表的字段。
同一辆车按照数据上报方式的状态量各自建表:表名采用状态量+VIN(车辆识别代号),表1是型号为d123456的某车车辆的数据库表名。

表1 d123456车辆数据库设计表名
2 数据库性能提升
数据库优化可以从硬件优化、存储系统、存储结构、SQL四个维度着手。层与层之间是相互关联的,硬件优化和存储系统的优化成本较高。数据库中的数据最终是落在物理磁盘上的,对物理存储结构的优化虽然不能减少对物理存储的访问次数,但是可以使读写并行化发生,减少对磁盘读写的竞争压力,减少不必要的物理存储系统的扩充,所以对于优化效果来说,存储结构和SQL会更佳。本文重点就存储结构和SQL优化进行数据库效率提升的分析。
2.1 并行查询
PostgreSQL的并行查询包含三个组件:leader、gather、workers。并行化关闭的时候,进程的工作流程是由进程本身处理所有的数据;并行化开启后,系统本身会在并行化节点上增加一个gather节点和多个workers线程,gather节点类似于查询树的子节点,workers线程的数量是由PostgreSQL的配置参数决定,workers线程之间相互配合,完成查询任务后将结果反馈给 leader进程。并行查询的原理如图1所示。

图1 并行查询原理图
workers的数量可以动态调整,max_parallel_workers_per_gather参数定义了 workers的最小数量,查询执行器从池子中获取 max_parallel_workers的数值,接着获取 max_worker_processes的数值,该参数定义了workers的上限。查询过程中,如果分配的worker进程启动失败,则会切换成单线程执行查询任务,查询执行器会依据表的大小,适时地调整 worker进程的数量,而调整worker的数量又与参数 min_parallel_table_scan_size、min_parallel_index_scan_size有关。根据表大小计算并行度(parallelism)的公式如下:
本次测试min_parallel_table_scan_size设置的数值为8 MB,min_parallel_index_scan_size设置的数值为 512 KB,根据式(1)计算出来最合适的并行度数值为4。
未开启并行模式,采用单线程查询模式,将dmax_parallel_workers_per_gather参数设置的数值0,查询d123456车辆发动机转速一年的数据,PostgreSQL执行过程如图2所示。

图2 测试结果
开启并行查询模式,将dmax_parallel_workers_per_gather参数设置的数值4,查询d123456车辆发动机转速一年的数据,PostgreSQL执行过程如图3所示。
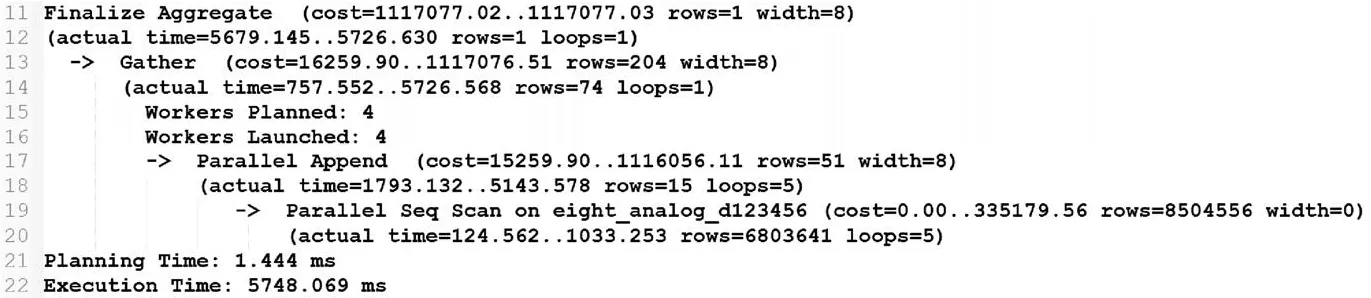
图3 测试结果
结论:通过数据表大小计算得到合适的并行度,开启并行化之前数据访问的时间是18 730.130 ms,开启并行度后数据访问的时间是5 748.069 ms,数据请求的效率提升约69%。
2.2 数据表索引
索引是对指定数据表中的某种字段进行特定排序,排序后的数据表就会形成存储记忆,可以迅速地提取所需数据,减少人工等待时间[3]。数据库的索引字段包含很多种方式,包含普通索引和唯一索引。普通索引常见的有 where条件查询、order by排序条件查询。唯一索引用关键字UNIQUE把某数据列定义成唯一项[4]。事实上,创建唯一索引不单单是为了提升数据库访问速度,而且能够避免重复数据出现,保证数据的有效性。PostgreSQL索引类型常用的索引hash、btree、gin。Btree索引适用的范围很大,它支持所有类型的数据查询。B树是平衡且多分支类型的,第一页是索引根,内部节点位于根下方,最低行是叶子页面,每个页面与根部都由相同数量的内部页面分隔。Btree工作原理如图4所示。
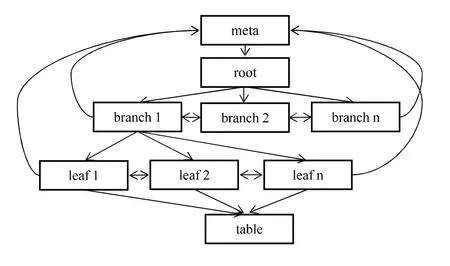
图4 Btree工作原理图
对某车的车辆数据表添加btree类型的复合索引,该索引字段的任何子集均可用于查询条件。使用如下代码对车辆行车数据表添加索引:
query4:= 'CREATE INDEX "' || name || '_brin"ON "public"."'|| name ||'" USING brin("sample_time","value_id")';
raise notice 'query4 is: %', query4;
execute query4;
根据上文对数据库添加btree类型的复合索引的优化策略,系统对优化前后的数据库进行请求的性能测试,测试条件为WIN7、RAM 16 GB、CPU 2.7 GHZ,对车辆里程数据进行查询,测试结果如图5所示。

图5 索引测试结果
结论:从上述测试对比可看出,相对比优化之前的请求数据时间,添加btree复合索引后,数据请求的效率提升约30%。
2.3 数据库分区
数据库分区是指将庞大的数据分段划分多个位置存放,分区后数据表仍然是一张表,但数据根据设置的分区条件存贮在多个分区块中。分区可分为水平分区和垂直分区两种方式。垂直分区是对表格中存在的列进行划分,对表格的宽度进行缩减。水平分区指的是对数据表内容横向划分,每张分区表中的初始结构相同,本文采用的是水平分区,由于每种行车数据都有独特的 value_id或者status_id(数据类型编号),提取数据一定会定义数据类型编号,所以对某车设置的分区条件为value_id或者status_id(数据类型编号)。
分区之前先使用 CREATE TABLE构建表的结构,使用PARTITION BY LIST()语句添加分区,括号中填入设计的分区字段。在分区测试中发现,终端上报的车辆行驶数据会存在一些测试或者无意义数据,这些数据未定义 value_id或者status_id(数据类型编号),如果对这些测试数据不设置一个固定存放区,则发现导入的车辆数据会出现丢失或者时间格式的跳变。PostgreSQL新版本支持创建默认分区即为default区,default区可以存放未匹配到数据类型编号的车辆数据。定义分区表需要对每张分区表分配特定的表格名称,这里采用的命名格式是表名+车型号+value_id或者status_id(数据类型编号)。使用如下代码对车辆行车数据表添加分区:
query2:='CREATE TABLE'|| name||' ("value_id" int4 NOT NULL, "value" float8 NOT NULL,"sample_time" TIMESTAMP (6) NOT NULL, "flag"int4 NOT NULL ) PARTITION BY list ( value_id )';
query_default:='CREATE TABLE'||name||'_def ault PARTITION of ' ||name || ' DEFAULT';
raise notice 'query2 is: %', query2;
execute query2;
raise notice 'query_default is:%', query_ default;
execute query_default;
分区划分完成后,每张车辆数据表中的value_id或者 status_id(数据类型编号)都存放在定义好的分区中,查询车辆的车速数据只需遍历车速的分区表,无需对所有表格进行遍历。使用select*from pg_tables where tablename LIKE '%d123456%',就可以查看分区表的建立是否完成。查看d123456车辆分区后的部分结果如表2所示。
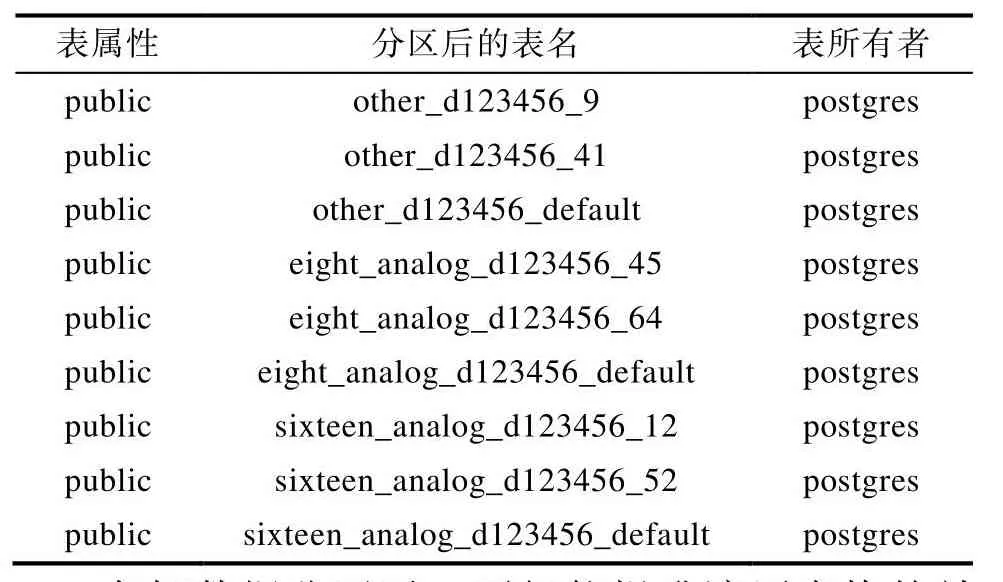
表2 d123456分区后的部分结果
车辆数据分区后,不仅能提升遍历表格的效率,还能减少后期对数据库的维护。车辆分区表创建后,车辆数据发送频率是1 s,数据量非常庞大,如果某张分区表发生故障或者某种信号的数据类型编号作出调整,就可以单独修改特定数据类型编号的数据表,而且不会影响其他车辆数据的正常使用,降低了数据库的运维难度和工作量。
数据库添加分区的优化策略,对优化前后的数据库进行请求的性能测试,测试条件为WIN7、RAM 16GB、CPU 2.7GHZ,对车辆水温数据进行查询,测试结果如图6所示。
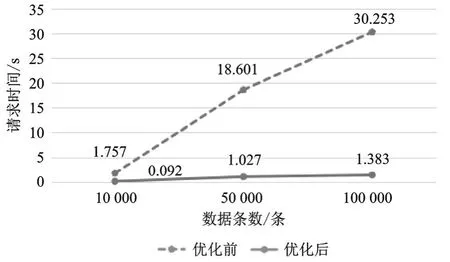
图6 分区测试结果
结论:从上述测试对比可看出,相对比优化之前的请求数据时间,对数据类型编号添加水平分区后,数据请求的效率提升约95%。
2.4 应用程序接口设计优化
应用程序在访问数据库时,需要避免重复连接数据库的行为,这将严重影响程序的响应速度[5]。普通的应用程序接口访问数据库,需要频繁地创建连接和关闭连接,产生多次网络交互,影响服务器性能。本文运用数据库连接池的方式访问数据,连接池的基本思想是将数据库连接作为对象存储在内存中,当用户需要访问数据库时,从连接池中取出一个空闲且已建立的连接对象,不需要建立新的连接机制。当用户使用完数据库连接后,将该连接放回池中,供下一个连接请求使用。数据库连接池的工作流程如图7所示。
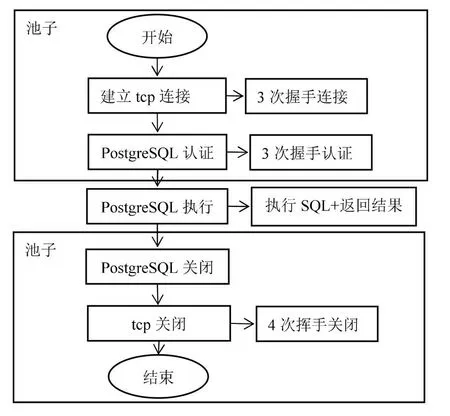
图7 数据库连接池流程图
使用如下代码对PostgreSQL进行数据池接口设计:
public postgresUtils(){
DataSource.setUrl(url);
DataSource.setDriverClassName(driver);
DataSource.setUsername(username);
DataSource.setPassword(password);
DataSource.setInitialSize(10);//初始化时创建链接个数
DataSource.setMaxTotal(50);//设置最大连接数
DataSource.setMaxIdle(5);//这只最大的空闲连接数
DataSource.setMinIdle(1);//设置最小空闲连接数字
}
总结:数据库连接池允许应用程序复用资源,统一连接管理,避免了数据库连接泄露和多个线程同时使用同一个连接。
3 结论
为了满足车辆数据库系统的大数据处理能力和混合负载能力的更高要求,本文提出和设计了提升车辆数据库性能的方法,融合了并行系统查询优化、数据表索引、数据表分区、应用程序连接池等技术。通过测试验证,与传统的单线程数据库相比,极大地提升了数据库性能。
猜你喜欢
国际眼科杂志(2023年7期)2023-07-11 01:35:10
国际眼科杂志(2023年3期)2023-03-13 02:52:46
国际眼科杂志(2023年2期)2023-02-13 08:46:12
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
数码世界(2020年5期)2020-06-23 00:14:36
党员生活(2020年2期)2020-04-17 09:56:30
铁道通信信号(2018年10期)2018-12-06 09:34:56
海峡科技与产业(2016年3期)2016-05-17 04:32:12
中国石油企业(2014年4期)2014-11-30 06:13:06
河南科技(2014年24期)2014-02-27 14:19:25
