
基于XLNet 的医学文本实体关系识别模型
2023-05-18 08:13郑增亮沈宙锋苏前敏
智能计算机与应用 2023年4期
郑增亮, 沈宙锋, 苏前敏
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引言
电子病历(Electronic Medical Records, EMR)是患者在医院就诊的记录,主要包含文本、图表以及影像等多种信息[1]。 随着EMR 的渐趋普及,人们对其了解得也更加详细。 总地来说,EMR 不仅包含了患者的检查结果、临床用药治疗、不良反应等信息,还涵盖了许多的医疗相关实体[2]。 如何将一个非结构化的临床EHR 转化为结构化的数据,挖掘其中有价值的诊疗信息,已然成为当前自然语言处理(NLP)任务的研究热点之一。 关系抽取任务是在消息理解会议(MUC)[3]上首次提出的,自2010年以来,国外对于电子病历相关实体关系抽取研究已经取得许多成果。 国内EMR 相关的研究发展起步时间较晚,公开的数据集和研究结果为数不多,已有的关系抽取模型主要依赖机器学习有关算法,这类方法大多依赖大量的特征工程建设,费时费力。 近年来在关系提取任务中,基于神经网络方法取得了良好的效果,但是常见的关系抽取并不能解决文本语句中一词多义的现象,同时也没有充分捕捉到电子病历中实体关系之间的特征信息,使得分类效果欠佳。
本文提出一种基于XLNet-BiGRU-Attention-TextCNN 的医疗文本实体关系抽取方法。 该方法首先使用XLNet 预训练语言模型将输入文本语句转换为向量表示,然后将向量化的文本特征序列输入至一个双向门控循环单元(GRU)进行长距离依赖关系特征提取,接着使用注意力机制(Attention)为特征序列分配权重,降低噪声影响,为了提高Softmax分类器的识别效果,最后利用卷积神经网络提取文本语句的局部特征。
1 相关研究
目前,实体关系抽取模型的训练、验证使用的数据集主要来源于开放数据源,例如新闻、微博、百科等[4]。 实体关系提取的早期方法主要是监督式学习,如CHEN 等学者[5]在关系抽取任务中,通过对原始数据集进行统计和特征提取的方法取得了较高的F1值(正确率∗召回率∗2 / (正确率+召回率))。ZHANG[6]在关系抽取任务中引入支持向量机的方法来提高抽取的效果。 这些方法大都需要手工构建大量特征,不仅费时费力,而且泛化性能也不强。
随着神经网络的快速发展,神经网络模型已逐渐应用到实体关系抽取任务中。 Richard 等学者[7]使用循环神经网络(RNN)获取文本序列信息,进行实体关系抽取,虽改进了模型抽取效果,但没有考虑到实体在训练语句中的语义和位置信息。 Zeng 等学者[8]采用词向量和词位置向量相结合方法获取模型输入向量,通过卷积神经网络层与层之间运算得到句子特征表示,充分利用句子中的实体信息,从而提升关系抽取的准确率。 Huang 等学者[9]采用两阶段方法,在长短时记忆(LSTM)网络模型中引入支持向量机(SVM)模型,以此抽取药物间的关系。
2 基于XLNet-BiGRU-Attention-TextCNN的关系抽取模型
关系抽取模型框架主要由3 个部分组成,分别是:词表示层、编码层、输出层。 其中,词表示层包含文本语句的输入,序列化表示模块;编码层包含BiGRU 模块、Attention 模块和TextCNN 模块;输出层使用Softmax模型,模型结构如图1 所示。 将句子输入到模型中,首先通过词嵌入层构建向量矩阵,将每个词映射成低维向量,随后将句子矩阵送入BiGRU,进一步提取字向量中上下文特征,接下来将处理后的矩阵通过自注意力层对重要信息进行加权,计算出权重系数,然后使用TextCNN 模型提取句子的局部特征,最后由Softmax模型确定关系类型,完成关系抽取。
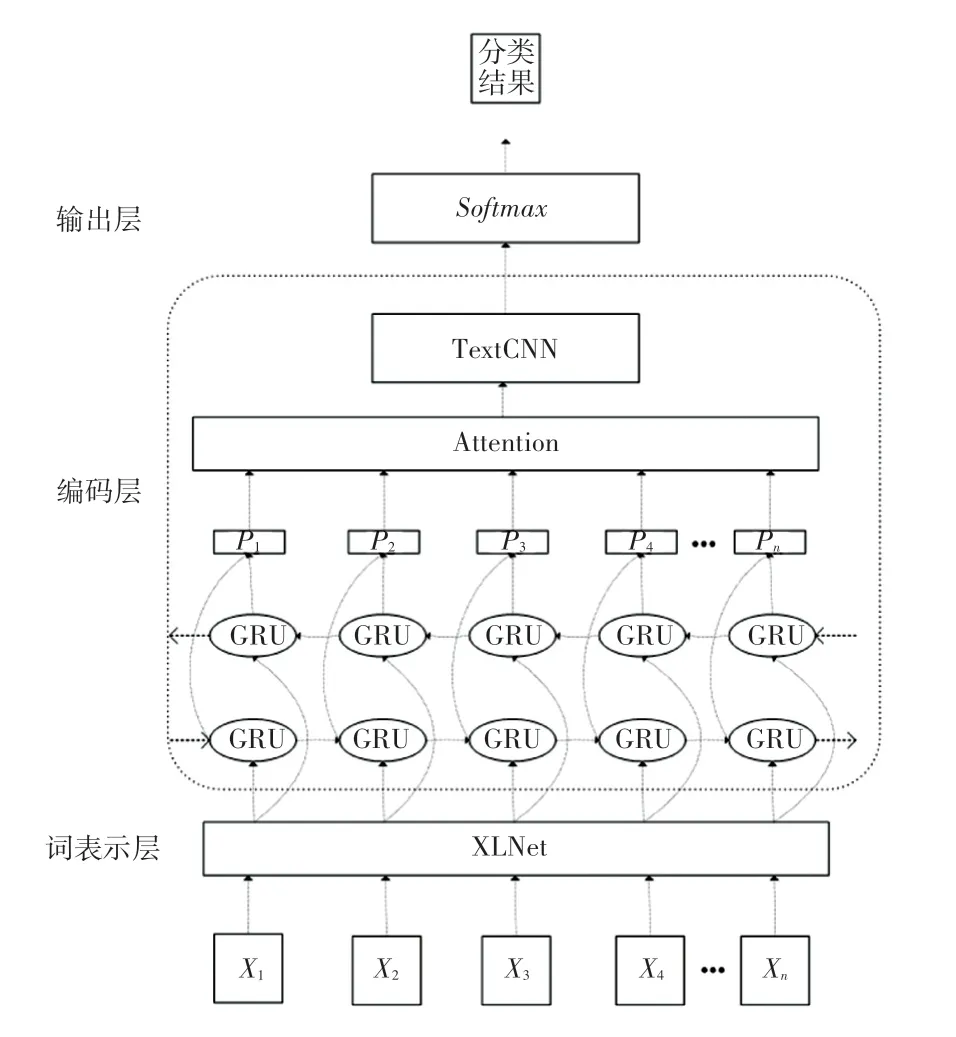
图1 XLNet-BiGRU-Attention-TextCNN 模型结构Fig. 1 XLNet-BiGRU-Attention-TextCNN model structure
2.1 词表示层
该模型的词表示层使用XLNet 预训练语言模型对输入语句进行向量表示。 针对Bert 模型[10]微调和预训练过程不一致的缺陷, Brain 提出了一种新的广义自回归模型XLNet[11]。 XLNet 利用排列语言模型(PLM)随机排列句子,使用自回归的方式预测句子末尾的单词,通过这种方式,可获取到单词间相互依赖的关系,而且可以充分利用单词或者字符的前后文信息[12]。 与Bert 相比,XLNet 没有采取在输入端隐藏掉部分单词的模式,而是通过注意力机制[13]在Transformer 内部遮掩部分单词。 XLNet的原理如图2 所示,XLNet 的输入包括词向量和位置信息,图2 中最下面的e(x) 就是词向量,w就是位置信息。 经输入层输入后,XLNet 会将句子重新排列,根据排列后顺序使用自回归方式进行预测。
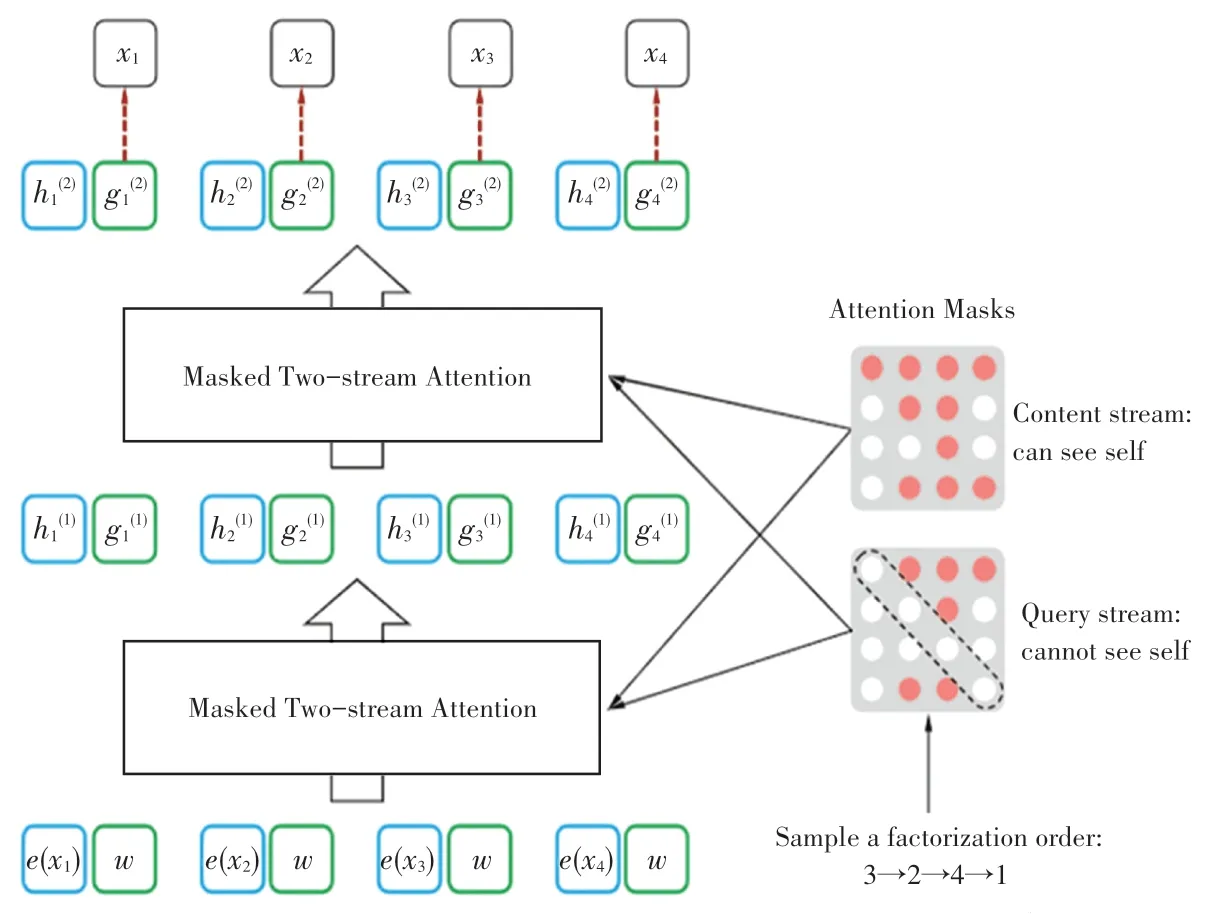
图2 XLNet 原理[11]Fig. 2 XLNet principle[11]
2.2 双向门控循环单元
门控循环单元(GRU)使用门控机制来控制输入、记忆和其他信息,并在当前时间步长内进行预测[14]。 GRU 可以视为LSTM 的变体,与LSTM 相比,GRU 具有参数少、训练时间短的优点。 GRU 门函数保留了重要的特性,可以捕捉时态数据中的长依赖关系。 图3 说明了GRU 的内部控制结构。 GRU内部结构中只有2 个门单元:更新门和重置门。GRU 结构中的参数具体如下。

图3 GRU 模型结构图Fig. 3 Structure diagram of GRU model
(1)重置门:rt计算公式见如下:
(2)更新门:zt计算公式见如下:
(3)隐藏层:状态更新计算公式见如下:
其中,σ表示sigmoid激活;W为权值矩阵;xt表示t时刻的输入;ht-1表示t时刻的隐藏状态。 本文采用BiGRU 结构,充分利用时间语境。 BiGRU 使用前向和后向计算,每个时间序列数据获得2 个不同的隐藏层状态。 隐藏层的最终输出是两者的连接隐藏状态[15]。
2.3 注意力机制
针对BiGRU 的输出ht学习相应的注意力权重α,然后对权重归一化,将得到的向量α作为注意力权重概率分布,最后将α与输出进行点积相加,从而得到经过注意力运算的特征向量[16]。
2.4 TextCNN
卷积层意在捕获局部语义信息,并将这些有价值的语义成分压缩为特征图[17]。 当卷积层输入特征矩阵后,卷积运算中需用到的公式为:
其中,b∈R表示偏置;f表示非线性激活函数;Xj为落入滑动窗口的第j个特征矩阵;池化是选择从每个卷积核中提取的特征[18]。 这里,最大池(max pooling)用来获得每个特征的最大值,该方式往往漏掉了其他关键信息。 另一种是平均池,即求出特征向量的平均值,能够表示整个文本的语义信息。 为了在句子中获取更多的语义信息,以提高关系识别的准确性,故将2 种池化后的特征进行拼接作为此层输出,可由式(6)~式(8)进行描述:
其中,yj为每个卷积核卷积出的特征向量,mj为池化后的输出。 最后通过Softmax层输出。
3 实验结果与分析
3.1 数据集
中文EMR 关系抽取数据集的构建不仅要求对原始数据进行预处理,同时要求标注人员需要具备一定的医学知识。 EMR 的诊疗信息中的实体关系主要存在于疾病、症状、检查等之间,故在本研究中,以I2B2 (informatics forintegrating biology and the bedside)的医学实体间关系标注规范作为参考标准[19],在专业医务人员的指导下,制定了本实验的中文EMR 关系标注类型,见表1。 由表1 可知,共包含7 种医疗关系。

表1 关系类型及描述Tab. 1 Relationship type and description
本实验的原始数据来自于上海市某二级甲等医院,包括内分泌科、呼吸内科、消化内科等不同科室的EMR,共1500 份。 为了保护患者的隐私,对EMR 文本进行去隐预处理,接着根据事先制定好的标注规则对文本数据进行标注。 最后,将标注好的数据集按照7∶2∶1 的方式进行划分,其中1050 份EMR 作为训练数据集,300 份EMR 作为验证数据集,150 份EMR 作为测试数据集。
3.2 评价指标
实体识别和关系抽取实验通常采用如下指标来评价模型的优劣,分述如下。
(1)准确率。 可由如下公式计算求得:
(2)召回率。 可由如下公式计算求得:
(3)F1值。 可由如下公式计算求得:
其中,TP表示测试集中正例被正确预测为正例的个数;FP表示测试集中正例被误分类为负例的个数;FN表示测试集中负例被误分类为正例的个数。
3.3 实验设置
本实验主要分为参数优化实验和不同模型对比实验。 参数优化实验主要是验证使用标签平滑交叉熵损失函数(Label Smoothing Cross Entropy,LSCE)是否可以提高识别效果。 与不同模型的对比实验可以验证基于XLNet 模型在实体间关系提取的有效性。 本实验均在Ubuntu 环境中搭建和运行,基于Python 和TensorFlow 搭建模型,并使用GPU 进行深度学习的计算,选用的计算机显卡配置为NVIDIA RTX 2060,显存为8 GB。 实验中主要的超参数配置包括: XLNet 预训练语言模型选取XLNet_base 版本,在编码层运行后,再输入到此后的网络结构中进行学习训练。 LSTM 的大小设置为64 维,网络层宽为64 维,网络学习率为2e-5,Dropout的比例设置为0.1,每一批量的样本数量为32,卷积核的尺寸分别是设置为5×5、9×9、13×13,卷积核个数设置为256,隐藏层的维度固定为768,使用relu激活函数,为了使模型收敛速度加快选用Adam 算法优化器。
3.4 实验结果
(1) 参数优化实验。 为验证LSCE 是否可以提高关系抽取效果,本实验设置Cross Entropy Loss和Focal Loss函数作为对比。 表2 是XLNet-BiGRUAttention-TextCNN 与不同损失函数在糖尿病数据集上达到的实验效果。
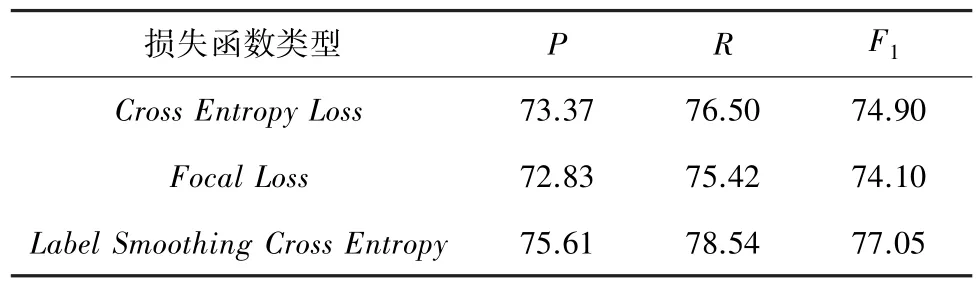
表2 不同损失函数实验结果Tab. 2 Experimental results of different loss functions %
(2) 不同模型对比试验。 为验证本研究提出的模型在中文糖尿病数据集的效果,本研究选择如下几种方法进行比较:
①CNN 模型[20]:CNN 用于关系提取,卷积深度神经网络(CDNN)用于提取词和句子的特征,并将所有的词标记都用作输入。
②BiLSTM-TextCNN 模型:该模型采用双向LSTM 网络模型提取语义依赖信息,并利用TextCNN网络提取局部特征,解决了传统关系抽取任务中复杂特征构建问题,在这项任务中取得了较好的效果。
③BiGRU-TextCNN 模型:采用双向GRU 网络模型获取文本前后向语义信息,然后连接TextCNN进行特征提取,利用更新门和重置门机制过滤噪声影响,提高模型识别效果。
④BiGRU-Attention-TextCNN 模型:在局部特征提取前加入Attention 机制,与BiGRU-TextCNN模型进行对比。
研究中得到的不同模型的实验结果见表3。
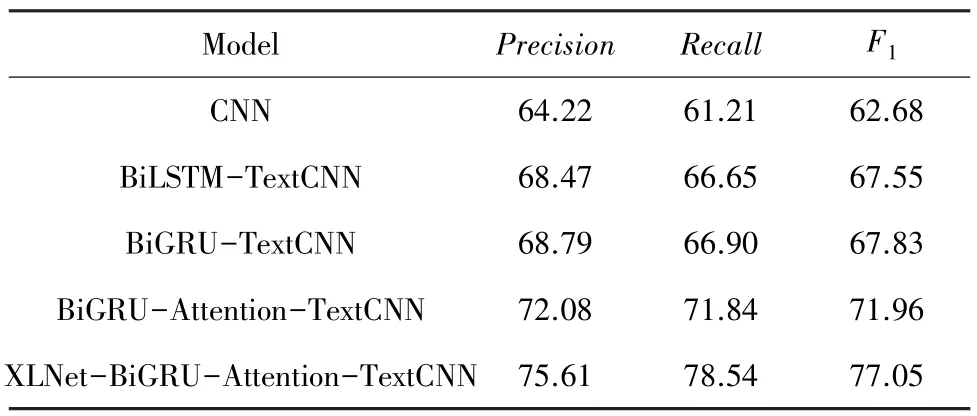
表3 不同模型实验结果Tab. 3 Experimental results of different models %
4 讨论
从表2 可以看出,当采用标签平滑交叉熵函数作为XLNet-BiGRU-Attention-TextCNN 模型训练的损失函数时,关系抽取的效果最优,其F1值较Cross Entropy函数和Focal Loss函数分别提高了2.14%和2.94%。 由于EMR 数据集中关系类型数量分布不均匀,最多为647,最少为115,对模型的关系预测带来一定程度上的干扰。 通过使用标签平滑交叉熵函数,缓解了医学文本中关系类型的数量不平衡问题,一定程度上提升了模型的性能。
通过表3 的实验研究结果可以看出,XLNet-BiGRU-Attention-TextCNN 模型与其他模型相比,总体上看,其精确率、召回率和F1值三方面均有提高:
第一,与传统CNN 模型对比,BiLSTM-TextCNN模型和BiGRU-TextCNN 模型在准确率分别提高了4.25%和4.57%,召回率分别提高了5.44% 和5.69%,F1值分别提高了4.87%和5.15%。 说明了CNN 网络的语义提取范围有限,在处理较长语句的关系识别时效果较差,利用含有门控机制的前后向长短时记忆网络和前后向门控循环网络可以更好地提取文本语句的长期依赖关系,并与TextCNN 网络结合可以更加充分地表示文本的语义信息。
第二,对比BiGRU-Attention-TextCNN 模型和BiGRU-TextCNN 模型,引入Attention 机制后关系提取的精确率提高了3.29%,召回率提高了4.94%,F1值提高了4.13%,说明了Attention 机制可以聚焦文本序列的关键信息,并为这些关键信息设置较大权重,降低噪声的干扰,通过动态调整权重矩阵,学习到关系抽取在长序列文本中隐藏的关键信息,提升模型识别抽取能力。
第三,对比XLNet-BiGRU-Attention-TextCNN模型和BiGRU-Attention-TextCNN 模型,采用预训练语言模型将精确率提高了3.53%,召回率提高了6.70%,F1值提高了5.09%,说明了采用双向自回归训练的语言模型XLNet 可以对文本上下文的语义信息进行更全面的表示,提高模型的关系抽取效果。
5 结束语
针对现有的实体关系抽取模型无法解决多义现象和文本语义信息捕获不足的问题,本文提出基于XLNet-BiGRU-Attention-TextCNN 的实体关系抽取方法。 利用预训练语言模型XLNet 对句子进行向量化表示,然后输入BiGRU 层充分表示捕捉字的上下文信息,通过注意机制提高在关系分类中起决定性作用的字符权重,最后加入TextCNN 提取局部特征,获得更细粒度的特征序列,有效解决一词多义的问题,提升了该模型在关系抽取任务中性能。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
