
高寒湿地分类的遥感特征优选研究
2023-05-17 05:03:46霍轩琳牛振国张波刘林崧李霞
遥感学报 2023年4期
霍轩琳, 牛振国, 张波, 刘林崧, 李霞
1. 长安大学 地球科学与资源学院, 西安 710054;2. 中国科学院空天信息创新研究院 遥感科学国家重点实验室, 北京 100094;3. 长安大学 土地工程学院, 西安 710054
1 引 言
湿地具有调节气候、保护生物多样性、蓄洪抗旱、改善环境等功能,同时为动植物提供了良好的生存条件(Moor 等,2015),是地球上最重要的生态系统(森林、海洋、湿地)之一(何菊红等,2015)。青藏高原高寒湿地是青藏高原乃至西部地区最重要的生态系统,近年来受到自然和人为因素干扰,高寒湿地面积已锐减了10%,且水量和湿地的面积减少速度还在加快(王根绪 等,2007;徐新良 等,2008)。因此,及时获知高寒湿地面积、分布区域等对青藏高原高寒湿地管理与保护乃至生态系统的可持续发展至关重要。
遥感分类特征的选择是目前对湿地进行准确分类与制图的众多挑战之一。分类特征需要考虑到以下两方面,其一,湿地是陆地生态系统和水域生态系统的交界地带,具有较高的景观异质性,仅靠一种特征变量可能无法很好地进行湿地的准确提取;其二,若使用过多的特征变量参与其中将影响分类精度和效率。可见,多特征变量提取与优化以及进行有效组合将是今后湿地信息智能化提取的重点难点(张磊 等,2019)。特征选择(Feature Selection)通常情况下是将特征按照相关性准则排序,去掉冗余和不相关的特征(Guyon 和Elisseeff,2003),按评价标准不同,特征选择算法可分为过滤式(Filter)、封装式(Wrapper)和嵌入式 (Embedded) 3 种(Dash 和Liu,1997;Dash 等,2002;Saeys 等,2007;Kira 和Rendell,1992)。其中,Filter方法利用特征本身内在特性给出特征评价,特征评价越高表示该特征区分能力越强。这也是该方法最主要的特点:特征选择独立于分类学习算法。它不依赖某种分类器,因此简单,速度快,效率高。Yu和Liu(2003)以特征间的相关性为指导,用Filter 方法进行特征选择,证实了该方法进行特征选择的有效性;Wrapper 方法是将特定学习算法性能作为筛选子集的评估准则,每次筛选出的特征子集都需调用特定分类器进行精度验证。John 等(1994)提出当满足一定条件时,将获得具有较高分类性能的识别模型。该方法准确率较高,利于关键特征的识别,在算法速度上比Filter 方法慢,时间复杂度较高;Embedded 方法是一种基本的归纳方法,可以说是Wrapper 方法的延伸。Embedded 方法将特征选择过程嵌入到分类器的建造过程中,主要的例子是套索回归的问题以及决策树如 Breiman (2001)的 CART 算法。该方法计算效率高,但是特征中可能存在无关特征降低分类精度,在本次研究中未涉及。
针对已有的特征选择方法,有一些学者就其在湿地遥感分类方面进行了探索。如Mahdianpari等(2019)利用JM 距离定量地确定不同类型湿地的可分性,结合随机森林进行分类总体精度达到88.37%;孙艳丽等(2015) 利用光谱角距离(SAD)和欧氏距离(ED)双重判定提取不变特征点,提出了一种基于光谱角—欧氏距离的辐射归一化方法;郝玉峰等(2021)利用Relief-F 算法计算了52 个特征变量的权重,选出前20 个特征变量构成最优特征集参与湿地信息提取;Han等(2012)利用Z 检验方法测定区分两种植被类型的最佳纹理波段。以上提到的这些方法均属于Filter 方法;解淑毓等(2021)采用Wrapper 方法中典型的RFE 算法进行沼泽湿地分类中的变量优选,显著减少了数据冗余。Phan 等(2020)在其研究中指出GEE 提供的像元级重组规则主要包括最大值、最小值、平均值、中位数和百分位数等。
总体而言,目前湿地分类特征优选的研究多集中于通过多特征变量参与、单一特征优选方法来甄选最优特征集。不同特征的统计方式和不同特征优选方法对分类的影响尚未见相关研究报道,同时不同分类特征对高寒湿地类别分类的适用性也未见相关研究。鉴于此,本文基于Sentinel-2 影像数据,以首曲高寒湿地保护区为研究区域,利用随机森林分类算法,探讨数理统计特征和特征优选方法对优选的各种影响,并分析不同特征对高寒湿地类型分类的适用性。该研究将对提高高寒湿地遥感制图具有重要的参考价值。
2 研究区概况与数据源
2.1 研究区概况
甘肃黄河首曲国家级自然保护区(33°20′01″N—33°56′31″N,101°54′12″E—102°28′45″E)位于甘南藏族自治州玛曲县境内,属于内陆湿地和水域生态系统类型的自然保护区,是青藏高原典型的面积较大的高寒湿地(薛鹏飞 等,2021),也是全球保存状态最为完整和原始的湿地。首曲高寒湿地属于高原大陆性气候,年均气温1.1 ℃,年平均降水量615.5 mm,全年降雨150 d 左右(高斌斌,2008),给黄河贡献了黄河源区总径流量58.7%的水量,被称为“蓄水池”和“高原水塔”。
2.2 数据及预处理
2.2.1 数据源及预处理
近年来随着遥感技术的迅猛发展,越来越多的多源传感器涌现,其空间分辨率、时间分辨率、波段数量得到了巨大提升(郑阳 等,2017),为湿地的遥感分类提供了更多的选择。综合考虑影像分辨率、波段、可获得性等多因素,研究采用Sentinel-2影像。Sentinel-2属于中高空间分辨率遥感影像,携带高分辨率多光谱传感器MSI,可提供可见光、近红外到短波红外的13 个波段,是目前唯一在植被光谱的红边区域(670—760 m)设置3 个波段的卫星。红边波段数据及其衍生指数可区分C3、C4植被(Shoko和Mutanga,2017;Korhonen等,2017;常文涛 等,2020),极大促进了对植被生长信息及其健康状况的有效监测(张磊 等,2019)。本研究使用的Sentinel-2数据是用GEE平台“COPERNICUS/S2_SR”数据集中2020 年1 月1 日至2020年12月31日的影像数据,采用已经过辐射定标和几何校正的 Level-1C 产品,去除云覆盖率大于10% 的影像后得到34 景Sentinel-2 的无云影像。
2.2.2 样本数据
本研究以Global Lakes and Wetlands Database、Wetland Dataset of CAS 湿地制图产品公开数据集为参考数据集,在Google Earth 软件上开展样本集目视解译工作。最终取得样本点共480个,每个地类(分类体系见表1)各80个(图1)。
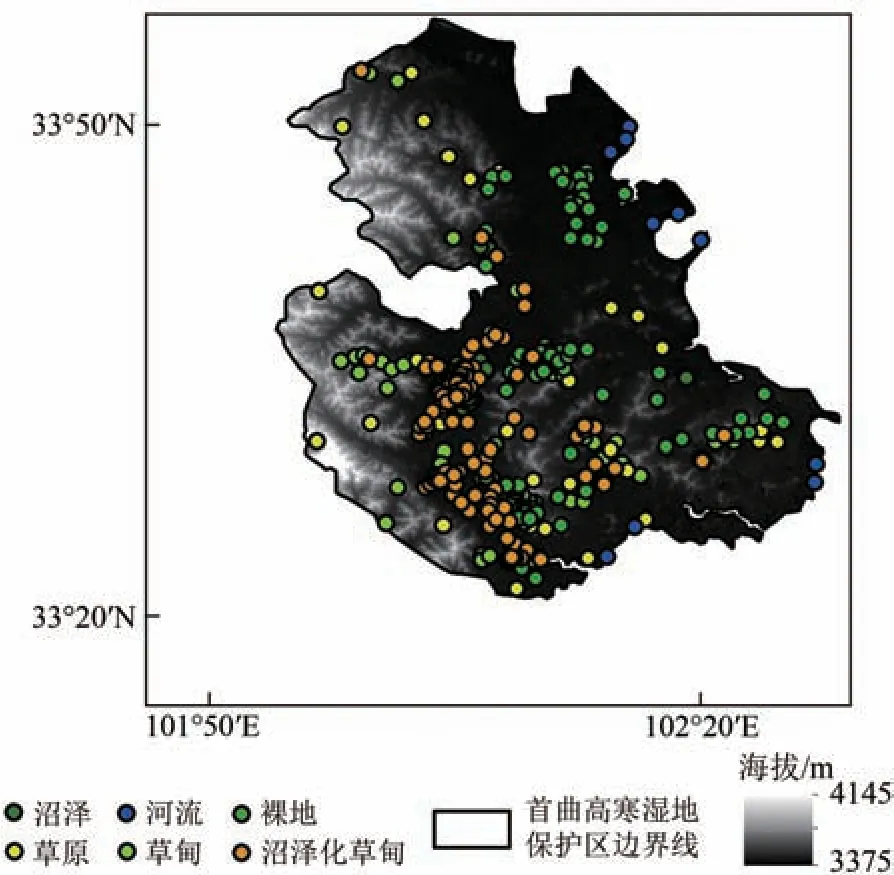
图1 黄河首曲国家级自然保护区样本点分布图Fig.1 Distribution map of sample points in the Yellow River Shouqu National Nature Reserve
2.3 分类体系方案
White 等(2020)指出,草甸沼泽对水位变化特别敏感,下垫面含水量一定程度上决定了湿地植被构成。本次不直接以湿地所在地域或湿地中细分植被为分类标准而是优先考虑造成湿地植被生长的起因——下垫面土壤含水量。随着土壤水分的增减,草原地区的草甸可能会发生演变,当水分增加时,可转变为沼泽;当水分减少时可转变为草原,沼泽化草甸是草甸与沼泽之间的过渡类型。沼泽、沼泽化草甸、草甸区域及边界的变化是监测湿地变化的重要指标,其变化可反映出当地的自然气候,生态环境的变化。因此本文土地覆被分类方案如表1所示。

表1 黄河首曲自然保护区土地覆被分类方案及影像示例Table 1 Land cover classification scheme and wetland corresponding image of Yellow River Shouqu Nature Reserve
3 研究技术流程和方法
3.1 技术流程
本文的技术路线图如下图2 所示。首先对Sentinel-2 影像数据进行预处理。基于样本计算32 种特征指数(3.2 节部分)的统计特征(均值、标准差、中值、最大值、最小值)后,分别利用JM 距 离、ED 距 离、SAD 距 离、RF-RFE 算 法、Relief-F 算法进行遴选,获取不同特征优选方法下的最优特征集。基于不同优选特征集利用随机森林进行湿地分类,依据特征优选方法及随机森林分类结果评价不同特征优选方案。
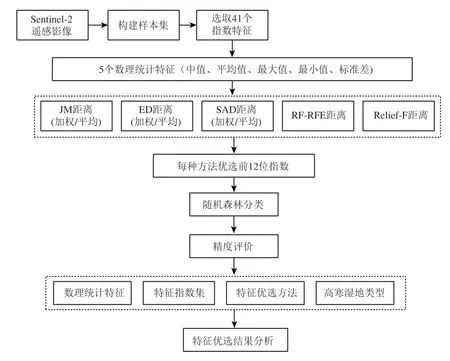
图2 特征优选技术流程图Fig.2 Feature selection technology flow chart
3.2 特征说明
本文选择了能够表征湿地植被、水文和土壤特征的指数进行分析,共选取了32 种特征集,包括光谱特征、植被指数、水体指数、红边指数(表2)。
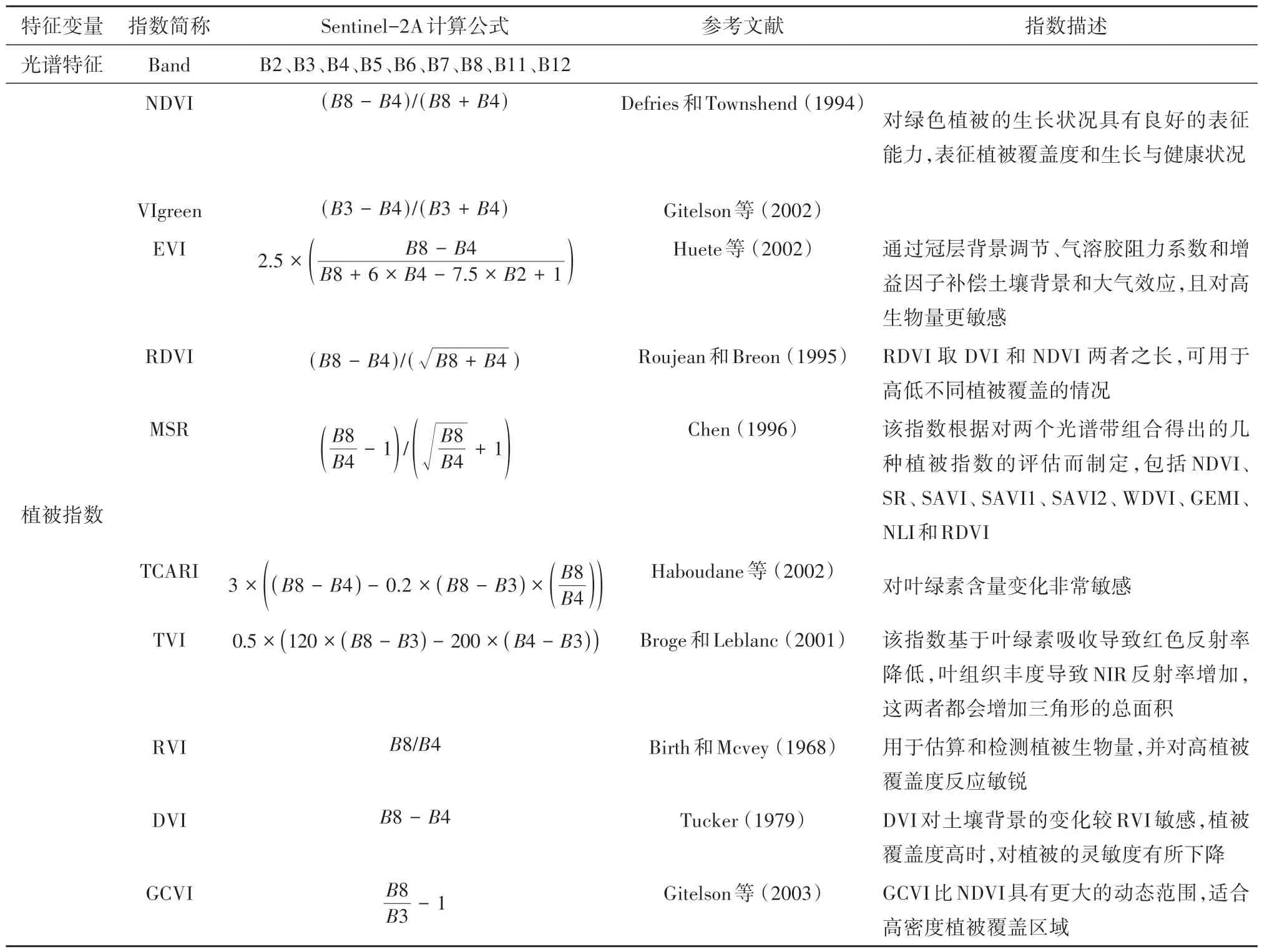
表2 Sentinel-2特征集概述Table 2 Sentinel-2 feature sets list
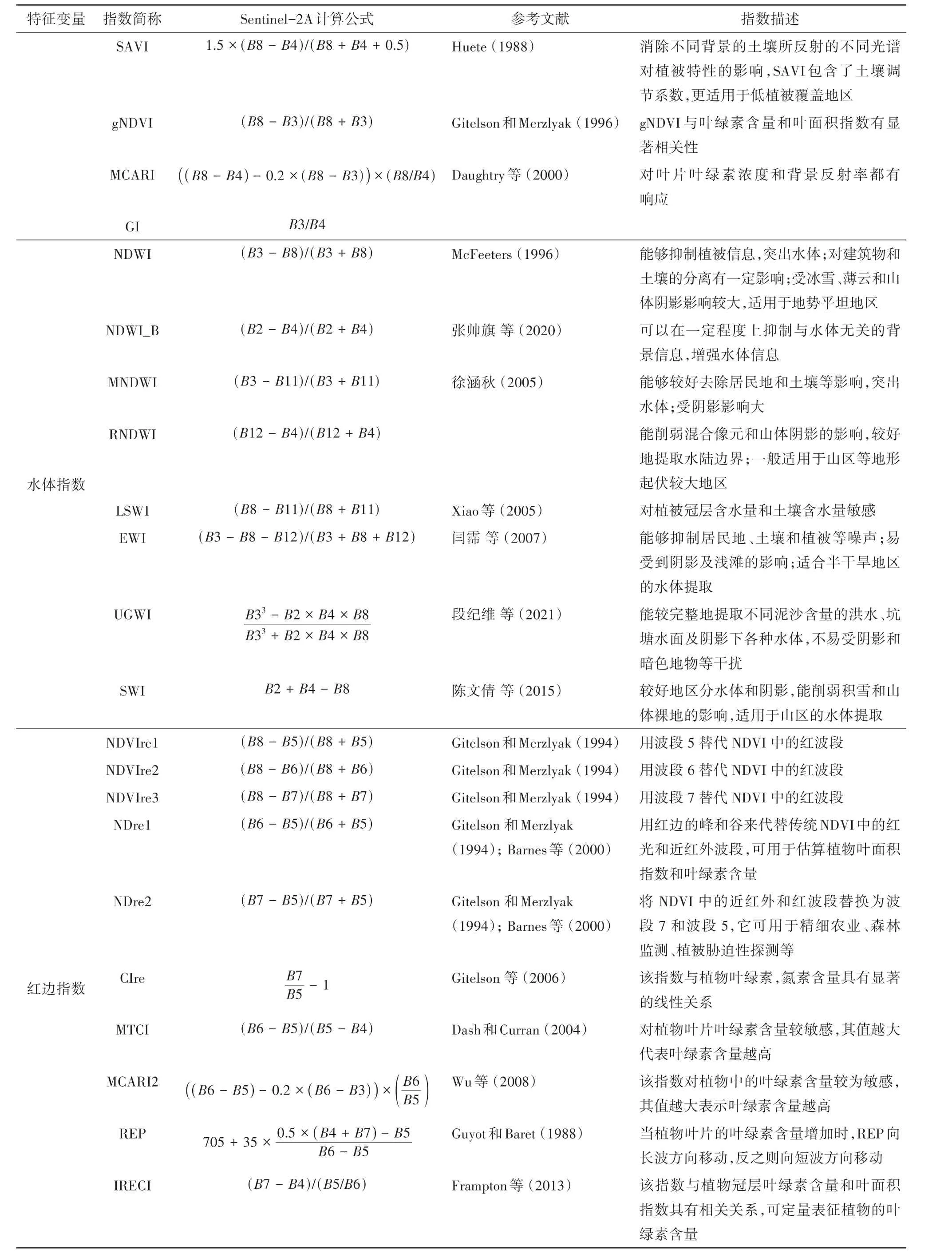
续表
3.3 特征优选方法
本文选择包括JM 距离、ED 距离、SAD 距离、Relief-F 算法、Z 检验在内的5 种Filter 方法,以及Wrapper方法的RFE算法进行本次实验。
3.3.1 Jeffries-Matusita距离
Jeffries-Matusita(JM)距离基于数据正态分布的假设得到不同类别的分离度,在模式识别和特征选择领域中较为广泛的使用(Dabboor 等,2014)。对训练样本集C(i,j= 1,2,…,C,i≠j)中两个待分地类wi和wj之间的JM 可分性准则定义如下
式中,dij是两个待分地类wi和wj之间的Bhattacharyya距离,定义为
式中,P(x/wi)和P(x/wj)是地类wi和wj的随机变量x的条件概率密度函数,通常假设多元正态分布,Bhattacharyya距离公式表达为
式中,mi和mj分别表示均值;Σi和Σj分别表示wi和wj的协方差矩阵,上标T表示矩阵的转置。
3.3.2 欧氏距离
欧氏距离ED(Euclidian Distance)是常见的相似性度量方法,其实质是通过一定的准则函数,求两个不同地类的像元对应的光谱向量之间的距离,此距离代表两像元的差异程度。两种地类的欧氏距离越大,代表两种待分地类间的可分性越强,反之,则表示可分性越弱(Carvalho Júnior等,2011)。由于欧氏距离算法默认每一个维度是相同权重,因此如果不同维度取值范围差别较大时需要先对其进行归一化,ED值计算公式为
式中,i表示波段,N表示波段总数,Xi和Yi分别表示两种待分地类样本集所对应的像元亮度值。
3.3.3 光谱角距离
光谱角距离SAD(Spectral Angle Distance)是常用的光谱分类方法。在光谱空间中,每个像元对应一个多维光谱向量,将两个向量之间的夹角定义为光谱角。光谱角越小,两光谱越相似,属于同类地物的可能性越大。由于光谱角距离不受光照、阴影等条件的影响,因此可以突出目标光谱形状特征。两种待分地类光谱的相似度越高,SAD 值越大,最大取值为1(Kruse 等,1993)。计算公式为
式中,i表示波段,N表示波段总数,Xi和Yi分别表示两种待分地类样本集所对应的像元亮度值。
3.3.4 Z检验方法
Z检验方法能够用来测定两种地物类型在不同特征变量间统计显著性差异。具体步骤为首先将特征变量分为植被指数、水体指数、红边指数3 组,再分别计算两种湿地类型在不同变量的Z值。Z统计表达式如下(Han等, 2012):
式中,u1和u2指的是两种待分地类的平均像素值;n1和n2指两种待分地类样本个数;s1和s2指两种待分地类像素值的标准差。Z值越大,待分地类在此特征上的差异就越显著。
以上4 种方法均用于判别两地类之间的可分性,为直观地表达指数对所有地类区分的能力,进行以下步骤:根据在样本解译时发现的沼泽、沼泽化草甸、草甸、草原4种类型越相邻越难区分的认识,采用加权(表3)对类型组合对应的JM值等进行处理,紧密相邻的两类权重赋4,次相邻的两类权重赋3,以此类推。在本次实验中同时采用了平均方法做补充。

表3 各类型组合权重分配Table 3 Weight distribution of various types of combinations
3.3.5 Relief-F算法
Relief-F 算法是基于分析邻近样本对类别的区分能力继而确定特征的权重,核心思想是一个优秀的特征应该使得同类的样本更加靠近,而使得不同类的样本更加分散,它是Relief 算法的拓展(刘吉超和王锋,2021)。其原理为假设数据集D中有N个类别的样本,对属于第n类中样本R,首先在同类即第n类的样本中寻找R的k个最近邻样本H,作为猜中近邻;在第n类之外的每个类中均找到R的k个最近邻样本M作为猜错近邻,最后定义的权重为
式中,diff(A,R1,R2)表示样本R1和样本R2在特征A上的差,其计算公式Mj( )C表示类别C中的第j个最近邻样本,p(C)为该类别的比例。
3.3.6 递归特征消除法
相比递归特征消除法RFE(Recursive feature elimination)(Elavarasan 等,2020),随机森林和RFE 相结合形成RF-RFE,其能够更加合理的决定最终特征子集的大小,避免了人为因素造成的影响。RF-RFE 算法用于特征选择(Wu 等,2017),是采用随机森林算法得到的重要性排序进行后向迭代删除特征重要度最小的特征,再将其余特征用随机森林算法重新评估后得到新的特征重要性排序,重复步骤,每次删掉特征重要性小的特征,最终得到分类的最优特征集。
3.4 分类方法
随机森林算法是由Breiman(2001)提出的一种统计学习理论,研究表明随机森林算法具有速度快,准确度高,稳定性好的优势。因此论文采用随机森林分类方法进行湿地信息分类。
3.5 精度分析
混淆矩阵是一种特定的矩阵用来呈现算法性能的可视化效果,主要通过比较分类结果与实际测量值之间的混淆程度进行精度评价。本文利用混淆矩阵,分别计算总体精度OA (Overall Accuracy)、Kappa系数、生产者精度PA(Producer’s Accuracy)、用户精度UA(User’s Accuracy)。其中总体精度和Kappa系数作为评价总体分类精度的指标,生产者精度和用户精度作为衡量各类的漏分和错分误差的指标。
4 结 果
为了方便叙述,论文用到的特征提取方法、数理统计方法和数据处理方式分别按表4编码进行论述。

表4 编号对照表Table 4 Number comparison table
4.1 指数的优选
根据JM 距离、SAD 距离、ED 距离、Relief-F算法和RF-RFE算法计算结果,逐一得出在水体指数、植被指数、红边指数中表现较好的指数。
4.1.1 JM距离
JM 距离取值范围为[0,2],JM 距离大于1.8表示样本间可分性较好,据此选出每类组合中JM值大于1.8 的指数,并对这些指数进行频次统计(图3(a))。植被指数在频次上大于水体指数和红边指数,其中最突出的是NDVI、VIgreen这两个指数;水体指数中频次数在前两位的指数为NDWI_B、NDWI;红边指数中NDVIre1、NDre1、NDre2指数出现频次较多。
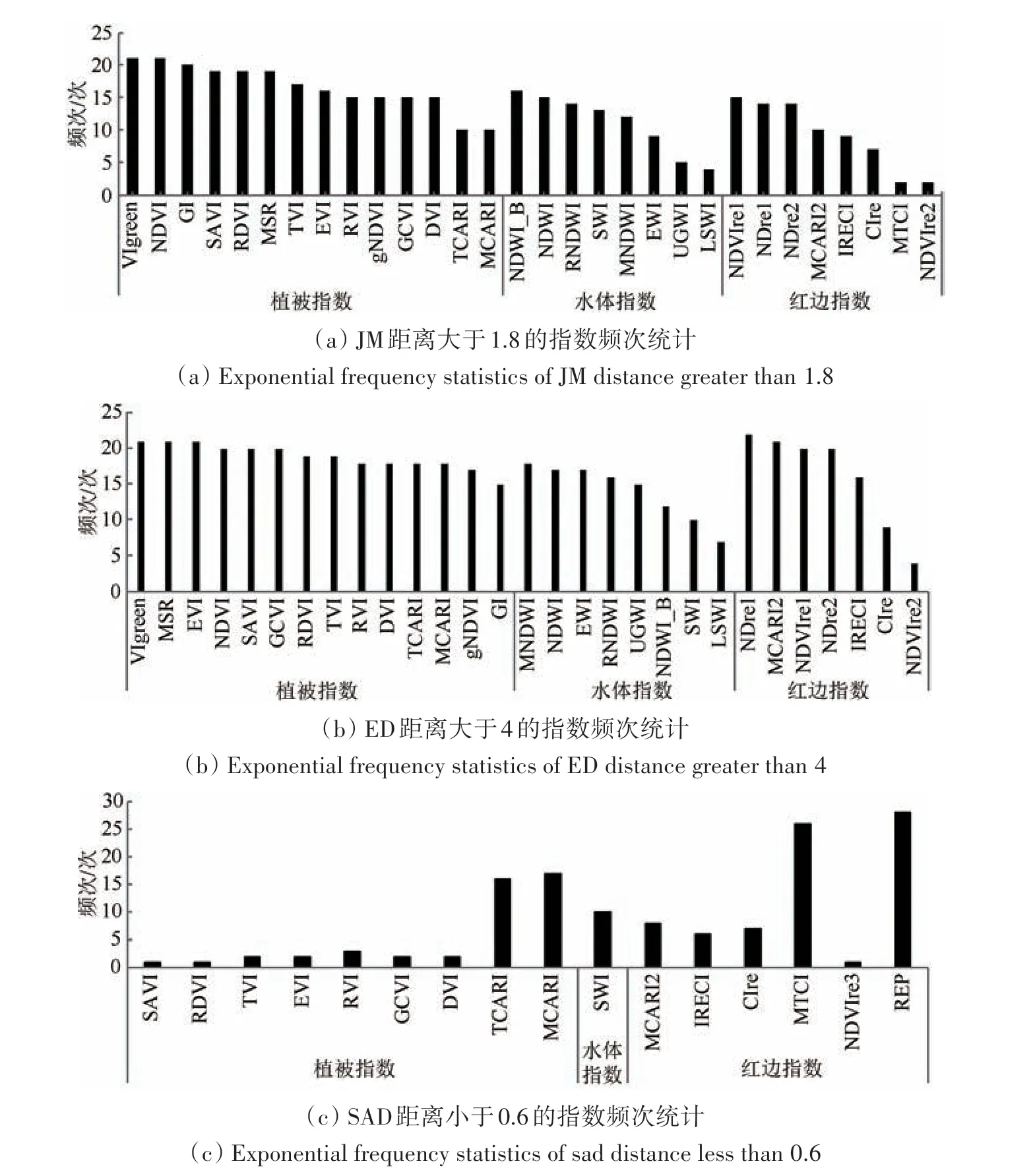
图3 JM距离、ED距离、SAD距离指数频次统计Fig.3 Frequency statistics of JM distance, ED distance and SAD distance index
采取加权和平均两种计算方式对数据进行处理,按重要性从大到小排序后,根据前12位指数。发现加权方式优选的指数TVI、DVI、SAVI 和以平均方式优选指数RDVI、SAVI,不论在哪一个数理统计特征中都有。当将两种方式所选的指数放在一起统计,优选至少出现5 次的指数作为JM 距离方法所选最优指数集,包括:SAVI、RDVI、TVI、DVI、MSR、EWI、NDWI、RNDWI、SWI、EVI、NDVI、gNDVI、RVI。基本包含了JM 距离大于1.8所选频次较高的植被指数和水体指数,但是红边特征指数没能入选。
4.1.2 ED距离
ED 值越大说明光谱距离越大,地类可分性越强。ED 值大于4 表示样本间可分性好,依此标准对优选的指数进行频次统计,指数出现频次如图3(b)所示。红边指数NDre1 出现次数最多。另外在红边指数中MCARI2、NDre2、NDVIre1 均表现出较好的区分能力。植被指数VIgreen、MSR、EVI 指数出现21 次,其余指数与之相比相差不大,植被指数在分类中指数数量最多。水体指数MNDWI、NDWI、EWI表现优异。
同样对15种类型组合的ED值进行加权与平均两种方式计算,得出加权方式优选的指数出现4次以上的有:EVI、RVI、SAVI、GCVI、RDVI;平均方式优选的指数出现4 次以上的是 GCVI、RDVI、 NDVI、 SAVI、 EVI、 MSR、 NDre1、NDre2、NDVIre1。综合两种方式所选的指数,同样以出现5 次以上的指数作为ED 距离方法优选指数 集,包 括GCVI、EVI、RDVI、SAVI、MSR、NDre1、NDre2、NDVIre1、gNDVI、RVI、NDVI、NDWI。所选水体指数只有NDWI一个。
4.1.3 SAD距离
光谱角检测是比较两类数据相似程度的光谱对比方法,当SAD 值越趋近于1,两类的光谱就越相似。以SAD 值小于0.6 的指数出现的频次进行统计,其指数出现频次统计如图3(c)所示,指数频次显示出较大差距,植被指数MCARI、TCARI不同于其他方法所选指数。进一步研究发现,TCARI 值是MCARI 值的3 倍,相比其他植被指数,对叶绿素浓度的变化十分敏感;红边指数REP 出现最多,其次是MTCI 指数。REP 指数可定量表征植物的叶绿素含量,而MTCI 指数同样对叶绿素含量敏感。SAD 距离所选植被指数和红边指数均对植物叶片含的叶绿素有较好的表征。水体指数仅选出SWI,该指数能较好区分水体和阴影。
对SAD 值分别进行加权和平均处理后发现,加权方式优选指数中出现4 次以上的指数为:TCARI、MCARI、MCARI2、IRECI、EWI、GCVI、NDWI、MNDWI;平均方式优选指数出现次数4 次以 上 的 为:TCARI、MCARI、MCARI2、IRECI、CIre、RVI、GCVI、LSWI、EVI。将两种方式所选指数共同考虑得到SAD 距离方法优选的指数集为TCARI、MCARI、MCARI2、IRECI、CIre、RVI、GCVI、EWI、MNDWI、EVI、LSWI、NDWI。
4.1.4 RF-RFE特征重要性排序
利用RF-RFE 算法优选得到的前12 位指数按重要性排序(表5),不同的数理统计特征出现很多重复的指数,一定程度上说明这些指数在重要性排序中表现较好。

表5 RF-RFE算法特征重要性前12位特征指数集排序Table 5 RF-RFE algorithm feature importance top twelve feature index set
其中,植被指数有RDVI、DVI、GI、VIgreen、TVI,水 体 指 数 有NDWI_B、MNDWI、RNDWI、EWI,红边指数有CIre。
4.1.5 Relief-F特征重要性排序
依据Relief-F 算法优选的指数按重要性排序(表6),其中,中值、平均值和标准差特征除了指数重要性排序不同外,选择的指数均相同,并且部分指数也出现在最大值和最小值特征中。指数特征中表现优异的指数分别为:水体指数中的RNDWI、MNDWI、EWI,植 被 指 数 有VIgreen、GI、 MSR、 GCVI、 RVI, 红 边 指 数 为NDre1、NDVIre1、NDre2,反映出这些指数对于区分地类较为重要。另外还发现重要性排序第一位的总是水体指数。

表6 Relief-F算法特征重要性前12位特征指数集排序Table 6 Relief-F algorithm feature importance top twelve feature index set
4.2 数理统计特征的优选
样本的空间分布具有随机性特征,虽然在湿地分类中通常采用平均值的方式对样本进行处理,但哪一种统计特征更能代表样本的属性特征,目前为止没有相关的研究。为此本文研究分别根据平均值、中值、最大值、最小值和标准差进行各类特征的计算,在此基础上评价对属性特征优选的影响。
4.2.1 JM距离
对表5 基于JM 距离优选的指数集分别采用随机森林分类器进行分类,得出中值和平均值特征总体精度和Kappa系数最高,均为86.70%、0.840,标准差特征的最低。依据JM 距离计算结果,指数数理统计特征的可分性能力可排序为平均值特征=中值特征>最小值特征>最大值特征>标准差特征。
4.2.2 ED距离
对ED 距离优选得到的指数集进行随机森林分类,分类精度结果如表7。
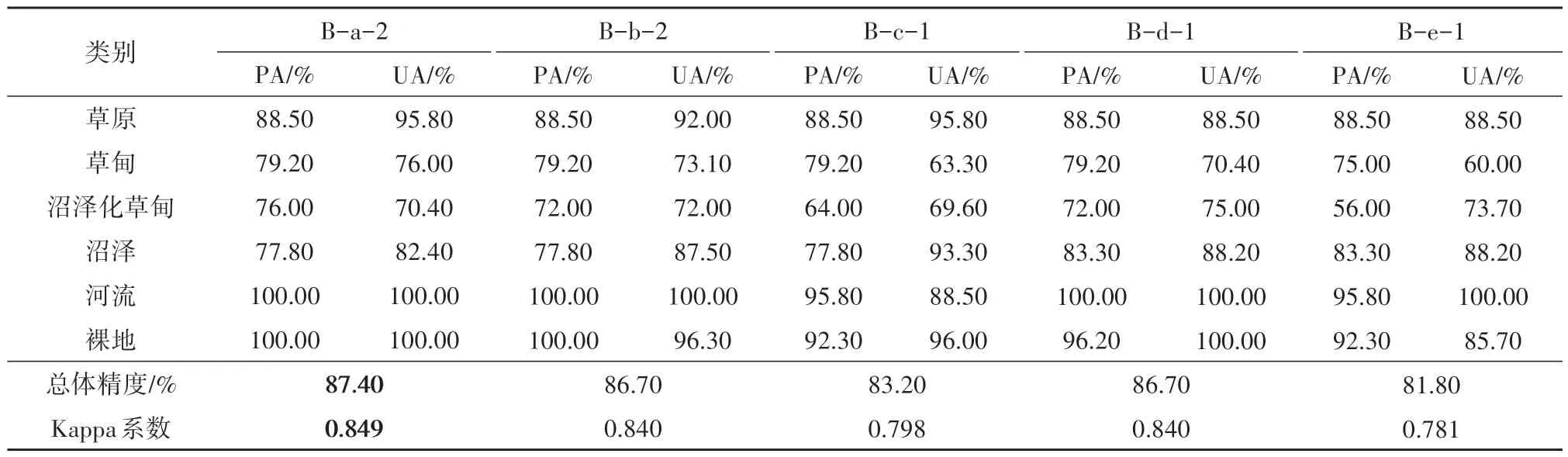
表7 ED算法分类精度统计Table 7 ED algorithm classification accuracy statistics
中值特征的总体精度与Kappa系数最高,达到87.40%、0.849;标准差特征的最小;平均值与最小值特征的相同。从ED 方法看,数理特征的可分性能力排序为:中值特征>平均值特征=最小值特征> 最大值特征>标准差特征。
4.2.3 SAD距离
对SAD 距离计算得到的指数集逐一进行随机森林分类,得出分类精度结果。将SAD 距离方法优选的指数组合利用随机森林分类方法,比较其精度后发现,虽然所选出的指数与前两种方法选出的指数有较大不同,但是平均值特征的总体精度依然能达到87.40%,Kappa 系数达0.848,SAD距离结果显示不同统计特征可分性能力大小排序为:中值特征>平均值特征>最大值特征=最小值特征>标准差特征。
4.2.4 RF-RFE特征重要性排序
根据RF-RFE 特征重要性排序选出指数集(表5)的对应分类结果:平均值特征的总体精度与Kappa 系数最高,达87.40%、0.848,而标准差特征的最低,中值和最小值的相同。依据总体精度和Kappa 系数的大小,可将其排序为平均值特征>中值特征=最小值特征>最大值特征>标准差特征。
4.2.5 Relief-F特征重要性排序
对Relief-F算法计算结果取前12位指数(表6)进行随机森林分类得到结果见表8。
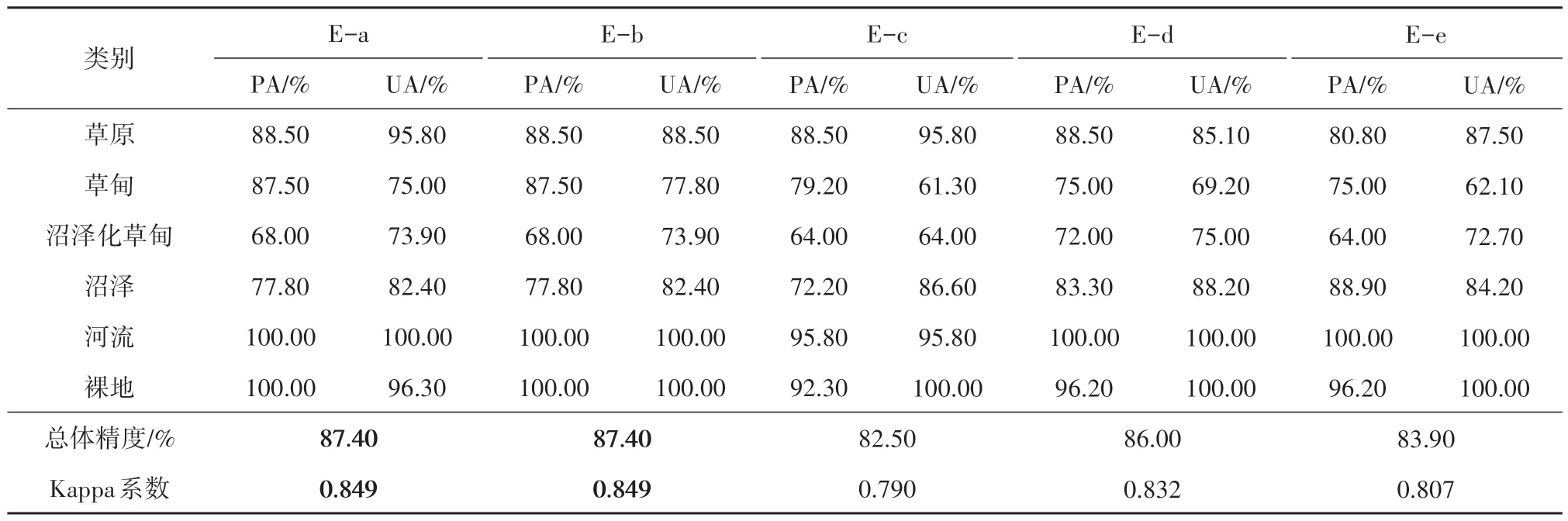
表8 Relief-F算法分类精度统计Table 8 Relief-F algorithm classification accuracy statistics
中值和平均值特征的总体精度和Kappa系数均为87.40%、0.849,最大值特征的最低,比中值和平均值低了4.90%、0.059。以数理统计特征的维度,依据总体特征和Kappa系数的大小,可将其排序为中值特征=平均值特征>最小值特征>标准差特征>最大值特征。
总体而言,湿地信息提取最适合的数理统计特征为中值和平均值。
4.3 高寒湿地类型的区分能力
本文将沼泽、沼泽化草甸、草甸、河流、草原和裸地等土地覆被类型分别两两组合分析其可分性,共有15组类型组合。
4.3.1 河流、裸地
河流与裸地因其截然不同的形状特征、下垫面环境,是所有类别中分类精度最高的,其制图精度和用户精度可达到100%。另外能用于区分河流或裸地与其他类别的指数数目很多。
4.3.2 沼泽、沼泽化草甸、草甸、草原
草原的制图精度和用户精度的中位数是88.5%,沼泽化草甸与草甸的制图与用户精度主要集中在72%,相比较低。沼泽相比于沼泽化草甸与草甸两类湿地过渡类型来说,制图精度和用户精度均要高,大部分情况集中在83.3%。沼泽化草甸与沼泽、草原与草甸、草甸与沼泽化草甸这3种类型组合难以区分,因此,结合JM 距离、ED 距离、SAD 距离计算结果,尝试找出易于区分这3种组合类型的指数。具体做法如下:依据JM 距离、ED 距离、SAD 距离指数的中值特征计算结果,选出沼泽化草甸与沼泽、草原与草甸、草甸与沼泽化草甸类型组合前10%的指数,共计25 个,根据指数出现的频次排序,选出前10%的指数为:MCARI2、 NDWI、 DVI、 EVI、 EWI、 IRECI、MCARI、TCARI、UGWI。
5 讨 论
5.1 分类指数集的构建
由于每种方法优选的指数不完全一致,为确定对于湿地分类最优的特征,我们分别取Filter 方法(JM 距离、ED 距离、SAD 距离、Relief-F 算法)和Wrapper方法(RF-RFE算法)计算结果中精度最高的指数集合,然后以这5个指数集合为基础,统计各个指数在5个集合中出现的次数,以众数为指标作为最终优选的指数,结果包括了11个指数。分别为 植 被 指 数RDVI、NDVI、MSR、RVI、VIgreen,水体指数RNDWI、NDWI、NDWI_B、MNDWI、EWI和红边指数CIre。
5.2 数理统计特征的选择
对优选出的11 个指数,分别对5 个统计特征进行随机森林分类,得到的总体精度和Kappa系数如表9。
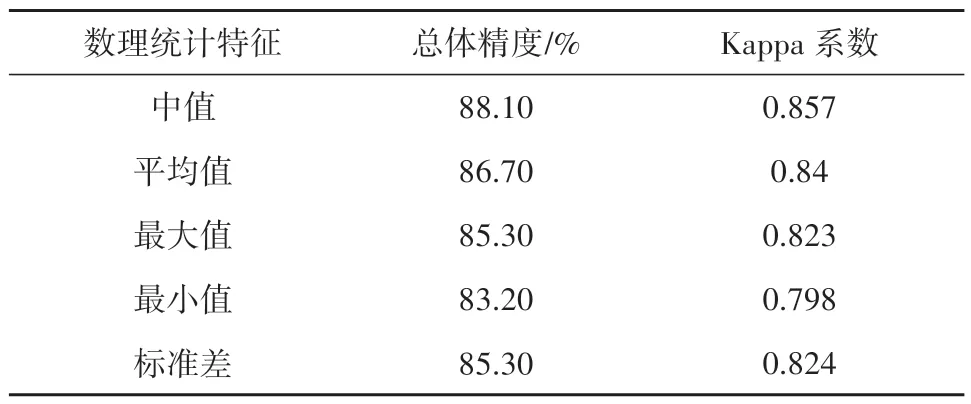
表9 不同数理统计特征下分类精度统计Table 9 Classification accuracy statistics under different mathematical statistics characteristics
可以看出,中值特征的总体精度和Kappa系数均是最高的,其次是平均值特征,和不同方法分别进行评价的结果一致(4.2 节部分)。说明基于样本的中值或平均值可以代表样本的属性。
5.3 特征优选方法的比较
由于中值特征的精度以及分类的效果最好,因此用中值特征计算的精度及混淆矩阵来比较5种特优选的方法。可以发现Filter方法的Relief-F算法与ED距离算法的总体精度和Kappa系数均为87.40%、0.849,JM 距离与SAD 距离得到的总体精度和用户精度均为86.70%、0.840,Wrapper 方法的RFE-RF算法的总体精度和用户精度为86.00%、0.832,由此可知,Filter 方法的Relief-F 与ED 距离算法在本次高寒湿地分类指数特征研究中略胜一筹。
5.4 指数特征的重要性排序
为了能够更好地查看水体指数特征、植被指数特征与红边指数特征对湿地分类的贡献,利用Filter 方法的Z检验方法对样本点的指数特征进行定量分析。依据5.2 节的结果,最终选择指数的中值特征进行计算。
图4表明了不同类型的指数特征对湿地的可分离度,Z值越大,两种湿地类型在此指数上的差异度越明显。通过观察决定以Z值大于37 为界限进行统计,可得水体指数特征Z值最大为60.3,大于37 的类型组合有8 个;植被指数特征Z值最大为51.9,大于37 的类型组合有5 个;红边指数特征Z值最大为39.8,大于37 的类型组合有3 个。由此可知,不同指数特征的特征重要性程度排序为:水体指数特征>植被指数特征>红边指数特征。
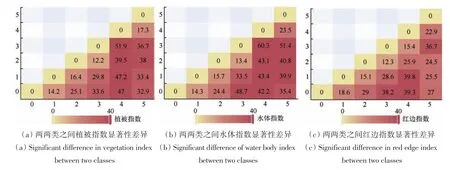
图4 两两类之间的植被指数、水体指数和红边指数的显著性差异(0-草原、1-草甸、2-沼泽化草甸、3-沼泽、4-河流、5-裸地)Fig.4 Significant differences in vegetation index, water body index and red edge index between the two classes(0-grassland, 1-meadow, 2-swamped meadow, 3-swamp, 4-river, 5-bare land)
5.5 分类特征的不确定性
沼泽化草甸与沼泽、草甸与沼泽化草甸、草原与草甸这3 种类型组合的可分性较差,而这3 类组合的分类情况决定着湿地分类结果的好坏。从类型角度来看,草原、草甸、沼泽化草甸、沼泽邻近两类型无论在植被长势还是下垫面水分含量都存在渐变的过程,邻近两类型之间没有明显的地缘间隙。因此,在用到的分类特征时是易混淆的。JM 距离、ED 距离、SAD 距离计算结果也证明了这一点,后续需要深入研究上述类型的分类技术。
此外,SAD 距离方法所得指数集的随机森林分类精度与JM 距离方法一样能达到86.70%,但是两种方法所选指数集却大相径庭,接下来可以从指数的物理机理、波段组合方式方面进一步研究。
6 结 论
本文基于Sentinel-2 遥感影像,以首曲高寒湿地为研究区,通过Filter 方法(JM 距离、ED 距离、SAD 距离、Relief-F 算法)、Wrapper 方法(RFRFE 算法)共同对植被指数特征、水体指数特征、红边指数特征进行分析,并借助随机森林分类方法计算了所选指数集的精度和混淆矩阵,最后利用了Z 检验方法对3 种指数特征进行了定量比较,主要得到以下结论:
(1)特征优选方法:在所选的Filter和Wrapper方法中,Filter 方法的ED 距离与Relief-F 算法得出的指数集其分类精度高于其他方法,精度最大相差1.4%。说明 ED 距离与Relief-F 算法在本次湿地分类研究中具有最好结果。其原因是Wrapper方法在特征选择中过分依赖聚类参数,缺乏合适的评价准则评估不同特征子空间的特征子集,所以采用Filter方法相对取得了较好的结果。
(2) 湿地分类优选指数:植被指数RDVI、NDVI、MSR、RVI、VIgreen,水体指数RNDWI、NDWI、NDWI_B、MNDWI、EWI,红边指数CIre。具体来说,水体指数在湿地分类中占重要地位,尤其是NDWI、MNDWI、NDWI_B,植被指数在所选总指数中所占数量最多,其中NDVI 指数尤为重要,红边指数虽没有前两类指数表现突出但是也不可或缺,表现好的指数有NDVIre1、NDre1、NDre2、CIre。通过Z检验对指数特征的定量分析,可得出水体指数特征的重要性程度大于植被指数特征,也大于红边指数特征。
(3)统计特征评价结果:基于中值的总体精度最高,达到88.10%。
(4)最易区分的是河流与裸地,其次为沼泽与草原,沼泽化草甸与草甸较为难分。沼泽化草甸与沼泽、草原与草甸、草甸与沼泽化草甸这3种类型组合较难区分,可尝试如下指数进行分类:MCARI2、NDWI、DVI、EVI、EWI、IRECI、MCARI、TCARI、UGWI。
猜你喜欢
儿童故事画报·自然探秘(2024年5期)2024-05-22 22:26:58
疯狂英语·新读写(2023年4期)2023-05-10 10:44:22
青海草业(2022年2期)2022-07-23 09:34:58
活力(2019年21期)2019-04-01 12:17:10
小学生导刊(2018年34期)2018-12-18 01:53:14
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
山东青年(2016年3期)2016-02-28 14:25:55
西藏科技(2015年1期)2015-09-26 12:09:29
科技创新与应用(2015年28期)2015-05-30 20:03:40
