
基于关键字的大屏动态文字识别软件设计研究
2023-05-17 03:16:18肖浩宇耿红玉吕怡晗康云丽窦育民
电子技术与软件工程 2023年5期
肖浩宇 耿红玉 吕怡晗 康云丽 窦育民
(新乡医学院 管理学院 河南省新乡市 453003)
车站、医院等公共场所为了保证人员的快速流动和业务的正常开展,常常使用大型电子屏幕作为信息公示栏显示车辆入站、挂号情况等信息,有时由于待公示的信息条目过多需要滚动或翻页显示,此时信息需求者需要仔细浏览电子屏幕,等待所有信息轮播结束才有可能找到自己需要的目标信息。信息需求者受视力、光线、位置等因素的影响,可能难以快速有效地寻找到自己所需要的目标信息,这种情况给出行人员、就诊人员办理业务带来一定的困难,同时增加了公共场所的负担。
随着文字识别技术的快速发展,与之相关的应用为人们的日常生活提供了极大的便利。目前多数文字识别应用软件主要运用OCR(optical character recognition)光学字符识别技术,它是利用光学技术和计算机技术通过检测字符每个像素的暗、亮模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程[1],可以广泛应用于车牌识别、文字识别等生活场景。但大部分文字识别软件仅支持对图片文件进行文字识别,不能满足部分用户的需求。如果用户想要提取视频中的文字内容,需要手动对视频内容进行截取,由于受视频帧率的影响,可能会浪费大量的时间且不能获得很好的效果。通过设计一款基于关键字的大屏动态文字识别软件,实现以视频作为源文件进行文字识别和检索的功能,以关键字作为检索对象,帮助用户在车站、医院等公共场所的滚动大屏幕上快速获取自己所需要的信息。
1 软件总体设计
1.1 模块设计
本软件主要实现的功能是用户输入需要查找的关键字,通过直接拍摄或上传视频文件的方式提交视频,系统自动筛选符合条件的视频帧进行文字识别,在包含关键字的视频图像上对关键字进行标记,将标记结果反馈给用户,同时支持用户对关键字使用备忘录、闹钟等附加功能。软件主要包括登录模块、注册模块、关键字检索模块、视频实时获取模块、附加功能模块[2]。图1 为该软件功能模块结构图。
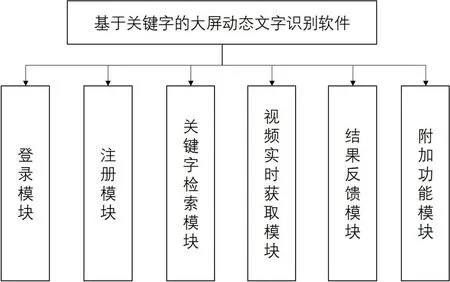
图1: 功能模块结构图
(1)登录模块:用户通过输入手机号和密码进行登录,系统确认信息后进入功能页面,新用户可以通过点击登录下方的提示进入注册页面进行账号注册。
(2)注册模块:用户输入昵称、手机号、密码等账号基本信息,填写正确的图片验证码信息和短信验证码信息后点击注册即可完成注册。通过图片验证码和短信验证码两种验证可以提高系统的安全性。如果已有账号,可以点击提示返回登录页面。
(3)关键字检索模块:用户在功能页面点击搜索框输入自己需要检索的关键字,系统对提取后的视频帧进行文字识别后,会将搜索框中的文本内容作为关键字进行对用户上传的视频检索。
(4)视频实时获取模块:用户在功能页面点击“拍摄视频”可以进行实时摄像,系统将同步获取用户的摄像内容。系统会调用相机功能进行拍摄,根据用户实时上传的视频作为源文件进行文字识别和关键字检索[3],便于用户快速进行拍摄;对于本机存储的视频可以点击“上传视频”完成视频文件上传。
(5)结果反馈模块:系统完成识别和检索后会自动进入结果反馈模块,对在视频中检索到的关键字进行特殊标记,检索结果将以图片的形式出现在结果反馈页面,便于用户快速查找自己的目标信息,降低因文字识别误差带来的影响。
(6)附加功能模块:用户根据结果反馈的内容,可以点击“闹钟”或“备忘录”,通过快捷方式使用本机闹钟或备忘录功能,结合生活场景提高软件可用性。
1.2 视频关键字检索流程设计
实现对视频进行关键字检索功能需要进行登录、确认关键字、获取视频、识别与检索、反馈结果等步骤,设计流程如下:用户在使用视频关键字检索功能时,系统首先会对其身份进行核对,判断是否登录,如果未登录则需要进行账号注册,注册完成后可重新进入登录页面。用户登录后可以输入自己想要检索的关键字,系统对关键字文本进行确认,然后获取用户实时摄像或上传的视频文件,筛选出符合条件的视频帧后进行文字识别,对识别出的文本进行关键字检索,识别与检索步骤完成后软件会反馈检索结果,用户在查看结果反馈后可以选择结束或者使用附加功能。图2 为视频关键字检索流程图。

图2: 视频关键字检索流程图
2 软件实现
2.1 功能实现
实现基于视频检索的文字识别功能主要需要进行视频帧提取、图像预处理、文字识别与定位、关键字匹配、关键字标记这5 个步骤。图3 为功能实现主要步骤流程。
(1)视频帧提取:该步骤主要由将视频文件转换为视频帧和关键帧的提取两部分内容组成。第一部分将视频文件转换为等帧间距的视频帧,具体实现方法是通过导入opencv 下的glob 和os 库,使用库中videoCapture 函数读取视频帧,确定存储视频帧的帧间隔,利用循环存储提取到的视频帧。第二部分是提取关键帧,由于不同视频文件的不确定性,用提前确定好帧间隔的方式提取到的图片很可能重复,如果对提取到的每一帧视频内容都进行检索与识别,则会大大降低提取和识别的效率,因此需要对提取到的视频帧进行筛选以获取关键帧。主要采用帧间差分法实现视频关键帧提取,通过对视频图像序列中相邻两帧作差分运算,得到两帧图像亮度差的绝对值,判断它是否大于阈值来分析视频或图像序列的运动特性。如果大于阈值则说明此帧与前一帧画面内容产生了一定的变化,可以作为关键帧进行提取[4]。
(2)图像预处理:主要包括对图像进行灰度化和二值化处理。灰度化有多种方法,这里选用加权平均值灰度化方法。加权平均值灰度化方法将彩色图像中像素的R 分量、G 分量和B 分量3 个数值的加权平均值作为灰度图的灰度值。首先对彩色的图像进行灰度处理,对每个像素点进行颜色的RGB 值(0-255 之间)的转换,使用Y=0.299R+0.587G+0.114B 公式建立灰度图。然后采用迭代法对图像进行二值化处理,首先确定图像分割阈值,选择一个近似阈值作为估计值的初始值,然后进行分割,产生子图像,并根据子图像的特性来选取新的阈值,再利用新的阈值分割图像,经过几次循环,使得图像成黑白两种取值,去除图像中多余的数据,仅保留我们所需要的图像信息[5]。图5 为灰度处理后的车站屏幕。
(3)文字识别与定位:将处理后的图像输入百度智能云提供的通用文字识别接口,识别出相应视频帧上的文字并输出文字所对应的坐标。文字识别引擎在识别过程中主要包括“图片布局分析”和“字符分割与识别”两个步骤,图片布局分析是OCR 系统识别图像文字首先要执行的步骤,它的意义在于通过特定的方式对待识别的图像进行布局分析,截取修正包含完整的文字信息区域, 对原图上的所有文字进行识别,区分图像中的文字区域和其他非文字区域,以提高有效性。来达到过滤掉图像中的非文字部分。字符分割与识别首先对文字进行粗略的分割,然后再使用精细分割精准分割和纠正错误[5]。具体的原理是:按比例场景通过清楚的空格和模糊间隔来分割,根据间隙的大小进行粗略的分割,分割出大部分的字符,找出文本线。根据识别出来的字符,进行粘连字符的分割,同时把错误分割的字符合并,再使用精细分割将字符同字符库对比来判断单个字符,完成字符的精细切分,使文字识别更加准确。
(4)关键字匹配:采用RK(Rabin-karp)算法,对待匹配串和文本中的子字符串分别进行哈希运算,计算出对应的数值,对得出的数值进行比对,若数值相等,则待匹配串和文本中的字符串匹配。由于可能会存在哈希冲突的情况,在匹配到相同数值的子串后,还需要进行字符比较,通过此方法把大量的匹配交给了数值比较,而计算哈希值和哈希值的比较都是很高效的。此算法的逻辑主要是选取主串中指定位置作为匹配的起点,将子串起点与该起点对比,比对成功后起点后移一位,子串的起点同样后移一位继续比较,直到将子串与主串中全部匹配。RK(Rabin-karp)算法不直接进行字符比较,而是先进行数值比较,通过此方法提高效率。PK算法能够处理多模式匹配,而且在实际应用中复杂度为O(m+n)(其中n 为文本长度,m 为字符串长度),暴力字符串匹配算法的复杂度O(mn),所以PK 算法要快于暴力字符匹配算法[6]。
(5)关键字标记:为了使用户能够清晰直观的查看检索结果,需要将符合检索条件的结果框选出来。具体方法如下:读取匹配成功的关键字在图像中的坐标,将该坐标代入rectangle 函数,实现关键字标记。Rectangle(‘Position’,pos)创建一个二维矩形,pos是一个向量[x y w h],其中(x,y)绘制矩形的左上角位置,从此点下绘制宽w 高h 的矩形。图4 为关键字标记结果。
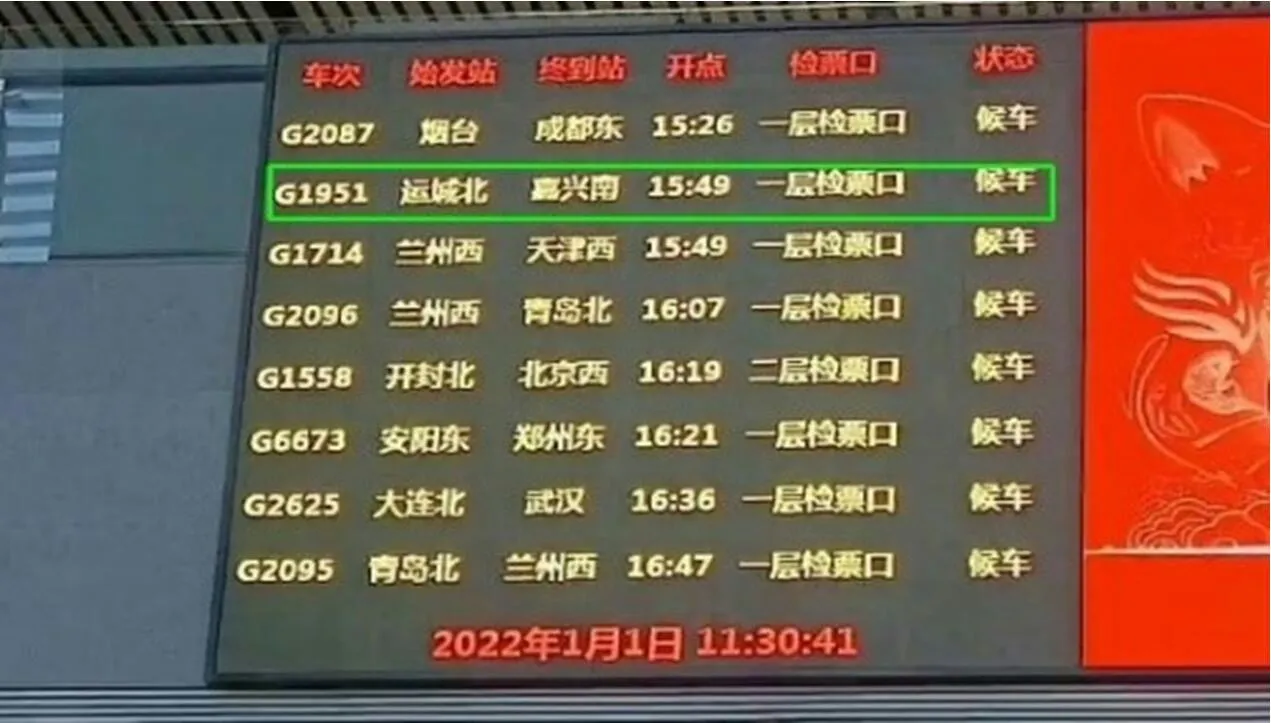
图4: 关键字标记结果
2.2 软件界面实现
使用“iVX 开发平台”完成“快拍”APP 的设计与开发。“iVX”是面向前后台应用开发的可视化无代码编程语言,通过“原子组件”加“逻辑编排”生成中间代码,基于云开发模式完成应用的开发、测试、发布和运维。“快拍”APP 的界面设计风格简约,主要包括登录界面、注册界面、功能界面、结果界面四个部分[7],在功能界面能够实现对视频内容进行关键字检索。
(1)登录界面:用户需要输入手机号和密码进行登录,当用户输入手机号和密码登录时,系统会将用户输入的信息与数据库中的信息进行比对,系统前端将用户名、密码发送到服务器,服务器进行常规的判断,判断用户名、密码长度是否满足,用户名是否重复等条件,若信息匹配成功则前台跳转至用户页面,否则条件不通过直接返回对应错误码给到前端。将提示用户“输入的信息错误,请输入正确的信息”,用户需要根据提示的信息重新输入正确的手机号或密码。如果没有账号,可以点击下方提示进入注册页面。如图5 所示。
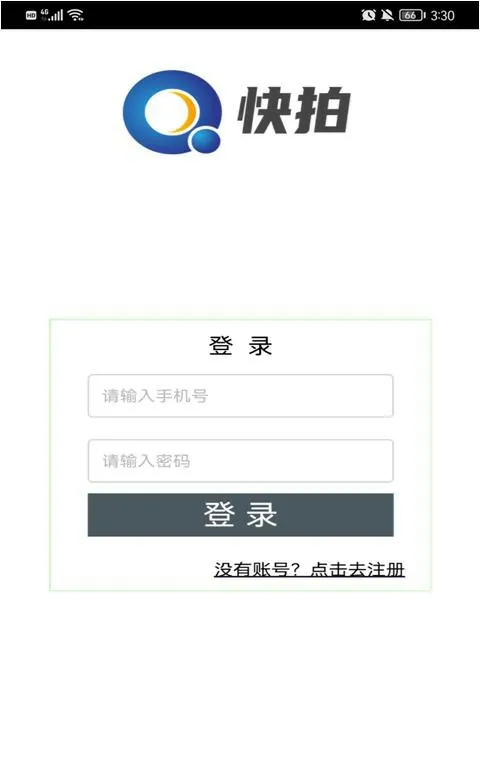
图5: 登录界面
(2)注册界面:用户在首次使用该软件时,需要注册账号,第一次注册后,后续使用该软件登录时不用重新注册账号,用户在注册页面需要输入手机号、自己设置的昵称和密码,并输入正确的图片验证码信息,系统确认后会向用户手机发送短信验证码,用户输入正确的短信验证码后点击注册,即可完成账号注册。如果已有账号,可以点击下方提示重新进入登录页面。如图6所示。
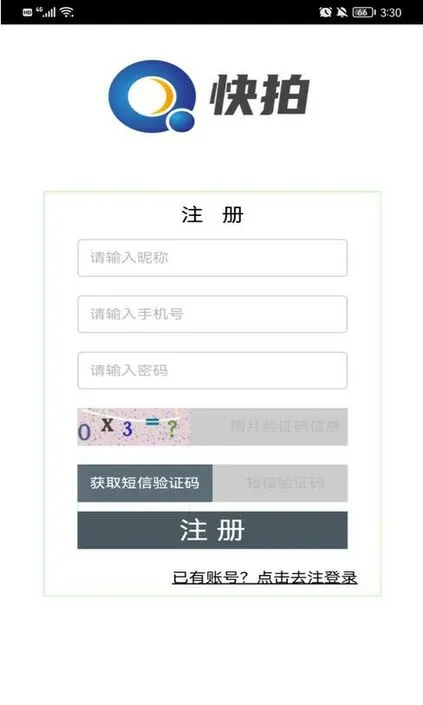
图6: 注册界面
(3)功能界面:用户需要在搜索框内输入自己想要检索的关键字,如车次、终点站等信息。可通过点击“拍摄视频”按钮进行实时摄像,也可通过点击“上传视频”按钮从本地文件中选取想要检索的视频。视频上传完成后点击“确定”即可根据用户输入信息的关键字开始检索,通过输入的关键字与视频中信息进行匹配,匹配成功后,系统就会框选匹配的关键字信息,点击“返回”则会返回至登录页面。功能界面是本软件的核心界面,通过本界面可以调用本机文件和相机功能,在对视频文件进行处理时需要调用外部接口,实现对视频帧中的文字内容进行识别,从而对用户输入的关键字进行检索。如图7 所示。
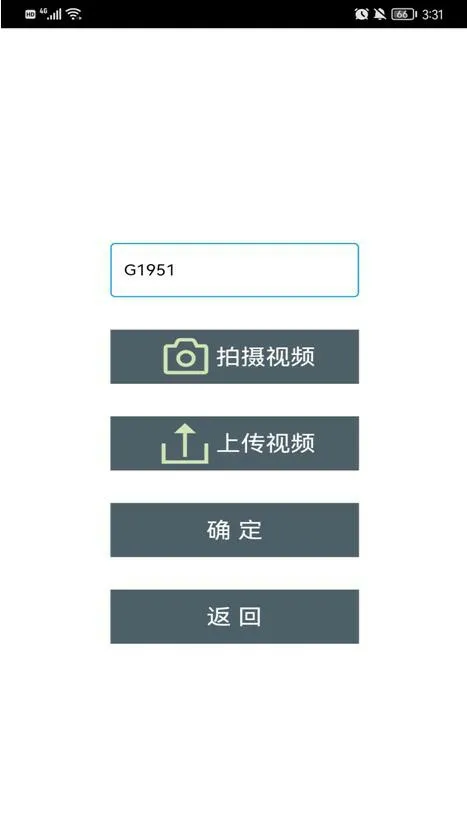
图7: 功能界面
(4)结果界面:用户可在结果界面上方查看检索结果,检索结果以关键字所在的视频帧图像作为主体,对关键字所在的部分进行框取,将框取结果反馈给用户,通过这种方式便于用户获取更多的信息内容,同时降低文字识别错误带来的影响。根据结果情况可以点击“重新检索”,返回功能页面重新进行检索设置,也可点击“备忘录”或“闹钟”调用本机备忘录或闹钟功能。点击“结束”则关闭应用。如图8 所示。

图8: 结果界面
3 结束语
本文首先对基于关键字的大屏动态文字识别软件基本模块和视频关键字检索流程进行设计,确定软件需要实现的功能与步骤。然后对实现软件功能的关键步骤进行分析与设计,采用帧间差分法对用户上传的视频文件实现关键帧提取,对提取后的视频帧图像采用加权平均值灰度化方法和迭代法进行预处理,通过接入百度智能云提供的通用文字识别接口实现文字内容的识别与定位,采用PK(Rabin-karp)算法对关键字字符串进行匹配,然后使用rectangle 函数对匹配出的关键字进行标记,最后通过“iVX 开发平台”进行软件UI 设计,完成软件的设计与开发。该软件界面简洁、操作简单,能够满足用户对视频文件进行文字识别和关键字检索的需求,帮助用户快速找到自己需要的文字内容,可以应用到车站、医院等生活场景,给人们的日常生活带来一定的便利。
猜你喜欢
大灰狼画报·益智版(2024年3期)2024-12-09 00:00:00
保健医苑(2022年1期)2022-08-30 08:39:14
华人时刊(2022年1期)2022-04-26 13:39:28
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
专利代理(2016年1期)2016-05-17 06:14:36
智能计算机与应用(2011年4期)2012-05-15 02:24:18
电脑爱好者(2011年11期)2011-06-22 08:20:18
河北软件职业技术学院学报(2010年3期)2010-06-06 07:18:42
质量与标准化(2010年5期)2010-05-03 04:15:40
