
一种基于图像patches分割的自监督生成对抗模型
2023-05-11 08:58陈才扣
软件导刊 2023年4期
陈才扣,高 俊
(扬州大学 信息工程学院,江苏 扬州 225127)
0 引言
近年来,一种新型生成模型的提出引起了广泛关注,以Goodfellow 等[1]2014 年提出的生成对抗模型(Generative Adversarial Nets,GAN)为代表,强调生成器(Generator)与判别器(Discriminator)两者之间进行博弈,最终输出高精度的图像。迄今为止,生成对抗网络已经在图像生成、语音合成、目标检测、风格迁移等领域发挥作用。在博弈过程中需要同步优化生成器和判别器,期望达到纳什均衡,但在实际过程中,难以要求判别器与生成器同时达到收敛,最终导致生成对抗模型的稳定性不足。在训练过程中,生成器更偏向于生成单一样本,而判别器倾向于识别单一样本,导致生成对抗模型出现模式坍塌(Mode collapse)问题,使生成的图片不具有多样性。
为了解决生成对抗模型的稳定性和多样性问题,学者们在原始生成对抗模型上进行多方面改进[2-6]。其中,最具有代表性的是Wasserstein GAN,首先从理论上解释了GAN 训练不稳定的原因,原模型中采用的JS 散度在一定情况下会产生梯度消失问题,因而选择Wasserstein 距离来度量真实图像分布与生成图像分布之间的距离。针对模式坍塌问题,Mescheder 等[7]观察到GANs 很难通过梯度下降的优化方式训练到收敛,而WGAN 中引入梯度惩罚项可很好地缓解模式坍塌问题。
在非稳态的环境中,神经网络模型的遗忘能力会随着网络深度的加深而加剧[8]。如果鉴别器忘记了先前的分类边界,可能会造成训练不稳定或重复训练等问题。在复杂数据集下,这些问题变得更加突出。可以说,用监督信息增强鉴别器可鼓励其学习更稳定的表征,防止灾难性的遗忘。将一种基于角度旋转的自监督模型应用于生成对抗模型中[9],用前置任务从大规模的无监督数据中挖掘自身的监督信息,将样本图像旋转0°、90°、180°、270°作为伪标签,建立一个平稳的对抗学习环境来抵抗模式坍塌问题,以提高图像的特征学习能力。
但是,基于旋转角度自监督的方式是在整体上进行旋转对比,只考虑到样本的全局信息,并不能注意到图片的局部信息,模型细化能力差,生成的图片不够清晰。因此,本文基于角度旋转自监督生成对抗网络提出一种基于图像块对比自监督生成对抗模型,同时解决两个前置任务:角度旋转与图像分割。模型不但能够注意到整体之间的联系,而且能从局部细节上获取信息,使生成器的表征能力得到提升。
1 相关工作
1.1 生成对抗模型
生成对抗网络如图1 所示。对抗生成模型分为生成器和判别器。生成器通过输入噪声产生虚假图片,判别器通过将真实图片与生成器输出的虚假图片进行对比,使得生成器不断更新,最终输出高质量的图片。生成器不断输出虚假的图片想要试图骗过判别器,而判别器的判别能力逐步加强,令生成器产生的虚假图片与真实图片区分开来,迫使生成器不得不逐步提高自己的能力,生成与真实图片更相似的图片。生成器和判别器在对抗中学习,模型的生成能力与判别能力也逐渐增强。
生成器G 捕捉样本数据的分布,用服从某一均匀分布或高斯分布等的噪声向量 z 生成一个类似真实训练数据的样本,追求效果是与真实样本越相似越好。

Fig.1 Generative adversarial nets图1 生成对抗网络
判别器D 是一个二分类器,估计一个样本来自于训练数据的概率。如果样本来自于真实的训练数据,则D 输出大概率,否则D 输出小概率。
1.2 基于角度旋转自监督模型
该模型属于一种基于图像变换的自监督对抗生成模型,如图2所示。
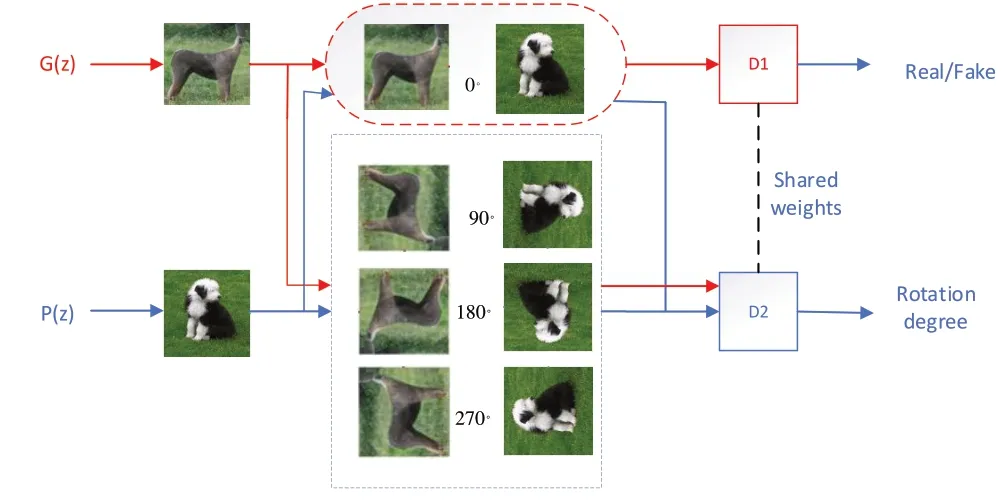
Fig.2 Self-supervised model based on angular rotation图2 基于角度旋转的自监督模型
生成器通过噪声随机生成32*32*3 的虚假图片,先进行图片旋转操作,将真假图片随机旋转0。、90。、180。、270。送入模型中。将未旋转的图片送入真假判别器D1中判别图片真假,旋转之后的图片送入角度判别器D2中判别旋转角度,真假判别器D1与角度判别器D2共享权值。其目标函数定义如下:
其中,x~PG表示图片来自于生成器,x~Pdata表示图片是真实的,V(G,D)表示上述的主判别器优化函数,R=r表示裁剪后图像的旋转角度标签,r={0,90,180,270},xr表示经过旋转后对应标签所对应的图,QD(R|xr)表示图像旋转角度预测分布,α、β表示判别器损失权重。
2 基于patches的自监督生成对抗模型
2.1 模型框架
考虑到基于角度旋转自监督的生成对抗模型仅考虑了全局相关性,而忽略了局部特性关联性,本文在角度旋转的基础上引入patches 分割技术,构建基于patches 的自监督生成对抗模型,如图3 所示,使模型能够同时注意全局与局部信息。
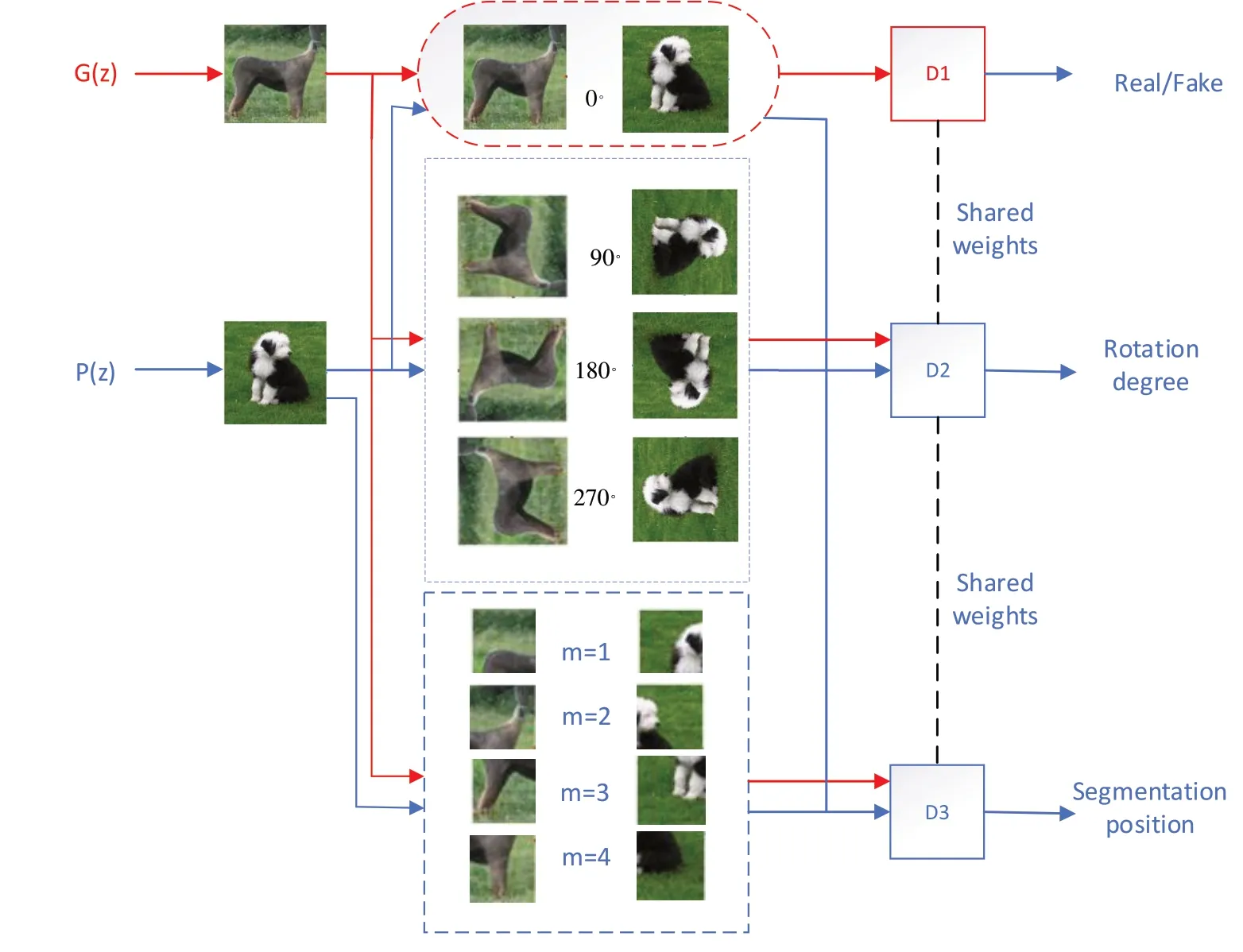
Fig.3 Self-supervised model based on patches clipping and segmentation图3 基于patches裁剪分割的自监督模型
该模型将噪声输入判别器G(z),产生虚假的图片,然后将产生的虚假图片与真实图片进行随机分割处理,按顺序分别标记为0、1、2、3、4。其中,0 代表未被分割的图片,1 代表图片被分割后的第一块,以此类推。通过给真实图片与虚假图片做标记,实现自监督的目的。接下来将标记的图片送入判别器中进行判别,主判别器用来判别未分割的图片,与普通生成对抗模型的判别器功能一致,判别图片是否为真,得到真假损失函数。将分割后的图片送入位置信息判别器D3,位置信息判别器损失函数可表示为:
其中,x~PG表示图片来自于生成器,x~Pdata表示图片是真实的,V(G,D)表示上述的主判别器优化函数,M=m表示裁剪后的图像分块位置标签,m={0,1,2,3,4},xm表示图像经裁剪过后对应标签所对应的图块,QD(M|xm)表示图像分块位置预测分布,η、λ表示判别器损失权重。
此时,模型的总损失函数为:
2.2 边缘重叠
考虑到将图像分块后忽略了局部与局部之间的关系,本文通过patches 图像重叠的方法又将不同patches 之间的信息联系起来[14],如图4 所示。原输入为左上角4*4 边框patches,大小为,通过改变分割区域大小,将输入patches 的大小增加至,此时输入图像的信息包含了另外3 个分块的部分信息。如图5 所示,以边缘重叠后第一块patches 为例,除原先的4*4 窗口外,分别包含另外3 个输入patches 窗口的信息。通过这种重叠patches 输入的方法,可有效增强分块后局部与局部之间的信息联系。
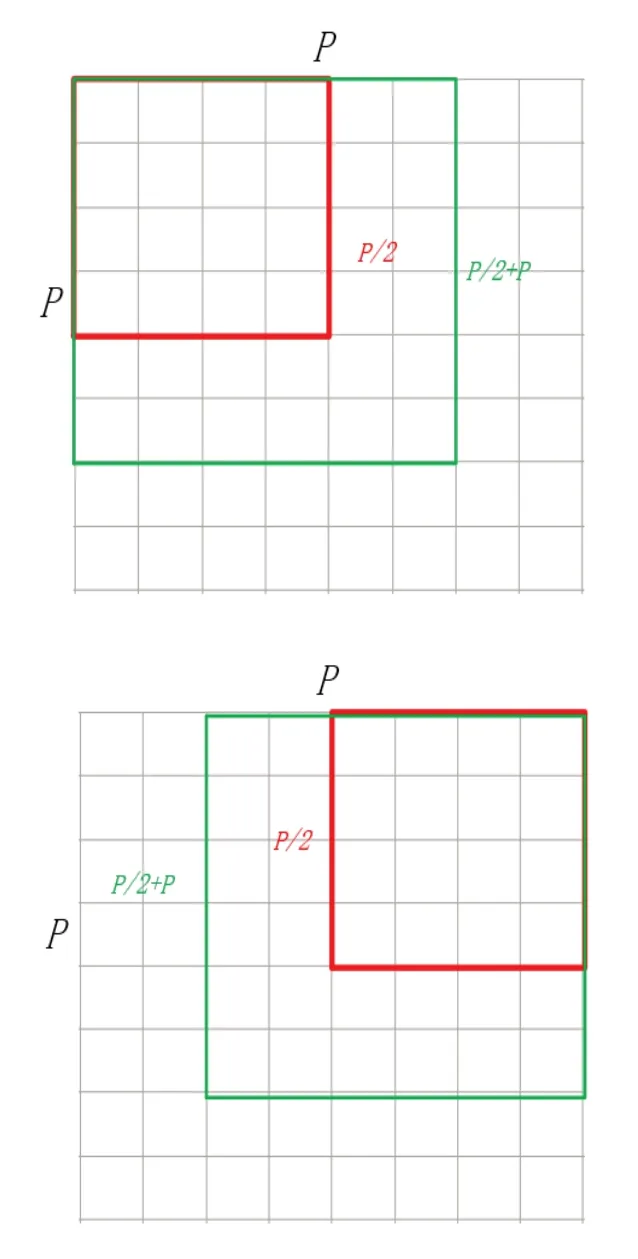
Fig.4 Amplify edge information图4 扩增边缘信息
3 评价指标
IS(Inception Score)[10]是生成模型的一种评价指标,其主要衡量模型两方面的性能:①生成的图片是否清晰;②生成的图片是否多样。

Fig.5 Information exchange among between patches图5 不同patches之间的信息交流
FID(Fréchet Inception Distance)[11]用来计算真实图像与生成图像的特征向量间距离。将生成图像与真实图像输入分类网络Inception v3 Network[12],在倒数第二个全连接层输出1*1*2 048 特征向量,用于度量真实图像在分类网络中输出的2 048 个特征向量集合的均值和协方差矩阵。
其中,μx、∑x表示真实图像在分类网络中输出的 2 048 个特征向量集合的均值和协方差矩阵;μg、∑g表示生成图像在分类网络中输出的2 048 个特征向量集合的均值和协方差矩阵。
4 实验与分析
4.1 实验环境
CIFAR-10 数据集[13]:如图6 的左图所示,CIFAR-10数据集由10 个类的60 000 个32*32 彩色图像组成,每个类有6 000 个图像。将数据集分为两部分,50 000 个训练图像和10 000个测试图像。
STL-10 数据集[14]:如图6 的右图所示,STL-10 数据集由10 类100 000 张96*96 彩色图像构成,设计灵感来自于CIFAR-10 数据集。但与其不同的是,该数据集中每个类的标记训练示例较少,以便在监督训练之前学习图像模型。
实验平台为PyCharm,实验参数如下:使用Resnet 残差结构以及Adam 自适应学习率的梯度下降算法,设置batch size 为120,learning rate 为0.000 2,迭代次数为25 000。损失权重α=1,β=0.5,η=0.5,λ=0.5。

Fig.6 CIFAR-10 dataset and STL-10 dataset图6 CIFAR-10数据集与STL-10数据集
4.2 实验结果
如图7、图8 所示,上面一排为数据集中的真实图片,下面一排为本文自监督模型生成的图片。生成的图片是根据原数据集中的10 类图片进行构造的,包括飞机、汽车、鸟、猫、狗等生活中常见的事物,从生成的图片中仍能清晰看出轮船、狗、汽车等图像。从生成图片的视觉效果来看,本文提出的自监督生成对抗模型具有较好的性能。

Fig.7 Images generated by the self-supervised model on the CIFAR-10 dataset图7 自监督模型在CIFAR-10数据集上生成的图像

Fig.8 Images generated by the self-supervised model on the STL-10 dataset图8 自监督模型在STL-10数据集上生成的图像
4.3 实验数据
如表1 所示,本文在同一设备上、同样的实验环境下,分别采用原始生成对抗模型、基于角度旋转的自监督生成对抗模型(SS-GAN)、基于裁剪分割的自监督生成对抗模型(SSC-GAN)以及基于角度旋转和裁剪分割的双自监督生成对抗模型进行实验。相较于原始的生成对抗模型,基于角度旋转的自监督模型(SS-GAN)将FID 降低到25.35,同时IS从7.662上升到7.871。
本文提出的基于裁剪分割的自监督模型与基于角度旋转的自监督模型相比,FID 与IS 获得的分数相差不大。考虑到裁剪分割自监督只将裁剪图像块进行比较,仅考虑了局部信息,而没有注意到整体之间的联系,因此在其基础上将局部与整体结合起来,提出基于角度旋转和裁剪分割的双自监督生成对抗模型,相当于提出两个前置任务,采用两个辅助判别器。实验数据如表1 所示,本文模型将FID 降低到了24.47,将IS提高到了7.871,效果相当明显。

Table 1 Comparison of FID and IS among original GAN,SS-GAN,SSC-GAN and SS+SSC-GAN models表1 原始GAN、SS-GAN、SSC-GAN、SS+SSC-GAN 4种模型FID与IS对比
为了更好地增强局部之间的信息传递,以拓展patches分割大小,进行不同块之间的信息扩增,再次将模型的FID提高到7.952,IS降低到23.34,实验结果如表2所示。

Table 2 Comparison of FID and IS before and after adding edge overlap表2 增加边缘重叠的前后FID、IS对比
研究表明,在基础卷积网络中采用合适的块大小分割能够取得媲美Transformer 的性能,Transformer 具有较好性能并不完全依赖于其注意力层的作用,而在于有效的窗口划分[15-16]。因此,本文在实验中也加入不同块分割进行对比,实验结果如表3 所示。经过对不同的分割模型进行实验,发现模型在进行4 次分割之后效果最好,块的数量低于或高于4 块,指标都会有所下降。其原因在于过小的patches 分割将使系统过分注重局部之间的联系,而过大的patches 分割会导致局部的直接关系弱化,最终影响生成图片的质量。

Table 3 Comparison of FID and IS under different Patches segmentation表3 不同Patches分割情况下的FID、IS对比
5 结语
本文在角度旋转自监督模型上进行改进,在角度判别的前置任务基础上新增patches位置判别任务,使模型能够兼顾全局相似性与局部相关性。在CIFAR-10 与STL-10数据集上进行对比验证,最终取得了比角度旋转自监督生成对抗模型更优的结果。但模型仍有很大的改进空间,例如,在前置任务上还可以有更多建设性想法以提高图像表征能力,将在以后工作中改进。
猜你喜欢
作文小学高年级(2022年3期)2022-04-20
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
数学物理学报(2021年2期)2021-06-09
福建中学数学(2018年1期)2018-11-29
知识经济·中国直销(2018年8期)2018-08-23
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
中国老区建设(2016年1期)2016-02-28
