
一种基于DFA的短文本信息过滤算法
2023-05-11 08:58关兴义伍文昌
软件导刊 2023年4期
关兴义,赵 敏,伍文昌
(陆军工程大学 指挥控制工程学院,江苏 南京 210007)
0 引言
随着信息技术的不断发展和智能手机的普及,移动互联网已逐步渗透至人们工作、生活的方方面面,大量的聊天消息、评论、新闻等碎片化信息在网络中传播,且数量呈上升趋势,这类信息通常以短文本为主[1]。本文所指的短文本是按照微软发布的关系数据库管理系统Access 中文本数据类型的分类,短文本的长度不超过255 个字符。如今,信息传递越来越便利,言论发表越来越自由,网络信息中更加容易出现带有敏感政治、暴力、色情、不文明等倾向的敏感词汇。因此,对通信过程中大量传播的短文本信息进行过滤是十分必要的。短文本信息具有字符数量少、上下文信息缺乏、语义模糊等特点,如何快速、精准地在海量数据中过滤敏感信息,成为亟需解决的重要问题。
1 相关研究
早期,文本过滤使用简单的蛮力匹配算法BF(Brute Force)算法。1975 年,Aho 等[2]提出一种经典的多模式匹配算法AC(Aho-Corasick)算法,该算法对英文文本具有很好的匹配效果,但是汉语词汇数量庞大,其利用失败指针匹配字符的方式,对中文词语的匹配达不到理想状态。1977 年,Knuth 等[3]在BF 算法基础上提出KMP(Knuth Morris Pratt)模式匹配算法,该算法在匹配过程中遇到失配字符时,模式串会根据已匹配成功的子串向右移动最大距离,相比于BF 算法每次只移动1 个距离,KMP 算法虽然更加高效,但对中文词汇的匹配效果仍不够好。
基于确定有限状态自动机(Deterministic Finite Automata,DFA)的过滤算法是目前针对中文文本较为理想的过滤算法。文献[4]提出的传统DFA 算法匹配检测时空效率较高,但未对敏感词的变形体进行有效匹配。文献[5]提出基于DFA 过滤算法的改进设计,改进后的算法能够有效过滤出部分敏感词的变形体,解决特定的人工干扰问题。但由于中文汉字数量庞大,词汇组合种类繁多,汉语运用情景复杂,不同的过滤算法在不同场景中应用的效果不同。
本文设计了基于DFA 的短文本信息过滤算法,依据敏感词出现的频率构建敏感词树,相比于传统的DFA 过滤算法[4],其时间复杂度虽然没有改变,但实际运行时间更短。通过对敏感词库扩充敏感词变形体,去除干扰字符,在SWDT-IFA 算法对敏感信息过滤具有90%以上查准率和查全率的基础上[5],其对短文本信息的过滤效果提升到95%以上。文献[6]关于敏感词过滤的研究虽然小幅提升了过滤效果,但其采用最大匹配原则,而本文算法使用最小匹配原则,对短文本中敏感词的过滤效果更好。
2 文本信息过滤相关技术
2.1 文本过滤主要问题
本文的文本过滤与模式串匹配相类似[7],是指从文本数据流中查找满足用户需求的特定文本,预先给定一个输入文本流和一个用户需求,根据用户需求建立一个初始模板,并判断流中的每一文本是否符合用户需求,然后将符合用户需求的文本反馈给用户,再根据评判情况修改模板。其中用户需求的特定文本就是敏感词,本文敏感词字数范围限定为不小于2,且不大于5。
2.1.1 敏感词变形体识别
信息发布者为确保信息顺利发出,使用变形后的敏感词表达原有词汇含义,以防止信息被过滤,本文主要解决中拼混合、词语简写、词语拆分3种变形词的识别问题。
(1)中拼混合。用敏感词的拼音替代汉字或者拼音与汉字混合的方式表达词语含义,例如“新冠”为敏感词,可以通过变形为“xinguan”“新guan”等中拼混合形式。文献[8]提出基于易混拼音分组的敏感词识别算法,用于识别敏感词拼音的变形体。
(2)词语简写。是指用词语缩写的方式替换原有词语,而不影响正常语义的表达。最常用的简写方式是用拼音的首字母表示,例如“新冠肺炎”简写成“xgfy”。
(3)词语拆分。是指将组成词语的汉字进行拆分,比如将敏感词“新冠”拆分成“亲斤冠”。文献[9]根据汉字特征对敏感词中的汉字进行人工拆分,然后采用区位码进行编码,对照形成汉字拆分表。通过人工更新拆分表,可以提升对敏感词拆分体识别的准确度,比如敏感词为“纸巾”,既可以拆分为“丝氏巾”,也可以拆分为“纟氏巾”。
2.1.2 敏感词识别的准确性
不同的过滤算法在不同场景下对敏感词的识别有一定差异,因此对敏感词的识别存在误判情况,正常的敏感词无法完全识别,而正常表达的词语也可能被误认为是敏感词。有的信息发布者会在敏感词中夹杂无意义符号,比如表达成“新*&冠”等,会影响敏感词识别的准确性。敏感词识别的准确性可用查准率来衡量,如式(1)所示。
2.1.3 算法时空效率
算法的时空效率包含时间效率和空间效率两方面。算法的时间效率是指算法的执行时间随问题规模的增长而增长的趋势,通常采用时间复杂度(time complexity)来度量[10]。时间效率是评价算法好坏的重要标准,为了不影响信息发送的时效性,过滤算法的时间复杂度应尽可能降低。随着时间复杂度的降低,往往会消耗空间资源。由于存储空间的大小是有限的,因此空间复杂度也不能无限度地增长[11-12],需要综合衡量时间效率和空间效率,对算法作出优化。文献[13]提出的一种DFA 压缩算法,在不影响匹配速度的前提下,实现了对存储空间的压缩。
2.2 DFA算法介绍
有限自动机(Finite Automata,FA)具有与正规表达式和正规文法等价的语言定义能力,使用有限自动机构造词法分析程序是一种比较好的实现途径[14]。有两种不同的有限自动机:确定有限自动机(Deterministic Finite Automata,DFA)、非确定有限自动机(Nondeterministic Finite Automata,NFA)。DFA 是文本主导,NFA 是表达式主导,在文本信息过滤上,DFA 的匹配速度更快。
图1 中的圆圈表示DFA 的状态,状态名称为q0、q1、q2、q3 和q4,每个状态有带标记的有向边射出,本文称这些带标记的有向边为转移(transitions)。DFA 中仅有一个状态用箭头标记为开始状态(start state)。q0 是开始状态,0 个或多个状态用双圈标记为接受状态(accept state),所有不是接受的状态是拒绝状态(reject state),q2 和q3 是接受状态,q0、q1和q4是拒绝状态。

Fig.1 DFA status transition图1 DFA状态转移
一个确定有穷自动机可以用一个五元式描述:M=(Q,∑,δ,q0,Z),以图1 为例,具体描述如下:①有穷的非空状态集合Q={q0,q1,q2,q3,q4};②输入字母表∑={b,c};③初始状态q0∈Q;④接受状态集合A={q2,q3}⊆Q;⑤状态转换函数δ。这些有向边构成一个函数,映射每个状态/字符到一个状态(有向边指向的状态),为Q×∑到Q的单值映射,δ(q,a)=q′(q′称为q的后继状态,q、q′∈Q,a∈∑)。
若对自动机M=(Q,∑,δ,q0,A)输入一段字符串x,x∈∑*,有δ(q0,x)=p,p∈A,则称x为自动机M 所接受的。
3 短文本信息过滤算法设计
3.1 过滤算法总体设计
图2 为本文算法设计的总体思路。第一步是对敏感词进行预处理,通过中拼混合、词语简写、词语拆分对敏感词库进行扩建,然后将扩建后的敏感词库按照敏感词出现的频率进行排序;第二步构建敏感词树,利用扩建后的敏感词库构建Trie 树;第三步过滤目标文本,将目标文本与敏感词相匹配,匹配过程中跳过无意义字符的干扰,识别出的敏感词被屏蔽后输出文本信息。
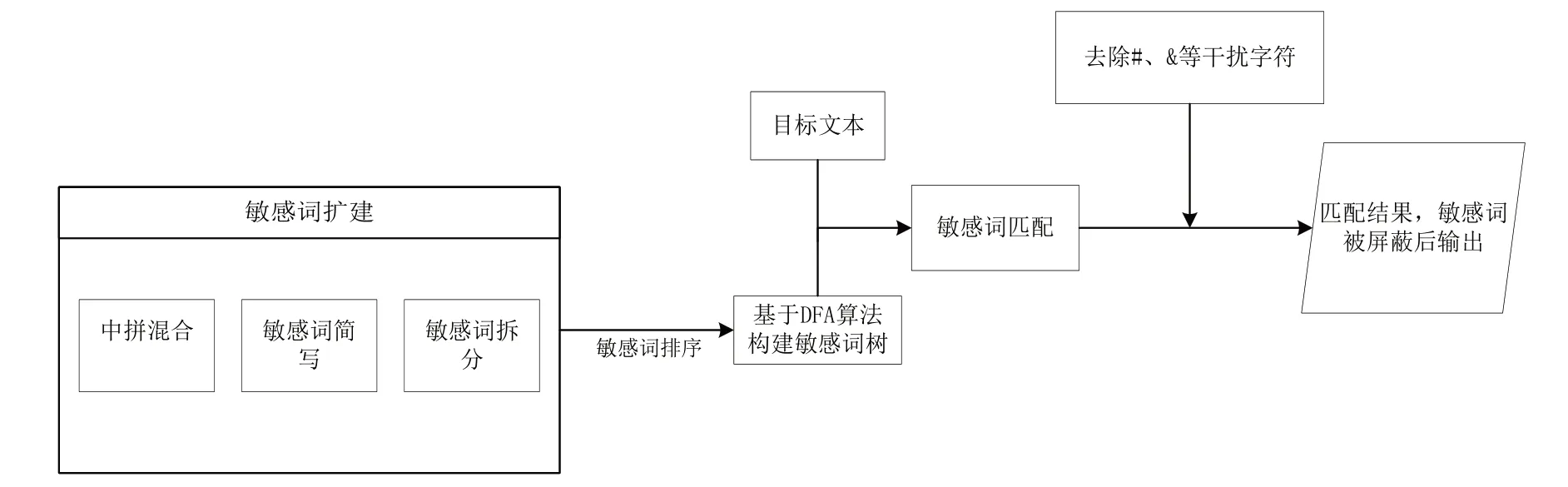
Fig.2 Overall design of the filtering algorithm图2 过滤算法总体设计
3.2 敏感词预处理
本文根据原始的敏感词设计对敏感词预处理的算法,将其扩展为中拼混合、词语简写、词语拆分的敏感词库,使得变形后的敏感词也可以被过滤。本文敏感词库扩展算法设计的执行过程有4个步骤:
步骤1:敏感词转换为拼音,首先建立一个文本文件存储汉字unicode 编码与拼音的对应关系,用数据流的方式读取,然后将unicode 码和拼音存入到一个关联式容器中,unicode 码为键,拼音为值,通过汉字编码获取对应的拼音。针对多音字的特殊情形,将多音字词组组合起来,以正确的拼音为键,词组为值,保存到一个关联容器中。获取目标词组中的汉字拼音时,先判断当前读取的汉字是否为多音字,如果是多音字,则用拼音在容器中查找目标词组,若找到目标词组,则该拼音为当前读取汉字的正确拼音,如没找到,则给其一个默认的拼音。
步骤2:敏感词转换为简写模式,本文的词语简写采用将敏感词转换成首字母简写的方式。具体方式是在将敏感词转换为拼音模式的基础上,取得拼字字符串的首字母。
步骤3:敏感词转换为拆分模式,根据汉字的部件对敏感词中的汉字进行拆分,部件是现代汉字的构字单位[15]。由一个部件构成的汉字称为独体字,例如“羊”“牛”等,不需要再进行拆分。合体字是指由两个或两个以上单字组成的汉字,是需要拆分的。本文在拆分时按照汉字部件的布局拆分,例如“明”拆分为“日,月”。通过建立字库文档存储汉字对应的拆分模式,并通过查询汉字对应的拆分模式实现对拆分词的识别。
步骤4:将扩建的敏感词加入敏感词库。将通过中拼混合、词语简写、词语拆分后的敏感词加入敏感词库,图3以敏感词“新冠”为例展示扩展后的敏感词,然后按照敏感词出现的频率,对敏感词进行排序,将排序后的敏感词依次加入构建的Trie树中,完成敏感词扩建。

Fig.3 Sensitive word expansion图3 敏感词扩建
3.3 敏感词Trie树构建
根据扩建后的敏感词库构建Trie 树,本文利用敏感词构建Trie 树的过程如下:①定义Trie 树;②根据敏感词初始化Trie 树;③将初始化后的敏感词树构成DFA 状态机。构建Trie 树的重点在于初始化过程,将每个词的公共前缀共享一个分支,在匹配过程中输入的下一个字符决定了下一步状态。假设敏感词为“香蕉”“香瓜”“香蕉酱”“香蕉乐园”“苹果”“苹果乐园”,图4 是使用Map 容器构建的Trie树,输入的每个字符作为当前匹配的键(Key),也是上一轮匹配对应值(Value)的一部分。当值为 1 时,标志着从开始到当前输入的字符串为一个敏感词,说明敏感词匹配成功。
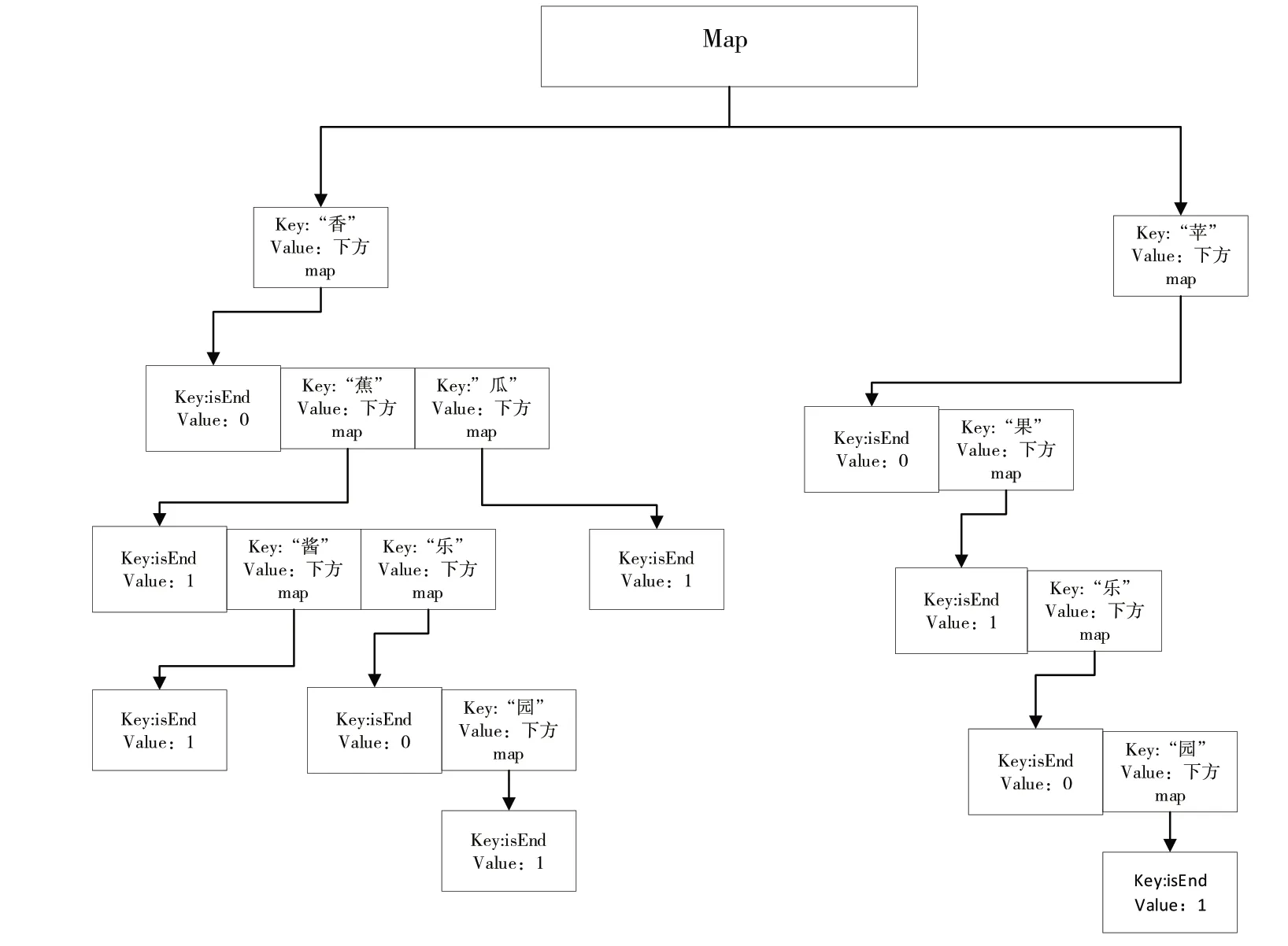
Fig.4 Sensitive word tree structure图4 敏感词树结构
3.4 过滤过程算法设计
本文算法根据目标文本的特征进行设计[16],由于短文本信息具有字符数量少的特点,文本中存在的敏感词通常同样字符数量较少,完成敏感词扩展并初始化Trie 树后,采用最小匹配原则对目标文本中的敏感词进行检索和过滤。最小匹配原则是指匹配尽可能少的字符,即一旦遇到与敏感词相匹配的文本时,该部分文本内容便会被判定为敏感文本,从而被屏蔽掉。比如“新冠”和“新冠肺炎”同为敏感词,当目标文本中出现“新冠肺炎”时会屏蔽“新冠”而不是屏蔽“新冠肺炎”。在匹配过程中,只需将目标文本匹配一遍,便能够完成过滤过程。具体过滤过程的伪代码描述如下:
算法1过滤算法



本文过滤算法采用最小匹配原则,一旦遇到敏感词的匹配成功标志符,就会判定为敏感词并结束,然后从下一个字符开始继续查找敏感词。
4 算法实验结果与分析
具体实验环境如下:CPU 为Intel i5-8250U,1.6GHz,内存为8GB,操作系统为64 位Windows10,采用Java 语言实现。分别通过实验比较其他算法和本文设计的过滤算法对不同文本信息的过滤效果,图5 为本文改进后的DFA 算法实验结果。由图5 可以看出,本文算法能够有效检测出敏感词,并能避免中拼混合、词语简写、词语拆分的干扰。

Fig.5 Experimental results of the improved DFA algorithm图5 改进后的DFA算法实验结果
4.1 短文本信息过滤结果
目标文本来自网络中提供的大规模中文对话数据集,分别比对3 649、2 680、3 556、2 434 条对话文本信息,每条对话的字符数量不超过255 个。实验采用SWDT-IFA 算法和本文设计的过滤算法分别对目标文本进行过滤,实验结果如表1、表2所示。

Table 1 Filtering results of the proposed algorithm表1 本文算法过滤结果
根据表1 和表2 比对的实验结果可以看出,在没有干扰的情况下,两种算法的查准率均达到100%,误报率都为0%。与SWDT-IFA 算法相比,本文使用人工更新后的敏感词拆分表,在查找目标文本敏感词过程中识别干扰字符,抗干扰能力得到提升。在有干扰的情况下,查准率保持在95%以上,敏感词匹配的查准率平均提高3.0%,误报率平均降低0.87%,验证了算法在检测率上的改进。在算法运行时间上,由于每次程序运行受系统调度、系统负载等因素影响,不是每一次实验运行时间都有所减少,通过多次实验比较,本文按照敏感词出现的频率构造敏感词树,在查找敏感词的运行时间上,每处理1 万字的内容平均用时减少12ms。

Table 2 Filtering results of SWDT-IFA algorithm表2 SWDT-IFA算法过滤结果
4.2 干扰类型对过滤效果的影响
本实验中,将文本内容随机分为4 组进行测试:第一组为50 篇文本信息,第二组为150 篇,第三组为250 篇,第四组为350 篇。分别根据中拼混合、词语简写、词语拆分3种变形体模式构建敏感词库,然后逐一与RSWDT 算法对比过滤4组文本信息的效果[9],如图6所示。

Fig.6 Experimental results of different interference types图6 不同干扰类型实验结果
通过分析实验结果可以看出,本文改进后的DFA 算法与RSWDT 算法相比,在中拼混合和词语简写上的查准率变化不明显。因人工更新了敏感词拆分表,所以对敏感词拆分的变形体过滤效果明显提升。由于很多词汇的简写内容相同,使得词语简写的识别准确率较低,不通过上下文分析很难判断准确,因此实验中对其识别的准确率普遍偏低。
4.3 长文本过滤实验结果
随机选择字符数量分别为100、1 000、2 000、5 000 的网络文本,按照字符数量将目标文本分为4 组,分别用本文算法对4 组文本进行过滤,实验结果如图7 所示。由图7可以看出,本文设计的改进算法随着目标文本长度的增长,查准率呈下降趋势后,其中目标文本长度为100 个字符和1 000 个字符的过滤性能变化最为明显。随着目标文本字符数量的增加,查准率下降,说明在文本长度改变时对算法的过滤效果存在影响,本文算法对于字符数量少的文本具有更好的过滤性能。性能变化的原因在于本文使用的是最小匹配原则,短文本中更容易使用简短的词语表达相同语义。比如,短文本中使用“新冠”的频率远高于“新冠肺炎”,本文可以有效识别出敏感词“新冠”,但对于含有敏感词“新冠肺炎”的目标文本不能有效识别。
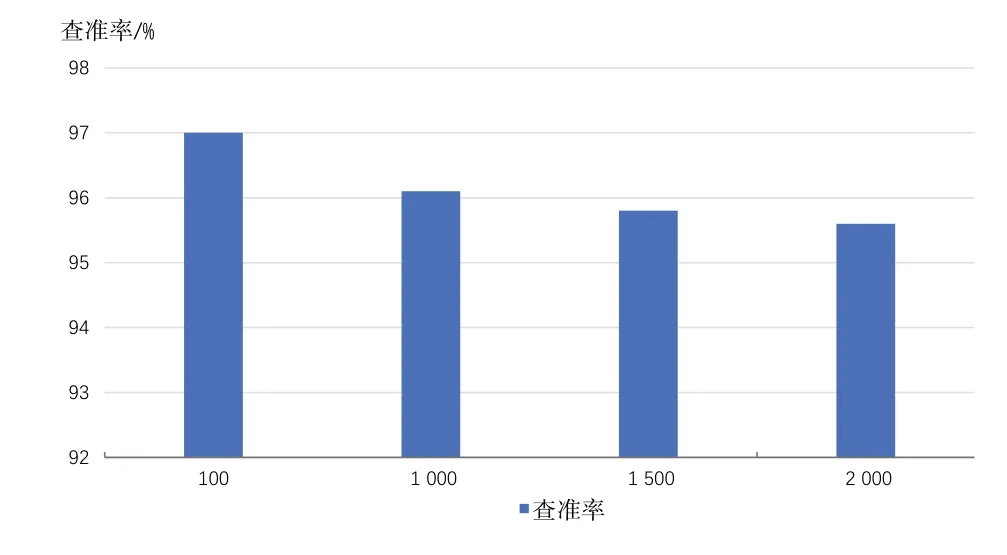
Fig.7 Experimental results of target texts with different length图7 不同长度目标文本实验结果
5 结语
本文基于短文本信息过滤的既定场景,设计了决策树的确定自动机算法。算法的复杂度与敏感词数据库的大小无关,只与敏感词长度和目标文本长度有关,通过在过滤目标文本前对敏感词进行预处理,对敏感词汇进行扩展和改进,提升了敏感词匹配的精准度。实验结果表明,该算法能够有效检测出文本中的敏感词,并对短文本信息有着较好的检测效果,可以实践运用于移动网络敏感信息过滤,实时净化网络环境。本文设计的算法对部分特定干扰字符的抗干扰能力弱,比如“!”“。”等字符既可以成为干扰字符,又可以成为正常文本符号,此类干扰字符的存在会降低算法过滤效果。要进一步提高敏感词过滤的精准度,还应考虑更多干扰方式,比如信息发送者利用同音字替换敏感词,或者用地方方言表示敏感词的含义将难以被识别。下一步将逐步进行深入研究,综合考虑影响过滤效果的因素,提升算法的时空效率,进一步提高对文本中敏感词过滤的效果,扩大算法的适用范围。
猜你喜欢
动漫界·幼教365(大班)(2020年7期)2020-06-26
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
英语知识(2016年1期)2016-11-11
