
基于字符嵌入与BiGRU的命名实体识别
2023-05-11 08:58甘晨阳万义程张庆达
软件导刊 2023年4期
甘晨阳,李 明,万义程,张庆达
(重庆工商大学 人工智能学院,重庆 400067)
0 引言
命名实体识别(Named Entity Recognition,NER)是指识别语料库中的人名、地名和组织结构名称等命名实体,即识别文本中具有特定含义的实体,也称为实体识别、实体提取、实体分割等。命名实体识别技术的应用场景十分广阔,它是自然语言处理领域许多研究问题的基础,例如关系提取、事件提取、知识图谱、机器翻译、问答系统等[1]。命名实体识别任务可划分为通用领域和专业领域[2],在通用领域中一般采用新闻稿、社交媒体等语料库,在生物、金融、材料等专业领域,由于具有大量专业词汇,因此语料库大都基于专业领域中的相关文献构建而成。
1 命名实体识别研究现状
由于命名实体识别是自然语言处理领域的子任务,因此目前通常将命名实体识别为序列标注任务,传统方法包括基于规则匹配的方法和基于统计机器学习的方法。例如,谢菲尔德大学在2012 年开发的GATE 框架[3],该框架具有十分具体且清晰的NER 规则,因此在特定时期内具有较高的匹配准确率,缺点是需要众多领域专家设计实体抽取规则,而且领域词典需要定期更新维护以保持最优性能。基于统计机器学习的方法包括隐马尔可夫模型(Hidden Markov Model,HMM)[4]、最大熵模型(Maximum Entropy,ME)[5]和条件随机场(Conditional Random Fields,CRF)[6]等,这类方法相较于基于规则的方法具有更好的性能,无需人工定义规则,但仍需要大量人工标注语料库,而且训练的模型十分依赖于标注特征,一旦标注特征不足以充分反映语料的特点,会导致模型性能下降。
近几年,随着计算机性能提升,大多数对命名实体识别的研究从基于规则与统计的方法转向深度学习[7],常用的命名实体识别深度学习网络模型包括长短期记忆神经网络(Long-Short Term Memory,LSTM)[8]、卷积神经网络(Convolutional Neural Nerwoek,CNN)[9]、门控循 环网络(Gate Recurrent Unit,GRU)[10]、结合自注意力机制的网络模型等[11]。Kuru 等[12]使用双向长短期记忆网络(Bi-directional Long-Short Term Memory,BiLSTM)模型在CoNLL-2003 数据集中F1 值达到84.52%。Ruder 等[13]通过整合两个深度递归神经网络(Recurrent Neural Nerwork,RNN),在OntoNotes5.0 数据集中F1 值为87.21%。张雪松等[14]通过在BiLSTM 网络中加入依存树信息,在OntoNotes5.0 数据集上的主要实体达到平均86.67%的F1 值。Zhang 等[15]编码输入一系列字符与该字符匹配的所有潜在单词,通过LSTM 进行训练,在中文数据集MRSA 上表现出色。
相较于传统方法,基于深度学习的方法在不依赖大量人工特征的前提下,取得了更好的性能,在专业领域的命名实体识别任务也具有出色的性能。Li 等[16]提出基于LSTM 与CRF 的神经网络模型,在中文电子病历中临床术语领域的数据集中F1 值分别达到89.56%、91.60%。Liu等[17]采用BRET 模型提取特征,通过BiLSTM 网络提取章节级特征,在化学药品领域命名实体识别精准度提高了80%;李林等[18]结合BERT 与BiLSTM,并辅以多源信息融合丰富字符集向量,在农作物害虫领域多个数据集上效果出色。Chen 等[19]通过结合词汇特征,使用BiLSTM-CRF模型进行训练,在中文药品领域取得了94.32%的F1值。
词嵌入(Word Embedding)技术是指单个词在预定义的向量空间中被表示为实数向量,每个单词均映射一个向量,可捕获单词间的相似性。因此,将经过词嵌入处理后的数据作为基本特征传入神经网络模型,提升自然语言处理任务效果。目前,较为流行的词嵌入模型为Word2Vec[20]、Glove[21]。通常而言,获取词向量的方式有两种,一种是采用预训练模型,这种模型通过网络上超大规模文本库进行训练得到一个开源的全局词向量库,例如BERT[22];另一种是通过自己收集的语料库进行训练,得到一个局部词向量库。本文通过结合BiLSTM 与Glove 训练收集的语料库。
由于命名实体识别任务中,BiLSTM-CRF 模型存在识别精度较低的问题,本文提出一种将BiLSTM、Glove 预训练模型、BIGRU-CRF 模型与注意力机制相结合应用于命名实体识别的模型。首先,通过BiLSTM 提取字符级单词信息;然后,拼接得到的字符级词向量与Glove 预训练模型得到词向量;接下来,将词向量送入BiGRU 模型进行训练;再之,使用自注意力优化权重;最后,使用CRF 进行分类,输出得分最大的标注序列。为验证本文模型相较于传统算法的性能优势,在CoNLL-2003、OntoNotes5.0 数据集上进行实验。
2 字符嵌入与BiGRU模型
图1 为本文提出的模型结构,该模型由BiLSTM 与Glove 词嵌入模块、BiLSTM 模块、CRF 模块3部分组成。

Fig.1 Complete architecture of the model图 1 模型完整架构
2.1 BiLSTM 模型与Glove
字符级神经网络语言模型可捕获句子底层风格和结构,为了让神经网络捕捉词汇特征而并非单一记住单词的拼写,可将BiLSTM 从预测下一个字符调整到预测下一个单词。BiLSTM 由一个前向LSTM 层和一个后向LSTM 层组成,可分别获取两个方向的上下文特征。单个LSTM 神经元由遗忘门、输入门和输出门3个模块组成,如图2所示。
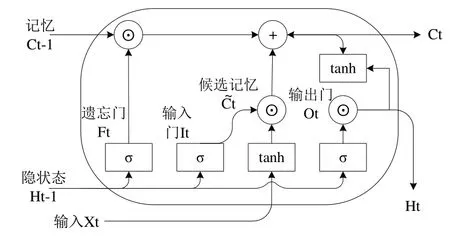
Fig.2 LSTM neurons图2 LSTM 神经元
由图2 可见,模型由3 个具有sigmoid 激活函数的全连接层处理,以计算遗忘门、输入门和输出门的值。LSTM 的数学表达为:
2.2 BiGRU模型
语料库分别经过BiLSTM 与Glove 模型进行向量化后,将两者向量拼接后直接输入编码层进行全局特征提取。其中,编码层采用双向GRU 结构,GRU 与LSTM 网络类似,也可充分捕捉前向和后向信息。单个GRU 单元结构如图3所示。

Fig.3 Gated Recurrent Unit图 3 门控循环单元
GRU 内部主要由重置门和更新门控制,这两个门均使用sigmoid 激活函数的两个全连接层构成。其中,重置门判断前一时刻有多少隐状态信息需要被遗忘,更新门则判断前一时刻有多少信息需要冲抵到当前单元的隐状态中。具体数学表达式如下:
其中,Rt、Zt分别为重置门和更新门的输出向量,H~t为候选隐状态输出,Ht为当前时刻的隐状态输出。W、b是重置门、更新门和候选隐状态的权重矩阵和偏置参数,σ、tanh为激活函数。
GRU 存在以下两个显著的特征:重置门有助于捕获序列中的短期依赖关系;更新门有助于捕获序列中的长期依赖关系。BiGRU 则为了从前向、后向两个方向上捕获两种依赖关系,然后拼接前、后向的输出向量,获得更充分的特征信息。
2.3 自注意力机制
为了更好地捕捉BiGRU 网络输出的信息,提高模型对关键信息的识别能力。本文在模型中加入一层自注意力机制,具体数学计算公式如下:
其中,Q为查询矩阵,K为键矩阵,V为值矩阵均由对应权重矩阵W点积状态矩阵计算得到,A 为自注意力层机制,dk为矩阵K的维度,使用softmax对结果进行归一化处理,MHA为多头注意力机制结果。
2.4 CRF层
条件随机场是一个经典的序列标注算法,CRF 是一种基于无向图模型的判别式模型,其中线性链条件随机场使用最为普遍[23],相较于隐马尔可夫模型和softmax模型而言,CRF 不仅可定义数量更多、种类更丰富的特征函数,还可获得全局条件下的标注序列最优解。因此,为得到具有最大概率的序列,使用CRF 模型对BiGRU 编码层的输出进行最终修正。对于给定的一个观测序列X,输出目标序列Y的分数,具体计算公式如下:
3 实验结果与分析
3.1 数据集
本文使用的数据集包括含有4 种实体的CoNLL-2003英文数据集、含有18 种实体的OntoNotes5.0 英文数据集。数据集采用BIOES 标注法标注实体。其中,B 代表Begin,表示实体的开始部分;I 代表Inside,表示组成实体的中间部分;O 代表Outside,表示非实体的单词;E 代表End,表示实体的结束部分;S 代表Single,表示长度为1 的实体。将上述两个数据集划分为训练集、开发集和测试集,具体的划分比例如表1所示。

Table 1 Summary of data sets表1 数据集摘要
3.2 评价指标
本文采用精确率P(Precision)、召回率R(Recall)和F1值这3 种评价指标作为模型性能评价标准,具体计算公式如下:
其中,Tp为识别正确的实体个数,Fp为识别错误的实体个数,Fn为未被正确识别的实体个数。
3.3 实验环境与参数设置
本文实验环境基于Python3.7 和PyTorch1.1.0 版本框架,GPU 为NVIDIA GeForce RTX2060。训练过程过中batch_size=10,隐藏层维度为300,字符嵌入维度为10,词嵌入维度为100,学习率lr=0.015,Dropout=0.55,采用SGD算法优化器,训练200次,实验结果在训练130次后收敛。
3.4 实验结果
为证明本文所提改进模型的有效性,选择BiGRUCRF 模型作为基线模型进行比较实验。实验结果如表2、表3所示。

Table 2 Experimental results on CoNLL-2003 dataset表2 CoNLL-2003数据集上的实验结果 (%)

Table 3 Experimental results on the OntoNotes5.0 dataset表3 OntoNotes5.0数据集上的实验结果 (%)
3.4.1 有效性
由表2可见,在BiGRU-CRF 模型中结合字符级嵌入与词级嵌入,在CoNLL-2003 数据集上F1 值达到91.04%,精确率达到91.57%,相较于BiGRU-CRF 模型分别提升0.42%、1.51%。在OntoNotes5.0 数据集上,该模型F1 值达到88.26%,精确率达到87.45%,相较于BiGRU-CRF 模型分别提高0.58%、0.52%。实验表明,所提融合方法对提升命名实体识别的模型的性能具有一定的作用。
3.4.2 合理性
由表2、表3 可知,加入多头自注意力层后,在CoNLL-2003 数据集上,本文所提方法F1 值达到91.69%,精确率达到92.12%,相较于BiLSTM-BiGRU-CRF 模型分别提升0.65%、0.77%。在OntoNotes5.0 数据集上,本文所提方法F1 值达到88.97%,精确率达到89.73%,相较于BiLSTM-Bi-GRU-CRF 模型分别提升0.71%、2.28%。实验表明,加入多头注意力机制后,重新分配特征权重对提升模型识别性能有所帮助。
3.4.3 性能比较
CHIU 等[24]提出一种将BiLSTM 与CNN 相结合的模型,自动检测单词和字符级特征。Huang 等[25]将BiLSTMCRF 模型运用于自然语言处理任务中。Ghaddar 等[26]将单词与实体类型嵌入一个低维向量空间中,并使用BiLSTMCRF 模型进行训练,取得了出色的效果。由表2、表3 可知,相较于BiLSTM-CNN 模型在CoNLL-2003 数据集与OntoNotes5.0 数据集上取得的F1 值,本文模型分别提升0.07%、2.69%,相较于BiLSTM-CRF 模型性能,本文模型的F1 值分别提升1.59%、1.02%。实验表明,本文模型相较于其他模型性能更优。
4 结语
本文提出一种结合BILSTM、BIGRU、MHA 与CRF 模型的命名实体识别方法。首先利用BILSTM 捕捉字符级特征;然后结合字符级词向量与预训练模型Glove 词向量,获得句子的语义编码信息;接下来,使用BiGRU 模型训练整合后的词向量;再之将训练输出送入自注意力层分配特征权重;最后使用条件随机场输出最优序列。在CoNLL-2003、OntoNotes5.0 数据集上的实验表明,本文模型对于提升命名实体识别任务的性能有所帮助。
由于文本使用BiLSTM 嵌入字符级词,导致了模型训练时间较长,并且使用Glove 模型的词向量为静态向量,无法较好地解决一词多义及嵌套实体的问题。未来,考虑在字符嵌入层也使用训练速度更快的BiGRU 模型,并通过语义编码更精准的BERT 模型代替传统Glove 模型,以提升模型命名实体识别任务的表现。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
数学物理学报(2017年5期)2017-11-23
中国科技术语(2012年5期)2012-03-20
