
基于深度学习多任务与标签分布的年龄估计研究
2023-05-11 08:58胥明晨胡春龙
软件导刊 2023年4期
胥明晨,胡春龙
(江苏科技大学 计算机学院,江苏 镇江 212000)
0 引言
年龄作为人脸的重要属性之一,因其在视频监控、人机交互等实际应用方面[1]有着重要应用价值,近年来得到了相关领域研究人员的广泛关注。最早的年龄估计工作始于Kwon 等[2]将年龄进行分组研究。第一个用于年龄估计的公开数据集是FG-NET,共包含82 人的1 002 张图像,年龄范围为0~69 岁。早期的年龄估计工作主要包含两大阶段:特征提取与分类。2002 年,Hayashi 等[3]提取人脸局部皱纹特征和颜色特征后使用直方图进行特征均衡化处理,将处理后的特征用于年龄估计。仿生学特征(BIF)方案也被广泛用于年龄估计[4],该方法受大脑皮层启发,通过手工制作人脸特征,输送至S1 层和C1 层,经降维处理后进行分类和回归以估计年龄。此外,局部邻域特征也是年龄估计领域中比较常见的选择[5-6]。
近年来,随着人工智能越发火热,深度学习在计算机视觉领域中取得了很多优秀成果,研究人员也将其应用于年龄估计领域。与传统方法不同,基于深度学习的方法[7-8]可以将特征提取与分类这两个独立的阶段整合到一个能直接从原始面部图像估计年龄的端到端模型中。2016 年,Rothe[8]提出一种基于期望值的表观年龄估计方法DEX,他们在IMDB-WIKI 数据集上训练了一个基于VGG-16模型的网络,利用完全连通层(FC)获取SoftMax 权重,最后使用SoftMax 的权重计算加权平均年龄。Yang等[9]充分利用相近年龄之间的相关性,采用高斯分布生成年龄标签的分布,将生成的年龄分布作为模型训练目标,取得了较好结果。此外,Jie 等[10]提出SE 模块,利用不同通道之间的信息,筛选出针对通道的注意力,其可以自适应地学习不同通道之间的依赖关系,提升模型性能,且易于集成到现有网络模型中,在深度学习中被广泛使用。
目前而言,从单个人脸面部图像估计年龄任一项重大挑战。首先,人脸的衰老是一个充满不确定的复杂过程,受到许多内在和外在因素的共同影响。内在因素包括基因遗传,外在因素包括生活方式、环境等,这意味着不同受试者在同一年龄段的面部外观可能会有很大差异。而且,衰老是一个缓慢的过程,同一受试者相邻年龄段之间的容貌差异往往难以察觉[11]。其次,人脸具有结构复杂、变化丰富等特点,如图1 所示,在相同年龄下,不同性别、种族的脸部外观差异很大,这会对年龄估计造成干扰[12]。
在当前的年龄估计研究领域,深度学习模型大多是基于单分支的任务网络模型。本文考虑是否可以采用多任务学习,通过引入一些简单的辅助任务,探究对年龄估计主任务的影响。鉴于此,本文设计了一个含性别辅助任务的双分支年龄估计模型,对面部年龄估计进行研究,希望两个网络模型能够学习到更有效的互补特征,以更好地提高网络表达能力,从而提升年龄估计准确度。
1 方法模型
本文设计的基于多任务与标签分布的双分支网络模型主要分为两部分,级联的多任务网络模型CUTResNet50 和标签分布学习(LDL)。多任务网络模型CUTResNet50 由基于ResNet50[13]的共享特征参数提取层、性别辅助任务层与年龄主任务层组成,整体网络结构如图2 所示。为了充分利用辅助任务提取的低级特征,本文将共享特征层与辅助任务层的特征进行级联融合,作为年龄主任务层的输入,用来进行年龄估计。同时,将真实年龄标签转换为年龄分布,作为模型训练目标。
1.1 多任务网络模型设计
本文设计了一个多任务的网络模型CUT-ResNet50(见图2),通过粗粒度的性别分类任务指导细粒度的年龄分类任务,目的是提高年龄估计主任务性能。所设计的整个网络模型分为3 块:共享网络层(Share Net)、性别粗粒度任务层和年龄细粒度任务层,由共享网络层学习低级特征后,分别输入到性别层与年龄层中。

Fig.1 Female and male face images of subjects in the MORPH-II dataset图1 女性与男性在MORPH-II数据集中的受试者脸部图像
通常,卷积神经网络先利用一定尺寸的卷积核按从左往右、由上而下的顺序扫描输入图像,获取浅层特征,而后不断地叠加卷积层以加深网络,从而通过扩大感受野捕获更深层的语义特征,但网络层数的不断加深,会出现梯度爆炸或者梯度消失等网络退化问题。而ResNet[13]通过短路链接的方式在卷积神经网络的基础上引入了恒等映射,在一定程度上能够缓解网络退化问题。基于其优秀性能,本文采用ResNet50 作为网络主干,截取其前22 层结构,组成多任务的共享参数层。将人脸图像预处理为224×224的尺寸输入到共享参数层,经卷积与池化后,由3 组[1×1,64|3×3,64|1×1,256]与4组[1×1,128|3×3,128|1×1,512]的残差块处理,输出尺寸为28×28×512的特征图,这些低级特征将分别输入到性别任务层与年龄任务层,并作进一步处理。
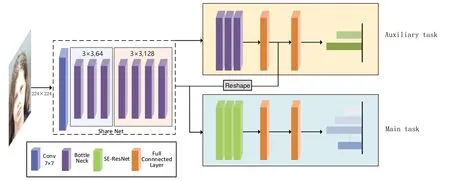
Fig.2 Structure of cascaded network CUT-ResNet50图 2 级联网络CUT-ResNet50结构
性别任务层由3组残差块和两个全连接层构成,网络的输入尺寸为28×28×512,堆叠残差块输出的特征尺寸为14×14×1024,第一个全连接层的输出为1×1×512,第二个全连接层的输出为1×1×2,最后由SoftMax输出男女的概率分布。
在深度学习的发展历程中,特征融合是提高模型性能的一种重要方法[14],本文将粗粒度性别任务层输出的特征与共享网络层输出的低级特征进行融合,通过级联将性别任务网络与年龄任务网络连接,采用reshape 方法,对性别任务网络第一个全连接层的特征尺寸作重新调整,使其与共享网络层的输出尺寸一致后,再与共享网络的特征进行叠加融合,作为年龄任务网络的输入。
年龄主任务网络采用残差块堆叠而成,考虑到年龄分类是一个细粒度的分类任务,本文引入了易于集成的SE 模块[10],组成SE-ResNet,利用SE模块的注意力机制,进一步提取出有助于年龄分类的特征。SE模块结构如图3所示,输入图像尺寸为H×W×C,经全局池化层加全连接层,将尺寸拉伸成1×1×C后再与原图像相乘,通过赋予每个通道权重,从而学习不同通道之间的依赖关系。如图4所示,SE模块在ResNet的BottleNeck 结构之后加入。年龄任务网络的主干为SEResNet,含两个全连接层,残差块输出的特征尺寸为14×14×1024,第一个全连接层的输出为1×1×512,第二个全连接层的输出为1×1×100,最后由SoftMax输出年龄估计的概率分布。
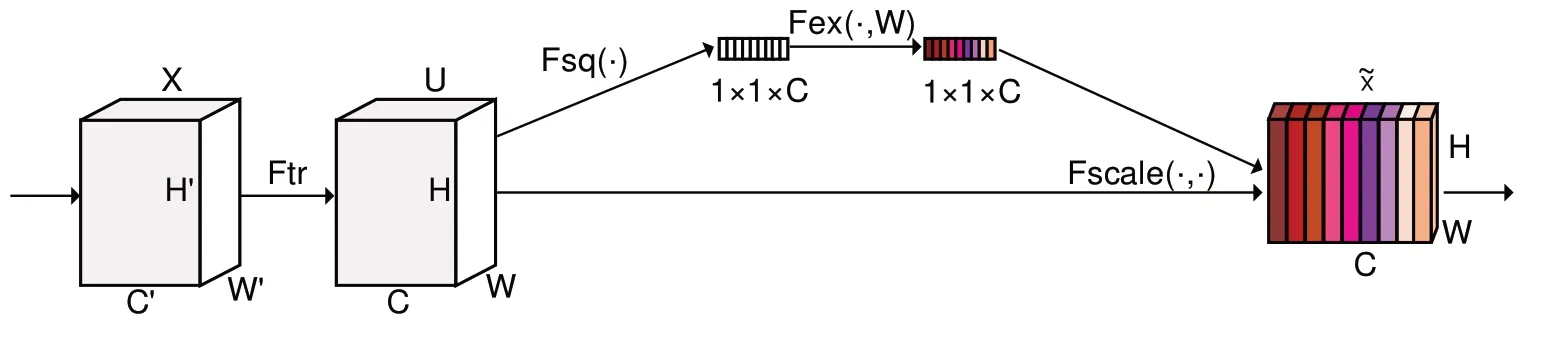
Fig.3 SE(Squeeze-and-Excitation)module图3 SE(Squeeze-and-Excitation)模块

Fig.4 SE-ResNet structure图4 SE-ResNet结构
为了验证本文所提出方法的有效性,另设计了4 种基础模型进行对比实验,网络结构图5 所示。其中,图5(a)、(b)分别是直接基于ResNet18、ResNet50 接入全连接层的模型,(c)s 是单任务的CUT-ResNet50-NoAuxiliary 模型(CUT-ResNet50 下移除辅助任务),(d)是多任务未融合特征的CUT-ResNet50-NoFusion 模型(CUT-ResNet50 下辅助任务层未进行特征融合)。
1.2 标签分布学习
年龄增长是一个缓慢的过程,同一个体在相近年龄其人脸外观变化难以察觉,例如一个人29 岁时的照片与30岁时的照片看起来会十分相似,因此可以利用人脸衰老规律,将人脸年龄从单一值转换为年龄的分布信息。本文采用式(1)的高斯分布函数将人脸对应的年龄值转换为年龄分布,作为对年龄的分布描述,年龄分布如图6 所示。可以看出,越接近真实年龄,其描述程度值越高,这反映了相近年龄之间的相关性,且在真实年龄处达到最大值。此外,合适的年龄分布有助于真实年龄的学习,同时更有助于邻近年龄的学习,从而在一定程度上弥补数据集样本分布不均的问题。
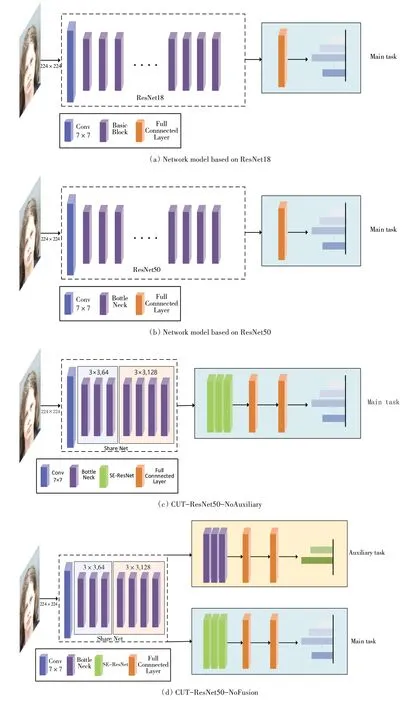
Fig.5 Structure of four basic comparison models图5 4种基础对比模型结构

Fig.6 Example of age distribution图 6 年龄分布示例
将深度学习与标签分布结合起来,将年龄分布作为网络训练目标,采用Kullback-Leibler(KL)散度作为损失函数,要尽量减少KL 的发散。
其中,yj是真值分布的第j个值,pj是预测分布的第j个值。关于多任务的损失占比,不同分类任务的损失存在较大差异,学者们通常会采用加权求和方式寻找最佳损失占比[15],本文不探讨损失比例问题,在性别为0-1 分布的情况下,如式(3)所示,直接叠加作为总损失。
此外,最终年龄的计算方式为概率分布对应的年龄累加,通过生成一个年龄范围为1~100 的元组,与分布对应的索引下标相乘后相加作为估计年龄。
2 实验与结果分析
2.1 数据集与预处理
MORPH-II 数据集[16]作为目前最大的公开真实年龄数据集之一,其包含了约1 300 个不同性别、不同种族人物的超过55 000 张面部图像。这些图片拍摄于2003-2007年,年龄范围为16~77 岁,虽然其覆盖年龄广,但也存在着各年龄段和各种族图像数量不均衡的问题,图像年龄主要集中在20~40 岁,且超过96%的人脸是非洲和欧洲人。在本文实验中,将实验数据随机打乱,采用8-2 原则[17-18],将其中的80%用于训练,20%用于测试。
UTKFace 数据集是一个年龄跨度大的人脸数据集,包含了不同性别、种族、人物约23 700 张面部图像,年龄范围为0~116 岁,但其分布不均衡问题更为严重,1~25 岁的图像最多,且包含了不同姿势、光照、遮挡、分辨率等外在因素影响的图像,训练难度较大。在实验中,同样将实验数据随机打乱,将其中的80%用于训练,20%用于测试。
此外,为了提升模型性能,保证数据多样性,避免过拟合,需要对训练数据进行增强。对于每个训练图像,以50%的概率将其翻转,放大为256×256 尺寸,并随机切出224×224 尺寸的图像,随机旋转±10°,以0.3 的概率随机擦除图像的一部分,最后进行平均标准化后作为训练网络的输入。
2.2 评价指标
本文采用年龄估计领域中常用的平均绝对误差MAE与累计指数CS 作为评价指标(以下简称MAE 与CS)。MAE 是计算真实年龄与估计年龄之间的绝对值误差,其计算方式如下:
其中,N为测试集图像总数,Ne≤j表示估计年龄与标签年龄的绝对误差在j范围内的图像数,CS值越高,模型性能越好。
2.3 超参数设置
本文实验在Windows10 系统下完成,深度学习架构基于开源的Pytorch1.7 框架,硬件环境为Intel Core i7-7700,GPU 为NVIDIA GeForce GTX 1060。
网络使用Pytorch 提供的预训练ResNet 网络。神经网络优化算法采用随机梯度下降法(SGD),初始学习率设为0.001,动量0.9,权值衰减2x10-4。在MORPH-II、UFTFace数据集上各迭代90 次,批处理大小为32,在第70 次与第80次迭代时学习率降低10倍。
2.4 结果与分析
在MORPH-II 数据集下,对本文提出的CUT-ResNet50模型与其他4 种模型在参数量、MAE、CS 3 个方面进行比较,具体实验数据如表1 所示。其中,CS5、CS3 分别表示估计年龄与真实标签年龄的绝对误差在5 岁和3 岁范围内的图像占比。
与ResNet18、ResNet50 模型相比,本文提出的CUTResNet50,在参数量仅为ResNet50 参数量2/5 的情况下,MAE 提升10%,与ResNet18 相比,参数量低于前者,MAE提升 13.5%。将 CUT-ResNet50-NoAuxiliary 与 CUTResNet50-NoFusion 相比,发现增加了辅助任务后,即使未进行特征融合,模型MAE 也提升近3%,且将进行特征融合后的多任务CUT-ResNet50 与单年龄任务CUTResNet50-NoAuxiliary 进行比较,模型MAE 提升13.8%,这说明与单个年龄任务网络相比,添加性别任务的多任务网络,进一步提高了网络表达能力,提升了年龄主任务的性能。
在上述实验基础上,引入标签分布学习,在生成分布函数中,标准差σ 作为统计分布程度的测量,反映组内个体间的离散程度,在本文代表可以学习的相邻年龄特征程度。本文研究了在MORPH-II 上多种标准差σ 取值下的实验结果,MAE 变化趋势如图7 所示。可以看到,随着σ 的增大,MAE 提升后又回落,当σ 为0.6时,模型性能最佳。
利用标签分布学习,取生成的分布函数的最佳标准差σ 为0.6,重新在MORPH-II 与UTKFace 数据集上训练了表1 中的各网络模型,实验结果数据如表2、表3 所示。本文级联网络在MORPH-II 数据集下MAE 为2.1,与未引入标签分布学习的CUT-ResNet50 相比,MAE 提升13%,在UTKFace 数据集下MAE 为4.91,都优于直接基于ResNet-18、ResNet-50的网络模型。
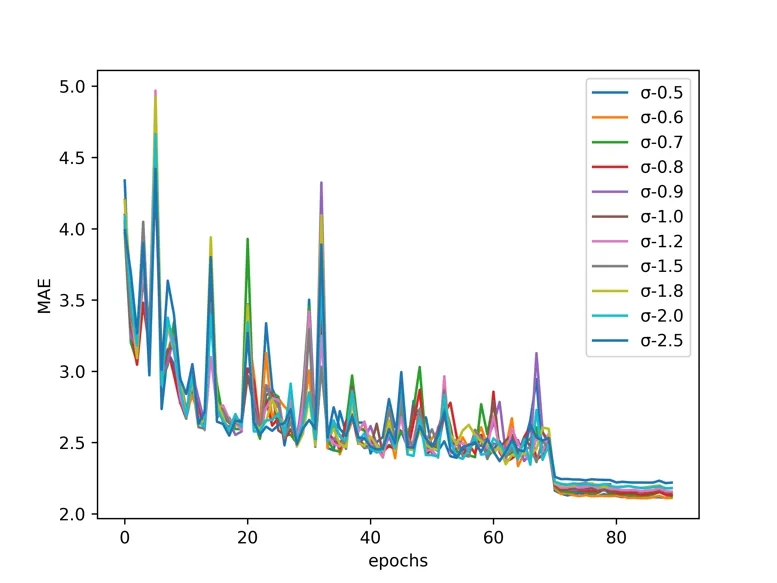
Fig.7 Validation MAE changes with different standard deviations during training图 7 训练时不同标准差的验证MAE变化
在年龄主任务网络结构中引入SE 模块,为了验证SE模块的有效性,引入消融实验,CUT-ResNet50-NoSE 在CUT-ResNet50 的模型下移除SE 模块,如表4 所示。结果表明,年龄主任务网络结构通过引入SE 模块,模型性能可提高4%。
3 结语
本文在公开的MORPH-II 与UTKFace 人脸数据集上,将深度学习神经网络与多任务学习结合,设计了一个带有共享网络的双分支多任务网络模型CUT-ResNet50,通过人脸的性别属性辅助人脸年龄估计,同时引入标签分布学习,将离散的年龄值转换为连续的概率分布,解决了单标签信息量不足的问题。实验结果表明,添加了性别任务的多任务学习与标签分布学习可以提升年龄估计准确度,证明了本文新设计模型的有效性。

Table 1 Comparison of parameters,MAE and CS of different methods under the MORPH-II dataset表1 在MORPH-II数据集下不同方法的参数量、MAE与CS的比较

Table 2 Comparison of different method parameter quantities,MAE,and CS after introducing label distribution learning in the MORPH II dataset表2 在MORPH-II数据集下引入标签分布学习后不同方法的参数量、MAE与CS的比较

Table 3 Comparison of different method parameter quantities,MAE,and CS after introducing label distribution learning in the UTKFace dataset表3 在UTKFace数据集下引入标签分布学习后不同方法的参数量、MAE与CS的比较

Table 4 Comparative experimental results of SE modules表4 SE模块对比实验结果
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
中国生物医学工程学报(2019年6期)2019-07-16
动漫星空(2018年9期)2018-10-26
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
自动化学报(2016年3期)2016-08-23
公民与法治(2016年10期)2016-05-17
电测与仪表(2016年5期)2016-04-22
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
