
基于Albert与TextCNN的中文文本分类研究
2023-05-11 08:58李飞鸽黄树成
软件导刊 2023年4期
李飞鸽,王 芳,黄树成
(江苏科技大学 计算机学院,江苏 镇江,212100)
0 引言
在移动互联时代,文本数据呈现爆炸式增长。通过对文本数据进行多标签标注,能够快速查询所需信息。根据文本信息关联的标签个数可分为单标签文本和多标签文本[1]。
目前,传统文本分类方法通过人为设计规则提取文本数据特征,造成文本分类结果误差较大并且提取的文本表征较差[2]。现阶段,基于深度学习的多标签分类方法逐渐成为主流,通过数据清洗、去重等操作提高文本提取的质量。
为此,本文提出一种基于Albert(A Lite BERT)和TextCNN(Text Convolutional Neural Network)的中文文本分类研究方法。其中,Albert 是一种预训练模型,文本数据首先经过Albert内部的双向Transformer 编码器获得相应的动态文本词向量;然后使用TF-IDF 算法抽取文本数据中权重最高的5 个词构建关键词表;接下来将关键词表与词向量进行向量拼接构成融合关键词信息的多义词向量,并将其作为TextCNN嵌入层的输入;最后实现多标签文本分类。
1 相关研究
1.1 词向量
词向量是文本数据向量化的一种主要表现形式,当前存在静态词向量和动态词向量两种。其中,静态词向量通过Word2vec 模型和Glove 模型获取;动态词向量则通过BERT(Bidirectional Encoder Representations from Transformers)模型获取。例如,Radford 等[3]提出Word2vec 模型包含Cbow 和Skip-Gram 两种方法,但均未充分利用语句间的整体信息。Penington 等[4]基于统计学词汇共现技术提出Glove 模型训练词向量,考虑了文本数据的全部信息。Devlin 等[5]提出BERT 预训练模型,通过注意力机制将任意两个单词位置间距转换为1,同时基于遮掩语言模型和句子上下文关系预测学习任务,能在海量文本数据中自主学习字符、语义级文本特征,并将学习到的文本特征向量应用于下游任务。Lan 等[6]提出Albert 模型改善BERT 训练参数过多、训练时间过长等问题。
1.2 文本分类
目前,机器学习和深度学习在文本分类中发展迅速,例如朴素贝叶斯方法[7]和支持向量机(SVN)。其中,朴素贝叶斯方法属于概率论分类算法,根据特征属性对某个对象进行分类;支持向量机通过简单的直觉和严谨的数学方法解决最小化问题,应用拉格朗日定理解决约束优化问题。
谢金宝等[8]提出一种基于语义理解的多元特征融合文本分类模型,通过神经网络嵌入各层通路,提取不同层次的文本特征表示。孙松涛等[9]使用卷积神经网络(Convolutional Neural Network,CNN)将文本内容词向量融合成句子向量,并将句子向量作为训练多标签分类器的语料。Long 等[10]采用多通道CNN 模型进行监督学习,将词矢量作为模型输入特征,可以在不同的窗口大小进行语义合成,完成文本分类任务Kim 等[11]提出文本卷积神经网络模型通过一维卷积获取句子中n-gram 的特征表示,通过卷积核窗口抽取深层文本局部特征表示。实验表明,该模型对文本数据浅层特征具有较强的抽取能力。
1.3 相关理论
1.3.1 TF-IDF
在中文文本数据中,词的重要程度与出现次数呈现正相关。其中,频数(Term Frequency,TF)为词在一个文本数据中出现的次数,逆文档(Inverse Document Frequency,IDF)用来衡量词的重要程度[12]。具体计算公式如下:
其中,N代表整个语料集中的文本总数,|{j:ti∈dj}|表示词ti在整个语料中存在的文档数。当一个词出现次数越多,IDF 值越小且无限趋近于0,为了避免零值,分母加上0.01。
1.3.2 Albert模型
模型内部Transformer 编码器使用编码特征提取器提取文本数据特征,特征向量经过双向Transformers 编码器获得相应的动态词向量输出。如图1 所示,输出向量包括两种形式,其中C={C1,C2,…,CN}表示初始输入文本数据中的字符,经过Albert 模型训练最终输出动态字向量特征表示Z={Z1,Z2,…,ZN}和CLS句子级别向量表示。

Fig.1 Albert model structure图1 Albert模型结构
Albert 采用基于Seq2Seq 模型的Transformer 编码器[13]提取各网络层的多头自注意力机制层[14]和前馈网络层。其中,对于前者通过b个不同线性变换对A、B、C 进行投影,拼接注意力结果;对于后者提供非线性变换,融合文本内容位置信息,并且每个子层都含有Add&Norm 层与上层相加后的输入与输出。
此外,将隐藏层归一化为标准正态分布,加速模型收敛速度,计算公式如下:
1.3.3 TextCNN模型
CNN 主要使用矩阵表示句子,特点是捕捉文本数据的局部信息[15]。具体的,利用矩阵的行代表单词或字符,即矩阵一行代表一个词向量。TextCNN 由CNN 衍变而来,主要用于文本分类领域,可设置过滤核范围对文本不同大小的局部特征进行组合和筛选。如图2 所示,TextCNN 包含嵌入层、卷积层、池化层和全连接层。

Fig.2 TextCNN model图2 TextCNN模型
(1)嵌入层。如图3 所示,该层将文本数据向量转化为指定大小,矩阵中每一行对应一个词。例如,句子X有n个词代表矩阵行数,则句子矩阵大小表示为:
其中,Xi为当前文本中的第i个词,⊕为向量拼接操作。
(2)卷积层。TextCNN 模型使用卷积核过滤器与输入层句子矩阵计算单位节点矩阵[16]。该矩阵能提取不同的层次特征,然后通过非线性激活函数得到特征映射矩阵C=[c1,c2,…,cn],特征公式为:

Fig.3 TextCNN convolutional layer model图3 TextCNN卷积层模型
其中,W为输出卷积核的权重矩阵,H为偏置参数,f为激活函数。
(3)池化层。目前,主要使用最大池化算法[17]拼接特征向量,构成一维向量表示以聚合重要特征,从而减少神经网络参数和特征向量个数,达到降维效果,在一定程度上也防止了过拟合现象。具体计算公式如下:
(4)全连接层。由于TextCNN 模型参数过多,为了避免过拟合现象发生,在全连接层加入Dropout 使神经元一定概率置0,减少网络对连接的过度依赖。然而,无论是前向还是反向传播,为了保持信息总量不变,需要根据Dropout概率进行修正补偿。
此外,在全连接层后接入softmax 函数层得到标签概率分布,具体计算公式如下:
2 基于词向量与TextCNN的多标签文本分类
为了高效管理互联网的海量中文文本数据,提出基于Albert 和TextCNN 的中文文本分类方法(简称为ATT),如图4所示。
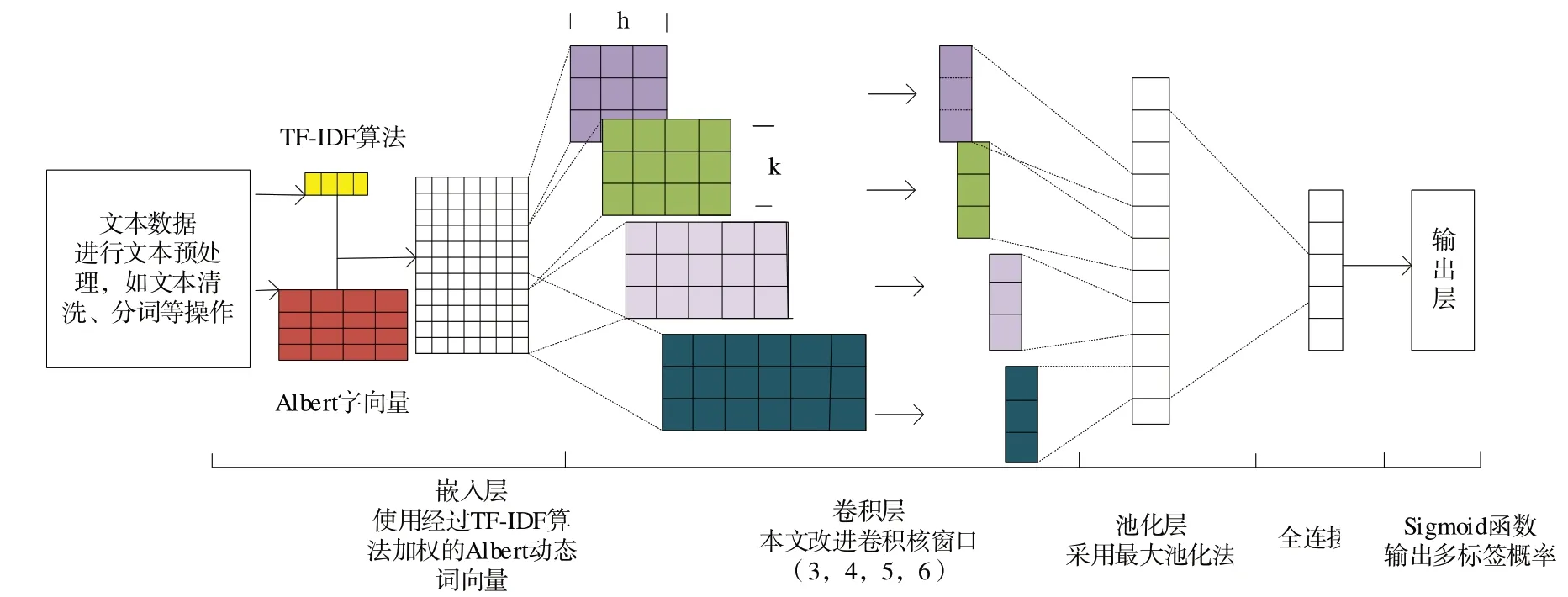
Fig.4 ATT model图4 ATT模型
该模型首先使用Albert 预训练模型获取多义词向量,基于TF-IDF 算法构建当前文档关键词表,通过向量拼接方法将两者融合成具有关键词信息的多义词向量。然后,将其作为嵌入层的输出和卷积层的输入,使用调整的卷积核窗口获取文本数据深层局部语义特征。最后,通过Sigmoid函数计算文本数据的标签类别。
(1)嵌入层。该层对文本数据进行预处理,包括数据清洗、分词等操作。本文在词向量上进行改进,使用纵向拼接方式进行向量拼接生成固定长度的维度矩阵。例如,首先训练得到一个DN×S矩阵,其中N为文本字符个数,S为Albert 代表的自定义维度;然后将TF-IDF 计算的关键词表构建成DM×S,选取M中前5个关键词组成关键词表,因此每个子文档不同关键词的TF-IDF 值各不相同;接下来将每个子文档的关键词信息进行拼接构成整个文档的关键词表;最后将预处理后的文本数据融合Albert-TF-IDF 词向量模型得到Oi:j=(O1,O2,…,On),并将其作为嵌入层输出。如图5所示。

Fig.5 Vector fusion strategy图5 向量融合策略
(2)卷积层。为解决中文文本数据的语言特点,基于hellonlp 对卷积层进行超参数调整。具体为,将卷积核的窗口大小h设置为3、4、5、6,使用不同大小卷积核捕获文本多字符特征和多个相邻字之间的隐藏相关性。具体公式如下:
其中,h为卷积核大小,Q为输出卷积核的权重矩阵,E为偏置参数,f为激活函数,Z为是卷积层提取到的特征向量。
(3)池化层。该层对卷积层的特征矩阵进行压缩,提取主要局部特征。本文采用最大池化方式获得主要的局部特征,丢弃部分次要特征,将计算结果拼接构成新矩阵,具体计算公式如下:
其中,Z为卷积矩阵,Y为最大池化后矩阵。通常情况下,新矩阵维度会变小,可为后续操作减少训练参数,如图6所示。
(4)全连接分类层。首先将池化层输出结果进行Sigmoid 函数归一化,得到文本标签概率分布矩阵R。然后,取出R超过设定阈值的索引得到中文多标签文本分类的结果。具体计算公式如下:

Fig.6 Maximum pooling model图6 最大池化模型
然而,当在多标签文本分类问题中使用Sigmoid 非线性激活函数时,为判断实际概率和期望值间的差距,需要使用交叉熵损失函数判定式:
其中,i为标签个数,n为Sigmoid 函数的结果,n∈[0,1],若Sigmoid 函数计算的值超过阈值,Ri=1。
3 实验结果与分析
3.1 实验环境
本文实验环境基于Centos 操作系统,处理器为AMD 3600 3.60GHz,内存为16G,显卡为RTX2080Ti,硬盘大小为512G。底层框架为Tensorflow,使用Python 语言编程。
3.2 数据集
通过爬虫技术在今日头条等网站爬取82 102 篇新闻数据。为了保证数据的有效性和真实性,去除低于200 个字符的文本数据,最后得到63 290 篇数据进行实验。然后利用各大新闻网站上的主题进行标签去重后得到30 个标签,设定验证集、测试集、训练集比例为1∶1∶8。
3.3 实验参数
在固定其他参数前提下,经过多次实验改变模型可变参数数值,得到最优参数如表1所示。

Table 1 Model parameters表1 模型参数
3.4 评价指标
为了比较不同模型的优劣,采用精确率、召回率、F1 对模型进行评估。P(Positive)代表1、N(Negative)代表0、T(True)代表正确和F(False)代表错误避免数字造成的歧义。其中,精确率(Precision)表示所有被预测为正的样本中,真正是正样本的百分比;召回率(Recall)表示在实际为正的样本被预测为正样本的百分比;F1即精确值和召回率的调和均值。具体公式如式(15)-式(17)所示:
3.5 实验结果
为体现本文模型的优势,在构建的中文新闻文本数据集中将ATT 与BR 算法[18]、CC[19]算法、Word2vec、Albert、TextCNN 进行比较。

Table 2 Model comparison表2 模型比较
由表2 可知,Albert、word2vec 模型的F1 值分别为83.77%和82.79%,说明Albert 生成的多义词向量特征向量多样化、代表性更高。Albert、ATT 模型的F1 值分别为83.77%和85.65%,说明融入TF-IDF 算法的关键词信息可避免Albert 生成词向量时丢失部分词。传统TextCNN、本文模型的F1 值分别为83.39%和85.65%,说明较大的卷积核窗口能理解中文文本局部上下文语意。
4 结语
本文提出一种基于改进的词向量和TextCNN 的多标签文本分类模型。其中,Albert 能更好使用双向编码器获取上下文信息,TF-IDF 算法抽取文本数据中权重最高的5个词构建关键词表,将关键词表与Albert 生成的词向量进行向量拼接,构成一个融合关键词信息的多义词向量。为了适用中文文本数据特点,通过调整卷积核窗口大小使TextCNN 更好地捕捉文本局部信息,避免丢失部分特征信息。在新闻评论数据集的实验表明,本文模型相较于基线模型效果更好,在一定程度上提升了训练效果。
然而,本文数据集仅来源于新闻评论,下一步将扩充实验数据集以提升模型的适用性和可靠性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年11期)2019-07-04
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
公民与法治(2016年10期)2016-05-17
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
