
基于实体对分类的联合抽取模型
2023-05-11 08:58朱天佑王路涛边靖宸陈振宇李继伟陈思宇刘普凡雷晓宇邓艳红
软件导刊 2023年4期
朱天佑,王路涛,李 博,边靖宸,陈振宇,李继伟,陈思宇,刘普凡,雷晓宇,邓艳红
(1.国家电网有限公司大数据中心,北京 100053;2.北京中电普华信息技术有限公司,北京 100089)
0 引言
随着国家电网有限公司数字化转型的不断深入,从海量业务数据中提取有效信息是强化数据赋能业务的关键[1]。实体关系三元组提取可从给定文本中提取(头实体、关系、尾实体)形式的所有关系三元组,其提取能力对知识挖掘、信息提取、图谱的构建与自动维护至关重要。目前,pipeline 与联合抽取方案被广泛应用于实体关系抽取任务。随着各种基线模型被陆续提出,三元组抽取能力与准确度不断提升。
1 相关研究
(1)pipeline 方案在实体关系抽取研究初期,研究人员尝试了分而治之的策略。首先提取给定文本的实体,即命名实体识别(Named Entity Recognition,NER)[2]子任务,然后确定实体间的关系,即关系分类(Relation Classification,RC)[3]子任务。经典的NER 模型采用线性统计策略,例如隐马尔可夫模型(Hidden Markov Models,HMM)[4]、条件随机场(Conditional Random Fields,CRF)[5]等。后期,Lample等[6]提出循环神经网络与条件随机场相结合的结构,Chiu等[7]采用BiLSTM-CNN 的架构,其已被成功应用于NER 子任务。
早期,关系分类任务大多基于统计方法。例如,Kambhatla[8]提出一种使用最大熵模型结合不同的词汇、句法和语义特征构建分类模型。Zhou 等[9]采用支持向量机(Support Vector Machine,SVM)进行关系分类。后期,采用深度学习方法。例如,Santos 等[10]提出CR-CNN 模型,该方法将每个词分为词向量和位置向量两部分,经过卷积获得整个句子的向量表示,在SemEval-2010 Task 8 数据集上F1-score 为84.1%,优于当时最好的非深度学习方法。
虽然,pipeline 方案具有易于执行、组件灵活配置等优点[11],但忽略了实体和关系间相互依存、不可分割的事实,可能会导致最终识别结果出现误差传播、泛化性能差等问题。
(2)联合提取方案。实体关系联合提取方法建立了任务间的关联,在一定程度上规避了基于pipeline 方法存在的问题,引起了国内外学者的广泛关注。根据不同的特征提取方式,联合抽取方法可分为基于特征工程和基于神经网络的联合抽取。基于特征工程的联合抽取需要根据数据特点设计特征。Kate 等[12]提出一个卡片金字塔图表示文本中的实体及其关系。Li 等[13]提出一种基于分段的解码器,以增量方式联合提取实体及其关系。虽然在简单文本抽取中基于特征工程的抽取方法取得了不错的效果,但该方法需要依赖其他自然语言处理(Natural Language Processing,NLP)工具,人工成本消耗巨大,并需要具备大量的领域专业知识。于是,深度学习工具被引入联合抽取模型中,通过基于数据驱动的深度学习方法规避了复杂的人工抽取特征。
基于神经网络的联合抽取方法自动抽取数据包含的特征,Miwa 等[14]首次采用基于神经网络的实体关系联合抽取方式,通过共享序列层和词嵌入层信息将实体对映射到对应的关系,实现了两个子任务间的交互,但难以高效解决关系重叠等问题,如图1所示。

Fig.1 Example sentences with overlapping relationships图1 关系重叠例句
关系重叠包含实体对重叠(Entity Pair Overlap,EPO)和单个实体重叠(Single Entity Overlap,SPO)。目前,解决关系重叠类型的三元组抽取,提升模型性能是研究重点。Yuan 等[15]采用基于关系的注意力机制优化句子特征表示,将关系提取映射到实体对的方式实现联合抽取,在一定程度解决了关系重叠问题,但基于关系识别出实体的难度较大,不利于泛化。随着预训练语言模型的普及,较新的研究方法包含基于Bert 编码器的级联模型[16]。Wang等[17]考虑了联合提取中token 对链接的问题,提出一种新的握手token 方法,但解码方式设计复杂。Zheng 等[18]提出将任务分解为关系判断、实体提取、主客对齐3 个子任务,但不可避免会产生误差传播问题。Shang 等[19]提出单模块单步框架优化网络结构,但仍然存在训练耗时长、占用内存较大的问题。
综上,尽管现有方法极大提升了实体关系的交互程度,但忽略了三元组提取过程中各元素的紧密相关度,并在处理关系重叠问题时召回率较低。针对上述联合抽取模型存在的关系重叠、模型性能差、模型结构复杂等问题,本文从新视角出发,尝试从分类后的头尾实体对跨度中直接解码出事实三元组。与文献[17]采用的基于预测实体引导的复杂解码器不同,直接对三元组整体结构进行建模,专注于从文本中提取实体与关系,以充分捕捉三元组各元素间的依赖关系,而非采用传统方法中基于某个元素来提取出其他元素的方式。
本文模型将初始文本送入预训练语言模型Roberta,获取文本token(经语言模型分词处理后的单词标记)嵌入表示。然后,基于关系枚举文本token,获得文本的token 对序列,并使用文本卷积神经网络和多层感知机整合token 对序列,获得其嵌入表示。接下来,采用分类器预测文本头尾实体的token 对标签。最后,基于关系和头尾实体的token 对跨度解码出事实三元组。该模型在基于远程监督方法生成的公共数据集NYT 上进行实验,取得了良好效果,其综合性能指标F1-score 达到92.1%,并且文本中包含的实体嵌套、关系重叠和多三元组情况准确度较高,证明了该框架在应对关系重叠三元组等复杂场景时的有效性。
2 模型构建
基于实体对分类的联合抽取模型从文本分类后的头尾实体token 对跨度中直接解码出事实三元组,该模型由4部分组成为:①文本词嵌入层,通过预训练语言模型Roberta 编码得到输入文本S={w1,w2,…wn}中单词wi的嵌入表示;②枚举并整合token 对表示层,将文本词嵌入层获得的token 嵌入两两组合成(vi,vj),重新编码token 对,并为每种关系构建一组token 对表示;③分类层,对每个类别的token 对嵌入表示进行标签预测,确定每种关系中每组token 对的所属类别;④解码层,根据分类层中对token 对所属类别的判断及token 对的分类标签,解码出事实三元组。模型总体结构如图2所示。

Fig.2 Network structure of joint extraction model based on entity pair classification图2 基于实体对分类的联合抽取模型网络结构
2.1 任务定义
给定一条文本S={w1,w2,…wN},N表示该文本共有N个词语;预定义关系表示为R={r1,r2,…rK},K表示共有K种预定义关系。
实体关系联合抽取的目标是识别文本S中所有可能的事实三元组T(S)={(hi,ri,ti)=1,hi,ti∈E,ri∈R},其中hi表示文本S的头实体,ti表示文本S的尾实体,E表示实体集,ri∈R表示预定义的关系,L表示文本S中三元组的个数。
2.2 文本词嵌入层
模型最底层为词嵌入层,该层将输入的文本词汇编码为嵌入向量,本文使用预训练语言模型Roberta[20]进行编码。模型输入序列S={w1,w2,…wN},由于Roberta 对单词使用BPE 标记器进行标记,可能会将一个完整的单词切分为几个token 片段,因此文本S输入Roberta 后将得到token级别的嵌入向量表示,具体数学表达式为:
其中,vi∈Rd,d为经过Roberta 表示后获得的token 级别的嵌入向量维度。
2.3 基于关系的枚举token对表示层
使用文本编码器Roberta 将文本S编码为token 嵌入后,将每条文本的token 两两组合,形成token 对。从文本内容的第一个token 枚举到最后一个token,以获得文本中所有token 的两两组合,形成token 对,即。其中,m表示文本S的token 数量,vi、vj表示token。
然而,真实的组合过程需将token 对应的嵌入两两组合,以获得token 对的长度为m2,因此对内存空间消耗较高。本文模型采用向后组合的方式,即token 对的组合只需要后一个token 的索引位于前一个token 索引的后方即可,通过,j>i表示一组token 对,得到组合token对的长度为m,其中m表示一条文本S中的token数量。如图3 所示,该图展示了文本首先被Roberta 划分为token 后,被两两组合为token 对的过程。
接下来,将token 对的嵌入表示相连接,首先采用文本卷积提取的token 嵌入连接后特征,然后利用多层感知机(Multi-Layer Perceptron,MLP)方式重新整合嵌入表示。
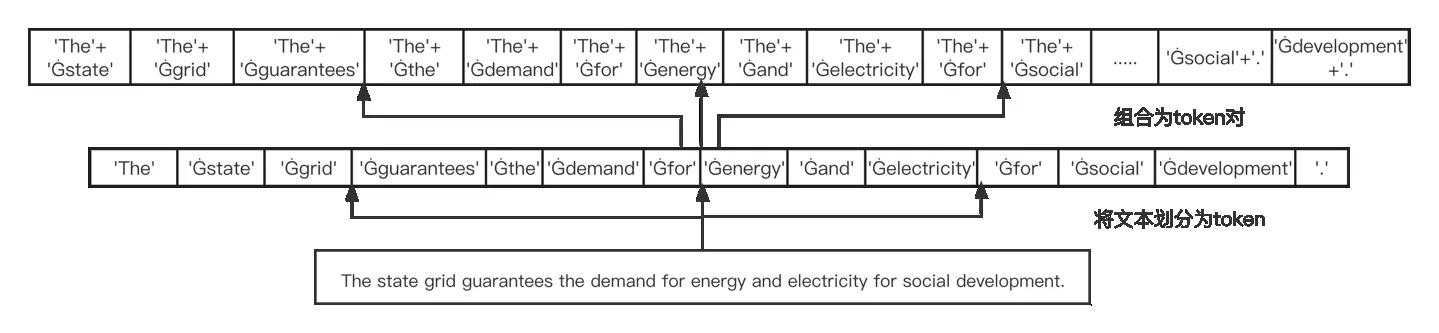
Fig.3 Token pair combination form图3 token对组合形式
其中,∅表示激活函数,Wv表示可训练的参数矩阵,Conv表示采用卷积,bv表示可训练的偏置。经过上述训练得到token 对的嵌入表示。
本文模型通过基于关系和边界token 确定实体,因此将每种关系得到的组合token 对复制两份,一份代表“HBto-TB”,另一份代表“HE-to-TE”。其中,HB(Head Entity to Begin Token)表示头实体的开始token,TB(Tail Entity to Begin Token)表示尾实体的开始token,这一组token 对嵌入表示将被用来预测每种关系中头尾实体对应的Begin tokens。例如,图3 中('The'+'Ġsocial')('The','Ġenergy')是关系'guarantee'和'provide'的“HB-to-TB”矩阵将要预测输出的内容。“HE-to-TE”中HE(Head Entity to End Token)表示头实体的结束token,TE(Tail Entity to End Token)表示尾实体的结束token,这一组token 对嵌入表示将被用来预测每种关系中头尾实体对应的End tokens。例如,图3中('Ġgrid'+'Ġdevelopment')('Ġgrid','Ġelectricity')为关系'guaranentee'和'provide'的“HE-to-TE”矩阵将要预测输出的内容。
2.4 分类层
经过基于关系的token 对表示可得到K×2 个组合token 对表示,其中K表示预定义的关系数量,直观而言就是枚举所有可能的(vi,rk,vj),j>i三元组组合。将这些组合token 对送入两个分类器,如式(3)、式(4)所示。通过一个分类器分类“HB-to-TB”矩阵,另一个分类器分类“HE-to-TE”矩阵,使用分类器获得“HB-to-TB”和“HE-to-TE”矩阵的token 对标签。
由于上述采用的是向后组合token 对的方式,因此会发生预测头实体位于尾实体后方的情况,受联合预测模型编码方式启发[17],本文模型将token 对标签设计为0、1、2,如图4所示。
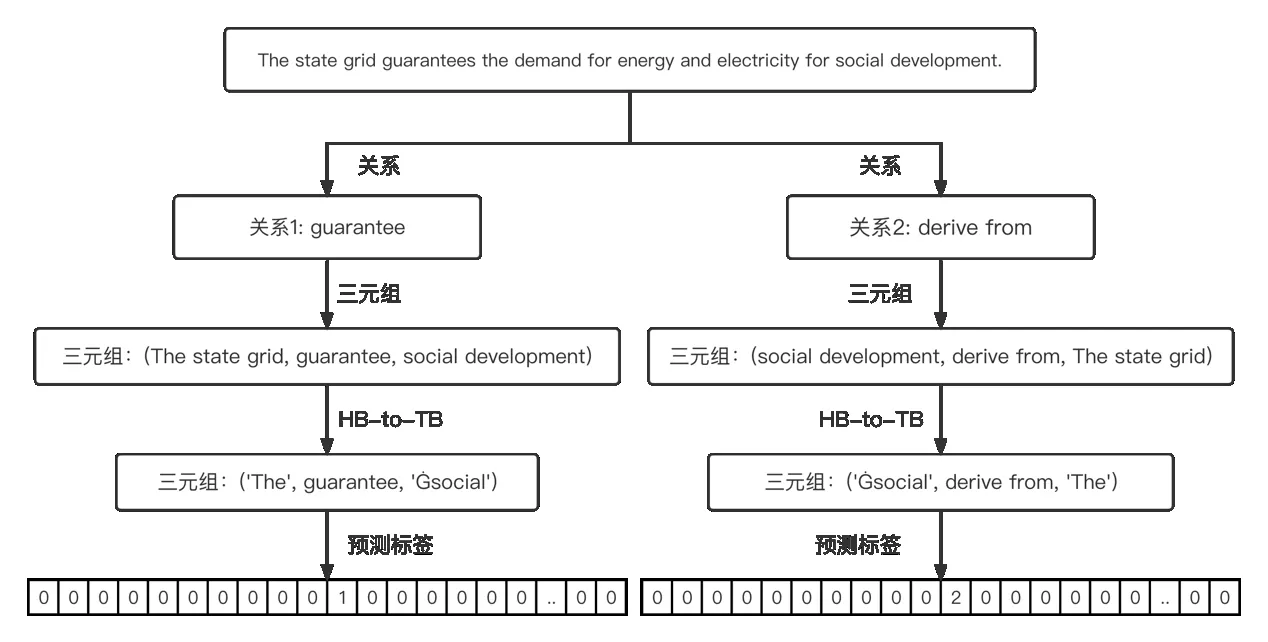
Fig.4 Examples of classification labels图4 分类标签示例
以“HB-to-TB”的token 对分类为例,0 表示该token 对不属于特定关系下头尾实体对的开始token 对;1表示该token 对属于特定关系实体对的开始token 对;2 表示该token对属于特定关系实体对的开始token 对,但该token 对中头实体位于文本S后方,尾实体位于文本S前方。图4 中('Ġsocial','The')并不存在图3 描述的token 对组合,因此token 对“HB-to-TB”矩阵的('The','Ġsocial'),在contains关系下对应位置标签被预测为2,通过该策略使得其在(vi,rk,vj),j>i的情况下仍能枚举到头实体位于尾实体后方。
2.5 解码层
解码层根据分类层预测的token 对标签及特定关系进行解码。具体的,由于每种关系均会被预测出两组矩阵“HB-to-TB”“HE-to-TE”,因此根据“HB-HE”的token 跨度解码出头实体,根据“TB-TE”的token 跨度解码出尾实体。此外,提取该关系类型便可解码出对应的事实三元组,具体解码策略步骤如图5所示。
由图5 可见,该解码策略可自然处理具有关系重叠情况的三元组。具体的,针对实体对重叠情况,对于不同关系预测出相同的“HB-to-TB”和“HE-to-TE”矩阵标签解码出实体对相同、关系不同的三元组。针对单个实体重叠情况,当两个三元组包含相同关系时,针对同一种关系预测的“HB-to-TB”“HE-to-TE”矩阵标签token 对中'HB''HE'相同,或'TB''TE'相同,同样可解码出正确的三元组,但该方式可能会发生预测实体冗余的情况。针对头尾实体重叠情况,例如(Bejing city,city name,Bejing),虽然预测出的“HB-to-TB“相同、“HE-to-TE“不同,但仍能被正确解码。

Fig.5 Decoding strategy steps图5 解码策略步骤
2.6 损失函数
由于该模型需要训练两个分类器,一个预测实体对的开始token,另一个预测实体对的结束token,因此损失通常由这两部分构成,他们均采用交叉熵方式计算损失训练损失函数。
3 实验结果与分析
3.1 数据集与评价指标
本文选用由远程监督产生的公共数据集NYT[22]验证模型的有效性,该数据集包含56 195 个训练文本,5 000 个验证文本,5 000 个测试文本。由于NYT 数据集中文本通常包含多个关系三元组和重叠模式,因此非常适合评估模型的提取能力。
本文根据关系三元组的不同重叠模式,将NYT 数据集分为正常数据(Normal)、实体对重叠数据(EPO)和单个实体重叠数据(SEO),如表1所示。

Table 1 Dataset information表1 数据集信息
表2 展示了NYT 测试集中三元组数量统计。本文遵循实体关系联合抽取模型常用的评价指标,采用标准的微精确率(Micro Precision)、召回率(Recall)和F1-score 作为评估指标量化模型优劣。

Table 2 Statistics of the number of triads in the NYT test set表2 NYT测试集三元组数量统计
3.2 实验环境与参数设置
本文实验在显存为32GB 的Tesla V100 GPU 上训练,基于pytorch 1.12.0 机器学习库。预训练语言模型使用Huggingface transformers 库中的Roberta(Roberta-base)获取词嵌入表示,生成词嵌入维度为768 维。训练集batch size 大小设置为24,学习率设置为5e-5,参数通过Adam 算法优化,并使用余弦退火方法调整学习率,最大长度设置为80。模型共训练了50 个epoch,保存在验证集上F1-score 最高的模型,在测试集上测试输出结果。
3.3 结果评估与分析
为验证本文模型的有效性,将其与TPLinker 模型[17]、CasRel 模型[21]、CopyRE 模型[22]、GraphRel 模型[23]等4 种基线模型进行比较。目前,最新的研究方法为PRGC[18]模型,研究过程中尝试复现该模型,但由于其占用系统内存过大,未能较好复现出该模型的应有效果,虽然该模型虽取得了最好效果,但内存量占用过大、训练效率较低,因此未作为本文的比较模型。上述基线模型在NYT 数据集上的结果均来自官方结果,如表3所示。
由此可见,本文模型相较于GraphRel、CasRel、CopyRE,在精确率、召回率和F1-score 方面均存在较大提升。具体的,在精确率方面分别提升30.2%、27.3%、1.5%;在召回率方面分别提升36.5%、33.1%、3.6%;在F1-score 方面分别提升33.4%、30.2%、2.5%。
本文模型相较于TPLinker 模型,在召回率、F1-score 方面分别提升0.6%、0.3%。尽管TPLinker捕获了三元组依赖关系,在精确率上略高于本文模型,但存在解码策略设计复杂、参数量大等问题。本文模型以牺牲微小精确率为代价,设计了更简单、快速的解码策略,可同时提取具有实体嵌套、关系重叠等情况的三元组。

Table 3 Comparison of effects of different models in NYT dataset表3 不同模型在NYT数据集效果比较 (%)
为验证模型处理一条文本中包含多个三元组的性能,本文在NYT 测试集8 种子集中,对模型在关系重叠模式下的三元组提取的性能进行实验验证,并与CopyRE、GraphRel、CasRel、TPLinker 这4 种基线模型进行比较,如表4所示。
由表4 可知,随着文本中三元组数量增加,CopyRE、GraphRel 模型的预测能力明显下降。当2≤N<5 时,Cas-Rel、TPLinker 预测能力呈增长趋势;当N≥5 时,CasRel、TPLinker 预测能力呈递减趋势;当2≤N<5 时,本文模型预测能力呈递增趋势;当N≥5时,本文模型相较于基线模型效果最好;当N≥2 时,本文模型相较于4 种基线模型,在F1-score 方面均有所提升;当N=4 时,F1-score 分别提升42.7%、41.2%、2.1%、0.2%,且在EPO、SEO 情形下的效果更优,这得益于本文模型的解码策略能充分抽取文本包含多三元组的情况。综上,本文模型相较于4 种基线模型能更好地处理关系重叠问题。
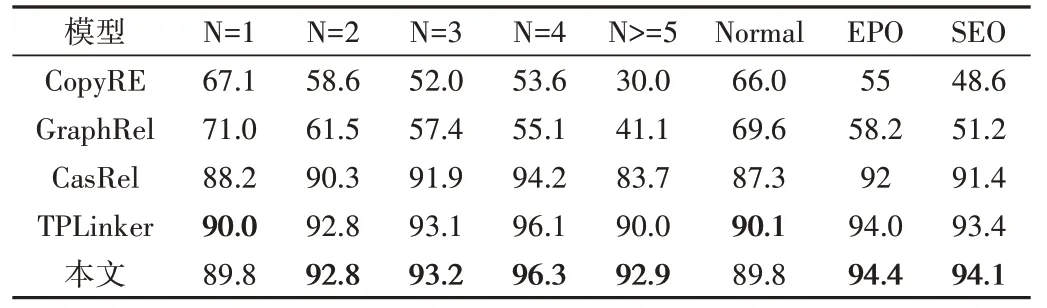
Table 4 Performance comparison of model processing multiple triples and relational overlapping triples表4 模型处理多三元组及关系重叠三元组性能比较
3.4 模型健壮性分析
为分析模型在不同应用场景下的健壮性,对本文方法进行案例分析,如图6 所示。该图展示了模型对初始文本中包含Normal、EPO、SPO 和多三元组情况的提取能力。

Fig.6 Model processing text multiple triples case图6 模型处理文本多三元组案例
由图6 可见,“Text1””Text2”均包含4 组三元组。“Text1”基本事实栏中第2、4 组三元组既为EPO 类型,又为SPO 类型;第1、2 组三元组为SPO 类型三元组;第3 组为Normal 类型三元组。“Text2”中三元组均既为EPO 类型,又为SPO 类型的三元组。在模型预测栏中可见本文模型对于“Text 1”预测正确3 组,但在”Text1”中将三元组(Bobby Fischer,nationality,Iceland)预测为(Fischer,nationality,Iceland),原因可能是模型未能较好地捕捉头实体的跨度,还需进一步完善模型实体跨度获取方案。“Text2”全预测正确。通过实验证明,本文模型在处理不同长度文本、不同三元组模式时的鲁棒性更强。
4 结语
本文针对实体关系联合抽取中普遍存在的实体嵌套、关系重叠及事实三元组各元素相互依存关系的问题,提出基于实体对分类的联合抽取模型。首先采用实体对分类方式获得token 对预测标签;然后对头尾实体token 对解码,同时抽取出三元组的实体和关系。实验表明,该模型采用实体对分类方式可充分捕获三元组各元素间的依赖关系,有效解决了实体嵌套、关系重叠等问题。
未来,将进一步优化模型训练效率,将模型应用于电网电力行业等亟需构建新场景业务领域知识图谱中,以充分发挥这些领域知识的价值。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
中国石油石化(2022年12期)2022-07-16
山西大学学报(自然科学版)(2021年1期)2021-04-21
中国外汇(2019年19期)2019-11-26
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
