
一种基于改进闭环检测的视觉SLAM算法
2023-05-08 03:01李振伟杨晓利
计算机应用与软件 2023年4期
赵 磊 李振伟 杨晓利 张 卫
(河南科技大学医学与技术工程学院 河南 洛阳 471000)
0 引 言
SLAM是指机器人利用相机、雷达等传感器探测周围环境信息,估计自身位姿,并对环境地图进行描述的一种技术[1]。机器人和计算机视觉的许多相关应用都要求能够快速获取环境的三维模型,并根据该模型估计相机的姿态,因此基于视觉的SLAM技术(vSLAM)引起了众多研究者的关注,vSLAM是未来机器人在复杂环境中能够完成诸多任务,实现智能化发展的重要技术。闭环检测作为SLAM系统的关键部分,能够有效消除前端里程计进行位姿估计时引起的误差,对长时间大范围内的机器人导航定位极为重要[2-4]。目前,对于基于视觉SLAM框架,国内外学者提出了许多闭环检测算法。
最直接也最准确的闭环检测方法是:对所有关键帧一一进行特征匹配,根据匹配结果得到最相似的图像。但该方法计算量大,在大规模的SLAM系统中无法满足实时性的要求。为此,基于外观的闭环检测方法被提出,该方法摆脱了前后端的相机位姿估计,使其相对独立于整个系统中的其他模块,已经成为了视觉SLAM中主流的方法。Mur-Artal等[5-6]提出的ORB-SLAM便是该方法的突出代表,其引入的闭环检测功能以及改进的关键帧选取策略使得该算法取得了非常不错的效果。王远配等[7]通过引入能够实现尺度不变性的ORB特征点,实现了较高的相似图像匹配率。李弋星等[8]提出一种关键帧的选择方法,对新插入的关键帧设定严格的阈值要求,提高了系统的处理速度和建图精度。Cummins等[9]通过Chow-Liu树对词袋模型中不同单词之间的相互联系进行了分析,提出了一种利用外观数据进行导航的概率模型。这些方法一定程度上都通过可以代表局部环境信息的关键帧进行整体优化,而关键帧的合理选择又能够为闭环检测模块提供更好的数据依据。对于目前基于外观的闭环检测算法,绝大多数都建立在词袋模型框架上,该框架为我们快速高效地查找可能存在闭环的图像提供了一个有效的工具。利用词袋模型及其对应的相似性度量方法进行候选闭环帧的选取对SLAM系统构建全局一致的地图有着十分重要的意义,但在这方面进行改进的工作并不多。
近些年来,视觉SLAM发展很快,在兼顾处理速度的同时还取得了不错的精度,但通过特征提取进行相机位姿估计仍占用了整个系统不少的时间。基于以上分析,本文利用深度相机进行图像采集,减少前端的计算量,对关键帧以及候选闭环帧进行合理删选,并改进词袋模型的相似性得分方法,减少感知歧义,最后利用ORB-SLAM2系统和标准数据集进行算法验证。
1 算法框架
本文的视觉SLAM算法整体框架如图1所示。相比SIFT和SURF特征,ORB在取得不错的精度的同时,还具有较高的计算速度,因此本文利用ORB进行图像特征提取。为了避免误匹配引起的误差,利用RANRAC算法[10]检测错误的特征点并进行剔除,并通过深度数据获取特征点的3D位置,结合PnP(Perspective-n-Point)算法[11]实现前端的相机位置估计。然后在词袋模型的基础上,利用本文改进的闭环检测方法识别闭环帧,并剔除错误帧,最后使用g2o优化工具对前端计算的相机轨迹进行全局优化,得到更为精确的轨迹和点云地图。

图1 SLAM系统框架
2 改进闭环检测算法
视觉SLAM前端仅仅通过图像匹配估计相机的大致运动轨迹,由于传感器本身会存在误差,加之部分场景中图像特征不明显,导致特征点对特征点的约束关系使得前端估计产生误差。该误差会随着时间的推移不断累积至下一帧图像,最后导致系统估计的地图与真实的环境相差甚远。而闭环检测则通过判断当前图像与历史图像的相似关系,为后端优化提供一种更强、时间更久远的约束,通过这种约束关系,可以有效地减少累积误差,得到更加准确的相机轨迹和地图。
目前普遍利用计算机视觉进行闭环检测的方法主要有三类,分别为:地图对地图[12]、图像对地图[13]和图像对图像[14]的匹配方法,Williams等[15]通过比较三种方法,得出最后一种方法的匹配性能最好。但将当前图像与所有历史图像进行对比的时间复杂度太高,不利于实时地图构建,因此词袋模型得到了广泛使用。该方法通过视觉单词对图像进行描述,能够有效地检测出闭环图像。但由于特征的分层投影步骤,使得传统的相似性得分方法存在一定的缺陷。另外,通过词袋模型聚类得到的单词向量只注重单词的存在与否,忽略了图像几何信息,容易发生相似图像误匹配的情况,影响闭环检测的准确率。
针对以上存在的问题,首先对前端提取的关键帧进行差分信息熵判断,剔除不符合条件的冗余帧,减少前端计算量,而且为后端优化提供更好的数据;然后利用词袋模型建立视觉单词树,并在文献[16]的基础上改进得分函数,得到大于相似度评分阈值的闭环候选帧;并利用改进的感知哈希算法对出现误匹配的闭环图像进行剔除,最终得到正确的闭环。
2.1 关键帧的筛选
相机采集图像的过程是连续的,而且采集频率较高,以Kinect为例,可以达到每秒30帧。如果没有对短时间内选取的关键帧进行合理筛选,会导致图像相似度过高,进而影响闭环检测的准确性。本文在ORB_SLAM2的关键帧选取机制的基础上,引入帧间位姿变化,选出满足条件的图像作为关键帧。
文献[17]通过比较当前帧与前一帧的信息熵差异和当前帧与前n帧差异的均值进行冗余帧的判断,该方法只比较了当前帧和历史帧,忽略了各历史帧之间的联系,容易出现误判,因此本文在此基础上提出新的冗余帧判断方法。设当前帧图像为Ii+1,上一帧图像为Ii,用当前帧减去上一帧,得到图像Ii+1-Ii,通过式(1)求得E(Ii+1-Ii)作为当前帧图像的差分信息熵,再根据式(2)判断该差分信息熵的大小程度,对具有较小信息熵的关键帧进行剔除。式(1)为信息熵计算公式,pi表示某像素灰度值为i时,该像素在整幅图像中的频率大小,式(2)表示当前帧差分信息熵是否小于之前的n帧图像中两两相邻图像之间的差分信息熵的均值,σ为均值系数。
(1)
(2)
2.2 改进的相似性得分匹配方法
词袋模型包括视觉单词字典的创建和相似度比较。利用Kmeans++算法对图像数据集进行特征分层聚类生成单词向量,但平面结构的词袋模型会导致特征搜索时间过长,因此本文采用k叉树结构来描述单词字典,词汇树结构如图2所示。

图2 视觉词汇树结构示意图
一颗分支因子为k,层数为d的字典树拥有的视觉单词个数为:
(3)
单词字典的容纳能力会随着层数的增加急剧增强,这样的字典树足以表征绝大部分图像。
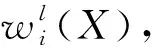
(4)
(5)
(6)
式中:TFi表示投影到树节点i上的特征数mi占特征点总数m的比例;IDFi表示节点i的权重;Mi表示至少有一个特征投影到节点i的图像数;M表示图像总数。由以上公式可得图像X在字典树的整体得分W(X)为Wl(X)的一个组合向量,而Wl(X)则是wi(X)的组合向量,Wl(X)表示X在字典树的各层投影得分(l∈{1,2,…,d},0层为根节点,无表征能力),wi(X)表示X在某层的各节点投影得分(i∈{1,2,…,kl})。
W(X)=(W1(X),W2(X),…,Wd(X))
(7)
Wl(X)=(w1(X),w2(X),…,wkl(X))
(8)

(9)
(10)
该得分函数通过计算两幅图像在同一层的各个节点的得分向量之间的欧氏距离来比较二者的相似性,采用分母加1再求倒数的方法,实现了归一化处理,而且得分越大,图像越相像。这样既减少了感知歧义,又保证了相似性计算的准确性。
根据文献[16],为了消除视觉字典树的相似性继承特性引起的得分继承误差,引入得分增量ΔS,并将第l层的增量ΔSl定义为:
(11)
文献[16]和文献[18]将金字塔匹配核定义为式(12),并由此得到最终的核函数:
(12)
K(X,Y)=K(W(X),W(Y))=Sd(X,Y)+
(13)
式中:1/pd-l为l层的匹配系数,用于调节不同层之间的匹配差异。但文献[16]和文献[18]并没有对p的取值进行详细分析,只是说明了p的大小和底层空间的相似性占比呈正比例关系。将式(13)展开可得:
(14)

K(X,Y)=Sd(X,Y)+
(15)
2.3 闭环候选帧的剔除
词袋模型通过逆序索引的方式可以得到闭环候选帧,但获得的候选帧中存在误匹配,错误的闭环会严重影响整个地图的结构,因此闭环帧的选择极为重要。均值感知哈希是通过将图像进行尺寸压缩,进而利用图像的低频信息来进行哈希值提取与图像相似性比较的一种算法[19-20],其在获得较高的准确率的同时,还具有极快的处理速度,可以用于闭环相似图像的判别。由于均值哈希算法压缩后的图像会失去绝大部分高频信息,对于高频信息变化更为明显的两幅图像来说会出现相似性误判,因此本文利用改进的均值感知哈希算法对错误的闭环候选帧进行剔除,具体步骤为:
(1) 图像尺寸缩小:将图像下采样至原来的1/n,并保留原来的纵横比。
(2) 将下采样后得到的图像变换为灰度图像。
(3) 求灰度图像各列的像素平均值pi,对pi相加求和,并计算平均值Mpi。
(4) 比较pi与Mpi的大小:大于Mpi的将其记为1,否则记为0。
(5) 哈希指纹生成:将第4步中得到的所有的0和1按照固定的顺序进行排列,得到哈希指纹。
相似度计算公式为:
1-H(hash(X),hash(Y))/Sp
(16)
式中:H(hash(X),hash(Y))表示图像X和Y生成的哈希值的汉明距离,Sp表示图像缩小后的列数。为了增强算法的鲁棒性,本文在相似度计算之前,增加了一项判定步骤:
|MPi(X)-MPi(Y)|>Q
(17)
若Q≥q,则表示图像相似度太小,直接剔除候选闭环帧;否则依据式(16)剔除相似度较小的候选帧。
3 实验结果与分析
本文实验使用的计算机配置为:CPU为Intel i5-3210M,主频2.5 GHz,内存4 GB,操作系统为Ubuntu 16.04。使用TUM标准数据集中的RGBD SLAM数据进行实验,RGB图像大小为640×480像素,本文算法中n为100,Sp为64,q为10。
3.1 改进的均值哈希算法测试结果
为了验证改进的候选帧剔除算法对于相似图像的有效检测性,分别从RGBD SLAM的fre1_desk、fre1_floor、fre2_large_with_loop(以下简称fre2_loop)、fre2_desk2数据集中选取20幅图像作为检测对象(数据集的部分图像如图3所示),其中:前5幅图像的顺序间隔相同,从中选取3幅图像作为闭环图像;后15幅图像中包含了部分与闭环图像相同的外观特征,顺序间隔大小不一。然后利用式(16)计算闭环图像与其余19幅图像的相似度,并按照由大到小的顺序选出前5幅图像,对该5幅图像进行判别,统计正确的图像个数,结果见表1。

(a) fre1_desk (b) fre1_floor

(c) fre2_loop (d) fre2_desk2图3 TUM数据集部分图像

表1 闭环检测统计结果
由表1的统计数据可知,对于fre2_loop和fre1_loop,由于场景中的低频信息占据了图像的绝大部分,随着相机的移动,图像低频信息变化不明显,导致均值哈希算法出现了较多的误判。而对于本文算法,除了fre1_floor中有一幅图像判别错误,其他几个数据集的相似图像都实现了准确的判别,而且算法耗时也略优。
3.2 轨迹误差实验
为了评判本文算法在实际SLAM系统中的运行效果,本文从TUM数据集中选取了4组深度相机数据集进行实验,每个数据集中都有真实的轨迹文件groundtruth.txt,便于进行算法优劣的对比。均方根误差(Root Mean Squared Error,RMSE)是评价SLAM算法的重要指标,文献[21]提供了计算RMSE的评估工具。
四组数据集中,除了fre1_floor不存在闭环外,其他三组都存在局部闭环或全局闭环。表2是本文算法与ORB-SLAM2和文献[22]中提出的RGBD-SLAM的均方根误差对比,可以看出,对于存在闭环的三组数据集,本文提出的算法都明显优于前两种算法,对于不存在闭环的数据集,本文算法也略优于前两者。图4是轨迹对比图,其中实线是高精度设备记录的相机运动时的真实轨迹,而虚线则表示本文算法估计的轨迹,可以明显看出本文算法得到的轨迹与真实轨迹是非常接近的。对于fre1_room,在特征点跟踪时出现了较长时间内的跟踪失败,对于fre2_desk,全局优化阶段出现了错误拟合,因此这两个数据集的轨迹误差相比fre1_floor和fre1_desk2有明显的增大。

表2 均方根误差对比 单位:m

(a) fre1_room

(b) fre2_desk

(c) fre1_floor

(d) fre1_desk2图4 真实轨迹与估计轨迹对比
表3是三种方法的时间对比。文献[21]采用了SIFT特征描述子进行特征提取,使得整个算法的耗时最长,实时性很差。而本文算法是基于ORB-SLAM2进行改进的,特征提取采用ORB描述子,相比ORB-SLAM2,本文算法在有效减少轨迹误差的同时,在处理速度上依然有略微的优势,完全能够满足系统的实时性需求。

表3 时间对比 单位:s
4 结 语
本文提出了一种基于改进闭环检测的视觉SLAM方法。该方法首先利用差分信息熵对视觉前端的冗余关键帧进行预处理,然后通过改进的金字塔相似性得分方法选取闭环候选帧,提升闭环识别率;并利用改进的均值感知哈希算法识别并剔除出现误判的闭环候选帧,提高闭环准确率。通过TUM标准数据集中的几组RGB-D数据集进行算法验证,计算轨迹误差和算法耗时,并与主流的视觉SLAM算法进行了对比,证明了本文算法对于消除累积误差,提高机器人定位精度的有效性和优越性。
猜你喜欢
大连理工大学学报(2017年4期)2017-08-07
黑龙江电力(2017年1期)2017-05-17
环境科技(2016年5期)2016-11-10
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
工业设计(2016年8期)2016-04-16
西北工业大学学报(2015年3期)2015-12-14
计算机工程(2015年8期)2015-07-03
系统工程学报(2015年2期)2015-02-28
电网与清洁能源(2015年2期)2015-02-28
计算机工程(2014年6期)2014-02-28
