
基于机器学习的早产儿视网膜病变高危因素分析
2023-05-08 23:34:00周鹏程左海维杨倩倩
电脑知识与技术 2023年9期
关键词:数据预处理
周鹏程 左海维 杨倩倩


关键词:早产儿视网膜病变;高危因素分析;LightGBM;数据预处理;特征优化
早产儿视网膜病变(retinopathy of prematurity,ROP) 是一种视网膜血管增殖性眼底疾病,占全世界儿童视力损伤和失明的因素的11%~45.8%[1]。由于ROP的病因和发病机制复杂,有效治疗的时间窗很短,因此需要尽快找到ROP相关高危因素。
影响ROP发生的因素很多,目前学术界公认的三大高危因素是胎龄、出生体重与氧疗[2],分析ROP相关高危因素主要的方法是倾向评分匹配[3~5]、Logistic回归分析[6-9]和回顾性统计分析等[10~13]等传统医学统计方法,其性能在很大程度上依赖于数据集样本和维度的数量,所能分析出的高危因素比较浅显,很难挖掘更深层次的ROP相关高危因素。随着人工智能的不断发展与成熟,机器学习算法为计算机辅助医学诊断与分析提供了有效工具。机器学习的优点是适合处理高维数据,对医学领域的先验知识要求较少,评估精度比较高[14]。鉴于此,本文综合分析ROP相关高危因素分析的研究难点,创新性地将机器学习LightGBM 模型应用到ROP相关高危因素的分析中,基于Light⁃GBM进行特征优化,挖掘ROP更多潜在的相关高危因素,验证机器学习方法在早产儿视网膜病变领域的应用价值,为医生提供诊断参考依据。
1 算法
1.1 LightGBM
本文考虑到ROP数据集具有维度高、样本少的特点,难于在小样本数据集中挖掘关键特征,因此本文使用机器学习应用领域中广经验证的LightGBM算法进行ROP相关高危因素的建模与分析,主要原因是LightGBM具有运行效率高、内存功耗小、模型精度高、特征降维速度快等优点。
具体优化:因为ROP数据分析存在维度很高的问题,需要对模型训练进行时空开销的优化,本文通过将数据存储在直方图中从而提升模型的整体训练效率和降低内存的占用;因为按层生长的Level-wise生长策略存在对同一层叶子节点不加区分所带来的一些没必要地计算开销的问题,需要对模型训练过程中的生长策略进行优化,本文使用Leaf-wise生长策略选择增益最大的节点进行分裂,极大降低模型的计算代价和提高模型的准确度;因为ROP存在数据集数据有限的问题,需要在样本少的前提下保持与精度之间的平衡,本文使用单边梯度采样算法从减少数据量的角度出发,仅使用大梯度样本和部分小梯度样本进行信息增益的计算,可以在ROP数据集中保持模型的高精度;因为在特征降维时通常需要将部分特征捆绑在一起,为了防止捆绑互斥特征造成信息丢失,本文使用互斥特征捆绑算法进行特征降维的优化。
1.2 Noise-student
Noise-student是一种半监督学习方法,其基本步骤是先在标记图像上训练模型并生成伪标签,然后在标记和伪标记图像的组合上迭代训练生成更大的模型。本文基于Noise-student思想设计最优特征集寻找方法,从零开始搭建最优特征集,分别进行特征添加特征删减,根据评判标准与容错值(rate) 之差的结果不断更新最优特征集。寻找最优特征集的评判标准基于训练结果受试者工作曲线(Receiver OperatingCharacteristic,ROC) 下方面积大小(Area Under所示。
其中count 为每一轮模型训练的次数,AUC 为每次模型搭建、训练、验证得到的AUC 值。基于Noisestudent思想的特征优化方法具体如表1所示。
2 实验
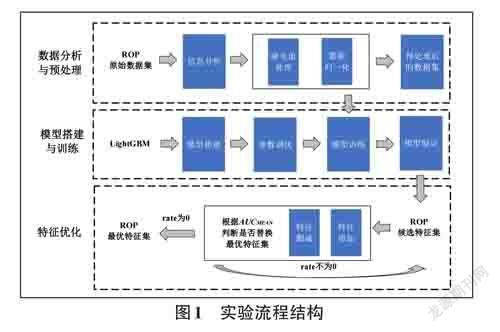
本文使用LightGBM进行ROP相关高危因素分析的实验流程结构如图1所示,依次完成了ROP数据集的基本信息分析与数据预处理,ROP高危因素分析模型的搭建、训练与验证,挖掘高危因素所进行的特征优化和对比验证。
2.1 数据集基本信息分析与预处理
数据集的质量很大程度影响模型的性能,需要对原始数据集进行数据预处理,本文采用的数据来源于医院ROP真实临床检查结果,时间跨度为2017年2月至2021年5月。为了清楚地了解数据集的基本信息,对单变量数据的基本信息进行分析,结果表明,数据共有141个样本,数据中有“性别12”~“是否治疗”共35个特征,数据类型有整数型(10个)、浮点型(34个)、字符型(1个)。
为了清楚地了解ROP数据集的分布情况,对数据集各特征变量数据的统计信息进行分析,结果表明,除了特征“ps”“窒息012”“IVH”的数据验证缺失外,其余特征的数据基本完整,此外还得知了该数据集各特征的平均值、标准差、最大值、最小值等信息,为数据预处理提供参考。
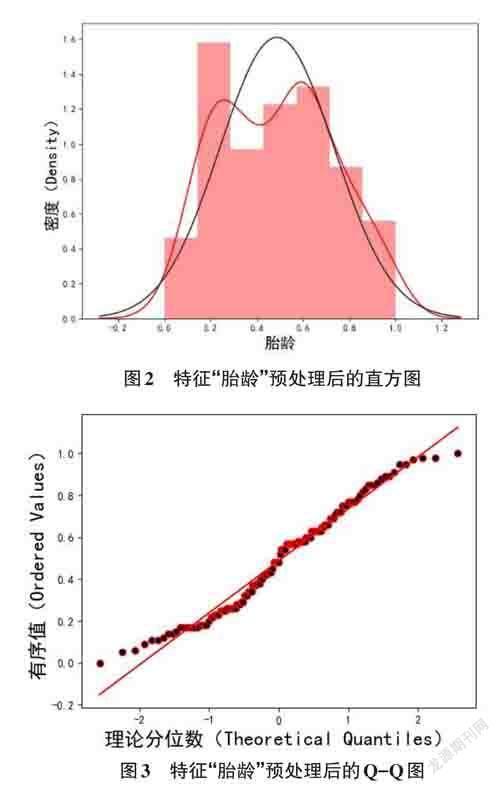
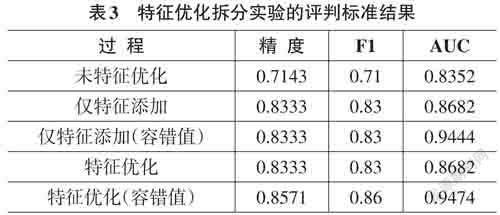
分析数据集的基本信息后,发现存在数据缺失、量纲不一致等问题。根据从数据集中识别出来的特征数据缺失的情况、数据的类型以及缺失值与目标变量的关联程度,使用计算该变量非缺失值的平均值进行填充,或直接成列删除该特征及其所代表的数据。对于字符型数据则进行数据编码,人为虚设十进制自增的自然数来反应该特征的不同属性,从而量化原本不能定量处理的特征。由于部分特征的取值量纲不统一,这将会极大影响估计,为了缩短特征数据之间的差距,使数据更加趋于正态分布,同时保持数据的完整性,使用区间缩放法将数据集样本映射到[0, 1]之间。最后对比参照数据的分位数与正态分布的分位数,查看数据是否符合正态分布,分别绘制特征的直方图和Q-Q图,特征“胎齡”预处理后的直方图和Q-Q图如图2和图3所示。可以看出预处理后特征“胎龄”的数据分布近似于正态分布,QQ图中的数据基本根据对角线分布,经过数据预处理后的数据集相较于原始数据集质量已经有了很大提升,可以足够适应接下来的模型训练。为了方便模型搭建与提高模型分析结果的准确度,本文还进行了设置图片显示字体、划分特征变量与目标变量、忽略代码警告信息、SMOTE过采样、切分训练集与测试集(8:2) 等准备工作。
2.2 模型搭建、训练、验证
进行ROP相关高危因素分析的关键所在是构建LightGBM 分类模型,使用网格搜索对learning_rate、n_estimators、num_leaves 进行参数调优,其中,learn⁃ing_rate用于控制模型训练性能,n_esti mators用于指定算法的迭代次数,num_leaves用于指定一棵树上的叶子节点个数,分别设置评估标准为AUC 值和进行5 折交叉验证。调优后得到的参数最优值如下:learn⁃ing_rate:0.2,n_estimators:20,num_leaves:10,然后对训练集进行模型训练。训练结束后计算模型的精度和F1值测试模型性能,精度为0.7142,F1值为0.71。为了使得测试的结果更加准确,计算模型的AUC 值。分别搭建1000次LightGBM模型,调整随机种子使得每次训练集和测试集的划分均不同,并通过控制KS值以防止模型发生异常。经过训练与验证后,发现当随机种子为547时的LightGBM模型AUC 值最高,为0.8352,而KS 值为0.4942也验证了该模型的优越性能以及确定了模型没有发生异常情况。
2.3 特征优化
计算原始特征集的特征重要性,以特征重要性≥1 的特征作为候选特征集,初始化rate为0.02,衰减值为0.002。经过10轮特征优化后,所得到的最优特征集为Apgar1、胎膜早破、胎龄、母亲年龄、Apgar5、败血症(E/L)、贫血E/L、氧时/d、Px、无创/d,且在第9轮后不再发生变动,其AUCMEAN为0.9189。
2.4 对比验证
使用LightGBM对最优特征集进行模型再验证,相关评判标准的结果如表2所示。可以看出,模型再验证的精度相对于优化前提高了20.00%,F1 相对于优化前提高了21.23%,AUC 值为相对于优化前提高了13.42%,KS 值为0.7460,低于0.75说明模型没有发生异常。
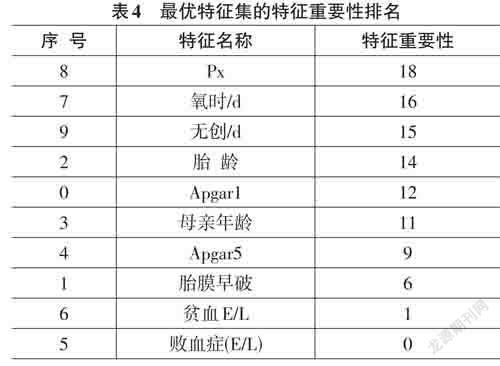
对特征优化过程进行拆分实验,分别验证未特征优化、仅特征添加和有无增加容错值的特征优化后的最优特征集在模型上的性能表现,如表3所示。可以看出,增加容错值的特征优化后的最优特征集在模型上的性能表现更加准确,其精度、F1、AUC 值都有所提升。
计算最优特征集的特征重要性,如表4所示。可以看出,最优特征集中的特征按特征重要性从高到低排分别为:Px、氧时/d、无创/d、胎龄、Apgar1、母亲年龄、Apgar5、胎膜早破、贫血E/L、败血症(E/L),对应的特征重要性分别是18、16、15、14、12、11、9、6、1、0,其中贫血E/L和败血症(E/L)相比于其他特征由于特征重要性太低,可能是特征优化过程中没有剔除出去的噪声。最终得出ROP相关高危因素为Px、氧时、无创、胎龄、Apgar1、母亲年龄、Apgar5、胎膜早破,其中氧时与胎龄与学术界公认的结果一致,母亲年龄、胎膜早破也符合临床医生诊断经验,而Px、无创、Apgar1、Ap⁃gar5则是通过机器学习挖掘出的ROP潜在相关高危因素。
3 结论
本文旨在基于机器学习进行ROP相关高危因素分析,对ROP原始数据集进行了基本信息分析和数据预处理后,建立了基于LightGBM的ROP相关高危因素分析模型,并根据该模型进行特征优化得到ROP最优特征集,即ROP相关高危因素,得出以下结论
1) 从数据集本身和模型训练的结果来看,本文使用的徐州医科大学附属医院的ROP数据集能够较好地反映ROP的潜在相关风险因素,利用胎龄、出生体重、高氧、氧时等34个特征作为LightGBM模型的输入特征,可以很好地挖掘出ROP的相关高危因素以及更深层次的潜在风险因素,其中,LightGBM分析模型的精确度达到0.7142,AUC 值达到0.8352,KS 值达到0.4942也证明了机器学习模型在早产儿视网膜病变分析领域處理高维度数据集的有效性;
2) 从模型再验证的结果来看,本研究对最优特征集再次进行LightGBM模型搭建、训练与验证后,经过LightGBM的特征优化所得的高危因素相对原始数据集的模型预测性能有了大幅提升,验证了特征优化过程的有效性和合理性,所得的最优特征集是通过机器学习模型特征优化后的ROP相关高危因素,其中大部分因素与临床医生经验一致,并通过对相关高危因素进行特征重要性排名,筛选出了潜在高危因素。
猜你喜欢
中国经贸(2017年16期)2017-09-22 06:37:55
现代农业科技(2017年15期)2017-09-15 16:59:52
数字技术与应用(2017年7期)2017-09-09 06:57:54
电子技术与软件工程(2017年7期)2017-06-05 08:46:47
科技创新与应用(2017年15期)2017-05-31 06:36:17
湖北农业科学(2016年22期)2017-04-12 23:25:16
科技视界(2016年27期)2017-03-14 22:45:40
现代农业科技(2017年1期)2017-03-06 12:59:21
中国市场(2016年41期)2016-11-28 05:30:48
电脑知识与技术(2016年10期)2016-06-16 21:32:52
