
基于改进的YOLOv3-SPP算法目标检测研究
2023-05-04 02:44洪毕辉李文彬王晓鸣张克斌
兵器装备工程学报 2023年4期
洪毕辉,李文彬,朱 炜,王晓鸣,张克斌
(南京理工大学 智能弹药技术国防重点学科实验室, 南京 210003)
0 引言
当今,随着深度学习技术的快速发展,在现代战场上智能弹药扮演着越来越重要的角色。从广义上讲,智能弹药是利用嵌入式系统将相关技术程序应用于无人机等移动设备上,装载相关弹药武器,能够在发射后实现简易具备察/打一体化能力,并通过一定的智能化技术完成命中目标的弹药武器。在执行相关任务中,关键的一点是利用机载摄影系统拍摄前方实时战况,对目标进行识别检测和定位,并及时将情况反馈给指挥人员。然而,战场上利用无人机对目标进行检测仍然面临着许多困难挑战:机载智能平台设备算力低下;无人机属于低、小、慢飞行器,容易受到周围环境干扰,其所采集到的目标容易受到环境光线和拍摄角度等影响。
目前基于深度学习的目标智能识别检测技术已成为新型智能弹药目标检测的主流技术中重要的一环。深度学习(Deep Learning)的概念由Hinton教授于2006年在《Science》提出,自此人类对于神经网络的研究进入了深度学习时代[1]。基于深度学习的目标检测框架主要分为两类,一类是基于Two-Stage方法,代表主流框架有R-FCN[2]、MaskR-CNN[3]、Fast[4]/Faster R-CNN[5]等,将检测任务分为回归和分类;另一类是基于One-Stage方法,代表的主流框架有YOLOv3-SPP[6]、YOLO9000[7]、YOLOv3[8]、SSD[9]等,同时完成检测和回归任务。2种方法各有所长,Two-Stage任务准确率比较高,但是相对的速度较慢,One-Stage能够达到实时性,然而在一定程度上牺牲了精度,董文轩等[10]得出One-Stage虽然在推理速度大幅提高,但是检测精度依旧是改进的主要内容。
为了提高智能弹药目标检测技术的算法性能,本文建立了一个包含多种地面军事作战单元的小型数据集,对数据集使用数据增强处理手段,使数据集更加贴近于军事作战环境,进一步增加了数据样本数量以提高模型的鲁棒性;基于One-Stage方法下的YOLOv3-SPP目标检测网络基础框架,采用K-means++[11]聚类算法提取数据集中适用于本文数据集的锚框,改善检测结果的最终误差;将DIoU[12]和Focalloss[13]分别作为预测框的定位损失函数和分类损失函数来降低正负样本对模型的影响,进一步提高算法的检测结果。实验结果表明本文提出基于改进的YOLOv3-SPP算法对复杂战地环境下军事目标具有更好的检测精度。
1 小型目标数据集建立
地面武器系统,是智能弹药打击的主要目标,为此本文选取地面目标作为首要打击目标,建立数据集,对YOLOv3-SPP算法进行改进研究。
根据陆地战场环境分析,整体军事行动单元可大致分为:以坦克为主的容纳攻防一体化的突击武器;以装甲车为主的供步兵机动作战用的装甲战斗车辆,用于协同坦克作战,快速机动步兵分队;以雷达为主的无线电波探测设备,能全天候工作是具备直接威胁的后方军事目标。然而,在真实作战环境中,通常会通过对军事作战单元采用各种伪装手段来提升生存能力,减低被探测到几率。
针对复杂战地环境下的整体军事行动单元,从互联网上下载多种复杂环境下目标图像,建立一个小型军事目标数据集。本文中所采用的小型军事目标数据集包括坦克、步战车、雷达以及为最后实物验证用普通小轿车等4类目标图像。数据集部分目标图像如图1所示。将数据集中各种军事目标按照8∶1∶1的比例划分为训练集、测试集、验证集。为方便后期进行深度学习训练,再利用开源软件LabelImg对数据集进行图像图形注释,将所需检测目标用方框注释。针对数据集将检测目标分为坦克、坦克炮管、步兵战车、雷达、轿车五类,其中坦克炮管作为坦克打击首要目标,进行专门的标注并识别。数据集注释以PascalVOC格式保存为XML文件,该文件包含了图像尺寸、目标类别及坐标等信息。

图1 数据集部分示例图像Fig.1 Sample images for the dataset
本文采用有监督学习单样本数据增强处理方法,增加训练样本的数量以及多样性(噪声数据),防止过拟合,提升模型鲁棒性。为了使数据集更加贴近于实际战地环境,兼顾无人机在前方可能会遇到各种不确定因素,针对军事目标会以任何角度任何方向出现在图片中,对样本进行镜像处理以增加样本存在更多角度;为提高在恶劣电磁对抗环境下的生存能力[14]采用高斯噪声对单样本处理。除此之外较为新颖的增强方式还有随机擦除(Random Erasing)[15]和Cutout[16]。
通过对军事目标数据集进行数据增强处理,将数据量扩增为原数据集的4倍。数据集具体信息明细如表1所示。
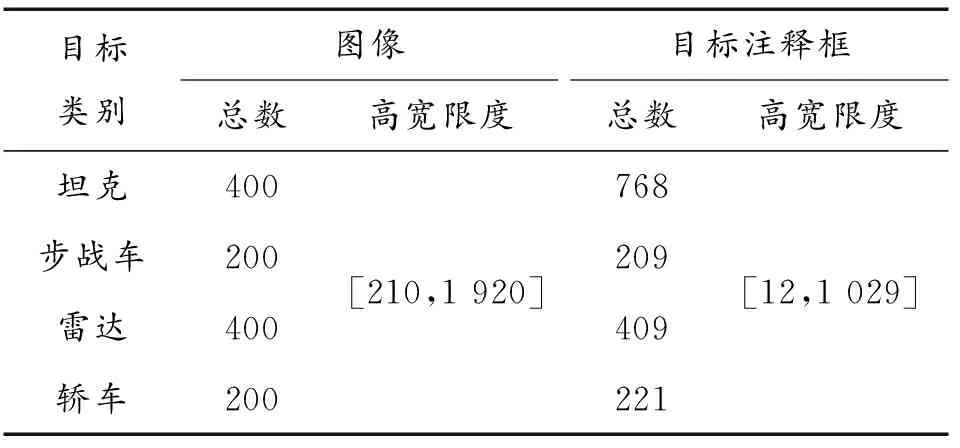
表1 数据集信息明细Table 1 Dataset information breakdown
2 YOLOv3-SPP目标检测算法改进
YOLO从2016年被Redmon等[17]提出开始,至今已发展到YOLOv5,其中以YOLOv3最为经典。YOLOv3主要分为特征提取和特征预测两部分。特征提取主体是一个Darknet-53网络,其大量使用残差(Residual Network)跳跃连接,去掉全连接层。为了降低池化带来的梯度负面效果,使用卷积下采样代替池化层,使YOLOv3成为一个全卷积网络,可以支持不同大小输入,支持全图end-to-end训练,更好的学习context信息。YOLOv3使用3种不同尺度对特征进行预测,并在3种尺度(13×13、26×26、52×52)上输出对物体的预测。与YOLOv3相比,YOLOv3-SPP是在第五、六层卷积之间加入一个SPP模块。该模块主要由3个最大池化层(5×5、9×9、13×13)和1个跳层连接组成,具体如图2所示。SPP模块借鉴了空间金字塔的思想,提取局部特征和全局特征,可以提升模型的感受野,有利于待检测数据集中目标大小差异较大的情况。在YOLOv3-SPP原始模型中,采用了MSELoss和BCEWithLogitsLoss两种损失函数,前者作为损失函数不能很好的区分预测框和真实框的位置关系,后者作为损失函数难以解决正负样本不平衡问题。因此,本文在YOLOv3-SPP框架基础上,改进锚框设计方法,将DIoU和Focalloss替换均方误差函数和交叉熵函数,进一步改善军事目标检测算法精度。

图2 SPP模块结构图Fig.2 SPP module structure diagram
2.1 锚框设计
YOLO系列自YOLOv2开始引入锚框(Anchorbox)机制,使锚框的生成不和以前一样靠经验所得,而是根据数据集中目标的真实框(Ground Truthbox)位置,使用K-means维度聚类[18]得到。因此算法仅需要在锚框的基础上进行微调即可得到与目标物体有良好的匹配的预测框(Predictionbox),这样模型可以更快的收敛,检测效果会更好。K-means聚类算法的思想就是对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇,随机选择K个聚类中心。簇内的点尽量紧密的连在一起,簇间的距离尽量的大。YOLOv3-SPP默认使用的锚框是在COCO数据集上使用K-means聚类得到了9个anchors。COCO数据集全称Microsoft Common Objects in Context,该数据集一个大型的、丰富的物体检测,分割和字幕数据集。图像包括91类目标,328 000影像和2 500 000个label。目前为止有语义分割的最大数据集,提供的类别有80类,有超过33万张图片,其中20万张有标注,整个数据集中个体的数目超过150万个[19]。可以说,默认使用的9个Anchors具有一定的适用性,但直接使用该锚框尺寸并不完全适用于本文的小型数据集,并且K个聚类中心位置的选择对最后的聚类结果和运行时间都有很大的影响。因此,为了更好的选取适用于本文数据集的锚框尺寸,选取K-means++算法来代替原有K-means算法。K-means++算法在K-means基础上优化了对聚类中心的选取,摒弃原来随机选择K个聚类中心的思想,改用随机从数据点集合里选择一个聚类中心,通过使用轮盘法[20]取到其余聚类中心。K-means++算法计算步骤如下:
步骤1从数据点中随机选取一个数据点作为初始聚类中心u1。
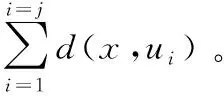

步骤4重复步骤2和步骤3,直到选出k个中心(j=k)。
步骤5在现有聚类中心基础上,继续使用K-means聚类。
最终得到9个锚框的尺寸分别为:(28,6),(80,11),(67,30),(76,73),(149,43),(129,111),(224,79),(301,129),(308,182)。
2.2 改进损失函数
YOLOv3-SPP损失函数Lall由定位损失函数Lbbox、置信度损失函数Lconf与分类损失函数Lcls组成,如式(1)所示:
Lall=Lbbox+Lconf+Lcls
⑴
MSELoss,也叫均方损失函数,用在做定位损失任务中。该函数的特点是光滑连续可导,方便用于梯度下降,但是MSE计算公式是模型预测值f(x)与样本真实值y之间距离平方的平均值,因此,离得越远,误差也就越大,受离群点影响很大。MSE计算如式(2)所示:
(2)
MSE用于做定位损失函数,需要计算预测框宽w、高h、中心点x、y的损失。这四者是需要解耦独立的,但实际上这四者并不独立,因此,将IoU系列损失函数用来能捕捉到它们之间的关系,IoU也叫交并比,是深度学习目标检测中常用的衡量指标,计算如式(3)所示:
(3)
式中:AP为预测框面积,AG为真实框面积。
它可以用来评价预测框和真实框的距离,很好地反映预测检测框和真实检测框的检测效果,拥有对尺度不敏感特性。但作为损失函数用来计算定位损失,会存在2个框没有相交的情况,根据式(3),IoU为0,不能反映两者的距离,并且因为损失为0,导致梯度没回传,神经网络训练收敛速度很慢,无法精确的反映两者重合度情况。为了避免这种情况,本文引入DIoU(DistanceIoU)损失函数作为定位损失函数。计算公式如(4)所示:
(4)
式中:ρ表示预测框和真实框之间的欧氏距离,aP和aG表示2个预测框和真实框的中心,c表示预测框和真实框闭包区域的对角线距离。DIoU损失函数设计了2个框之间的距离ρ作为惩罚项,使得检测效果更符合实际。c的作用是防止损失函数的值过大,加快神经网络训练过程,提高模型收敛速度,得到更准确的预测框回归结果。
BCEWithLogitsLoss和BCELoss,一组经常用到的二元交叉熵损失函数,常用于二分类问题,前后者区别在于后者的输入为经过sigmoid处理过的值。交叉熵损失函数计算如式(5)所示。在模型中,采用多尺度特征输出对目标做检测任务,模型输出包括13×13、26×26、52×52三种检测特征图,特征图中一个像素点为一个单元格,每个单元格会有3种检测框,因此会输出 10 647个检测框。但只有极少部分检测框会包含物体,所以大部分的候选框都会被认为是负样本。这种情况在检测小物体时会更加明显。因此在训练过程中正负样本数量差异过大,容易导致过多的负样本在训练过程占据主导作用,使网络模型无法得到有用信息,降低了检测准确率。

(5)
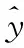
为了解决正负样本不平衡问题,引入Focal Loss函数。该函数基于交叉熵函数改进而来,引入加权因子α抑制正负样本数量的失衡,引入γ控制简单/难区分样本数量失衡。计算公式如(6)所示:

(6)
综上得,YOLOv3-SPP损失函数Lall如下:
Lall=Lbbox+Lconf+Lcls=

3 实验结果分析
3.1 实验环境配置与检测结果
将本文改进的YOLOv3-SPP算法在小型军事目标数据集上进行训练和测试,以验证其有效性。本文实验所使用的环境配置:实验均在Windows操作系统上进行,中央处理器为Inteli7-10750H,图形处理器为NVIDIA GeForce RTX2060,显卡内存为6GB,采用Pytorch+TensorFlow为基础框架,使用Python语言进行编程。
本实验采用平均精度(mean Average Precision,mAP)、准确率(Precision,P)、召回率(Recall,R)来评价模型检测的综合性能。平均精度是用来衡量训练模型在检测类别上的好坏程度,准确率表示预测为正的样本中有多少是真正的正样本,召回率表示样本中的正例有多少被预测正确了。定义分别表示为

其中:N为测试样本个数,p(n)为检测n个测试样本的精度值,TP表示为检测正确目标个数,FN表示为未检测出来的目标个数,FP表示为检测错的目标个数。
模型训练过程:在模型训练过程中,使用随机梯度下降法(SGD)进行模型训练,受到显存的影响,Batch-size大小设置为2,每迭代32步更新一次参数,初始学习率设置为0.001,权重衰减系数和动量因子分别设置为0.000 5和0.93,训练批次设置为200次。应用改进军事目标检测算法(YOLOv3-SPP-DFDA+)对复杂战地环境下军事目标小型数据集进行训练检测,其检测效果如图3所示。

图3 标检测算法检测结果示例Fig.3 Example of an object detection algorithm result
3.2 检测结果分析
图4展示的是模型在训练过程中的曲线变化,其中图4(a)表示检测精度,图4(b)表示平均精度,图4(c)表示召回率,图4(d)、图4(e)分别为训练损失和验证损失。黑色线代表原模型(YOLOv3-SPP,模型A)用无增强处理数据集训练的损失曲线;红色线代表模型(YOLOv3-SPP-DFDA,模型B)替换成DIoU函数和Focalloss函数(DF)后并对数据集进行数据增强处理(DA)的损失曲线;蓝色线代表模型(YOLOv3-SPP-DFDA+,模型C)引进K-means++锚框后的损失曲线;绿色线代表对比模型(YOLOv4-SPP,模型D)用增强处理数据集训练的损失曲线。横坐标表示训练批次,纵坐标表示损失值。

图4 模型训练过程曲线对比Fig.4 Comparison of model training process curves
通过对图中曲线的对比可以得出:
模型A→模型B:模型总体性能有了很大的优化,数据集的增强处理能够加快训练模型的收敛速度,增强模型的鲁棒性和泛化性,替换成DIoU和Focal Loss函数后进一步提高了模型的定位能力和分类能力,使模型检测精度提高了近3%,模型的召回率和mAP分别提高了近8%和10%,说明了模型对正确分类和能找到检测出来目标的能力都有所提高。
模型B→模型C:针对本文所创建的军事目标数据集使用K-means++得出的锚框系列,能够使模型预测框的回归效果更好,提高了模型的回归精度,在召回率和平均精度近乎不变的情况下,使模型的精确度提高了近6%,使得模型总体对目标的检测能力有所上升,可以更快的使模型收敛,检测效果更佳。
模型C→模型D:将文中改进后模型C与经典YOLOv4-SPP模型对比,可以得出模型C在训练精度、平均精度和准确率上均比YOLOv4-SPP训练结果来的更好,改进后的模型C更加适用于本文中建立的数据集。
实验证明,通过上述改进方法,可以有效提高模型的检测能力。
4 结论
本文中基于YOLOv3-SPP算法,将数据集进行数据增强处理,训练结果表明数据增强能有效加快模型收敛速度,增强了模型的鲁棒性和泛化性;针对预测框和真实框的位置关系、正负样本不平衡问题,将DIoU和Focal Loss替换原模型中的均方误差和交叉熵函数,训练结果表明改进函数能进一步提高了模型的定位能力和分类能力;使用K-means++聚类锚框算法替换原K-means聚类锚框算法,优化了对聚类中心的选取,得到更适用于本文数据集的锚框尺寸,训练结果表明对预测框的回归效果更好,提高了回归精度。
此外,本文数据样本及类别数量和种类都存在不足问题,并且模型训练得到的权重比较大,在后续的研究中,扩充数据集和对模型进行轻量化处理都将是本文研究的重点。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
中学生数理化·高一版(2021年2期)2021-03-19
今日农业(2019年15期)2019-01-03
知识经济·中国直销(2018年8期)2018-08-23
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
