
基于行踪标识量的跨监控探头轨迹预测方法
2023-05-04 03:00乔勇军王丽媛陈青华
兵器装备工程学报 2023年4期
袁 首,乔勇军,王丽媛,陈青华
(海军航空大学, 山东 烟台 264001)
0 引言
在智能监控、自动驾驶、航班飞行[1]等应用领域中,对监控探头中的轨迹进行预测是一个热点且具有挑战性的问题。但目前该领域的工作集中于单监控探头轨迹预测,即在同一监控探头视图下的未来预测,使得模型无法预测目标如何进入到新场景[2],并且限制在1~5 s的短期轨迹预测[3]。为了解决这个问题,首次提出了跨监控探头轨迹预测问题,即利用轨迹来预测目标接下来将在哪个监控探头中出现,何时出现以及在视图中的何处出现,这和以往的工作不同,之前使用轨迹信息进行行人重识别或是跟踪是后置性的,而这次是先验性的,便于监视人员提前做出预警和判断。
首次考虑在跨监控探头设置下的轨迹预测,其关联到数据集使用、行人重识别、监控探头轨迹预测等内容,而当前最新相关领域研究并不一定完全适用。在数据集方面,使用鸟瞰角度收集的行人轨迹预测的数据集如UCY[4]、ETH[5]、Stanford Drone等[6],只在单监控探头下适用;其他诸如Duck-MTMC等[7]多监控探头的数据集无法公开提供。因此对于本问题的应用场景,使用一个专门应对于跨监控探头轨迹预测数据集(across-monitoring vidicon trajectory prediction dataset,AMVTP)[8]。在行人重识别方面,绝大多数工作集中在图像级匹配上,只使用了视觉线索[5,9];在Market-1501[10]数据集上,rank 1的行人重识别表现从2015年的47.3%[10]提升到2019年的96.8%[11],但在匹配之前,必须首先对人进行检测和跟踪,需要在一个大型监控探头网络上同时运行,会造成计算成本的高昂;Wang等[12]证明,通过回溯性地利用轨迹信息和视觉特征,可以在流行的Duke-MTMC数据集上获得最有效的结果;但注意,以上的行人重识别均是后置性的,即在目标出现之后进行识别抓取,而非本文提出问题中先验预测性的考量。在单监控探头轨迹预测方面, Social lstm[13]、Social gan等[14]方式在结合池化层的影响时被提出;关注于通过提取社会交往特征的Sophie[15]则用来避免在群体运动中与他人的碰撞;从非最低点视点提取人体姿态[16]以及利用光流[17]也考虑到了将环境约束应用于轨迹预测。在多监控探头方面,考虑到包含检测、跟踪和行人重识别的大计算需求,将其应用在跨监控探头轨迹预测网络中是一个挑战。Jain等[18]研究了缩放监控探头跟踪对大型网络的影响,并表明将搜索空间过滤到高流量区域可以以很小的召回成本来减少搜索空间;Alahi等[19]设置密集的监控探头组来预测目标的出发地和目的地,其使用最低点视点和深度传感器在坐标空间来绘制轨道;乔少杰等[20]使用序列频繁扩展的方式来把阈值以上的连续轨迹作为轨迹值从而实现轨迹的预测匹配;Hsu等[21]反应性地利用了轨迹信息,使得跨监控探头视图匹配对象的次信息来源用于补充现有基于外观的模型。
基于此,以跨监控探头轨迹预测的新问题为背景,引入了行踪标识量的思想,提出了相应系统模型将问题予以解决。该问题包括目标接下来将在哪个监控探头中出现,何时出现,在视图中何处出现3个任务。解决问题的模型使用到了本文构建的用来代替坐标的行踪标识量,其可以将跨监控探头的视点划分为不同的网格单元,直观地为不同未来位置建模,且易于表示任意数量视点中的目标位置。最后通过搭建的模型,先验性的在物体进入下一个监控探头视图之前预测其未来一系列信息。实验验证表明,该方法可以很好地解决相关问题,并且对该领域的前期研究做出了一定贡献。
1 问题描述
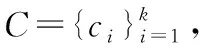
1.1 目标接下来将在哪个监控探头中出现
在给定的B(s-n:s)中,寻找C的一个子集,目标可以出现在将来任意的timestep中(最多为m),同时也可以在C中任意数量的监控探头中出现。这是一个分类问题,需要得到每个监控探头中出现目标的概率,P(ci|B(s-n:s)),ci∈C,每个预测的概率值均在0~1。更确切的说,输出的是一个长度为k的向量,[P(c1|B(s-n:s)),…,P(ck|B(s-n:s))]。
1.2 目标将何时出现
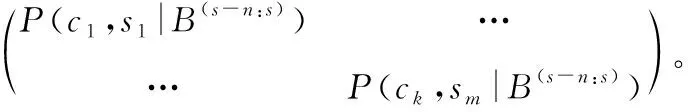
1.3 目标将在视图中何处出现
在上述两步的基础上,需要对目标进行空间定位。将每个监控探头的视图划分成长×宽为l×w的网格,并定义每个单元网格rxy中出现目标的概率为P(ci,sj,rxy|B(s-n:s)),其中x=1,…,l以及y=1,…,w。因而,本问题输出的是一个k×m×l×w的四维张量Z,包含概率P(ci,sj,rxy|B(s-n:s)),其中ci∈C,j=1,…,m,x=1,…,l以及y=1,…,w。
2 模型构建
将首先阐述行踪标识量的构建,再以此为基础针对问题提出相应的解决模型。
2.1 行踪标识量的构建
当下主流的轨迹表示是通过坐标来标记[13-15],如(x,y,l,w)s,表示在timestep为s时目标的位置以及长宽。但是这种标记方法有一定的缺陷,例如该方法不定义零轨迹,即当目标被遮挡导致检测算法失效时,坐标就不可用;同时坐标轨迹的方法只能表示从一个监控探头观察到的轨迹,除非所有对象均在所有监控探头中可见,也需要精确测量监控探头的位置以及内在的参数,但并不总是可以实现的;最后由于轨迹预测任务具有的确定性,导致无法应对目标在某一点可以有多个移动方向概率的多模态情形。
由于上述的不足,本研究中提出了一种跨监控探头的行踪标识量构建方式,来弥补缺陷,更好地服务于问题的解决,构建方式如下。
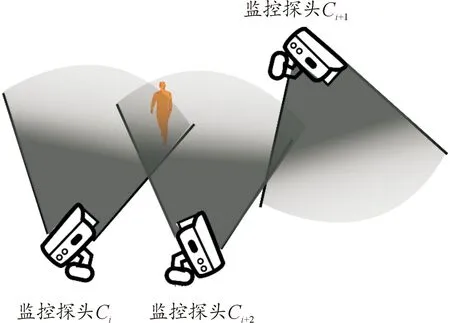
图1 目标出现示意图Fig.1 Target appearance diagram
2) 对于每个监控探头ci的视图,把其中检测到的目标用Bounding Box框出,并用Bi代表。如图2所示。

图2 各探头检测目标示意图Fig.2 Schematic diagram of each vidicon detecting targets
3) 针对每一个Bi,将其转化成大小为l×w的矩阵热图Hi,其中每个单元格都是一个二进制的值,用0和1表示其中是否存在该目标。目标可以依据其大小占有任意数量的网格单元,如图3所示。

图3 各探头矩阵热图示意图Fig.3 Matrix heat map of each vidicon
4) 将得到的k个监控探头矩阵热图按照监控探头尺寸堆叠,并沿m个timestep长度展开,使用高斯核平滑热值,使得每个单元格的值在0~1,最后得到大小为k×m×l×w的行踪标识量F。其表示在多个监控探头视图中的目标轨迹,可以表示的目标位置包括过去的输入和未来的预测。如图4所示。
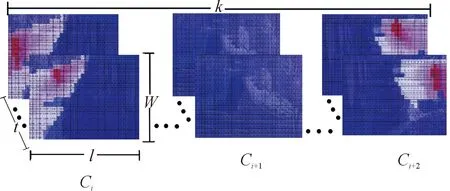
图4 行踪标识量F示意图Fig.4 Track identifier F schematic diagram
提出的行踪标识量,表示直观方便,可以代表空轨迹,取代了之前丢弃数据或者使用占位符值的方式;也可以在多个监控探头视图中展现;同时考虑目标的尺寸大小变化,使其可以占有多个网格单元,这是相比于以往单监控探头表示效果的提升。
2.2 解决模型的构建
定义一个解决跨监控探头轨迹预测问题的系统模型:AMVS+。接3.1的内容,基于行踪标识量思想所构建的模型需要对所有监控探头均可使用,这种统一化的思想使得解决“哪个”、“何时”、“何处”问题更加的简便,并且容易扩展。
如图5所示为AMVS+模型的整体架构图,其包含处理模块和预测模块两大部分,当带有矩阵热图的行踪标识量输入到处理模块后,基于预激活ResNet-200的3D CNN对其进行数据处理,之后把处理得到的信息传递到预测模块中,根据目的的不同经过FC层、1D-tCNN层或者3D-tCNN层输出“哪个”、“何时”以及“何处”问题的答案张量。
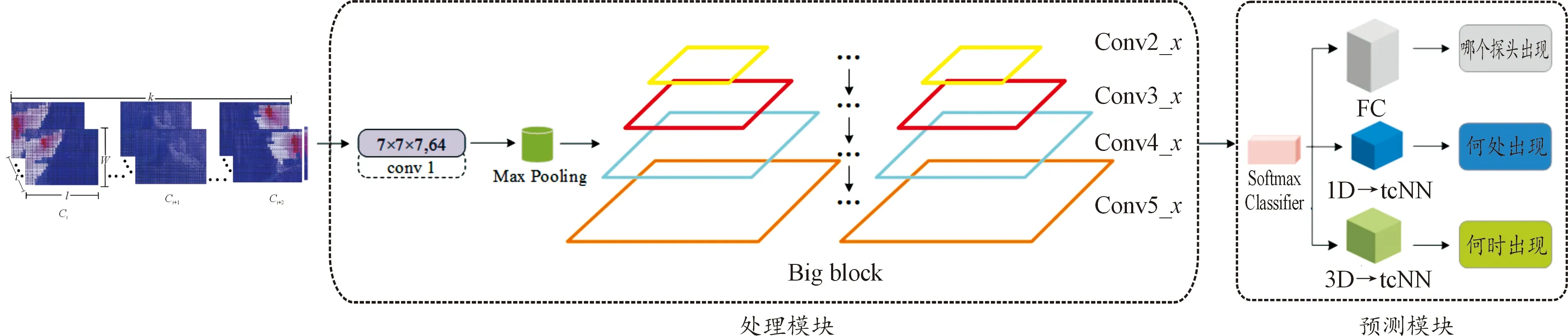
图5 AMVS+模型架构图Fig.5 AMVS+ model architecture diagram
2.2.1处理模块
处理模块由conv1、Max Pooling池化层和Big block三部分构成。conv1接收矩阵热图来进行卷积运算,其中卷积核大小为7×7×7,通道数为64,并以2个步长对输入进行时空下采样。之后采用大小为3×3×3的Max Pooling方法来对信息中有目标相互影响的情况进行综合分析,过滤无用信息,保留有用特征。得到的信息输入到Big block中进行最后一步时空采样处理,其是由经过预激活ResNet-200结构构成的一种3D CNN的组合,结构简单有效,基础模块命名为little block,如图6所示。
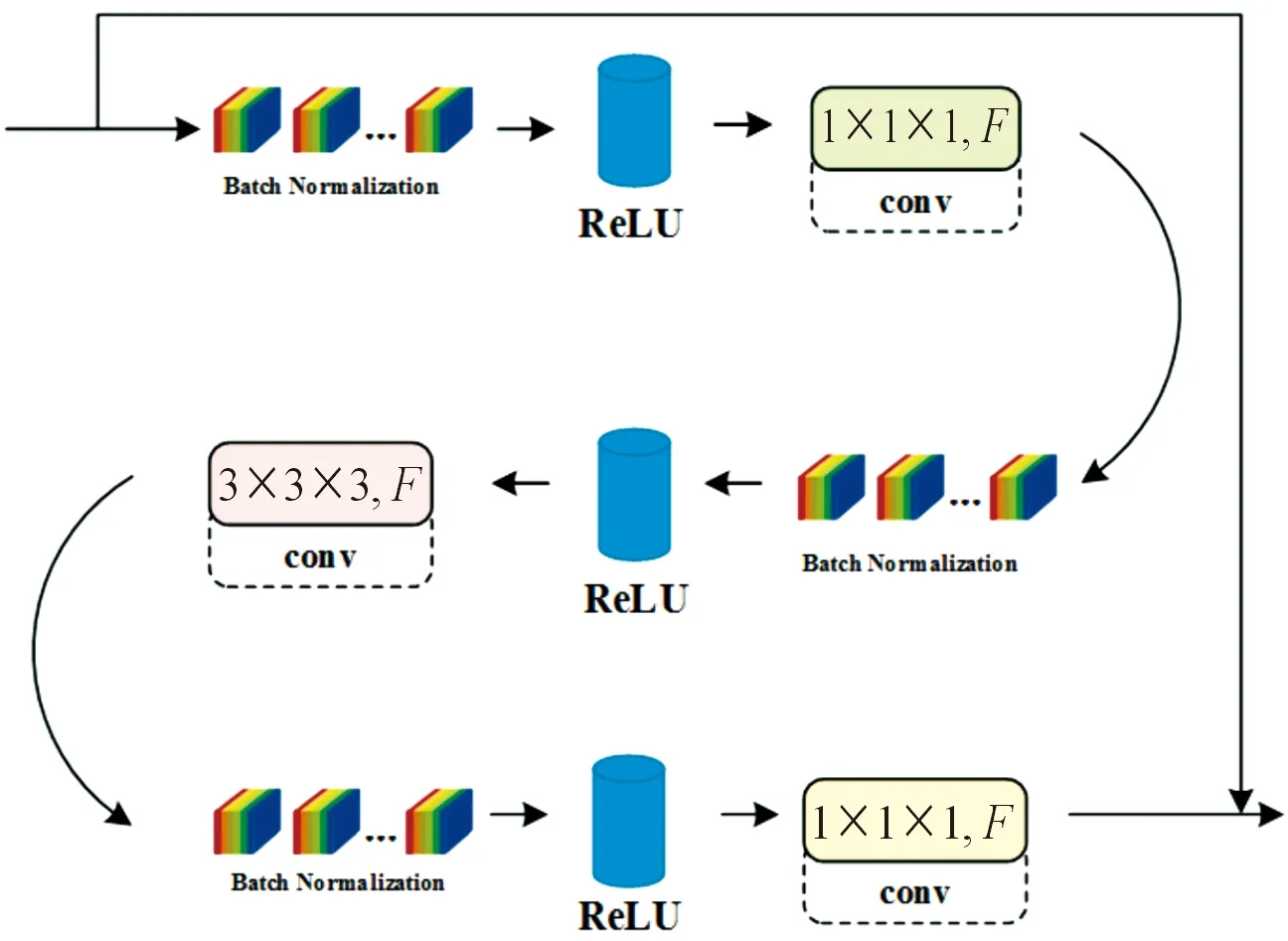
图6 little block示意图Fig.6 Little block schematic diagram
每一个little block都由3个卷积层组成。第一和第三卷积层的核尺寸为1×1×1,而第二卷积层的核尺寸为3×3×3。但是第3个卷积层的通道数是一和二的4倍,主要起到先降维减少运算量,后升维输出的作用。预激活ResNet架构按照Batch Normalization、ReLU和卷积顺序组成。shortcut pass快捷通道将块的顶部跳级链接到块中最后一个卷积层之后的层。使用的这种预激活方式,有助于优化训练,并减少过度拟合,而且由于这些连接通过网络的梯度流从后期层到早期层,可以促进非常深层网络的训练。先由little block按照通道和重复方式构成conv2_x、conv3_x、conv4_x和conv5_x四部分,其通道数F和重复次数N构成的数据对(F,N)分别为(64,3)、(128,24)、(256,36)、(512,3),再由这4部分顺序连接构成Big block。
2.2.2预测模块
3 实验验证与结果分析
实验采用跨监控探头轨迹预测数据集(AMVTP)进行可行性的验证,本章首先介绍数据集基本情况,之后给出相应的评估标准,继而对比基线和相关模型进行结果分析。实验运行在Windows 10操作系统,使用PyCharm编译软件,PyTorch 1.1.0,GPU为NVIDIA GEFORCE RTX 2080 Ti,使用Cuda10.1以及Cudnn v7.5.0进行加速。
3.1 AMVTP数据集
采用专门为AMVS+所构建的AMVTP数据集来训练评估本研究模型。该数据集选取了某基地在室内外架设的12个监控探头中10天360个小时的数据作为视频来源,包含了重叠和非重叠视图,当目标离开一个监控探头视图,然后会在不超过10 s后重新出现在另一个视图中,同时在此期间,目标也可以在任何数量的其他监控探头视图中可见。
在每个监控探头的交叉轨迹中只针对一个目标,目标之间的互动干扰由于平均每帧1.41个的低密度行为而受到限制。首先使用半自动的方法进行视频过滤,得到1.0 k个可以使用的视频,之后利用预训练的检测和跟踪算法生成目标的Bounding Box,并且通过选定IOU≥0.5来手动验证其准确性。为了避免数据采集周期长导致的跨监控探头轨迹唯一的问题,专门提供多视角偏离来为重叠的视角添加新的注释,并且手动参考监控探头的拓扑图和时间戳来舍弃错误的匹配。
在实验中使用5-fold交叉验证来评估每个模型,验证集和测试集的记录时间与训练集不同。在每个fold中,选择6 d进行训练,剩下的4天被分成相同大小的验证集和测试集。针对基于神经网络的学习方法,每种都训练了10个epoch,batch size值选用16,学习率为1×10-3,全连接层之间的dropout系数设置为0.2。
3.2 评价指标
考虑到该模型是针对3个问题,即将在哪个监控探头、何时、何处出现,因而结合高不确定性和多模态性,评价指标也将从3个方面进行考量,按照哪个、何时、何处的顺序,对应的下标依次为1、2、3。
3.2.1哪个监控探头中出现
由于本文根据目标在单个监控探头中的轨迹预测接下来其会在哪个监控探头中出现,关注点是目标接下来出现的监控探头的正确性。因此,在本研究中采用直观的评价方法,计算所有模型问题的平均精度(AP),得到AP1,并且绘制precision-recall曲线(PRC)。之所以不采取受试者工作特征曲线(ROC),是因为在本实验中正例(对象存在)和负例(无对象存在)样本比例悬殊较大,ROC在这种情况下表现的过于完美,而PRC则可以正确反映问题。
因而在“哪个监控探头中出现”问题中,评价指标为AP1。
3.2.2何时出现
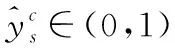
(1)
表示有目标出现的所有监控探头的预测与真值timestep之间的时间重叠。
证明较为直观,假设目标在某监控探头中被探测到,接下来便会有模型预测得到的此时timestep以及目标现实中运动到同一时间的未来timestep,将二者相比得到的结果便是此时预测与真值的时间重叠,将其扩展到所有监控探头,便可以得到一个0~1的比较值,即目标出现的所有监控探头的预测和真值timestep之间的时间重叠,来细化表明预测结果的好坏。
因而在“何时出现”问题中,评价指标为AP2和COM2。
3.2.3何处出现
该问题也继承4.2.1提出的评价指标AP3,并且针对4.2.2提出的COM公式进行如下修改,提出COM3,其中重复出现的标识解释同COM2,R+和R为预测和真正目标所在的网格单元集合。则:
(2)
计算所有监控探头和timestep的预测和真值网格单元位置之间的空间重叠。
证明如下,假设目标在某监控探头中被探测到,接下来便会模型预测得到的未来目标出现网格单元以及现实中目标运动到的网格单元,将二者相比得到的结果便是此时预测与真值的空间重叠,将其扩展到所有timestep以及所有监控探头,便可以得到一个0~1的比较值,即所有监控探头和timestep的预测和真值网格单元位置之间的空间重叠。
目前主流轨迹预测[13-15]采用标准平均位移误差(ADE)和最终位移误差(FDE)为评价指标,也采用这样的方式来评估,但需要根据问题的实际做出如下更正。按照ADE和FDE定义的公式,需要计算得出矩阵热图Hi的单个坐标值,方式是通过计算重心Axy来得到。
(3)
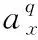
因而在“何处出现”问题中,评价指标为AP3、COM3、ADE3和FDE3。
3.3 实验模型的创建
根据跨监控探头轨迹预测问题的特点,构建了以下基线作为对比。
1) 实际距离最短法。依照实际探取到的监控探头之间的物理距离,预测目标会出现在距离最近的下个探头中。仅适用于“哪个”问题。
2) 轨迹最相似法。在训练集中找到与当前观测到的轨迹最相似的那个,并预测二者具有相同的轨迹,目标继而进入相同的下一个监控探头中,时间与位置也同样。
3) 训练集均值法。针对某一个特定监控探头所有训练集的观测值做处理,并且取其ground truth标签的均值作为结果。
4) Hand-crafted特征法。从Bounding Box中提取素材,构建了10维Hand-crafted特征。包含x和y方向的速度,x和y方向的加速度,最后观察到的Bounding Box的高度和宽度,以及它的4个坐标。根据监控探头捕捉到的二维坐标系统计算所有特征,并用全连接层对其进行分类。除此以外,使用归一化的Bounding Box坐标作为输入,为每个监控探头采用一个单独的网络模型,应用于3个不同问题。
同时对比文献[8]中的AMVS模型。
5) AMVS-GRU。如文中所示,并做了扩充。针对“何时”任务,使用另一个GRU作为解码器,它有128个隐藏单元,后面是一个全连接的分类层。在“何处”任务中,译码器GRU之后是2D-tCNN层,用于空间上采样。
6) AMVS-LSTM。在原模型的基础上后续增加同上。
本文模型。
7) AMVS+。构建方法同3.2。
3.4 实验与分析
3.4.1实验设置
提出的AMVS+模型可以在所有监控探头中共同使用,因此需要较大的表示能力。在保持视频帧的原始纵横比的情况下,需要对输入热图Hi大小进行考量,有16×9、32×18和48×27三种可供选择。热图尺寸越大,模型的表示能力就越强,但代价是参数数量越多,而且容易过度拟合训练数据。因而,决定使用32×18的热图尺寸。此外,用于平滑的高斯滤波器核大小应介于0~4,平滑通过减少检测和跟踪阶段错误的影响从而具有正则化效果。依据热图的尺寸和实验目标,通过交叉验证选取不同值使得结果最好。在“哪个”和“何时”问题中,核大小使用2;在“何处”问题中,核大小使用4。在预测模块均使用了Sigmoid激活函数和二元交叉熵损失函数进行训练。激活的二分类会将每个输出映射到0~1之间的值,表示每个监控探头中目标出现、时间以及位置的概率。使用Adam优化器,学习率为1×10-4,提取大小为512的特征向量,并且使用batch size为64进行训练。需要注意的是,在“何处”问题中,使用热图尺寸大小32×18,因此,输出行踪标识量的大小为[12×60×32×18]。不将高斯核平滑应用于行踪标识量目标的ground truth。使用转置卷积层对提取的特征向量进行上采样,以行踪标识量输出来表示目标未来的位置。
3.4.2结果分析
1) 针对于“哪个”问题
实验模型的AP1如表1所示,对应的PRC如图7所示。
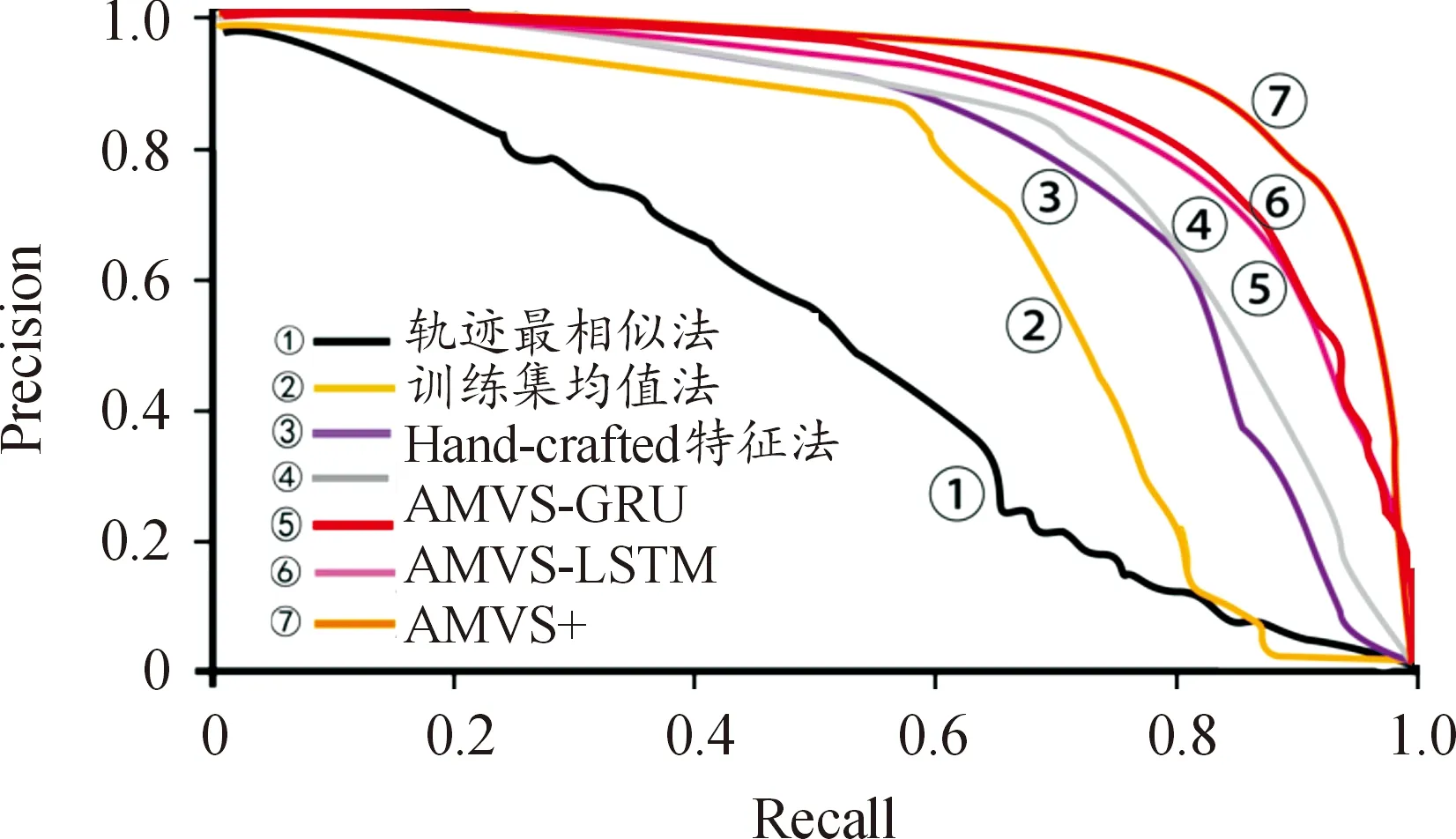
图7 各模型的PR图Fig.7 PRC of each model
从结果可以看出,相比于基线和AMVS方法,本研究的AMVS+模型在数据集上取得了很好的效果。AMVS+模型的AP值比实际距离最短法提高了82.3%,比轨迹最相似法提高了30.4%,比训练集均值法提高了17.3%,比Hand-crafted特征法提高了14.1%,比AMVS-GRU和AMVS-LSTM的平均AP值提高了3.2%。可以发现,结果分成3个区间,基线方法由于自身结构简单导致分类滞后以及过于依赖数据集本身而忽略现实条件等问题,导致在训练集上效果一般,无法适应复杂的情况。比如实际距离最短法的AP值最低,是因为过度理想化,好比2个监控探头离得最近但是分别在室内外,目标也不可能穿透墙壁而进入。AMVS方法的效果已经足够优异,但AMVS+从提高分类精确度的目标出发,前移了池化层位置、增加了预激活ResNet-200层中的卷积运算次数并且深度使用Sigmod进行二分类,可以在保证训练质量的同时减少过拟合情况的产生,在计算成本增加不多和实时性差别不大的前提下,既提高了结果的精确度,也证实了AMVS+模型的高度可扩展性,为解决“何时”和“何处”问题奠定了基础。
2) 针对于“何时”问题
实验模型的AP2和COM2结果如表2所示,AP值对应的PRC如图8所示,与3)的COM值对比如图9所示。
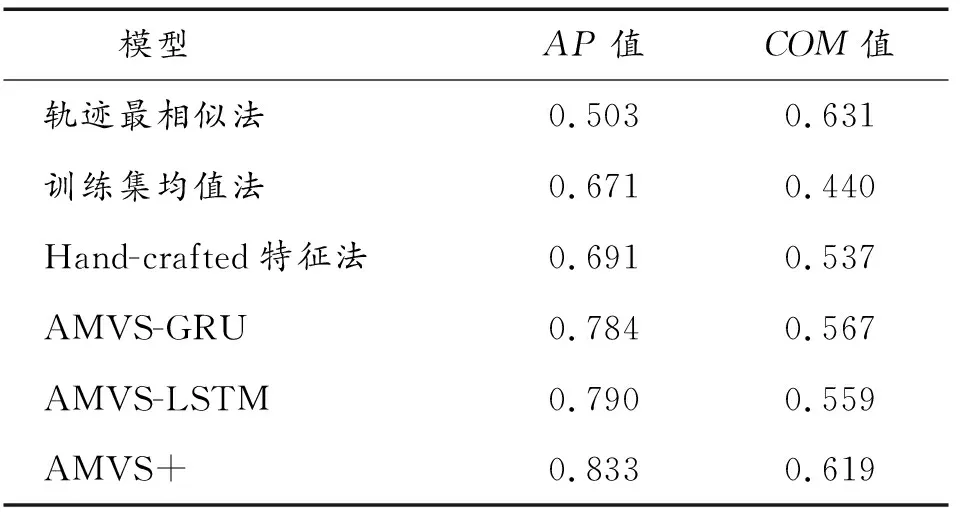
表2 各模型的AP值和COM值Table 2 AP and COM values of each model
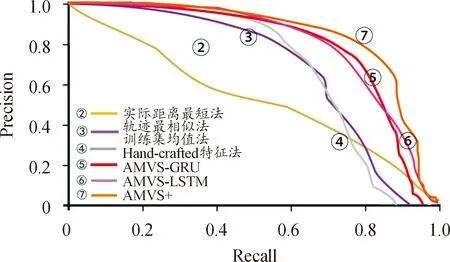
图8 各模型的PR图Fig.8 PRC of each model

图9 2)和3)的COM值对比图Fig.9 Comparison of COM values on 2) and 3)
从结果可以看出,AMVS+模型在AP值预测方面依旧表现突出,比基线方法平均AP值提高了34.0%,比AMVS方法平均AP值提高了5.9%,这和“哪个”问题的结果相似,原因便不再重复。在COM值方面,轨迹最相似法取得了最好的结果,AMVS+模型紧随其后,差距仅为0.012。分析原因,因为COM值反映的有目标出现的所有监控探头的预测与真值timestep之间的时间重叠,或者说时间timestep的占比,而轨迹最相似法在训练中不断地学习已有的路径,在数据集相对不大的条件下容易获得较好的结果。从另一个方面看,在这种不利条件下AMVS+模型性能也紧随其后,说明选用转置卷积使得该模型有很强的适应性以及可用性,又在侧面证实其优势。训练集均值法效果一般,主要是由于其对某一个特定监控探头所有训练集的观测值进行处理,而数据集中监控探头数目较多,容易出现相互干扰,尤其在处理二维的时间序列时不利于做出正确的结果。AMVS模型表现依旧稳定,其在最后预测模块采用的结构与AMVS+类似,主要的差距点是之前模块的结构,相关原因已经在“哪个”结果中做出了解释。还需要注意的是,某些基线(如训练集均值法)在AP2方面表现良好,却在COM2方面表现不佳,这说明有效地预测目标在正确的监控探头中出现和在监控探头中可见的正确时间窗口不一定总是同时发生。
3) 针对于“何处”问题
实验模型的AP3、COM3、ADE3和FDE3结果如表3所示,AP值对应的PRC如图10所示,与2)的COM值对比如图9所示,ADE和FDE值对比如图11所示。
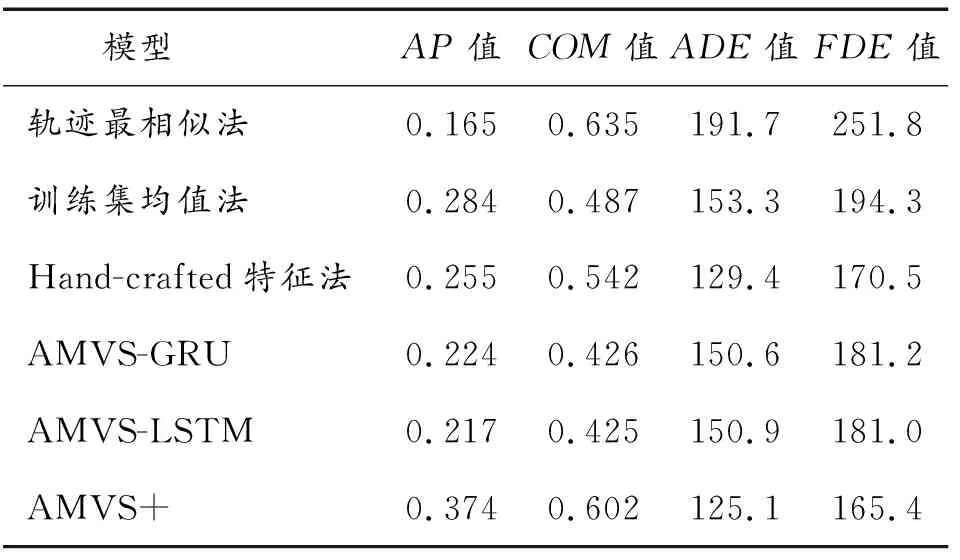
表3 各模型的AP、COM、ADE、FDE值Table 3 AP,COM,ADE and FDE values in each model
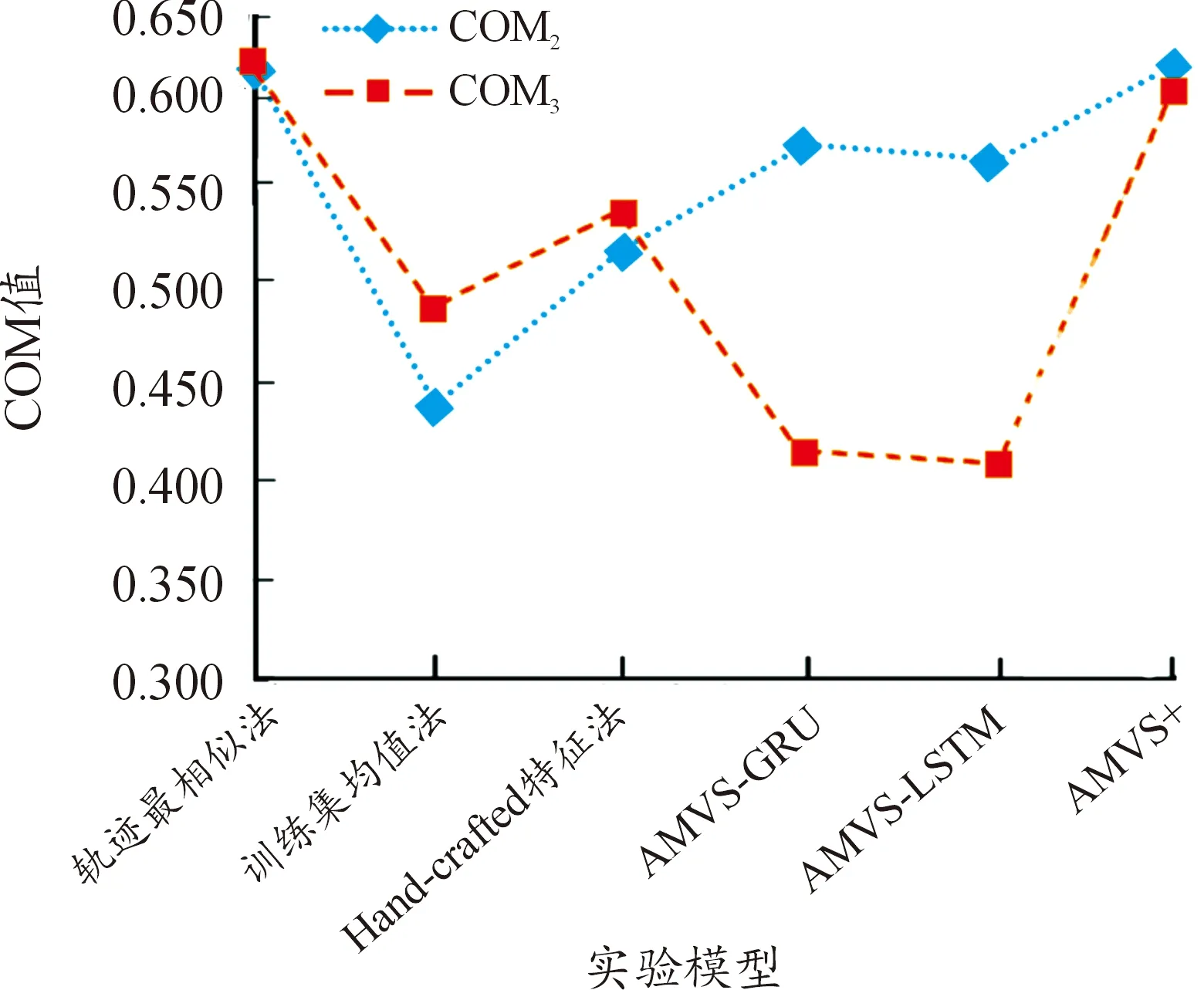
图10 各模型的PR图Fig.10 PRC of each model
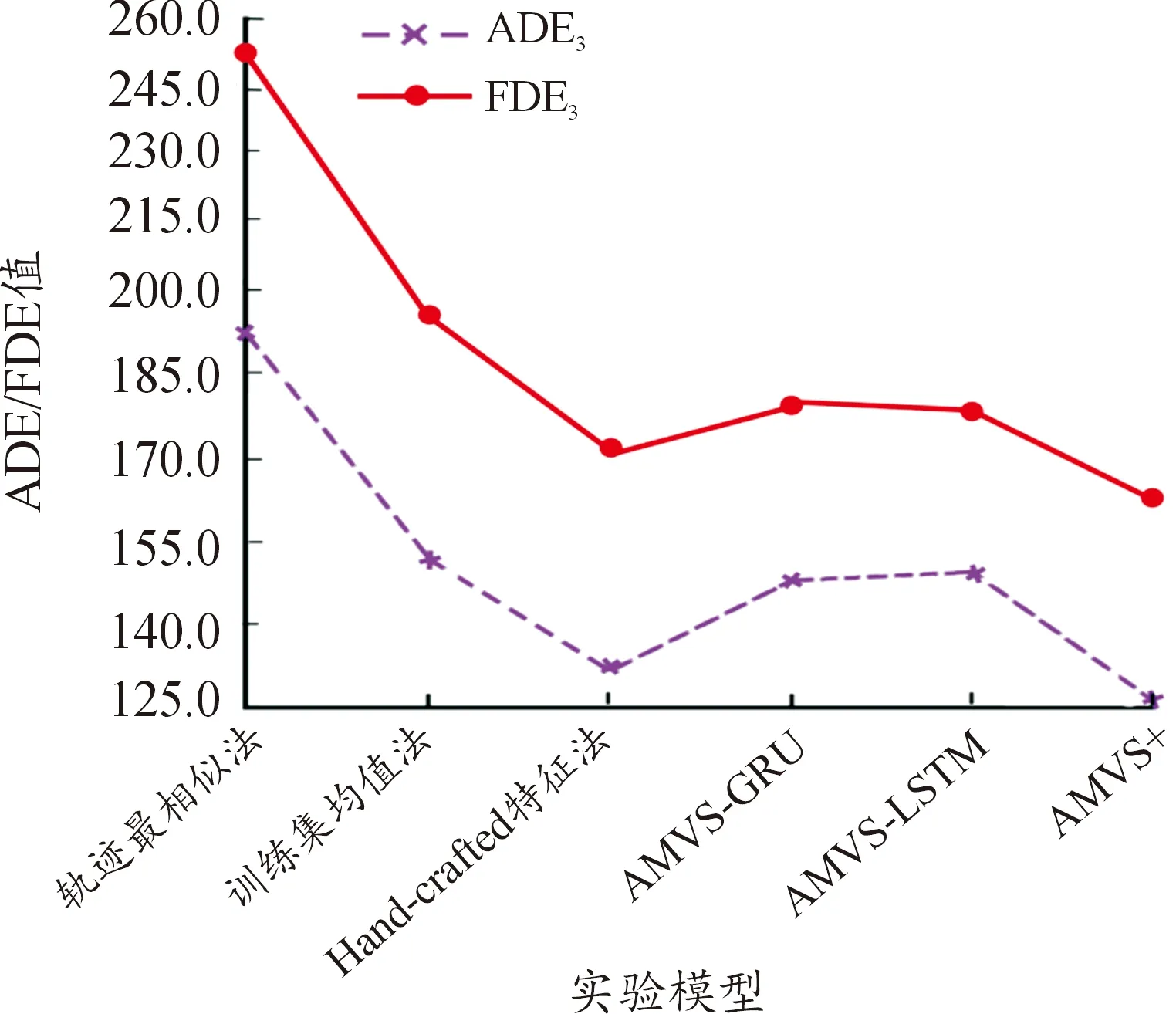
图11 ADE和FDE值对比图Fig.11 Comparison of ADE and FDE values
从结果中可以发现,相比于“哪个”和“何时”问题,“何处”问题模型的AP值普遍要低得多,虽然AMVS+模型依旧取得了最好的结果。这是由于“何处”问题公式的复杂性比其他公式大得多,是在考虑目标将重新出现的监控探头和将出现的timestep的基础上做的将出现在视图中位置的预测,因而无法实现复杂度和精确度之间较高程度的兼容,这也是下一步将要着重解决的问题。反观COM3结果,轨迹最相似法和AMVS+的表现依旧强劲,显著优于其他模型,而且最差保持在六成的重叠度,满足实际情况下的使用。但AMVS模型效果不佳,分析原因是因为其设计的初衷只考虑了“哪个”问题,因而在频繁增加后置模块之后不能够很好地适应新情况从而效果有所损失。再看ADE值和FDE值,即使将公式做了更改使得精度更高,但AMVS+模型依旧很好地实现了减少预测误差的目标。综合来看,AMVS+模型的ADE值比最高值降低了53.2%,比AMVS模型平均值降低了20.5%;FDE值则比最高值降低了52.2%,比AMVS模型平均值降低了9.5%。说明本研究中使用little block进行concat得到的Big block以及3D-tCNN进行四维张量的输出确实可以起到保证参数量的同时减小误差的作用。同时AMVS模型表现效果也较好,主要是因为和AMVS+使用均tCNN来进行空间上采样的缘故。还需要注意的是,某些基线(如Hand-crafted特征法)在ADE3和FDE3结果表现较好,而在AP3和COM3方面表现较为一般,这是因为与AP值度量不同,COM值和位移误差的度量不考虑目标未出现的监控探头视图中的错误预测,导致其虽然准确地预测了目标轨迹,但错误地为出现在其他监控探头视图中的目标分配了高可能性。
总而言之,从上面的结果分析中可以发现,使用行踪标识量作为输入的学习模型通常优于其他基线,可以完成跨监控探头轨迹预测问题的解决。并且将基于预激活ResNet-200的3D CNN置于架构中效果也突出,因为实验时使用48×27的分辨率,而不是视频识别中常用的224×224或更高分辨率,这大大减少了参数的数量,并便于在相对适中的数据集上进行训练。但同时低分辨率意味着有效信息变少、识别难度增加,因而对于使用的目标识别算法提出了更高要求;并且低分辨率也易出现丢帧现象,这就需要识别损失函数的鲁棒性以及数据集的丰富性足够优异,因此将分辨率与参数量的代价进行合理约束也是值得思考的问题。此外,将轨迹表示为张量型的行踪标识量使本文能够同时在多个监控探头视图中建模相对对象位置,从而提高输入时的性能,并提供一种直观的方式来表示目标的多模态未来。行踪标识量也使得问题解决更为简便,因为可以使用单个模型,而不是为每个监控探头创建单独的模型。需要注意的是,本研究中的方法和对比模型、基线要求在训练和测试时有相同的监控探头网络。
4 结论
提出了一种针对跨监控探头轨迹预测问题的解决方案,通过构建行踪标识量首次解决了目标接下来将出现在哪个监控探头、何时以及何处出现的问题,在AMVTP数据集上取得了很好的结果,为跨监控探头轨迹预测问题的研究提供了新思路。同时本研究思路还有以下的优势:
1) 长期预测行踪标识量的使用,减少了对整体系统网络的依赖,长时使用可以通过删除单个监控探头视点的约束来实现。
2) 智能监控当通过监控探头网络跟踪特定感兴趣的目标时,可以使用AMVS+模型的预测来智能监控个别热点,而不是持续监控所有探头。
3) 跟踪加强位置预测可与行人重识别模型结合使用,以实现更稳健的跨监控探头跟踪。
4) 强鲁棒性目标预测在跨监控探头视图中的位置增加了冗余,即使模型上的一个或多个监控探头不再工作的情况下,仍然可以识别目标。
5) 可扩展性以本文构建的行踪标识量和AMVS+模型为基础,其在解决轨迹预测时可以简便的使用单个模型,因而便于将其扩展到多目标条件下跨监控探头轨迹预测问题,解释也更为直观。
但同时也意识到几点不足,首先本研究中使用的数据集内容丰富度需要加强,容量有待进一步扩充;其次模型构建时基于行踪标识量的方法较为单一,仅有本文介绍的AMVS+一种,需要增加对比基线以提高说服力;此外由于本研究方向内容较新,可供参考文献较少,故需要紧跟国际前沿研究来开拓视野。
跨监控探头轨迹预测问题的复杂度高,依旧有许多研究空白。接下来将考虑构建使用更多的相关数据集,从而在不同环境下对模型进行训练评估;同时在多目标条件下的跨监控探头轨迹预测问题中开展研究,从而补充完善现有的行踪标识量构建方法,使得应用领域更为广阔;此外鉴于本文AMVS+模型的构建是以3D-CNN为基础,后续可以考虑改用CNN-GRU或2D-1D-CNN等其他深度学习框架为基础,构建更多有效的轨迹预测模型。
猜你喜欢
疯狂英语·新读写(2021年10期)2021-12-07
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
新世纪智能(英语备考)(2019年4期)2019-06-26
铁道通信信号(2019年11期)2019-05-21
现代装饰(2018年5期)2018-05-26
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
中国三峡(2017年2期)2017-06-09
现代兵器(2017年4期)2017-06-02
