
基于多智能体深度强化学习的体系任务分配方法
2023-04-24 11:26:48林萌龙任棒棒张萌萌陈洪辉
指挥与控制学报 2023年1期
林萌龙 陈 涛 任棒棒 张萌萌 陈洪辉
1.国防科技大学信息系统工程重点实验室 湖南 长沙 410073
马赛克战[1]、联合全域指挥控制[2]等新型作战概念所构想的未来作战场景中,传统的多任务平台被分解为了众多的小型作战单元,这些小型作战单元通常具备更高的灵活性,能够根据战场环境的变化快速对自身所承担的任务进行调整,以实现更好的整体作战效果. 在未来的新型作战场景中,传统的集中式指挥控制模式存在着指挥链路过长、决策复杂度过高等问题,从而导致决策时效性和决策质量难以满足要求[3]. 近年来,边缘指挥控制等新型指挥控制模式应运而生,边缘节点也即各作战实体将具备一定程度的自主决策能力[4]. 由于战场环境的复杂多变特性,以及作战实体的小型化、智能化发展趋势,分布式决策的模式将在未来的战场决策中发挥越来越重要的作用.
作战体系是为了完成特定的作战任务由一系列具备各项能力的作战单元动态构建而成,在以往的集中式决策模式下,体系设计人员会根据作战任务的能力需求以及作战单元所具备的各项能力,以最大化作战效能或最小化作战单元的使用成本等为目标,来统一地对各作战任务和作战单元进行匹配. 作战体系的“作战任务—作战单元”匹配问题可以建模为一个优化问题,当问题规模较小时,可以采用集中式决策的模式运用整数线性规划等运筹学方法快速得到全局最优解[5],而当问题规模较大时可以采用遗传算法等启发式算法[6]或者强化学习算法[7],得到问题的近似最优解. 采用集中式决策的一个重要前提条件是中心决策节点和作战单元叶节点之间的通信畅通,因为叶节点需要将自身的状态信息和观测信息发送给中心决策节点,而中心节点需要将决策命令发送给叶节点. 然而在未来的作战场景中,由于敌方的通信干扰等原因,中心节点和叶节点之间的通信链接很难保证连续畅通,同时频繁的信息交互会造成一定的通信负载和通信延迟,因此,在未来很多的任务场景中,需要作战单元根据自身的状态信息和观测到的信息独立地进行决策.
强化学习是一种利用智能体与环境的交互信息不断地对智能体的决策策略进行改进的方法,随着深度强化学习技术的快速发展,强化学习算法在无人机路径规划[8]、无线传感器方案调度[9]等领域都取得了非常成功的应用,同时近年来多智能体强化学习算法在StarCraftⅡ[10]等环境中也取得了很好的效果. 在作战体系任务分配场景中,可以将各作战单元视为多个决策智能体,那么“作战任务—作战单元”的匹配任务可以视为一个多智能体强化学习任务.而当前尚未有将多智能体强化学习方法应用到类似作战体系的任务分配环境中的先例. 本文的主要工作如下: 1)建立一个通信受限情况下的作战体系“作战任务—作战单元”匹配的任务场景;2)提出了一个基于多智能体强化学习技术的作战体系任务分配算法;3)通过实验验证了采用上述算法训练的各智能体,可以在通信受限的场景下,实现一定程度的自主协同,在没有中心决策节点的情况下依然能够实现作战体系任务的有效分配.
1 背景
1.1 集中式决策VS 分布式决策
集中式决策模式下存在一个中心决策节点来负责全局的任务决策,如图1 所示,各作战单元通过通信链接将自身的状态信息和观测信息发送给中心决策节点,中心决策节点进行全局的决策后,将决策命令发送给各作战单元去执行. 与集中式决策不同,分布式决策模式下将不存在一个中心决策节点来协调各实体间的行动,而是由各实体根据自身所拥有的信息,独立地进行决策. 采用分布式决策一般是为了应对两种情形,一种是采用集中式决策需要考虑的要素过多,决策复杂度过大难以进行有效的决策;另一种是由于决策节点与叶节点之间的通信受限或通信成本过高难以进行有效的通信,导致各叶节点需要独立地进行决策.

图1 集中式决策示意图Fig.1 Schematic diagram of centralized decision-making
集中式决策具有分析简单、可靠性高等优点,然而并不是所有的决策问题都适合采用集中式决策,例如在有些任务场景中不具备进行集中式决策的通信条件或者通信成本过高. 在分布式系统中,如果不存在中心节点进行全局协调,那么该分布式系统就被称为是自组织系统[11],自组织系统是各个子模块根据有限的自身感知和一些预定的规则,独立地进行思考、决策并采取相应的动作,共同完成分布式系统的任务. 典型的狼群系统、蚁群系统都属于自适应系统,传统的自适应系统大多采用基于规则的方法进行研究,但是这些规则的制定往往需要领域专家进行深度参与,并且是一个不断试错的过程.
强化学习作为一种端到端(end-to-end)的学习训练方法不需要领域专家的过多参与,而是通过智能体与环境的动态交互来不断改进自身的决策策略.采用强化学习方法来解决分布式决策问题已经在多个领域得到了成功应用,在定向传感器最大目标覆盖问题(maximum target coverage)中,XU 等将该问题抽象为一个两层决策问题[12],其中,上层决策为各传感器分配检测目标,下层决策为各传感器调整角度,之后每层决策问题均使用单智能体强化学习算法来进行求解,实验结果表明,该方法能有效解决定向传感器最大目标覆盖问题;SYKORA 基于图神经网络和注意力机制,提出了一个用来解决多车辆路径规划问题(multi vehicle routing problem,MVRP)的深度神经网络模型[13],并采用强化学习方法对模型进行训练,该模型包含一个价值迭代模块和通信模块,各车辆根据自身观测信息和通信信息独立进行决策,结果显示该模型可以有效解决MVRP 问题.
1.2 多智能体强化学习
强化学习技术已经在多个领域得到了成功应用,并取得了非常显著的效果,包括Atari 游戏[14]、围棋[15]等,然而上述场景多针对的是单智能体在静态环境中的应用,而现实中的很多场景都是多个智能体在动态环境中的应用,涉及到智能体间的复杂交互. 与单智能体强化学习任务相比,多智能体强化学习任务需要同时对多个智能体的策略进行优化,优化难度显著增强,总结来看,多智能体强化学习任务主要在以下几个方面与单智能体强化学习任务存在显著区别:
1)观测范围的变化.在单智能体强化学习所解决的马尔可夫决策过程(Markov decision problem,MDP)中,通常假定环境完全可观测的,智能体直接从环境那里得到全局的状态信息;而多智能体强化学习任务通常被建模为部分可观测马尔可夫决策过程(partially observable Markov decision problem,POMDP),智能体不再拥有全局视野,而是根据一个观测函数从全局状态中得到自身的观测数据. 部分可观测的假定与现实世界中的场景更加契合,但同时也增加了模型训练的难度.
2)环境的不稳定特性(non-stationarity). 多智能体强化学习的一个重要特点就是各智能体通常是同时进行学习的,导致每个智能体所面临的环境是非静止的,因此,导致了环境的不稳定特性. 具体地说,就是一个智能体所采取的行动会影响其他智能体所能获得的奖励以及状态的变化. 因此,智能体在进行学习时需要考虑其他智能体的行为. 环境的不稳定特性,违背了单智能体强化学习算法中环境状态的马尔科夫特性,即个体的奖励和当前状态只取决于之前的状态和所采取的行动,这也就使得在多智能体强化学习任务中使用传统的单智能体强化学习算法,可能会存在算法难以收敛等问题.
多智能体强化学习的相关研究已经成为了机器学习领域的一个研究热点,其中,独立Q 学习算法(independent Q-learning,IQL)[16]是最早应用于多智能体强化学习任务的算法之一,IQL 算法为每一个智能体都设置一个Q 价值函数,并进行独立的训练,由于将其他的智能体视为环境中的一部分,而其他智能体又是在不断学习进化的,导致了环境的不稳定性,因此,当智能体的数量超过2 个时,IQL 算法的性能表现通常较差.
近来有很多研究采用集中式训练和分散式执行的模式来解决多智能体强化学习任务,有很多研究采用Actor-Critic 算法来训练模型,其中,Critic 网络在训练阶段可以利用全局的状态信息来辅助Actor网络的训练,而在模型执行阶段,智能体的Actor 网络再根据自身的观测信息独立地作出动作选择. 例如Lowe 提出的多智能体深度确定性策略算法(multi-agent deep deterministic policy gradient,MADDPG)算法[17],为每一个智能体都提供一个集中式的Critic 网络,这个Critic 网络可以获得所有智能体的状态和动作信息,然后采用深度确定性策略算法(deep deterministic policy gradient,DDPG)训练智能体的策略网络. FOERSTER 提出的基准多智能体算法(counterfactual multi-agent,COMA)[18]也采用一个集中式的Critic 网络,此外还设计了一个基准优势函数(counterfactual advantage function),来评估各智能体对总体目标的贡献程度,以此解决多智能体任务的信用分配(credit assignment)问题. SUNEHAG 提出的价值分解网络算法(value-decomposition networks,VDN)[19],将集中式的状态-动作价值函数分解为各智能体的价值函数之和,然而该方法是假定多智能体系统的总体价值函数可以用各智能体的价值函数之和来进行表示,然而在大多数的任务场景中该约束条件并不能得到满足,因此,限制了该方法的适用范围. 针对VDN 模型所存在的问题,RASHID 提出的Q-Mix算法[20]在此基础上进行了改进,去除了集中式critic网络的价值函数相加性要求,而只是对各智能体的状态-动作价值函数施加了单调性约束.
2 问题描述
作战体系是为了完成特定的使命任务而动态建立的. 通常,作战体系的使命任务可以分解为一系列的子任务,而每项子任务的实现又都需要一系列能力的支持,同时不同类型的任务对能力的需求也不同,例如对敌方目标的打击任务所需要的火力打击能力的支持较多,而对敌方目标的侦察任务所需要的侦察能力支持较多. 在通常情况下,体系设计人员会根据己方的任务能力需求,以及自身所拥有的作战单元所能提供的能力值,来为各作战任务分配合适的作战资源,这是一种集中式的决策方法. 集中式决策方法的优点是可以获取全局信息,能根据已有的信息对整体作出合理的决策,集中式决策的方法通常能得出全局最优解. 然而随着马赛克战等新型作战概念的应用,未来的战场环境下,由于敌方的通信干扰等因素,以及决策时效性的要求等原因,传统的集中式决策的方式可能难以实现,因此,需要根据各作战单元根据战场环境和自身状态信息独立地进行决策. 由集中式决策向分布式决策方式的转变,也更加符合边缘作战等新型作战场景的构想,边缘节点将具备更高的自主决策权,可以更加独立地根据战场环境的状态调整自身的动作.
2.1 场景描述
在一个通信受限的联合作战场景中,如图2 所示,几个作战单元分别位于战场空间中的不同位置,每个作战单元都具备一定的能力,由于通信受限,作战单元不能与中心决策节点进行有效通信,而各实体间只能进行有限的通信或者不能通信,因此,在进行决策时每个作战单元都只能根据自身所能获取到的信息独立地进行决策. 这种分布式的决策方式可能会带来一系列的问题,例如由于没有中心决策节点来协调任务分配,各实体在进行独立决策时可能会出现多个作战单元都选择去完成同一个任务,从而造成某些任务没有作战单元来完成的现象. 因此,希望能够利用多智能体强化学习技术,来为每一个作战单元都训练出来一个能够进行独立的分布式决策的策略网络,并且根据这些策略网络得到的智能体策略,能够实现一定程度上的自协同.

图2 分布式决策场景下的体系任务分配Fig.2 SoS task assignment in decentralized decision
2.2 状态空间、动作空间与奖励函数设计
上述场景中的作战单元决策过程,可以被建模为一个部分可观测的马尔可夫决策过程. 场景中的每一个作战单元都可以被视为一个决策智能体,智能体的状态空间也即观测空间包含自身的位置信息和能力值信息、其他智能体的位置信息,以及任务节点的位置信息和能力需求信息. 智能体的动作是选择哪一个任务节点作为自己的目标,因此,智能体的动作空间是离散的.
在利用强化学习解决此类优化问题时,优化目标函数的取值,通常就可以作为强化学习中智能体的奖励值,确定优化问题目标函数的过程也就是确定强化学习奖励函数的过程. 在上述作战体系的任务分配场景中,体系任务分配的目标是体系中所有的任务节点都被分配了合适的作战单元来完成,因此,该场景是一个合作型的多智能体强化学习任务,各智能体共享一个相同的奖励值,相关奖励函数的设计可以根据任务节点的覆盖程度以及任务的完成效果来进行设计:
1)如果有任意一个任务节点没有被分配作战单元来完成,那么奖励值-5,任务节点的覆盖程度越低,则智能体所获得的奖励值越低.
2)任务完成的效果可以根据作战单元与任务节点的距离,以及作战单元的能力取值与任务实体的能力需求的匹配程度来确定. 作战单元与任务节点的距离越小,任务完成的时效性越高,智能体获得的奖励值相应也越高,同时任务节点的能力需求与作战单元所能提供的能力值匹配度越高,则任务完成的效果越好,相应地智能体所能获得的奖励值越多.
智能体i 所包含的信息可以用一个元组进行表示<(xi,yi,hi),ci1,ci2,…,cin>,其中,(xi,yi,hi)表示智能体i 当前所处的位置坐标,ci1则表示智能体i 在能力1 上的取值,n 为能力类型的数量. 同时任务节点j包含的信息也可以用一个元组来表示<(xi,yi,hi),ci1′,ci2′,…,cin′>,(xi,yi,hi)表示任务节点j 的位置坐标,ci1′表示任务节点j 对能力1 的需求. 那么智能体i 与任务节点j 之间的距离可以根据两者的坐标计算得到,如式(1)所示,智能体与任务节点j 的能力匹配值effij也可以根据式(2)计算得到,其中,cij表示能力匹配系数. 对于任意一项能力来说,智能体i 所能提供的能力值与任务节点j 的能力需求值之间的比值越大,说明采用智能体来完成任务在该项能力上取得的效果越好,将各项能力的效果进行累加,可以得到完成该任务的整体效果评估结果,累加得到的取值越大,则该项任务的整体完成效果越好;同时考虑如果智能体所提供的所有能力值都大于该任务节点的需求值,那么表示该任务节点的所有需求都得到了较好的满足,则将上述累加得到的匹配值乘以一个系数2,而如果有一项智能体所提供的能力值小于任务节点的需求值,则认为任务节点的需求没有得到很好的满足,因此,将上述累加得到的匹配值乘以一个系数1/2,如式(3)所示.
各智能体独立地进行决策后输出的决策结果共同构成一个完整的体系任务分配方案a=(a1,a2,…,aN),其中,ai表示智能体i 的决策结果,也即该智能体的目标任务节点的索引,N 为智能体的数量.
各智能体奖励函数的设计如式(4)所示,其中,rewd为各智能体与任务节点距离的倒数,rewe为各智能体与任务节点的能力匹配之和,n0为没有被分配对应的作战单元任务节点的数量.
在上述作战体系任务分配场景中,所有的智能体共享同一个奖励值,各智能体的决策目标就是使得该奖励值最大化.
3 基于MADDPG 算法的作战体系任务分配模型
依据生成数据的策略和进行评估的策略是否相同,强化学习算法可以分为在线(on-policy)算法和离线(off-policy)算法,on-policy 算法例如优势动作评论算法(advantage actor critic,A2C)、置信域策略优化算法(trust region policy optimization,TRPO)中,用于生成数据的策略和进行评估的策略是相同的,每个批次用于评估的数据都是由当前最新的策略网络新生成的并且数据用完就丢弃,而off-policy 算法例如DDPG 算法、软演员-评论家算法(soft actor-critic,SAC)算法,则是将智能体每次与环境的交互数据存放在一个名为经验回放池(replay buffer)的结构中,模型每次进行训练时,就从数据经验回放池中取出一定数量的训练样本进行参数更新. 由于采用经验回放机制在每次训练时是随机抽取不同训练周期的数据,因此,可以消除样本之间关联性的影响,同时在强化学习任务中,训练交互数据通常是比较宝贵的,如果每条数据只能被利用一次则是对训练数据的严重浪费,采用经验回放机制还能够提高样本的利用效率,加快模型的训练速度,尤其是在多智能体的强化学习训练任务中,各智能体与环境的交互数据更显宝贵. 因此,在多智能体强化学习中多采用offpolicy 算法进行模型训练,例如著名的MADDPG 算法及其诸多变种,都属于多智能体领域的off-policy强化学习算法.
但是经典的MADDPG 算法并不能直接应用到体系的“作战任务—作战单元”匹配任务中来,主要是两个原因,一个是MADDPG 算法,它是专门为连续动作空间任务所设计的,而体系的任务分配场景中各智能体都是离散型的动作空间,因此,需要对算法进行一定的修改,使得修改后的算法可以应用于离散型动作空间的问题;另一个原因是当前MADDPG算法所解决的问题都是多步决策问题,也即每个智能体最后输出的是一个动作序列ai=(ai1,ai2,…,ait),这样在进行网络参数训练时智能体i 就可以利用数据组(si,ai,ri,si′)进行梯度计算,而体系“作战任务—作战单元”匹配任务,是属于单步决策问题每个智能体最终输出的动作只有一个而非一个序列,智能体所生成的训练数据组为(si,ai,ri)缺少了智能体的下一步状态si′,因此,需要对智能体的策略网络和价值网络的损失函数计算方法进行一定的修改,使得该方法可以应用到单步决策问题中来.
MADDPG 算法是用来解决连续动作空间的强化学习任务的,当智能体的动作空间是离散时,通常采用的是利用argmax 函数将具备最大输出概率的动作节点作为神经网络的输出,但是由于argmax 函数不满足多元函数连续且具有偏导数的条件,因此,argmax 函数是不可导的,这样神经网络就无法计算梯度并采用反向传播的机制进行参数学习,此外argmax 函数的输出不具备随机性,函数的输出每次都是将最大值的节点输出,忽略了该数据作为概率的属性. 采用Gumbel-softmax 方法可以根据输入向量生成一组离散的概率分布向量[21],以此来解决上述问题.
采用Gumbel-softmax 方法生成离散的概率分布向量的算法流程如下所示.
1)给定的神经网络输出为一个n 维的向量v,首先生成n 个服从均匀分布U(0,1)的独立样本ε1,ε2,…,εn.
2)之后通过Gi=-log(-log(εi))计算得到Gi.
3)将向量v 中的元素与对应的随机向量Gi相加后得到新的值向量v′=[v1+G1,v2+G2,…,vn+Gn].
4)通过softmax 函数计算得到各类别的选择概率,如式(7)所示,其中,为温度参数,该参数控制着softmax 函数的soft 程度,温度越高所生成的分布越平滑(探索性越强),温度越低则生成的分布越接近离散的one-hot 分布,因此,在训练过程中,可以逐步降低该温度的大小,以逐步逼近真实的离散分布.
MADDPG 算法在解决多步决策的强化学习任务时,利用一个价值网络来计算智能体i 在当前状态的Q 值Qsi和下一步状态的Q 值Qsi′,并利用ri+Qsi与Qsi′进行对比来计算策略网络和价值网络的损失值,在单步决策中,由于没有下步状态si′的存在,将价值网络的评估值从Q 值估计值转变为奖励值ri的估计值,那么可以用ri与Qsi进行对比来计算策略网络和价值网络的损失值,以此来对网络参数进行更新.
3.1 基于MADDPG 体系任务分配算法框架
采用修改后的MADDPG 算法来解决体系的“任务—作战单元”匹配任务时,每个智能体都有一个策略(actor)网络和一个价值(critic)网络,其中,策略网络可以根据智能体的观测信息,快速输出一个能够使得智能体获得最大预期收益的动作,而智能体的价值网络则只在模型训练阶段出现,用来对智能体策略网络输出的动作进行评价,并以此来辅助智能体策略网络参数的训练. 模型训练阶段的总体框架如图3 所示,图中实线表示产生训练数据的过程,虚线表示模型训练的过程,在产生训练数据阶段,智能体i 从环境中获得自身的观测数据oi并输入给策略网络πi,策略网络根据输入的信息生成一个动作ai作为智能体i 的输出,之后所有的智能体都将自身的动作输入到环境中,环境反馈给各智能体一个奖励值r=(r1,r2,…,rN),然后各智能体将生成的数据组(si,ai,ri)存储到经验回放池中供下一步的模型训练,其中,si表示智能体i 的状态,包含智能体i 自身的信息以及从环境中观测到的信息;在进行模型训练时,从经验回放池中抽取一定数量的数据,并利用抽取的数据计算各智能体价值网络Qi的梯度,并根据采样数据和价值网络的取值计算各智能体策略网络的梯度,之后根据所计算得到的网络梯度对网络参数进行更新.

图3 基于MADDPG 的体系任务分配算法框架Fig.3 SoS task assignment algorithm based on MADDPG
值得注意的是,采用集中式训练的方法,在训练阶段的价值网络,能够获取全局的状态信息和动作信息作为网络的输入,在体系任务分配的场景中就是将所有智能体的观测信息和动作信息一并作为各价值网络的输入信息,如图4 所示,智能体1 的价值网络1 就是将智能体1~N 的观测信息和动作信息作为输入信息,并输出智能体1 在观测数据为o1时采取动作a1的Q 值Q1.
当模型训练完之后,智能体的价值网络就被丢弃了,在模型应用阶段,智能体可以利用自身的策略网络根据从环境中观测到的信息,快速得到一个能够使自身获得最大预期收益的动作,各智能体的动作构成了体系“任务—作战单元”匹配任务的联合动作a=(a1,a2,…,aN),如图5 所示,将该联合动作输入到环境中后,各智能体可以得到一个奖励值来对自身所采取的动作进行评价.
3.2 actor 网络结构
智能体的策略网络结构如图6 所示,智能体i 的策略网络的输入是该智能体的观测信息oi,包含智能体i 自身的位置信息、状态信息、其他智能体相对于智能体i 的位置距离,以及任务节点的位置信息和能力需求信息,输入信息经过多层神经网络处理后输出一个维度为任务节点个数的向量,之后经过Gumbel-softmax 方法处理后得到各任务节点的选择概率,最后选择概率最大的节点作为智能体i 在观测信息为oi时的动作选择结果.
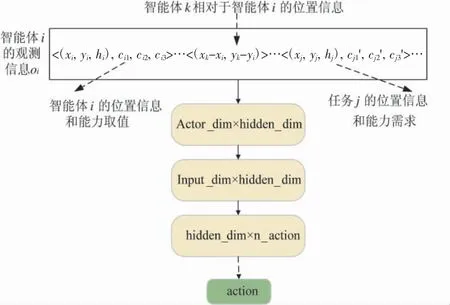
图6 actor 网络结构Fig.6 Actor network structure
3.3 critic 网络结构
智能体的价值网络结构如图7 所示,智能体i 的价值网络的输入包含所有智能体的观测信息o=(o1,o2,…,oN)和动作选择信息a=(a1,a2,…,aN),同样的,策略网络的输入信息经过多层神经网络处理后输出一个维度为1 的向量,该向量的取值就是各个智能体在观测信息为o 且动作选择结果为a 时的奖励估计值.

图7 critic 网络结构Fig.7 Critic network structure
基于MADDPG 的体系任务分配算法如算法1 所示. 当模型训练完成后,各智能体就可以独立地根据自身的观测信息对体系任务进行高效的分配.
4 实验
4.1 对比算法设置

算法1 基于MADDPG 的体系“任务-作战单元”匹配任务强化学习训练算法输入: 初始化各智能体策略网络的参数θ=(θ1,…,θN)和价值网络参数ϕ=(ϕ1,…,ϕN)输出: 训练后的最优参数θ*,ϕ*1: for iep←1,2,…maxeposide do 2: 重置环境,得到每个智能体的观测向量o=(o1,o2,…,oN)3: 根据各智能体的策略网络得到各智能体的动作ai~πi(·|oi)4: 将联合动作a=(a1,a2,…,aN)输入到环境中,得到反馈的奖励值r=(r1,r2,…,rN)5: 将各智能体的数据元组(si,ai,ri)存储到数据池D 中6: if iep >最小参数更新间隔:7:从D 中采样出一个批次的数据样本B 8:for agent i=1 to N:9:计算各智能体的策略网络和价值网络的梯度值:10:dθi←1 aiQiπ(ok,a)11:dϕi←1 k=1E o~D,a~πΔ n ∑n θiπi(oik)Δ n ∑n k=1E(o,a,r)~D(rik-Qiϕ(o,a))2 12:for agent i=1 to N:13:更新各智能体的策略网络和价值网络的参数:14:θi←(1-η)θi+η*Adam(dθi)15:ϕi←(1-η)ϕi+η*Adam(dϕi)16: end for
为了验证集中式训练模式下的多智能体强化学习算法在分布式决策环境下,面对体系“作战任务—作战单元”匹配任务时的有效性,选择分布式训练的多智能体强化学习算法作为对比算法. 集中式训练的多智能体强化学习算法与分布式训练的智能体强化学习算法最大的不同就是,集中式训练的多智能体强化学习算法是采用集中式训练分布式执行的模式,智能体的价值网络在训练阶段可以获取全局状态信息来辅助智能体策略网络的训练;而分布式训练的多智能体强化学习算法则是采用分布式训练分布式执行的模式,各智能体都将其他智能体视为环境的一部分,无论是在模型训练阶段还是模型执行阶段,都是独立地根据自身的观测信息进行独立决策.
4.2 实验环境
本文设计了一个通信受限条件下的体系“任务—作战单元”匹配的任务场景,在该任务场景中,设计体系中拥有相同数量的作战单元节点和作战任务节点,各作战单元和作战任务节点分别位于场景中一个随机生成的位置上,该位置的坐标在[-1,+1]×[-1,+1]×[-1,+1]范围内随机生成,此外每个作战单元都拥有3 种类型能力,各能力的取值采用均匀分布的形式在一定的数据范围内随机生成,同样的每个任务目标也有一定的能力需求对应于作战单元所能提供的3 种能力,任务目标的能力需求也采用均匀分布的形式在一定的数据范围内随机生成. 由于敌方通信干扰等因素的影响,各作战单元间不能进行通信,同时场景中也不存在一个中心决策节点来协调各作战单元的决策,因此,各作战单元需要根据自身的状态信息和观测信息独立地进行决策,决策内容是选择哪一个任务目标作为自己的目标节点. 由于所设计的体系任务分配场景属于是合作型的任务,各作战单元希望通过合作达到体系总体决策效果最优,因此,将各作战单元的任务分配整体效果作为各智能体的奖励值.
所有算法都采用Python 进行实现,并在同一台配置了Geforce RTX3090 显卡、Intel 16-Core i9-11900K CPU 的计算机上运行. 基于MADDPG 算法的体系任务分配模型网络主要超参数如表1 所示,为了保证一致,对比算法DDPG 采用相同的网络参数.

表1 模型网络超参数Table 1 Hyperparameters of model network
4.3 实验结果分析
集中式训练的多智能体强化学习算法和分布式训练的多智能体强化学习算法,在解决体系的“任务—作战单元”匹配任务时的模型训练曲线如图8 和图9 所示,横坐标表示训练的回合数,纵坐标表示智能体得到的平均奖励值. 可以看到,随着训练进程的推进,采用集中式训练的多智能体强化学习算法进行训练的智能体所得到的奖励值不断增大,最终稳定在0.6 左右的水平,曲线收敛. 在模型训练刚开始的时候,智能体所得到的奖励值是小于0 的,也就是智能体还没有学会与其他智能体进行任务协同分配,导致体系的任务分配出现有的任务被多个智能体选择,而有的任务没有被选择的现象,而随着训练进程的推进,由于环境反馈作用的影响,智能体逐渐学会了与其他智能体进行任务协同分配,即使在没有中心决策节点进行协调的情况下,各智能体依然能够根据自身的状态信息和观测到的信息,采用分布式决策的方式独立地作出使得体系的效能最大的任务分配方案. 相对应地,采用分布式训练的多智能体强化学习算法得到的奖励值始终为负数,表示智能体没有学会上述任务协同分配策略,随着训练进程的推进,各智能体没有学会如何与其他智能体合作任务分配,主要原因是分布式训练模式下的多智能体强化学习算法中,智能体是将其他智能体视为环境的一部分,由于智能体的决策策略是在不断改进变化的,从而导致了环境的不稳定性,而采用集中式训练分布式执行模式的多智能体强化学习算法,在一定程度上缓解了环境不稳定性所带来的影响. 从上述实验结果来看,采用集中式训练分布式执行模式的多智能体强化学习算法,来训练智能体在通信受限的场景下进行分布式决策是有效的.

图8 集中式训练的多智能体强化学习算法训练的智能体平均奖励曲线Fig.8 Mean reward curve of agent trained by centralized training multi-agent reinforcement learning algorithm

图9 分布式训练的多智能体强化学习算法训练的智能体平均奖励曲线Fig.9 Mean reward curve of agent trained by decentralized training multi-agent reinforcement learning algorithm
5 结论
随着军事装备的快速发展,以及战场环境的复杂多变,传统的集中式决策模式越来越难以适应未来战争的需求,边缘作战单元根据自身的状态信息和观测信息独立地进行决策将更加常见.
本文设计了一个在通信受限的场景下,作战体系的“任务—作战单元”匹配体系设计任务,并基于多智能体强化学习技术,提出了一个基于MADDPG算法的体系任务分配模型,该模型针对体系设计场景中的离散动作空间,以及单步决策等问题进行了相应改进,并采用集中式训练和分布式执行的模式,在模型训练阶段各智能体的价值网络将能够获取全局状态信息来辅助策略网络的训练,而在模型运行阶段,各智能体只需要根据自身的观测信息就能快速独立地进行决策. 实验结果显示,与分布式训练的多智能体强化学习算法相比,采用集中式训练的多智能体强化学习算法训练出来的各智能体,在进行分布式决策时具备更高的协同能力,所作出的体系任务分配方案效率更高.
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
纺织科学研究(2021年9期)2021-10-14 08:52:10
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
能源(2018年8期)2018-09-21 07:57:16
电子测试(2017年23期)2017-04-04 05:07:46
电气化铁道(2016年5期)2016-04-16 05:59:55
工业设计(2016年10期)2016-04-16 02:44:12
中国卫生(2015年12期)2015-11-10 05:13:34
