
面向ICS的CGAN-DEEPFOREST入侵检测
2023-04-19 05:12:22郑灿伟李世明王禹贺倪蕴涛
小型微型计算机系统 2023年4期
郑灿伟,李世明,2,王禹贺,杜 军,倪蕴涛,赵 艳
1(哈尔滨师范大学 计算机科学与信息工程学院,哈尔滨 150025)2(上海市信息安全综合管理技术研究重点实验室,上海 200240)3(洛阳师范学院 信息技术学院,河南 洛阳 471934) E-mail:hsdlsm@163.com
1 引 言
工业控制系统(Industrial Control System,ICS)被应用于电力、石油化工、制造业和和交通运输等领域[1].此外,其在国家的关键基础设施中也发挥着重要作用,如水利系统、金融系统和通信系统等.因此,ICS的安全性直接影响一个国家的经济命脉和社会稳定.
随着信息技术的快速发展和ICS网络协议逐渐趋于标准化,工业化与信息化的融合也更加紧密.最初,ICS是隔离存在的系统,故没有充分考虑连接外部网络后的安全问题.现在,ICS与外部的连接逐渐频繁,潜在的网络安全问题也逐渐暴露出来.近年来,世界ICS受到的网络攻击的次数显著增加.2021年美国最大油气管道遭受网络攻击,被迫关闭数天,引起美国汽油市场的波动;2018年台积电的工厂和运营网络遭受病毒攻击,造成生产线的停滞;以及2015年乌克兰电网遭受攻击,导致数百万人在圣诞节期间陷入黑暗,等等.此外,据美国权威统计机构统计,仅在2010—2013年间,ICS应急响应小组累计响应了600多起ICS安全事件,且年均安全事件呈现急剧上升趋势[2].针对ICS的安全性问题,权威组织提出相关标准和建议.2018年,ISA99委员会发布了ISA/IEC 62443安全标准,该标准建议采用灵活的框架,以解决ICS中当前和未来的安全漏洞[3].当然,为了确保工业生产的稳定性,制定相应标准的同时,还需要防范ICS被恶意入侵.因此,入侵检测技术作为研究的热点,入侵检测模型作为入侵检测技术中的重要方法再次成为关注的焦点.
入侵检测模型适用于不同的场景.根据应用场景不同,模型需要做出相应的调整.基于深度学习[4-6]和机器学习[7,8]的传统入侵检测模型作为一种可靠的异常数据检测方法,在传统网络中可以高准确率的识别出攻击类型数据.但是,工控场景中的数据具有不平衡、维度高、攻击数据类型复杂多样的特点,并且ICS对模型的分类时间也有特殊要求.因此,需要对传统入侵检测模型进行改进,以适用于工控场景.近年来,基于工控应用场景的特点,借鉴传统入侵检测模型的思想,一些学者提出许多适用于ICS的入侵检测模型.
针对数据不平衡问题,传统解决方式还有过采样[9]、欠采样[10]和SMOTE.但是,过采样虽然可以扩展小样本的数量,提升模型分类效果,但是会产生过拟合的现象.欠采样通过删除样本的方式,提升模型分类效果,同时也会增大丢失重要大样本数据的概率.SMOTE方式增大了类边界重叠的概率,会生成一些无效样本.文献[11]使用改进Border-SMOTE降低数据的不平衡性对模型检测准确率的影响,提升了分类模型TWSVM对攻击样本的识别能力,但是模型对复杂攻击类型的效果有待验证.针对模型分类时间问题,文献[12]使用改进鲸鱼算法优化模型参数的方式,加快了模型的收敛速度,进而减少分类时间;文献[13]通过包含随机森林在内的多组对比实验,证明简单模型收敛速度快;但是,以上均没有解决数据不平衡的问题.OCSVM具有较快的收敛速度,但是模型准确率较低[14].Dong H等人将单一的SVM应用于Modbus TCP/IP协议下的ICS内,取得了较好的实验效果,但是难以解决多分类问题[15].针对模型分类准确率的问题,石乐义、朱红强等人[16]提出了基于相关信息熵的CNN-BiLSTM入侵检测模型,将信息熵用于特征选择,CNN-BiLSTM模型用于数据分类,提升了模型准确率和收敛速度,但是模型的超参数多,不易训练;文献[17]集成深度神经网络DNN和决策树DT来用于检测攻击型数据,在两个数据集上证明其适用性,模型可以高准确率的识别出正常数据和攻击数据,但是模型分类效果仅局限于二分类问题.
综上所述,虽然现存模型在ICS中取得了较好的检测效果,但是依然存在诸多缺陷:1)没解决数据不平衡问题或解决数据不平衡问题的方式存在问题使得小样本数据检测率降低,数据分类偏向于大样本数据;2)使用简单模型进行分类,模型收敛速度快,但是准确率较低且不适用于多分类问题;3)超参数较多的分类模型,准确率较高,但是不易训练,分类时间较长.
针对上述问题,本文将条件生成对抗网络(CGAN)[18]和深度森林(Deep Forest)[19]相组合,融合两者优点,提出一种综合效果较好的CGAN-Deep Forest入侵检测模型.模型在解决数据不平衡问题的基础上,具有准确率高、小样本检测率高、分类速度快的特点.在Gas数据集上,通过与随机森林和深度卷积神经网络进行对比实验,模型有效性和创新型得到验证.
2 相关工作
2.1 条件生成对抗网络
生成对抗网络(GAN)[20]是由Goodfelllow提出的一种借鉴零和博弈思想的数据生成模型,后被用于解决数据不平衡问题[21-24].条件生成对抗网络(CGAN)作为GAN的改进模型,其结构依然由生成器(G)和判别器(D)两部分组成[25],如图1所示.
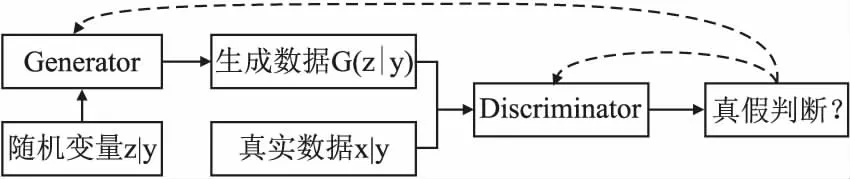
图1 CGAN模型结构Fig.1 CGAN model structure
其中随机变量x表示真实数据,y表示数据标签,z表示噪声数据.CGAN与GAN上的不同之处在于生成器和判别器中分别加入条件标签y,可以定向生成指定类型的数据,完成数据的定向扩充,弥补了GAN随机生成数据的缺点[26].CGAN模型中生成器可接收噪声及其标签(z|y),输出生成数据G(z|y).判别器可接收生成数据G(z|y)、真实数据及其标签(x|y),并输出损失函数对应的数值用于反映输入数据的真实性,该数值可进一步指导模型参数更新.上述博弈过程中生成器和判别器交替训练、迭代更新,达到动态平衡时价值函数收敛到0.5左右,此时模型趋于稳定,生成器生成的数据接近于真实数据.CGAN模型的数学表达式如公式(1)所示:

z~pz(z)[log(1-D(G(z|y)))]
(1)
如公式(1)所示,CGAN模型训练分两步进行:1)固定生成器G不动,调整判别器D来最大化价值函数V(D,G),让判别器完成真实数据与生成数据的区分;2)固定判别器D不动,调整生成器G来最小化价值函数V(D,G),让生成器尽可能生成判别器无法轻易识别的数据.两步交替进行,直至达到动态平衡为止.
2.2 深度森林
深度森林作为一种深度学习算法,由多粒度扫描和级联森林两部分组成[27].多粒度扫描时,首先对输入数据进行切分,其次将切分后的数据输入到由随机森林和完全随机森林组成的森林层进行处理,最后将处理后的特征向量输入到级联森林并进行下一步处理.级联森林的各层分别由随机森林和完全随机森林组成,其对多粒度扫描输出的特征向量进行逐层处理,最后用输出概率向量表示分类结果.
多粒度扫描借鉴卷积神经网络中卷积核的思想,具有对数据特征进行不同尺度提取的优点[28].多粒度扫描善于提取原始数据间的空间关系,所以当数据为图像格式时可以较好的发挥它的优势;但是,在入侵检测领域产生的数据通常都是结构序列化数据,因此特征间的关系不像图像那样突出.故在多粒度扫描时用不同大小的窗口和指定步长,对输入数据特征信息进行不同尺度的提取,不同大小的窗口可以增强数据的表现能力,增强数据特征间的关联性,从而进一步保证分类准确率.
级联森林借鉴深度神经网络分层的思想,通过逐层处理获取更多的潜在信息,逐步逼近正确分类结果.因为训练层没有使用卷积神经网络,取而代之的是由决策树[29]组成的森林层.决策树作为基分类器,通过集成学习方式将多个弱分类器集合在一块,构成一个强分类器,多个强分类器作为一个训练层进行分类处理.所以,级联森林的训练层参数少,计算复杂度低.
3 工业控制系统入侵检测模型
为了在保证准确率的前提下,解决数据不平衡问题,提高小样本检测率,降低整体模型的复杂度,减少分类时间,本文提出基于CGAN-Deep Forest的工业控制系统入侵检测框架,该框架主要由数据预处理和入侵检测模型两部分组成,其中入侵检测模型又主要由CGAN和Deep Forest组成.本文入侵检测模型的整体执行流程为:首先,将ICS原始数据集进行预处理,使其符合本文模型可接受的数据类型;然后,将预处理后的数据放入CGAN中,对小样本数据定向扩充;最后,将扩充后的数据集进行特征提取后,输入Deep Forest进行数据分类,输出分类结果.
3.1 数据预处理
数据预处理一般情况下可分为数值化、标准化和归一化.因本文所用数据集中无字符型属性,故无需进行one-hot编码和数值化,只需进行标准化和归一化.
1)标准化:原始数据通过公式(2)进行标准化,标准化处理之后将会加快模型梯度下降速度,进而提高分类精度.其中x表示原始数据,μ表示均值,σ表示方差,z表示标准化处理后的结果.
(2)
2)归一化:标准化完成以后,通过公式(3)将标准化数据映射在区间[-1,1]内来消除数据量纲影响,使其符合模型的输入,保证模型的准确率.
(3)
3.2 CGAN-DeepForest模型
CGAN作为一种特殊的深度学习模型,是一种数据生成模型而不是数据分类模型.模型可以在生成器和判别器对抗过程中逐渐生成无限接近于真实数据的生成数据,实现数据的定向扩充.若数据是非平衡数据,则可以使用CGAN来解决数据不平衡问题,降低数据不平衡性对模型检测率的影响,提高模型检测的准确率.
深度森林作为一种深度学习模型,与其它深度学习模型相比,具有超参数少、深度动态增加、准确率较高的特点[30].在本文入侵检测模型中深度森林担当分类器的角色,可以在保证较高准确率的前提下拥有更快的模型训练速度,降低数据分类时间.
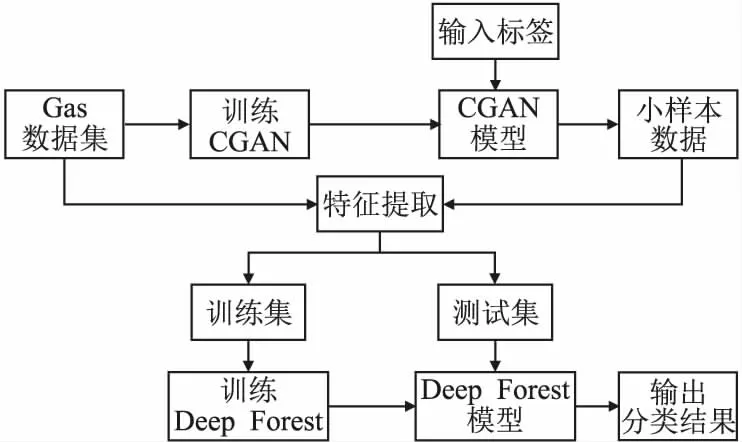
图2 CGAN-Deep Forest模型结构Fig.2 CGAN-Deep Forest model structure
鉴于ICS接收的数据具有非平衡性、攻击类型复杂和维度高的特点,以及CGAN和深度森林所具有的优良性能.CGAN可以实现数据的定向扩充,生成小样本数据;深度森林作为分类模型而言,具有准确率高、易训练、小样本检测率高的特点,适用于攻击类型复杂的工控环境,具有较好的综合解决问题的能力.本文充分整合CGAN和DeepForest两个单一模型的优点,创建适用于ICS的入侵检测模型CGAN-DeepForest,模型结构如图2所示.
将预处理后的Gas数据集输入CGAN模型,按照指定的迭代次数,完成CGAN模型的训练.然后,根据数据分布情况,输入数据标签,借助训练完成的CGAN模型完成数据的定向扩充.再将扩充后的小样本数据集与预处理后的Gas数据集进行混合,对混合后的数据集进行特征提取并按比例分成训练集和测试集,然后用训练集训练深度森林模型;训练结束之后,用测试集测试训练完的模型,输出数据的分类结果.
3.2.1 数据定向扩充
CGAN的生成器和判别器一般情况下是由全连接层组成的一种深度神经网络.本文模型中的CGAN借鉴卷积神经网络的优点,对传统CGAN进行了改进,将判别器中的一个全连接层替换为卷积神经网络[31],通过卷积神经网络的优势可以增强数据的表达能力,进而保证CGAN模型经过较少的迭代次数就可以达到较稳定的状态,生成符合要求的扩充数据,加快模型的收敛速度.CGAN的判别器所用卷积神经网络参数如表1所示.

表1 卷积神经网络参数Table 1 Convolutional layer parameters
本文模型使用CGAN对数据集中的小样本数据进行定量扩充,使数据集接近平衡状态.具体步骤如下:
Step1.数据预处理以后,按照指定的迭代次数,分批次训练CGAN模型.将处理后的数据集分批次按照CGAN的输入格式输入CGAN模型进行训练,完整遍历一次数据集记为一次迭代.
Step2.训练过程中,将真实数据与生成数据进行混合.训练判别器过程中,记录每一批次判别器的损失函数值,同时更新判别器的参数.若完成一次迭代,需将一次迭代中的所有批次损失函数求均值后记录.
Step3.训练过程中,每一批次数据完成判别器的训练,就需固定判别器,训练生成器.训练过程中记录CGAN模型的损失函数,同时更新生成器的参数.若完成一次迭代时,需将一次迭代中的所有批次损失函数求均值后记录.
Step4.在判别器和生成器完成指定迭代间隔以后,按照需求设置类别参数和数量参数,对小样本数据进行定向扩充,解决数据不平衡问题,并将扩充后的数据存储.判别器和生成器参数的更新过程中,若判别器损失函数达到0.5,则说明达到动态平衡,生成器生成的数据近似为真实数据,此时的CGAN模型达到最佳状态.
Step5.完成一次迭代以后,若没有达到指定的迭代次数,则继续交替执行生成器和判别器,执行Step 2-Step 3,直到完成指定的迭代次数.否则,将最接近CGAN最佳状态时产生的扩充数据集与原数据集进行混合,准备用于训练Deep Forest模型.
3.2.2 训练DeepForest模型
CGAN完成对数据扩充以后,缓解了数据不平衡性对分类模型准确率和检测率的影响.使用随机森林[32]对数据进行特征提取后,借助Deep Forest对数据集进行分类.Deep Forest训练过程分为多粒度扫描和级联森林两步,如图3和图4所示.
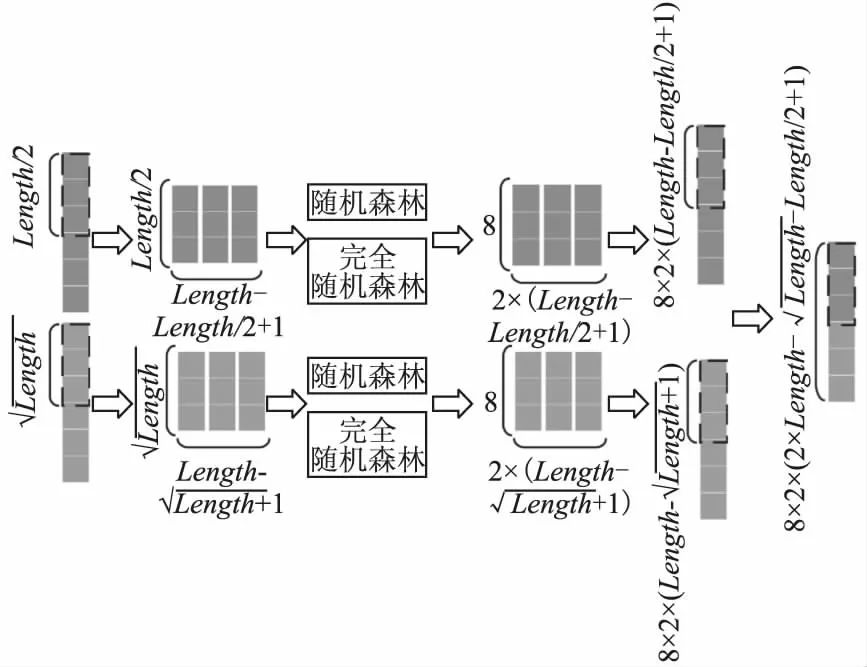
图3 多粒度扫描Fig.3 Multi-grained scanning

图4 级联森林Fig.4 Cascade forest
Step2.级联森林阶段,若有标签信息,将连接信息分为训练集和验证集,其中训练集分别输入深度森林层的随机森林和完全随机森林组成的森林层进行模型训练,用验证数据对模型进行验证.若验证输出结果满足要求,结束模型训练,若不满足将训练输出结果与连接信息进行整合形成新的连接信息,对自动增加森林层进行训练.
Step3.级联森林阶段,若无标签信息,输入信息为测试集.进入测试阶段,说明模型训练达到所需的要求,模型训练完成,模型层数无需增加,只需用训练好的模型对输入的测试集输出结果进行预测即可.
Step4.最后用测试集对模型进行测试,选出最大概率所对应的类标签作为输出结果,输出混淆矩阵,按照指定评价指标对模型分类效果进行评估.
4 实验结果与分析
4.1 实验环境和数据集
1)实验环境:编译软件为PyCharm编辑器,运行环境为Python3.6,使用框架为TensorFlow1.14、Keras2.3.1、Sklearn0.23.2,适用处理器为IntelCoreI54200H,内存为8GBDDR3L.
2)数据集:本文使用数据集Gas来自密西西比州立大学搭建的天然气管道实验平台,采集自天然气管道控制系统网络层的数据信息,经过数据清洗以后形成数据集Gas.本文所用数据集为Gas数据集总量的10%,数据类型分为8类,1类正常数据,7类异常数据,每条数据记录包含26列固定属性特征和1列标签属性,数据分布如表2所示.
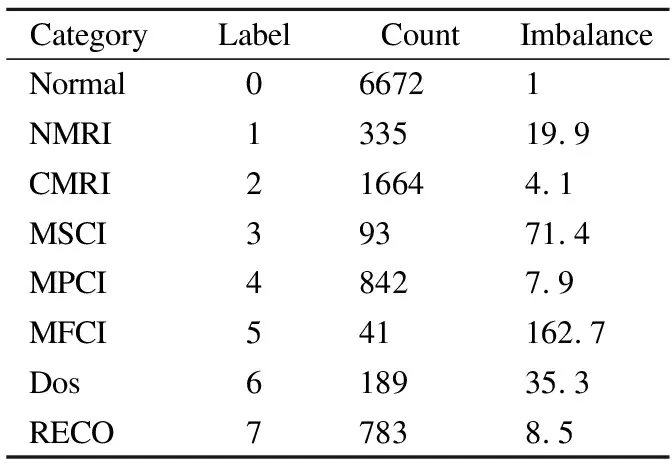
表2 数据分布Table 2 Data distribution
其中Category为攻击类型,Label为类标签,Count为各类的统计数量,Imbalance为非平衡系数(大样本类与小样本类的比值)[33].由Imbalance系数可知Gas数据集是非平衡数据集,标签为0的数据为大样本,标签为1,3,5,6的数据为小样本.
4.2 评价指标
在不考虑数据集的不平衡性对模型影响的前提下,传统模型使用基于混淆矩阵的准确率(Acc)、查准率(Precision)、查全率(Recall)作为模型评价指标,但是数据不平衡时小样本类对Acc的影响较小,因此会有误报情况的出现.本文在考虑到数据非平衡性影响的前提下,在以上评价指标基础上又引入F1作为模型评价指标,F1同时兼顾查准率和查全率,其为Precision和Recall的一种加权平均,可以综合的评价模型的效果.本文所用评价指标公式为(4)-公式(7):
(4)
(5)
(6)
(7)
其中TP代表混淆矩阵中正确分类的正常样本数;FP代表混淆矩阵中错误分类的正常样本数;TN代表混淆矩阵中正确分类的异常样本数;FN代表混淆矩阵中错误分类的异常样本数.
4.3 实验结果与分析
针对本文模型设计3组对比实验,验证本文模型的有效性和创新性.第1组对比实验:改进CGAN前后对比实验,证明卷积层可以增加数据的表达能力,使判别器具有较稳定的收敛效果.第2组对比实验:使用深度森林作为分类器的CGAN平衡前后的对比实验,证明CGAN在处理数据不平衡问题方面的有效性.第3组对比实验:使用改进CGAN完成数据平衡之后,使用不同的分类器,验证本文所用深度森林分类器,综合来说,具有较好的分类效果.
4.3.1 改进CGAN对比实验
CGAN在判别器和生成器对抗过程中逐渐达到平衡状态,平衡状态时判别器准确率在0.5附近,判别器无法判别数据的真实性,此时CGAN模型达到最佳状态,生成器生成的数据最接近真实数据.但是,原始CGAN不稳定收敛于0.5附近,鉴于卷积神经网络的优点,故本文使用卷积神经网络对CGAN判别器进行改进,改进前后对比如图5所示.

图5 CGAN改进前后收敛状态对比Fig.5 CGAN improves the convergence state comparison before and after
改进之后,虽然也是在0.5附近波动,但是CGAN收敛更加稳定,明显更接近稳定于0.5.可以证明CGAN中添加卷积改进后,生成数据效果会更好.并且,当改进CGAN迭代到第55次时,生成的数据最接近真实数据,因此接下来实验选用改进CGAN的第55次训练结果对数据集小样本类进行扩充.
4.3.2 CGAN平衡前后对比实验
对使用数据集的数据种类进行分类统计,表明本文使用数据集为非平衡数据集,标签为1、3、5和6数据较少.因此,使用改进的CGAN对标签为1、3、5、6的小样本类分别进行扩充,进行本阶段实验.在数据不平衡问题被解决前后,分别将数据集的80%作为训练集,20%作为测试集,以深度森林作为分类模型,进行对比实验.
在没进行数据平衡处理之前,分类模型总准确率为92%,时间消耗为28.02s,NMRI、MFCI和Dos攻击的查准率、查全率和F1均为0,具体分类实验结果如表3所示.
对数据平衡处理,需要对数据进行定量扩充.为了寻找最佳扩充量,对比以下3种扩充方案.
方案1.对标签为1、5、6的小样本分别扩充750、1000和800条数据,标签为3的数据不进行扩充,使部分小样本在同一数量级.经过上述数据平衡处理之后,分类模型总准确率提高了3%,达到95%,时间消耗为48.83s,NMRI、MFCI和Dos的查准率、查全率和F1分别接近提高95%、84%、90%;没进行数据扩充的MSCI类型实验结果变化不大,具体分类实验结果如表4所示.

表4 CGAN平衡后Deep Forest分类结果(Ⅰ)Table 4 Deep Forest classification results after CGAN equilibrium(Ⅰ)
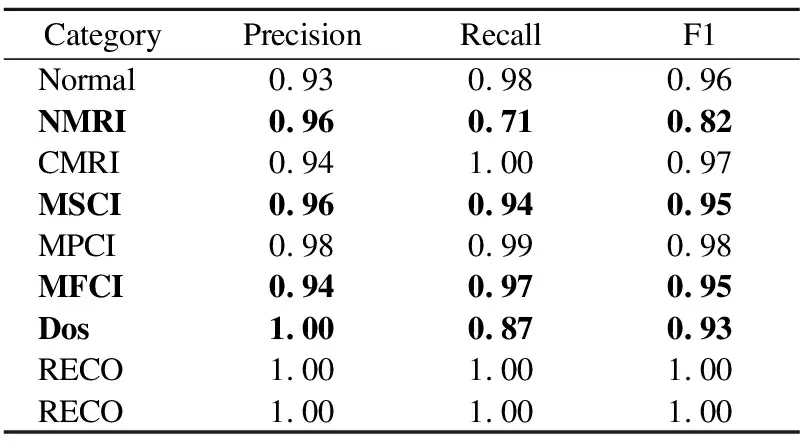
表5 CGAN平衡后Deep Forest分类结果(Ⅱ)Table 5 Deep Forest classification results after CGAN equilibrium(Ⅱ)
方案2.对标签为1、3、5、6的小样本分别扩充1000条数据.经上述数据平衡处理之后,模型总准确率达到95%,时间消耗为63.85s,具体分类实验结果如表5所示.
方案3.对标签为1、3、5、6的小样本分别扩充3000条数据.经上述数据平衡处理之后,模型总准确率达到96%,时间消耗为247.78s,具体分类实验结果如表6所示.
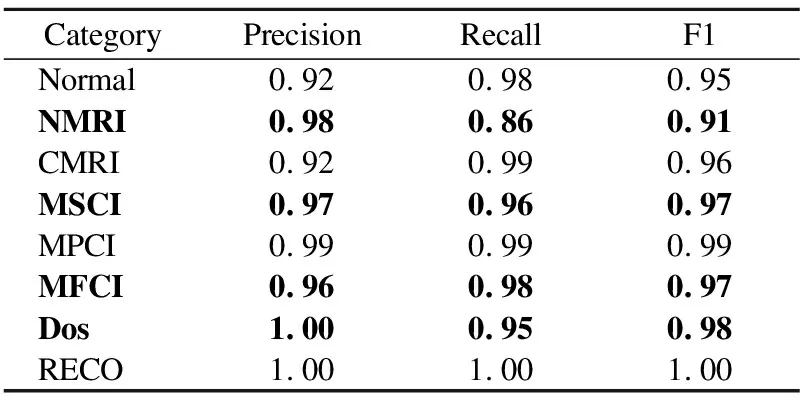
表6 CGAN平衡后Deep Forest分类结果(Ⅲ)Table 6 Deep Forest classification results after CGAN equilibrium(Ⅲ)
以上4组实验结果表明,改进CGAN在处理数据不平衡方面起到了较好的作用,数据的定向扩充可以提高不同类型小样本检测率.但是,对比扩充方案1、方案2和方案3可知随着小样本数据量的增多小样本检测效果不再明显提高,时间成本却在显著增加.基于上述情况,后续实验使用方案1对数据进行扩充,验证本文模型综合效果.
4.3.3 不同分类器对比实验
本阶段,通过使用平衡处理之后的数据集和不同类型的分类器进行对比实验,进一步证明模型的创新性.本文模型可以在解决数据不平衡问题和提升小样本检测率的情况下,提高整体检测准确率,降低模型训练和分类时间.
分类模型选用机器学习中的随机森林时,分类模型总准确率达到89%,时间消耗为3.07s,具体分类实验结果如表7所示.

表7 CGAN平衡后随机深林分类结果Table 7 Random deep forest classification results after CGAN equilibrium
通过对比表4和表7实验结果表明:模型使用随机森林作为分类器时,虽然对小样本具有检测效果,且模型收敛速度较快,但是各攻击类型的查准率、查全率和F1整体低于本文模型的实验结果.另外,与本文模型相比,其整体准确率也低了6%.
分类模型选用深度卷积神经网络时,其迭代训练150次之后,整体准确率为94%,训练时间为73.45s,迭代过程如图6所示.与本文模型相比,两者准确率相近时,准确率都在94%附近,时间成本提升了50%,深度卷积神经网络分类时间大约多25s.
通过以上多组对比实验可以证明,本文模型CGAN-Deep Forest综合效果较好.通过CGAN平衡前后对比实验,证明CGAN在复杂的工控环境中,依旧具有较强的解决数据不平衡问题的能力.通过不同分类器间的对比实验,证明经过平衡处理之后,深度森林可以充分发挥自身优势,多项评价指标最佳,综合表现能力最好.因此,本文模型各组成部分充分发挥自身优势,进而充分保障整体模型可以同时解决数据不平衡问题、准确率问题、小样本检测率问题和分类时间问题.
5 结束语
目前,在工业控制领域存在许多入侵检测模型,但是缺少一种综合性的入侵检测模型,可以兼顾处理多方面问题.因此,本文提出入侵检测模型CGAN-DeepForest,应用于ICS的入侵检测领域.模型各组成部分优势互补,确保具有较强的综合解决问题的能力.首先,为了数据生成模型具有较为稳定的效果,对原始CGAN进行改进.然后,借助改进CGAN来完成数据的定向扩充,解决数据的不平衡问题.最后,对平衡后的数据集使用随机森林进行特征提取后,使用准确率高、小样本检测性能好、训练和分类时间短的深度森林对数据进行分类,输出分类结果.经过实验验证,在工业控制领域,CGAN-DeepForest模型可以取得了较好的效果.未来研究重点在于,进一步改进CGAN,使其震动幅度减小,降低CGAN的发散可能性.在不同数据集上验证本文模型的有效性,证明模型的普适性.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中国交通信息化(2018年5期)2018-08-21 03:37:40
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
