
企业数据财产权益的归属判定及实现程序
2023-04-12 00:00:00姬蕾蕾
苏州大学学报(哲学社会科学版) 2023年4期

摘 要:企业数据财产权益如何配置及实现是当前数字法学面临的司法困境和理论难题。企业数据财产权益分配困难的根源在于,学界依附于传统财产权理论解决企业数据权属问题,未能有效识别数据之上的复杂利益关系,亦未能澄清数据权利制度所欲解决的核心问题。算法是数据价值生成的核心,运用算法思维探索可计算的数据权益分配方案,更契合数据流转的客观规律与当下实践。具体而言,以算法架构判断数据的价值形态,以裁判基准界定数据的权益范围,可对企业数据权益进行阶段化配置。数据价值生成经历数据源、数据集合及数据产品三种形态,考察各阶段数据权益边界的司法立场,判定财产权益的归属主体:数据源的财产权益归属个人,数据集合的财产权益由个人与数据企业共有,数据产品的财产权益归属数据企业。在此基础上,以“卡-梅框架”检验企业数据权属的效果,并决定其上权益实现的程序规则,由此达到对企业数据财产权益的归属确认及动态保护的双赢效果。
关键词:企业数据;权益归属;算法规制;裁判基准;卡-梅框架
作者简介:姬蕾蕾,上海交通大学凯原法学院博士后,主要从事民法学与信息法学研究。
基金项目:国家社会科学基金项目“民法典中隐私与个人信息的协同保护研究”(项目编号:21CFX034)的阶段性成果。
中图分类号:D923;D922.294 ""文献标识码:A ""文章编号:1001-4403(2023)04-0088-12
DOI:10.19563/j.cnki.sdzs.2023.04.009
随着数字社会的到来,以数据、个人信息为核心范畴的数字法学成为新时代法学研究的主角。《网络安全法》《数据安全法》的出台以及《民法典》第127条关于数据的引致性规范,彰显出有关数据保护与利用的立法、司法以及学术研究已经成为法学前沿的重要课题。由于数据之上呈现出多重利益并存的格局,其上权益如何划分,便成为当下法学领域需要研究的一个核心问题,然而立法层面未对这一问题作出明确回应。尽管学界多致力于对个人信息与数据作出划分,以此肯定企业享有数据之上的财产权益,①【" ①目前,关于个人信息是否具有经济价值,学界持不同的观点,但普遍承认企业对个人信息(数据)集合之上的财产利益。肯定个人信息具有财产价值的学者认为,个人信息权益是天然内置财产属性的人格权益。参见彭诚信:《论个人信息的双重法律属性》,《清华法学》2021年第6期,第78-97页。否认个人信息具有财产价值的学者认为,个人信息的经济价值存在“稀薄效应”,赋予个人以财产利益,将导致个人之间人格的不平等。参见张新宝:《论个人信息权益的构造》,《中外法学》2021年第5期,第1144-1166页。】但未能意识到二者在客体属性上的共性关联。企业数据权益的具体内涵与外延,取决于如何配置数据之上的财产权益,而权益配置方案决定了数据财产权益的实现方式和权利主体行使权益的边界。本文试图以数据权属分配的司法立场为基准,根据数据的权益属性以及数据价值的生成规律,提出数据权益的配置方案,并与其财产权益的实现程序进行对接,以期对当前的数据法学研究有所裨益。
一、问题的提出:企业数据财产权益分配的实践困境
传统权利理论的代表是意志理论和利益理论,这两个理论在当下分析数据权益问题时仍然是重要的理论工具。①【" ①参见彭诚信:《现代权利理论研究:基于“意志理论”与“利益理论”的评析》,法律出版社2017年版,第14页。】在司法实践中,法院对数据纠纷的处理一般基于人格权和财产权两个维度展开。对于人格权类的数据纠纷②【" ②确切地说是个人信息纠纷,鉴于本文是以数据法律问题为主题的,为行文方便,对于个人数据与个人信息不做区分。】,倾向于从对既有的规范出发解决案件争议焦点,如《个人信息保护法》《民法典·人格权编》等,这恰是意志理论通过审视法律规则内容识别权利的方式。对于竞争类的数据纠纷,由于数据保护立法的缺位,法院一般从利益理论出发,将既有的企业数据利益作为竞争性利益,采用反不正当竞争的一般条款加以解决,体现了利益理论通过探寻规则的目的识别权利的方式。本文根据个人在数据纠纷中的直接或间接作用,对当前的数据纠纷归纳出三类,从而发现在司法实践中数据财产权益分配的困境所在。
(一)涉及人格权的数据保护纠纷
该类纠纷是关于个人与企业之间的利益冲突,主要源于企业未经个人同意采用自动化技术处理个人信息引发的人格权纠纷,典型的如“微信读书案”③【" ③参见北京互联网法院(2019)京0491民初16142号民事判决书。】“凌某诉抖音案”④【" ④参见北京互联网法院(2019)京0491民初6694号民事判决书。】“孙某诉搜狐网案”⑤【" ⑤参见北京互联网法院(2019)京0491民初10989号民事判决书。】“朱某诉百度案”⑥【" ⑥参见江苏省南京市中级人民法院(2014)宁民终字第5028号民事判决书。】等。尽管这类案件并未直接涉及数据权属争议,但仍引发两个关联问题:其一,个人信息的范围模糊。涉案信息是否属于个人信息直接关系到数据归属主体的确定,但在实践中,法院对个人信息的认定标准裁决不一。例如,“微信读书案”中个人的读书信息和读书时长,以及“凌某诉抖音案”中凌某的通讯录好友列表均被认定为个人信息。但在“朱某诉百度案”中,法院一方面认为用户网络偏好信息具有隐私属性,另一方面又认为涉案信息不具有识别性,不应认定为个人信息。这类信息通常由个人借助平台产生,例如个人浏览记录、个人位置信息等,如何确定这类信息的归属?其二,个人信息是否具有财产权益。实践中,个人通过侵权损害赔偿获得救济的情形较少,但近来法院的态度逐渐松动,开始认可个人对其信息享有财产权益。例如,在“凌某诉抖音案”“孙某诉搜狐网案”中,法院均支持了个人的财产损失赔偿请求。由此引起的疑问是,若个人对其信息享有财产权益,如何在数据财产权益中让个人分一杯羹?
(二)涉及财产权益的数据竞争纠纷
该类纠纷主要是数据企业与第三方利用者之间的利益冲突,起因是第三方数据利用者未经同意抓取数据企业的用户数据引起的不正当竞争纠纷。比较典型的案例如“新浪微博诉脉脉案”⑦【" ⑦参见北京知识产权法院(2016)京73民终588号民事判决书。】“杭州撞库案”⑧【" ⑧参见杭州铁路运输法院(2018)浙8601民初956号民事判决书。】“阿里巴巴诚信通案”⑨【" ⑨参见浙江省杭州市滨江区人民法院(2019)浙0108民初5049号民事判决书。】“淘宝诉美景案”⑩【" ⑩参见杭州市中级人民法院(2018)浙01民终7312号民事判决书。】“微信群控案”B11【" B11参见杭州铁路输法院(2019)浙8601民初1987号民事判决书。】等。在这类案件中,一方面,法院肯定企业对整体数据资源享有财产性权益,认为平台的用户数据是企业投入大量人力、物力及技术,经过长期经营累积而成,第三方利用者爬取/抓取平台数据的行为侵害了企业的财产权益,由此企业可通过反不正当竞争法获得损害赔偿;另一方面,法院虽认可个人对其信息享有受法律保护的权利,指出企业对个人信息享有使用权,具有保障个人信息安全的义务,但对于单一用户能否对其信息主张财产权益的问题,要么持否定态度,要么不予回应,仅对第三方利用者的不当行为进行评价。
(三)数据纠纷同时涉及人格权与财产权
这类纠纷虽然是数据企业与第三方数据利用者之间的争议,但个人授权第三方数据利用者从数据企业直接获取个人数据成为这类纠纷的直接起因,较为典型的包括“微头条案”①【" ①参见北京市海淀区人民法院(2017)京0108民初24530号民事判决书。】“腾讯诉抖音、多闪案”②【" ②参见天津市滨海新区人民法院(2019)津0166民初2091号民事裁定书。】等。在“微头条案”中,个人是否有权许可第三方数据利用者对其数据处理成为本案的争议点,争议引发的矛盾直指数据权属问题,即新浪微博用户在平台发布的数据究竟属于个人所有还是企业所有。法院认为,微博平台展示的内容并非仅由用户单独生成,而是在此基础上投入资源和服务后形成的成果,本质上是一种竞争性财产权益,应属企业所有。随后指出,用户在处分个人信息权益时不能超出其自身范围,侵害新浪微博基于经营享有的合法权益,即新浪微博对用户生成内容进行收集、处理及服务过程中所添附的内容。在“腾讯诉抖音、多闪案”中,同样是基于腾讯用户授权抖音、多闪抓取其微信头像与昵称等信息引起的纠纷。法院认为腾讯公司积累该类数据,已经成为可以为其带来竞争优势的商业资源,故支持腾讯的禁令申请。综合两则案例可以发现,在数据竞争纠纷中,个人信息作为整体资源显示出了强大的财产属性。但对数据财产权益的分配往往局限于对数据整体资源的竞争,单个信息的经济价值被淹没,由此导致在数据财产权益分配中,个人信息作为基础资源的作用被忽略。
综上可以看出,个人在不同的情境下对其信息享有的权益份额并不相同。在人格权数据纠纷中,个人尚能就其损失获得损害赔偿的救济,但在财产权数据纠纷中,尤其是在人格权与财产权并存的数据纠纷中,个人作为利益主体的地位直接被漠视。尽管法院着眼于实现企业对数据财产权益的基本诉求,依托诚信原则、商业道德以及劳动理论,并通过法律适用证成了该项利益的正当性,推定数据企业对数据资源的竞争性权益。但对于单个用户的数据权益诉求,仍然只是将其作为企业获得合法授权的判断要素,对于企业对数据进一步的支配力、个人主张数据财产权益的权限以及数据之上的权益边界划分问题缄默不语。如要解决个人、企业、第三方数据利用者之间的权益分配困境,首先就需要理清导致数据财产权益难以分配的根源所在。
二、企业数据财产权益分配困难的根源
企业数据财产权益分配之所以在实践中存在困境,表面原因是企业数据之上权益形态复杂以及多元主体并行。在理论层面,学界难以有效确定数据权益归属的根本原因在于,局限于以传统财产权理论解释该问题,未能有效厘清数据之上的利益形态,未能揭示数据价值生成的核心架构,也未能真正把握数据流转的客观规律和权益分配的核心依据。
(一)传统财产权理论难以为企业数据权益的分配提供有效的解释力
在大陆法系的民法中,罗马法式的以所有权为中心的财产权观念长期占据主流地位,且影响至今。所有权的核心是“对所有物的完全支配权”,③【" ③周枏:《罗马法原论》(上册),商务印书馆2014年版,第341页。】而根植于所有权的自物权,以及由此派生的他物权,本质上都是一种“直接支配一定的物,并获得利益的排他性权利”。④【" ④我妻荣:《新订物权法》,有泉亨补订、罗丽译,中国法制出版社2008年版,第9页。】但在数字社会,以保护排他诉求为基本功能的传统财产权体制,与数据的规模价值和非对立性之间存在深刻张力。⑤【" ⑤参见戴昕:《数据界权的关系进路》,《中外法学》2021年第6期,第1564页。】大量间接的、数字化的表达和交往方式,突破了传统财产权的自然人基础和权利逻辑。①【" ①参见马长山:《数字法学的理论表达》,《中国法学》2022年第3期,第126页。】
其一,共享性和可控性是数据的自然属性,不同于传统有体物交易的单线结构,买卖双方较为清晰。数据利用的过程是通过不断循环交织之后形成的网状互联的权利结构,因此,传统物债二分的研究范式难以解释数据权益的保护与利用问题。其二,数据并不具有物理外观上的质量、重量和形状,而作为权利客体意义上的数据具有复合属性,其上承载复杂多元的利益交织在一起,难以从物理意义上进行完全切割,因而传统所有权的权能分离理论难以对数据的法律属性、权益归属及保护路径作出有力解释。其三,数据主要通过流通、交换进而创造出更大的利用价值和预测价值,因而不同于有体物通过占有、分配来分享其权能的法律关系构造。②【" ②参见胡凌:《数据要素财产权的形成:从法律结构到市场结构》,《东方法学》2022年第2期,第130页。】因此,各个数据权益主体利用数据权利的绝对排他性受到消解,各个权利人对数据的利用往往呈现出叠合与并行的共赢局面。③【" ③参见王利明:《论数据权益:以“权利束”为视角》,《政治与法律》2022年第7期,第101页。】由此可以发现,传统以有体物为研究对象的财产权理论难以有效解释数据权益问题,这种局限性在司法实践中体现得最为明显。受制于传统财产权利中的排他性理论影响,法院为实现企业对数据权益的应然诉求,回避了解决企业数据之上的权益分配问题,仅确认企业享有竞争性权益,以此排除他人的不当使用。既未能进一步确立数据企业对数据权利的支配力,只是通过对用户授权的解读肯定企业的部分意志;又忽略了个人在数据价值生成中的贡献力,漠视了个人在数据流通中的意志选择。尤其是在“微头条案”中,个人自主授权的自由意志被置于企业数据权益保护的价值位阶之下,导致个人在事实上成为企业数据排他权的义务主体。
(二)未能有效识别企业数据之上的利益形态
在既有数据保护法律规范缺失的困境中,确立新型数据权利呼之欲出,成为当前保护数据财产权益、解决数据归属不明的有效途径之一。此时,利益理论作为推定企业享有数据财产权益的理论支撑,在司法实践中发挥了其独有的功能。然而,利益理论是以功利主义为基础,着眼于利益的保护与实现,④【" ④参见彭诚信:《现代权利理论研究:基于“意志理论”与“利益理论”的评析》,法律出版社2017年版,第124页。】因此只能回应企业对数据的有限利益诉求,无法在识别既有利益形态的基础上,有效厘清数据之上的利益类型,从而解决数据权属分配问题。缘由在于,数据从收集、加工到利用是一个持续循环的过程,在不同的处理阶段,可能会形成各种利益互动关系,再通过分享和控制,逐步形成多元主体间的复杂权益网络。⑤【" ⑤参见戴昕:《数据界权的关系进路》,《中外法学》2021年第6期,第1580页。】诚然,在学界,数据之上的多元利益已成为一种共识,学者们更试图从不同的侧面解决数据之上的多元利益冲突。⑥【" ⑥参见钱子瑜:《论数据财产权的构建》,《法学家》2021年第6期;包晓丽:《二阶序列式数据确权规则》,《清华法学》2022年第3期。】但并未跳脱既有的分析范式,囿于劳动理论作为权利化依据,忽视了数据价值的生成机制,以致仍难以从实践上有效剖离企业数据之上的利益形态。
在数据之上的多元利益关系中,数据经济利益是企业数据中最核心的利益关系,⑦【" ⑦参见龙卫球:《再论企业数据保护的财产权路径》,《东方法学》2018年第3期,第56页。】也成为重点关注的对象。对此,法院一般以劳动理论重点解决数据企业的财产权益诉求,但是劳动理论无法回答“主体是谁”的问题。在实践中,大部分法院都强调数据企业成本、技术的投入,以“合法权益”保护数据控制者的劳动投入,推定数据财产权益应该归属于企业。如在“微信群控案”中,法院指出,微信产品形成的数据资源,是微信平台投入大量人力、物力,且经过长期积累聚集而成的,微信平台自当对其数据资源享有竞争性利益。但深入考究,根植于洛克的劳动生产理论并一定能推定数据企业享有数据权利,近来这一理论受到不少学者质疑。⑧【" ⑧参见纪海龙:《数据的私法定位与保护》,《法学研究》2018年第6期;丁晓东:《论企业数据权益的法律保护——基于数据法律性质的分析》,《法律科学》2020年第2期。】毕竟,劳动只能最低限度地回答数据是被生产的事实,远无法回应数据权利的生成机制问题。①【" ①⑧参见韩旭至:《数据确权的困境及破解之道》,《东方法学》2020年第1期,第102、106页。】若遵循这一理论,肯定数据企业的主体地位,那个人作为企业数据生成的提供者,其权益诉求如何实现?有学者据此认为,保护用户隐私成为企业主张排他权益祭出的主要理论依据。②【" ②参见戴昕:《数据隐私问题的维度扩展与议题转换:法律经济学视角》,《交大法学》2019年第1期,第40页。】
(三)未能澄清数据权利制度所欲解决的核心问题
既然现有的裁判规范和理论基础无法有效解决数据权益分配问题,对企业数据的研究就必须回归到对数据保护的规范目的的分析上,而对其规范目的的思考就要根植于数据权利的历史发展过程进行考察,从而识别数据所欲解决的核心问题。数据权利之所以成为一项新型财产权,缘由在于数字社会的到来,尤其是智能算法的应用,重塑了信息与数据的关系。数据技术能够做到量化传统数据技术所无法收集的一切事物,将现象转化为可制表分析的量化形式,将一切予以数字化,③【" ③参见陈兵:《大数据的竞争法属性及规制意义》,《法学》2018年第8期,第115页。】形成了万物皆可数据的网络格局。数据技术在给社会带来积极影响的同时,也给现有的法律制度体系带来了巨大挑战。
一方面,数据技术的发展为企业带来了巨大的经济利益。在互联网刚刚兴起之时,数据的经济价值并不明显,早期立法对数据问题的关注,可以追溯到欧美对数据库的保护。数据库客体的类型一般局限于事实数据和作品数据,无论在数量上还是类型上都比较单一局限。但大数据技术的快速普及与应用,导致企业获取数据和传输数据的能力得到飞跃发展,借助算法的分析能力可以为企业提供智力洞察和决策判断。④【" ④⑥参见李谦:《法律如何处理数据财产?从数据库到大数据》,《法律和社会科学》第15卷第1辑,第91页。】在这种背景下,传统上并不具有经济价值的数据具有了成为财产的可能。另一方面,数据技术的应用为企业数据保护带来了巨大的冲击。在数字社会,个人信息成为企业数据的主要来源,企业数据作为数据资源和数据分析技术的结合体,其本身既包含了网络空间中的初始数据,也包含着数据分析加工后的商业附加值。换言之,数据不再是个人意志的网络表达集合,而是人格与财产属性于一身的混合体。⑤【" ⑤参见张玉洁、胡振吉:《我国大数据法律定位的学说论争、司法立场与立法规范》,《政治与法律》2018年第10期,第142页。】因此,数据的财产权利安排已经不再是有关数据的权利建构的主要争议,个人数据权利进入数据权利的演化逻辑之中,⑥个人、企业及第三方数据处理者之间的利益关系如何协调,成为数据权利制度最紧迫也是最核心的问题。
三、企业数据财产权益的归属:从算法赋值到司法界权
围绕企业数据权利的研究,必须根植于数字社会背景,根据数据本身的复合属性以及其流转规律等重新识别利益形态,并立足于司法实践确定的裁判基准,依此确定企业数据权益的分配规则。
(一)算法架构生成数据价值——企业数据类型化依据
尽管智能算法的应用是数据之上主体的多元性和客体的复合性成因,但依赖算法亦可以反向生成数据权益空间,由此厘清数据之上的利益关系。因此,对企业数据权益的讨论还应立足于数据价值的生成机制,回归到其技术架构上来。
事实上,无论是单个数据还是海量数据资源,抑或是数据产品的生成,都依赖于算法为媒介,算法技术才是数据价值生成的核心。⑦【" ⑦参见韩旭至:《算法纬度下非个人数据确权的反向实现》,《探索与争鸣》2019年第11期,第142页。】在算法的应用下,数据完成了从最低价值的原始数据到最高价值的数据产品的财产变现过程。具体而言,数据的价值依赖算法的激活,在数据采集阶段,算法激活代码层的数据,形成大量数据集合;在数据成品阶段,算法通过对数据的代码层分析演绎来激发数据的内容层,进而通过定性定量的分析为市场提供智力决策,创造利润。⑧由此可见,数据价值的生成机制是以“数据源—数据集合—数据产品”的价值形态逐步增值的过程,即数据从代码符号逐渐生成反映具体内容的信息。从数据价值的生成机制可以发现,从数据的权利诉求到权利保护,算法处于中心地位,既是界定数据利益类型的客观方式,又是判断数据之上权利主体的核心依据。数据在不同的处理阶段,因算法的作用力不同,其承载的利益类型也是向前向后迁移转换的。鉴于此,可以在不同的场景中识别出数据之上的利益形态,并进行有效抽离,以此确定多元主体的权益层次需求。本文以数据的价值生成机制为标准,将数据分为原始数据、数据集合与数据产品。①【" ①参见姬蕾蕾:《企业数据保护的司法困境与破局之维:类型化确权之路》,《法学论坛》2022年第3期,第120页。】原始数据是指未经算法加工的原始形态的数据,在本文中仅限于个人数据(个人信息);数据集合是运用算法对原始数据进行收集、加工后形成的海量化数据资源;数据产品是借助算法进行深入分析和处理后形成的,以利用数据为目的的数字化产品。
(二)司法界定权益边界——企业数据财产权益的裁判基准
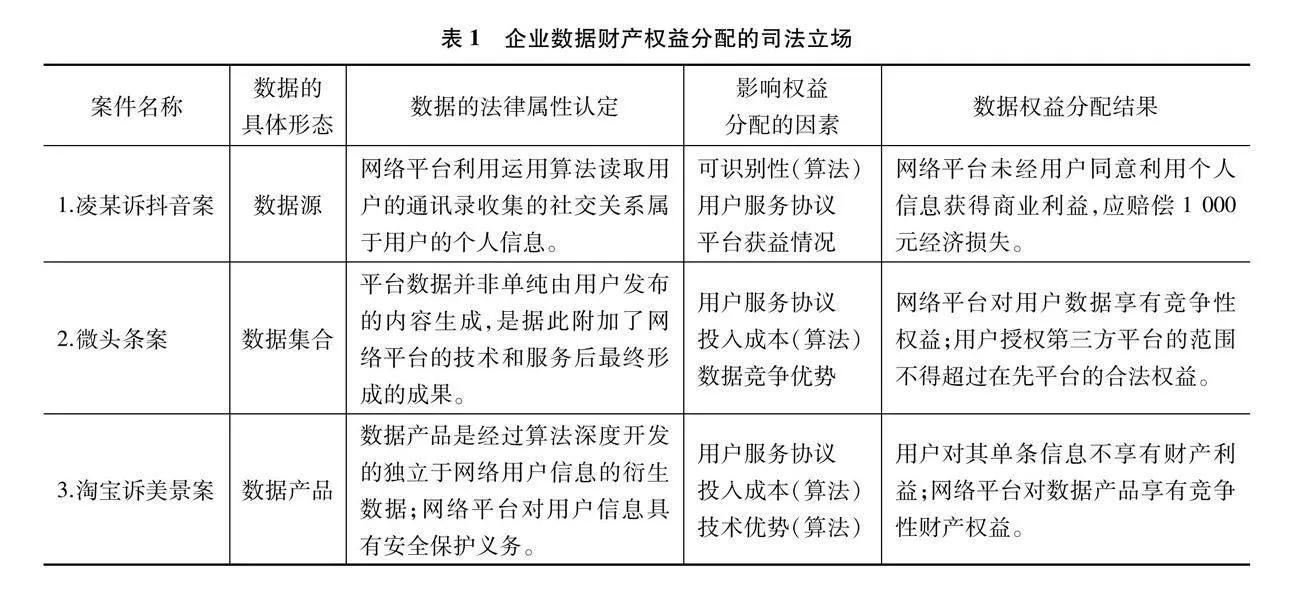
在司法实践中,尽管数据纠纷的发生场域、争议焦点以及诉争权益并不相同,但从客观上呈现的恰好是数据在不同阶段的利益形态,贯穿其中的正是数据价值的生成机制。以下三则案例(表1)是本文从现有纠纷中选出的较为典型的案例,分别代表数据在不同场域中的显性属性、价值形态以及由此确定的权益配置的考量因素。
由上表可知,在不同的数据流转阶段,数据权利诉求并未停留,是随着数据价值的生成逻辑相应变化的。即按照“人格属性—双重属性—财产属性”的演化顺序,其权益诉求分别表现为“人格权益纠纷—人格与财产权益并存纠纷—财产权益纠纷”三种类型。尽管数据纠纷的法律属性并不相同,但深入考察可以发现三种因素造就了数据权益的分配现状。
1.算法技术的运用既是侵害个人信息权益的典型表现,又是启动其财产价值的诱因
无论从立法体例抑或理论解释层面来看,个人信息的法律属性是人格利益已成为共识。在“凌某诉抖音案”中,涉及的主体是个人与数据企业,法院主要基于单个主体的信息数量及信息敏感度,判断涉案信息的法律属性。与此同时,法院并未考量个人信息的财产因素,仍适用人格权规则解决此类纠纷。这说明,个人信息作为数据源时,数据的控制主体、数据敏感度以及数据功能,决定人格权保护规则在该类纠纷中起主导作用,而涉及财产的保护规则很难涉入其中。本文认为,其原因主要在于以下两个方面:其一,人格权规则的适用依赖个人信息的精确查找,在个人信息未被数据企业利用之前,其完整性与可识别性决定了个人信息具备的人格权意义,而财产因子仅作为隐形因素附在个人信息之上。其二,实践表明,算法技术催生了个人信息的财产价值,用户服务协议是个人信息财产外化的典型体现。个人作为数据之源,为企业数据提供生产要素,是企业数据价值生成的直接参与者。而个人信息内部财产外化的过程是个人通过授权给企业使用而实现的。①【" ①参见彭诚信、史晓宇:《个人信息财产价值外化路径新解——基于公开权路径的批判与超越》,《华东政法大学学报》2022年第4期,第41-57页。】因此,违反知情同意规则是个人信息侵权认定的主要因素,而侵害个人信息的人格属性才是该类纠纷的直接起因。上述分析可推演出①:个人信息天然蕴含的财产基因是企业数据财产化的内在逻辑。
2.“个人信息+算法技术”影响了数据集合权益的分配
在“微头条案”中,企业对数据资源的竞争成为该案的起因,侵权行为表现为对数据集合完整性的破坏。法院基于企业数据的数量、功能、形态以及技术投入推定数据集合的财产属性,最终从人格权路径转换为反不正当竞争的路径来解决。可以发现,引起这种路径转换的原因主要有以下三点:其一,算法识别性是判断个人信息范围的核心依据,而算法识别性亦可以反向确定企业数据的客体范围。个人信息因算法技术的客观记录产生社会典型公开性,个人信息的可识别性是判断个人信息权益是否受到侵害的关键,②【" ②参见姚佳:《论个人信息处理者的民事责任》,《清华法学》2021年第3期,第50页。】这种可识别性必须以算法识别为前提。③【" ③参见彭诚信:《重解个人信息的本质特征:算法识别性》,《上海师范大学学报(哲学社会科学版)》2023年第3期,第75-78页。】同样,在数据流转过程中,从数据源到数据集合是个人信息财产化的过程,其本质是将内含于个人信息中的财产价值通过授权他人使用而实现。④【" ④参见彭诚信:《论个人信息的双重法律属性》,《清华法学》2021年第6期,第85页。】个人信息经过算法处理汇聚成数据集合,不具有单个可识别性特征,完成了从强人格属性到强财产属性的变迁,具有了可交易性。其二,算法投入是数据企业享有竞争性利益的判断依据。从数据价值的生成机制可以判断,数据企业是数据价值生成的制造者。在个人提供个人信息作为原料时,正是源于数据企业运用算法将个人信息脱敏,方能构成数据集合,从而纳入数据权利的客体范畴。从数据权利的生成逻辑看,亦是数据企业对数据权益的现实诉求,才成为法院对权利进行确认和维护的逻辑起点。其三,尽管企业数据的财产属性是纠纷发生的直接起因,然而数据企业对个人信息具有安全保障义务。这表明个人信息不会因数据企业处理而丧失人格权益,其上人格权益与财产权益具有不可分割性。上述分析可以推演出②:算法规制实质造就了个人信息权益与数据集合权益的二元空间结构。
3.“数据集合+技术优势”影响了数据产品权益的分配
与数据集合的有限财产权益不同,数据产品具有独立的财产属性,此时其上已经不再具有人格属性,技术优势成为数据企业享有财产权益的主要依据。在“淘宝诉美景案”中,“算法技术”既是引起该案的起因,又是划定数据产品范围的关键,而“合法性”是法院判断算法行为合法与否的核心因素。一方面,法院以匿名算法技术检测数据产品与个人信息的对应关系,实现了对两者范围的划分,正面确定了数据产品作为财产权益的独立内涵。同时以“合法、正当、必要的原则”作为处理个人信息的合法性基础,以此作为涉案双方处理数据合规性的判断标准。另一方面,数据企业一般通过Robots协议、加密技术等技术措施控制自身数据,法院以技术是否具有侵入性判断第三方处理行为是否合法。在“微头条案”中,法院根据“算法技术+Robots协议”,衡量第三方数据处理者的“获取行为+利用行为”是否具有侵入性、是否造成实质性损害等,这都是合法性的判断要素。由此可以推演出③:算法合法性限定了数据产品的权益边界。
(三)企业数据权属的分配规则
从数据价值的生成机制看,算法处于中心地位,从数据权利的生成逻辑看,因数据呈现的价值形态与利益类型的差异,导致各阶段的权利诉求自不相同。基于此,本文对企业数据在不同阶段的权益分配规则如下:
首先,作为数据源泉的个人信息,是个人行为与算法技术合作生成的结果,因此,对个人赋权是数据权益分配的逻辑起点。个人信息由平台和用户共同产生,但因其可识别性而具有人格属性,是个人意志的体现,个人依据原始取得获得所有权。一方面,个人信息之上的人格权益由个人永恒享有与动态控制。个人信息的保护具有优先性已在学界达成共识,这是社会价值观念形成的自发性规则。即便个人信息的人格属性在后续流转中已成为隐形因素,人格权优先保护思维时刻嵌入个人信息的全生命周期,人格利益永不褪色。另一方面,个人信息中的财产权益可以和个人分离并让渡,但在算法的作用下,其财产权益很难在数据集合纠纷中得以实现(推论①可知)。因此,个人信息的财产利益暂时只能通过人格权救济的方式消极实现。
其次,数据集合由“个人数据+算法技术”生成,其财产权益由个人与数据企业共同控制,其中数据企业基于算法投入享有有限排他权,用于对抗第三方数据处理者的不当抓取。一方面,数据集合作为一种资源,呈现的是数据控制者的劳动投入与数据价值可视化增长,数据企业自应成为数据权益分配的最大受益者(符合推论②);另一方面,由于个人信息人格利益与财产利益的不可交割性,当个人行使权利时,必然会对数据权利产生重大影响,由此导致两种利益相互冲突的现象。①【" ①参见王利明:《论数据权益:以“权利束”为视角》,《政治与法律》2022年第7期,第109页。】因此,在数据集合之上可设置有限财产权,②【" ②参见姬蕾蕾:《企业数据保护的司法困境与破局之维:类型化确权之路》,《法学论坛》2022年第3期,第116-119页。】可赋予数据企业对抗他人不当获取与利用的行为,但在权利内容、权利期限上应予以限制,以免对其他利益造成误伤。
最后,数据产品是算法技术对数据集合的深入挖掘分析后,生成的独特数据产品,符合深层加工的归属规则,应由数据企业依据原始取得的方式获取所有权。一方面,数据产品作为一种准知识产品,真正实现媒介属性和技术属性的高度融合,呈现为一种具象化的技术产品,将其确立为一种新型财产权,不单是对数据企业投入成本的肯定,更是对其作为新型财产本身的全面回应;另一方面,合法数据既是数据自由流通的要求,亦是数据企业获得权利的前提(符合推论③)。个人信息财产权益中都包含着人格权益,由此决定了数据利用不能突破保护个人信息之人格利益的底线,③【nbsp; ③参见彭诚信:《数字社会的思维转型与法治根基——以个人信息保护为中心》,《探索与争鸣》2022年第5期,第122-123页。】这也决定了数据企业对个人信息的处理,必须按照人格权益的法律保护逻辑,具备合法性与正当性基础,同时承担一系列的信息保护义务,为个人信息提供全面周延的保护。
四、企业数据财产权益的实现程序——以“卡-梅框架”规则检验归属效果
基于以上对企业数据权益归属的确认,本文借助“卡-梅框架”的分析范式,④【" ④“卡-梅框架”是以财产规则和责任规则为代表的理论模型,之后我国学者凌斌在此基础上增加管制规则和无为规则。参见凌斌:《法律救济的规则选择:财产规则、责任规则与卡梅框架的法律经济学重构》,《中国法学》2012年第6期,第6页。】根植于数据本身的复合属性以及数据流转的客观规律,从法律救济的角度检验企业数据的权益分配效果并决定规则选择,由此实现企业数据之上权益确认及其客体流转的双赢效果。
(一)数据源财产权益的实现路径:禁易规则+责任规则
根植于个人信息内含财产基因的人格本质属性,结合数据价值的生成阶段以及财产权益实现的当下实践,对个人信息的救济采用“责任规则+禁易规则”的复合性方式,可以达到保护与效率的双重法律效果。
1.禁易规则与个人的隐私利益及尊严
禁易规则是在明确法益归属的前提下,禁止买卖双方在即使是自愿情况下的自由转让。①【" ①⑤Calabresi G,Malamed D.Property rules,liability rules,and inalienability:one view of the cathedral.Harvard Law Review,Vol.85,1972,p.1092,p.1092.】个人信息是个人标识自己以及社会交往的工具,因而具有社会属性,也因此具备了流通的合法基础。但是,隐私信息作为自由与尊严的价值体现,不具有任何财产属性的交易价值。②【" ②参见彭诚信:《数据利用的根本矛盾何以消除——基于隐私、信息与数据的法理厘清》,《探索与争鸣》2020年第2期,第85页。】这类信息敏感度极高,一旦被泄露会对个人造成重大伤害,且损害是不可逆的。③【" ③Ohm P.Sensitive information.Southern California Law Review,Vol.88,p.1131.】如性取向、犯罪前科等应被列为隐私信息进行强化保护,原则上不得收集、处理或者利用。④【" ④参见范姜真媺:《个人资料保护法关于“个人资料”保护范围之检讨》,陈海帆、赵国强主编:《个人资料的法律保护:放眼中国内地、香港、澳门及台湾》,社会科学文献出版社2014年版,第60页。】尤其是大数据技术的应用,极大地提升了对隐私侵害的风险,人工智能技术还充斥着对个人自由意志的侵蚀。因此,隐私信息的内在性质决定了对其保护应适用禁易规则,如若允许隐私信息的自由交易,会降低其社会价值,并导致个人尊严的自我减损。我国《民法典》对隐私权与个人信息采用二元区分规定,并规定私密信息适用隐私权规则,可见立法从正面排除了隐私信息作为财产交易的属性与可能。因此,隐私信息保护采取禁易规则是个人信息进行合法流通的前提与底线,亦是算法行为合法的判断标准之一。
2.责任规则与个人信息财产利益的外化路径
责任规则是一种强买强卖规则,指相对人对权利人的财产可直接侵害,无须事先征得权利人同意,当对权利人财产造成损失时,应对其损失给予补偿,补偿价格(客观价格)通常由法官在具体案件中评估。⑤责任规则是从交易的角度考察个人信息的保护规则,可以发现以知情同意规则为基础构建的数据保护机制,符合“卡-梅框架”中财产规则以自愿交易为特征的基本设定。但在当前的现实情境中,运用财产规则实现个人信息中的财产价值既不现实,也不具有可操作性。其一,同意不等于授权。知情同意的性质不能一概而论,而应放在具体的法律关系中确定。个人信息的本质是人格利益,具有人身专属性,个人不得随意处分。因此,在网络服务协议中的同意条款难以产生授权效果,确切地说应该是一种免责事由。⑥【" ⑥参见高富平:《同意≠授权——个人信息处理的核心问题辨析》,《探索与争鸣》2021年第4期,第87-94页。】其二,个人信息的经济价值需要由数据企业利用智能算法催生,且由数据企业积极控制,个人在客观上很难享有对信息财产的处分权。其三,实践中知情同意规则的操作失灵。数据企业处理个人信息会以《隐私政策声明》告知个人并取得其同意,但大部分人不会仔细阅读隐私声明,甚至都不想更改默认隐私设置。⑦【" ⑦Ben-Shahar O,Schneider C E.The failure of mandated disclosure.University of Pennsylvania Law Review,Vol.159,2011,p.665.】其四,在交易中若参与主体的数量过多,则可能增加谈判障碍,导致协商议价失灵。⑧【" ⑧参见杨涛:《论知识产权法中停止侵害救济方式的适用——以财产规则与责任规则为分析视角》,《法商研究》2018年第1期,第185页。】换言之,虽然个人拥有议价的权利,但并未考虑在谈判过程中单条个人信息估价难且价值低的问题,⑨【" ⑨Schwartz P M.Property,privacy and personal data.Harvard Law Review,Vol.117,2004,p.2056.】这决定了财产规则中一对一的谈判模式并不符合效率正义。
对比财产规则对个人信息保护与利用中的理想状态与现实差距,责任规则更符合当下情境。其一,适用责任规则符合当下实践中对个人信息财产权益的保护方式。责任规则是一种事后救济,也可以对市场交易产生事前激励的效果,即留出一定空间对权利进行调整进而增进社会福利。⑩【" ⑩参见凌斌:《肥羊之争:产权界定的法学和经济学思考——兼论〈商标法〉第9、11、31条》,《中国法学》2008年第5期,第183页。】也就是说,责任规则能够使企业产生损害预防的正向激励,弥补收集、利用个人信息给个人带来的潜在损害,更能积极发挥个人信息的社会价值。B11【" B11参见曹博:《论个人信息保护中责任规则与财产规则的竞争与协调》,《环球法律评论》2018年第5期,第100页。】其二,责任规则更具有效率优势。责任规则的适用跳过了权利主体对其法益处分的主观意愿,这就回避了双方磋商产生的成本问题,解决了因授权成本过高导致效率难以达到最优的现状。换言之,当个人信息遭受侵害时,通过法院定价的方式要求数据企业承担赔偿责任,这恰好符合在司法实践中个人信息权益的实现方式。其三,责任规则符合分配正义。实践中,个人与数据企业对数据权益的分配方案是二者对数据收益进行共享。其中,数据企业基于算法投入与技术成本对数据财产权益享有积极控制权,符合分配正义和激励机制;个人对其财产权益不一定是通过积极确认的方式变现的。同时,考虑到个人在数据处理中的弱势控制地位,立法明确了一系列个人对其信息进行控制的权利组,并和数据处理者履行风险防范的义务规范群,形成全面周延的保护系统。一旦数据企业侵害个人权利或违反义务规范,均需承担法律责任,符合责任规则的法定交易内涵。
(二)数据集合财产权益的实现路径:财产规则+管制规则
将“卡-梅框架”放到对数据集合保护的实践中可以发现,现行司法裁判中对数据集合已然适用财产规则对其财产权益进行确认和保护。同时,考虑到数据集合权益之上利益重叠的现实困境,需要通过规制方式反向确定数据集合的边界,即适用“财产规则+管制规则”的复合方式,实现权利保护与算法管控的有效协同。
1.财产规则与数据集合的有限财产权益
在司法实践中,数据企业大多以不正当竞争为由提起诉讼,法院只能在这一框架内加以解决,这意味着数据企业是通过事后救济的方式实现权益诉求的,符合责任规则的基本特征。但是这种解决方式并未解决数据权属问题,清晰的产权规则是实现企业数据资源有效配置的逻辑前提,也是限制权利行使的制度基础。①【" ①参见包晓丽:《二阶序列式数据确权规则》,《清华法学》2022年第3期,第65页。】数据的价值在于流通,而数据许可使用是数据价值实现的基本内涵。无论是司法实践还是理论学说,将数据企业作为数据集合的权利主体已经成为共识。在产权清晰的前提下,财产规则能够最大限度地保障交易双方的意思自治,使资源配置达到帕累托最优。也就是说,对数据集合保护运用财产规则,数据企业可以和相对方进行谈判,形成一对一、一对众及相互许可的数据集合流通方式,②【" ②参见高富平:《数据流通理论 数据资源权利配置的基础》,《中外法学》2019年第6期,第1405-1424页。】实现数据集合的共享。需要注意的是,由于数据集合之上的多元利益纠葛,其上财产权并不是一种绝对排他性的权利,而仅是对抗具有竞争关系的行为人的权利。
2.管制规则与数据安全利益
管制规则是国家对私人交易直接干预,以保护交易双方之外的社会价值,是对法益的事前或事中救济。③【" ③参见凌斌:《法律救济的规则选择:财产规则、责任规则与卡梅框架的法律经济学重构》,《中国法学》2012年第6期,第6页。】在保障数据自由流通实现其价值的同时,必须要保障数据安全,消除数据流动产生的负外部性。④【" ④关于数据跨境流通规则的中国路径,参见沈伟、冯硕:《全球主义抑或本地主义:全球数据治理规则的分歧、博弈与协调》,《苏州大学学报(法学版)》2022年第3期,第44-46页。】因此,引入管制规则,既可以通过合法性标准对数据集合进行确权,又可以通过规制算法行为塑造其权益边界,扫清数据交易的障碍。具体而言:首先,管制规则一般由行政部门通过“标准”实现“管制”目的,即“要么达标,要么退出”。⑤【" ⑤参见肖冬梅、文禹衡:《法经济学视野下数据保护的规则适用与选择》,《法律科学》2016年第6期,第123页。】数据集合若要成为一项法律保护的法益,必须符合严格的合法性要件。如《网络安全法》关于数据保密原则,数据合法、正当、必要原则,匿名化原则等,《数据安全法》关于数据风险监测、数据风险评估等数据安全义务的规定。其次,通过算法规制,构建以用户为中心的算法规则体系,可以塑造数据集合的权利范围。即引入风险最小化的算法设计标准、确立算法解释权、制定数据迁移标准、建立算法审计制度等,⑥【" ⑥参见韩旭至:《数据确权的困境及破解之道》,《东方法学》2020年第1期,第107页。】达到平衡多方利益的效果。最后,通过管制规则,可以对第三方数据处理者不当抓取数据的行为进行限制和处罚,这恰好与数据集合有限财产权的内容相呼应。从风险防范的角度,单纯依靠私法规制和行业自律难以制止数据不当竞争纠纷,相比责任规则,引入管制规则进行事前遏制更具有效率优势,即由专门的监管部门对第三方数据处理者的不当行为进行合理控制,达到防患于未然的效果。
(三)数据产品财产权益的实现路径:财产规则+责任规则
在数据产品权属清晰的前提下,引入财产规则可以最大限度地实现其经济价值。同时为防止数据垄断的发生,引入责任规则打破数据壁垒,有助于促进社会福利最大化。
1.财产规则与新型财产权益
技术优势造就数据产品成为一项新型知识产品,是数据价值的最高点,为数据企业增添了竞争优势。由于数据产品与个人信息在内容上不再具有对应性,在其之上设置绝对权既不存在理论障碍,也是立法应有之义。数据财产权作为一项新型财产权,其权利结构体现为数据企业对数据产品地控制、使用、传输、处分的权能体系。因此,在法律关系单一,产权清晰的现实情境中,建立在自愿交易基础上的财产规则,可以最大限度地实现数据产品的优化配置。数据企业通过合同处分进行再分配,由第三方数据处理者通过技术创新突破数据产品的最大价值。质言之,对于数据权利财产价值的实现,以交易为手段来达到数据权利的权能分离状态,以最大限度地保持数据的活力和竞争力。需要强调的是,数据企业在进行初始分配后,对数据产品后续开发利用生成的财产权益,应由第三方数据处理者享有,在先企业仅在财产权益受损失时消极享有数据价值。
2.责任规则与社会公共利益
如果财产本身即具有较强的社会关联性,它就应该受到更多限制。①【" ①参见张翔:《财产权的社会义务》,《中国社会科学》2012年第9期,第111页。】数据本身即承载人格利益、经济利益及公共利益,在涉及公共利益的特定情形时,引入责任规则是破除数据垄断,强制数据流动的必要选择。“当政策偏好在于促进数据产业发展或其他公益目的时,运用责任规则可以扫清数据获取的障碍就会变得更为可取。”②【" ②丁晓强:《个人数据保护中同意规则的“扬”与“抑”——卡-梅框架视域下的规则配置研究》,《法学评论》2020年第4期,第137页。】具体而言:其一,建立数据合理使用制度。当数据产品被应用于教育、科研领域时,为了社会发展的需要,数据企业应许可数据利用者对其使用,但不得与第三方恶意共享。其二,构建数据强制许可制度。强制许可是依照法律的规定,无须权利人同意,政府可直接使用该财产,但应当向权利人支付适当报酬。“这是一项针对特定事项的应急性制度,可以满足社会的特殊要求”③【nbsp; ③钱子瑜:《论数据财产权的构建》,《法学家》2021年第6期,第88页。】,是对数据企业独占地位的一种社会性约束,可保障数据健康流通,避免扼杀其后续价值。其三,确立数据强制公开制度。与传统财产权不同的是,数据的利用价值在于其可预期性,在公共管理和公共安全中发挥重要功能。因此,数据企业在获取与国家公共安全、社会稳定等相关预测信息时,应及时向国家相关机构报告,并公开其数据信息内容。④【" ④参见龙卫球:《再论企业数据保护的财产权化路径》,《东方法学》2018年第3期,第61页。】
五、结论
在数字社会,推动数据创新的关键在于解决数据权益分配问题。数据之上复杂交织的利益关系,决定了其上存在网状互联的权益结构,并非简单套用状态性的赋权方式可以解决,必须根植于数字社会背景,探寻数据价值以及数据权利的生成机制,方能确定可供参考的权益配置图景。“算法即规则”强调算法为人类的线下和线上生活提供了数据化框架,①【" ①参见张吉豫:《数字法理的基础概念与命题》,《法制与社会发展》2022年第5期,第49页。】亦体现出算法在数据价值生成中的核心架构。因此,本文意在探寻可计算性的数据权益配置方案。具体而言,按照数据价值的生成逻辑,将数据分为数据源、数据集合与数据产品三种价值形态,结合实践中数据财产权益分配的裁判基准,对数据权益分配方案进行设计:运用算法识别出来的个人信息(数据源),因内含财产基因的人格属性而归属个人所有,可通过“禁易规则和责任规则”消极实现其财产权益;数据集合的财产权益由个人与数据企业共同享有,数据企业可通过“财产规则+管制规则”积极实现其有限财产权益;数据产品由数据企业完全享有,可通过“财产规则+责任规则”实现其财产权益最大化。
[责任编辑:无 边]
Attribution Determination and Realization Procedure of Property Interests in Enterprise Data
JI Lei-lei
(Koguan School of Law,Shanghai Jiao Tong University,Shanghai 200240,China)
Abstract:How to allocate and realize the rights and interests of enterprise data property is a judicial dilemma and theoretical problem faced by digital jurisprudence.The root cause of the difficulty in the distribution of the rights and interests of enterprise data property is that the academic community relies on the traditional property rights theory to solve the problem of enterprise data ownership,and fails to effectively identify the complex interest relationship on the data,and fails to clarify the core problems that the data rights system aims to solve.Algorithm is the core of data value generation,and using algorithmic thinking to explore the calculable data equity distribution scheme is more in line with the objective law of data flow and current practice.To be specific,using algorithm architecture to judge the value form of data and judge the scope of data rights and interests can be phased allocation of enterprise data rights and interests.Data value generation goes through three forms:data source,data set and data product.The judicial position of data equity boundary at each stage is investigated,and the ownership subject of property equity is determined:the property equity of data source belongs to the individual,the property equity of data set is shared by the individual and data enterprise,and the property equity of data product belongs to the data enterprise.On this basis,the “Camp;M framework” is used to test the effect of enterprise data ownership and determine the procedural rules for realizing the rights and interests on it,so as to achieve the win-win effect of the ownership confirmation and dynamic protection of enterprise data property rights and interests.
Key words:enterprise data;ownership of interests;algorithm regulation;the basis of judgment;the Camp;M framework
