
基于物联网视角农业环境大数据系统设计要点研究
2023-03-22 09:29:16张向丰
物联网技术 2023年3期
张向丰
(黄河水利职业技术学院,河南 开封 475000)
0 引 言
在传统的农业生产模式中,从业者依靠经验判断作物长势、制定管理策略,但由于缺乏精确的数据支撑,容易出现偏差。基于物联网的农业环境大数据系统能够解决该问题。此类系统的设计重点在于数据的获取途径、存储方式以及分析处理方法,本文从这三个方面对系统的设计要点进行深入探索,旨在提出科学的设计方案。
1 农业物联网
1.1 农业物联网技术
农作物生长对环境条件有一定的要求,如土壤水势、土壤酸碱性、环境温度、空气湿度、光照强度等方面。现代农业生产的精细化、智慧化程度在不断提高,这就要求在农业管理中加强对各类环境数据的监控,并在其基础上制定科学、高效的策略。在这一过程中涉及到各类农业环境数据的检测、存储和展示。
农业物联网以互联网技术为基础,融合了各种类型的农业数据传感器,加强了农业生产者的信息感知能力。另外,将农业物联网技术与数据分析算法、人工智能等相结合,可实现较高水平的自动化种养。
1.2 农业物联网的体系架构
按照数据生成到应用的先后顺序,可将农业物联网的体系架构划分为五层,如图1所示。
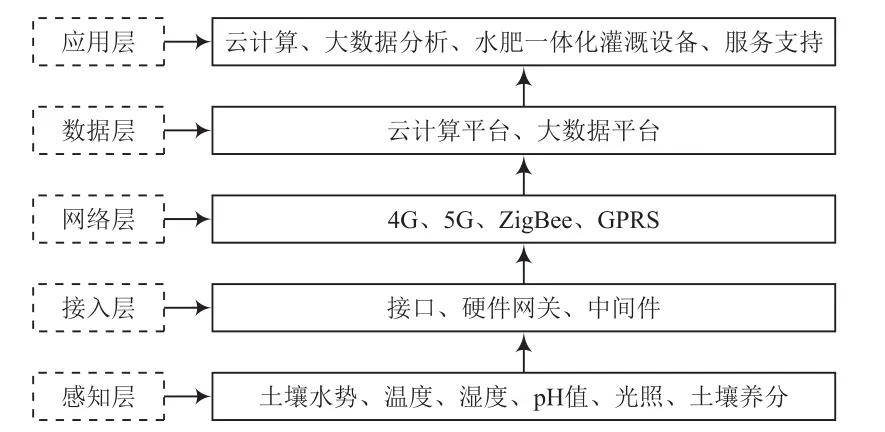
图1 农业物联网体系架构
(1)感知层
感知层是农业物联网采集环境大数据的主要渠道,其核心设备是各种传感器,如小型智能气象站、土壤墒情检测仪、温湿度测量仪器等。当前,传感器的智能化水平不断提高,其采集的数据可自动上传至系统管理后台。
(2)接入层
农业物联网中存在多种类型的传感器,其生产厂家、通信方式可能存在差异。接入层用于实现不同传感器的访问,提升系统兼容性。接入层由中间件、网关以及接口组成。以硬件网关为例,可兼容以太网、RS 485、RS 232等多种输入方式,可满足不同传感器的通信需求[1-2]。
(3)网络层
通信网络是农业物联网的重要组成部分,传感器的数据上传、管理后台对设备的远程操控均依赖于通信网络。常用的通信方式为GPRS、4G、5G等。在大数据系统中,数据传输规模较大,对网络层的传输速率提出了较高的要求。
(4)数据层
数据层的功能包括两个方面,分别为数据存储和数据预处理。传感器长期运行,会产生大量的农业环境数据,由数据层提供存储功能,实现资源集中与共享。数据预处理的目的是清洗粗大误差、补充部分缺失值,必要时进行数据转换,如归一化处理,为后期的数据分析、计算和应用创造有利的条件。
(5)应用层
数据层实现了原始数据的集中存储,应用层的功能则是进一步分析、开发、挖掘原始数据,从而发现农业生产的规律、建立相应模型,指导农业生产决策[3-4]。云计算、大数据技术在应用层发挥着重要作用,是数据分析的主要技术手段。
2 物联网视角下的农业环境大数据系统设计要点
2.1 设计思路分析
2.1.1 农业环境大数据采集
数据是大数据系统的基础,在设计过程中应该根据农业生产的特点,完成传感器选型、网络通信方式选择,并考虑数据存储方式、存储能力等因素。
2.1.2 农业环境大数据存储
搭建农业环境大数据系统需要解决大规模存储以及访问快速响应的问题。在本文的系统设计中将HDFS作为农业环境大数据的存储方式。HDFS是Hadoop体系中的分布式存储组件,其本质是一个文件系统,通过流式数据访问模式存储超大文件,能够将数据分块存储到硬件集群内的不同机器上。
2.1.3 数据计算和挖掘
初始采集的农业大数据缺乏规律,难以指导农业生产决策,因而需借助算法挖掘数据中的潜在规律。大数据技术中的聚类算法、神经网络算法、决策树算法等均能处理农业生产数据,既能分析历史数据,又能预测作物生长情况。例如,在智慧灌溉中可采用随机森林算法构建水肥一体化模型。ID3算法、C4.5算法以及CART算法属于较为成熟的随机森林算法。在实际应用中先收集农业灌溉及作物生长的大数据,在其基础上提取数据特征,开展模型训练,最后形成具有水肥预测能力的灌溉模型,进而指导灌溉活动。
2.2 系统架构及主要子模块
2.2.1 系统整体架构
(1)数据层
数据层分为数据源存储模块和大数据存储模块两部分,前者建立在关系型数据库(如MySQL、SQL Server)的基础上,从农业传感器以及国家农业信息化资源网站获取原始数据。后者采用HDFS分布式存储模式,用于汇总经过预处理的合格数据,在汇总的过程中还须根据业务特点实施数据分类。
(2)业务层
业务层采用Apache Spark大数据处理引擎,以聚类算法构建数据分析和计算的模型。Spark中的MLlib机器学习库可用于迭代计算,利用该扩展库提高农业大数据的处理效率。
(3)交互层
交互层设计有三大功能,分别为算法管理、数据管理、数据上传及下载。显然,交互层服务于人机交互。数据管理模块以可视化的方式展示数据挖掘的结果,提高管理人员的数据理解效率。
2.2.2 系统主要子模块
子模块是对数据层、业务层、交互层的功能细分,在软件设计中需逐层分解功能需求,以便开展详细的业务流程设计与程序代码开发。系统平台子模块包括HDFS分布式存储模块、源数据存储模块、机器学习模块、算法实现模块、源数据获取模块、数据预处理模块、SQL查询模块、上传下载模块。
2.3 系统硬件设计
2.3.1 软硬件配置
软硬件资源是农业环境大数据系统的重要组成部分,涵盖部署在农田环境内的终端传感器、计算机、操作系统等。计算机为系统提供了计算资源,大数据系统中集成了算法,可批量处理规模较大的数据,对计算机的CPU、缓存、硬盘资源等提出了较高的要求。表1为计算机软硬件设计方案。
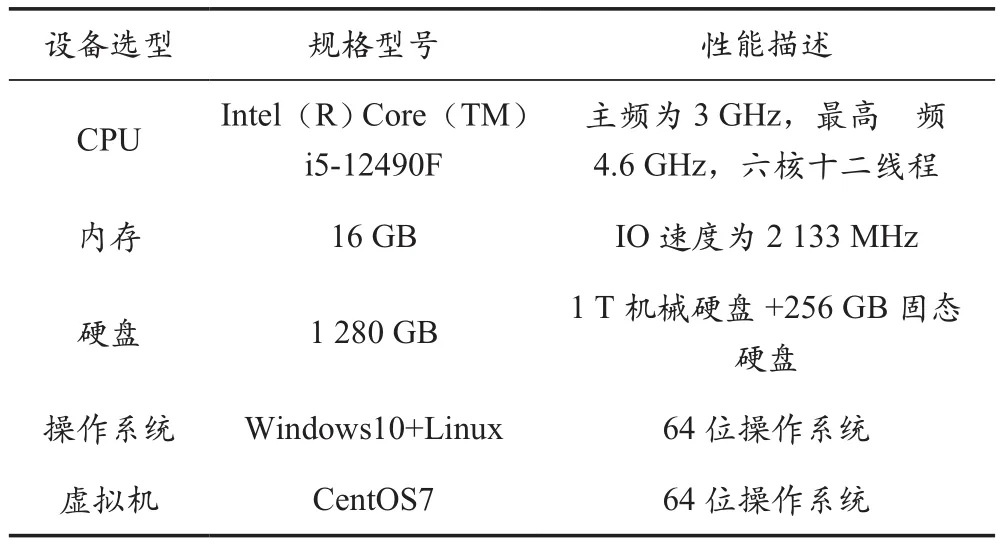
表1 农业环境大数据系统软硬件资源配置
2.3.2 集群设计
HDFS采用分布式存储方式,将较大的数据文件分块存储在不同的机器上。因此,在系统硬件设计阶段应配置集群。具体实现流程为创建CentOS虚拟机、网络调试、虚拟机克隆、安装系统基本环境、安装Hadoop、安装Apache Spark、配置ssh访问秘钥等[5-6]。以上安装过程推荐采用Linux环境。集群中设置多个Hadoop节点,可根据实际需求进行拓展。
2.4 数据处理功能
2.4.1 数据存储
(1)数据源存储
数据源存储于MySQL数据库,传感器采集的数据通过通信网络上传至接口,再经过后台代码的处理,最终写入数据库,网络中采集的数据也可采用相同的方式进行存储。设计人员应根据数据特点设计表结构、字段名称、字段类型以及字段长度等。农业环境中的温度、湿度、pH值、光照强度等均为数值型数据,因而可采用关系型数据库。表2为字段设计的实例。
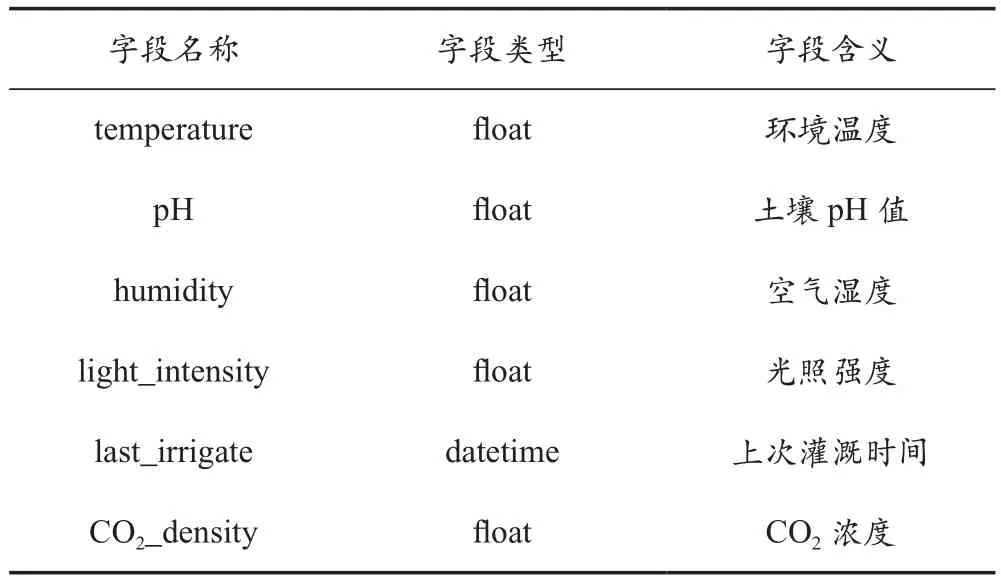
表2 农业环境大数据系统数据源字段存储实例
(2)HDFS数据存储
HDFS主要存储经过预处理的农业环境大数据,Hadoop技术框架中存在Stributed File System(分布式文件系统),由多个机器组成,每台机器上运行一个DataNode进程,负责管理一部分数据。在所有机器中,由一台机器独立运行NameNode进程,客户端通过该进程实现数据读写[7-8]。HDFS通过以上方式实现大数据的分布式存储。
2.4.2 数据分析
Spark的MLlib机器学习库集成了数据清洗、SQL查询、建模等一系列功能,模型建立依赖于算法。在MLlib中内置了通用性的学习算法,包括分类、协同过滤、回归、聚类等。农业环境大数据系统利用MLlib中集成的GMM算法、K-means算法完成数据分析和建模。软件工具中提供了统一的算法调用编码方式。例如,K-means算法的调用代码为import org.apache.spark.ml.clustering.BisectingKMeans。将预处理后的农业环境大数据导入算法中,再进入数据训练阶段。
2.5 系统应用测试
2.5.1 测试方法
(1)数据源
以某地的高等级西瓜种植区为数据采集的主要对象,棚内设置有多种传感器,数据采集指标为CO2浓度、植株间距、根系温度、环境温度、土壤pH值等[11-12],共计10项内容。实地采集的数据样本不足以支撑算法模型训练,因而引入部分网络开源数据,以提高各项指标的数据量。为检验数据量对处理结构的影响,将其设置为三种级别,其对应的数据量分别为1万组、10万组、100万组。数据存储在HDFS中,文件格式为csv。
(2)实施过程
以JAVA语言编写算法调用程序以及各类功能性程序,实现数据导入功能;再启动Hadoop集群,开展数据分析和模型训练。
2.5.2 结果分析
本系统以K-means算法和GMM算法处理西瓜种植的各类环境大数据,结果见表3所列。K-means算法的关键在于K的取值,其决定了数据分簇的数量,表3为K=3时的处理结果。在Spark的MLlib库中设置有专门的算法性能评估工具,使用该工具评价K在不同取值时的聚类准确率[9-10]。当K=2时,该算法的数据处理准确率达到了86.8%。当K=3时,该算法的数据处理准确率达到了89.5%。另外,系统平台的数据分析处理能力与其运行时长存在密切关联,如果数据完全一致,处理时长越短,表明其性能越强。针对三种级别的数据规模,该系统的数据处理时长分别为8 593 ms(数据量为 104)、25 989 ms(数据量为 105)、215 098 ms(数据量为106),可见系统的运行时长与数据量呈正相关。数据分簇意味着产生了三种聚类结果,观察表3中各项指标的数值,发现其一致性较高,只有个别指标存在小幅差异,如植株间距、根系温度、土壤湿度,可能原因是各簇的数据样本有所不同。总体而言,基于物联网的农业环境大数据系统能够高效分析和处理农业生产中的各类数据源。

表3 农业环境大数据系统的K-means算法聚类处理结果示例
3 结 语
将物联网技术、大数据技术和现代化的智能传感器整合在一起,可建立科学的农业数据服务及管理平台,为制定农业生产措施提供强大的技术支撑。基于物联网的农业环境大数据系统由传感器、计算机、通信网络、算法程序等软硬件模块组成,设计要点为软硬件交互方式、算法模型、数据存储方式,具体的解决方案是依托Spark的MLlib库引入K-means、GMM算法,利用HDFS构建分布式存储。
猜你喜欢
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
电脑爱好者(2020年19期)2020-10-20 06:02:06
电子制作(2019年13期)2020-01-14 03:15:18
中国交通信息化(2019年2期)2019-03-25 03:20:12
中国设备工程(2019年8期)2019-01-17 11:16:42
计算机与生活(2018年3期)2018-03-12 08:38:11
自动化学报(2017年5期)2017-05-14 06:20:51
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
