
基于SE-ResNeXt的苹果叶片分类方法
2023-03-21 08:59:04白旭光刘成忠韩俊英高嘉蒙陈俊康
计算机与现代化 2023年1期
白旭光,刘成忠,韩俊英,高嘉蒙,陈俊康
(甘肃农业大学信息科学技术学院,甘肃 兰州 730070)
0 引 言
苹果的种植资源非常丰富,世界各地都有栽培。根据西汉司马相如的《上林赋》记载,中国最早的苹果栽培历史可以追溯到公元前125年,到现在的2000多年里,苹果新品种不断被选育,导致苹果品种混杂频繁,苹果产业效益低。因此,如何高效、简便、准确地识别苹果品种是一个重要课题,对优质苹果品种的推广与苹果产业的发展至关重要。
传统的苹果品种分类方法,需要苹果种植户或育种人员依靠自己的直觉和专业知识对果园中的果实、树木、树枝和树叶的植物学特征进行现场观察和分析,这种方法过多依赖人员的知识经验储备和主观判断,此外由于不可量化,并不适合在大规模的果园中使用;另一种方法是依靠专业人员在实验室中使用物理、化学和生物技术分析苹果的理化性质从而识别苹果品种,这种方法不仅昂贵和耗时,且对普通种植者非常不友好。
目前,随着数字图像处理技术和计算机视觉技术在农业中的应用,人们提出并研究了许多利用植物叶片图像进行植物分类的机器学习方法,如k-最近邻(KNN)、决策树、支持向量机(SVM)[1-8]。传统的机器学习方法需要人工设计和提取判别特征,而人工提取的特征在不同植物间的迁移性较差,因此不同植物品种需要设计不同的判别特征。受人工特征选择的影响,传统机器学习模型的稳定性、鲁棒性与泛化性较差,无法满足实际科研和生产的需要。近年来,卷积神经网络(CNN)已发展成为计算机模式识别任务的最佳分类方法之一,判别特征不再需要人工设计,而是由卷积神经网络通过多次卷积操作自动提取图像中的低维和高维特征。卷积神经网络在基于图像识别中的突破性应用激发了其在智慧农业中植物分类和识别研究中的广泛应用。
近年来,国内外针对植物叶片图像识别的研究取得了不错的成果。Yalcin 等[9]提出了一种卷积神经网络结构,使用叶子图像对不同的作物进行分类。郑一力等[10]通过使用Inception V3 预训练模型得到的植物叶片图像测试集准确率为95.40%,有效提高了识别准确率。Dyrmann等[11]通过使用卷积神经网络,对22 种处于早期生长阶段的杂草和作物图像训练和测试,分类准确率达到86.2%。Lee 等[12]提出了一种基于植物多器官的卷积神经网络HGO-CNN,通过融合植物器官和植物整体的信息,支持使用不同数量的植物图像进行分类,在PlantClef 2015基准测试中的表现优于其他网络。郑艳梅等[13]使用BiseNet 卷积神经网络对苹果叶片图像自动分割,并进行引导滤波处理,对174 种苹果叶片试验,精确率达到98.99%。李鑫然等[14]提出一种改进的Faster RCNN模型,对5种苹果叶片病害进行检测,平均精度均值达82.48%。周宏威等[15]通过构建VGG16、ResNet50、Inception V3 这3 种神经网络模型,使用迁移学习的方法,对5种病害苹果叶片进行识别,精度分别达到97.67%、95.34%和100%。
以上研究中,基于叶子图像输入的卷积神经网络对植物进行分类已经成为智慧农业中的一个焦点与挑战,引起了全球学者及从业人员的广泛关注,但目前该方向仍处于起步阶段,相关研究成果较少,特别是在特定植物品种上。因此,本文从实际生产与研究问题出发,以主流的苹果品种为研究对象,使用深度残差网络SE-ResNeXt101,基于深度学习提出一种基于苹果叶片图像的苹果品种分类方法,用于解决科学研究与实际生产中的苹果品种分类问题。
1 材料与方法
1.1 样本数据集
将采用尼康COOLPIX B700 数码相机在位于甘肃省平凉市静宁县的苹果产业基地所拍摄的苹果成熟叶片作为图像数据集。苹果叶片图像数据集包含20 种苹果,分别为(a)宝斯库普、(b)紫云、(c)西伯利亚白点、(d)花奎、(e)金花、(f)甜黄魁、(g)战寒香、(h)甜帅、(i)帕顿、(j)早生赤、(k)伏红、(l)毕斯马克、(m)60-15-9、(n)维斯塔贝拉、(o)齐河短金冠、(p)矮黄、(q)1192、(r)矮红(荷兰)、(s)张家口短枝、(t)红星。对存在背景干扰的图片使用GrabCut算法分割图像提取苹果叶片目标,剔除背景干扰,优化模型从而对目标识别。20种苹果叶片类别如图1所示。

图1 20类苹果叶片图像
数据集共包含20 个苹果品种,每个品种有50 幅苹果叶片图像,按照8:2 的方式分离为训练集与测试集。对训练集进行随机数据增强处理,缓解了原数据集数据量过少的问题。
对苹果叶片图像良好的数据增强操作会提高模型的精度,降低模型的运行开销。分析数据集样本的数量、分布和一致性。针对数据集数据量较少的问题,在保证不丢失数据特征信息的情况下增强数据特征。通过随机缩放策略将图片缩放至不同大小,在不改变模型的前提下改变了模型的感受野,模型可以提取更多特征;通过随机旋转策略和随机水平和垂直翻转策略来模拟从不同角度拍摄的图片;通过向图片中添加适量的高斯噪声来扭曲图片的低频和高频特征,增强模型的学习能力,提高模型的泛化能力与鲁棒性。
1.2 模型方法
模型训练的总体结构如图2 所示。将拍摄的不同种类苹果叶片图像数据预处理,按照8:2 的比例随机分成训练集和测试集,并对训练集图像进行数据增强。使用基于SE-ResNeXt101 的迁移学习(Transfer Learning)模型,将训练集数据导入模型训练,在所有的训练结束后使用测试集检验模型最终的精确度(Accuracy)与损失率(Loss)。至此,得到基于苹果叶片图像数据集的苹果品种分类模型。该模型是一种卷积神经网络模型,在模型训练的过程中,每张图像都以3×224×224的尺寸依次输入模型,模型通过多层卷积操作可以提取出图像从低级到高级的复杂特征。在初始卷积阶段获取图像局部、细节信息;深层卷积阶段获取图像复杂、抽象的信息;经过所有卷积层的卷积操作最终得到特征矩阵(Feature Map),再通过全连接层(Fully Connected Layer)与Softmax 函数将分类结果转化成概率分布,从而实现苹果叶片品种的分类。

图2 总体结构图
SE-ResNeXt101[16]深度卷积神经网络模型是由ResNet 网络的变体ResNeXt[16]网络以及在残差结构(Residual Block)中添加SE(Squeeze and Excitation)模块组成,101 指网络的深度为101 层。理论上不断扩展网络的深度,可以让网络学习到更多维度的信息,提升网络的最终学习效果。但在实际情况中一味扩展网络的深度会造成梯度消失(Vanishing Gradient)、梯度爆炸(Exploding Gradient)[17]以及退化问题(Degradation Problem)等情况,网络的学习效果反而会变差。在ResNet中使用了Residual模块解决模型的退化问题,以及使用BN(Batch Normalization)解决梯度爆炸或梯度消失问题。ResNeXt网络是ResNet网络的一种变体,其设计的初衷是为了降低原模型的参数量,故采用了Inception 网络的思想,使用组卷积(Group Convolution)[18]代替传统卷积(Convolution),加宽网络,有效降低了训练参数量,以更加结构化的方式学习数据特征,模型训练更加快速,占用资源更小,运行更加稳定。传统卷积与组卷积参数对比如图3所示。

图3 传统卷积与组卷积

表1 SE-ResNeXt101 网络架构
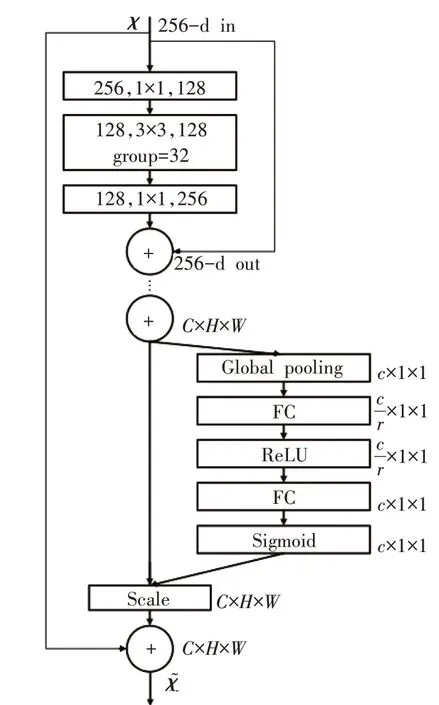
图4 SE-ResNeXt模块
1.3 迁移学习
对于深度卷积神经网络来说,动辄上千万个的参数量使得训练过程中需要大量的数据集作为支撑,且训练速度不够快。而模型中的浅层卷积层所提取的各种点、线、角信息以及纹理信息在其他数据集中也是通用的,因此将深度神经网络模型在相似训练集上训练得到的参数提取出来,并用于新的数据集的训练中,将能大幅度缩短模型训练时间,且在数据量较少的情况下也能一定程度上保证模型的泛化能力。这种深度神经网络模型的训练方式被称为迁移学习。常见的迁移学习方式有3种:
1)模型载入权重后训练所有参数。此方法需要降低学习率,且最后一层无法载入预训练参数,但会使模型更加具有泛化能力。
2)模型载入权重后只训练最后几层全连接层的参数。此方法训练参数少,训练速度快。
3)模型载入权重后再添加新的全连接层,且只训练新的全连接层。
本文选择第2 种迁移学习方法,训练过程收敛速度较快且拟合效果好,较小的学习率使模型的训练过程较为稳定,模型仅需做出局部调整,降低了系统的的运行压力。
1.4 模型评价指标
模型评价指标用来评估模型的泛化能力,为了从不同角度考察模型,本文采用精确率(Precision)、召回率(Recall)、F1-score 等指标进行评估[23]。精确率P为预测结果为正例样本中的真实标签为正例的比例;召回率R为真实标签为正例样本中的预测结果为正例的比例;F1-score 为精确率与召回率的调和平均值,反映了模型的稳健性[24]。指标公式如表2所示。

表2 模型指标公式
2 实验与结果分析
2.1 实验设置
本文使用百度飞桨深度学习平台PaddlePaddle框架,版本为2.0.2,采用Adam 优化函数,PiecewiseDecay学习率如公式(1)。
其中训练迭代次数step为260次,共20个Epoch,批大小为64。基于Linux Ubuntu系统,采用Python3.7语言,使用高性能GPU设备加速计算。训练配置如表3所示。
表3 训练配置表
2.2 图像识别模型性能对比
本 文 使 用ResNet50、ResNet101、SE-ResNet50、SE-ResNet101、SE-ResNeXt50、SE-ResNeXt101 进行对比实验,在保证除模型外的所有条件都相同的前提下,结合苹果叶片图像数据集,使用基于ImageNet 预训练后的参数进行迁移学习[25],最后评价上述6个模型的性能。将用训练集训练好的各模型,使用同一测试集进行分类预测,记录各模型的最高Top-1准确率与模型的可训练参数量,经过可视化后比较选出最优模型,如图5 所示。使用Top-1 准确率(Top-1 accuracy)、平均精确率(Average precision)、平均召回率(Average recall)、F1-Score[26]作为模型评价指标,如表4所示。

图5 多种模型参数量与准确度比较
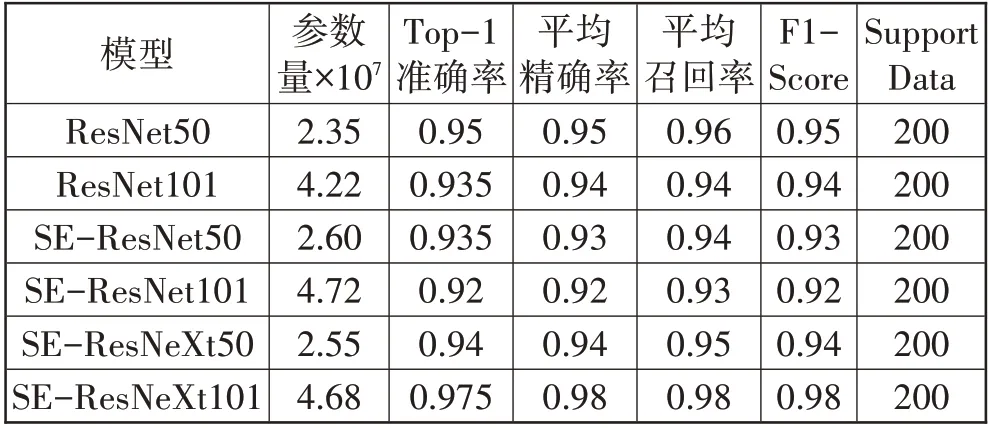
表4 各模型性能指标比较
如图5 所示,从SE-ResNet 与ResNet 模型可以看出一味地增加模型深度与参数量可能会使模型准确度下降;ResNet 相比SE-ResNet 模型准确率要高出1.5%,说明SE 模块提取的特征多为噪声;SEResNeXt 模型由于在Bottleneck 加入了组卷积使模型参数量相对于SE-ResNet 模型有了明显降低,并且组卷积通过以对角线为结构的稀疏性来学习各特征层间的联系[27],故具有组卷积的SE-ResNeXt 模型相对于SE-ResNet与ResNet模型有着更好的泛化性能。
表4 为各模型在苹果叶片测试数据集上的各项性能指标。各模型Top-1 准确率与平均精确率均在92%以上,平均召回率在93%以上,各模型在苹果叶片图像数据集上均有优秀的表现。模型F1-Score 均在92%以上,说明各模型在精确率与召回率上表现较为均衡。由于对训练集进行有效的数据增强,且SEResNeXt101的网络结构较为合理,故基于迁移学习的SE-ResNeXt101在测试集上得到最高Top-1准确率为97.5%,且其他性能指标均为最高,达到了98%。
2.3 SE-ResNeXt101模型性能分析
表5 为模型在训练集和测试集上的准确率表现。Top-1 Accuracy 是指排名第1 的类别与实际结果相符的准确率,Top-2 Accuracy 是指排名前二的类别包含实际结果的准确率[28]。经过长时间训练,训练集的准确率接近100%,Top-1 训练集准确率达到了99.43%,此时Top-1 测试集准确率达到了97.50%,模型在测试集上表现效果较好。

表5 模型准确率
图6 为SE-ResNeXt101 模型基于测试集的混淆矩阵,其主对角线位置上的数字代表模型的正确识别率,其余位置为模型的错误识别率,横坐标为模型预测标签,纵坐标为叶片真实的标签。由于宝斯库普、紫云、西伯利亚白点、花奎等品种的叶片形态特征非常突出,与其他品种差异较大,因此这些品种的识别率为100%;金花、甜帅与60-15-9 的识别率中等,金花容易被错误分类成毕斯马克,甜帅被错误分类成伏红,60-15-9 被错误分类成矮黄,它们的识别率分别为91%、92%、90%;帕顿的识别率最低,由于帕顿和早生赤品种叶片有一定的相似性,且帕顿叶片缺乏独特性,所以帕顿的识别率较低,只有82%。
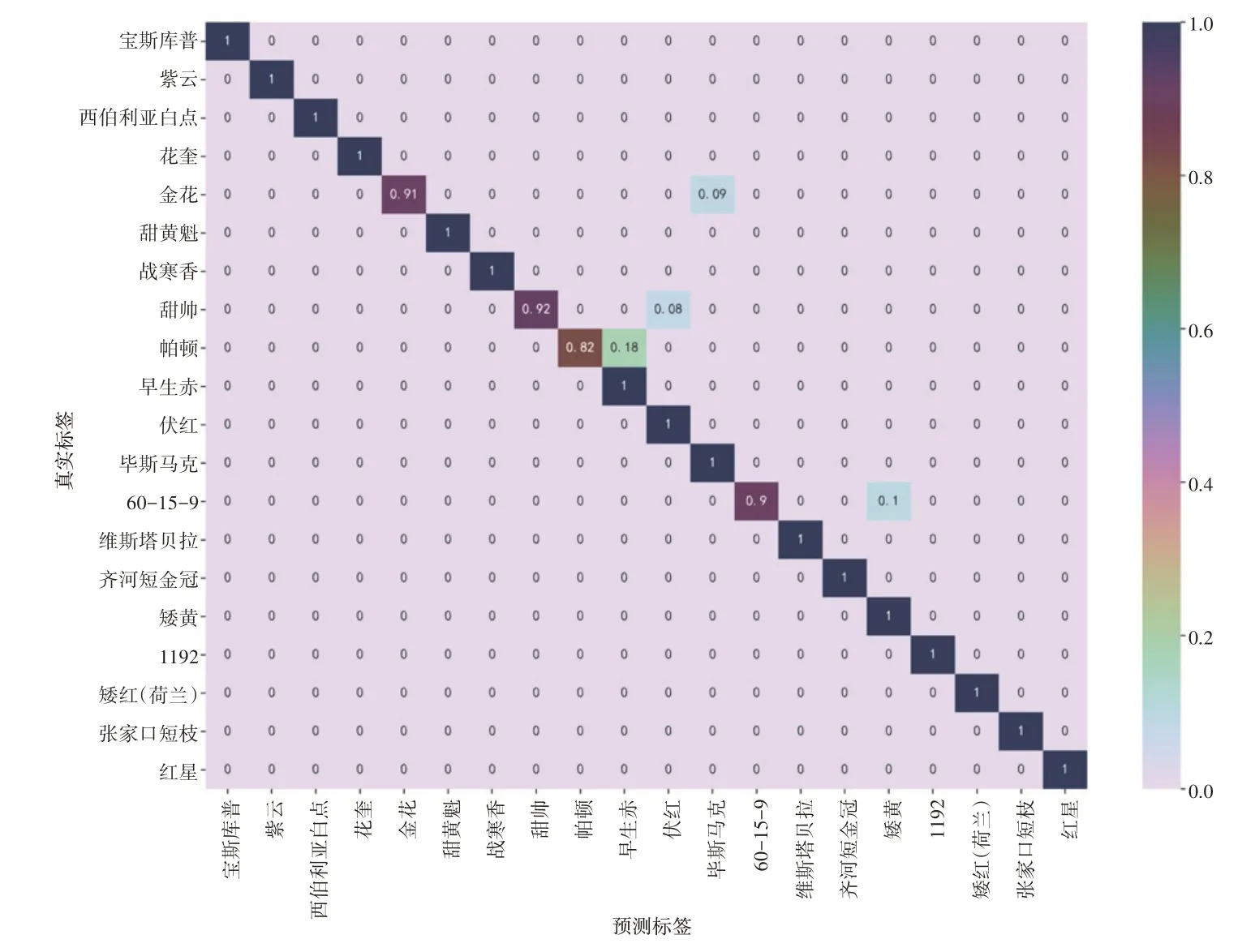
图6 混淆矩阵
综合上述混淆矩阵以及模型分类评价指标表,如表6 所示,考虑识别准确率的情况下,模型对帕顿的识别能力最差,如果综合考虑精确率与召回率(β=1)即F1-score的情况下,模型对帕顿的识别能力同样是最差的,F1-score 仅为0.90,表明模型对帕顿叶片特征的提取还有待提高。

表6 模型分类评价指标
3 结束语
本文基于SE-ResNeXt101 的迁移学习网络构建了苹果叶片图像分类模型,模型可以自行设计和提取判别特征,不需要额外的工作,其可以自动检测不同维度的语义特征,实现了对生活中常见苹果如甜帅、金花和矮黄等20 种苹果的有效识别,在测试集上的Top-1 识别准确率最高可以达到97%以上,Top-2 识别准确率最高可以达到100%以上,平均精确率、平均召回率和平均F1-Score 均达到了98%。经过对比发 现,模 型 比ResNet50、ResNet101、SE-ResNet50、SE-ResNet101 和SE-ResNeXt50 模型分类效果更好,通过数据增强的方式提高了数据集的数据量,可靠性与泛化能力较强。该模型可以运用到农技科研工作人员与苹果种植农户的实际科研和工作中,结合农业专家系统提高农业智能化水平和工作效率。
未来的工作将旨在通过研究其他深度神经网络模型,例如Transformer 来识别苹果品种。此外,需要收集来自不同种植区的更多苹果品种的更多叶子图像,以提高模型在更多苹果品种上的泛化性能和效率。且该模型还可迁移至其他果树的品种识别甚至其他植物的品种识别。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
