
基于YOLOv5的目标识别追踪模型轻量化
2023-03-17 11:48:18李海鹏
汽车实用技术 2023年5期
李海鹏,余 强
(长安大学 汽车学院,陕西 西安 710064)
自动驾驶领域离不开道路环境感知,其中基于卷积神经网络的目标检测近年来发展迅速[1]。基于深度学习的目标检测算法可以分为单阶段与两阶段。其中单阶段常用的有单阶段多盒检测器(Single Shot MultiBox Detector, SSD)[2]算法和YOLO系列,包括YOLOv3[3]、YOLOv4[4]和YO- LOv5[5],双阶段的有区域卷积神经网络(Region Convolutional Neural Networks, R-CNN)系列等。目标追踪算法用于车载移动端多采用在线追踪算法,其中Deep SORT[6]算法被广泛采用。但是由于网络权重较大,不易于以较低成本部署在边缘设备,而大幅度的压缩权重会以牺牲目标检测准确度为代价。因此,本文提出如何在减小YOLOv5模型权重下,尽可能减小目标检测准确度的下降。
1 数据集准备
1.1 获取车载视频流
道路环境复杂多变,采用单目摄像机获得车辆周围物体的信息。通过安装在车辆上的摄像头获取车辆在道路上行驶时的实时视频,进而处理分析。实验车辆与摄像机的安装位置如图1所示。

图1 实验车辆与摄像头位置
数据包括在高速路、城市道路以及乡村道路车载实时视频,同时也应包括在城市行驶一天的早高峰、午低谷和晚高峰三个时间段内车辆道路环境视频。
1.2 数据集标注
需要先从视频中随机截取图片进行图片标注,再进行视频流标注。截取的图片大小均为 1320 bits×1080 bits,标签共分为15类。其中选择3330张图片作为训练集,888张图片作为测试集。利用软件LabelImg标注所有图片。完成后进行部分视频流标注,随机从数据集中选择连续的241帧图片和650帧图片,其中分别有37条轨迹和108条轨迹。标注出每帧目标的位置信息、分类信息和序号。
2 改进YOLOv5算法
在目标检测算法中,模型太大不易于低成本地部署于边缘设备中。在压缩模型与保持模型精度需要进行取舍,本文选择YOLOv5系列中的YOLOv5s进行改进,在降低模型大小同时以损失精度较小代价。
2.1 YOLOv5算法
根据模型大小的宽度和深度不同,可以将YOLOv5算法分为YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x四种版本。本文选择宽度和深度最小的YOLOv5s进行改进,其结构主要分为预处理、主干网络、Neck部分和Head检测端。预处理需要对数据集进行Mosaic数据增强、自适应锚框计算以及自适应图像填充处理。在主干网络中需要运用Conv模块和C3[7]模块进行特征的提取,其中C3模块可以起到压缩模型并提高推理 速度的作用。在Neck部分由特征金字塔(Feature Pyramid Networks, FPN)和路径聚合结构(Path Aggregation Network, PAN)所构成,可以将语义信息和特征信息进行不同层级间的交流传递。Head检测端是处理得到的不同尺寸下的特征图,具体区分为大目标、中目标和小目标。目标识别完成后将置信度信息、位置信息和分类信息重新映射回原图,同时输入给目标追踪网络进行进一步处理。YOLOv5流程图如图2所示。

图2 YOLOv5流程图
2.2 YOLOv5结合GhostConv
在传统的卷积特征提取中会存在大量的冗余,如图3所示。对于给定数据X∈Rc×h×w,其中c是输入通道数,h和w分别是输入数据的高度和宽度,用于生成n个特征图的任意卷积层的操作可以用公式描述:

图3 传统Conv处理过程
式中,b为偏置常数;n为通道数;Y∈Rh'×ω'×n为输出的特征图;卷积核为f∈Rc×k×n;h'和w'为输出特征图的高和宽;k×k为卷积核f的大小。
可以运用GhostConv[8]来代替YOLOv5中的卷积模块来对模型进行压缩,同时减小对模型精度的影响,如图4所示。需要先进行普通卷积得到部分的基础特征图,再对基础特征图进行廉价卷积线性变换φk得到ghost特征图,最后特征图数目与原来的卷积操作一致,如以下公式描述:
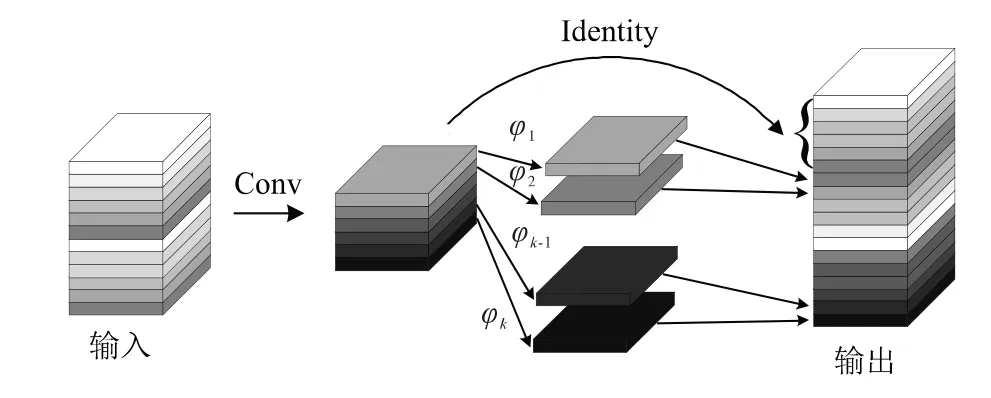
图4 GhostConv处理过程
式中,Y'∈Rh'×ω'×m;*为卷积操作;m为进行普通卷积的通道数;φi,j为进行线性变化卷积操作。廉价的卷积操作消耗算力少,也可以包括其他变换等。其中m始终不大于n,若m=n则与等价于普通卷积。
2.3 YOLOv5结合shufflenetv2
shufflenetv2是一种轻量形网络,融入YOLOv5网络中能起到压缩模型大小,加快推理的效果,主要是图5中的两种模块起作用。

图5 shufflenetv2模块
图5 (a)中的Conv为普通卷积,DWConv表示深度卷积。Channel Split操作为对特征图的通道进行分割,在此为均分。Channel Shuffle操作可以增加通道间的信息交流,类似于将通道以某种方式打乱重组。
图5(a)中先将通道均分,一部分不做处理,另一部分进行卷积等操作。随后将两份特征图合并,使得输出的通道数和输入的通道数一致,最后进行的Channel Shuffle操作。图5(b)中没有Channel Split操作,将特征图进行不同的卷积处理,后续操作与图5(a)一致。两者模块均采用了1×1卷积,可以压缩模型大小同时对精度影响不大。
3 结合Deep SORT算法
Deep SORT算法是由SORT算法改进而来。以YOLOv5处理后得到的目标检测框、置信度和特征作为输入,运用级联匹配算法、交并比(Intersection over Union, IOU)匹配算法和卡尔曼滤波算法进行处理,完成目标追踪。
在Deep SORT算法中,先收到由YOLOv5网络传来的已识别目标的种类信息、置信度信息和位置信息。在初步筛选后运用卷积神经网络进行重识别,对目标框内的特征进行提取。利用余弦距离计算距离,结合卡尔曼滤算法,加权马氏距离进行级联匹配,未匹配目标则继续进行IOU匹配,最终可得到目标轨迹,在经过最终结果可利用匈牙利算法得到目标追踪轨迹。此处将重识别网络使用shufflenetv2中的模块进行组合替换,可进一步压缩模型大小,并对追踪精度影响较小。目标追踪算法流程图如图6所示。

图6 Deep SORT流程图
4 实验结果
表1为YOLOv5s、YOLOv5s+ shufflenetv2和YOLOv5s+shufflenetv2+Ghostconv的结果对比,包括模型参数、GFLOPs、权重大小和mAP-0.5的对比。

表1 mAP-0.5对比
图7为在数据集中视频流的追踪效果图,其模型大小在压缩的情况下实时性和模型精度均可达到预期要求。

图7 目标追踪示意图
5 结论
本文通过对YOLOv5s结合shufflenetv2中的模块,模型大小从13.7 MB下降为1.9 MB,而mAP-0.5只从0.888下降到0.810。网络在融入Ghost模块后,可以对模型整体进一步进行压缩,模型大小下降至1.7 MB,而mAP-0.5可以达到 0.835。选取同样权重大小较小的模型NanoDet-m模型进行横向对比,在检测精度上YOLOv5s+ shufflenetv2+Ghostconv的精度更高。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
电子制作(2019年11期)2019-07-04 00:34:38
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2018年11期)2018-08-04 03:25:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
测绘科学与工程(2016年5期)2016-04-17 06:51:15
电子设计工程(2015年3期)2015-02-27 12:03:45
电视技术(2014年19期)2014-03-11 15:38:20
