
面向多角度文字检测的旋转交并比神经网络
2023-03-15 09:55姚宏扬仝明磊施漪涵
计算机应用与软件 2023年2期
姚宏扬 仝明磊 施漪涵
(上海电力大学电子与信息工程学院 上海 200090)
0 引 言
文字检测是计算机视觉领域的一个重要研究方向,在各行各业中具有广泛应用。自然场景下的文字蕴含重要的语义信息,有助于描述和理解图片内容。目前,文字检测的方法大多数是通过卷积神经网络(CNN)得到的特征图上生成区域建议作为候选目标,生成有可能包含待检测目标的预选框,随后进行文字的分类和回归,如CTPN[1]、R2CNN[2]、MultiBox[3]、Textbox++[4]、Faster R-CNN[5]和Mask R-CNN[6]等。在以上的检测算法中,边界框回归是定位目标的一个关键步骤。在检测算法的网络中,文本区域通常都表示为带有多个参数的矩形框,分别是矩形框的中心坐标、尺寸和方向等。因此,文字检测任务通常被描述为回归任务,目的是达到标注值与预测值之间的差异最小化。
文字检测最常用的评价标准是文字区域框选的准确程度。通常采用重叠面积交并比评估指标来比较不同检测算法的精度。2016年提出的IoU(Intersection over Union)损失函数(IoU Loss)[7]和2019年提出的广义IoU损失函数(GIoU Loss)[8]证明了L1和L2损失函数在边界框回归上效果不如IoU损失函数。在网络中,边界框的每个参数独立训练,使用L1和L2损失函数将梯度反向传播时每个参数也是独立的,但实际上这些参数共同组成边界框,应当是有相关性的。IoU损失函数就在反向传播时,将每个单独的参数整合为边界框之间的交并比,作为重叠面积的损失传播到网络。尽管IoU Loss和GIoU Loss解决了预测框的尺度敏感及参数缺乏相关性的问题,但仍面临回归不精准的问题。
现在的检测算法可以较好地收敛水平或垂直的边界框,但是自然场景中的文字目标都有很大的方向随机性,如果只能收敛成水平和垂直边界框,就会包含非常多的背景冗余区域,使得检测准确度不高,也影响到后续的文字识别等操作,如何更好地回归出具有旋转方向的边界框来检测随机方向的文本仍然是一个挑战。
为了实现更快、更精准的旋转目标检测和解决模型训练时预测参数缺乏相关性的问题,本文提出一种旋转交并比(Rotation-Intersection over Union,RIoU)损失函数。通过添加锚点旋转参数,使预测边界框的参数中带有角度信息,将角度信息用于边界框回归,再对交并比损失函数添加合适的角度惩罚项,使预测到的边界框参数具有很强的相关性,并且角度参数也能够快速收敛。与之前的水平检测方法不同,我们增加旋转锚点的方法可以使预测提议更加适应文本区域,减少了检测出的背景部分所占比,在网络最后的非极大值抑制部分也引入了旋转交并比的算法,在抑制冗余预测框时,不仅考虑交并比分数,还要考虑到边界框的角度信息,使得最终获得的结果能够更加精准。
1 文字检测关键步骤
1.1 文字检测的评估
大多数文字检测任务中的评估标准使用联合交叉指标(IoU),具体表现为预测框与标注框的面积交并比来确定一组预测中的正样本和负样本,以及预测框对目标包围的准确性。现有的文字检测数据集标注都是以文字区域的真实形状标注,通常是矩形框或四边形框的四个点坐标,具体形状的方向角度有很大的随机性。此时,只能提供水平和垂直区域的检测算法不能精准地框选住真实的文字区域,使得检测精度不会很高。
1.2 损失函数与边界框回归
在文字检测中,网络模型学习边界框的参数至关重要。在2016年提出的YOLO v1[9]中采用了对边界框参数直接回归的方法,并对w和h参数取平方根来减轻回归边界框时的尺度敏感。2018年的YOLO v3[10]则是采用了2-wh。R-CNN中是通过选择性搜索算法[11]计算出预测框的位置和大小,并对预测框进行参数化表示。通过定义了边界框尺寸的对数偏移量来减轻预测框的尺度敏感,最后将L2范数作为损失函数来优化网络参数。Fast R-CNN[12]中为了使网络对于异常值的学习鲁棒性更高,提出了L1平滑损失函数。2018年提出的Focal loss[13]解决了训练时正样本和负样本之间的不平衡而导致训练预测框参数困难的问题。
1.3 非极大值抑制
非极大值抑制(NMS)是大多数目标检测算法中的最后一个步骤,对于同一个目标预测得到的多个检测框,非极大值抑制会删除与最高得分框的重叠部分超过阈值的冗余框。2017年提出的Soft-NMS[14]通过连续IoU函数使网络学习的鲁棒性更高。最近,自适应NMS[15]和Softer-NMS被提出,以用来学习合适的阈值和加权平均算法。在本文中,RIoU Loss的方法也被应用于非极大值抑制步骤中,抑制冗余框时会同时考虑到重叠面积和边界框的角度偏差。
2 旋转交并比损失函数
交并比的表达式:
(1)
式中:Bgt=(xgt,ygt,wgt,hgt)为标注边界框真值;B=(x,y,w,h)为网络模型预测边界框参数。IoU损失函数的表达式为:
(2)
然而,这里的IoU损失函数只能以水平预测框去对比场景图片里的文字区域,在有角度偏差的情况下也不会提供额外的移动梯度去优化边界框的回归,导致检测准确度无法提高。
2.1 旋转锚点参数
为了能检测到旋转文字区域,在生成锚点时,锚点的参数中加入角度信息θ,由中心点坐标、宽与高、旋转角度组成:
vanchor=(x,y,w,h,θ)
(3)
式中:θ为边界框底边与x轴的夹角。在整个网络中,从区域建议网络(Region Proposal Network,RPN)生成目标可能存在的区域,到锚点框在特征图上得到的候选预测框,再到最后预测框的分类和回归,整个过程中边界框的参数都带有角度信息,网络可以正确地训练边界框的旋转参数以检测旋转目标区域。
2.2 旋转交并比损失函数的计算
为了更好地训练旋转参数,增加预测框参数之间的相关性,本文设计一种旋转交并比损失函数,损失函数带有额外的角度惩罚项,将预测框的形状与角度关联起来,该惩罚项的定义为:
(4)

如图1所示,对于宽高比为2∶2的正方形和4∶1的矩形文字框实例,两种形状的文字框面积相同,深色的预测框与浅色的标注框之间的角度都相差30度,中心点坐标和宽高都分别相等,此时两种情况的smooth L1损失函数都是为1的最小值。细长矩形文字框的IoU损失值要大于方形文字框,表明细长文字预测框与标注框重合程度较低。RIoU损失函数的角度惩罚项对于两种实例得出两个不同的值,30度的偏差时角度惩罚值都是0.33,但因为宽高比不同,角度惩罚值乘以了一个不同的约束值,约束值和宽高比成正比。对于宽和高相差较大的矩形文本框,角度的偏差会使文字框远离中心的两端产生更大的偏差,导致预测框两端不能框选到文字部分,大幅影响交并比。而宽高相近的方形文字框即使有角度偏差,也能与标注框有较大的重合部分。故式中宽和高平方和与和平方的比值就是用来调整不同形状的边界框角度偏移的约束值。最终的旋转交并比损失函数定义为:
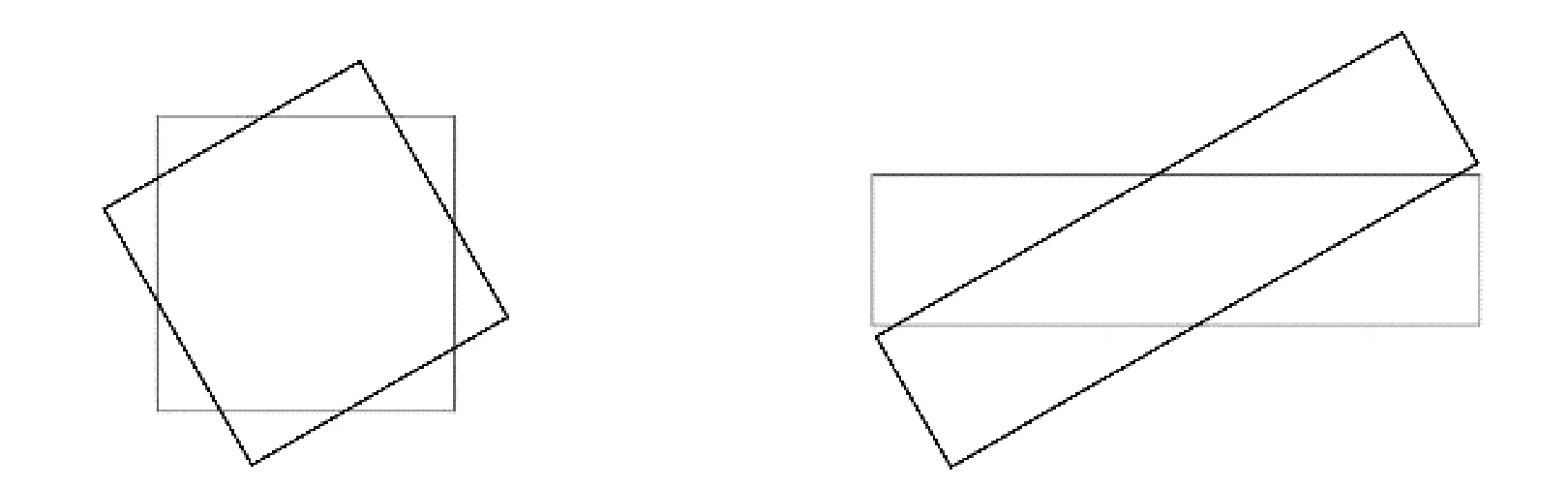
LSmoothL1:1 LSmoothL1:1LIoU:0.3 LIoU:0.66R(B,Bgt)=0.5×0.33 R(B,Bgt)=0.68×0.33图1 smooth L1损失函数与IoU损失函数两种情况对比
(5)
当预测框与目标框完全重合时,LRIoU=0;当两个边界框不相交但角度一致时,LRIoU=1;两个边界框不相交且角度有偏差时,LRIoU≤2。
对于旋转多边形的IoU计算,我们采用算法1。
算法1RIoU旋转矩形交并比计算
输入:预测框x,目标框xgt。
输出:RIoU。
x=Coordinate transformation(x)
xgt= Coordinate transformation(xgt)
For eachpixal(i,j) do
ifintersection(i,j)>0 then
I=intersection(i,j)
U=rectangle(x)+rectangle(xgt)-I
else
RIoU=0
end if
end for
function Coordinate transformation(boundingbox)
(x1,y1,x2,y2,x3,y3,x4,y4) ← (xc,yc,w,h,θ)
return result
end function
带有角度的矩形交并比不同于水平矩形交并比的算法,水平矩形之间的相交部分也是矩形,只用通过简单的宽与高相乘即可得到,而带有方向的矩形之间,重叠部分都是不规则的多边形,我们计算多边形的面积是采用程序中引用多边形函数库的方法。在算法1中,x表示预测框的位置形状参数,xgt表示目标框的位置形状参数,文字框的参数都是以(xc,yc,w,h,θ)的形式组成。数据集所提供的标注坐标都是以边界框四个点的形式标注,为了方便计算交并比和绘制边框,需要将锚点的参数转化为相同形式的坐标,通过基于基本数学三角函数的坐标转换函数Coordinate transformation将文字框参数转化为文字框的四个点坐标,具体为从左上点起顺时针计算(x1,y1)到(x4,y4)为方框的四个点坐标。如果预测框与标注框有相交部分,则通过多边形函数库求出相交面积I。rectangle(x)为预测框的矩形面积,rectangle(xgt)为目标框的矩形面积。U为联合区域的面积。由此可以得到预测框与标注框的旋转交并比。
RIoU损失函数弥补了smooth L1损失函数的不足。如图2所示的三个实例分别表示不同情况下三种损失函数的值。其中深色框与浅色框分别为预测框和标注框。当预测框和标注框都水平时,RIoU损失函数会简化为IoU损失函数,仅考虑两个框的重叠面积。但是现实图像上绝大部分文字区域都是有旋转角度的,前两种情况中因为smooth L1损失函数只考虑边界框的位置和形状所以得到的值相同,但明显两个框的偏差较大。此时RIoU损失函数就能很好地反馈到预测框的偏差。第三种情况下两种框的位置形状完全相等,smooth L1损失函数的值已经最低,无法给网络传播梯度,但实际预测到的并不准确。RIoU损失函数可以将角度偏差传递给网络进行优化,对于文字检测来说,RIoU损失函数对其检测的准确度有很大提升,能够增强训练文本的角度信息,更准确地框选出文本区域。如果需要针对3D空间的目标检测,也可以设计出合适的定轴旋转方案。
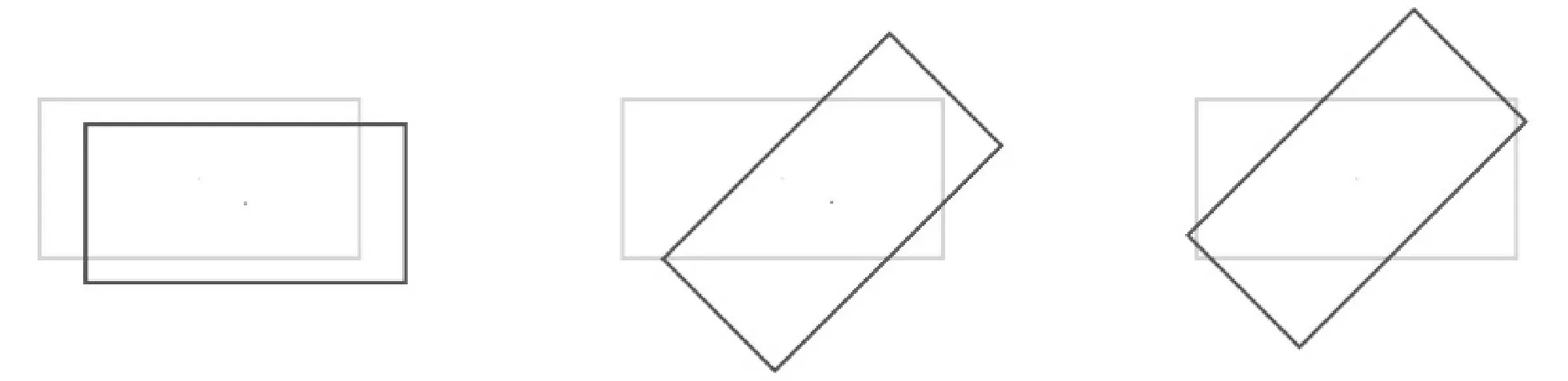
LSmoothL1:1.4 LSmoothL1:1.4 LSmoothL1:1LIoU:0.3 LIoU:0.7 LIoU:0.6LRIoU:0.3 LRIoU:0.725 LRIoU:0.625图2 三种损失函数对应不同情况下的值
2.3 旋转交并比损失函数与边界框收敛
损失函数作为神经网络对训练误差惩罚的依据,可以直接影响到网络模型的收敛。相比于smooth L1损失函数单独地优化锚点参数, RIoU损失函数是将边界框统一为一个边界框整体,去训练边界框统一后的位置和形状,从而提供更准确的边界框预测。RIoU损失函数对尺度没有敏感性,对于形状相差很大的边界框也能进行归一化后的比较,损失函数的值范围是[0,2]。如图3所示,RIoU损失函数与smooth L1损失函数和IoU损失函数相比在快速收敛边界框形状的同时,能够准确地回归边界框的角度信息,使预测框与目标框更加匹配,在最后进行评估时减少了很多冗余区域,准确度会有很大的提升。
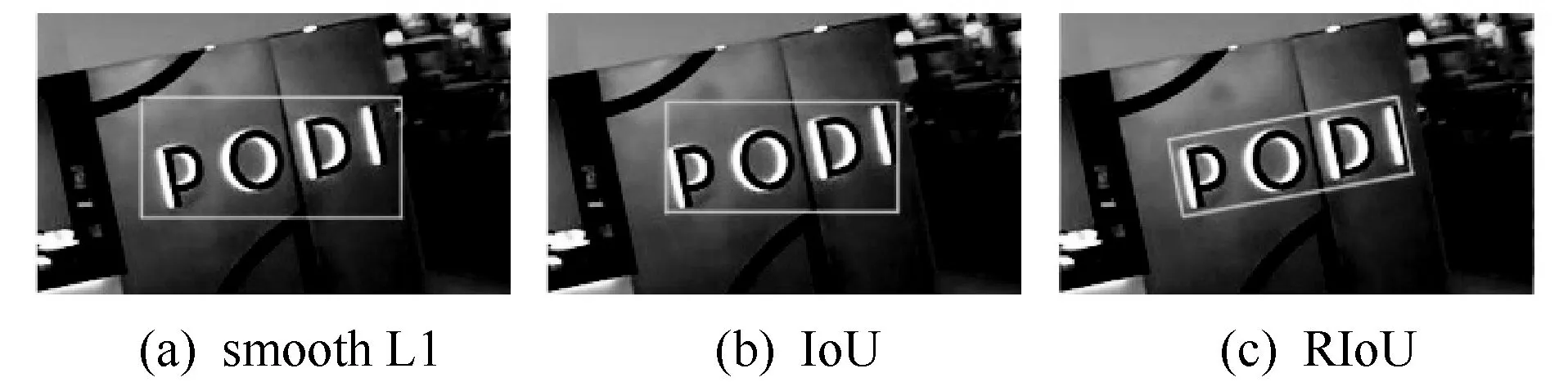
图3 三种损失函数回归结果
在非极大值抑制步骤,我们采用RIoU来替换原始的IoU标准来抑制冗余检测框。在抑制过程中不但要考虑重叠区域,还要考虑两个文字框之间的夹角,共同组成预测框的阈值分数。RIoU-NMS定义为:
(6)
式中:M为最高得分的预测框;ε为非极大值抑制的阈值;通过考虑IoU和两个框之间夹角来删除冗余框Bi;si为未被删除的预测框的分数。若某个预测框与最高得分框相交面积较小或角度相差过大,则这个预测框可能是其他目标的检测框,不应该被抑制删除。重叠面积较大,但角度相差也很大的预测框也会保留,这样对于重叠或相交的两个文本目标就可以被很好地区分检测出来。
3 实验结果
实验使用一块TITAN X显卡,显存为12 GB,CPU为Intel Core i5-2320 @3.00 GHz×4,内存为15.6 GB。软件环境为ubuntu16.04,cuda9.0+cudnn7.4.1。遵循相同的训练方案:每次训练5万迭代次数,主干网络为ResNet-50。
3.1 数据集
本文在文字检测公共竞赛数据集ICDAR 2015[16]上进行了实验,ICDAR Robust Reading Competition是进行场景文字检测和识别任务最知名和最常用的数据集。ICDAR 2015数据集共包含1 500幅图片,其中1 000幅作为训练图片,500幅作为测试图片。图片内容为随身穿戴设备拍摄的现实场景照片,照片中的文字都具有透视形状和角度方向性。
3.2 实验与分析
本文将增加锚点旋转参数的方法和RIoU损失函数结合到目前主流的Faster R-CNN检测算法中。在训练模型最后的边界框回归阶段我们使用RIoU损失函数与smooth L1损失函数和IoU损失函数进行了对比。另外,本文还对三种损失函数的回归情况进行了比较,对比了模型收敛速度和检测效果。图4展示了三种损失函数在ICDAR2015上的测试结果。

图4 ICDAR2015数据集结果对比
图4(a)中使用smooth L1损失函数的检测器虽然检测出比较多的文字区域,但是每个文字区域的框选不够精准,存在将文字邻近的边界图案一起框选进来的情况。相比之下图4(b)中IoU损失函数的检测器对文字区域的框选就更加准确,对文字区域边框的检测较为准确,但是因为只能检测水平区域导致有很多的背景也被框选进来。检测结果最好的图4(c)中,使用RIoU损失函数的检测会对边界框进行旋转角度的回归,相比IoU损失函数,文字区域的框选因为旋转后向文字的真实区域收缩,框选到多余背景的情况大量减少,对文字区域的检测更精确。
为了验证RIoU损失函数对于文字检测的有效性,将三种损失函数在ICDAR 2015数据集下的测试结果进行了对比。表1展示了测试结果。采用的是相同的官方评估标准。通过最终的检测结果显示,使用RIoU损失函数配合网络中边界框增加旋转参数和改进非极大值抑制的方法,相比较于默认检测方法,召回率和检测准确率得到11百分点的提升,H-mean得到11百分点的提升。
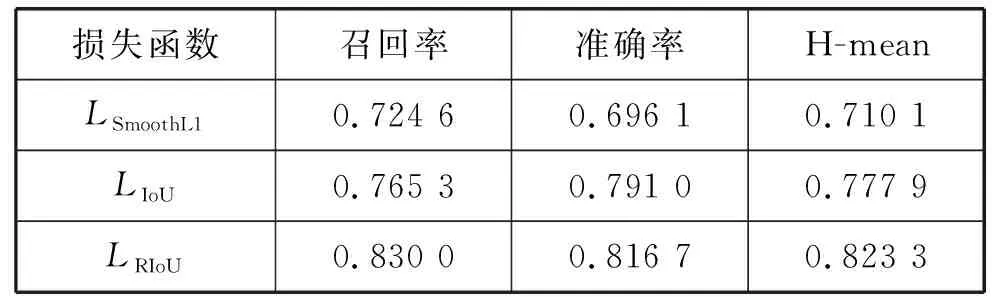
表1 ICDAR 2015数据集的测试结果
为了验证每个损失函数对于网络参数的收敛速度影响,采取了每10 000个迭代次数保存一次训练模型的方式。图5所示,RIoU损失函数和IoU损失函数在10 000次迭代时就能获得很高的检测准确度,虽然IoU损失函数也会让网络模型加快收敛,但在相同的迭代次数下,使用RIoU损失函数的模型检测准确率要高于IoU损失函数。相比之下,smooth L1损失函数只能较为平缓地优化网络,需要大量的训练步数才能达到中等的检测精准度,一方面是smooth L1损失函数只能单独优化回归框的每个参数,向网络传播梯度时没有传递足够的指示性,导致回归框的参数只能单独缓慢收敛;另一方面是对于非水平的文本区域也只能检测出一个水平方框,会有很多背景区域被框选进来,导致精准度随训练步数上升得较慢,最终的结果也不是很高。
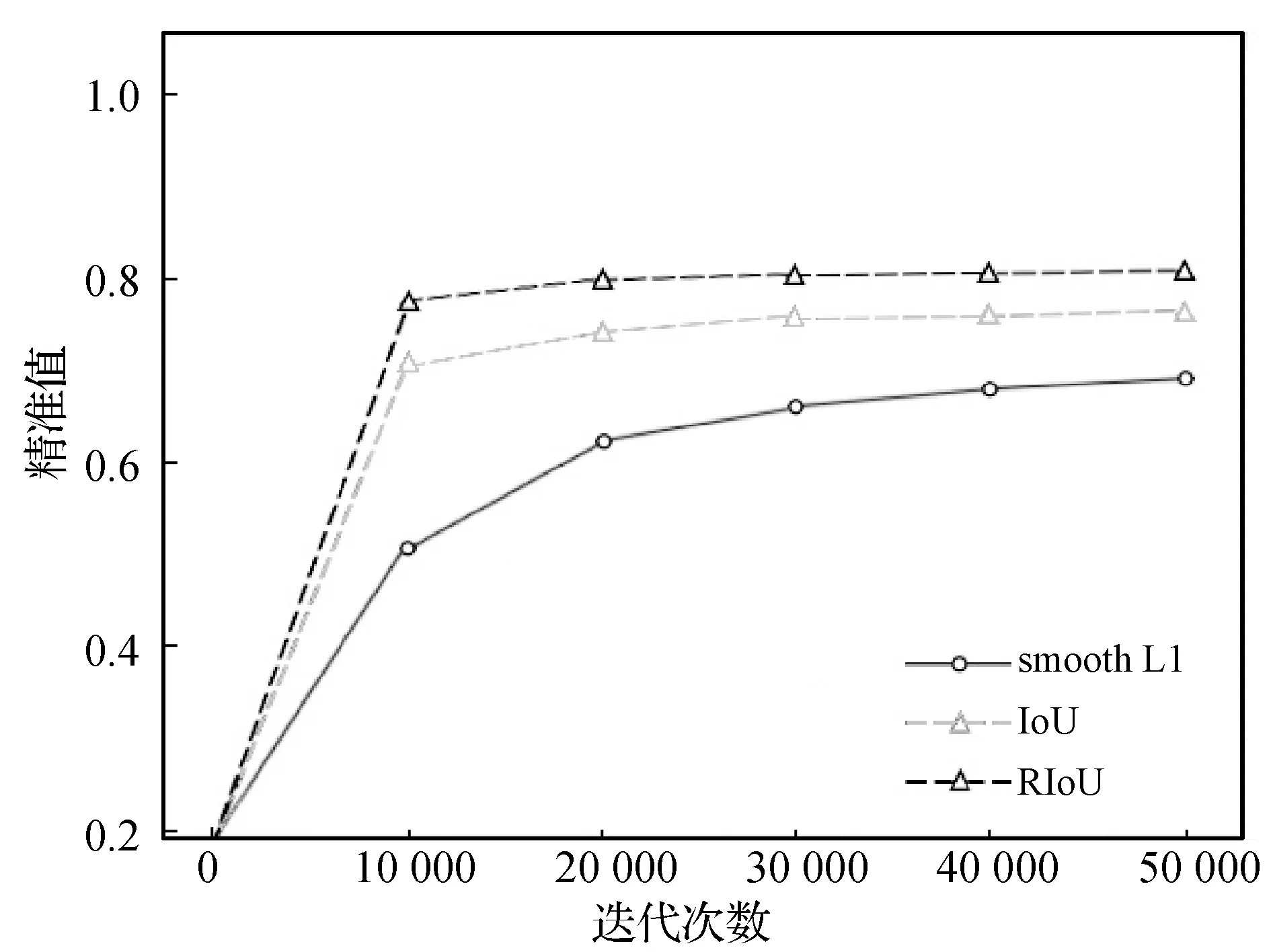
图5 不同迭代次数下精准值
对于损失函数,仅仅使用检测结果来分析预测框回归的过程是不够的。大量随机的文本区域、位置、比例和角度都是不受控制的因素。在实验中我们记录了三种损失函数训练时的多组数值,综合考虑收敛情况。图6为三种损失函数在前200步迭代中的损失函数值的走势。
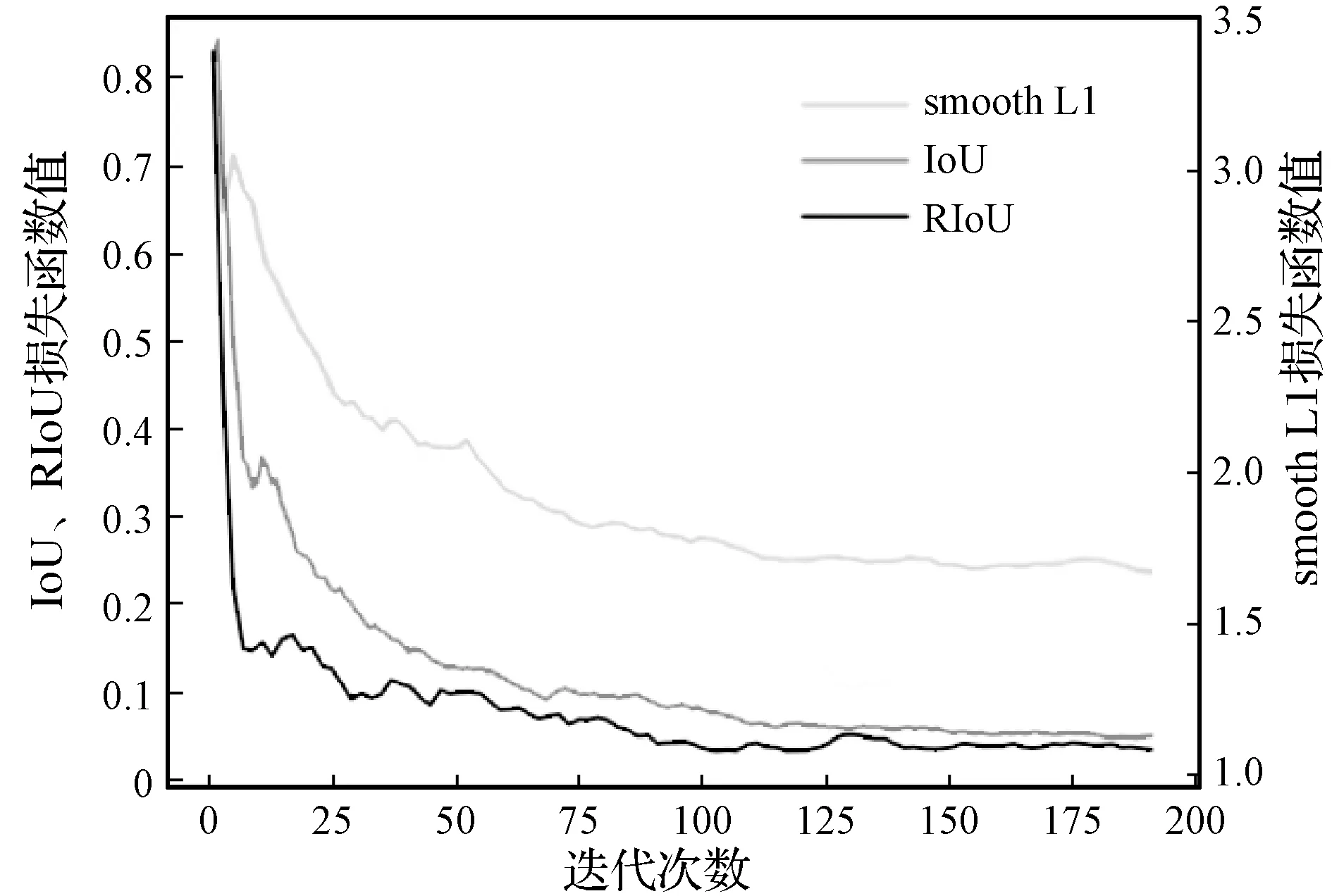
图6 RIoU、IoU和smooth L1损失函数收敛速度对比
图6中横轴代表迭代次数,纵轴为损失函数的值。因为smooth L1值的范围是大于1的,而IoU损失函数和RIoU损失函数值的范围分别是[0,1]和[0,2],所以图6中有两个尺度的纵轴。虽然范围不同,但可以观察出smooth L1损失函数初始的损失值很大,之后随着训练的进行损失值开始缓慢下降,到了200步附近损失值的下降已经非常缓慢,而且此时的值距离最优值还有很大的差距。相比较IoU损失函数和RIoU损失函数,尤其是RIoU损失函数的下降曲线尤为明显,在初始的十步训练中,损失函数很快地下降到与最优值较为接近的数值,之后的迭代中再继续优化,慢慢逼近最优值。虽然IoU损失函数的下降曲线也明显领先于smooth L1损失函数,但是在面临随机方向的文本框时,还是RIoU损失函数表现更好。
4 结 语
本文设计一种旋转交并比损失函数用于边界框回归。将评价指标交并比引入损失函数,使边界框参数之间具有相关性,旋转交并比损失函数可以比原始的smooth L1损失函数更快更好地收敛。并且在边界框参数中加入角度信息,边界框回归的角度偏差归一化后作为惩罚项来反向传播,网络可以更好地检测随机方向性的文本目标,在检测准确率上取得了11百分点的提升。所提出的旋转交并比损失函数可以很容易地整合到各类目标检测算法中。在下一步的研究工作中,损失函数的惩罚项还有更多设计的可能性,针对不同网络模型,寻找到更加合适的损失函数解决方案,这些过程都还需要更加细致的研究。
猜你喜欢
作文小学高年级(2022年3期)2022-04-20
儿童时代·幸福宝宝(2021年11期)2021-12-21
数学小灵通·3-4年级(2021年5期)2021-07-16
现代装饰(2020年4期)2020-05-20
今日农业(2019年15期)2019-01-03
福建中学数学(2018年1期)2018-11-29
证券法律评论(2018年0期)2018-08-31
37°女人(2017年8期)2017-08-12
滇池(2017年7期)2017-07-18
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
