
基于多源遥感的大尺度高分辨率不透水面深度学习提取方法
2023-03-15 10:04:20孙根云张爱竹
测绘学报 2023年2期
孙根云,王 鑫,安 娜,张爱竹
1.中国石油大学(华东)海洋与空间信息学院,山东 青岛 266580;2.海洋国家实验室海洋矿产资源评价与探测技术功能实验室,山东 青岛 266071; 3.中国自然资源航空物探遥感中心,北京 100083
近50年来,全球城市化水平持续提升,预计到2050年全球约有68%的人生活在城市中[1],城市的快速扩张导致不透水面急剧增加。不透水面被定义为阻止水渗入地下的坚硬区域,如沥青道路、停车场、建筑屋顶等人工建筑[2]。不透水面的扩张侵占了大量森林、农田、草地和水体,导致生物栖息地遭到破坏、城市热岛效应增强、非点源污染加剧等现象,影响了城市地区的生态平衡和水文循环[3-4]。因此,及时、准确地获取不透水面信息对城市规划、管理及城市可持续发展等具有重要意义。
随着以Google Earth Engine(GEE)[5]为代表的遥感云计算技术的发展,使得数据的获取与处理更加容易[6]。研究者基于GEE和Landsat数据,研制了一系列30 m土地覆盖或不透水面分类产品,如GlobeLand30[7]、GHSL-2014[8]、MSMT-2015[9]、FromGLC-30[10]等产品。这些产品在生态环境、气候变化等研究及应用中发挥了重要作用。但是受数据分辨率限制,难以提供更加精细的不透水面信息,限制了它们的进一步应用[11]。另外,在热带亚热带区域,比如东南亚地区,常年多云多雨,导致可利用的光学影像稀少且影像质量较差,使得这些产品的精度难以得到保证。
目前,不透水面提取方法大致可以分为3类:混合像元分解法[12]、指数法[13]和图像分类法[14]。混合像元分解法通过分解出每个像元中各种地物端元所占比例,可以有效解决混合像元对不透水面信息提取的影响[15]。指数法利用不透水面的光谱特性,通过光谱波段之间的代数运算来增强不透水面与其他地物的差异,以实现不透水面的提取[16]。图像分类法将不透水面看成一类地物,利用不透水面的光谱和空间特征对其进行分类[17]。近年来,由于卷积神经网络(convolutional neural network,CNN)能够自动提取图像的高层语义特征,在计算机视觉领域得到了大量研究[18],提出了一系列经典的CNN模型,如VGG[19]、Resnet[20]等模型。CNN模型的优越性能得到了遥感界的广泛关注[21]并逐渐应用到土地覆盖分类和不透水面提取中,取得了显著效果[22-23]。例如,文献[24]首先利用CNN提取高层特征,然后结合面向对象分割与模糊聚类实现了高分辨率不透水面的自动提取。文献[25]结合CNN与多层感知机,通过挖掘地物的空间和光谱信息,有效改善了地物边界处的分类效果。在大尺度制图方面,CNN也表现出了优势。比如,文献[26]提出了一种迭代样本选择方法,利用少量已标注数据预训练CNN模型,然后在大量未标注数据中迭代选择样本,对CNN模型进行迁移,提高了大尺度土地覆盖分类精度。文献[27]利用改进的HRNet语义分割模型并以From-GLC10[28]土地覆盖产品为标签,进行全国3 m土地覆盖分类,取得了较高的精度。文献[29]构建了一个6层的CNN模型,并从多个不透水面产品中自动获取大量训练样本,实现了全球10 m分辨率建成区提取。上述算法虽然在大尺度制图上取得了较高的精度,但是依然面临以下问题:①输入数据源较为单一,无法有效利用多源数据提供的互补信息,限制了大范围复杂区域制图的精度。②CNN模型的性能依赖足够的训练样本,然而大量高质量的样本获取非常困难;另外,样本噪声会影响模型性能[30]。③CNN模型参数量大,模型的训练和预测消耗了大量的计算资源,计算效率较低。
因此,针对热带亚热带光学影像数量少、质量差,以及样本获取难、CNN模型运行效率低的问题,本文构建了一种融合多源多时相数据的超轻量CNN模型,该模型能够充分利用地物的光谱、空间和微波散射等特征,实现大尺度高分辨率不透水面的精确提取。同时,为了解决训练样本难以获取的问题,本文利用OpenStreetMap(OSM)众源数据和开源不透水面产品,提出了一种自动样本获取方法。该方法首先利用OSM数据自动获取样本,然后基于样本可靠性加权的思想,利用开源不透水面产品对获取的OSM样本进行加权,降低标签噪声对网络训练的影响,提高模型的抗噪性能。最后将训练好的模型用于越南全境的不透水面提取,得到2019年越南10 m分辨率的不透水面专题图(VNMIS-2019),并对结果进行了精度评定。
1 研究区与数据源
1.1 研究区概况
越南位于中南半岛东部,介于8°10′N~23°24′N,102°09′E~109°30′E之间,国土面积约33万km2。越南地势由西北向东南倾斜。越南纬度跨度大,山区较多,常年多云多雨,年平均降水量达1800~2000 mm。越南复杂的地形和气候条件,为大尺度不透水面提取研究提供了丰富的场景,能够充分检验所提方法的有效性和可靠性。
1.2 数据源及预处理
研究所用数据包括Sentinel-1/2影像数据,美国航天飞机雷达地形测绘任务(shuttle radar topography mission,SRTM)所生产的DEM数据(表1)和4个开源不透水面(土地覆盖)产品(表2),训练样本来自OSM众源数据。

表1 用于不透水面制图的输入数据

表2 开源不透水面产品信息
光学影像利用GEE提供的Sentinel-2 L1C级多光谱影像(multi-spectral imagery,MSI)。影像获取时间为2019年1月至2019年12月,剔除了云量大于70%的影像,共获得5020景。本文选取了4个10 m空间分辨率的可见光近红外波段影像(Band 2/3/4/8)和2个20 m分辨率的短波红外波段影像(Band 11/12),将短波红外影像重采样到10 m。利用质量评估波段(QA)对影像中的云进行掩膜。最后将所有影像进行中值合成,既减小了数据冗余,又减弱了残留的云污染。获得合成影像后,对合成影像计算归一化植被指数[31](normalized differential vegetation index,NDVI),并设置一个相对宽松的阈值0.35,对植被区域进行掩膜,减少不透水面的预测时间。
合成孔径雷达(synthetic aperture radar,SAR)影像利用GEE提供的Sentinel-1A/B卫星干涉宽幅模式的地距多视产品,空间分辨率为10 m。本文共收集了2019年1月至2019年12月覆盖越南全境的Sentinel-1A/B影像1735景。每张影像包含VV、VH两种极化方式。SAR影像几乎不受天气影响,大大提高了多云多雨地区影像的可利用性[32]。为了获得地物的时相特征,利用均值合成,将获得的SAR影像每6个月(1~6月、7~12月)合成为一张。SAR影像在均值合成后,减弱了光斑噪声、地形叠掩等不利影响。
为了确定训练样本的可靠性,本文利用了4个与制图时间接近的全球不透水面产品作为辅助数据(表2),包括全球人类居住地图(GHSL)、全球高空间分辨率人造不透水面逐年动态数据产品[33](GAIA)、全球精细分辨率土地覆盖观测和监测产品(FROM-GLC10)和多源多时相不透水面产品(MSMT-2015)。
2 研究方法
本文方法主要包含4个部分(图1):①影像与矢量数据收集和预处理;②训练样本自动获取与生成;③模型训练与不透水面制图;④制图结果精度评定。
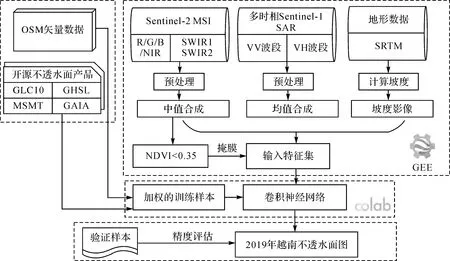
图1 试验流程
2.1 训练样本自动获取与生成
为了获取足够的训练样本,首先从“Geofabrik”网站(https:∥download.geofabrik.de/asia/vietnam.html,发布于2019年1月1日)下载越南全境的OSM数据集。该数据集包括3类数据:①面状数据,包括建筑物、水体和土地利用数据;②线状数据,包括道路、水路和轨道数据;③点状数据,包括兴趣点、自然点和交通站点。
在获取不透水面样本时,首先选择其中的建筑物、道路和铁路、交通站点数据;然后,对建筑物数据,去除面积小于100 m2的建筑物斑块,并计算每个建筑物的中心点;对道路和铁路数据,将自行车道、生活街道、人行道和地铁等宽度较窄的道路移除,同时移除长度小于500 m的道路,计算剩余道路线中每条线段的中点;最后将建筑物中心点、道路中点和交通站点合并,作为原始的不透水面样本点。
在获取非不透水面样本时,使用了其中的水体、土地利用和自然点数据集。对土地利用数据集去除其中的住宅区、商业区、工业区,以及面积小于300 m2小斑块。防止建筑物和区域边界对样本的干扰。然后,在剩余的土地利用和水体区域中随机撒点,并限制随机点之间的距离大于30 m(3个像元)。最后将随机点和自然点合并得到原始的非不透水面样本点。最终获得不透水面点82 030个,非不透水面点82 125个,所有样本点的分布如图2所示。

图2 OSM训练样本点分布
从OSM数据中获得的样本标签,大部分是正确的,但是由于定位与配准误差,样本中存在部分标签噪声,如图2(c)黄色椭圆中所示,少量不透水面点落在了植被区域。为了减弱标签噪声对模型训练的影响,本文利用上述开源不透水面产品对每一个样本进行加权,对可靠性高的样本赋予高权重,对于可靠性低的样本赋予低权重,具体的计算公式如式(1)和式(2)所示
(1)
(2)
式中,yi表示从OSM数据中获得的样本标签;βi表示不透水面或非不透水面出现的频率;λi表示第i个样本的权;Ij表示第j个开源产品的土地覆盖类型,不透水面为1,非不透水面为0;m表示开源不透水面产品的数量,本文中为4。
2.2 模型构建
为了利用多源数据的互补特性,本节构建了一个超轻量级CNN模型。该模型用3个平行分支融合光学、SAR和坡度数据,如图3所示。具体说明如下:①MSI分支接受7×7×6的多光谱图像块输入,包含4个卷积层和一个池化层,用来提取地物的空间和光谱信息;②SAR分支将双时相SAR图像块作为输入,每一时相的图像块大小为7×7×2,首先经过两个三维卷积层提取时相和空间信息,再经过池化层和卷积层进一步提取高层语义信息;③Slope分支的输入是由DEM计算出的坡度图,大小为7×7×1,将地形信息融入模型,减弱山地对不透水面提取的影响。最后,将3个分支提取的抽象特征合并,送入由128个神经元构成的全连接层对中心像元进行分类。输出神经元经过Sigmoid函数将模型的输出值映射到0~1范围内,大于0.5的被判定为不透水面。为了进行逐像素分类,采用基于图像块和滑动窗口的方法,滑动步长设置为1。

注:3×3×16@1代表卷积核大小为3×3,卷积核数量为16,卷积步长为1,其他标记类似;Conv代表二维卷积运算,3D Conv代表三维卷积运算,BN代表批标准化,Relu代表修正线性单元激活函数,MaxPooling代表最大池化运算,Concat代表特征组合,Dense代表全连接层的神经元。
2.3 模型优化
一个合理的损失函数是模型获得良好性能的关键因素。本文基于样本加权的思想,在原交叉熵函数上进行改进,对样本的损失值赋予权重,减弱噪声样本对模型的影响。
对于二分类问题,标签取值为0或者1,假设每个批次训练n个图像块,每个图像块的交叉熵损失函数可以表示为式(3)
(3)
式中,yi表示第i个图像块标签值,取值为0或1;pi表示第i个图像块的预测值。
每个图像块都有一个从OSM样本中获得的一个标签yi,以及从开源产品中获得的一个权λi,修改后的损失函数可以表示为式(4)

ln(1-pi)]
(4)
最后,采用自适应矩估计算法(adaptive moment estimation,Adam)进行网络参数优化。网络的初始学习率为0.000 1,之后根据训练轮数epoch自动调整学习率,Batch size设置为64。本文的试验环境为Ubuntu 18.4操作系统,显卡为NVIDIA 1050ti,显存为4 GB,采用Keras神经网络框架实现。在进行图像预测时,将影像数据从GEE中导出到Google Drive中,并将训练好的模型上传至Google Drive,最终在Google Drive提供的Colab云计算平台中获得越南全境的不透水面产品(简称“VNMIS-2019”)。
2.4 精度评价方法
为了定量验证结果精度,本文采用分层随机抽样策略,借助Google Earth历史影像和Sentinel-2影像对样本点进行目视解译。共计获得验证样本点1583个,用于模型训练时的精度评估与超参数调整;获得测试样本点2120个,用于对制图结果的精度评估。采用了常用的精度评估指标,总体精度(overall accuracy,OA),用户精度(user 's accuracy,UA),生产者精度(producer 's accuracy,PA)和Kappa系数验证结果精度与模型识别的一致性[34]。
3 试验结果与分析
3.1 精度评估与对比
将训练好的模型用于越南不透水面提取,结果如图4所示。图4展示了越南不透水面的整体分布,以及6个典型区域的不透水面分布细节。可以看到,越南大部分不透水面分布在东南部的红河三角洲地区、东部沿海地区以及以胡志明市为中心的东南部湄公河三角洲地区。北部和西部山区受地形和环境的影响,不透水面分布极少。

图4 越南2019年不透水面制图结果
基于测试样本,定量评估了越南不透水面的提取精度,并与其他3个不透水面产品进行对比,结果见表3。总体来看,VNMIS-2019获得了最高的总体精度(91.01%)和Kappa系数(0.820),其次是MSMT-2015。相比之下,GAIA-2018的总体精度只有81.33%,Kappa系数为0.621。从用户精度看,GAIA-2018的精度高于其他产品,达到了94.64%,最低为From-GLC10,只有86.72%。这可能与From-GLC10在生产时只使用Sentinel-2多光谱影像有关。从生产者精度看,VNMIS-2019的生产者精度达到了最高89.97%,最低的为GAIA-2018,只有75.77%,主要原因可能是GAIA-2018产品分辨率较低,造成小斑块不透水面的遗漏。

表3 不同不透水面产品的精度对比
为了定性对比不透水面产品之间的差异,本文选取From-GLC10和MSMT-2015,在4种典型场景(城市、郊区、山区、农村地区)下进行对比,如图5所示。总体而言,VNMIS-2019与From-GLC10和MSMT-2015不透水面的整体分布基本相同,但是在细节处存在差异:MSMT-2015由于分辨率较低,受混合像元的影响,导致零散细小的不透水面遗漏和空间细节缺失,如图5(d)黄色椭圆区域中郊区与农村地区的道路被遗漏,而在城区及山区(图5(d)蓝色椭圆区域)存在不透水面高估现象;相比而言,两个10 m分辨率产品VNMIS-2019和From-GLC10具备更多的细节。但是,From-GLC10容易将裸地和农田错分为不透水面,造成不透水面高估,如图5(c)蓝色椭圆区域。相比之下,VNMIS-2019获得了最好的目视效果,与定量对比的试验结论是一致的。

图5 不同不透水面产品定性对比
3.2 样本加权对精度的影响
由图6(a)可以看出,在模型训练过程中,原始OSM样本训练的模型验证精度在84%左右,而召回率却达到了95%,说明对不透水面存在严重的高估现象。相反,加权样本模型的验证精度大于92%,同时召回率与验证精度相差小于2%(图6(b))。说明利用开源不透水面产品对OSM样本进行加权,能够明显减弱样本噪声对模型训练的影响。另外,本文研究的制图时间为2019年,与使用的开源产品最大时间间隔仅为5 a。根据文献[33]的研究,近年来东南亚地区不透水面扩张相对缓慢,因此,认为不会对权重造成明显影响。

图6 使用加权样本与原始样本的精度对比
为进一步证明样本加权的有效性,本文选取了越南4个具有代表性的场景进行可视化对比,如图7所示。由图7可以看出,使用原始OSM样本提取的不透水面结果,在不同的场景下均存在不同程度的高估(图7蓝色椭圆区域)。例如,在建筑密集区(图7(a)),使用原始样本提取的结果将许多房屋之间的植被分为了不透水面,而在郊区和沿海地区(图7(b)、(c))将高反射率的裸地和农田分为不透水面。相反,使用加权样本的模型不仅提取出了大块不透水面区域,同时提取出了不透水面的精细结构以及细小的道路(图7绿色椭圆区域)。值得注意的是,在图7(d)中,虽然影像中存在薄云覆盖,但是使用加权样本训练的模型,仍然精确地分类出了云覆盖像元。这主要是因为,在深度学习模型中融合了多时相SAR数据,减弱了云对不透水面提取的影响。

图7 加权样本与原始样本的不透水面提取效果对比
3.3 模型结构与计算效率分析
因为模型结构和规模对提取精度和预测效率都会产生影响,所以本节分4种情况,一共对比分析了8种模型的提取精度及其预测1.0×106个像素点所用时间,①模型的分支组合,MSI单分支模型、MSI-SAR双分支模型(简写为MSI-S)、MSI-SAR-Slope三分支模型(简写为MSI-SS);②增加模型分支间的连接,将3个分支间的深度特征相互组合连接,形成分支间的信息交互(命名为MSI-SS-X,如图8(a)所示);③扩展模型的宽度,将MSI-SS模型每层卷积核数量增加为原来的2倍和4倍(分别简写为MSI-SS2和MSI-SS4);④增加模型的深度,在MSI-SS模型的每个分支添加两个卷积层(命名为MSI-SS-D2,如图8(b)所示)及在每个卷积层后面再增加一个卷积层(简写为MSI-SS-D4,如图8(c)所示)。

图8 不同结构的CNN模型
试验结果见表4,可以看到,MSI-SS模型的OA比MSI单分支模型高2.4%,Kappa系数高4.8%。这主要是因为MSI-SS模型能够融合地物的光谱、空间、后向散射及地形特征,从而提高了精度。增加模型分支间交互会轻微提升模型精度,但模型计算复杂度和参数量明显上升,计算效率下降了5.2%。卷积核数量的增加并没有明显提高精度,且导致预测效率明显降低。MSI-SS2和MSI-SS4模型的预测效率比MSI-SS模型分别降低了16.9%和59.0%。另外,MSI-SS-D2和MSI-SS-D4模型虽然轻微地提升了精度(<1%),但是,预测效率比MSI-SS模型分别降低了10.4%和23.7%。由于制图范围较大,在综合考虑了精度、预测效率和参数量后,本文最终采用MSI-SS模型。

表4 不同模型结构的精度与计算效率
3.4 样本数量对精度的影响
由于训练样本来自于OSM众源数据,各个地区的可用样本数量相差较大。为了验证该方法在其他地区的适用性,进一步研究了样本数量与精度之间的关系。试验结果如图9所示,随着样本数量的增加,使用加权或原始样本的分类精度都有所提升,但是,加权样本的分类精度一直高于原始样本。当样本量超过总量的30%时,加权样本的分类精度超过92%,原始样本的分类精度只有84%左右,继续增加样本量精度几乎不再发生变化。这表明,即使在OSM样本比较少的地区依然可以使用该方法。

图9 精度与训练样本量的关系
4 结 论
本文结合多源遥感影像和OSM众源数据,提出了一个自动的大尺度高分辨率不透水面提取方法。该方法利用开源不透水面产品对获得的原始OSM样本进行加权,对可靠性高的样本赋予高的权重,对低可靠性样本赋予低权重。通过样本加权,有效抑制了标签噪声对模型训练的影响,提高了模型的泛化能力。在此基础上,为了解决热带亚热带地区云雨覆盖对不透水面提取的影响,提出了一个三分支的超轻量CNN模型,融合了光学、SAR和地形数据,实现了大尺度10 m分辨率不透水面的精确提取。通过对越南全境的不透水面制图试验,并与其他开源不透水面产品进行对比,检验了算法的有效性。试验发现获得的不透水面专题图总体精度达到了91.01%,Kappa系数达到0.82,高于目前已公开的不透水面产品。未来将考虑利用全卷积神经网络实现不透水面自动提取,进一步提高分类效率;并研究更优的加权策略,获取更高质量的训练样本。
猜你喜欢
农业工程学报(2022年4期)2022-04-24 03:44:10
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
科技创新与应用(2020年6期)2020-02-29 10:39:27
自然资源遥感(2019年3期)2019-09-12 01:56:44
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
电视技术(2014年19期)2014-03-11 15:38:20
