
融合网络和文本特征的智能课程推荐方法
2023-03-15 08:46卢春华胡晓楠彭璐康李翠霞
计算机应用与软件 2023年2期
卢春华 胡晓楠 彭璐康 李翠霞
1(安顺学院数理学院 贵州 安顺 561000) 2(朴茨茅斯大学会计与金融管理系 朴茨茅斯 PO1 2UP) 3(北京邮电大学网络技术研究院 北京 100876)
0 引 言
近年,随着科技的发展和“互联网+”概念的迅速普及,基于互联网的在线学习应运而生,学习方式发生了翻天覆地的变化。在线学习由于其在资源利用、学习方法和教学形式等方面的优点,逐渐成为了一种新的趋势。然而,随着时间的推移以及用户的不断增加,在线学习系统上的数据变得愈加庞大,资源过载问题日益凸显,给学生在课程选择方面带来了极大的困难。个性化推荐方法可以通过分析学生的历史行为数据等对其进行个性化建模,自动生成潜在兴趣课程并进行智能推荐,有效缓解课程资源过载问题,为用户个性化、精准化地提供学习资源建议,提升学习效率和用户满意度。
传统的个性化推荐算法主要分为三种:基于内容的推荐方法、协同过滤推荐方法和混合型推荐方法[1]。这些推荐算法在某些特定的应用场景下能取得良好的推荐效果,但在某些方面还存在一些缺陷[2]。目前,深度学习在图像识别、文本处理和语音识别等领域都取得了前所未有的突破,其方法也被不断地应用到课程推荐领域。Shen等[3]结合卷积神经网络和隐含因子模型,利用卷积神经网络从课程资源的文本描述中获取隐式特征,提升了模型的推荐效果。朱柳青[4]基于神经网络设计了一种课程推荐模型,该模型使用卷积神经网络处理用户和课程的数据并建模,得到它们的隐式特征,提高了课程推荐的准确性。Khribi等[5]根据学生浏览记录对用户进行个性化建模,并结合学习资源等内容完成课程推荐。林木辉[6]通过构建学习资源本体,提出一种基于学习者认知水平的个性化课程推荐模型,其中认知水平是通过对知识点进行难度标注产生的。Aher等[7]使用半监督机器学习从用户历史数据中挖掘用户的主要兴趣,较为合理地为学习者进行课程推荐。Batouche等[8]提出一种基于改进的人工神经网络的教学资源推荐模型,获得了较为合理的推荐结果。文孟飞等[9]通过结合支持向量机与深度学习,将网络教学视频实时推送给学习者,提升了教学资源的利用率;Zhou等[10]提出了基于长短期记忆网络(Long Short-Term Memory,LSTM)的在线学习路径推荐策略。总体来说,以上模型在特征选择的时候都使用同种类型的结构化数据,而现实世界中的数据大多都是异构的、非结构化的,这大大制约了推荐模型的建模能力。基于这个角度出发,本文提出了一种基于网络拓扑和文本特征的智能课程推荐方法,旨在通过融合在线教育过程中产生的大量异构数据对在线课程进行全面的建模,进而匹配用户特征并进行智能化的推荐。具体步骤为:首先为了充分利用网络结构信息,分别以课程-学生、课程-教师和课程为主体构建网络拓扑,利用node2vec随机游走的方法生成节点序列;然后使用句向量将它们和相关课程的描述文本信息嵌入到更低维的表示向量中;其次通过多模块的卷积神经网络(Convolutional Neural Network,CNN)分别得到它们的向量表示,通过向量首尾拼接的方法来建模用户的偏好;最后,通过计算用户查看课程信息与目标课程的相似度大小得出推荐课程序列。
1 相关理论
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是一个重要的深度学习模型。目前,卷积神经网络在自然语言处理中的应用已经取得了较好的结果[11-12],框架如图1所示,其主要包含三层结构:卷积层、池化层和全连接层。

图1 卷积神经网络结构图
卷积层:用来提取某个区域的特征,卷积层计算式如下:
xj=σ(Wj⊗X+bj)
(1)
式中:xj表示在j层(卷积层)的特征图;Wj是第j层的卷积核;X表示第j层输入;⊗表示卷积操作;bj是第j层的偏置项;σ表示激活函数。
池化层用来对不同位置的特征图进行压缩,可以减少特征图的大小,简化网络计算复杂度。池化层运算公式如下:
xj=σ(δjS(xj-1)+bj)
(2)
式中:S(∘)表示降采样函数;δ为乘子偏差;b为附加偏差;σ表示激活函数。一般情况下,池化层后接入全连接层,主要实现从特征到分类类别输出的转换。
1.2 Doc2vec
词的向量化是将自然语言中的词语映射到低维连续空间,生成一个实数向量[13],Word2vec[14-15]是一种使用广泛的无监督式词向量化模型,它从海量文本语料中学习富含语义信息的低维词向量,使得语义相似的单词在向量空间中距离相近[16],Word2vec包括两种训练模型,分别是连续词袋模型CBOW和Skip-gram[17]模型。类似Word2vec、Doc2vec用来进行语句或段落的向量化表示,网络结构如图2所示,Doc2vec将句子和词的向量通过求平均或者首尾相连作为输入来预测文本中的下一个单词,对于给定的段落di和其词语序列w1,w2,…,wt,该方法的目标是使平均对数概率最大化,计算式如下:
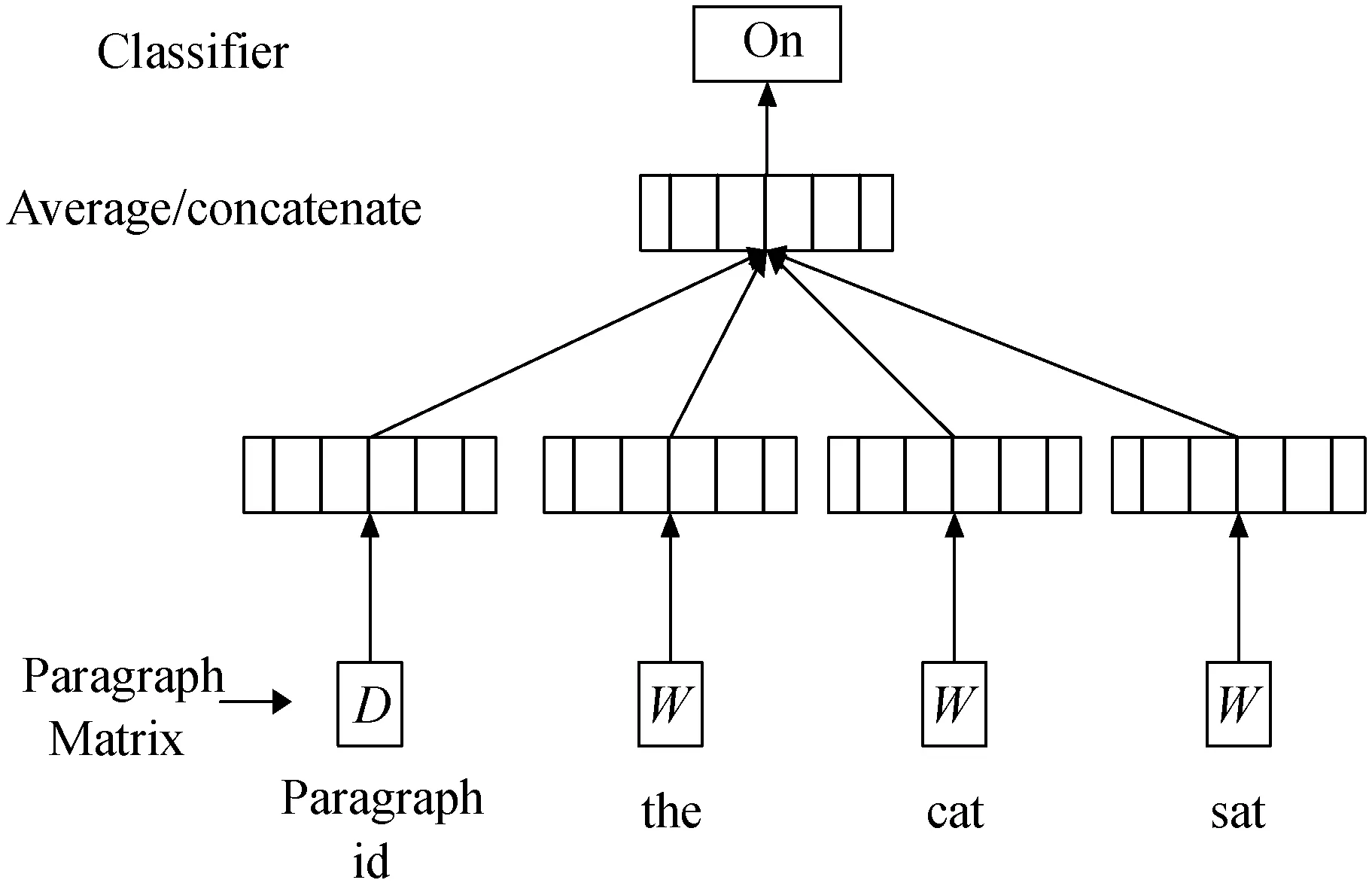
图2 Doc2vec
(3)
(4)
y=b+Uh(wt-k,…,wt+k,di;W,D)
(5)
式中:U和b是模型参数。h由W中提取的词向量与D中提取的段落向量联结或平均构成。
1.3 Node2vec
受到Skip-gram的启发,Vasile等[18]使用元数据嵌入,将项目元数据映射到潜在空间后通过计算元数据之间的相似性来得出推荐序列。后来,Perozzi等[19]发现自然语言处理中单词的出现频率和无标度网络中节点的出现频率均服从幂律分布[2],并基于此提出了Deepwalk,该方法将随机游走产生的节点序列作为文本的句子并将节点作为单词,使用Word2vec学习节点序列的低维表示。Grover等[20]在Deepwalk的基础上提出了Node2vec方法,该方法结合广度优先搜索算法(BFS)和深度优先搜索算法(DFS)这两种策略,通过调节随机游走的走向来挖掘网络拓扑。研究结果表明邻居节点具有相似性,而充当相同角色的节点具有结构一致性。在网络的表示中,节点间的这种性质是十分重要的。在生成序列时两个节点间的转移概率是通过如下公式产生的。
πvx=αpq(t,x)·ωvx
(6)
式中:ωvx表示节点v和节点x之间边的权重值,α为转移概率,如图3所示,计算公式为:
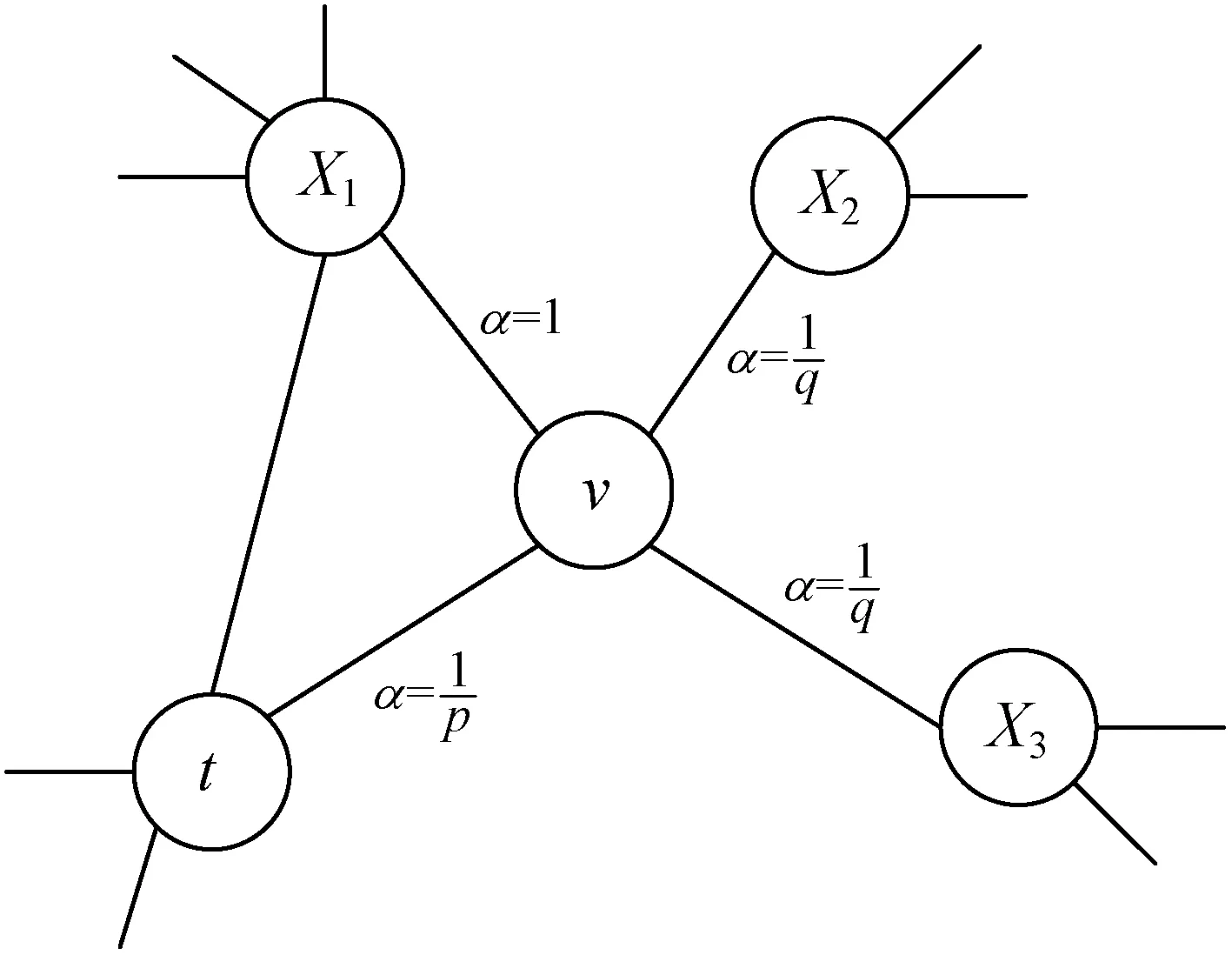
图3 Node2vec的游走策略
(7)
式中:v表示当前的节点,t是v的上一步所在节点,而x代表下一步的位置;dtx表示t和x之间的最短距离。
2 基于课程网络和文本特征的CNN推荐模型
2.1 随机游走构造节点序列
在线课程网站上具有丰富的元数据信息(包括课程、老师和学生等实体以及属性信息),这些实体构成一个巨大的图结构,充分挖掘其中蕴涵的特征对于个性化推荐系统的性能提升具有重大意义。如图4所示,学生a和学生b同时学习了课程A,同时学生b也学习了课程B,而课程A和课程B属于同一个二级学科,这时课程B和学生a之间存在较强的相关性,可以给学生a推荐课程B。为了缓解数据稀疏性,本文分别以课程-学生、课程-老师和课程所属二级学科科目为依据构建课程图结构,从相关元数据的信息中得到课程的向量表示。
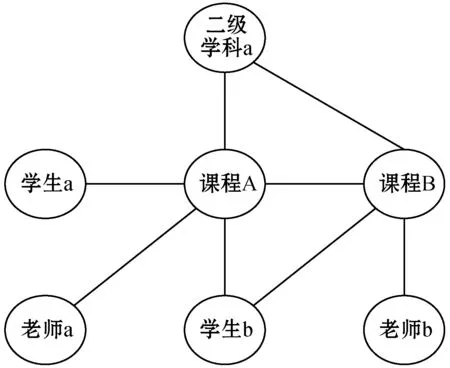
图4 课程图结构示意图
在课程-学生元数据图结构AS={VS,ES,WS},VS表示课程节点集合,ES表示节点之间的边集合,WS是边的权重。它结合了学生社交关系(关注与被关注)、个人信息等,如具有社交关系的学生学习的课程之间、共同学生占课程总人数超过比重P的两个课程之间构成边。
在课程-老师元数据图结构AT={VT,ET,WT}中,VT表示老师节点集合,ET表示节点之间的边集合,WT是边的权重。它结合了老师之间的社交关系、个人信息等,如具有社交关系的老师所教授课程之间、具有相同研究方向的老师教授课程之间、同一个老师所教授课程之间构成边。
在课程-课程元数据图结构AC={VC,EC,WC}中,VC表示课程节点集合,EC表示节点之间的边集合,WC是边的权重。课程元数据图结构主要根据二级学科进行统计的,例如计算机系统结构、计算机软件与理论、计算机应用技术属于同一个学科大类,属于它们的课程之间构成边。
关于边的权重值,以课程-课程元数据图结构为例,若其与其他课程共含有n种边的关系类型,课程i和课程j之间有边,若课程i和课程j之间共有m种关系,则课程j和课程j在图结构中边的权重值w(i,j)∈WS为:
(8)
在课程推荐系统中,热门课程通常会得到很多学生的青睐,所以在随机游走过程中考虑到边的权重可以使节点往较为热门的方向游走。在课程-学生元数据图结构AS={VS,ES,WS}中,随机选定节点S1,从S1出发选定长度为L的游走节点学列,如图5所示,节点从Sk-2游走到Sk-1,则下一步的游走概率为:
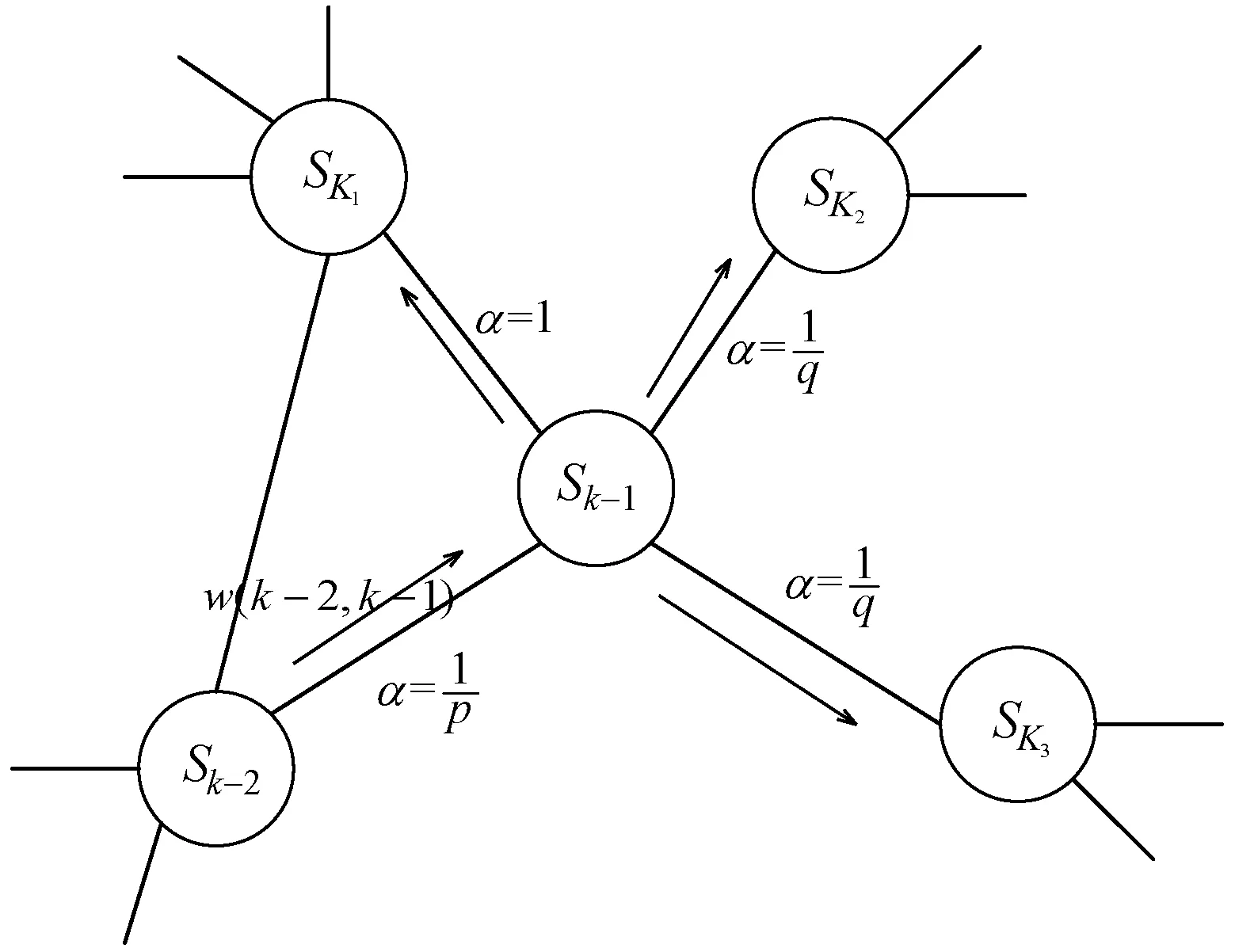
图5 游走过程示意图
(9)
式中:α为二阶随机游走参数,v为与Sk-1节点有边的节点。
2.2 模型介绍
针对课程推荐中特征单一、结果不精准的问题,本文提出了基于边随机游走的多模块神经网络表示学习方法。该方法包括生成节点序列、使用向量嵌入学习生成图结构中节点以及课程描述文本的低维表示、训练基于异构特征的多模块CNN模型三个阶段。首先分别将课程-学生、课程-教师和课程-课程为主体构建网络拓扑;其次利用Node2vec随机游走的方法各自生成节点序列并嵌入表示,使用Doc2vec将相关课程的描述文本信息嵌入到低维的表示向量中;最后通过多模块的CNN进行网络和文本特征的转换,并使用向量首尾拼接的方法得到的向量来用户的偏好表示X,计算X与前馈层处理的目标课程Y(包含网络和文本特征)的相似度大小得出课程推荐序列。模型架构图如图6所示,课程相似度大小计算式为:

图6 模型架构图
XTY=S
(10)
式中:X表示用户的偏好向量;Y表示目标课程向量;S表示与目标课程(候选课程)相似度大小,S值越大,目标课程在推荐序列中的排名越靠前。
3 实验和结果分析
3.1 实验数据集
本文数据集来自于“爱课程”网。通过网络爬虫技术采集“爱课程_中国大学MOOC(慕课)”上的课程,涉及的课程类别包括计算机、化学、外语、经济学、管理学、医药卫生、电子和教育教学这八个门类。采集的课程信息主要包括中文文本格式的课程名称、课程详情、课程页面链接、教师详情和学生详情等内容,实验总共收集350余门在线开放课程的相关元数据,共计170余万字。具体详情如表1所示。
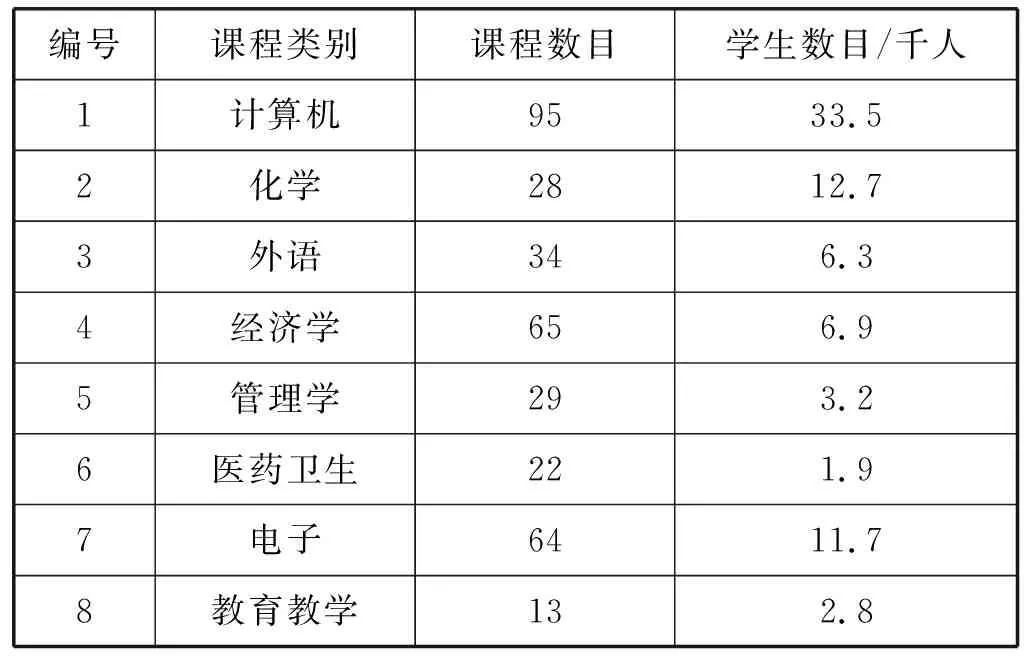
表1 数据集
3.2 基准模型
本文设置的基准模型如下:
(1) 基于用户的最近邻推荐方法(User-KNN):将评分数据集和当前学生ID作为输入,找出与当前学生的听课记录有相似偏好的其他学生,对当前学生未学习的每个课程A,利用学生的近邻对课程A的评分进行预测;最后,选择评分最高的TopN个课程推荐给当前学生。
(2) 基于物品的最近邻推荐方法(Item-KNN):通过计算课程的相似度代替用户的相似度进行推荐,但是并不以课程的内容属性计算相似度,而是主要通过分析学生的行为记录。一般而言,课程A和B具有很大相似度是因为喜欢物品A的用户大都喜欢B。
(3) 非负矩阵分解(NMF)[21]:将用户—课程矩阵分解为用户和课程矩阵相乘的形式,矩阵中每行代表一个个体,最终匹配得分通过这些向量表示。
(4) FGMSI[22]:基于社会影响力因素的图形推荐模型。该模型首先构建一个异构的社交网络,然后计算基于元路径的相似性。最后,从网络中提取一些特定功能,并将其用于推荐。
3.3 评价指标
在本文实验中,选取准确率(Precision)和折扣累计利润及其归一化(Normalized Discounted Cumulative Gain,NDCG)作为推荐结果的评估指标[14]。
Precision表示推荐方法推荐的课程被用户喜欢的比例,其计算式如下:
(11)
式中:R(u)表示推荐模型认为用户喜欢的课程;T(u)表示用户真正喜欢的课程。
NDCG指标通过比较推荐课程结果列表中位置与课程指定所在位置,评估出推荐结果有效性,其计算式如下:
(12)
(13)
式中:r(i)是第i个课程的结果得分;iDCG是查询的理想值,即查询结果好的状态下计算出来的DCG值。
3.4 模型超参数设置
对于神经网络模型,其超参数的初始化设置对模型性能是极其重要的。本文对所构建网络拓扑利用Node2vec随机游走的方法进行嵌入表示,对将相关课程的描述文本信息使用Doc2vec的方法进行嵌入表示,其中Node2vec和Doc2vec参数设置如表2和表3所示。
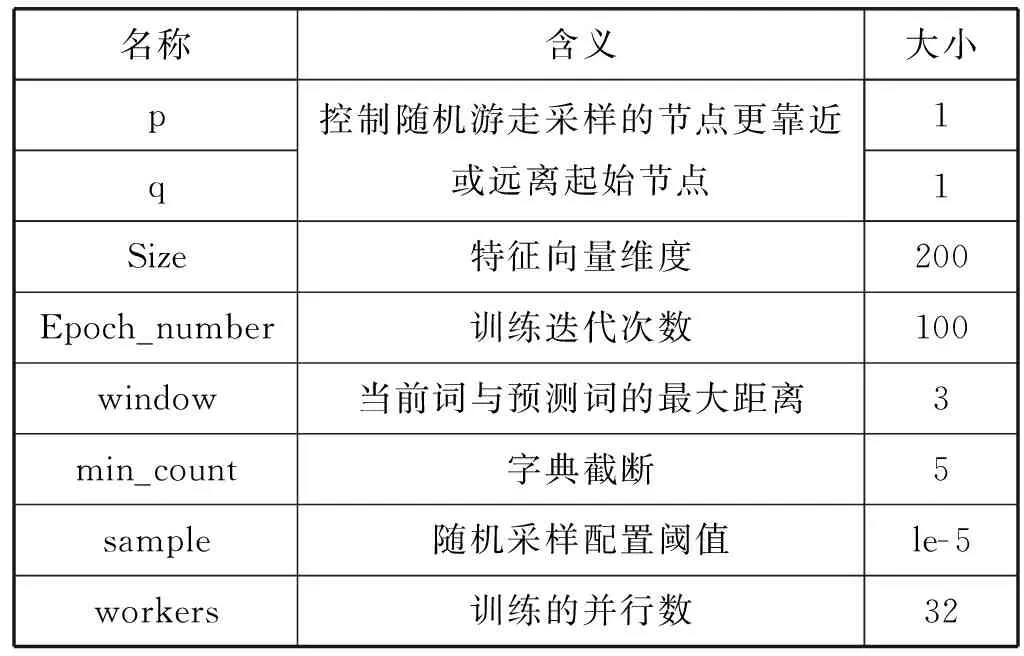
表2 Node2vec参数设置
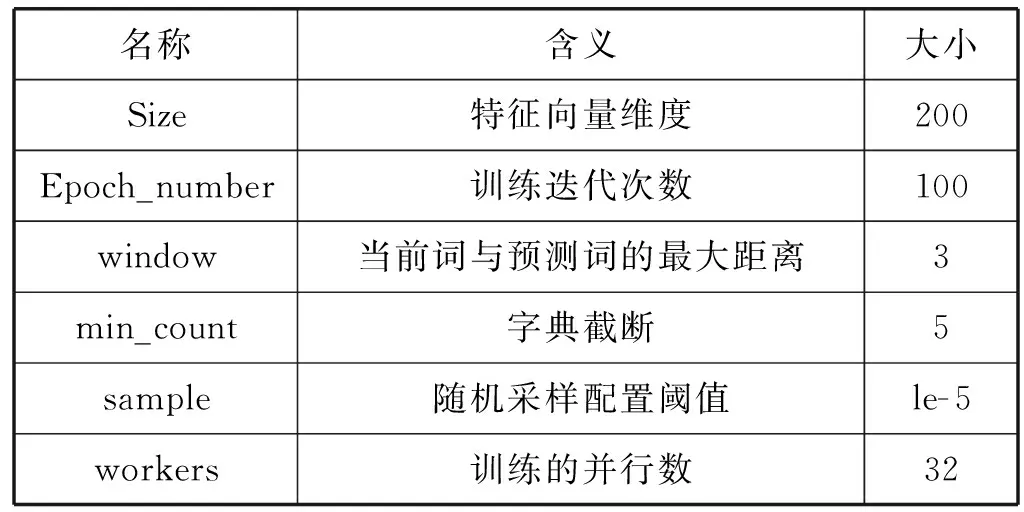
表3 Doc2vec参数设置
最后通过多模块的CNN进行网络和文本特征的转换,为了训练得到性能最好的模型,Epoch大小设定为250,且在每20个Epoch后保存一次模型,最后选择在测试集上效果最好的模型作为本文最后的推荐模型。表4给出了本本提出模型的参数设置情况。
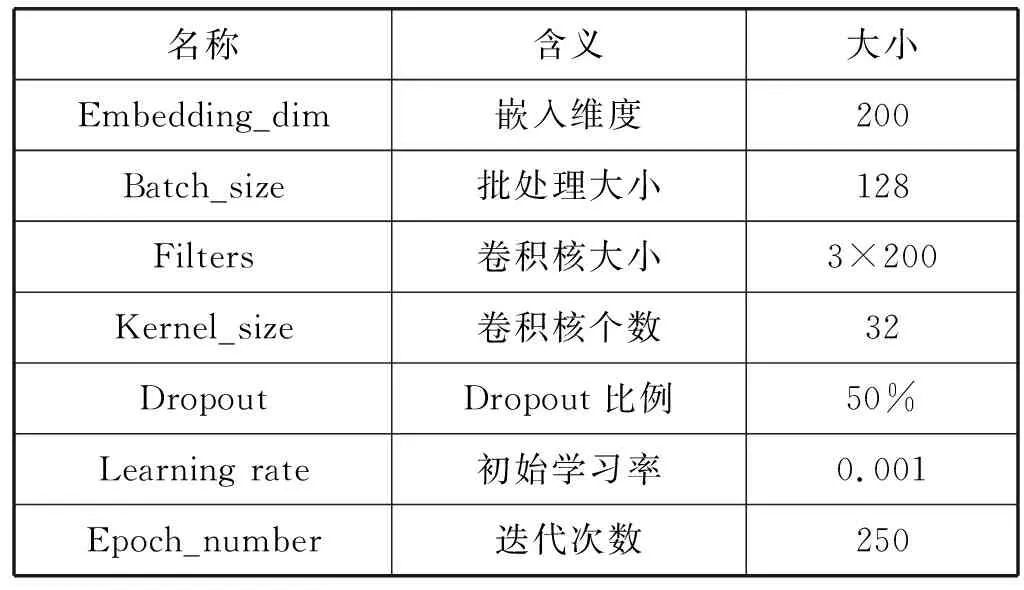
表4 模型超参数设置
3.5 模型对比结果分析
TopN推荐中,N表示在推荐列表中的前N个推荐课程。实验结果如表5和图7所示,本文推荐模型较其他模型表现出了最好的推荐效果。当N=10时,在推荐指标准确率Precision指标上,本文模型比基于用户的最近邻推荐方法有约16.4百分点的性能提升,比基于物品的最近邻推荐方法有约10.2百分点的提升,比NMF推荐方法有约9.5百分点的提升,比基于神经网络模型的FGMSI推荐方法有约5.2百分点的提升;在更注重推荐列表排序的指标NDCG方面,本文模型比基于用户的最近邻推荐方法有约23.6百分点的提升,比基于物品的最近邻推荐方法有约23.5百分点的提升,比NMF推荐方法有约16.9百分点的提升,比基于神经网络模型的FGMSI推荐方法有约4.86百分点的提升。可以得出,本文以课程、学生和教师为主体构建网络拓扑,利用Node2vec随机游走的方法获取了课程与课程、学生与课程、老师与课程之间的关系,并通过多模块的神经网络结构将它们有机地融合在一起,有效地提升了模型的推荐性能。
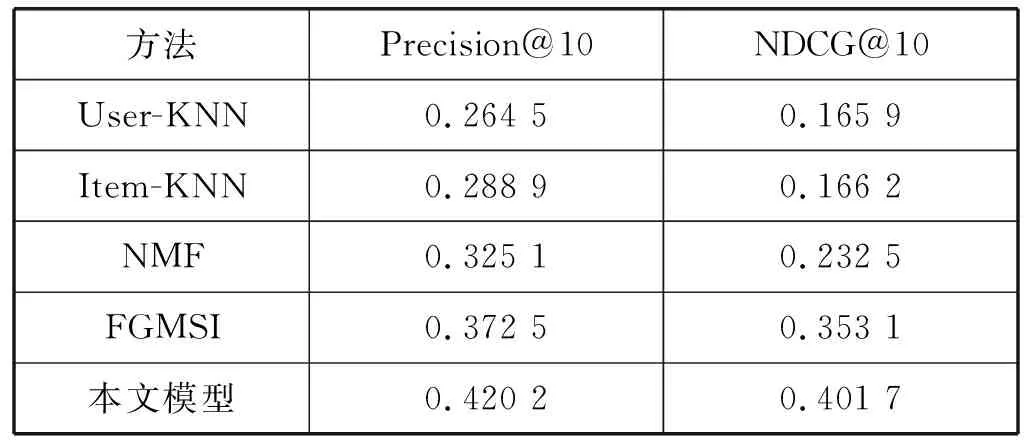
表5 N为10时推荐模型的性能

(a) 准确率
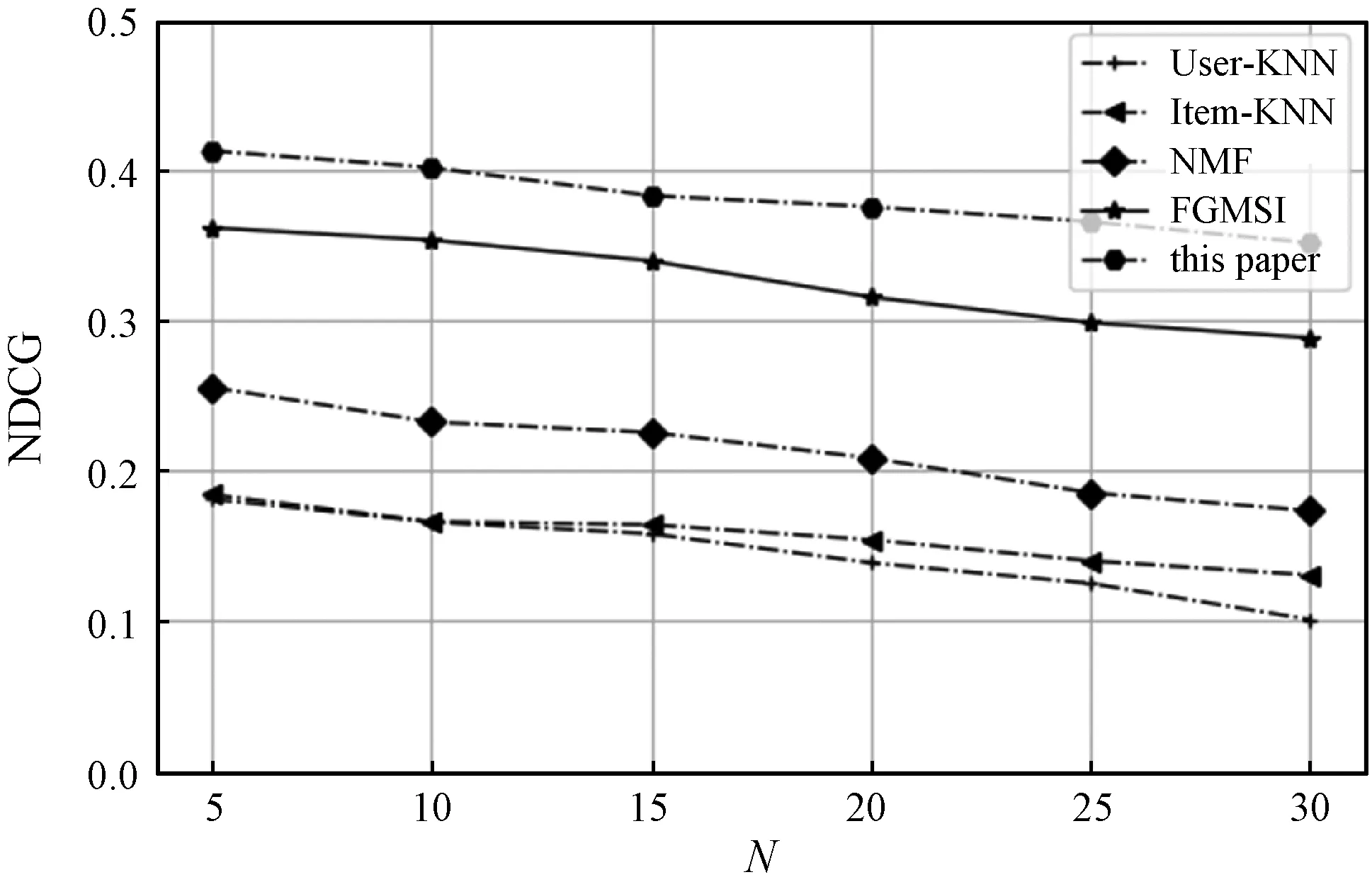
(b) NDCG图7 各模型在数据集上的性能比较
3.6 推荐实例
为了能直观地说明本文模型的推荐机制,本文选取了数据集中的一条推荐实例加以说明。如图8所示,对于特定学生A,推荐目标是根据目前学习记录(计算机组成原理、数据结构、人工智能原理等),及其相关的图结特征和文本描述特征,将目标课程“操作系统”进行精准推荐。在本实例中,由于“操作系统”与已学习的三门课程具有类似的网络结构,同时,它们的描述文本也具有相似之处(如:计算机、基础课程、大学生必修等),因而本文提出的模型会将该目标课程排在相对靠前的位置(第二名),它与排名第一的课程“计算机网络”具有相似的特征。这说明本文提出的模型能够进行精准推荐,同时对于推荐结果是可解释的,显示出其在大规模在线教育平台应用中存在极大的潜力。

图8 推荐实例
3.7 特征重要性分析
除了上述实验,文本通过依次将各特征模块消除的方法来探索各特征对模型性能的影响。实验结果如9所示,图中,C_Student表示在原模型的基础上消除课程-学生元数据信息模块,同理,C_Teacher、C_Course、C_Description表示在原模型的基础上分别消除课程-教师、课程-课程和相关课程的文本描述信息模块。
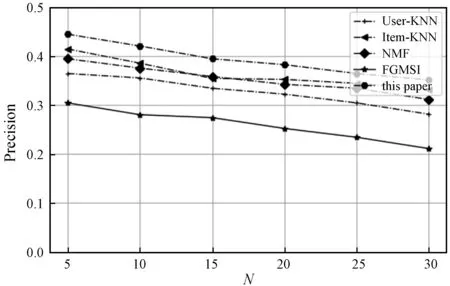
(a) Precision
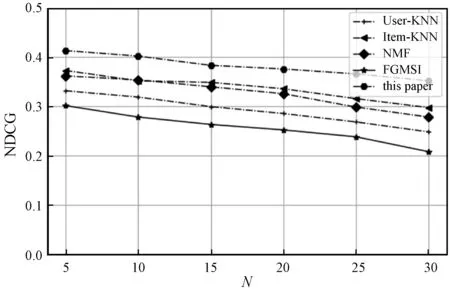
(b) NDCG图9 各实验在数据集上的性能比较
由图9可知,对于本文模型四个输入模块(课程-学生元数据信息、课程-老师元数据信息、课程-课程元数据信息和课程的文本描述信息),去掉某种输入特征之后模型的性能都会下降,说明本文使用的三个网络拓扑结构和文本特征对于模型都有正面的积极作用。在三个网络拓扑结构中,课程-教师网络对模型推荐结果影响最小,课程-课程网络次之,课程-学生网络影响最大,表明对于学生与课程关系的挖掘具有重大潜力。而课程文本描述信息相较三种网络特征对模型的推荐效果影响都大,说明文本特征对推荐模型效果最重要。这进一步表明本模型融合课程-学生、课程-教师和课程-课程的网络拓扑结构,并结合课程描述文本信息来建模学生的偏好,能为学生提供个性化、精准化的学习资源推荐服务。
4 结 语
本文提出了一种融合网络特征和文本特征的智能课程推荐方法。首先构建在线课程的网络拓扑结构,并将其通过Node2vec映射到低维向量空间中,同时将文本数据通过Doc2vec表示,使用多模块CNN神经网络拟合网络和文本特征并计算用户和目标课程之间的相似度。在进行推荐时,选择匹配度最高的TopN课程。实验结果表明,该方法的性能远远超过四种基准模型性能,同时消除实验表明本文使用的每种特征对于推荐性能的提升都有积极作用。在以后的工作中,将挖掘更多形式的异构特征(例如学习序列、课程的多模态数据),并探讨不同特征融合方法对于智能课程推荐的影响。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
高中生学习·高三版(2016年9期)2016-05-14
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
大连工业大学学报(2015年4期)2015-12-11
