
三维人体姿态估计中均一化金字塔特征捕捉网络
2023-03-15 03:50汪洋继鸿杨大伟
大连民族大学学报 2023年1期
汪洋继鸿,杨大伟,毛 琳
(大连民族大学 机电工程学院,辽宁 大连 116605)
姿态估计准确度与特征提取能力密切相关,但人体部件遮挡、肢体欠匹配会带来估计误差,降低这些误差仍是当前实现精准姿态估计的主要困难。目前基于深度学习的主流算法分为基于3D信息的直接回归[1]、基于2D信息生成和混合方法三类,其中混合方法因其训练负荷较低且可避免姿态多义性而被广泛使用。
在混合方法中,Jahangiri等[2]首次将2D与3D特征信息混合训练,生成较为准确三维姿态,但3D人体生成器网络结构较为简单,提取特征信息能力有限。同年Zhou等[3]提出一种户外弱监督[4]3D人体姿态估计网络,加入深度回归模块提取深度特征,同时利用2D特征对3D姿态加以约束,既提高估计精度又有效预防过拟合,但骨架信息过于单薄,不能充分表达人体姿态,姿态估计需要一种新的呈现方式。SMPL[5]通过改变形状与姿态等参数构建一个完整的网格化“人体”,可以精确表达不同性别、体型等人体姿态。Choi与Moon等以SMPL为基础提出Pose2Mesh[6],通过增加更深层网络复杂特征表达能力,使估计结果更接近真实值。HRNet[7]从加宽网络的角度将姿态估计的精度进一步提高,与加深网络层数不同,网络拓宽使得整个过程保持高分辨率表征,避免从低分辨率表征中恢复高分辨率表征过程丢失特征细节,预测关键点热图和空间点更精确。Sun等[8]以混合方法构建一套将HRNet作为网络主干的姿态估计算法,利用生成人体中心热图约束三维人体模型,既对特征进行良好提取,又保证所估计模型的准确性。针对以上方法进行大量研究,混合方法可以简化为主干提取特征,三条支路对主干所提供丰富特征信息进一步提取,最后分别生成热力、2D和3D图像并融合。现有研究对混合信息种类与融合方式等进行改进,但尚未关注各支路特征提取性能对遮挡和肢体欠匹配问题的影响。
针对遮挡和肢体欠匹配问题,本文提出一种多通道多尺度的均一化金字塔[9]特征捕捉网络(Unified Pyramid Features Capture Net,UC-Net),将特征捕捉模块应用于该网络的三条支路,利用不同大小卷积核感受野不同的特性对特征进行多尺度捕捉,为分类器提供更准确的特征信息,明显改善姿态估计过程中由遮挡、误识别等造成的误差较大问题,在VR、AR和动作捕捉[10]等场景估计结果更精准。在3DPW[11]数据集上测试结果MPJPE[12]与PA-MPJPE比ROMP分别降低1.9%和3.1%。
1 UC-NET算法
1.1 问题分析
三维人体姿态估计常用混合方法,将混合特征融合获取人体姿态,其结构如图1。混合方法将相同特征分为三条支路同时处理,三条支路分别生成热力、2D和3D三种图像,通过fM将三种图像融合,最后输出三维人体姿态图像M0,其中热力图像为语义信息,2D图像为纹理信息,3D图像为姿态信息。
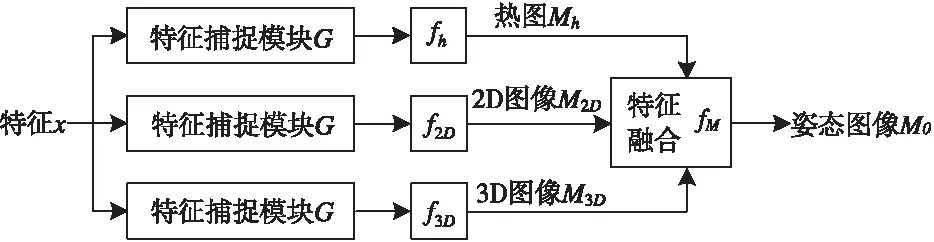
图1 混合方法简化结构图
为能够充分提取图像中语义、纹理和姿态的细节特征,本文将卷积、归一化和激活函数的特定组合设定为特征捕捉模块,将上述特征提取过程称为特征捕捉。主干网络提取特征x传递至混合支路,经特征捕捉模块G进一步提取特征,使用图像生成器fh、f2D和f3D分别生成热力、2D与3D图像,对这些图像进行融合输出三维姿态图像。
混合方法从多个维度解决姿态估计问题,利用热力、2D与3D三种信息,极大程度地降低从2D图像生成三维姿态造成的姿态多义性误差,其过程可以表示为
(1)
式中:G为特征捕捉模块函数;C、B和R分别为卷积、归一化和激活运算;fh、f2D和f3D分别为热力、2D和3D图像三条支路中,生成对应图像特征运算;Mh、M2D和M3D分别代表热力、2D和3D图像;fM为特征融合过程;M0为输出三维人体姿态图像。
由于对语义、纹理特征提取不足,当图中人物出现遮挡情况造成人体不完整时,会出现人体部件遮挡、肢体欠匹配等误差。姿态估计失败示意图如图2。
混合方法中,因行为场景前背景复杂程度高,各种干扰因素众多,单一尺度很难观察清楚全部细节信息。特征捕捉模块不能对主干网络提取的丰富特征进行充分利用,导致特征表达能力不足,难以对图像姿态细节充分表征。因此,通过多尺度方式提高特征的利用率,进一步提高分类精度。

图2 姿态估计失败示意图
1.2 均一化金字塔特征捕捉网络
1.2.1 金字塔特征捕捉模块
为解决上述人体部件遮挡、肢体欠匹配等问题,本文专注于提高特征捕捉模块性能,提出金字塔特征捕捉模块,其网络结构如图3。
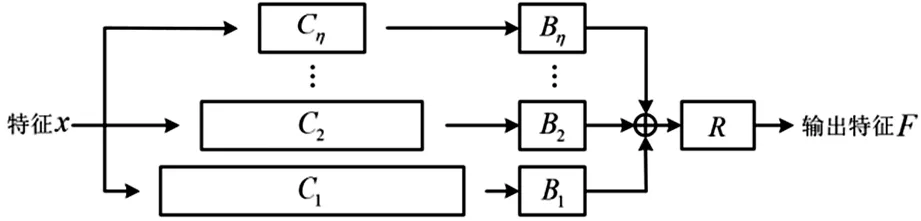
图3 金字塔特征捕捉模块结构图
金字塔特征捕捉模块为一个η层金字塔结构,每层结构都由卷积串联归一化构成,输入为特征x,将所有批量归一化模块输出相加,最后经过激活函数ReLU输出。金字塔特征捕捉模块计算公式:
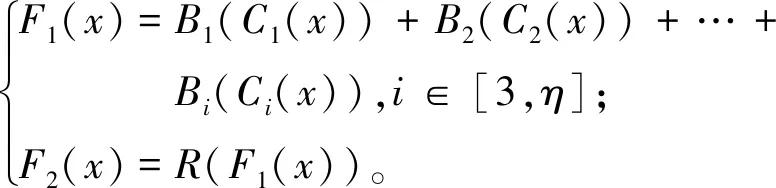
(2)
式中:i为金字塔层数;Ci为金字塔第i层卷积计算;Bi为第i层批量归一化计算;F1为金字塔结构输出函数;F2为输入F1并经过R激活的输出函数。
金字塔特征捕捉模块以特征x为输入,经过并联多尺度卷积Ci对其进行特征提取,利用Bi线性化处理,最后将结果相加并激活。对于特征捕捉模块,单一尺度卷积感受野有限,难以提取多尺度特征信息,造成细节特征提取不充分,须加强对特征提取的能力,使特征信息多样化,因此加入多尺度卷积改变感受野面积,强化对不同特征提取能力。同时因为原网络特征捕捉模块为单通道,对特征捕捉能力有限,于是将多尺度卷积并联排列,进一步强化特征提取能力。
为了下文更方便地表达该模块,公式(2)可整体表示为式(3),其中F为特征捕捉模块输出函数。
(3)
1.2.2 均一化处理
特征捕捉模块结构单一是热力、2D和3D图像三条支路共同的问题,因此本文采取均一化处理方式,即将金字塔特征捕捉模块同时应用于三条支路,构成“相同组成结构、不同处理维度”的均一化金字塔特征捕捉网络,其结构如图4。
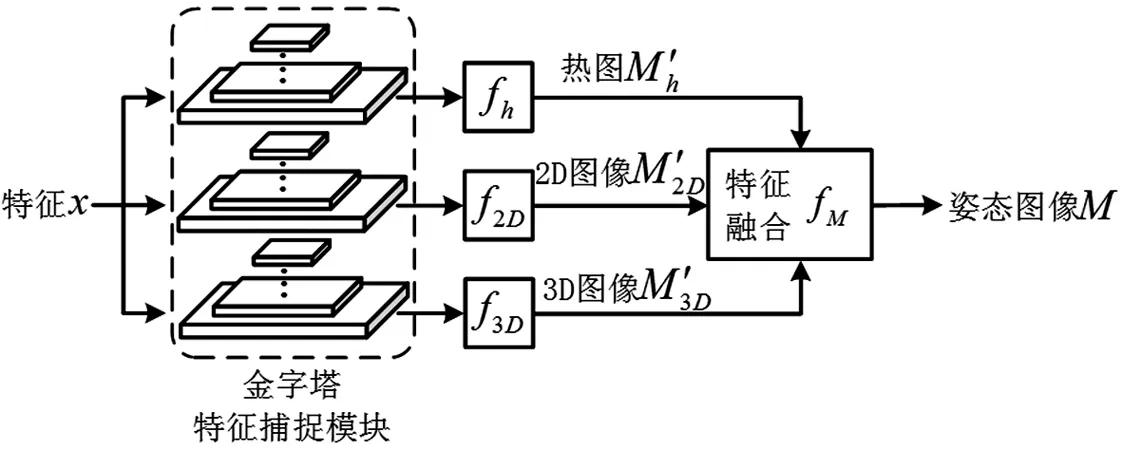
图4 均一化金字塔特征捕捉网络结构图
均一化金字塔特征捕捉网络计算公式可以表示为
(4)
式(4)与式(1)相比,均一化金字塔特征捕捉网络可以对不同尺度特征进行更充分提取,丰富特征使热力、2D和3D图像对细节特征更敏感,热力、2D和3D特征图像M′h、M′2D和M′3D包含更多细节特征,进而融合后输出姿态图像M更加精准。
1.3 整体网络结构
在特征捕捉模块部分,本文提出了金字塔特征捕捉模块以获取更丰富的细节特征,进而增强姿态估计模型性能。整体姿态估计模型如图5。
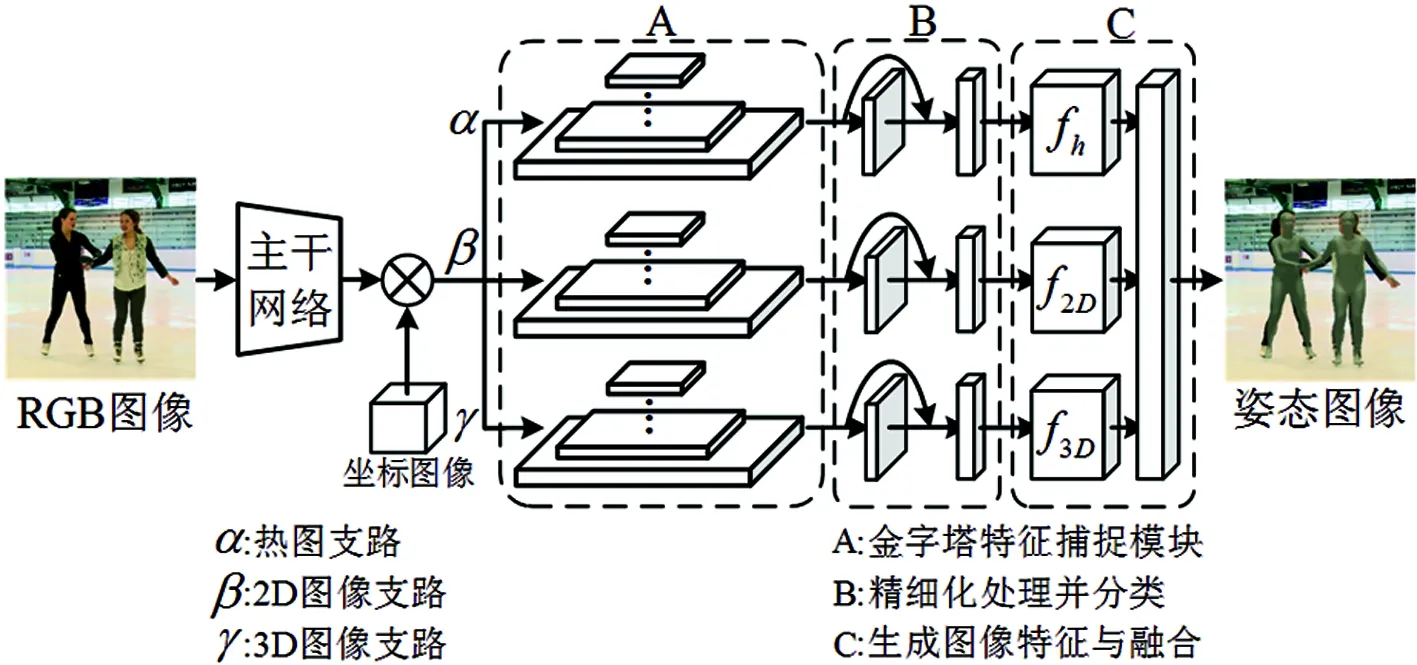
图5 整体网络结构图
网络流程如下:
步骤1:主干提取与坐标融合。在初步特征提取阶段,采用HRNet32作为提取主干,并将提取到的特征与坐标图像进行融合。该过程为主干H32对输入RGB图像Iinput进行特征提取,并将输出结果与坐标图像Coordmaps融合,输出特征图像FBC。
步骤2:特征捕捉。主干HRNet32提取基础特征与坐标图像融合后传送至三条支路,均一化金字塔特征捕捉网络对特征进一步提取,将特征FBC带入式(3),经过多尺度卷积和归一化运算后使用ReLU函数激活,将输入通道数为34维的特征图像扩充为64维,得到特征F′BC。
步骤3:精细化处理。首先对两个连续基础ResNet模块RN对F′BC进一步精细化处理,其次通过1×1卷积C1×1对三条支路输出图像特征进行维度处理,使热力、2D和3D三条支路输出特征图像FC维度从64分别升降至1、3和142。
步骤4:支路图像生成与融合。将三条支路中维度变换后的特征图像FC分别输入至热力、2D和3D图像,生成器fh、f2D和f3D中生成热力、2D和3D图像Mh、M2D和M3D。将2D与3D图像相加得到三维人体网格图像Mm,与热力图Mh进行参数采样输出三维人体姿态图像M。
2 实 验
2.1 实验设计
使用1张NVIADIA GeForce 1080Ti显卡,在Ubuntu16.04环境基础上,应用PyTorch1.7.0深度学习框架进行训练和测试。使用主干网络HRNet32,输入图像尺寸为512×512,训练阶段与测试阶段批尺寸皆为16,学习率为0.000 05,同时训练人数最大值为128。
采用4个2D数据集和3个3D数据集进行训练:2D数据集为COCO[13]、CrowdPose[14]、LSP[15]和MPII[16];3D数据集为Human3.6M[12]、MPI-INF-3DHP[17]和MuCo[17];测试集为3DPW。具体数据见表1。
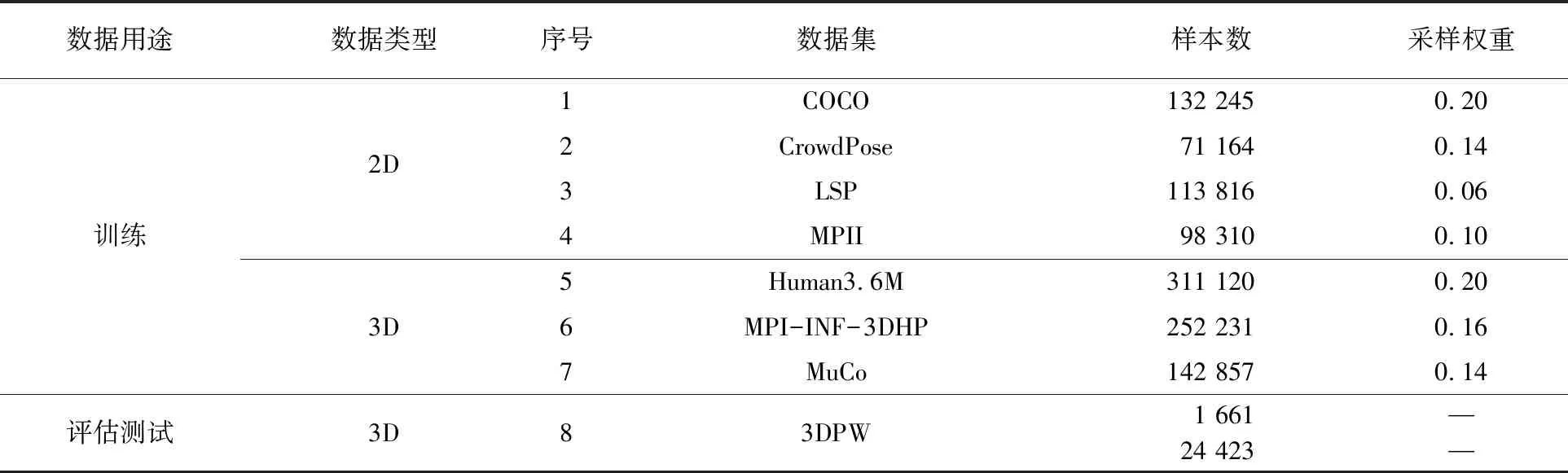
表1 数据集信息
2.2 性能指标
为确保生成估计结果准确性,测试模型与真值平均每关节位置误差的欧氏距离(Mean Per Joint Position Error,MPJPE),MPJPE最早由Catalin Ionescu在Human3.6M中提出,对于帧f和骨架S,计算公式:
(5)
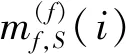
另一个指标PA-MPJPE是MPJPE的改进型,对估计模型参照真值进行平移、旋转和缩放,即进行普罗克鲁斯对齐后计算误差(Procrustes-Aligned Mean Per Joint Position Error,PA-MPJPE)。PA-MPJPE可以消除平移、旋转和尺度的影响,更专注于评估重建3D估计骨架的准确性。
2.3 实验结果与分析
对比实验数据采用3DPW数据集,结果见表2。

表2 三维人体姿态估计算法对比
实验结果表明,所提出网络UC-Net中MPJPE与PA-MPJPE评分分别为87.2和53.6,相较于改进前原始算法ROMP的MPJPE与PA-MPJPE评分88.9和55.3分别降低1.9%和3.1%。
将ROMP与本文针对输出姿态图像进行可视化结果对比如图6。

图6 姿态图像可视化结果对比
本文使用三组图像对比改进前后网络输出姿态差别。图6第(1)行可以明显看出,面对普通遮挡情况时,ROMP与UC-Net都能够进行准确估计,但面对严重遮挡与模糊时,ROMP无法识别人体,UC-Net则可以对人体进行估计;图6第(2)行中,UC-Net相较于ROMP对纹理细节特征更敏感,可以对图中微小目标进行估计,而ROMP会出现遗漏情况;图6第(3)行同时面对肢体遮挡与运动模糊困难,ROMP所估计姿态肢体匹配不准确,但UC-Net输出姿态则与真实姿态十分接近,能够克服遮挡等造成肢体匹配不准确的误差。
2.4 消融实验
为验证所提出网络的有效性,对网络模型进行消融实验,采用3DPW数据集和MPJPE、PA-MPJPE评价指标。为探究不同卷积核大小及特征捕捉模块层数对结果准确率的影响,设计实验见表3。

表3 不同卷积核大小及特征捕捉模块层数性能对比
表3中,不同组别特征捕捉模块结构:
k∈[0,2]。
(6)
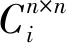
3 结 语
本文针对三维人体姿态估计混合方法进行改进,提出均一化金字塔特征捕捉网络。通过金字塔特征捕捉模块,加强了对图像中语义、纹理和姿态细节特征的提取能力,生成热力、2D和3D图像准确度提高,增强了融合后生成姿态图像表征能力,改善了由人体部件遗漏和肢体欠匹配造成估计误差较大的问题。为VR、AR和动作捕捉等领域精准姿态估计提供有效解决策略。后续工作将进一步提高对不同体型人体姿态估计能力,扩大适用人群范围。
猜你喜欢
西安石油大学学报(自然科学版)(2022年5期)2022-10-08
环球时报(2022-09-19)2022-09-19
考试与评价·七年级版(2020年4期)2020-10-23
少儿美术(快乐历史地理)(2019年2期)2019-06-12
电子制作(2018年19期)2018-11-14
童话世界(2017年11期)2017-05-17
自动化学报(2017年11期)2017-04-04
电信科学(2016年9期)2016-06-15
电测与仪表(2016年13期)2016-04-11
噪声与振动控制(2015年4期)2015-01-01
