
基于DRL的抗干扰电视频谱资源分配算法
2023-03-09 06:08鲍家旺丘航丁徐浩东
电视技术 2023年1期
鲍家旺,丘航丁,徐浩东,马 驰
(福州大学 电气工程与自动化学院,福建 福州 350108)
0 引 言
快速发展的物联网会产生巨量的数据,这增加了对频谱资源的需求,导致频谱资源稀缺的问题[1]。认知无线电(Cognitive Radio,CR)是解决这一问题的有效工具。电视的空白频段是第一个被考虑的频谱共享案例。大多数物联网设备通过无线通信技术进行互联,由电池供电。电池容量限制所造成的能量问题是制约物联网发展的另一问题。能量采集(Energy Harvesting,EH)技术可以从各种绿色能源(如光、热、风和射频源)中获取能量,延长了能量限制网络的使用寿命[2]。许多研究考虑将EH和CR技术与物联网结合起来,提出了能量采集认知物联网(EH-CIoT)。
CR网络由于其开放的特点,比其他无线电网络更容易受到安全威胁,受到的攻击包括主用户仿真攻击、学习攻击、窃听和干扰等。其中,干扰攻击被认为是最具有威胁性的攻击,它会导致系统吞吐量下降、网络瘫痪等。文献[3]提出了一种基于批处理的安全感知协议。最近,深度强化学习(Deep Reinforcement Learning,DRL)技术被认为可以帮助物联网在环境和干扰源之间存在连续交互的情况下实现最优的传输策略。文献[4]将双DQN(Deep Q-Network)算法和跳频策略应用于多用户环境下的干扰攻击。然而,上述现有的工作以及对抗干扰策略的研究都只考虑了短视或离线模型。短视的政策只考虑即时奖励,而忽略了长期回报,这不是连续CIoT系统的最优策略。离线策略假设环境动态是已知的,但在发射机或控制器上是非因果关系的。在上述文献的基础上,本文将研究在干扰攻击下基于DRL的EH-CIoT传输算法,以最大限度地提高系统的长期吞吐量。
1 系统模型
本文考虑了CR的交织模式,即一种保护性的频谱共享方案。EH-CIoT系统模型如图1所示,主要由三部分组成:主用户网络(Primary User Network,PUN),由M个主用户(Primary Users,PUs)和1个基站(Base Station,BS)组成;认知物联网络(CIoTN)由1个 代 理 基 站(Agent Base Station,ABS)和N个EH-C节点组成;1个恶意攻击节点(Malicious Attack Node,MAN)。PUN覆盖了K个正交电视频谱信道,CIoTN位于PUN的覆盖区域内,所有设备在同步的时隙模式下工作。假设ABS能获得完美的频谱感知,Ik(t)={0(busy),1(idle)}表示ABS在t时隙感知到的第k个信道的状态,空闲通道数量为
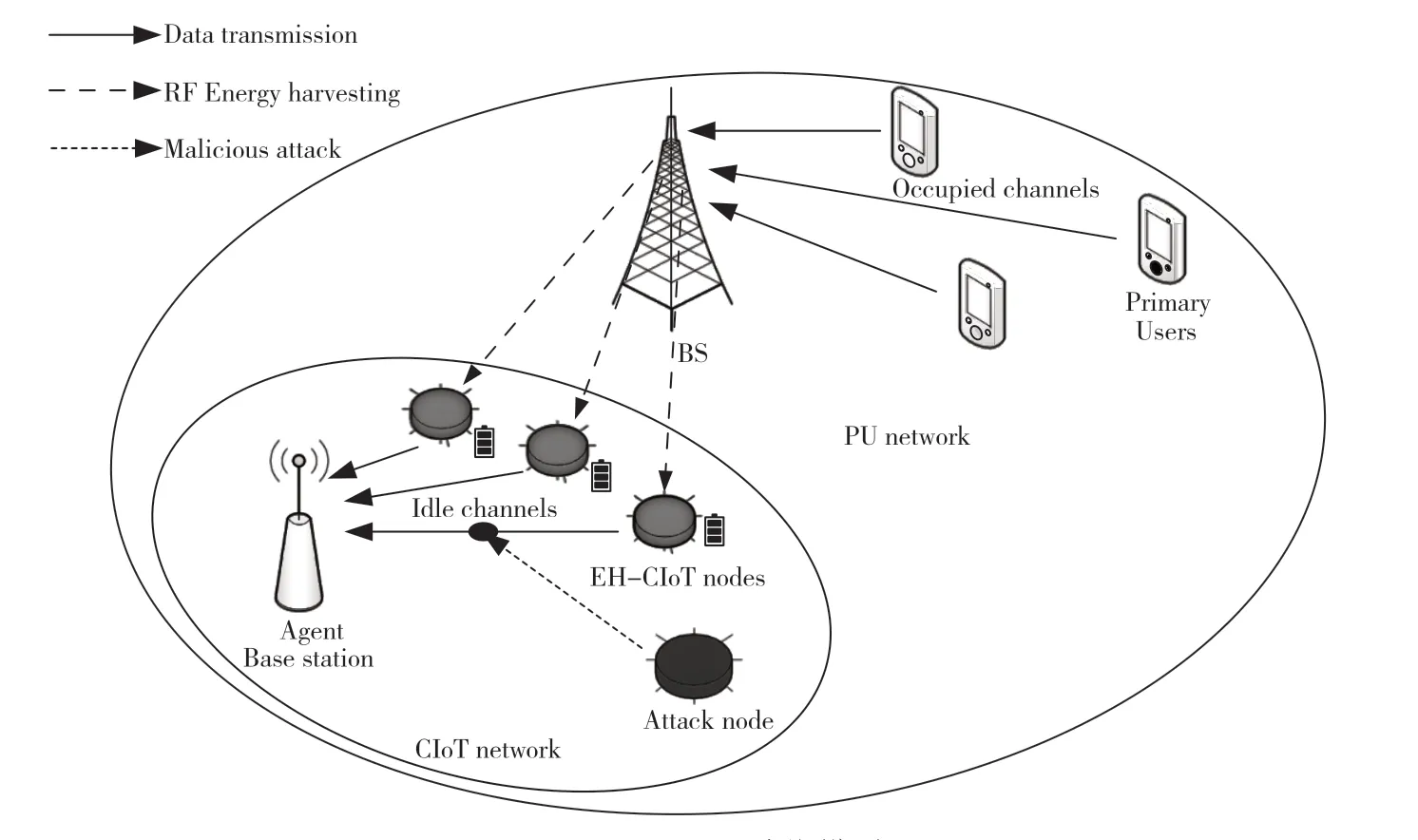
图1 EH-CIoT系统模型
1.1 EH-C节点的两种模式选择
在CIoTN中,每个EH-C节点都有相同的配置,节点不能同时执行射频能量采集和信道接入。EH-C节点在每个时隙t的开始将自身的电池水平状态集通过专用的控制信道发送到ABS。ABS在当前时隙t根据感知到的信息来确定所有EH-C节点的工作模式(采集模式或传输模式),分配所有EH-C节点的传输功率并广播决策。表示第i个EH-C节点在第t个时隙的发射功率,设EH-C节点最大发射功率为即因此,在第t个时隙,所有EH-C节点的功率分配策略集合表示为第i个EH-C节点在第t个时隙的工作模式Mi(t)可以描述为

图2 EH-C节点时隙
1.2 能量采集和更新
上述系统均有功率约束。主基站(Primary Base Station,PBS),MAN和ABS由电网供电,EH-C节点由可充电电池供电。
1.2.1 能量采集
第i个EH-C节点在第t个时隙采集的能量Ei(t)为
式中:η表示能量转换率,表示与i不同的第s个EH-C节点的发射功率,为干扰功率。第t个时间隙内所有EH-C节点总的采集能量集合记为
1.2.2 电池更新
第t个时隙中所有EH-C节点的电池状态集为电池容量标记为Bmax。第i个EH-C节点的电池状态从第t个时隙到第t+1个时隙的演变可以表示为
2 问题定式化
本文考虑一种广泛使用的主动干扰攻击,它不知道设备的任何活动,只根据预定义的策略发射干扰脉冲,用策略表示,其中Ik(t),分别为在时隙t与信道k的干扰间隔、干扰概率和干扰功率。本文考虑两种攻击方法:
(1)随机干扰器,在每个时隙t以功率Pk J(t)随机选择干扰一个信道;
(2)扫描干扰器,在一个时隙t内以概率Pk J(t)从K个信道中顺序干扰KN个信道。
干扰器的最大发射功率为PJmax,ABS接收到的第i个EH-C节点的信噪比(Signal to Interference plus Noise Ratio,SINR)可用以下公式计算:
本文的主要目的是在恶意攻击的环境下最大化长期信道吞吐量。CIoTN的瞬时和吞吐量为
式中:0<γ<1表示折扣函数。利用干扰模型,将累积吞吐量最大化问题表述如下:
式中:E[·]表示期望的给定值。式(11)所列的条件保证EH-C节点用于传输的能量不超过可用的剩余能量,保证接收的信噪比不小于接收阈值SINRthreshold,保证接入信道数不大于可用信道数。
3 基于DRL的传输优化算法
3.1 基于RL的EH-CIoT网络框架
本文构建一个环境模型,用一个MDP来描述要解决的问题[5],即MDP=(S,A,Psa,R,γ),其中S表示状态空间,A表示动作空间,Psa为状态转移概率,R为即时奖励,γ是折扣因子。Agent是系统模型中的ABS。
状态空间S:第t个时隙的状态空间定义为
式中:I(t)={I1(t),…,IK(t)}表示信道状态集。
动作空间A:第t个时间段的动作向量定义为:At=P(t)。ABS以连续功率分配作为动作值。
即时奖励R:在采取行动后,ABS将获得即时奖励:
3.2 基于DDPG的资源分配算法
深度确定性策略梯度(DDPG)算法由策略网络、价值网络和经验回放池三部分组成。网络由4个深度神经网络组成,即在线批评网络θQ,在线策略网络θ μ,目标批评网络θQ´和目标策略网络θ μ´。更新网络参数时,从容量为C的经验回放池D中抽取NB份数据,第i份表示为(sx,ax,rx,sx+1)。让它们通过梯度上升/下降算法来训练网络参数。
在线批评网络的损失函数为差值的均方误差:
目标值yx的计算方法如下:
在线策略网络的损失函数为:
对于两个目标网络的更新,采用软更新方法:
式中:ξ∈(0,1]表示更新速率,具体步骤如算法1所示。每一步动作都从期望为μ(St|θ μ)方差εσ2的随机过程中选择,即At~N(μ(St|θ μ),εσ2),其中ε是一个参数,用于减弱训练中动作的随机性。
算法1干扰攻击下基于DDPG的资源分配算法
初始化:初始化参数θQ和θ μ;清空D;动作随机参数ε;EH-C节点的电池水平。
输入:CIoT网络仿真参数,恶意攻击节点参数。
步骤1 for 迭代次数episode=1,2,...,F do
步骤2 初始化环境状态s0
步骤3 for 训练步数t=1,2,...,G do
步骤4 选择动作At~N(μ(St|θ μ),εσ2)
步骤5 获得R(St,At)和下一个状态St+1。
步骤6 将数据(St,At,Rt,St+1)保存至D
步骤7 ifD已满,do
步骤8 采样NB个数据(sx,ax,rx,sx+1)
步骤9 最小化L(θQ)更新在线批评网络
步骤10 最大化L(θ μ)更新在线策略网络
步骤11 按式(17)软更新目标网络
步骤12 衰减动作的随机性:σ2←εσ2
步骤13 end for
步骤14 end for
输出:每个时隙的最佳动作At。
4 实验仿真及结果分析
4.1 模拟设置
本文模拟了恶意攻击的多用户认知物联网模型。在1 km×1 km区域内,PBS位于[500,500],ABS位于[250,250]。N=10,K=10,M=3,T=1 s,交换所消耗的能量ef=0.01 J,最大干扰功率,能量转换率η=0.8。每个结果都在Pytorch 1.7.1工具上实现。本文与以下算法进行了比较:
(1)随机算法,随机选择传输信道,并随机分配节点的功率;
(2)贪婪算法,感知空闲信道,以允许的最大功率传输数据;
(3)SAC算法,连续控制的非策略DRL算法。
DDPG和SAC算法的在线和目标网络分别包含L1=256和L2=256。激活函数设置为ReLU,并将优化器都设置为Adam,学习率为0.004和0.002。软更新速率ξ为0.005。迭代次数为300,每次迭代的步数为10~100。
4.2 统计结果及分析
首先比较了无干扰下的算法性能,结果如图3(a)所示。DDPG算法在150次迭代后趋于收敛。SAC算法的收敛速度优于DDPG算法。当迭代数为80时,它趋于收敛。但DDPG比SAC获得了更高的平均吞吐量(>30%)。这表明,与基于SAC的算法相比,DDPG算法更适合在CIoT环境中使用。图3(b)和图3(c)比较了四种算法在随机和扫描干扰两种主动干扰策略下的性能。与无干扰的情况相比,DDPG算法在随机干扰和扫描干扰下的性能仅降低了约5%,而收敛后的SAC的性能降低了约15%。这两种RL算法都明显优于传统的随机算法和贪婪算法。DDPG算法的性能是随机算法的2.5倍,是贪婪算法的2倍。这表明,该算法能够有效地学习主动干扰的固定策略,预测干扰,合理分配功率,从而减少干扰,提高吞吐量。

图3 三种攻击下的平均吞吐量
图4显示了这些算法在三种干扰情况下的能量效率。每焦耳能量可以通过系统发送的比特量称为能量效率(b·J-1)。显然,在三种干扰条件下,DDPG算法的能量效率最高,保证在6 b·J-1左右。SAC在干扰条件下的性能与随机算法相当,均在3 b·J-1左右。贪心算法的性能最差,保持在1 b·J-1。这说明了该DDPG算法对每个EH-C节点的功率分配的合理性。

图4 三种攻击下的能量效率
5 结 语
本文研究了恶意攻击环境下CIoTN的资源分配问题,目标是在抗干扰的同时使EH-CIoTN的长期吞吐量最大化。本文提出了一种基于DDPG的DRL算法,它的目标是在与动态环境交互、不断学习攻击策略、智能调整传输策略的过程中获得最大的奖励。仿真结果表明,无论是随机干扰还是扫描干扰,DDPG算法都能更好地学习恶意节点的策略,系统性能明显优于其他算法。
猜你喜欢
舰船电子对抗(2020年2期)2020-06-23
铁道通信信号(2018年9期)2018-11-10
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
舰船电子对抗(2016年3期)2016-12-13
广西大学学报(自然科学版)(2016年5期)2016-11-12
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
电子设计工程(2015年8期)2015-02-27
