
文本分析途径的课程持续改进目标识别
2023-03-08 10:57董东
软件导刊 2023年2期
董 东
(河北师范大学 计算机与网络空间安全学院,河北 石家庄 050024)
0 引言
面向能力的学习效果评价越来越受到计算机教育领域的关注[1-4]。完成任务所需的知识(Knowledge)、技能(Skills)和素质(Dispositions)合称为胜任力(Competency)[5]。持续改进是工程教育的基本要求,利用教育数据实现教学持续改进引起越来越多教育工作者的关注[6]。对持续改进目标的识别一般通过任课教师的经验,或对课程目标的达成度分析实现[7]。对知识的学习效果易于实施客观教育测量,然而技能和素质更多是内隐的心理生理认知习得成果,难以通过面向知识的客观教育方法实施有效评价。是否可以通过对学生的技能和素质在实操过程中认知发展水平进行度量,进而实现对学习目标的难度评价呢?教育与认知心理学的相关研究给予了肯定回答[8]。
卖油翁说:“我亦无他,惟手熟尔。”[9]这意味着技能是靠实际操练才能形成,并不是依赖单纯的记忆和理解等认知行为,因此技能评价也应在实际操练中进行。例如,中国传统武术通过打擂台比拼功夫高低;对厨师水平的评价是通过专家品尝其制作的菜品来完成;在车里平放一满杯水,通过观察水是否溢出这一显式特征评价驾驶员行车的平稳性这一内隐特征。目前对能力的度量方法包括基于课程测验成绩和基于量表两大类。基于课程测验成绩的方法通过设计面向能力度量的试题卷,按照一定评分标准判卷后得到一个分数,然后通过这个分数评价学习者个体和总体对能力目标的达成度;基于量表的方法通过设计量表,通常使用评分加总式的李克特(Rensis Likert)五级量表,然后让学习者回答问卷的项目,具体指出自己对该项陈述的认同程度,最后对量表进行分析。这两种方法共同的问题有:一是对试卷题目或李克特选项的设计难度较大;二是没有体现实际操练。
随着大数据可得性的提高[10-11],数据驱动教学引起了教育工作者的兴趣。例如,王树梅等[12]基于线上讨论、作业、实验、阶段测试等各教学环节的评价数据提出数据驱动的形成性学习效果评价方法;王莉等[13]对大学计算机公共课的“平台+数据”线上混合式教学课前、课中、课后3 个环节中得到的学生学习数据进行分析,阐述如何把握教学质量。然而,如何通过学习过程中的数据发现课程教学改进目标未见深入论述;樊敏生等[14]对如何有效地在教学中实现基于数据的、动态化的学习干预进行了理论与实践探索;梅鹏江等[15]通过学习通平台收集学习行为数据对学生进行聚类分析,以发现不同类型学生的学习行为特点,但仅限于对学习行为方面的教学改进目标识别。
当前大多数据驱动教学改进方法基于过程性评价数据进行。为此,本文提出一种直接包含外显性因素过程数据的方法,通过本科课程软件工程项目实践中对工程项目《学生选课系统》的案例研究,总结了通过文本分析技术识别持续改进目标的方法,即完成一学期的程序设计类课程后,在后继学期要求学生使用该课程所学语言完成一个具体的工程项目,然后通过分析学生在项目完成过程中遇到的问题和认知变化发现其能力方面的欠缺,从而得出对该课程的改进目标。
1 课程概况
Java 面向对象程序设计课程在应用型本科计算机类专业第2 学年第4 学期进行,学生已经学过C 语言程序设计和数据结构知识。该课程每周线下讲授2 课时,实验2课时。课堂教学以板书知识点+程序演示方式为主;实验教学以验证型实验为主,主要通过重做教师课堂演示的例子强化对知识点的理解。
该课程的目标包括能够通过例子解释封装、继承和多态的概念;能够实现给定的类模型;能够使用群集框架(Collections Framework)实现集合、线性表等数据结构;能够使用Java Swing 设计图形用户界面;能够使用输入输出流读写文件;能够使用Java 程序解决综合实际问题等。课程评价主要根据平时作业、实验报告和期末考试进行。《学生选课系统》是一个基于Java 平台的软件工程实践项目,要求学生提交的项目报告包含组员分工及组内评价、文件版本、数据库版本、图形用户界面(GUI)版本、Web 版本等各个版本完成的工作(基本要求)、扩展功能实现方法、遇到的问题及解决方法、个人提高等。
2 持续改进目标识别方法与过程
通过对学生提交的项目结项报告进行文本分析来识别课程的持续改进目标。从最具演绎性到最具归纳性可将文本分析分为计数和字典方法、有监督学习和无监督学习3 类。演绎性使用了先验知识,事先知道寻找什么,并假设某些规则或前提;而归纳性是指不使用先验知识,以某种算法从文本中识别有意义的模式。计数和字典方法使用关键词、布尔表达式或正则表达式来计算文本中某些词元的出现频率。如果预先确定了类别,有监督的方法比较合适;无监督方法的优势在于发现未知的类别。
选课学生结项报告中的“遇到的问题及解决方法”和“个人提高”部分为能力达成度评价提供了外显特征。通过关键字语境查询、特征排名、用户自定义关键字分类查询和话题检测等技术,综合识别存在的共性特征,最后结合人工解释和判断,形成前驱课程目标达成度评价,得到前驱课程的持续改进目标。通过文本分析识别课程持续改进目标的技术路线如图1所示。
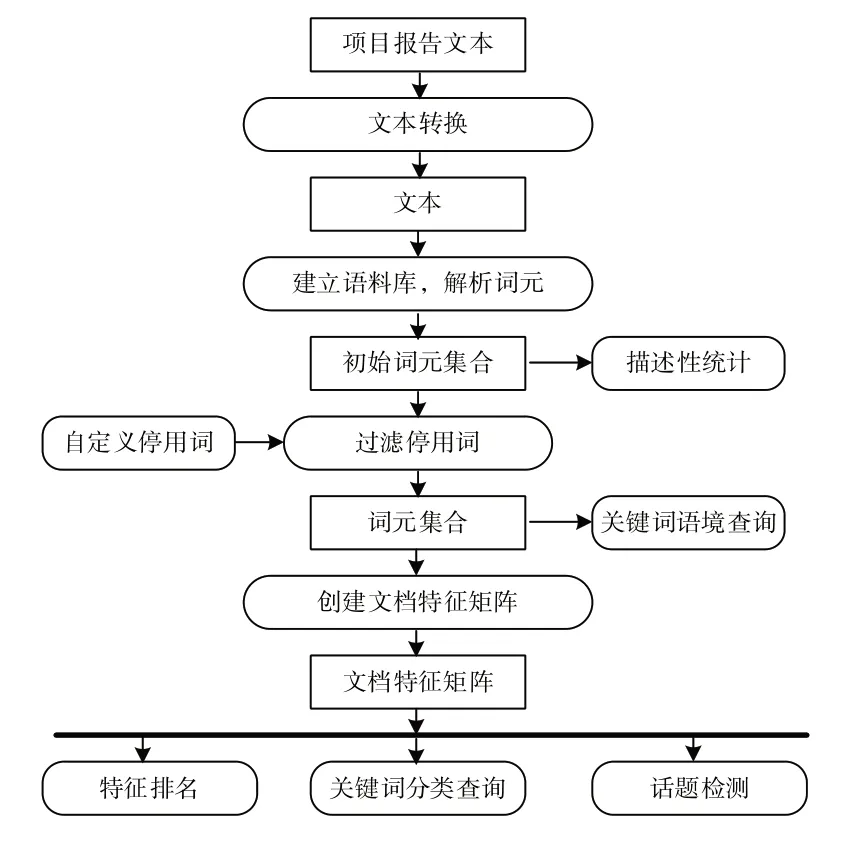
Fig.1 Technology roadmap图1 技术路线
3 工具与实现
建立语料库以及后续分析均在R 4.1.2 中完成,使用的R 包包括文本数据量化分析包quanteda[16]、结构话题模型包stm[17]以及 readtext 包等。本文使用的quanteda 包提供的功能及其实现函数如表1所示。
本案例中共有84 名同学参与工程项目,自由结合,分为21 组。首先将学生提交的Word 文件形式的结项报告另存为文本文件,然后删除“完成工作”部分,仅保留“遇到的问题及解决方法”和“个人提高”部分。通过R 包readtext导入这21 个文本文件,然后使用quanteda 包的corpus()函数构造成语料库。
解析词元也称为词元化(tokenize),是指将文本切割为词元的过程,这一步骤对计算文本分析至关重要,最常见的词元为英文单词、运算符、标点符号、汉字、汉字词组、成语等。采用quanteda 包的summary()函数得出的语料库中词元和句子描述性统计如表2 所示。可以看出,21 篇文档平均每篇有1461 个词元,最少的有36 个词元,最多有4618个词元,可以进一步进行基于词元的分析。
下一步是过滤停用词。首先自定义停用词,例如姓名、学号、任务、分工、实验、报告、错误、代码、进行、GUI、Person、Teacher 等,连同英文通用停用词、中文停用词全部过滤,如此便得到用于进一步分析的词元集合。基于词元集合,以“了解、熟悉、加深、明白、清楚、懂得”这些认知动词作为关键词,通过kwic()函数逐一查询其出现的上下文。返回88 个匹配项目,其中有“加深final 关键字理解”“加深 HashMap 理解”“加 深Iterator 接口理 解”“了解map 键值用法”等,说明学生对final 关键字、对群集Map、迭代器以及接口等的掌握可能有所欠缺。
然后使用dfm()函数创建文档特征矩阵,应用topfeatures()函数从特征矩阵中提取前90 个特征,结果如表3 所示。文档特征矩阵将词元作为行,将词元的计数作为列,例如“用户”在语料库中的计数是97。计数相同的词元视为排名相同。从表中可以看到,学生对接口、容器、路径、输入、布局、窗口、框、Map、导入(import)等的学习目标未达成。
接下来进行关键词分类查询。首先定义6 类关键字,分别为异常、群集、流、接口、和图形界面。异常类中的关键字有NullPointerException、InputMismatchException、try、catch;群集类中的关键字有List、Map、HashMap、key、value、equals、hashcode、Iterator、next、hasNextInterface;流类中的关键字有FileReader、FileInputStream、Scanner;接口类中的关键字有泛型、连接、接口;图形界面类中的关键字有JTableJScrollPane、AWT、Swing、JPanel。然后使 用tokens_lookup()函数查询这些自定义关键字在每个文档中出现的频数,然后按照类别求均值,结果如表4 所示。统计结果表明学生对“接口”“群集”的掌握较差,而对“异常”和“流”的掌握较好。

Table 1 Functions and implementation表1 功能及实现函数
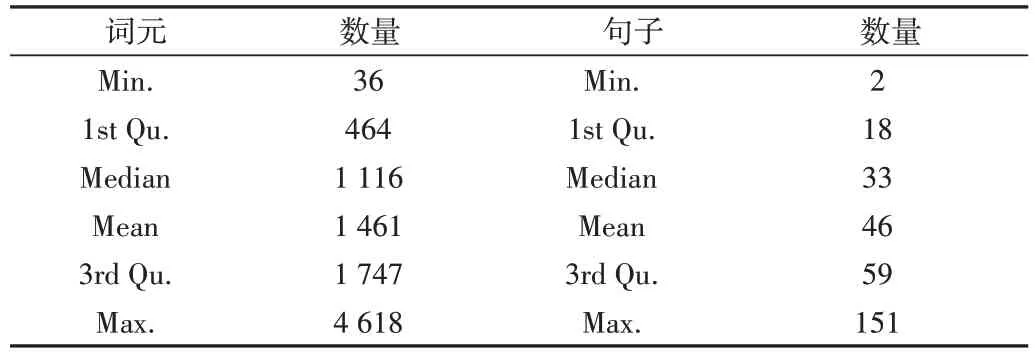
Table 2 Descriptive statistics of tokens and sentences in the project reports表2 项目报告中词元和句子的描述性统计
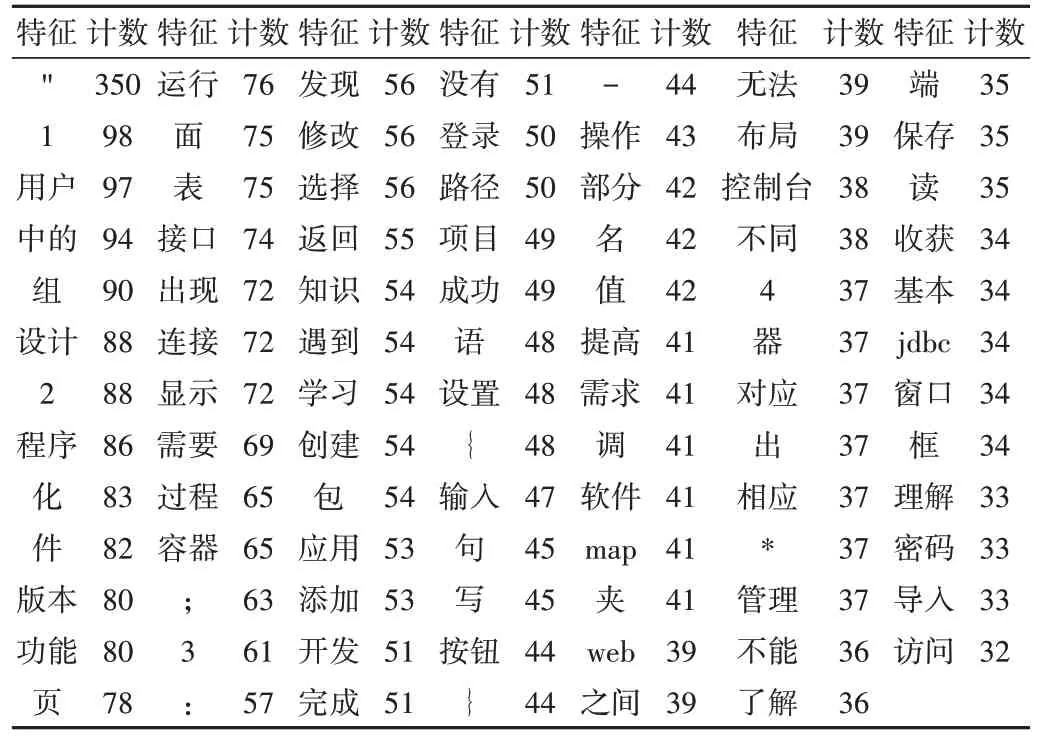
Table 3 Top 90 features in the document feature matrix表3 文档特征矩阵中排名前90的特征

Table 4 Result of aggregation by group表4 分组统计结果
最后识别话题。首先使用dfm_trim()剔除低频词元,然后使用函数dfm()识别话题。检测出话题有“发现,显式,需要”“件,组,容器”“版本,功能,化”“连接,用户”“map,类型”“表,修改”“发现,合作”“需求,设计”“容器,成功”“接口,元素”等,进一步确认了群集对象Map、接口、图形用户界面、合作能力是学生的弱项,可使用plot()函数可视化识别到的话题。将特征提取结果{接口,容器,路径,输入,布局,窗口,框,Map,导入}、分组查询结构{接口,群集}和话题模型检查结果{Map,接口,图形用户界面,合作}综合,得到Java 面向对象程序设计课程的改进目标为{Map,接口,图形用户界面,导入,合作}。随机从84 个选课学生中选择10 名,针对改进目标设计调查问卷,结果显示90%同学选择完全符合,10%同学选择部分符合。将该结果用于次年的教学改进中,例如在Java 面向对象程序设计课程教学中不再让学生使用Eclipse 自动导入程序需要的包,而是改用jGrasp 设计程序,使学生手动导入包。次年度按照持续改进目标调整了前驱课程Java 面向对象程序设计的教学方案。将继续选修后继课程——软件工程项目实践的学生的结项报告按照前文描述的技术路线识别出改进目标为:{多线程,接口,合作}。与上一轮课程的改进目标{ Map,接口,图形用户界面,导入,合作}相比,数量上减少了40%;内容上,“Map”“导入”“图形用户界面”等60%的改进目标完成。
4 应用问题分析
在实际应用本文提出的方法和工具时,应注意以下问题:①quanteda 包对中文分词的结果并没有注意到特定的软件工程和程序设计语言的上下文,这可能导致分词结果并不理想;②应根据课程目标人工定义用户自定义字典以进行分组查询。由于课程目标不同,可能导致查询结果不具有参考价值或可解释性;③虽然结构话题模型可能过多识别不被感兴趣的话题,但该模型能够在大数据无标签环境下实现自动话题识别以及呈现话题网络,考虑到课程改进目标的查全率应高于查准率,因此结构话题模型是适用的;④案例实施期间,任课教师应通过课前告知、课上公开表扬、线上私下批评、评分策略等方式鼓励学生诚实、独立地报告自己的感受。只要输入是完整客观的,输出就可解释、可使用;⑤本案例研究中只有84 名学生分为21 组开发同一个项目。虽然参与者的选择具有随机性,也可以视为总体,但是结果是否能够具有更大的一般性还需要进一步评估。本案例研究确实可以找到有意义的学生课程目标达成弱项,但是如果能够在更大规模的学生参与下进行研究结果会更好。
5 结语
本文提出一种半自动化的针对程序设计类课程的持续改进目标识别方法。该方法直接使用学习过程数据而不是评价数据,通过对学生的后继项目结项报告进行文本分析,手工导入数据,自动识别学生在前驱程序设计类课程能力目标方面的短板,适用于大规模在线课程以及线上线下混合课程。识别能力目标达成的弱项可为工程教育的持续改进活动提供方向,还可更好地掌握学情,有针对性地改进课程教学内容。未来研究将在以下几个方面展开:①增大参与学生规模;②针对不同年级连续研究;③提升查准率。
猜你喜欢
华人时刊(2022年1期)2022-04-26
计算机教育(2020年5期)2020-07-24
动漫界·幼教365(大班)(2019年10期)2019-10-28
电子制作(2019年9期)2019-05-30
福建质量管理(2019年10期)2019-03-28
电子测试(2018年9期)2018-06-26
长春师范大学学报(2017年9期)2017-03-29
山东工业技术(2016年15期)2016-12-01
制造技术与机床(2015年10期)2015-04-09
环球时报(2009-11-25)2009-11-25
